Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SRE study group 3rd slide
Search
Korenaga Makoto
May 01, 2020
Technology
75
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
SRE study group 3rd slide
Korenaga Makoto
May 01, 2020
More Decks by Korenaga Makoto
See All by Korenaga Makoto
SRE study group 4th slide
hapoon
2
110
SRE study group 2nd slide
hapoon
1
75
SRE study group 1st slide
hapoon
1
73
Slackアプリを使ってデイリースクラムを効率化
hapoon
1
600
モノリシックからマイクロサービスへ
hapoon
0
130
Other Decks in Technology
See All in Technology
product engineering with qa
nealle
0
140
SRE歴2ヶ月でも開発6年の知見を活かして、チームで止まっていた環境改善を前に進めた話
a_ono
0
200
RAGの精度向上とエージェント活用
kintotechdev
2
130
きのこカンファレンス2026_肩書きを外したとき私は誰か
yamasatimi
1
130
勉強会企画をアプリで構造化してみた 〜そこで見えた、AIとの付き合い方〜 / I've structured a study group plan using an app.
pauli
0
300
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
0
150
AIペネトレーションテスト・ セキュリティ検証「AgenticSec」紹介資料
laysakura
2
8k
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
870
組織における AI-DLC 実践
askul
0
300
從觀望到全公司落地:AI Agentic Coding 導入實戰 — 流程整合與安全治理
appleboy
1
750
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
0
140
ご挨拶「10周年を迎える共創ラボのこれまでとこれから」
iotcomjpadmin
0
180
Featured
See All Featured
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
A Soul's Torment
seathinner
6
3k
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
From π to Pie charts
rasagy
0
230
Transcript
