Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Introduction to Deep Learning and Neural Networks.
Search
Bedanta Bikash Borah
July 24, 2018
Education
290
0
Share
Introduction to Deep Learning and Neural Networks.
Bedanta Bikash Borah
July 24, 2018
More Decks by Bedanta Bikash Borah
See All by Bedanta Bikash Borah
Thinking beyond platforms with KMP
iambedant
0
15
Let's Stream that Video - an ExoPlayer Starters Guide
iambedant
0
130
A tale of Multiplatform
iambedant
0
100
A Full-Stack app with Kotlin —by an Android Developer
iambedant
2
250
Other Decks in Education
See All in Education
Data Presentation - Lecture 5 - Information Visualisation (4019538FNR)
signer
PRO
1
3.1k
Data Processing and Visualisation Frameworks - Lecture 6 - Information Visualisation (4019538FNR)
signer
PRO
1
3k
0318
cbtlibrary
0
120
BITCOIN : Les fondamentaux !
rlifchitz
0
130
Dashboards - Lecture 11 - Information Visualisation (4019538FNR)
signer
PRO
1
2.6k
2026年度春学期 統計学 第1回 イントロダクション ー 統計的なものの見方・考え方について (2026. 4. 9)
akiraasano
PRO
0
120
Gitの仕組みと用語 / 01-b-term
kaityo256
PRO
1
360
Interaction - Lecture 10 - Information Visualisation (4019538FNR)
signer
PRO
0
2.6k
Gesture-based Interaction - Lecture 6 - Next Generation User Interfaces (4018166FNR)
signer
PRO
1
2.2k
From Days to Minutes: How We Taught an AI to Onboard 50+ Tenants on our AI Features
mfcabrera
0
110
Modelamiento Matematico (Ingresantes UNI 2026)
robintux
0
280
From Participation to Outcomes
territorium
PRO
0
450
Featured
See All Featured
Art, The Web, and Tiny UX
lynnandtonic
304
21k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.3k
KATA
mclloyd
PRO
35
15k
The agentic SEO stack - context over prompts
schlessera
0
770
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
740
Marketing to machines
jonoalderson
1
5.2k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
420
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Odyssey Design
rkendrick25
PRO
2
610
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
910
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2k
Evolving SEO for Evolving Search Engines
ryanjones
0
190
Transcript
Introduction to Deep Learning and Neural Networks. Bedanta Bikash Borah
@iamBedant
None
None
Agenda 1. What is Deep Learning? 2. Why Deep Learning
is taking off? 3. How Deep Learning works? 4. Training. 5. Example MNIST. 6. Code Sample. 7. Few extra concepts.
Deep Learning The term Deep Learning refers to training very
large Neural Network
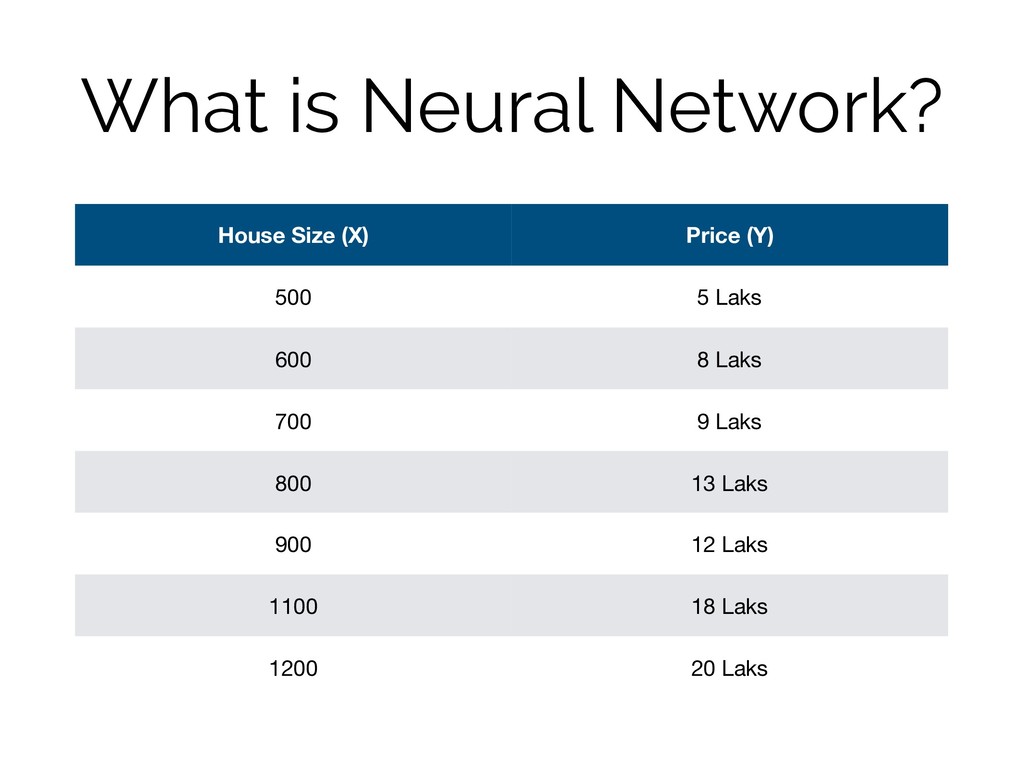
What is Neural Network? House Size (X) Price (Y) 500
5 Laks 600 8 Laks 700 9 Laks 800 13 Laks 900 12 Laks 1100 18 Laks 1200 20 Laks
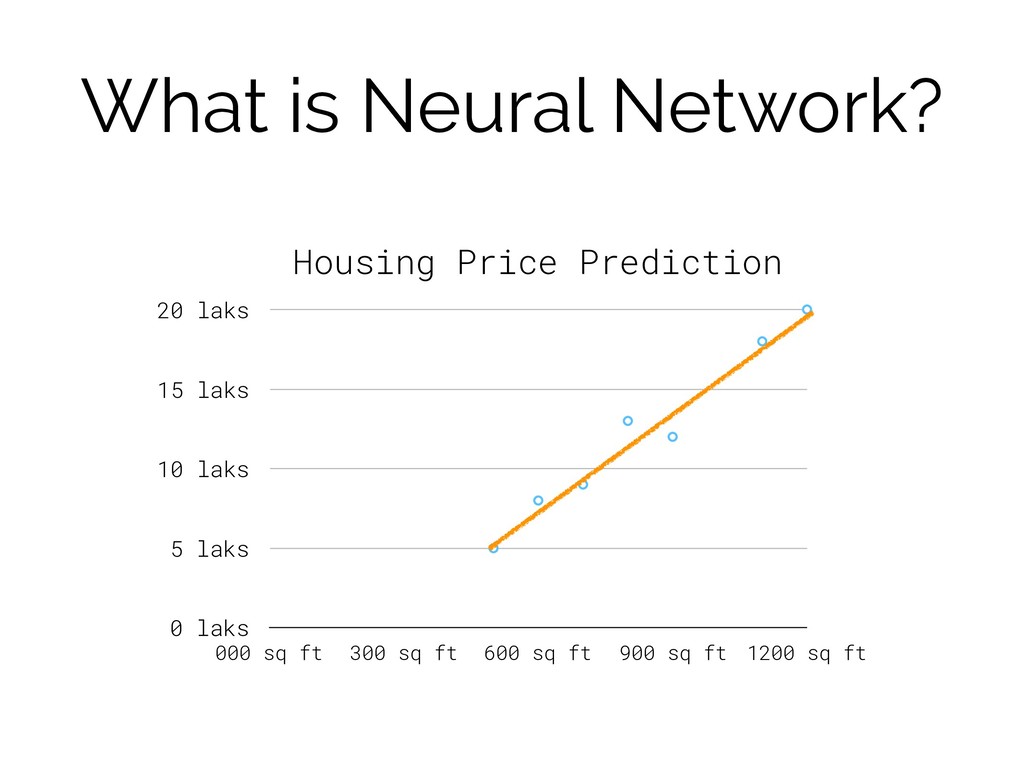
Housing Price Prediction 0 laks 5 laks 10 laks 15
laks 20 laks 000 sq ft 300 sq ft 600 sq ft 900 sq ft 1200 sq ft What is Neural Network?
