NeurIPS, 1999. [Swaminathan&Joachims,16] Adith Swaminathan and Thorsten Joachims. Batch learning from logged bandit feedback through counterfactual risk minimization. JMLR, 2016. [Dudík+,11] Miroslav Dudík, John Langford, and Lihong Li. Doubly robust policy evaluation and learning. ICML, 2011. [Saito+,24] Yuta Saito, Jihan Yao, and Thorsten Joachims. Potec: Off-policy learning for large action spaces via two-stage policy decomposition. 2024. [Brown+,20] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. NeurIPS, 2020. November 2025 PhD candidacy exam (A-exam) @ Cornell CS 100
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
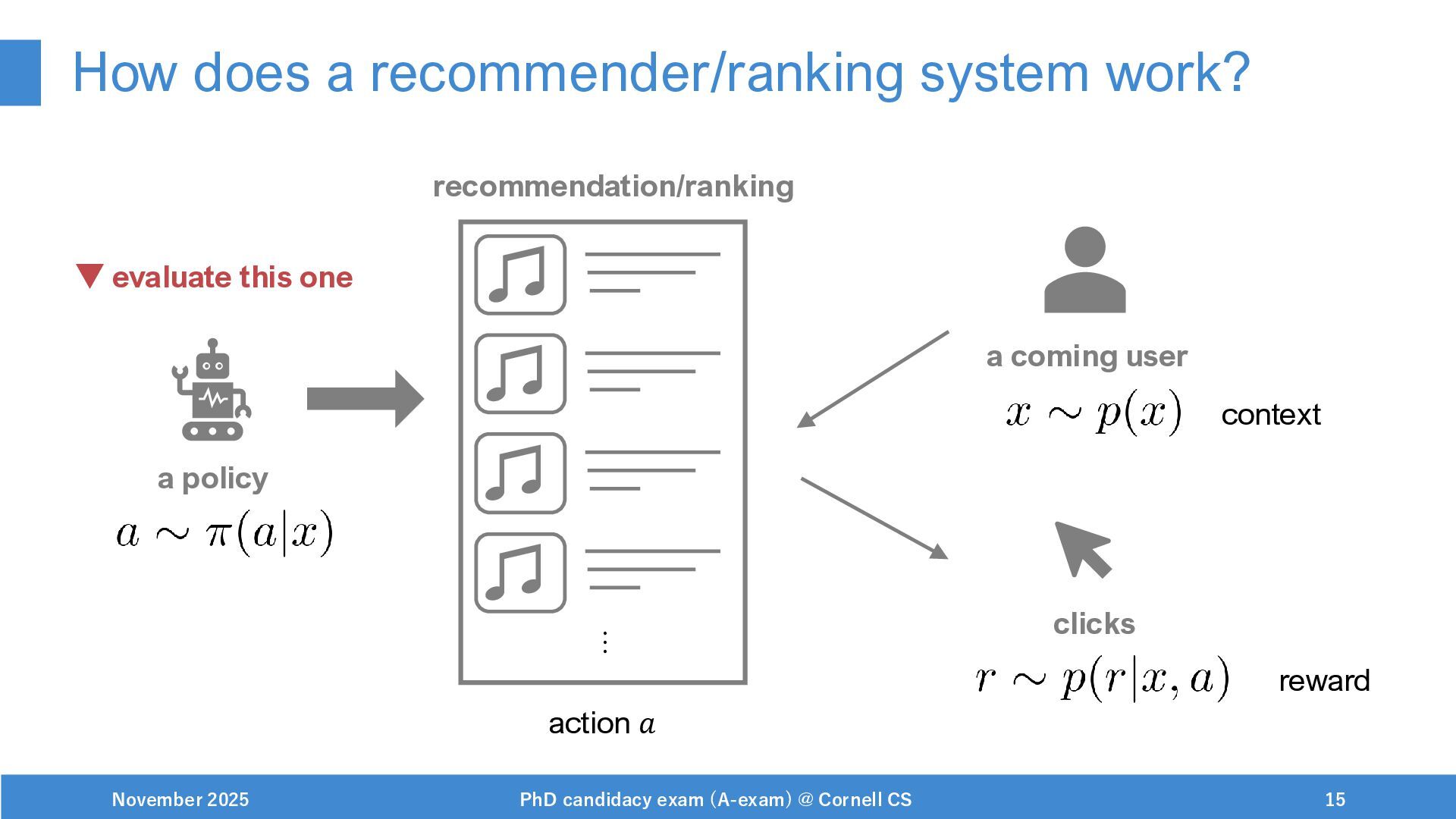{kind=link}
{kind=link}
{kind=link}
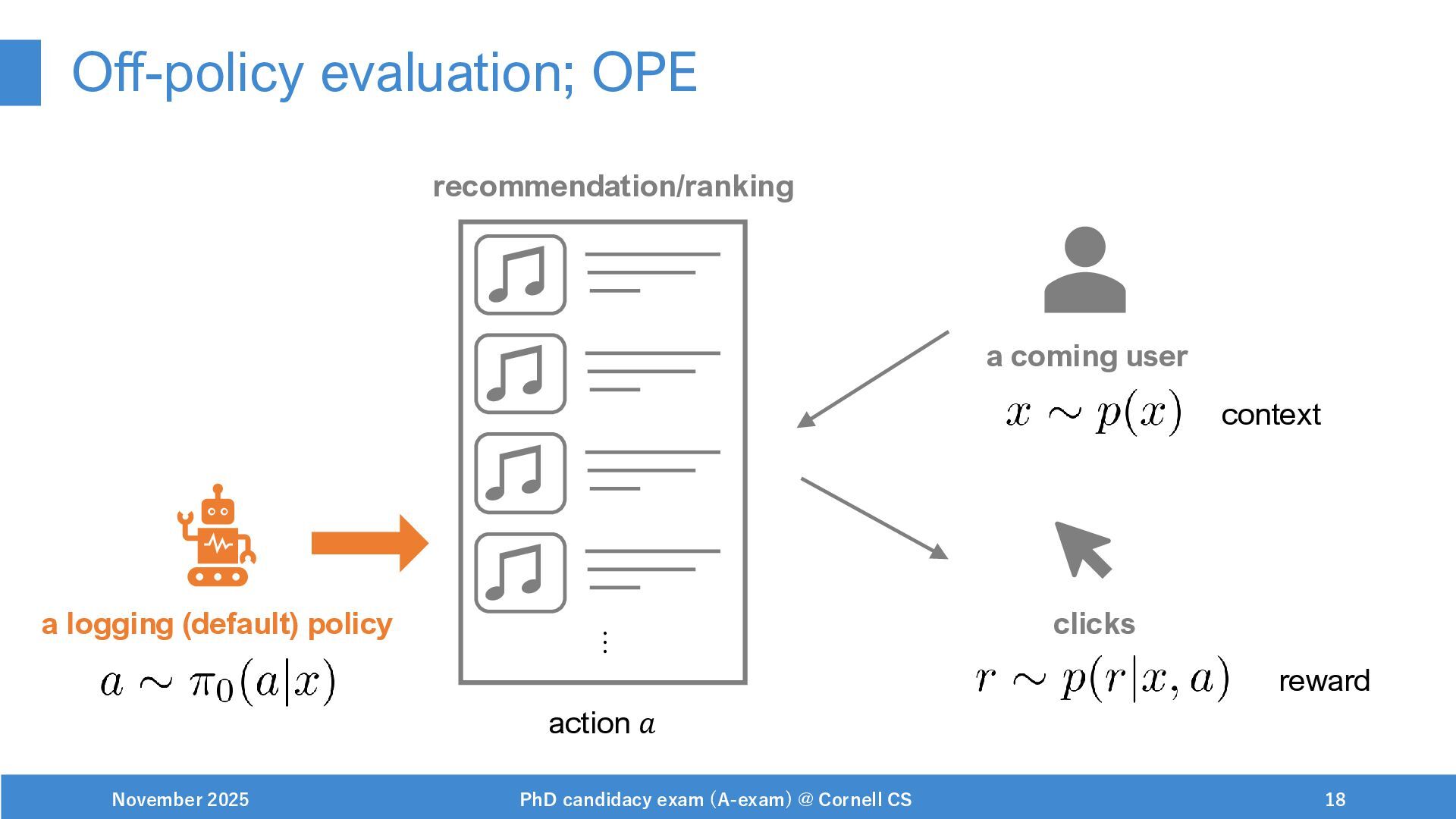{kind=link}
{kind=link}