Site Reliability Engineering 3rd DevOps unit study group Makoto Korenaga
アジェンダ 1. リスクの受容 2. サービスレベル目標 3. トイルの撲滅 4. 分散システムのモニタリング
リスクの受容
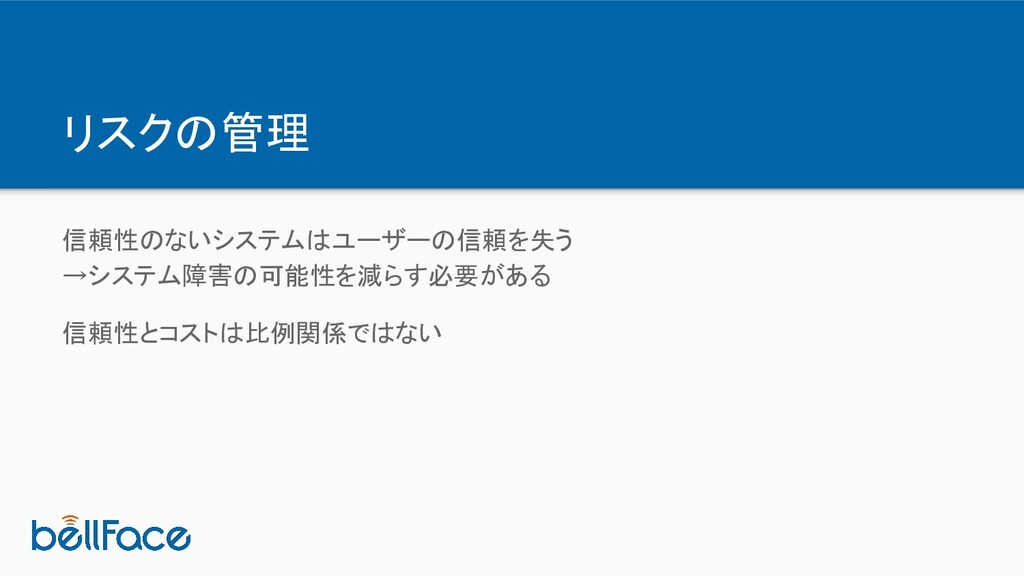
リスクの管理 信頼性のないシステムはユーザーの信頼を失う →システム障害の可能性を減らす必要がある 信頼性とコストは比例関係ではない
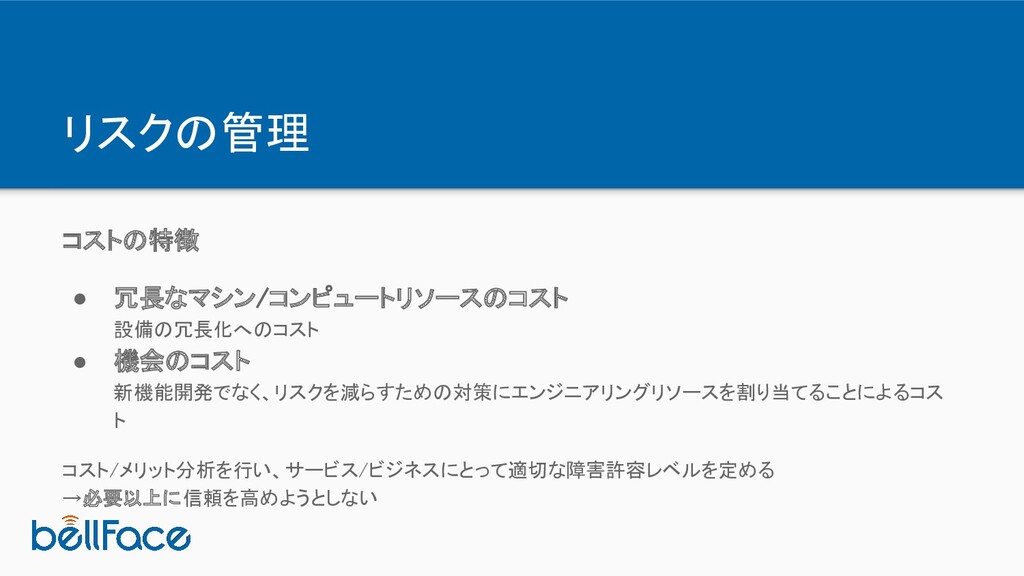
リスクの管理 コストの特徴 • 冗長なマシン/コンピュートリソースのコスト 設備の冗長化へのコスト • 機会のコスト 新機能開発でなく、リスクを減らすための対策にエンジニアリングリソースを割り当てることによるコス ト
コスト/メリット分析を行い、サービス/ビジネスにとって適切な障害許容レベルを定める →必要以上に信頼を高めようとしない
サービスリスクの計測 最適化したいシステムの特徴を表す客観的なメトリクスを見つける 例)計画外の停止時間 可用性=稼働時間/(稼働時間+停止時間) 年間の停止時間を52分33秒以内に収めれば99.99%を満たせる 例)リクエスト成功率
可用性=成功したリクエスト数/総リクエスト数 1日250万リクエスト処理するシステムの場合エラーが250回以内なら99.99%を満たせる
サービスリスクのリスク許容度 SREがプロダクトマネージャーと共同で作業を行い、一連のビジネスゴールをエンジ ニアリング可能な、明確な目標として設定する コンシューマサービスはプロダクト責任者が明確だが、インフラストラクチャサービス にはプロダクト責任者が不在であることが普通なので、リスク許容度の明確化のアプ ローチも異なる
サービスリスクのリスク許容度 コンシューマサービスの場合 • 必要な可用性のレベル • 障害の種類の違いによるサービス影響の差 • サービスコスト • 考慮すべき重要なサービスメトリクス
サービスリスクのリスク許容度 必要な可用性のレベル • ユーザーが期待するサービスレベル • サービスが直接的に収入につながっているか • サービスは有料か、無料か • 市場に競合がある場合、その競合が提供しているサービスレベル
• サービスはコンシューマ向けか、企業向けか
サービスリスクのリスク許容度 障害の種類 • 完全なサービス障害なのか、部分的なサービス障害なのか • 頻度はどれくらいか ユーザーの使用時間帯が明確に分かっているサービスでは、使用時間帯を外して定 期メンテナンスを入れることが可能になる
サービスリスクのリスク許容度 コスト • 可用性を1桁改善するようにシステム構築と運用をした場合、収入がどのように 増加するか • この追加の収入は信頼性をそのレベルに高める為のコストに見合うか 例)可用性の改善案: 99.9% →
99.99%(0.09%改善) サービスの収益: 10,000 万円/月 改善された可用性の価値: 10,000(万円/月)x0.0009=9(万円/月)
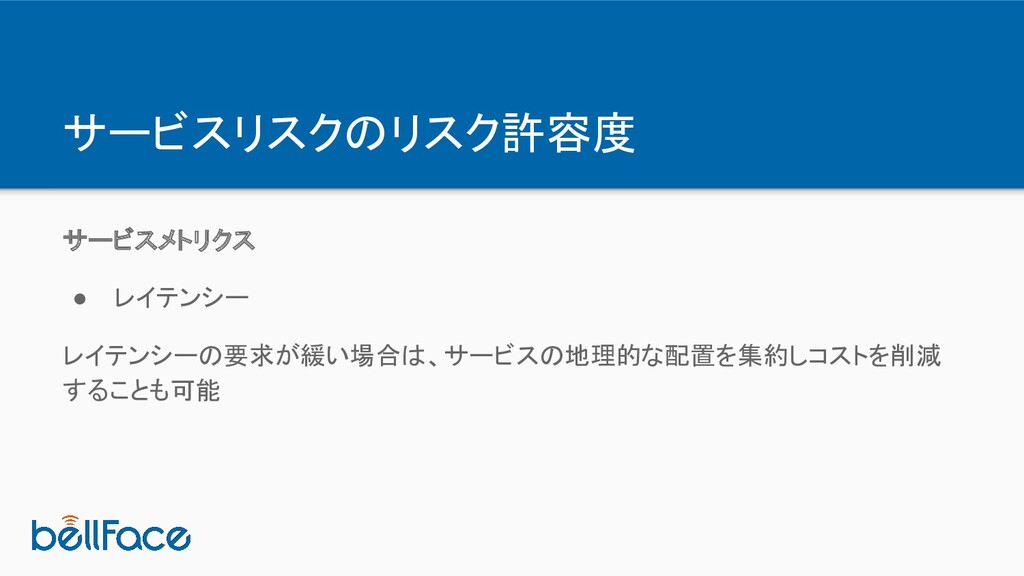
サービスリスクのリスク許容度 サービスメトリクス • レイテンシー レイテンシーの要求が緩い場合は、サービスの地理的な配置を集約しコストを削減 することも可能
