Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データ分析の再現性を高くするためのExploratoryの活用法
Search
Ikuya Murasato
June 11, 2021
Business
2.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データ分析の再現性を高くするためのExploratoryの活用法
2021/06/11(金) に開催したExploratory データサイエンス勉強会#19の株式会社フォーバルテレコム様のご登壇資料です。
Ikuya Murasato
June 11, 2021
More Decks by Ikuya Murasato
See All by Ikuya Murasato
トピックモデル分析を活用した問合せ業務の効率化
ikuyam
1
310
回帰分析の活用による新商品の販売力予測
ikuyam
1
210
生存分析モデルを利用したLineのブロック要因分析
ikuyam
0
140
自動車トラブルと気象条件などの探索的データ分析
ikuyam
0
130
データサイエンス「も」使えるチェンジメーカー輩出への挑戦
ikuyam
0
490
ExploratoryとRによる全学データサイエンス教育
ikuyam
0
730
エンゲージメント向上のための人事制度改革 - 管理部門におけるExploratoryの活用
ikuyam
0
2.2k
「学ぶ」分析技術から「使う」分析技術へ - Exploratoryによるドリル演習
ikuyam
0
540
データサイエンス入門教育の現場から - 46歳新任教員2年間の苦闘
ikuyam
0
660
Other Decks in Business
See All in Business
株式会社アイリッジ 会社説明資料
iridge
0
6.9k
結果、生き残った_きのこカンファレンス2026
yurufuwahealer
0
150
会社紹介資料/Idein株式会社 ※URLが変わりました
ideininc
0
62k
station会社紹介資料
station_inc
PRO
0
150
unname_会社概要資料 2026.06.25 update
unnameinc
PRO
1
3.8k
Railsガイド協賛プランの概要
yasslab
PRO
2
14k
プロシェアリング白書2026_PROSHARING_REPORT_2026
circulation
0
180
セーフィー株式会社(Safie Inc.) 会社紹介資料
