PyConAPAC2023 Day2 13:55 - 14:10
合同会社長目 小川 英幸
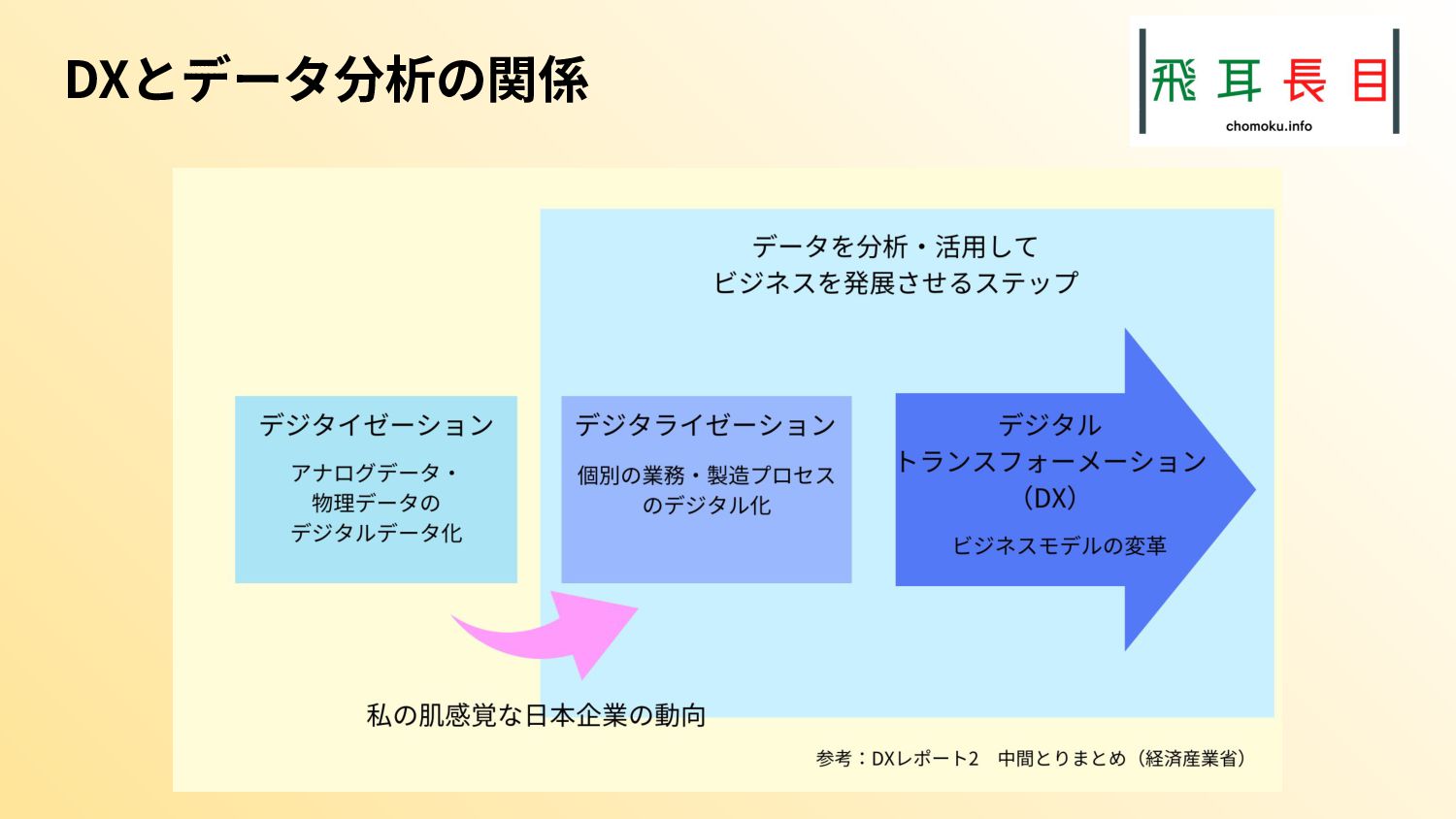
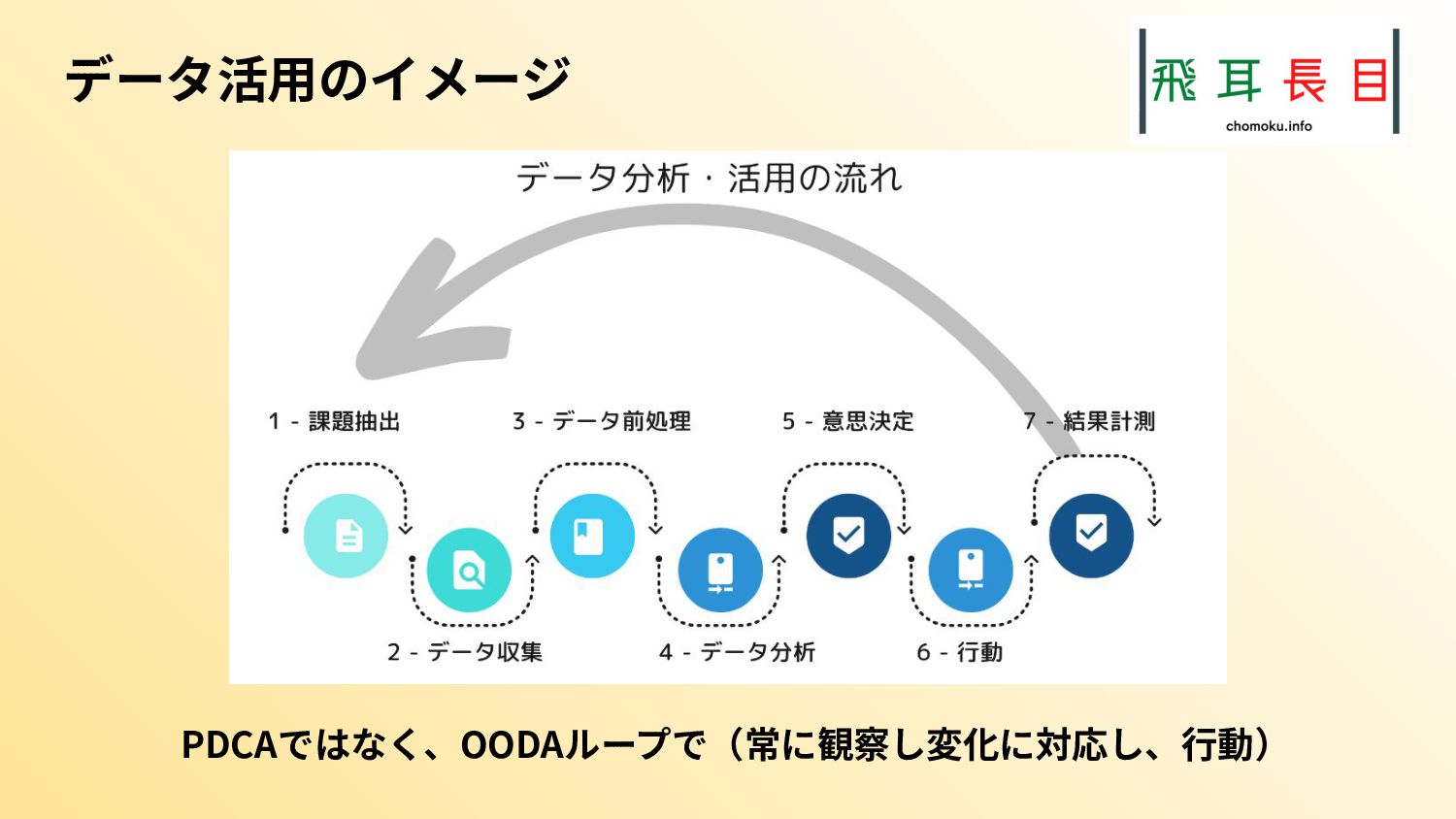
DXは最終的にデジタル活用したビジネスモデルの変革を目指す。