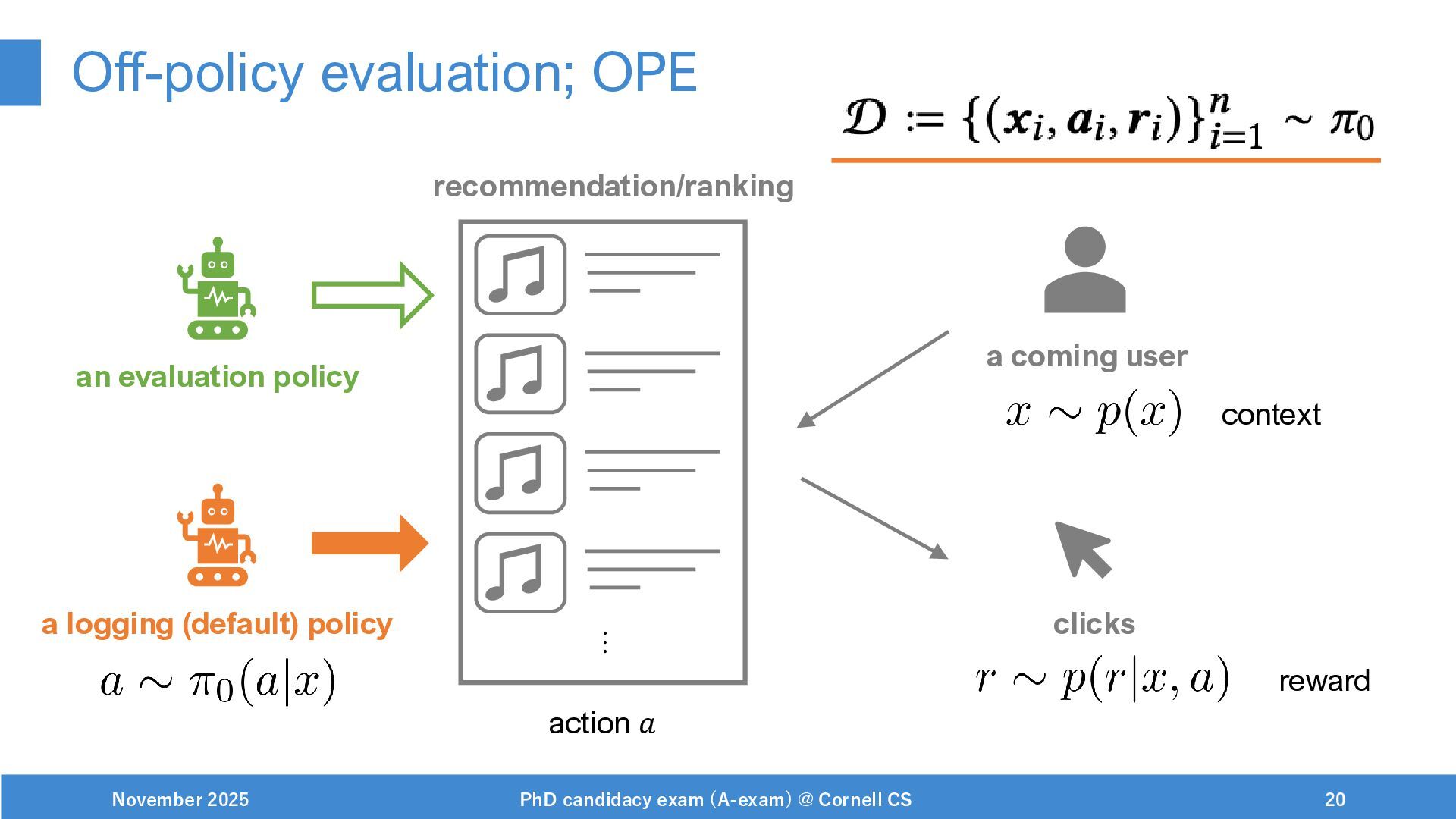{kind=link}
{kind=link}
{kind=link}
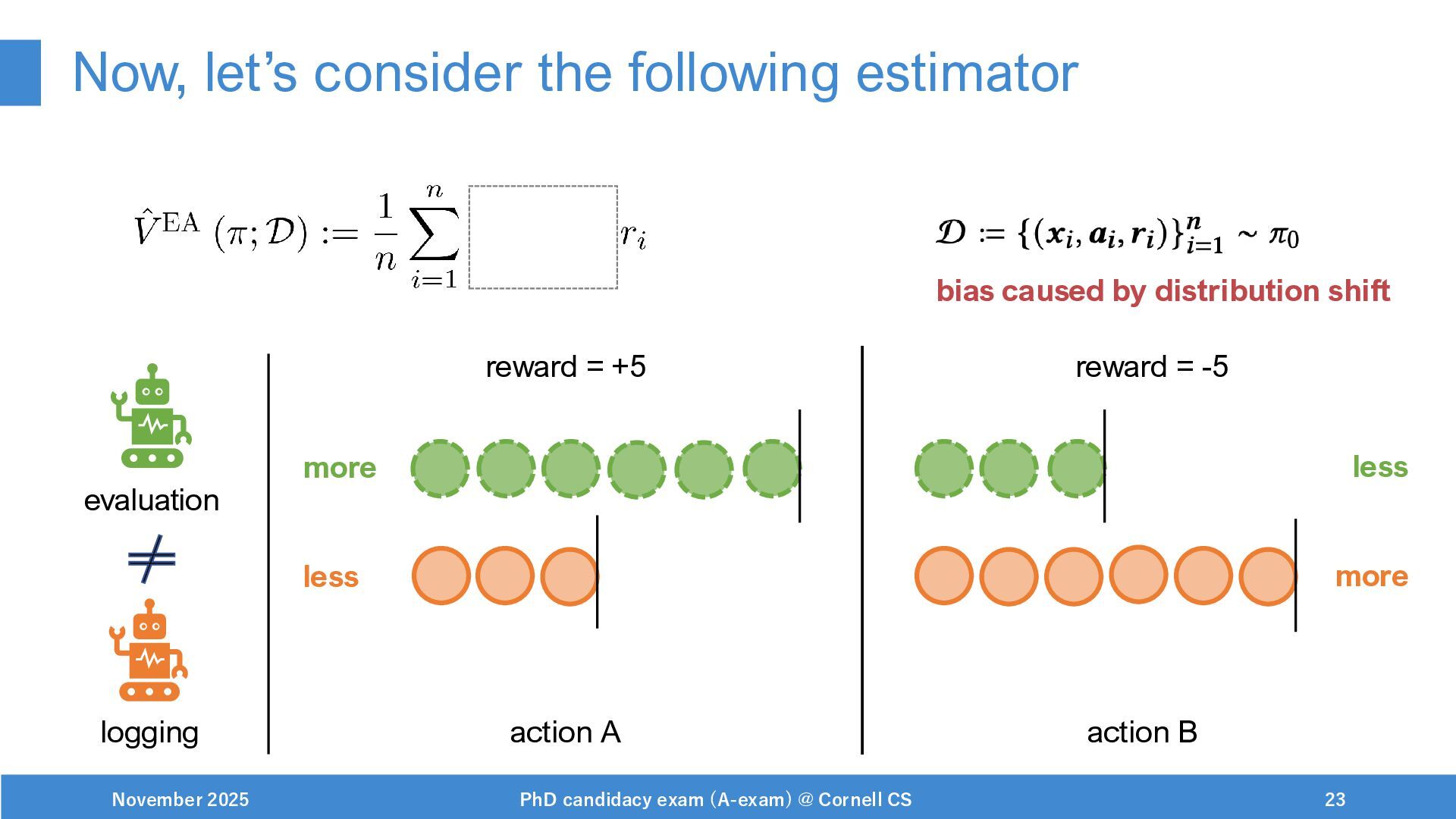{kind=link}
![Importance sampling [Strehl+,10] November 2025 PhD candidacy exam (A-exam) @](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_23.jpg){kind=link}
![Importance sampling [Strehl+,10] November 2025 PhD candidacy exam (A-exam) @](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_24.jpg){kind=link}