safie_recruit
7
460k
「プロダクトヒストリーカンファレンス2026」リチェルカ投影資料
recerqainc
0
190
会社紹介資料/Idein株式会社
ideininc
0
120
BizDev視点で見る、Snowflake最新動向!/ snowflake-trend
finanori
1
220
株式会社スタイルブレッド 会社紹介資料
yuzurukikuta
0
700
Featured
See All Featured
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Automating Front-end Workflow
addyosmani
1370
210k
Making Projects Easy
brettharned
120
6.7k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
Typedesign – Prime Four
hannesfritz
42
3.1k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Embracing the Ebb and Flow
colly
88
5.1k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
WCS-LA-2024
lcolladotor
0
680
Transcript
データ分析の再現性を 高くするための Exploratoryの活用法 内容は個人の見解ですので所属する組織とは関係ありません また、効用には個人差があります
自己紹介と業務概要 • 名前 矢通 康弘@株式会社フォーバルテレコム • 事業概要 おもに小・中規模事業者向けの通信・通話サービス提供や 販売店等が提供する保守サービス等の一括請求サービス、 最近は電力小売事業やサブスク型サービスの受注管理システム提供など
• やってきたこと 警備員、工事現場監督(補助)、 DTP、LAN構築、PCヘルプデスク ↑前職 ↓現職 通信サービス企画、データ集計、 業界団体の委員会メンバー、 最近は主にBI関係、Python、BigQueryとかを使って事業状況を詳細に把握するための データ分析基盤などの仕組みづくりに注力
可視化 蓄積 加工 データ処理業務の概要 社内LAN ファイル サーバ BigQuery DataPortal 情シス管轄データ
