Yi, Ji Yang, Minmin Chen, Jiaxi Tang, Lichan Hong, Ed Chi. Off-policy Learning in Two-stage Recommender Systems. WWW, 2020. [Gao et al., 2022] Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, Tat-Seng Chua. KuaiRec: A Fully-observed Dataset and Insights for Evaluating Recommender Systems. CIKM, 2022. [Shao et al., 2022] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Y. Wu, Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. 2024. July 2026 Credit-assigned policy gradient in two stage ranking @ ICML 48
{kind=link}
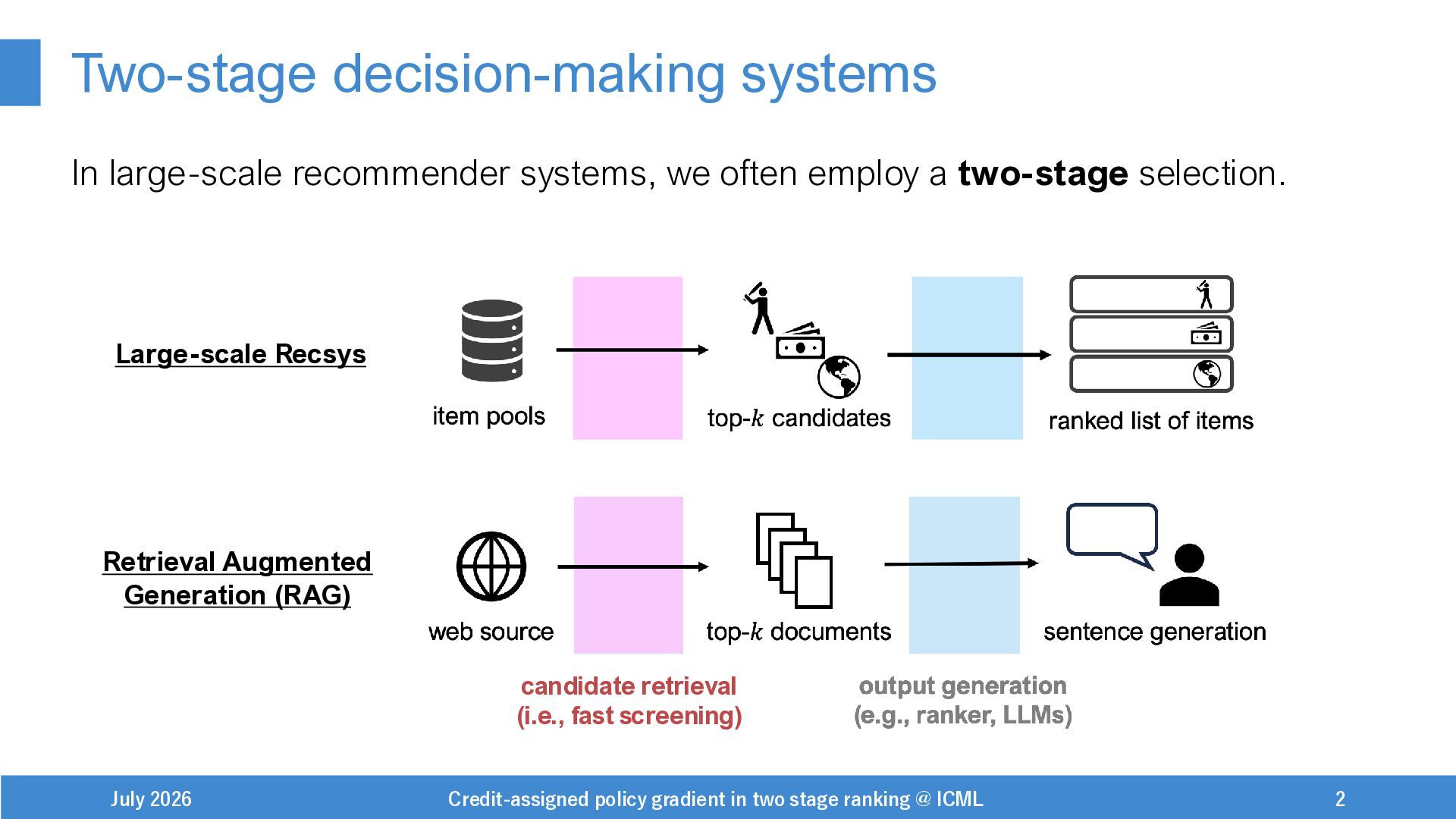{kind=link}
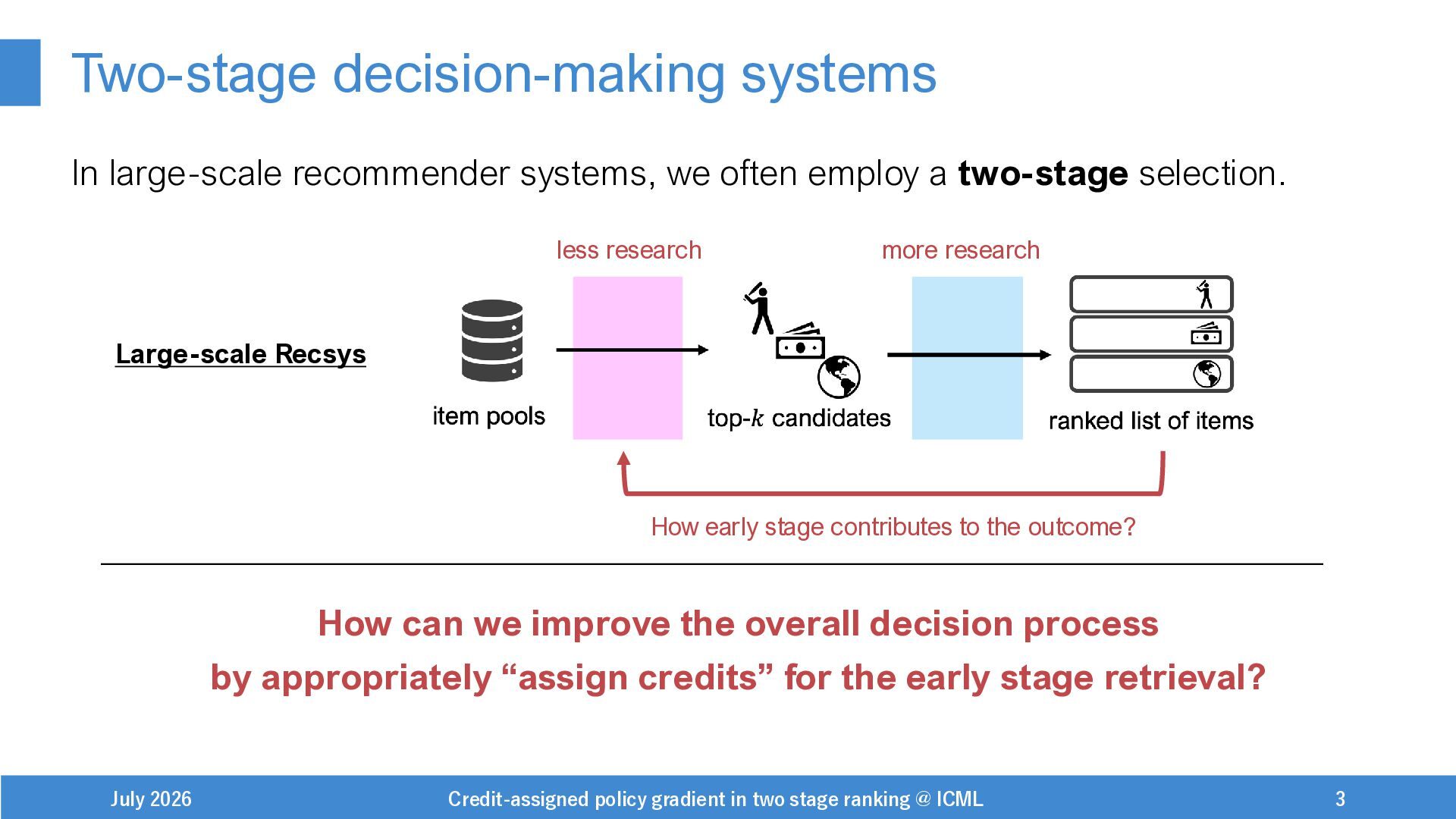{kind=link}