![Importance sampling [Strehl+,10] November 2025 PhD candidacy exam (A-exam) @](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_25.jpg){kind=link}
![Importance sampling [Strehl+,10] November 2025 PhD candidacy exam (A-exam) @](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
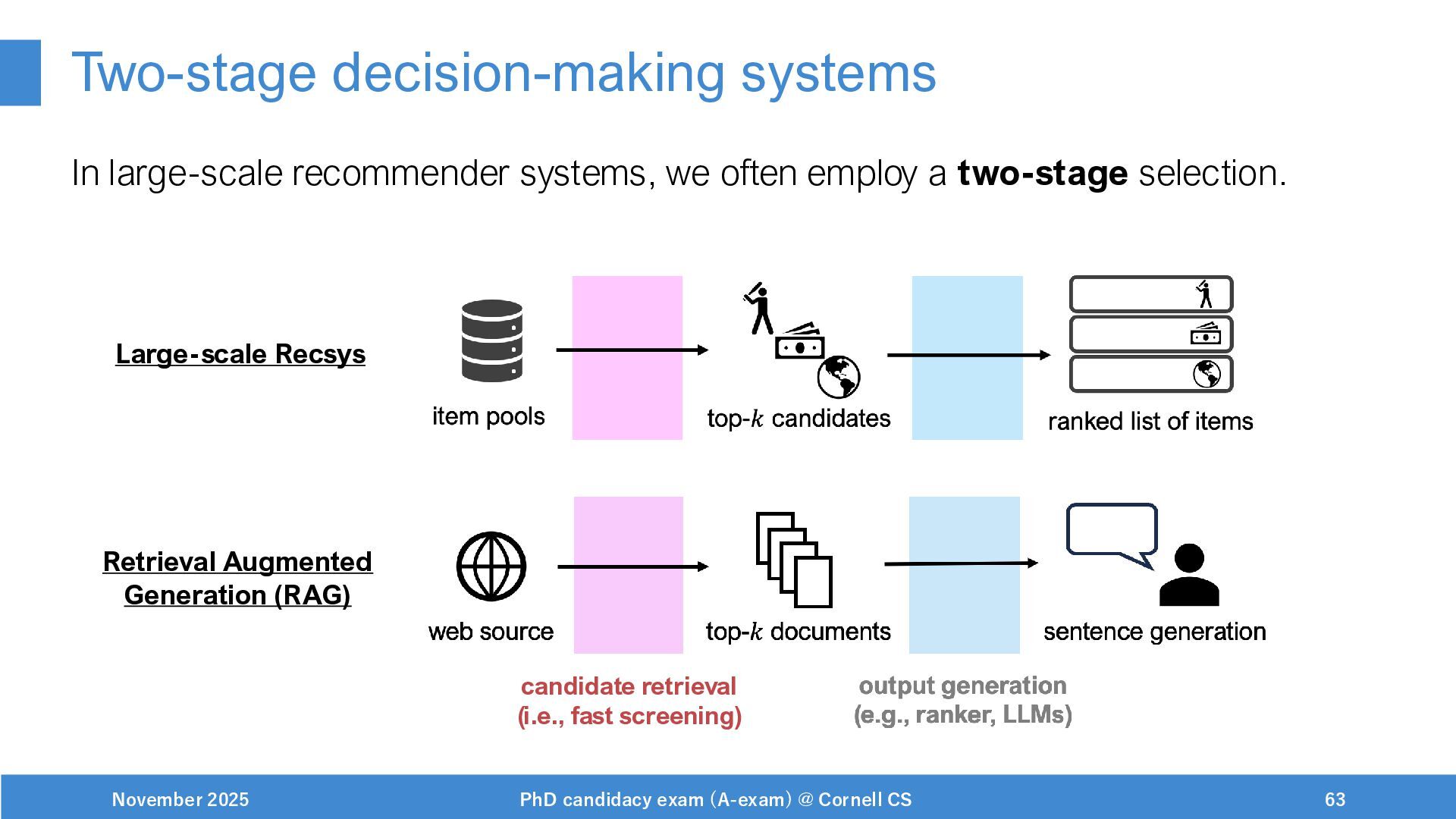{kind=link}
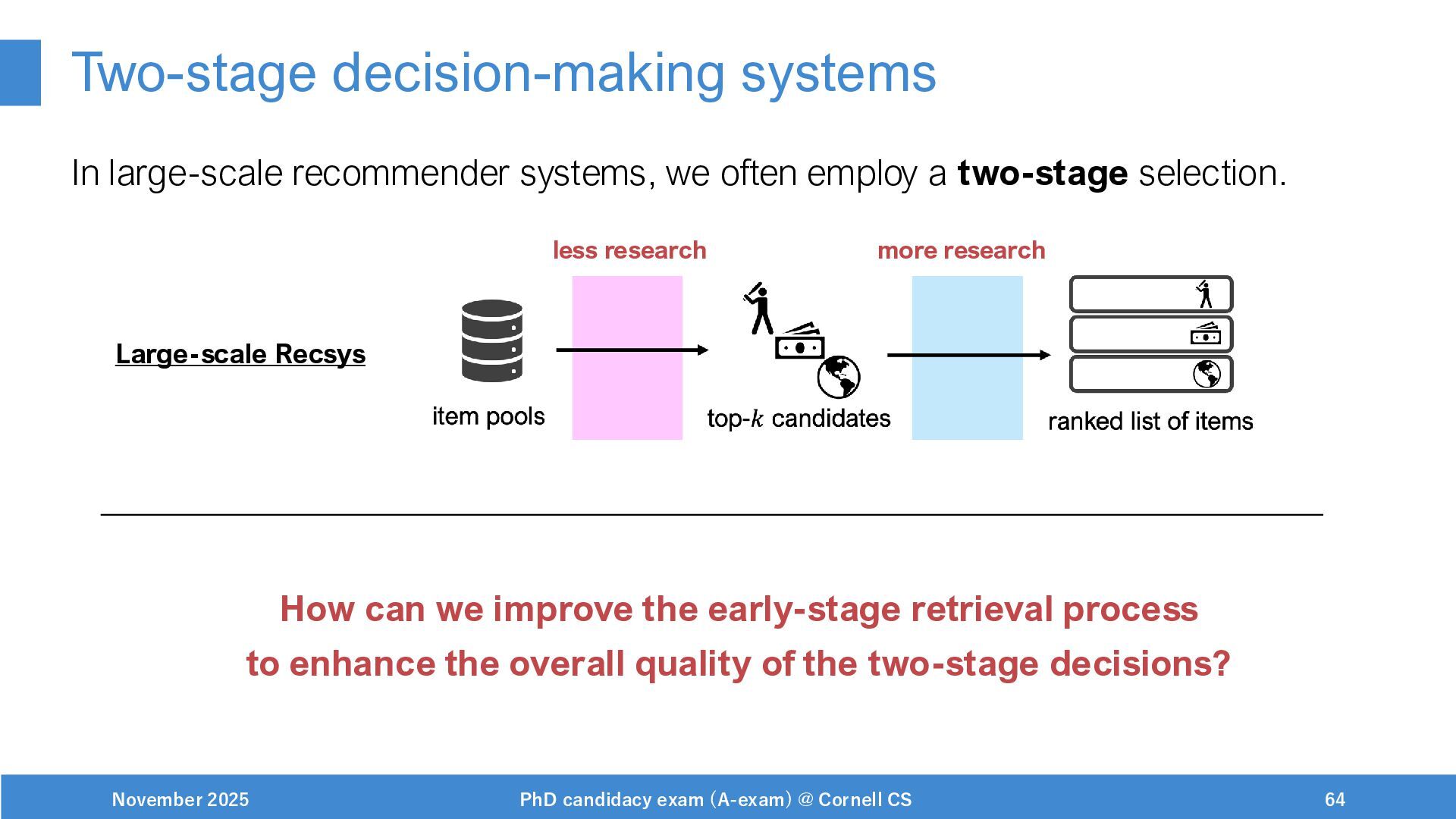{kind=link}