その作業には物理・アナログデータのデジタルデータ化(デジタイゼーション)と、業務プロセスのデジタル化(デジタライゼーション)があり、それらが組み合わさってDXが進む。
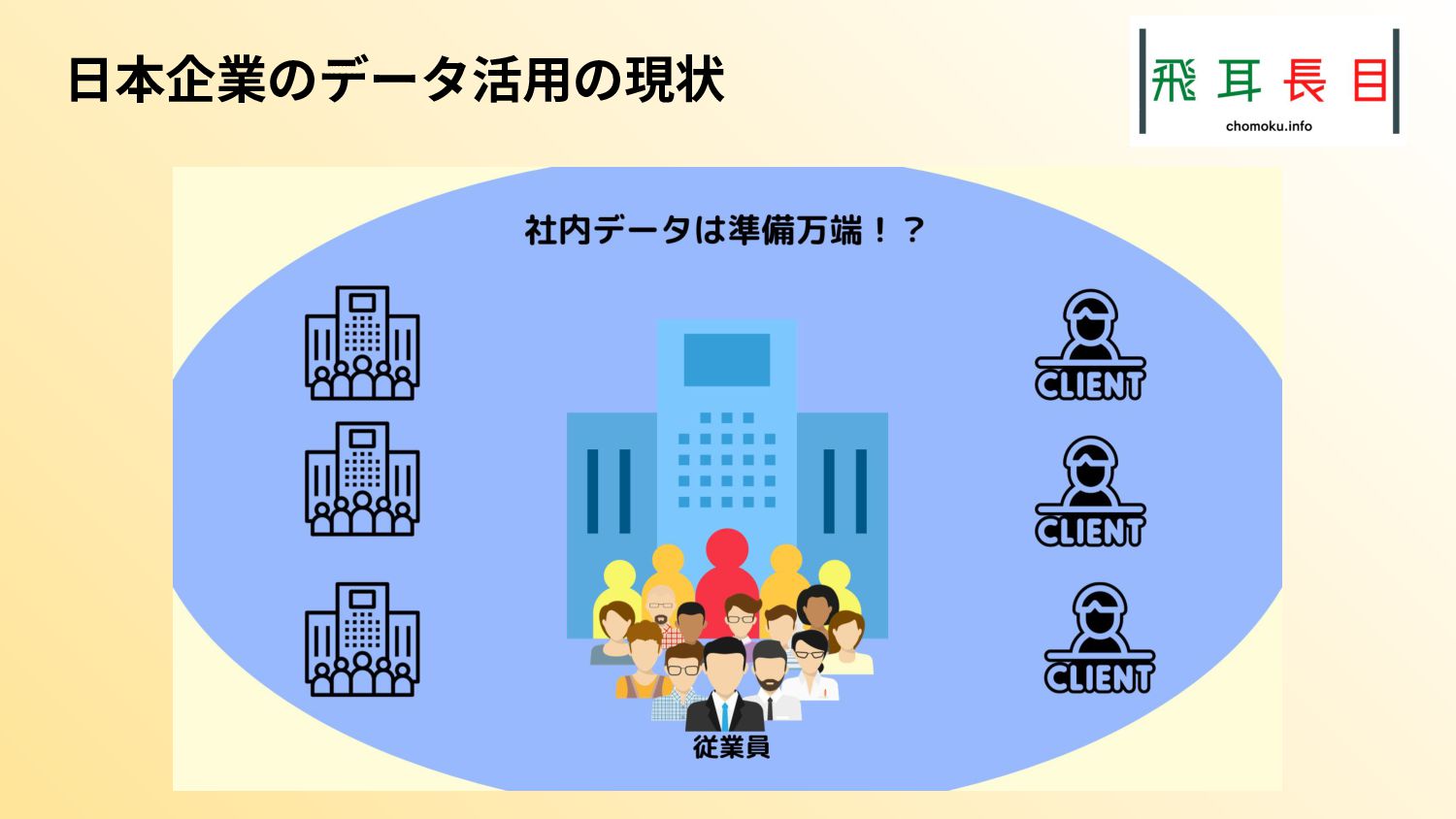
昨今の日本企業では、両方のプロセスが進み始め、活用できる社内データが増え始めている。