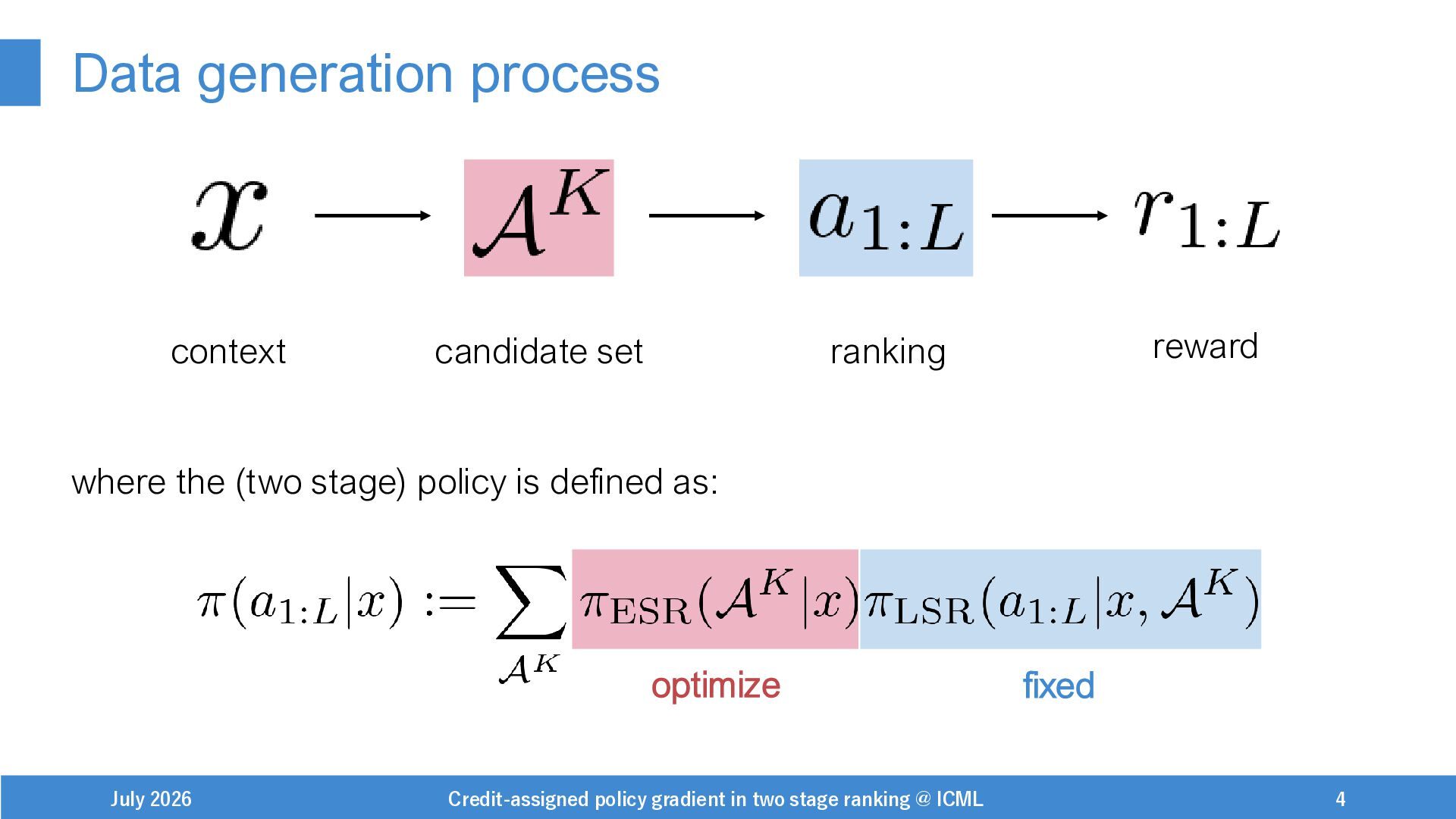{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
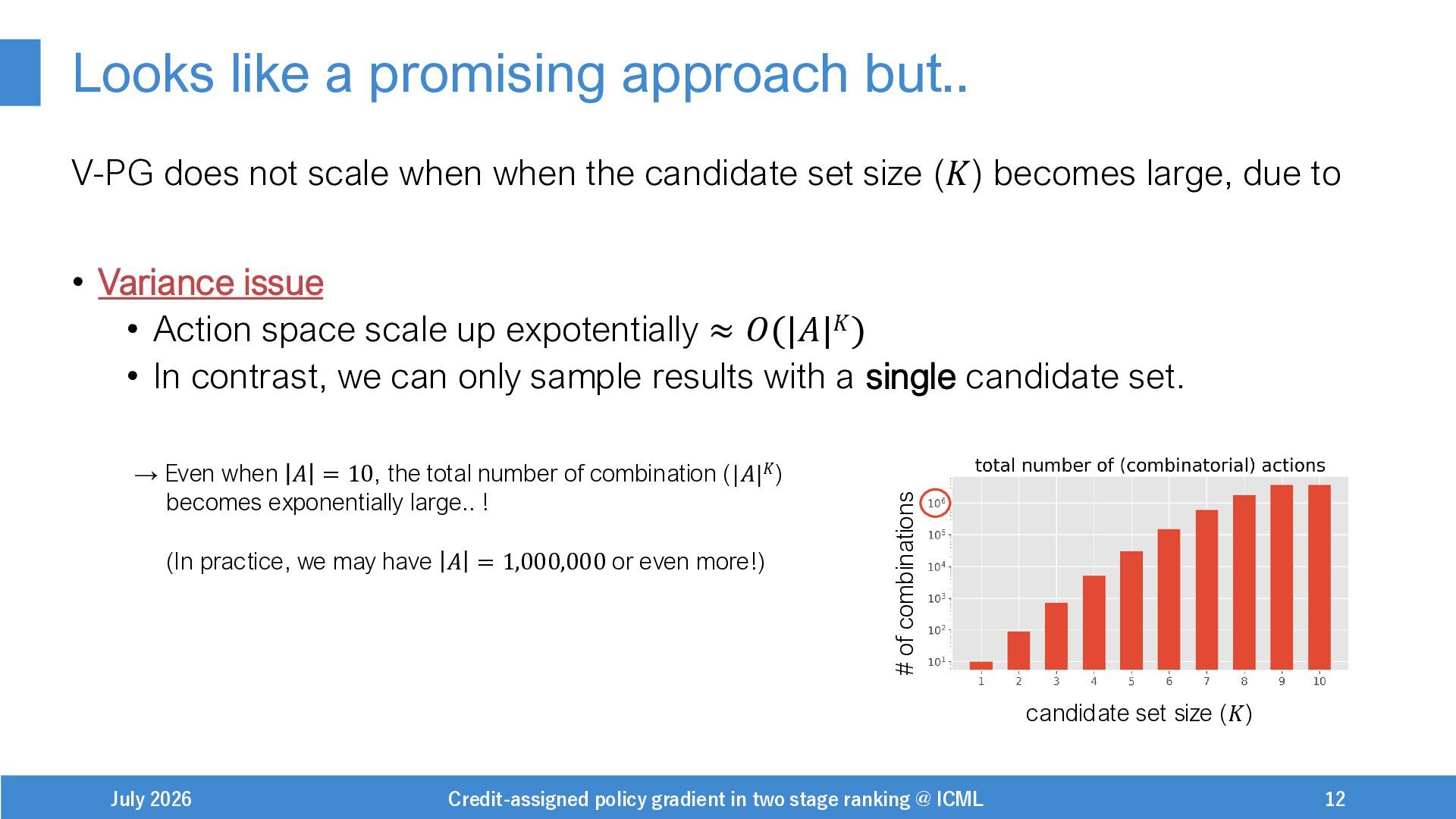{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