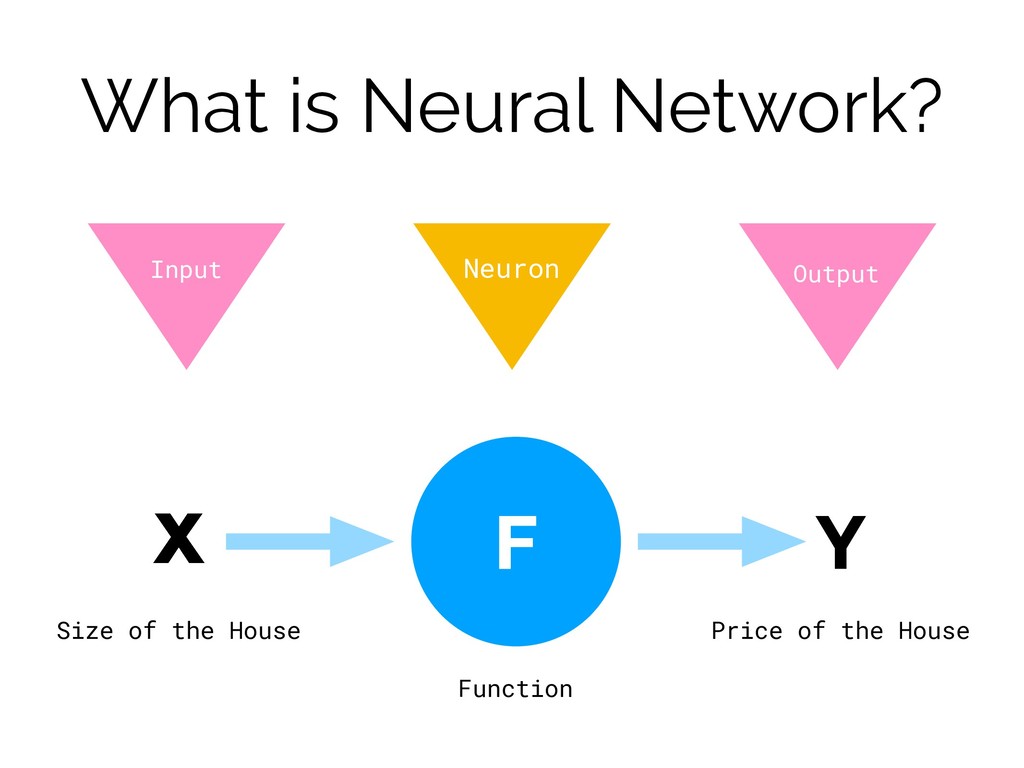
What is Neural Network? x Y Size of the House
Price of the House Neuron Function F Input Output
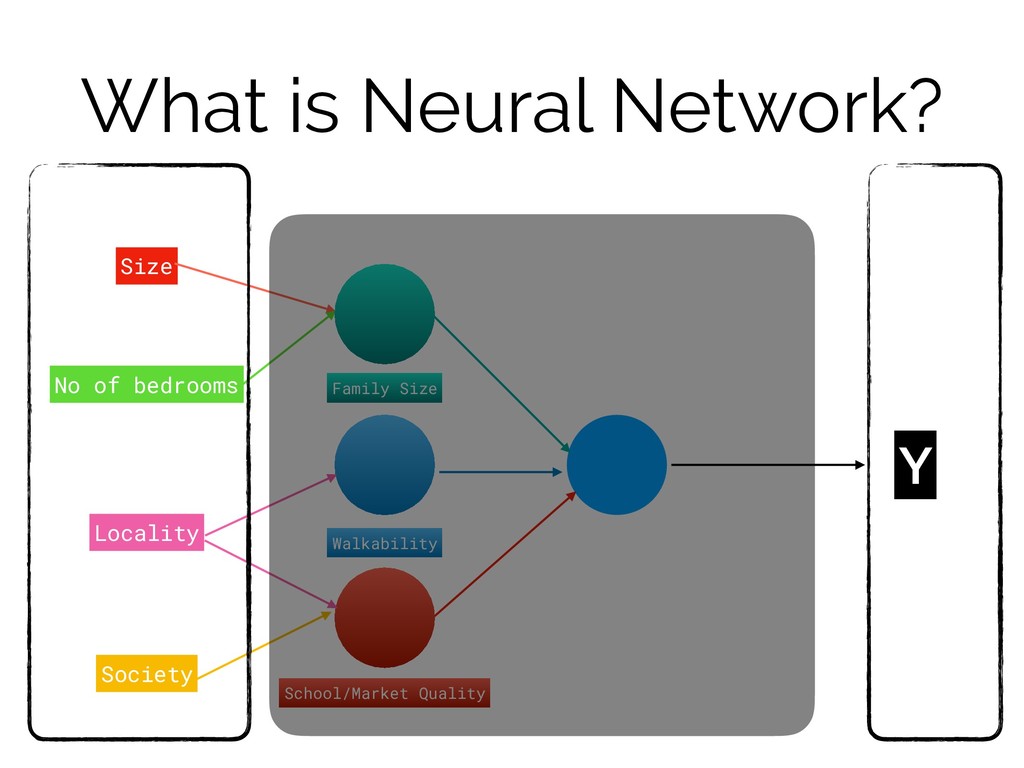
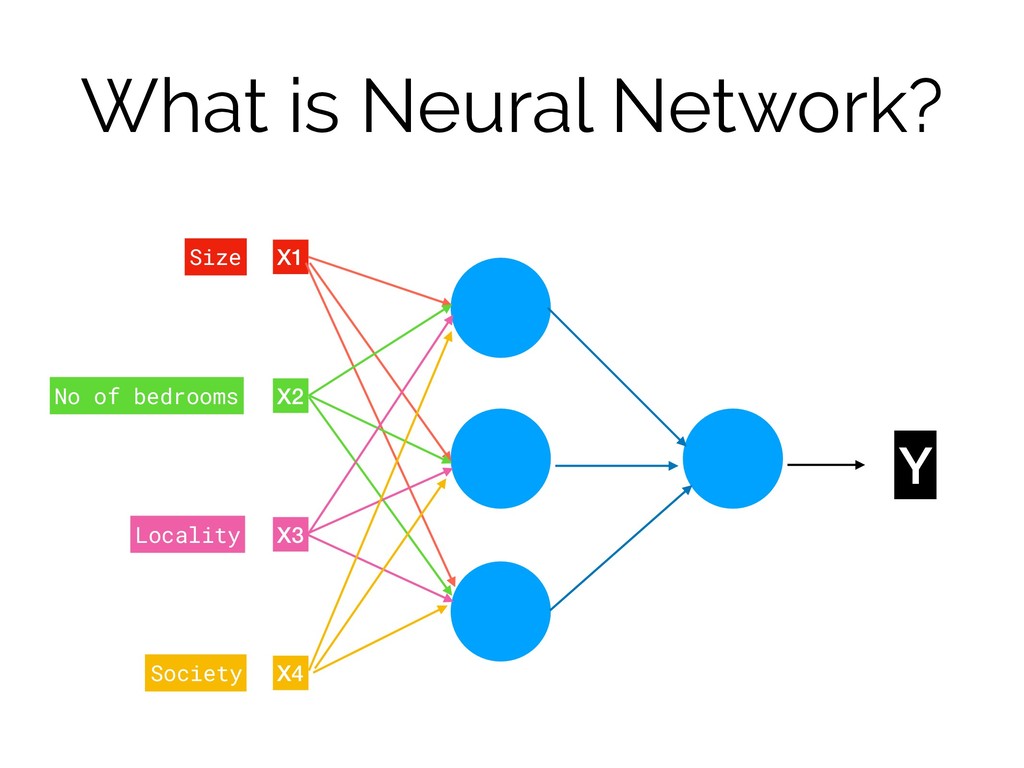
What is Neural Network? Size No of bedrooms Locality Society
Y Family Size Walkability School/Market Quality
What is Neural Network? X1 X2 X3 X4 Y Size