そのため、データを分析してビジネス価値を生み出せる段階にある。
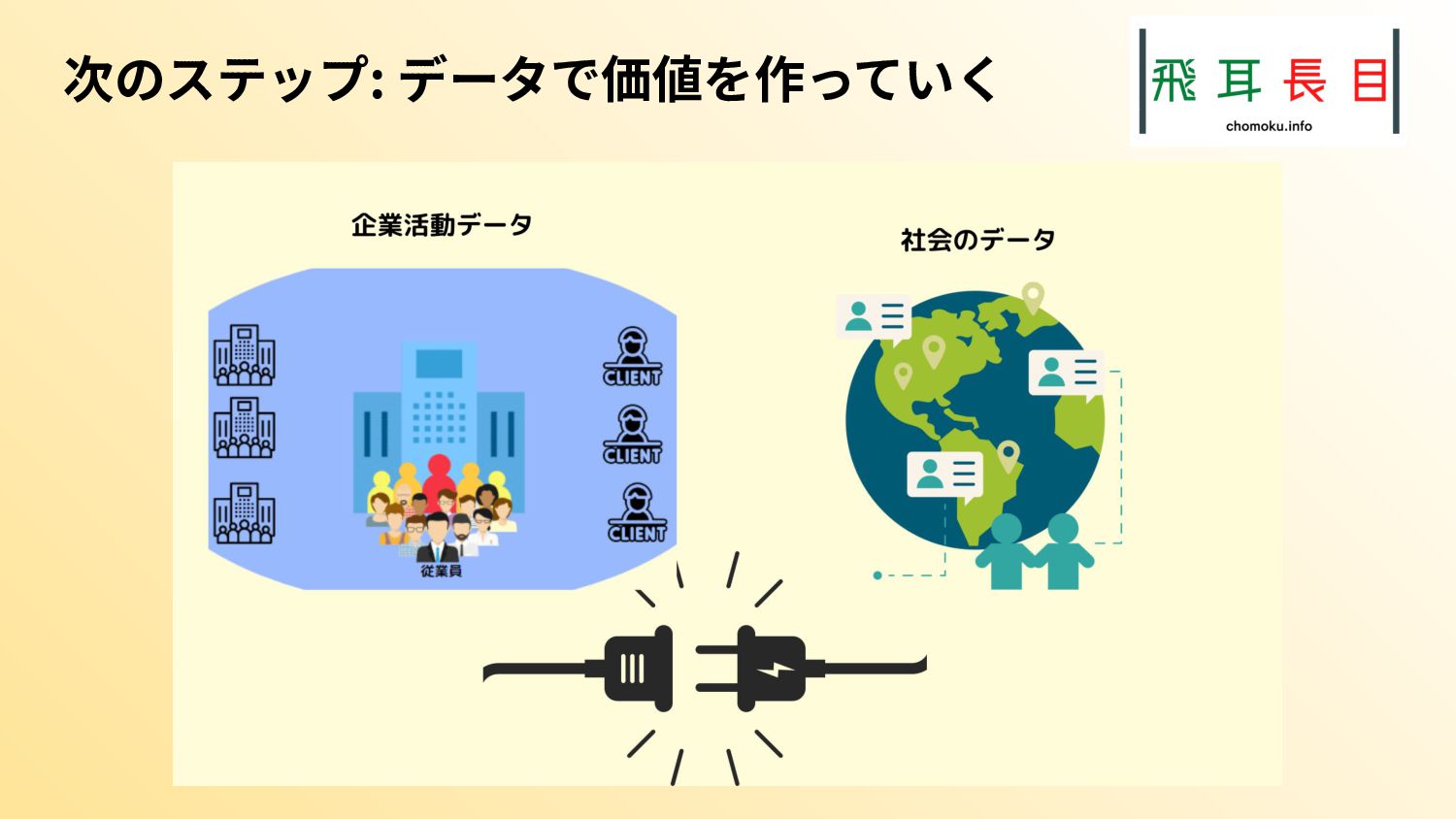
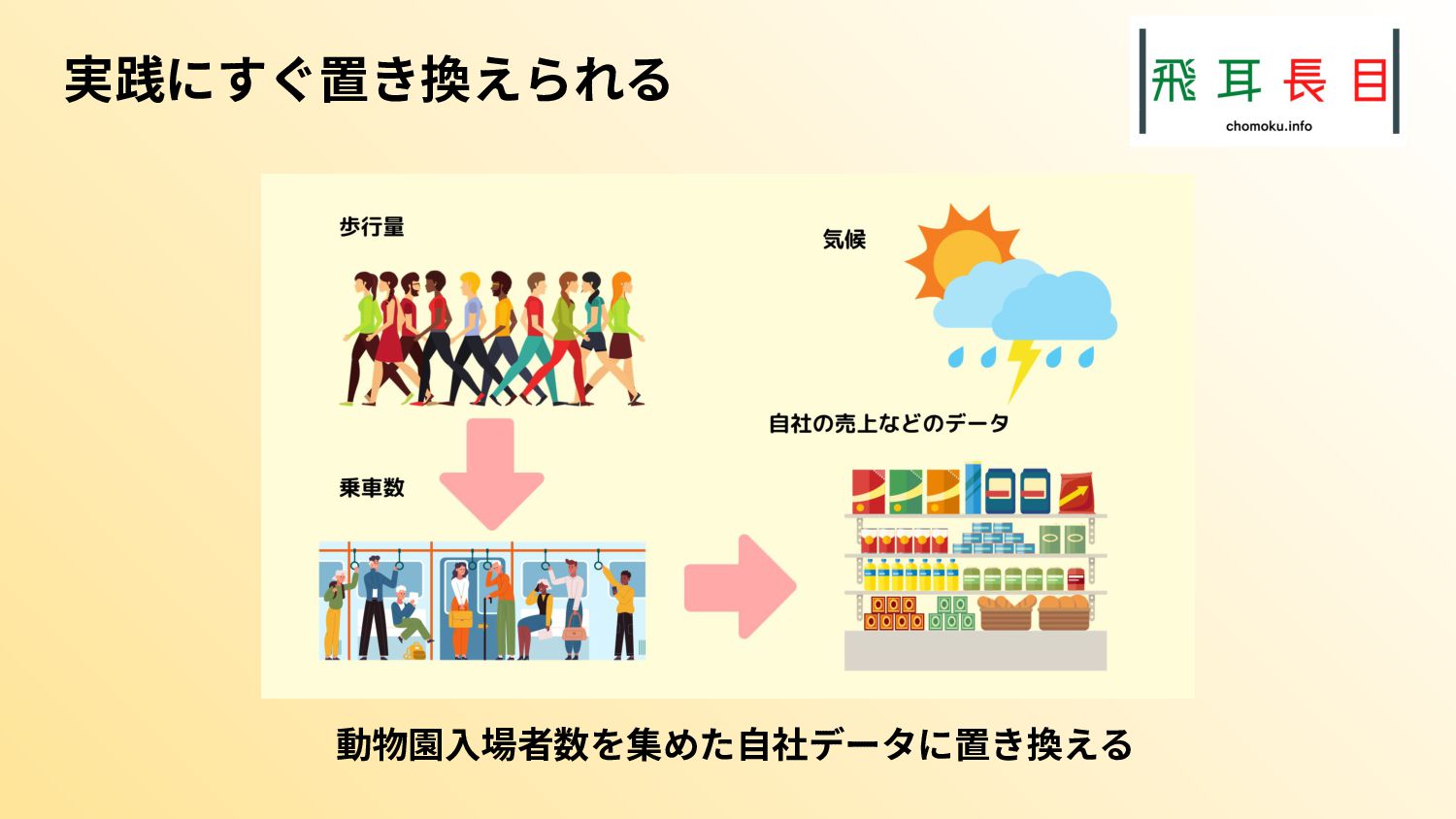
一方で、社内のデータだけではビジネスの価値向上を達成するのは難しく、社外のデータも必要となる。