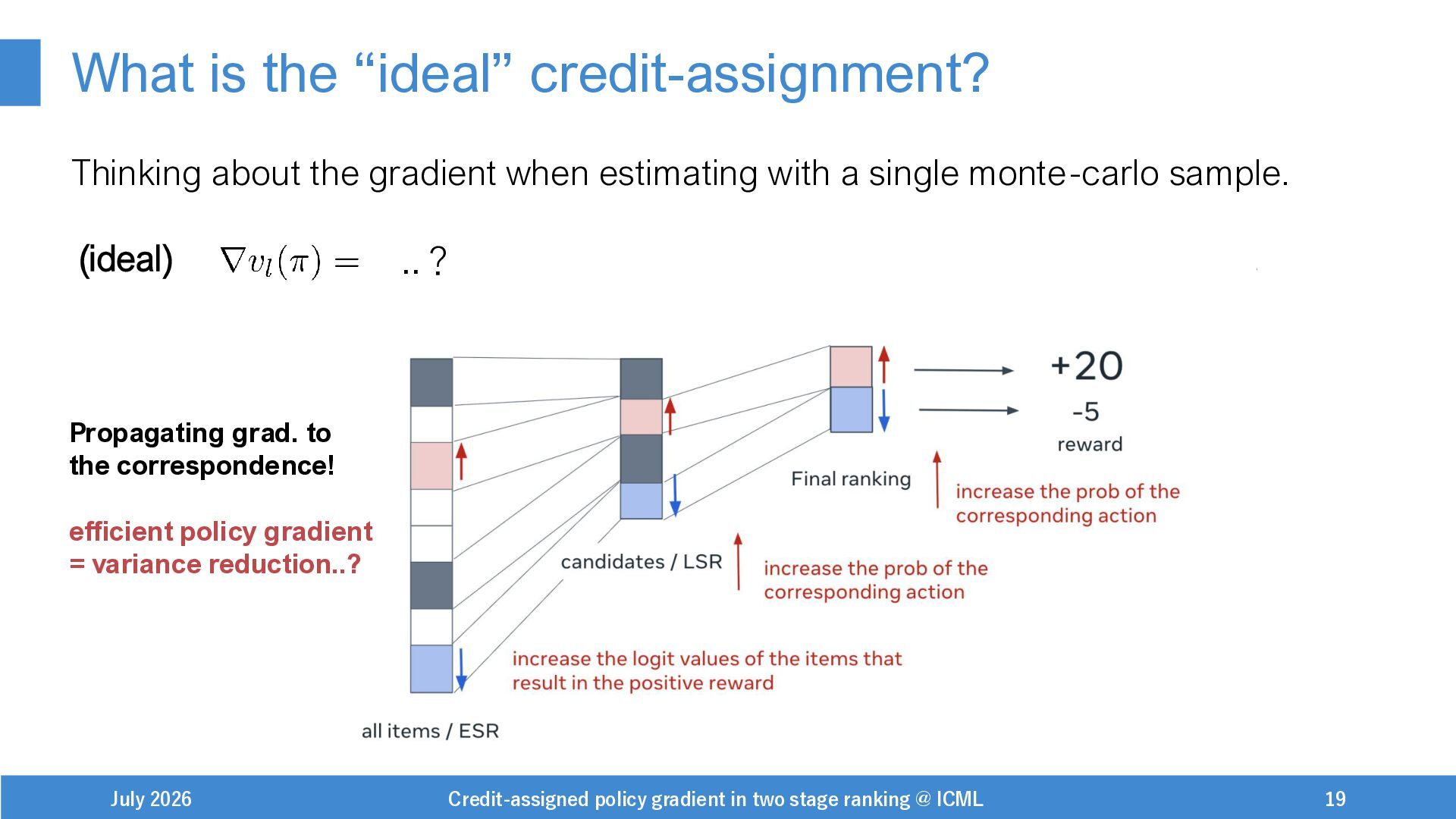{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
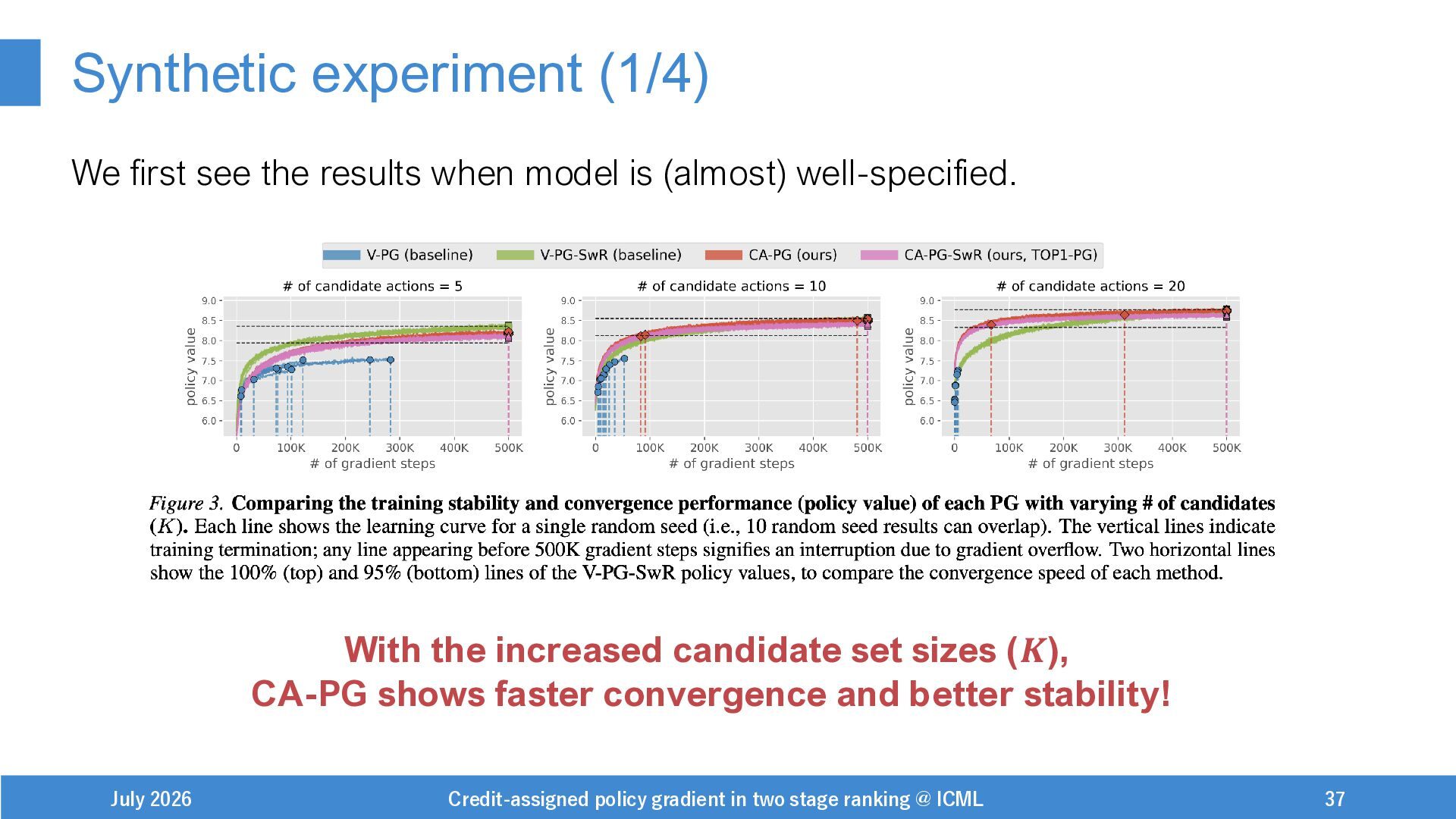{kind=link}
{kind=link}
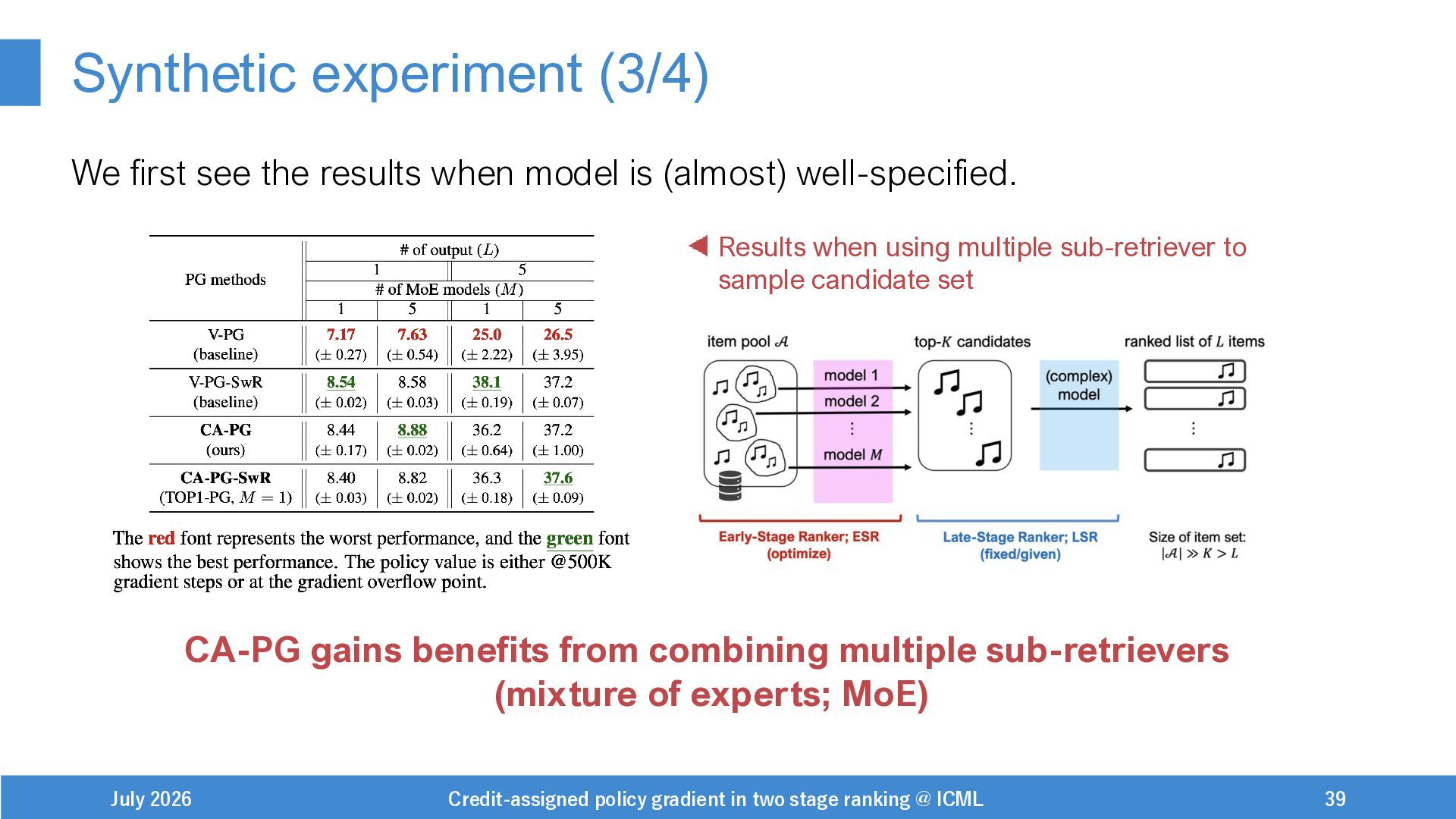{kind=link}