No of bedrooms Locality Society
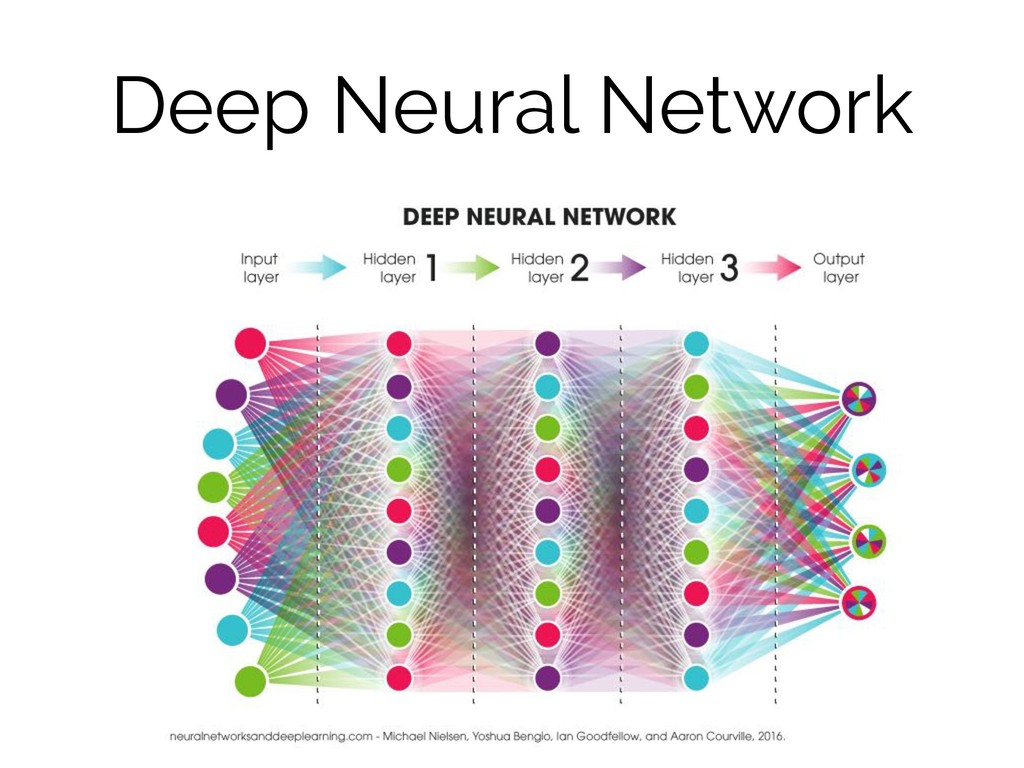
Deep Neural Network
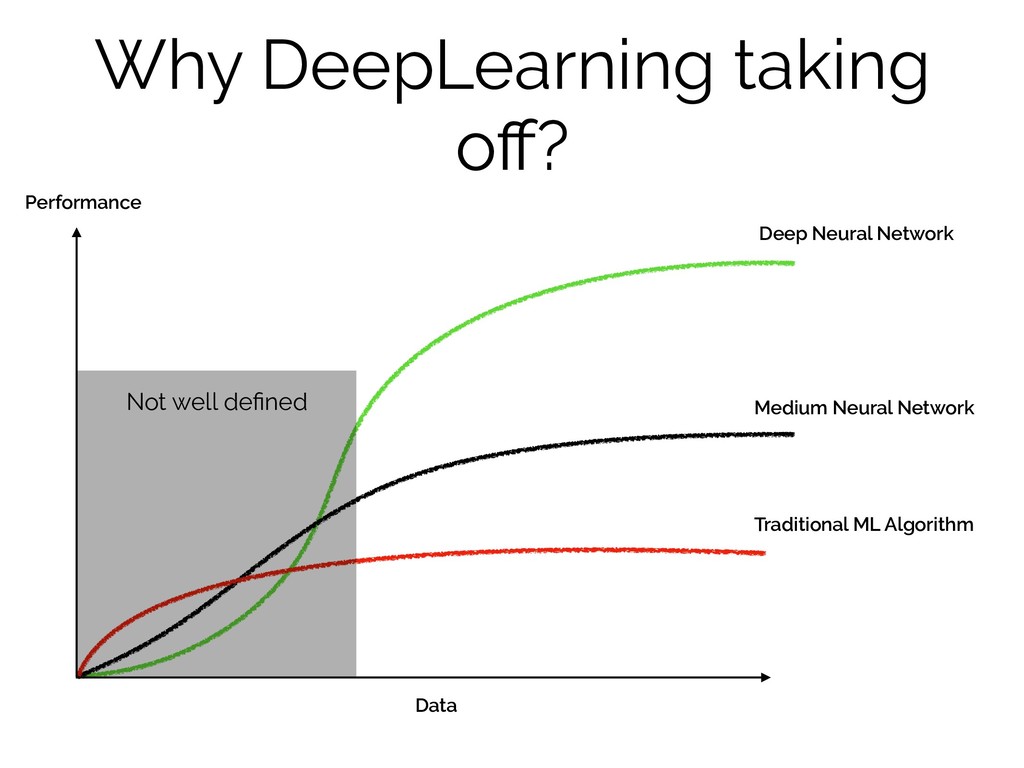
Why DeepLearning taking off? Deep Neural Network Medium Neural Network
Traditional ML Algorithm Data Performance Not well defined
Why DeepLearning taking off? 1. Data 2. Computation 3. Algorithm
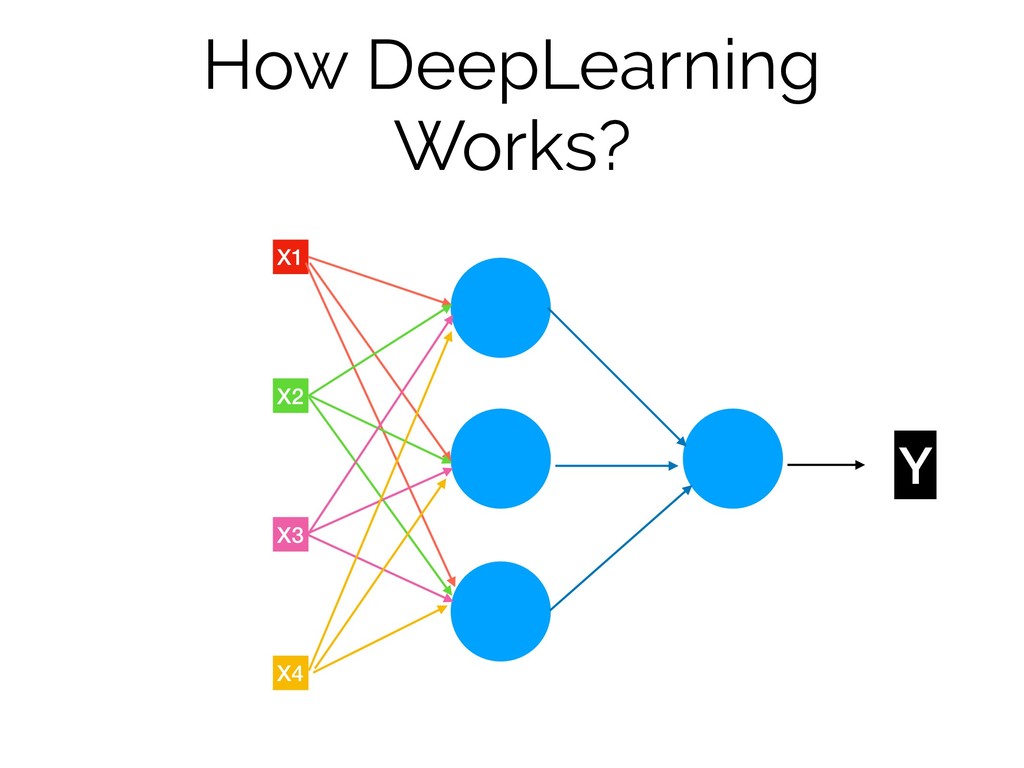