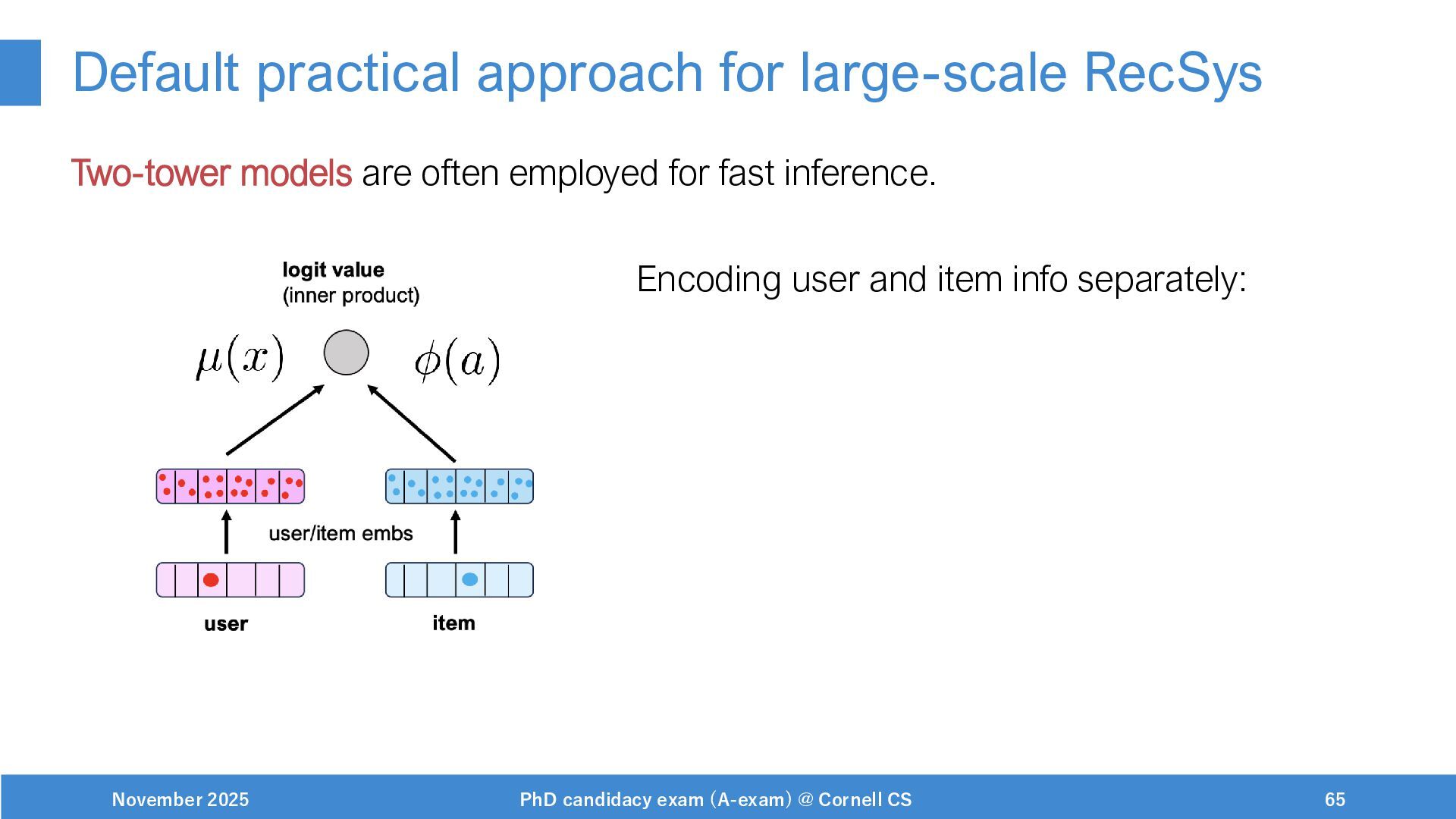{kind=link}
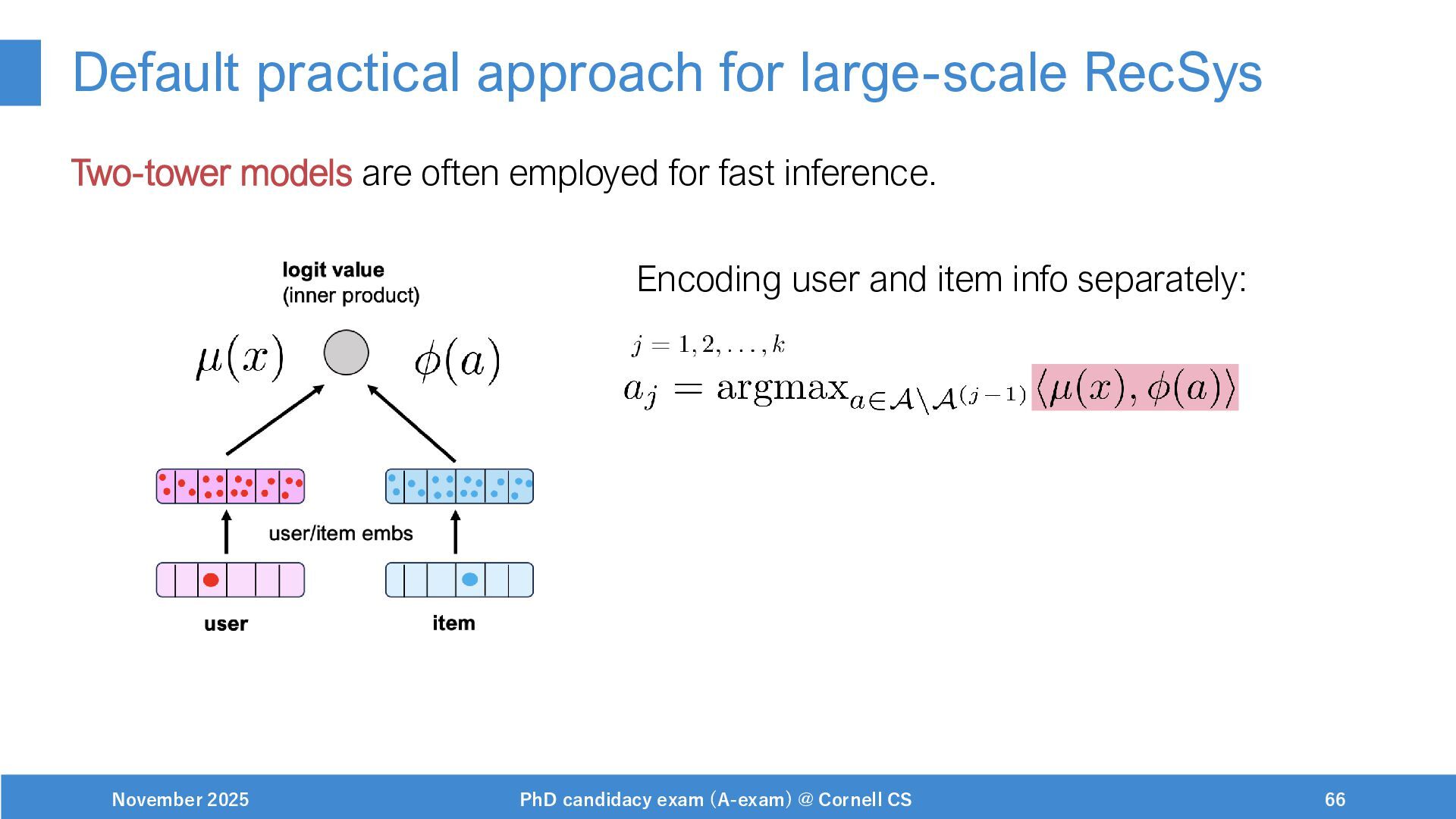{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Full-LLM experiment using MovieLens [Harper&Konstan,15] Original dataset Augmented dataset •](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_84.jpg){kind=link}
![Full-LLM experiment • Semi-synthetic experiments on the MovieLens-10M dataset [Harper&Konstan,15].](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_85.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
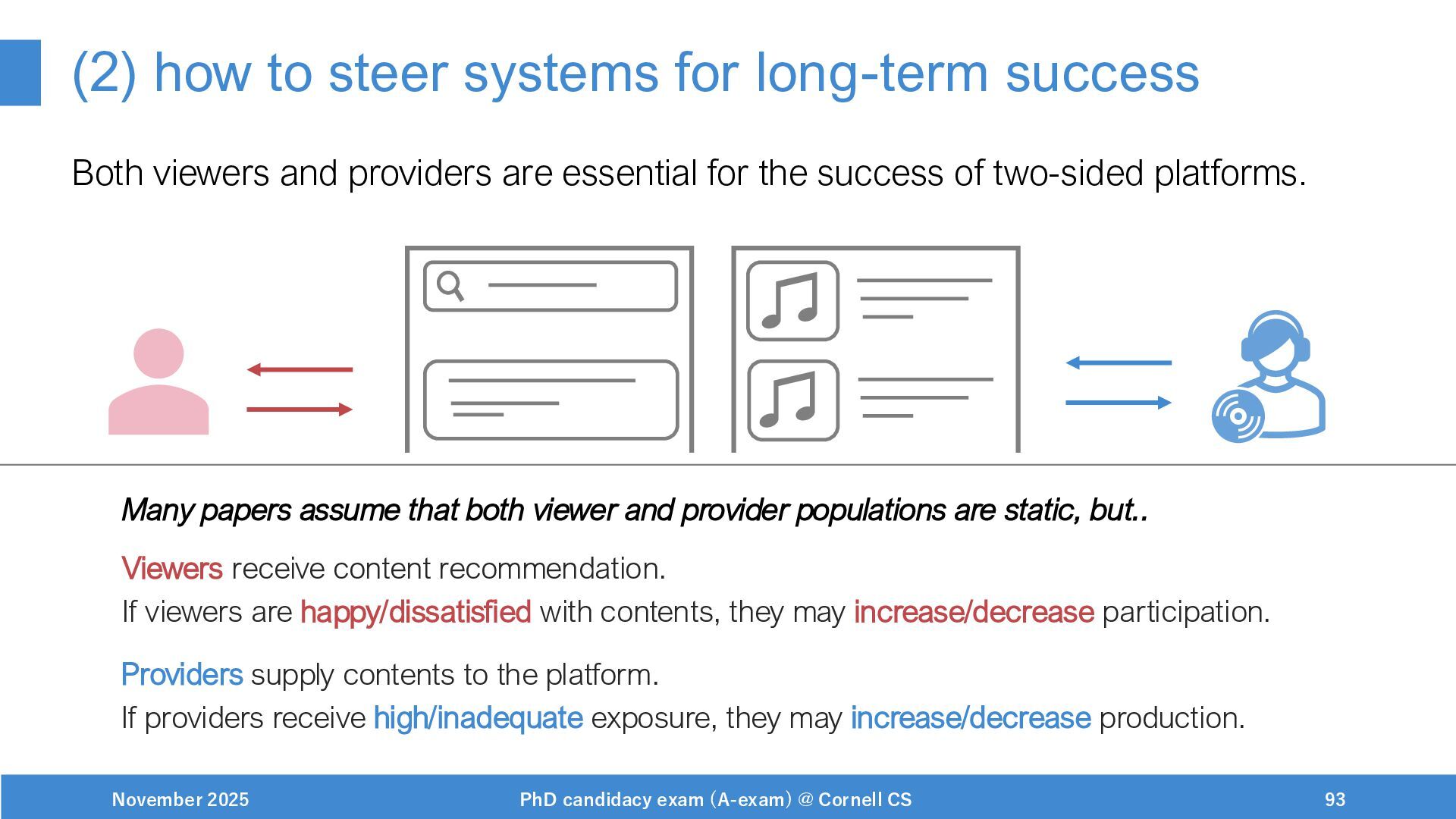{kind=link}
{kind=link}
{kind=link}
![Reference (1/4) [SST20] Noveen Sachdeva, Yi Su, Thorsten Joachims. Off-policy](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_95.jpg){kind=link}
![Reference (2/4) [SSK20] Yi Su, Pavithra Srinath, Akshay Krishnamurthy. Adaptive](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_96.jpg){kind=link}
![Reference (3/4) [YRJ22] Yuta Saito, Qingyang Ren, Thorsten Joachims. Off-Policy](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_97.jpg){kind=link}
![Reference (4/4) [STKKNS24] Tatsuhiro Shimizu, Koichi Tanaka, Ren Kishimoto, Haruka](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_98.jpg){kind=link}
![Reference (5/6) [Konda&Tsitsiklis,99] Vijay Konda and John Tsitsiklis. Actor-critic algorithms.](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_99.jpg){kind=link}
![Reference (6/6) [Jiang+,23] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch,](https://files.speakerdeck.com/presentations/853000647f6f419e9ead9e68dae1d133/slide_100.jpg){kind=link}