社外のデータとしてはオープンデータが活用できる。
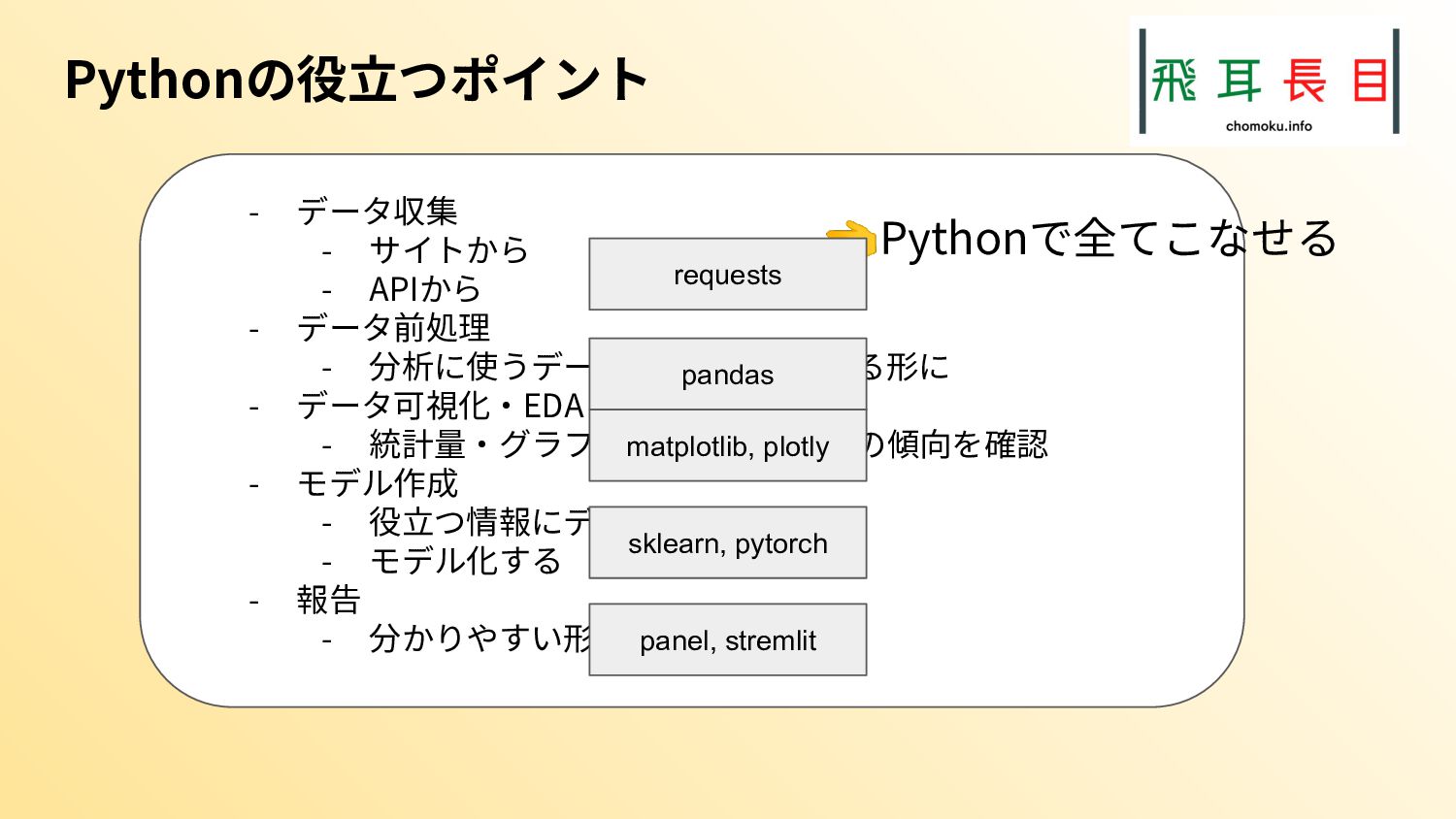
本トークは、社外のデータの取得や、社外のデータと社内のデータを組み合わせて分析して、価値を出す作業はPythonを使うと簡単にできるということを示すトークとなる。