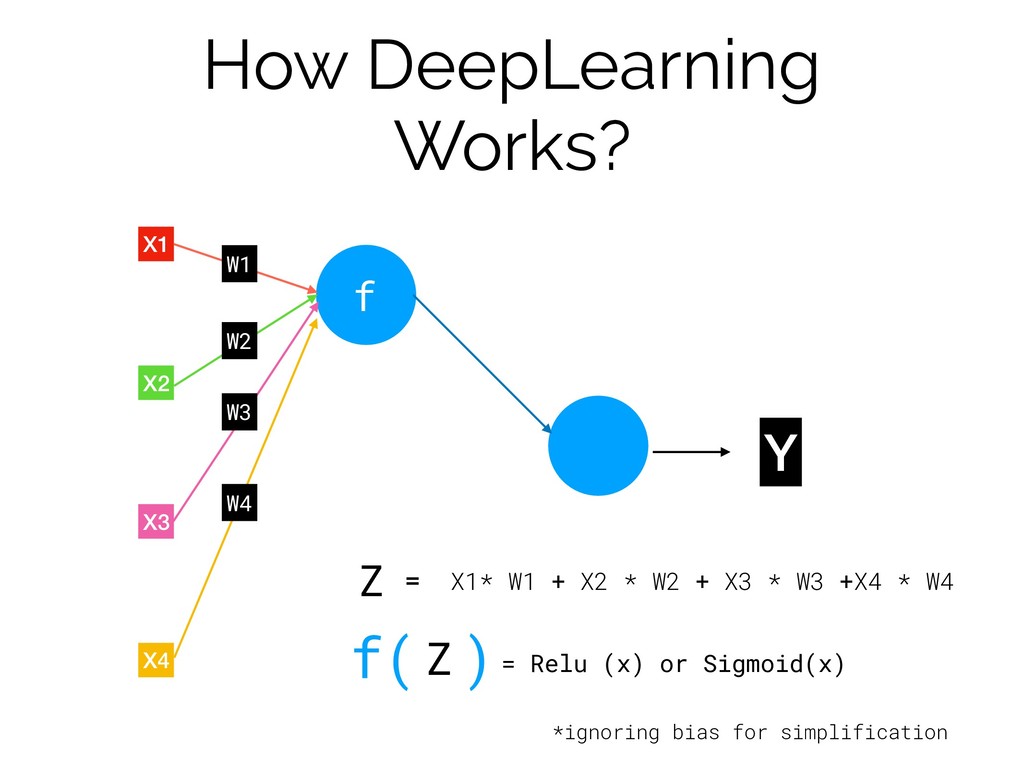
How DeepLearning Works? X1 X2 X3 X4 Y
How DeepLearning Works? X1 X2 X3 X4 Y f W1
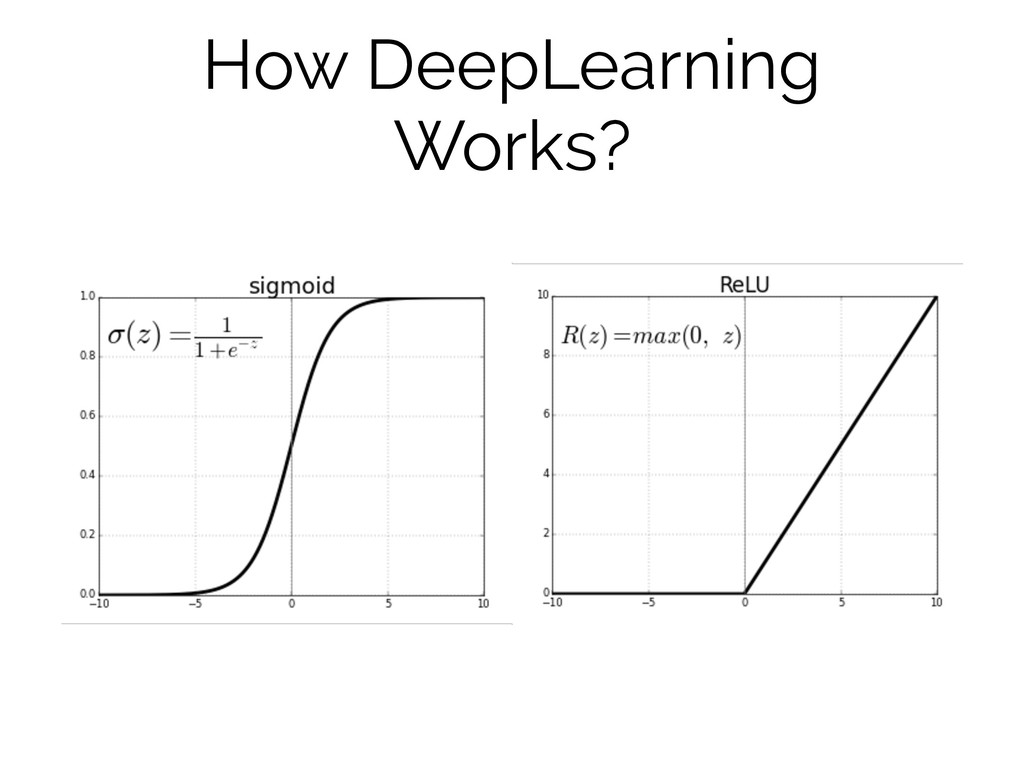
W2 W3 W4 X1* W1 + X2 * W2 + X3 * W3 +X4 * W4 Z f( )= Relu (x) or Sigmoid(x) *ignoring bias for simplification Z =
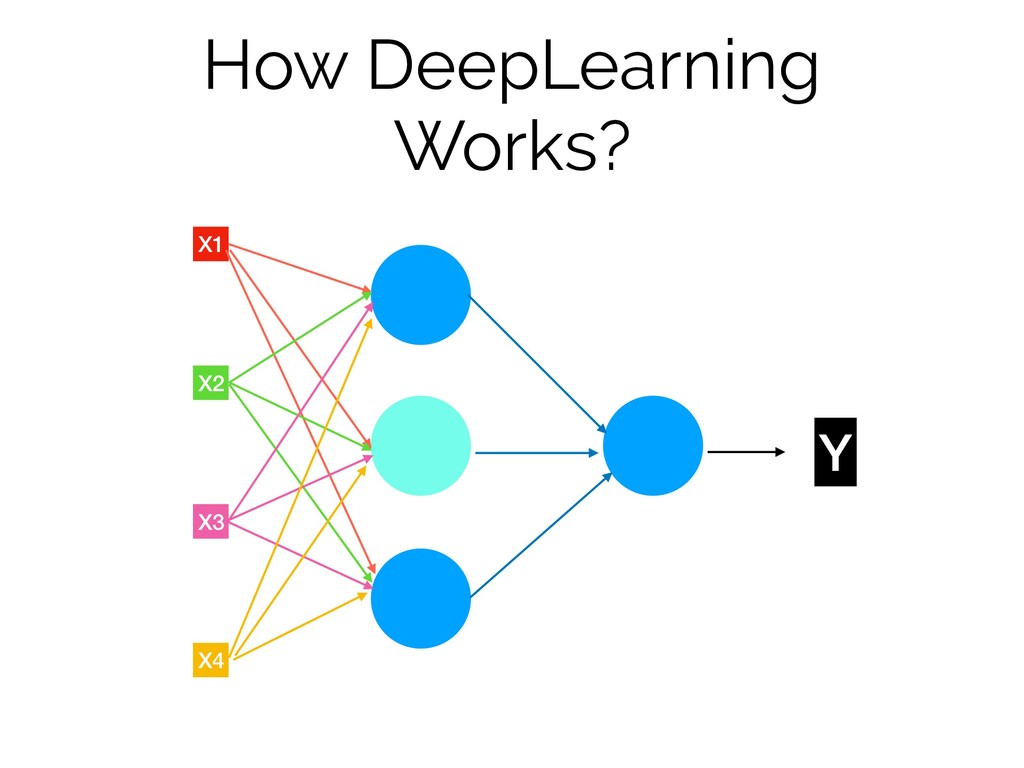
How DeepLearning Works?