サービスリスクのリスク許容度 インフラストラクチャサービスの場合 可用性の要求がサービス、使用するユーザーによって異なる 例)Bigtableの場合 ユーザーサービスでリクエストで使用 低レイテンシーと高可用性 分析チームで使用 高スループット Bigtableの場合、低レイテンシーのクラスタと高スループットのクラスタの2種類を構築できる
エラーバジェットの活用 プロダクト開発が主にプロダクト開発速度で評価される一方で、SREはサービスの信 頼性を基に評価される • ソフトウェア障害の許容度 • テスト • プッシュの頻度 •
カナリアテストの期間と規模
エラーバジェットの活用 エラーバジェットの形成 エラーバジェットとはエラーに対する予算のこと SLO(Service Level Objective)に基づく四半期のエラーバジェットを規定 • PdMがSLOを規定 =
四半期内に期待されるサービスの稼働時間設定 • 実稼働時間は、中立な第三者であるモニタリングシステムによって計測 • 上記2つの差異が、その四半期内の損失可能な信頼性という予算残分となる • 計測された稼働時間がSLOを超えている(エラーバジェットが残っている)なら新しいリリースをプッシュ できる
エラーバジェットの活用 メリット • プロダクト開発者とSREに共通のインセンティブを提供 • 両者がイノベーションと信頼性の適切なバランスを見出すことに注力できる エラーバジェットを使い切りそうな場合、リリースは一時的に停止させ、システムの弾力性を増したり、パ フォーマンス改善にリソース追加する →プロダクト開発者はローンチできなくなるリスクを減らすために、テストを追加したりしてリリースの安定性 を高めたりするようになる
サービスレベル目標
サービスレベルに関する用語 • サービスレベルアグリーメント(Service Level Agreements,SLA) ユーザーとの間で結ぶ明示的あるいは暗黙の契約 SLOを満たせなかった場合は払い戻しやペナルティなど •
サービスレベル目標(Service Level Objectives,SLO) SLI ≤ ターゲット もしくは 下限 ≤ SLI ≤ 上限 • サービスレベル指標(Service Level Indicators,SLI) リクエストのレイテンシー、エラー率、システムスループット、可用性
指標の実際 • サービス提供者とユーザーの関心事を指標とする ユーザーとやり取りするサーバーシステムの場合、可用性、レイテンシー、スループット • 収集 Prometheusのようなモニタリングシステムやログ分析、クライアント側で収集の仕組みが必要な場合 も •
集計 平均よりも分布で考える。パーセンタイルを指標として 50%(中央値)近辺を使えば典型的なケースに 重点を置ける。
指標の実際 • 標準化 例) ◦ 集計のインターバル: 「集計時間は1分とする」 ◦ 集計の対象領域:
「クラスタ内のすべてのタスク」 ◦ 計測の頻度: 「10秒ごと」 ◦ 対象となるリクエスト: 「ブラックボックスモニタリングジョブからのHTTP GET」 ◦ データの取得方法: 「モニタリングシステムを通じて、サーバーで計測」 ◦ データアクセスのレイテンシー: 「最後のバイトまでの時間」