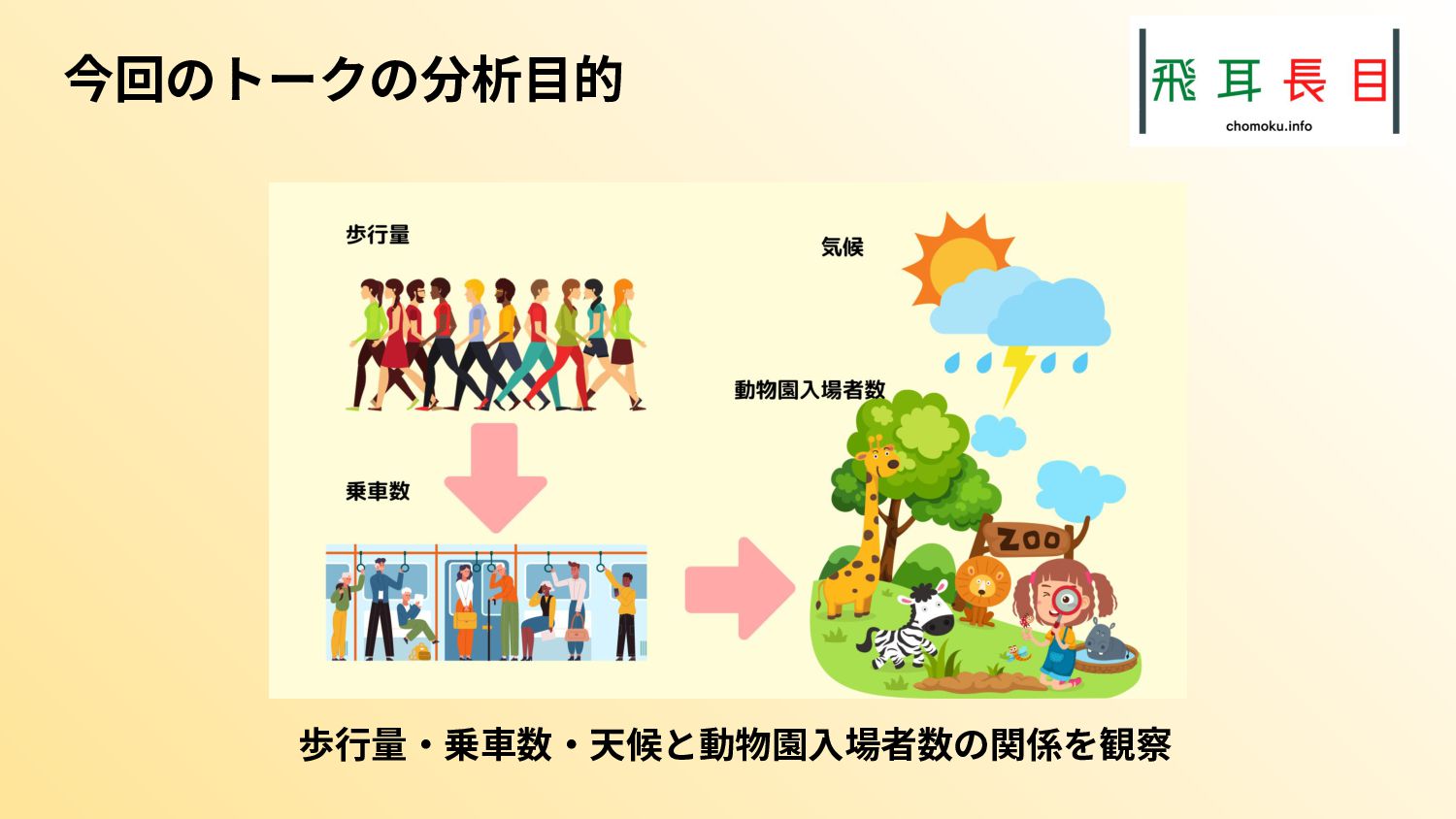
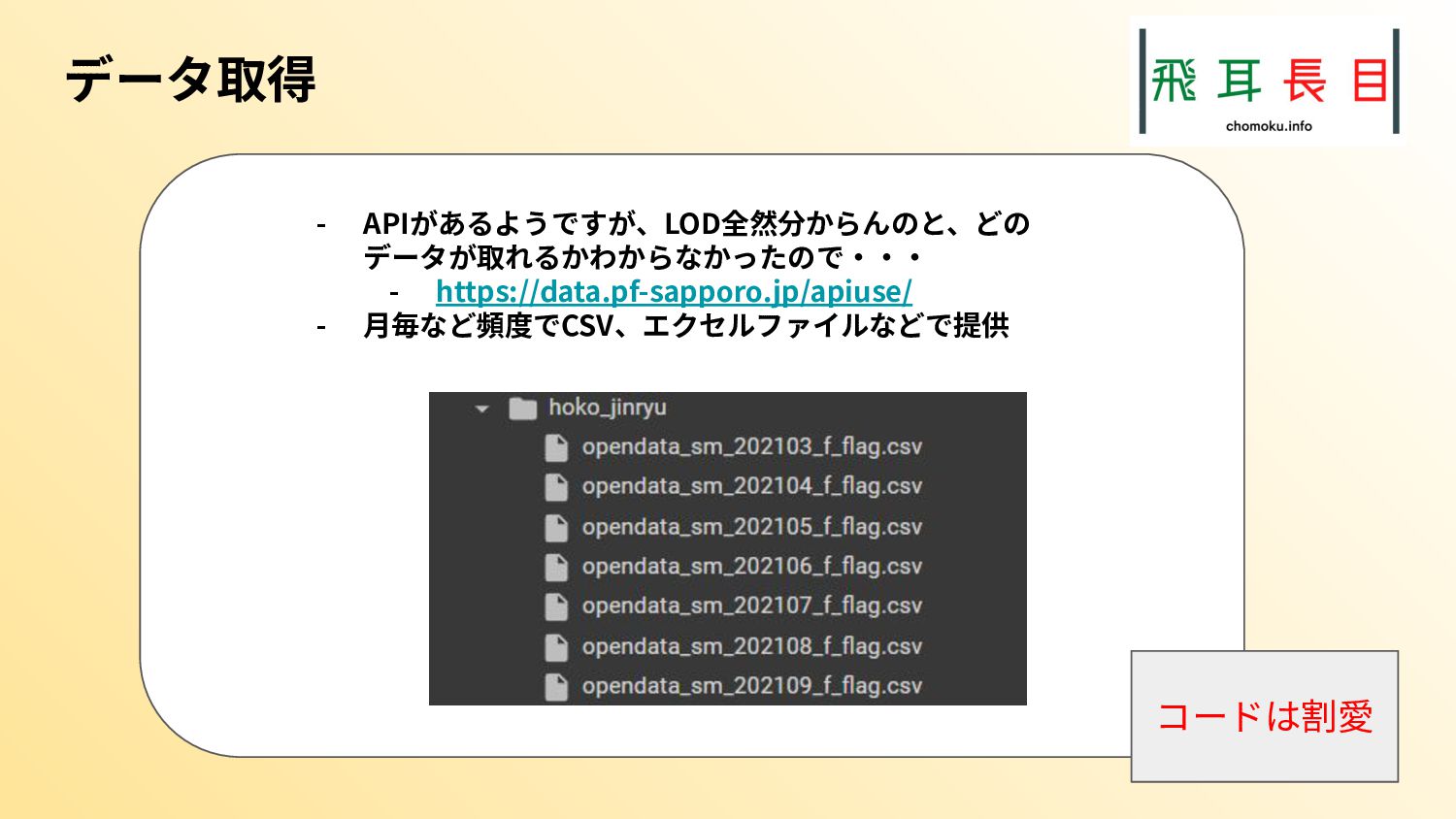
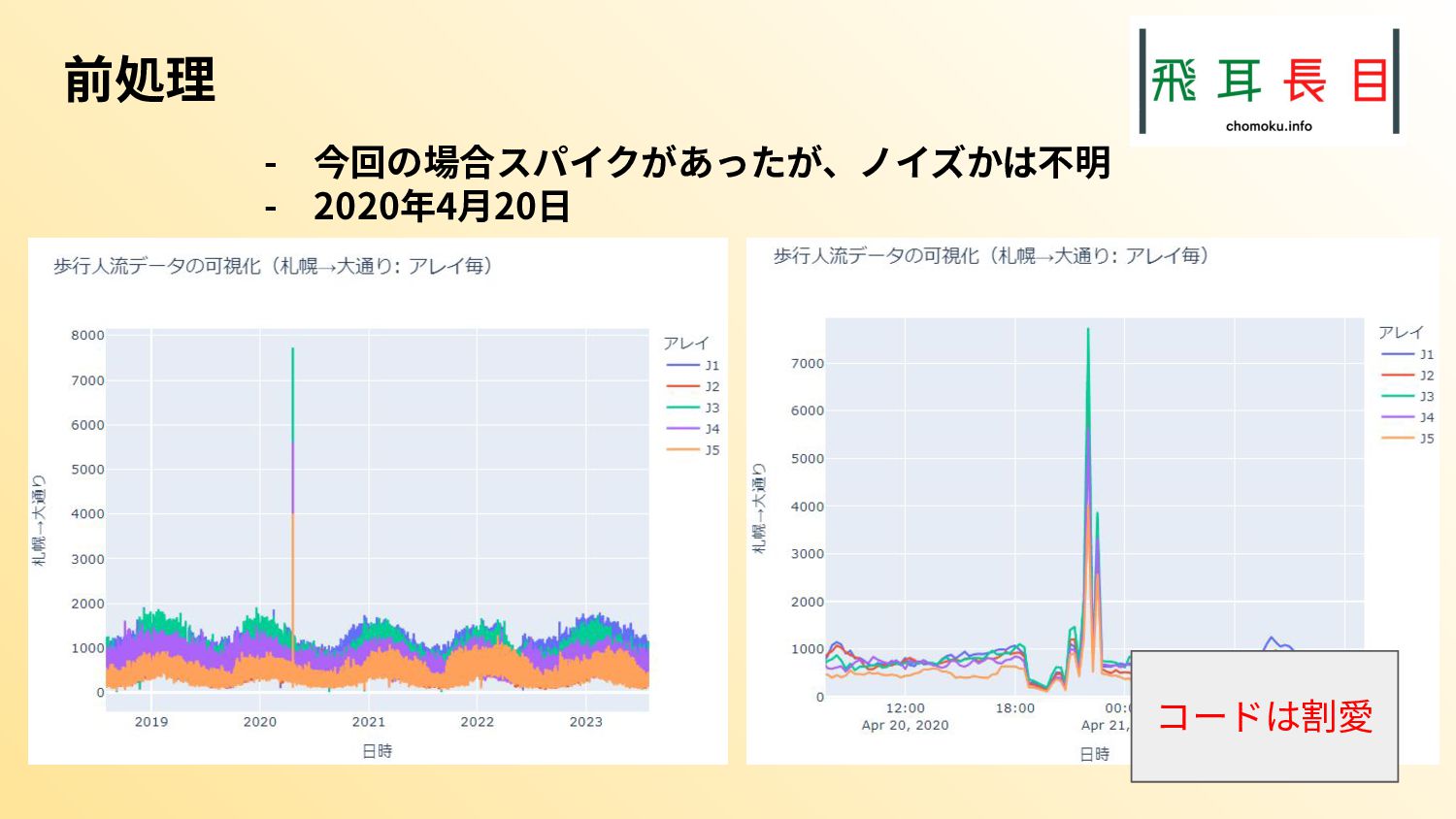
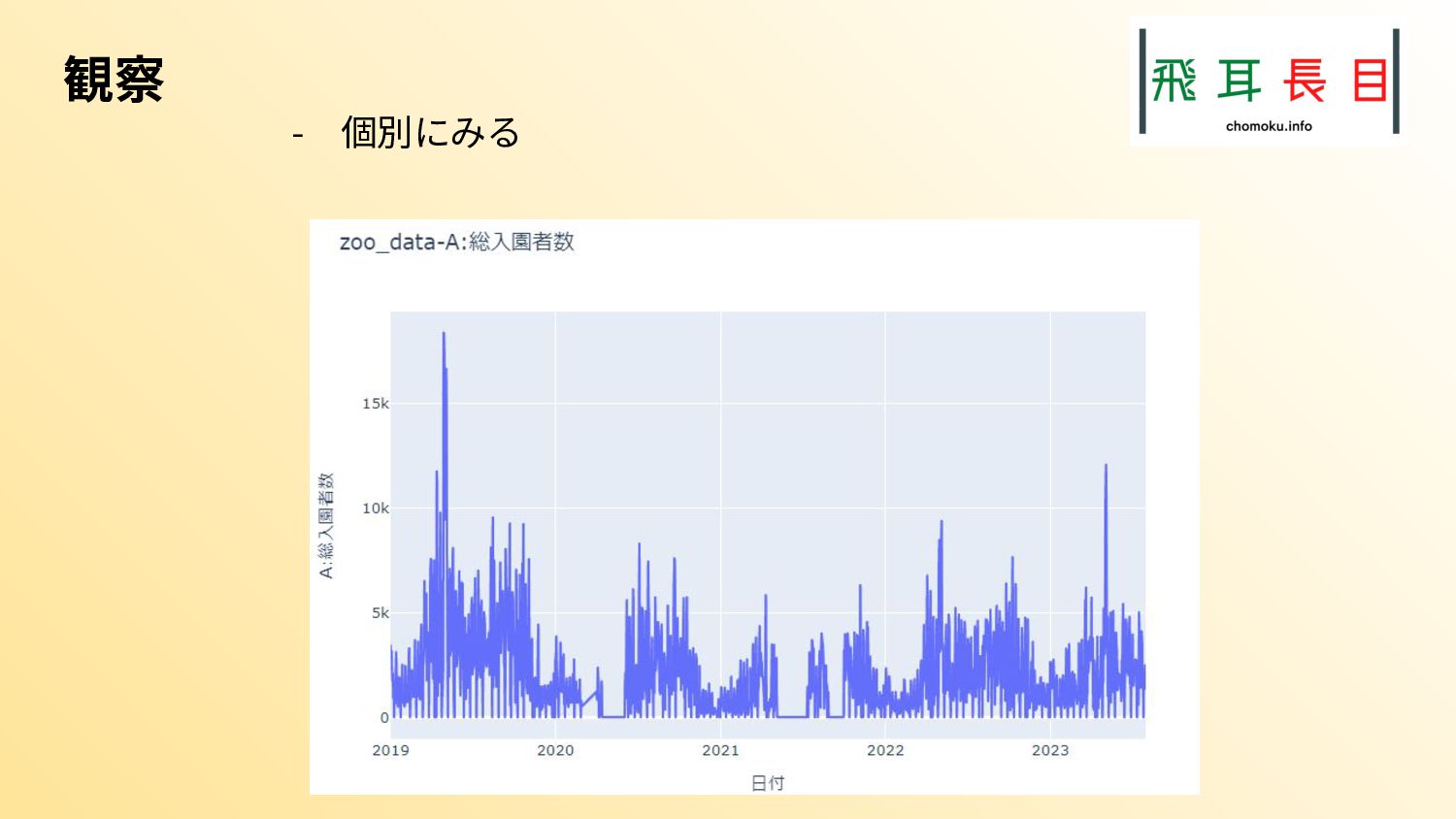