How DeepLearning Works? X1 X2 X3 X4 Y
Interviewer: What is your biggest strength? Me: I am an
expert in machine learning. Interviewer: What’s 9 + 10? Me: It’s 3. Interviewer: Nowhere near. It’s 19. Me: It’s 16. Interviewer: Wrong. It’s still 19 Me: It’s 18. Interviewer: No. It’s 19 Me: It’s 19. Interviewer: You’re hired
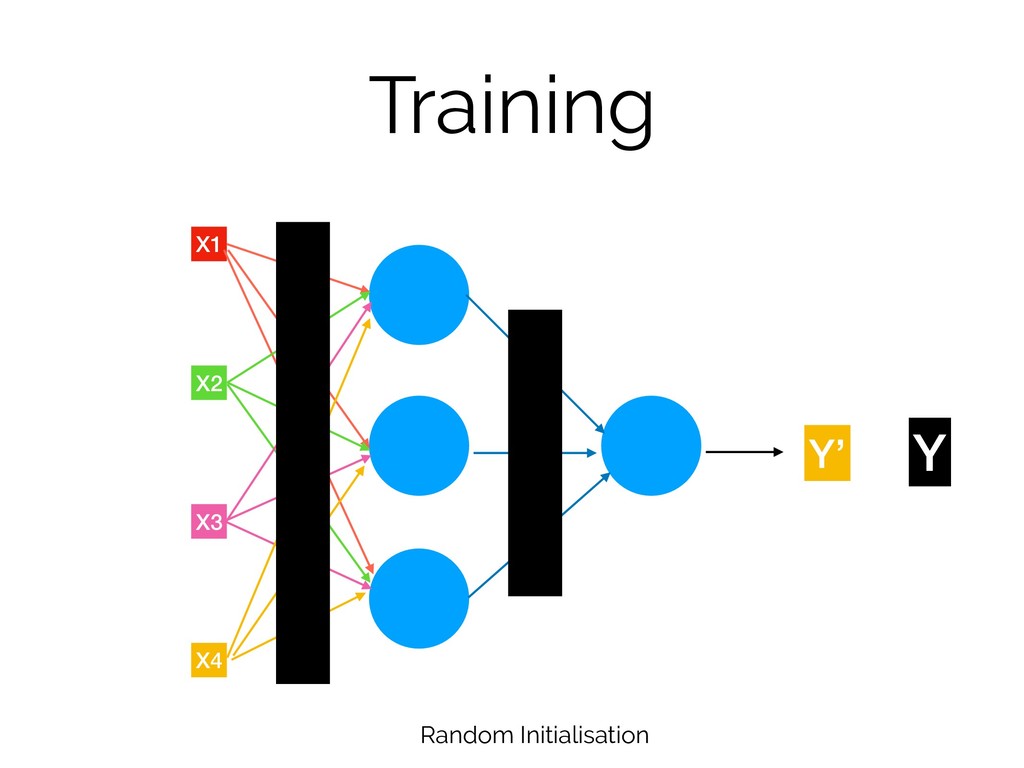
Training X1 X2 X3 X4 Y Y’ Random Initialisation
Training 1.Quadratic cost 2.Cross-entropy cost 3.Exponential cost Cost Function:
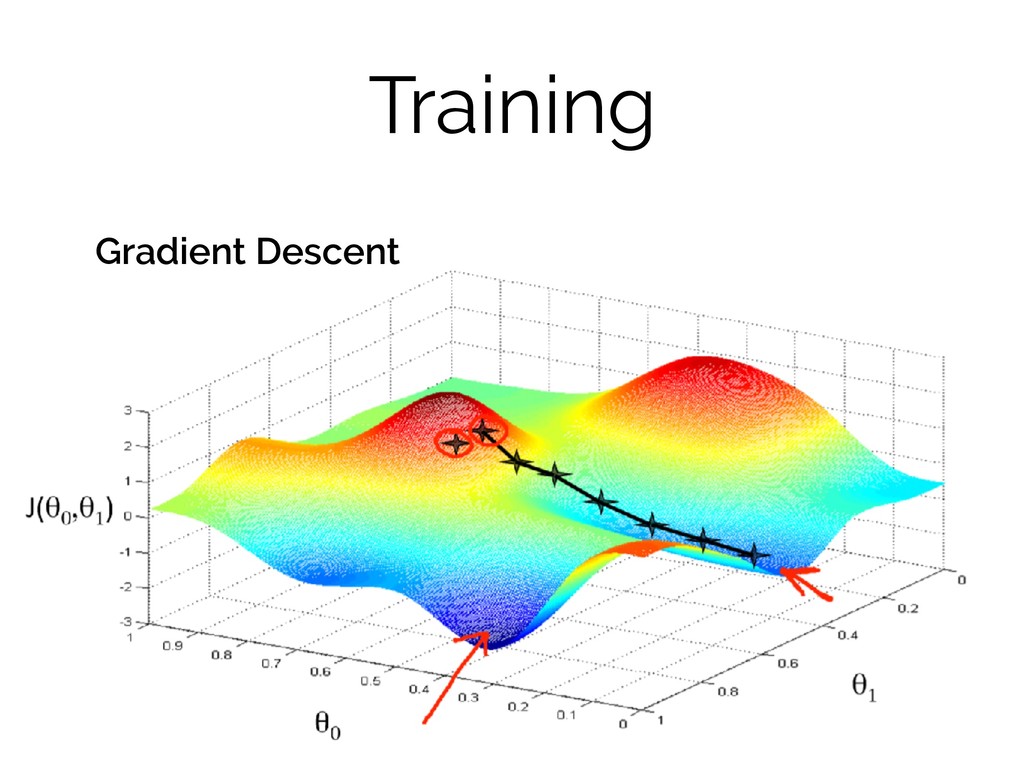
Training Grad Gradient Descent