目標の実際 • 定義 計測方法と計測値が適性である条件を指定するべき 例)GETリクエスト呼び出しの 99%が100ミリ秒以下で完了すること • ターゲットの選択
◦ 現在のパフォーマンスに基づいてターゲットを選択してはならない ◦ シンプルさを保つ ◦ 「絶対」は避ける ◦ SLOは最小限にとどめる ◦ 最初から完璧でなくてもよい
目標の実際 • 計測値のコントロール ◦ システムのSLIモニタリングと計測を行う ◦ SLOに対してSLIを比較し、アクションが必要か判断する ◦
アクションが必要な場合、 改善点を明らかにし改善行動を取る • SLOによる期待の設定 ◦ 安全マージンを確保する 公開しているSLOより内部的なSLOを厳しくしておく ◦ 過剰達成を避ける 高可用性に依存した設計となり過度に依存されることを避ける為
アグリーメントの実際 顧客が幅広くいるほどSLAの変更はしづらくなる為、ユーザーに開示する内容は控え めにしておくことが賢明。 SREは、SLOを満たせる可能性や難易度をビジネス及び法務チームに理解させ違反 の際の規程やペナルティを適切に選択できるよう支援する。
トイルの撲滅
トイルの定義 プロダクションサービスを動作させることに関係する作業 以下の1つ以上に当てはまる仕事はトイル度合いが高い • 手作業であること • 繰り返されること • 自動化できること •
戦術的であること • 長期的な価値を持たないこと • サービスの成長に対してO(n)であること
トイルが少ない方が良い理由 GoogleのSREではトイル比率は各人の作業時間の50%以下という目標 トイルを減らし、サービスをスケールさせる作業がSREにおけるエンジニアリング →SREの組織規模がサービスのサイズや数に比例せずに効率的に管理できる
エンジニアリングであるための条件 典型的なSREの活動 • ソフトウェアエンジニアリング • システムエンジニアリング • トイル • オーバーヘッド
四半期あるいは1年を通して平均で50%以上エンジニアリングの作業に当てられな かった場合は何が問題なのか把握し改善が必要
トイルは常に悪なのか? 個人的なデメリット • キャリアの停滞 • モラルの低下 → 燃え尽きや倦怠、不満に繋がることも
トイルは常に悪なのか? 組織的なデメリット • 混乱の発生 → 旧来のシステム管理者と変わらない • 進捗速度の低下 • 習慣づけ • 摩擦の発生 → チーム内でトイルに対する扱い
• 信義違反 → 採用や異動でSREとして加入した場合モラルに悪影響
分散システムのモニタリング
定義 • モニタリング システムに関するリアルタイム定量データの収集、処理、集計、表示を行うこと。 • ホワイトボックスモニタリング システム内部に公開されているメトリクスに基づくモニタリング。 • ブラックボックスモニタリング ユーザーが目にする外部の振る舞いをモニタリング。
• ダッシュボード サービスの主要メトリクスのサマリビューを提供するアプリケーション。
定義 • アラート 人間に読まれることを意図した通知。 チケット、メールアラート、ページに分類。 • 根本原因 ソフトウェアの欠陥やヒューマンエラーで、修正されれば同じことが同様に発生しないと確信できるも のを指す。 •