またその実践として、札幌市のオープンデータを具体的にどう扱うかも示した。実際のコード、データは次のgithubリポジトリにある。
[https://github.com/mazarimono/pyconapac2023](https://github.com/mazarimono/pyconapac2023)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
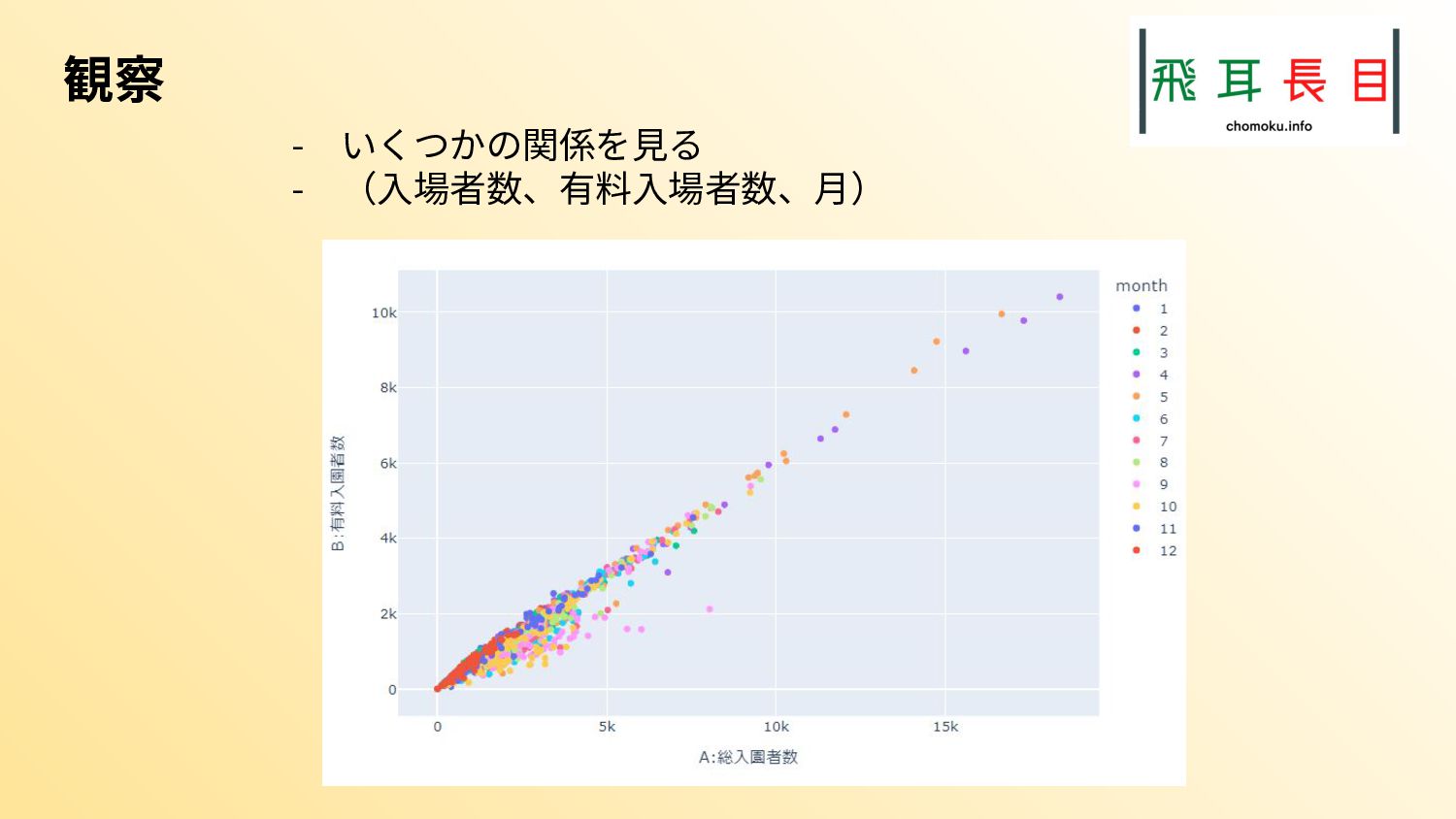{kind=link}
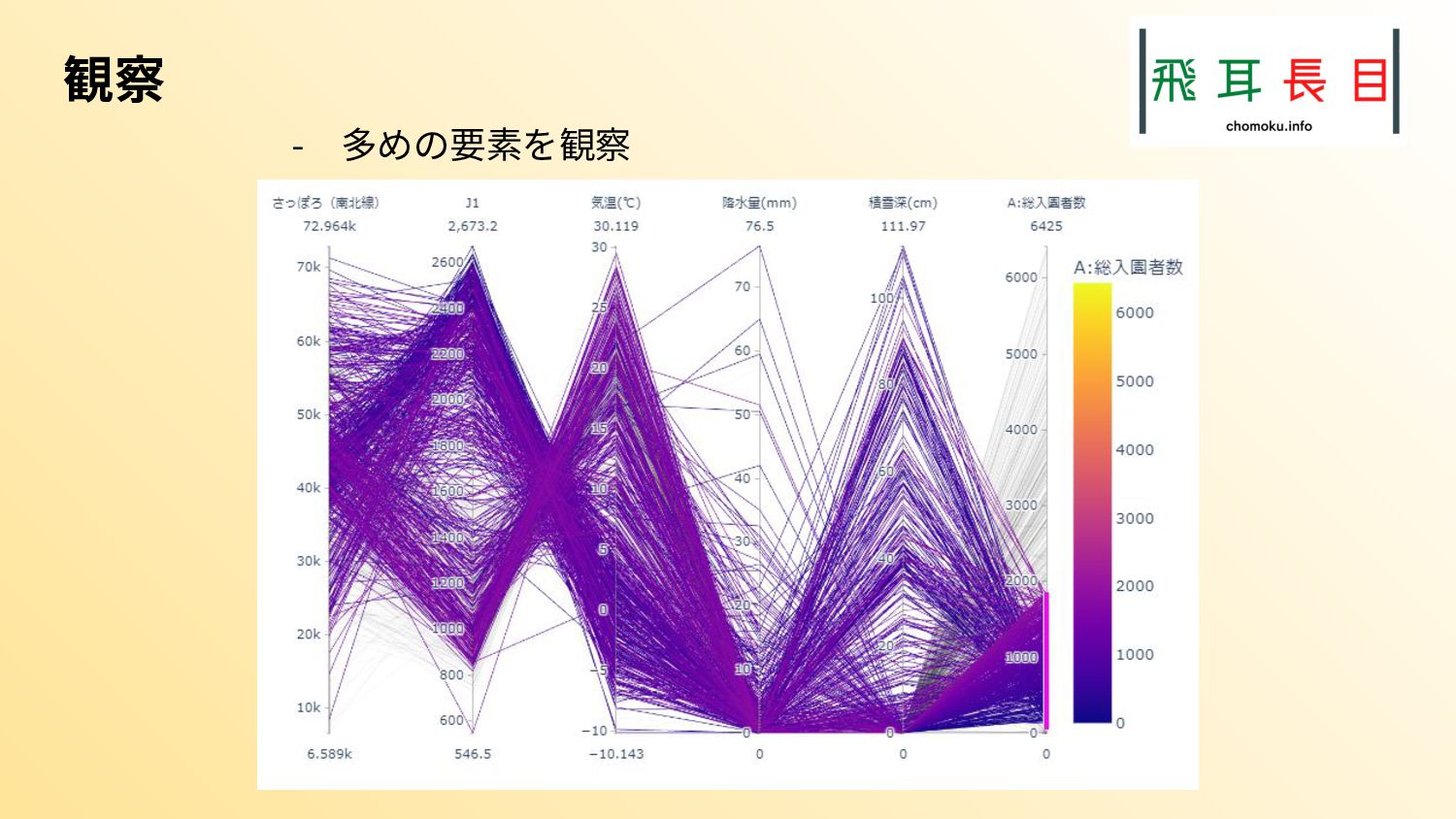{kind=link}
{kind=link}