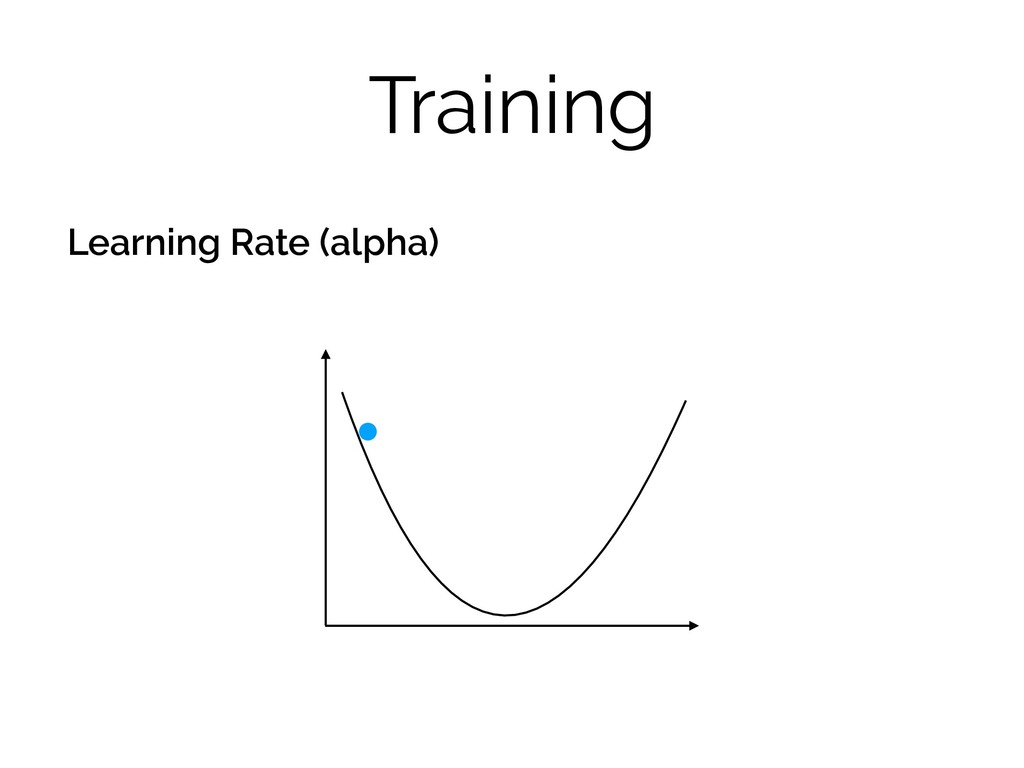
Training Learning Rate (alpha)
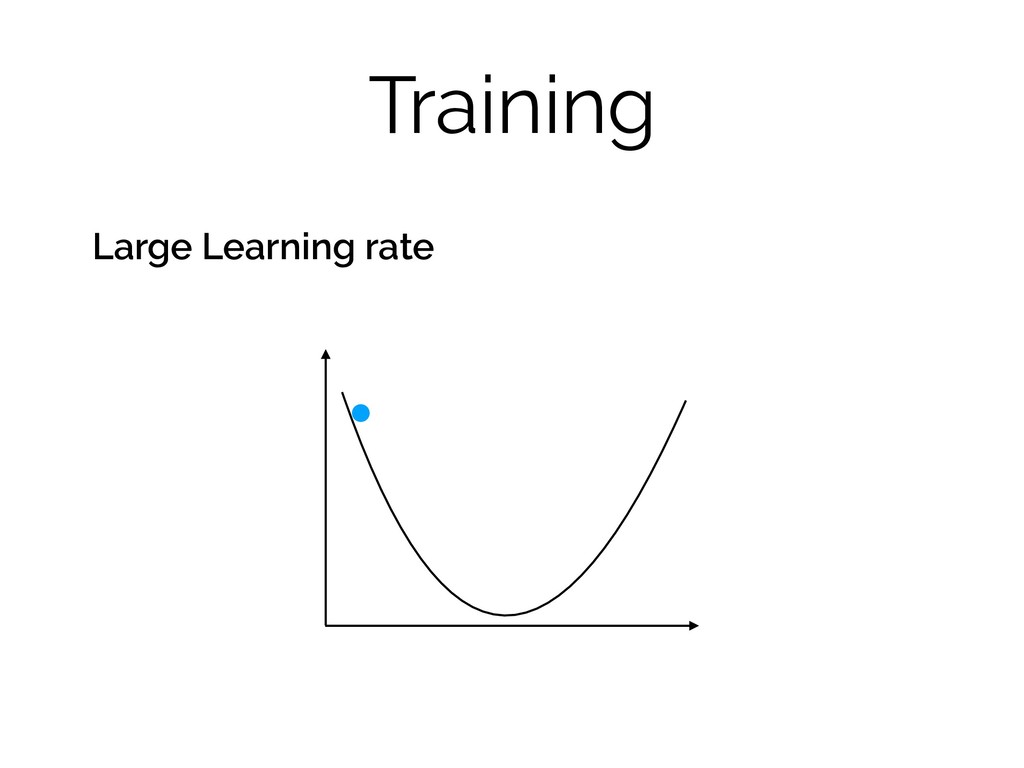
Training Large Learning rate
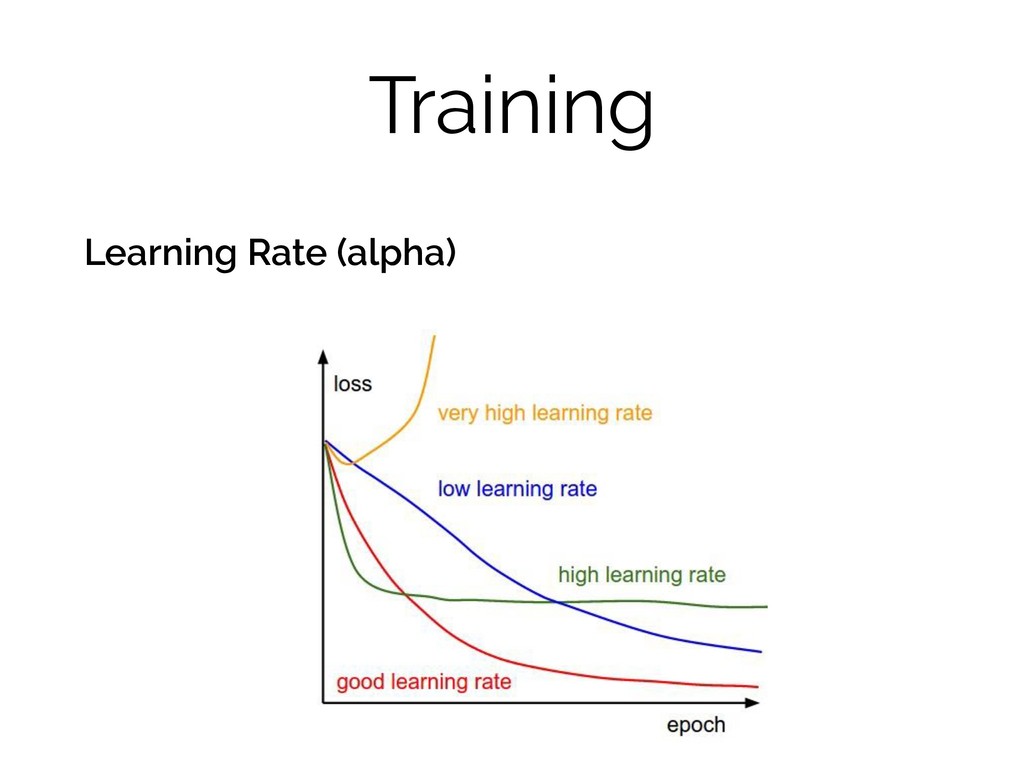
Training Learning Rate (alpha)
Training New Weights = Existing Weights Learning Rate - *
Gradient ( )
Interviewer: What is your biggest strength? Me: I am an
expert in machine learning. Interviewer: What’s 9 + 10? Me: It’s 3. Interviewer: Nowhere near. It’s 19. Me: It’s 16. Interviewer: Wrong. It’s still 19 Me: It’s 18. Interviewer: No. It’s 19 Me: It’s 19. Interviewer: You’re hired.