ノードとマシン 物理サーバー、仮想マシン、コンテナ内で動作しているカーネルの 1つのインスタンスを示す。 • プッシュ サービス動作中のソフトウェア、あるいはその設定に対する変更。
モニタリングの必要性 • 長期的なトレンドの分析 データベースの余裕や DAUの増加ペースなど • 時間や実験グループ間での比較 どちらのクエリの高速か、 memcacheのヒット率はなど •
アラート • ダッシュボードの構築 • アドホックな振り返り分析の進行(デバッギングなど) レイテンシーが急上昇したが、他に何か同時期に生じていることがないか
4大シグナル • レイテンシー リクエストを処理してレスポンスを返すまでの時間 • トラフィック システムに対するリクエストの量 • エラー 処理に失敗したリクエストのレート
• サチュレーション サービスがどれだけ飽和状態になっているか(メモリ、I/Oなど)
適切な計測粒度の選択 粒度を細かくすると収集、保存、分析のコストが非常に大きくなる 一方で粒度を大きくすると一時的なスパイクが平均で均されて気づけなくなる
可能な限りシンプルに、やり過ぎない • 本当のインシデントを最も頻繁に捉えるルールは、可能な限りシンプルで、予想 しやすく、信頼できるものであるべき • ほとんど実施されない(四半期に1回未満のような)データの収集、集計、アラー トの設定は削除すべき • 収集されてはいても、事前に作成されたダッシュボードのいずれにも表示され ず、どのアラートにも使われていないシグナルは削除候補
モニタリングやアラートでの確認点 • ルールが検出する状況は、 そのルールなしで検出されない 状況で、緊急対応が可能で現時点あるい は近い将来にユーザーに影響を及ぼすか? • そのアラートが無害なものだと判断して対応せずにできるものか? (どのような時に、どのような理由で無視できるか? )
• そのアラートが間違いなくユーザーに悪影響を及ぼしているか? (トラフィックのドレイン済やテスト用のデプロイなど除外すべきケースは? ) • そのアラートに対応してアクションが取れるか? そのアクションは緊急か、翌朝まで待つことができるか? 安全に自動化できないか?そのアクションの修正効果は短期的か長期的か? • その問題でページを受ける人は他にもいるか?その場合少なくともページの 1つが不要ではないか?
ページ及びページャーでの確認点 • ページが来る度に緊急事態という感覚で対応が必要。(緊急事態の感覚で対応 可能なのは1日に数回が限度、それを超えると疲弊し始める) • すべてのページは具体的な対応が可能であることが必要。 • あらゆるページは対応に人の判断が必要。自動化が可能なものはページとす べきではない。 •
ページは新たな問題か、これまで見られたことがないイベントに関するものであ るべき。
次回予告
Googleにおける自動化の進化 リリースエンジニアリング 時系列データからの 実践的なアラート オンコール対応 第肆回
ありがとうございました 参照: SRE サイトリライアビリティ エンジニアリング Googleの信頼性を支えるエンジニアリングチーム (オライリー・ジャパン)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}