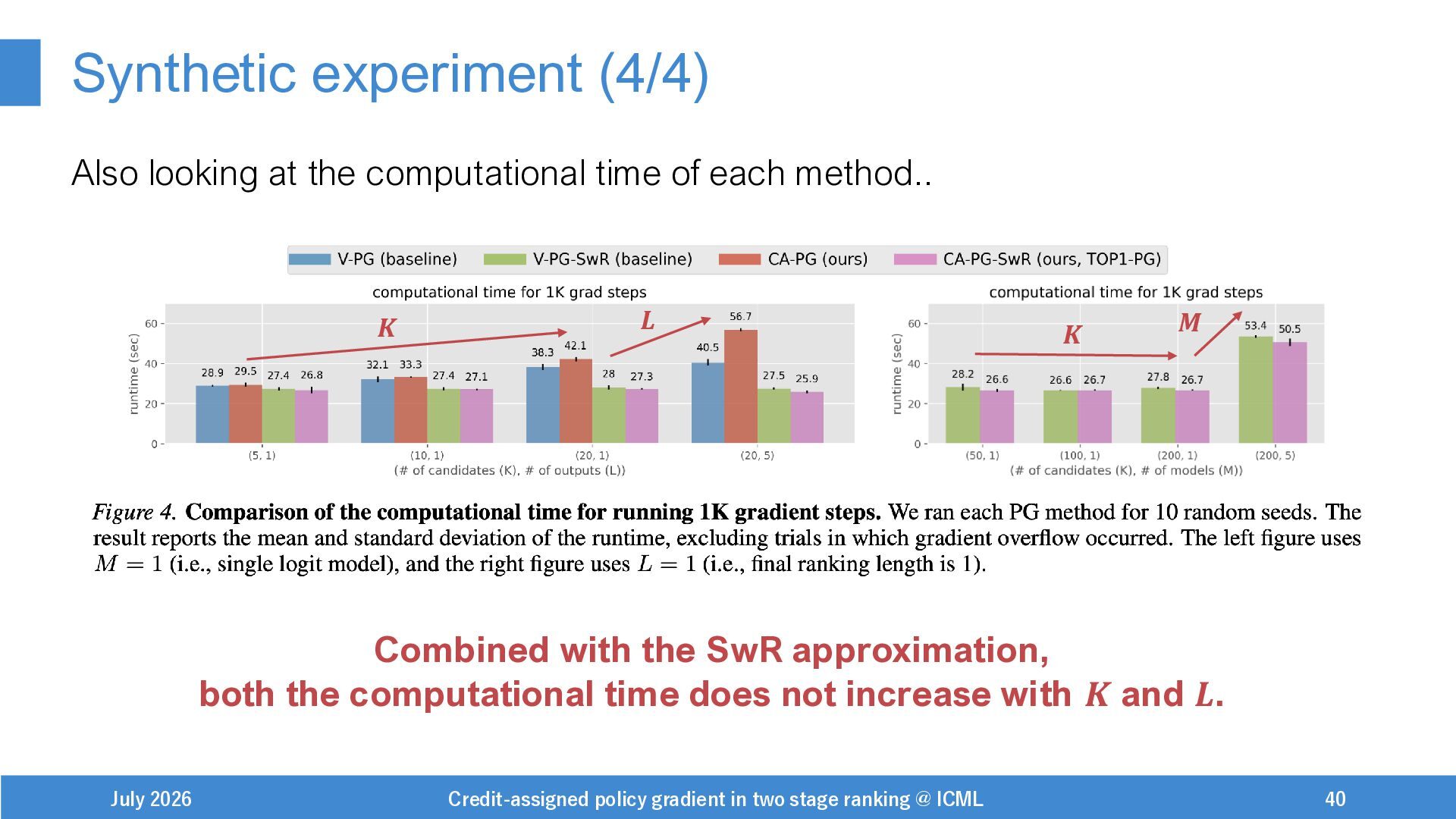{kind=link}
![Real-data experiment on KuaiRec [Gao+,22] We test with a larger](https://files.speakerdeck.com/presentations/825521f4bbd2448c8a9ae0aed9df3365/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
![Additional results combined with GRPO [Shao+,24] CA-PG can be easily](https://files.speakerdeck.com/presentations/825521f4bbd2448c8a9ae0aed9df3365/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [Ma et al., 2020] Jiaqi Ma, Zhe Zhao, Xinyang](https://files.speakerdeck.com/presentations/825521f4bbd2448c8a9ae0aed9df3365/slide_47.jpg){kind=link}