Example MNIST
MNIST 60,000 training samples 10,000 test samples
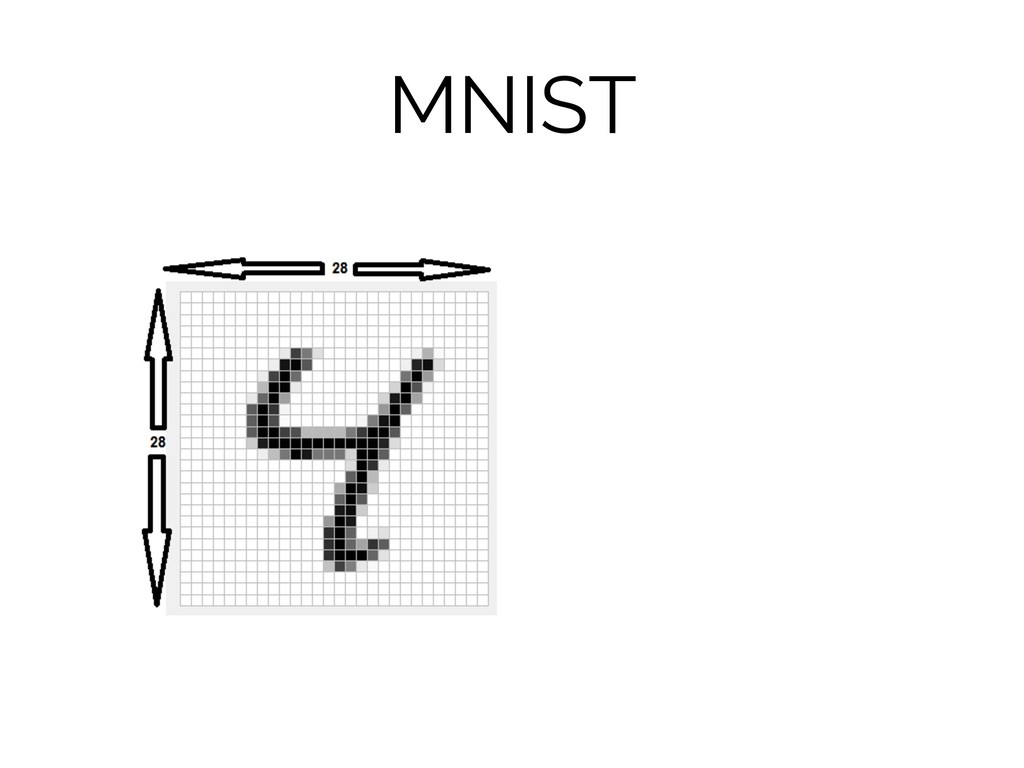
MNIST
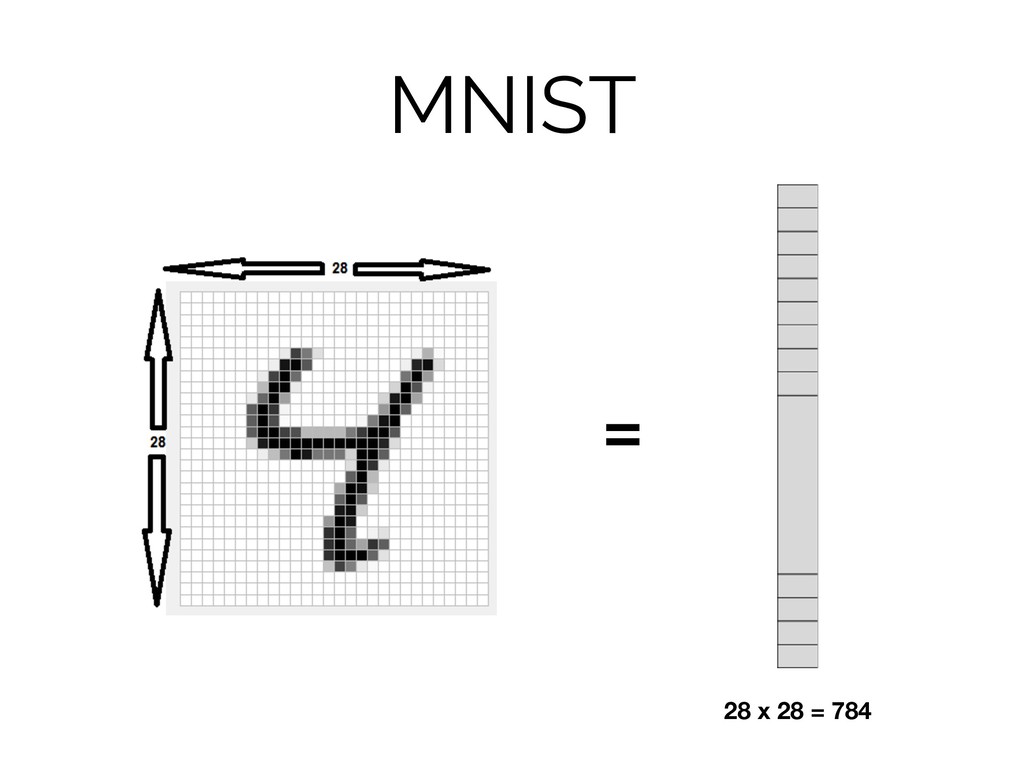
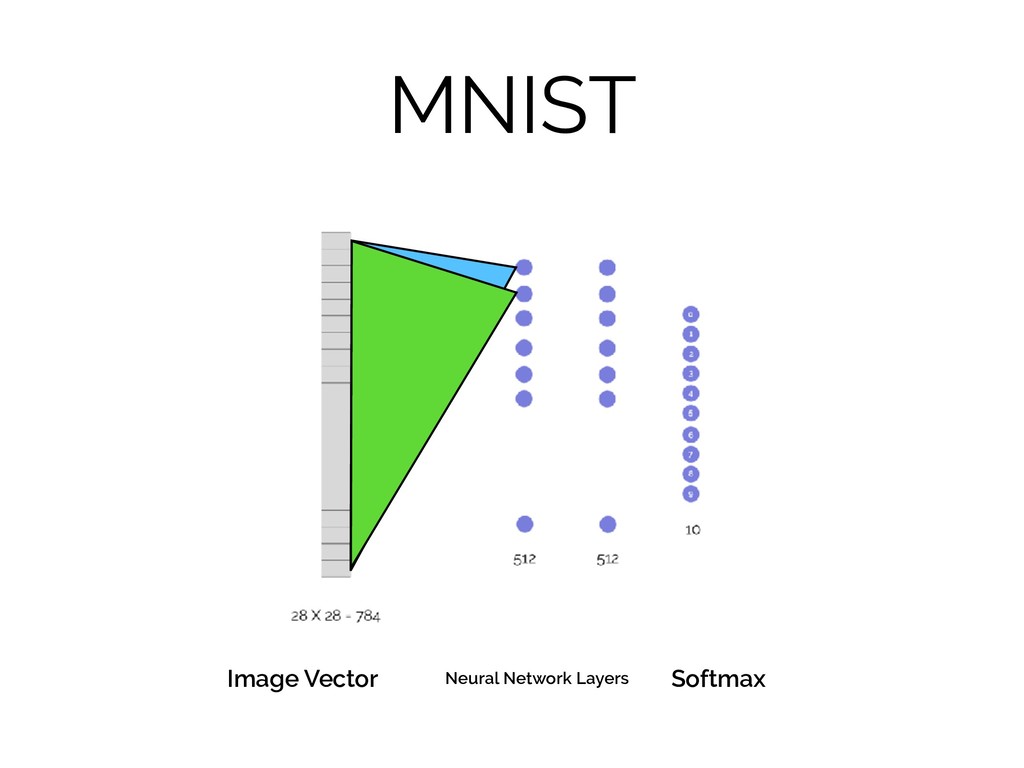
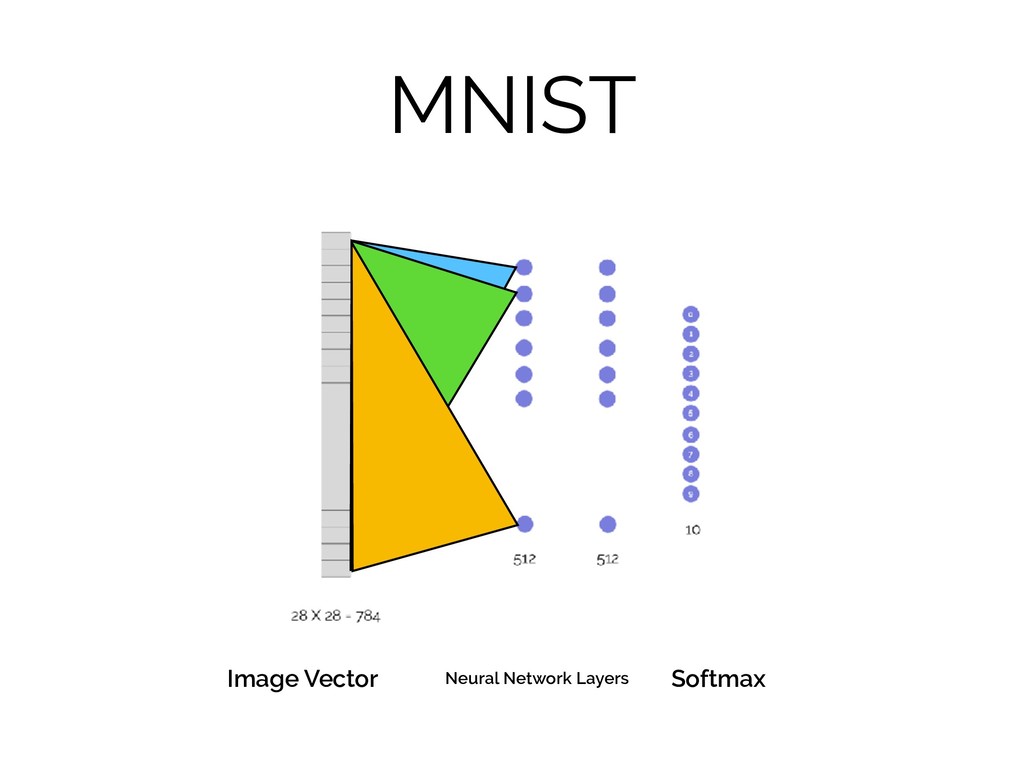
MNIST = 28 x 28 = 784
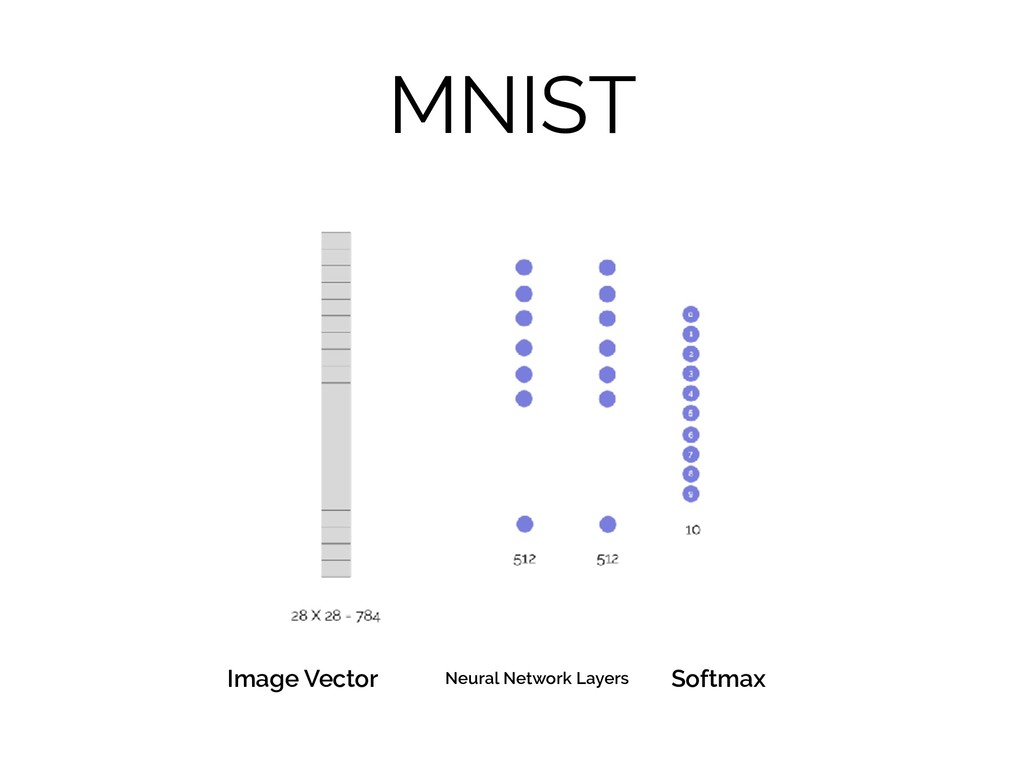
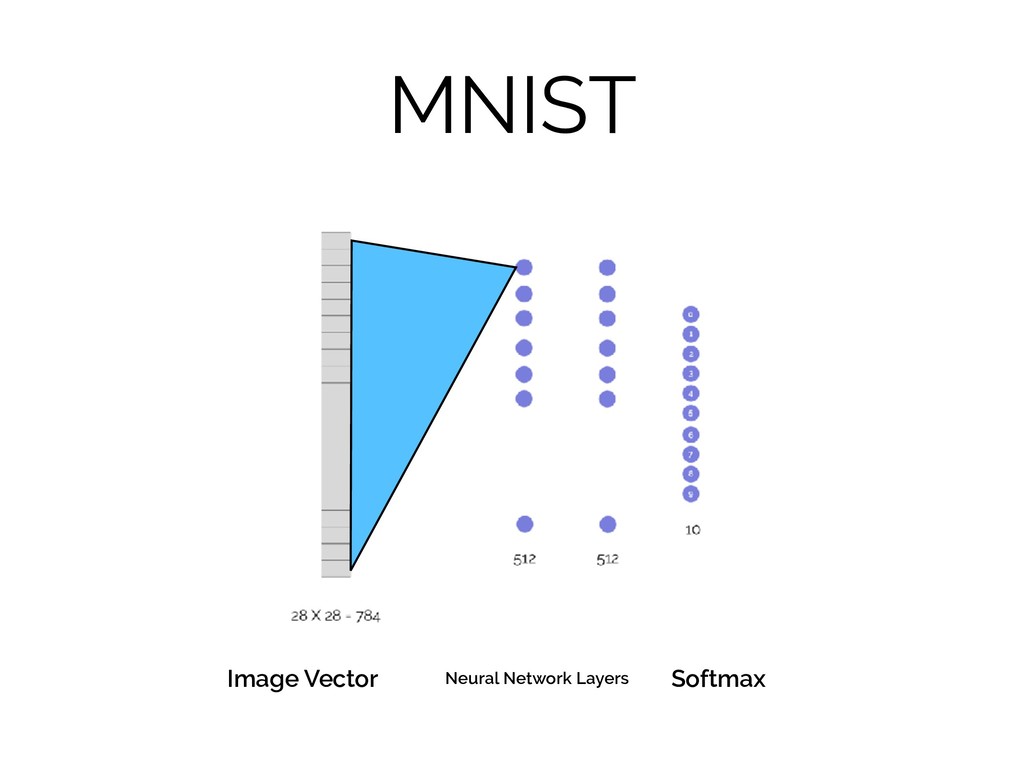
MNIST Softmax Image Vector Neural Network Layers
MNIST Softmax Image Vector Neural Network Layers
MNIST Softmax Image Vector Neural Network Layers
MNIST Softmax Image Vector Neural Network Layers
MNIST Softmax Image Vector Neural Network Layers
MNIST **from three blue one brown’s “But, what is a
neural network?” video**
Talk is cheap show me the code.
Advanced MNIST CNN (convolutional neural network)
Interviewer: What is your biggest strength? Me: I am an
expert in machine learning. Interviewer: What’s 9 + 10? Me: It’s 3. Interviewer: Nowhere near. It’s 19. Me: It’s 16. Interviewer: Wrong. It’s still 19 Me: It’s 18. Interviewer: No. It’s 19 Me: It’s 19. Interviewer: You’re hired.
Interviewer: What is your biggest strength? Me: I am an
expert in machine learning. Interviewer: What’s 9 + 10? Me: It’s 3. Interviewer: Nowhere near. It’s 19. Me: It’s 16. Interviewer: Wrong. It’s still 19 Me: It’s 18. Interviewer: No. It’s 19 Me: It’s 19. Interviewer: What’s 20 + 10? Me: It’s 19
Advanced MNIST Overfitting (Regularization, Dropout)
Extras
Reference https://github.com/iamBedant/CMRIT-Deeplearning-TechTalk-Demo Simple MNIST Example https://github.com/iamBedant/TensoreFlowLite Android TFLite Example Others:
https://www.tensorflow.org/ https://keras.io/
Thank You !!! @iamBedant
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}