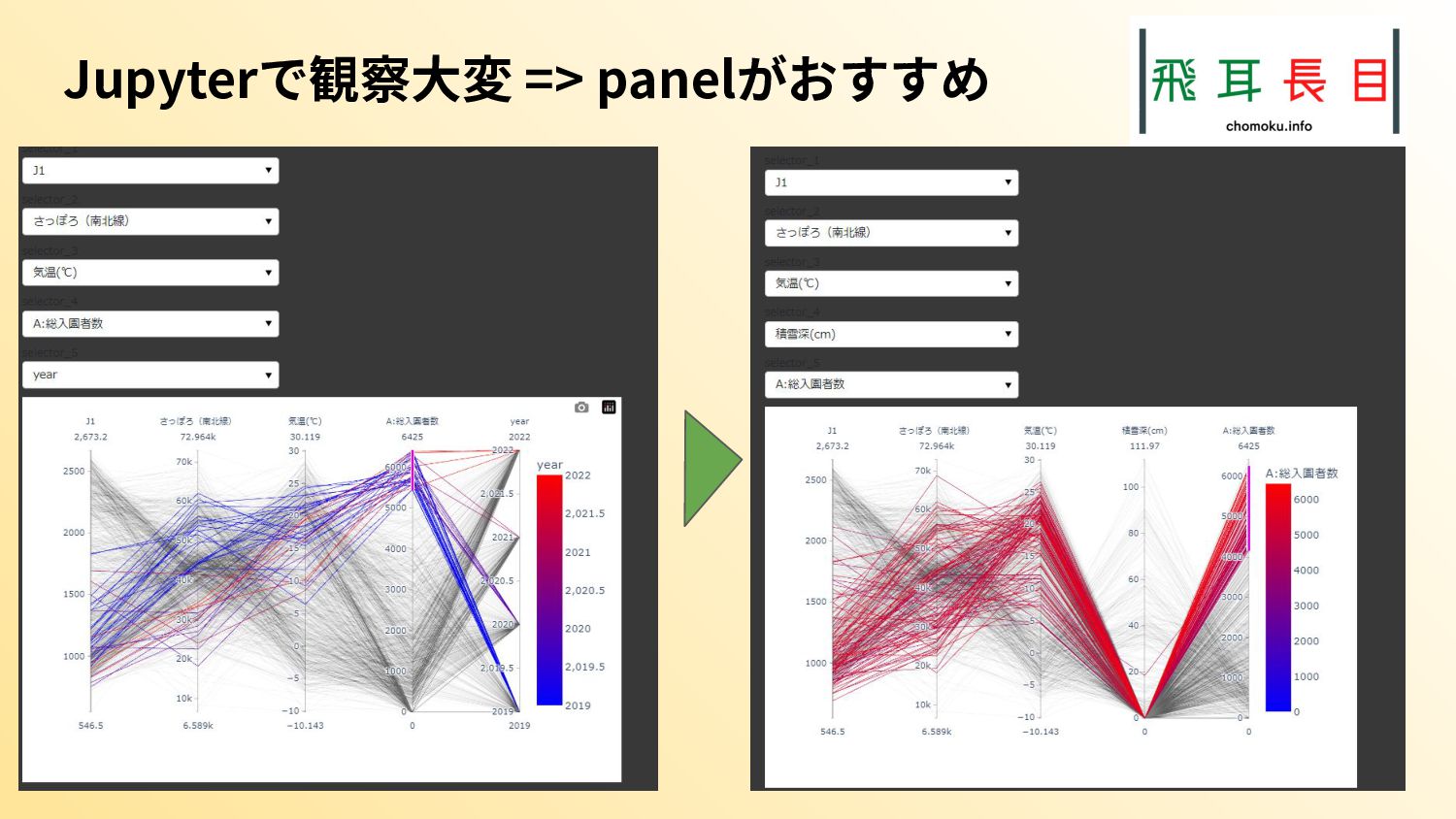{kind=link}
{kind=link}
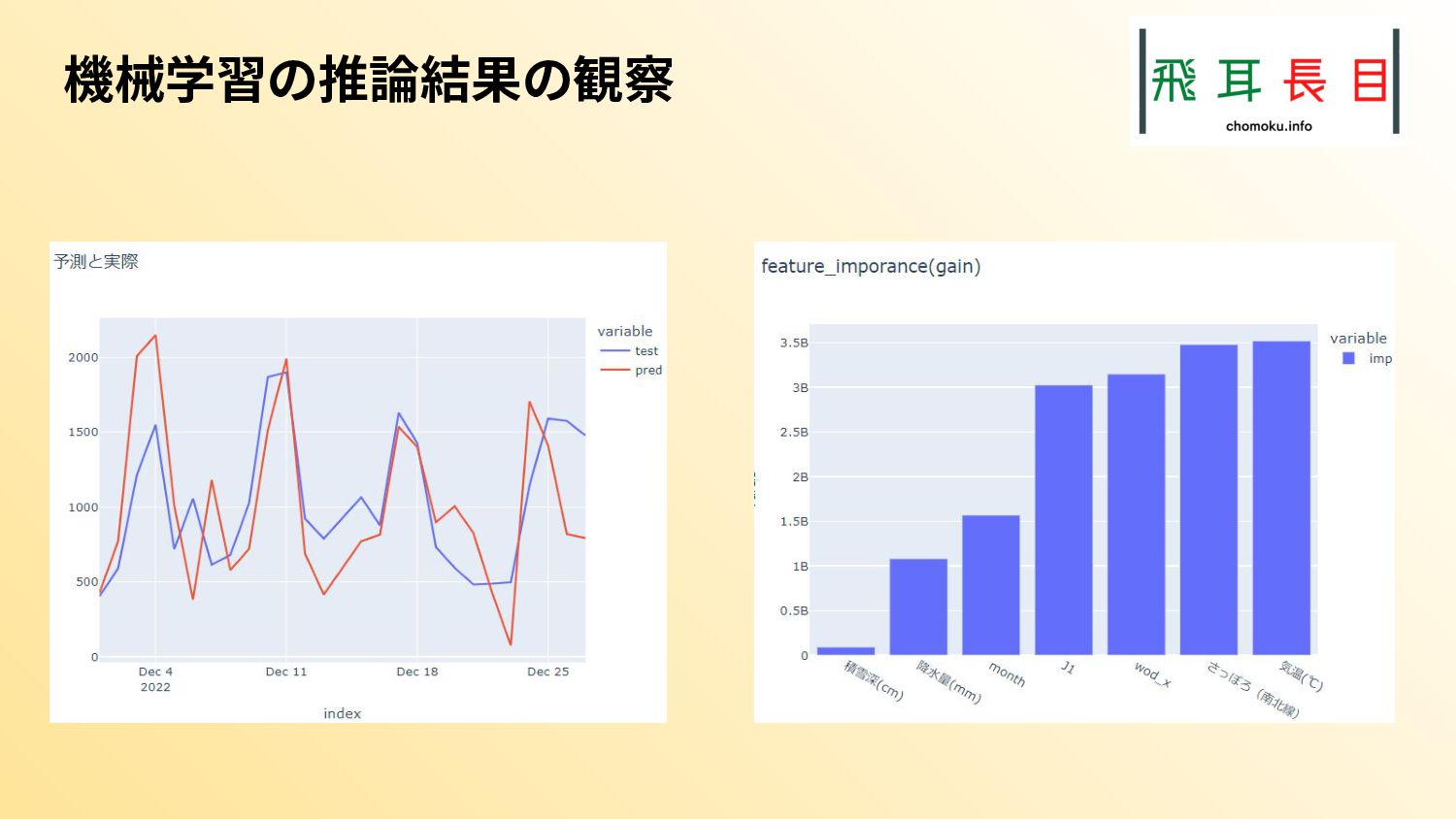{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}