1回で数百万~ 数千万レコード規模 電力の使用量データ(30分値)や、 通信サービスの請求明細から契約数・利用動向などを集計、可視化 Web-API FTP 1回で 数十万万レコード規模 定型レポートの 社内共有 インサイトを得るための アドホックな分析
一般的な分析の種類と取り組み方 • アドホックな分析 →チャートやアナリティクスに取り組むときはこの考え方、 これをやっている時はひたすらアウトプットだけを追求 (ある意味、手段は問わない) • 定型的なレポート →ここに落とし込む時は徹底的な効率化を追求、 定期的な処理として運用する際のラングリングはこれに該当
定型レポートの運用においては 再現性の確保が重要 • いつでも、誰でも同じ結果が出せる • それぞれに再現可能性があればその中で細かく改善していける • その時に「手をいれやすい」作り方にしておくのがよい このへんを参考にしました→https://www.igaku-shoin.co.jp/paper/archive/y2020/PA03357_03 方法の再現可能性
同じデータから同じ方法を用いて同じ結果が得られること 結果の再現可能性 異なるデータ群に同じ方法を用いて同じ結果が得られること 推論の再現可能性 異なるデータ群や、異なる手法から同じ結論が導き出せること
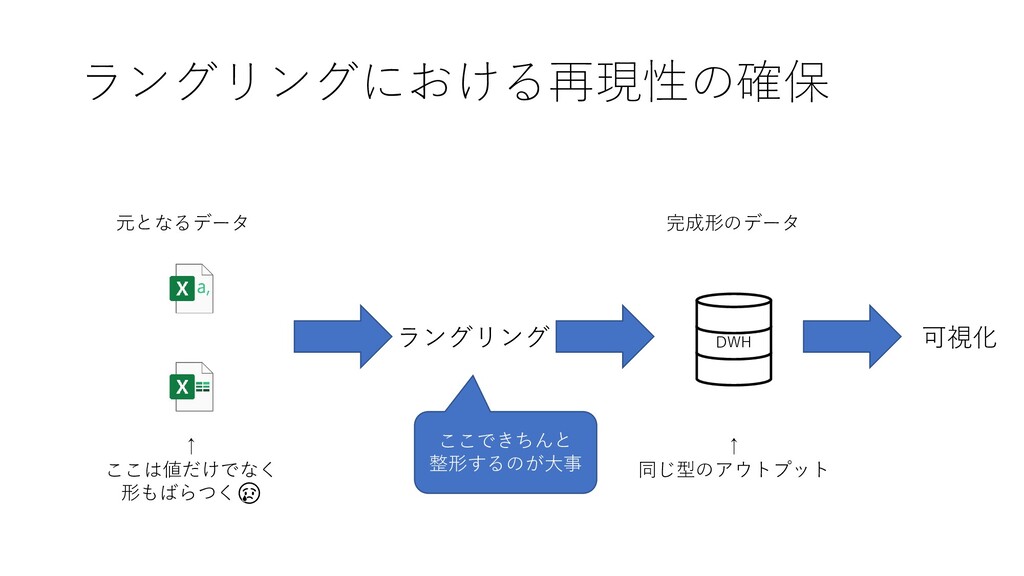
ラングリングにおける再現性の確保 元となるデータ DWH ↑ ここは値だけでなく 形もばらつく😢 ↑ 同じ型のアウトプット 可視化 ここできちんと
整形するのが大事 完成形のデータ ラングリング
再現性確保のために心がけていること 1. 確実に同じ入力を作る • データタイプの自動認識は基本OFF • 入力データはできるだけExcel形式を避ける 2. 徹底的な工数整理 •
最初にやることの順番を決める • ステップをできるだけ減らす • 効率のよい処理の仕方を考える 3. 可読性 • フォルダを活用してデータフレームを整理 • 適宜ブランチを作成 • 似たような処理はまとめる • コメントをつける 4. アップデートへのキャッチアップ
1.確実に同じ入力を作る 毎回毎回ソースデータの内容を確認しながら運用するのは負荷が高いし、 再実行時のエラーはリカバーするのがたいへんなのでできるだけ避ける
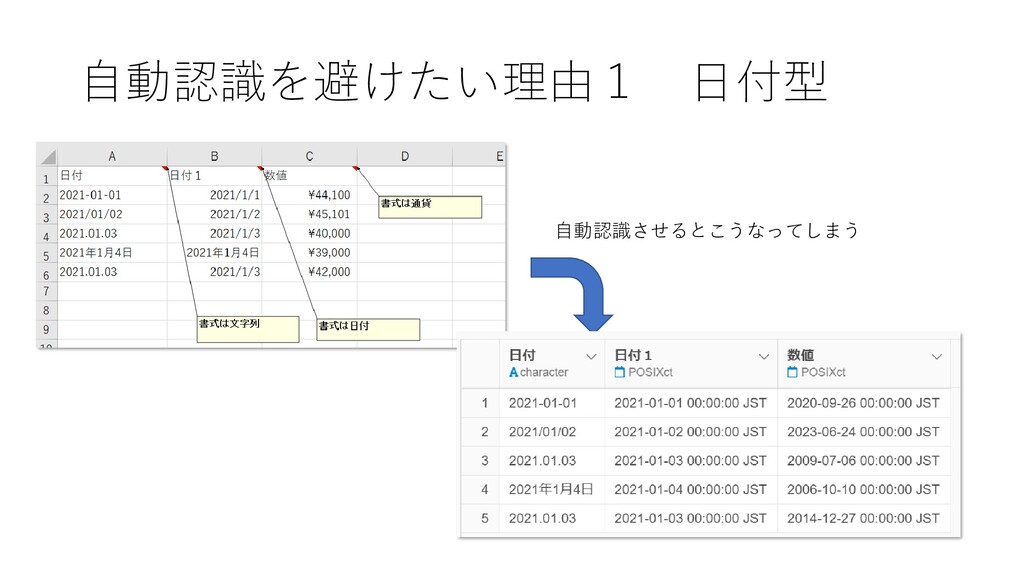
自動認識を避けたい理由1 日付型 自動認識させるとこうなってしまう
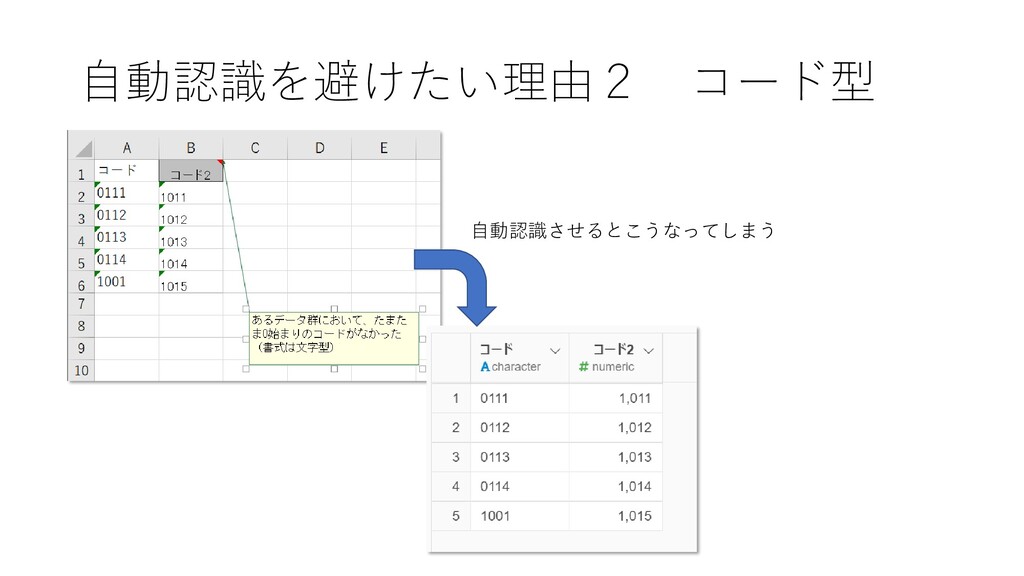
自動認識を避けたい理由2 コード型 自動認識させるとこうなってしまう
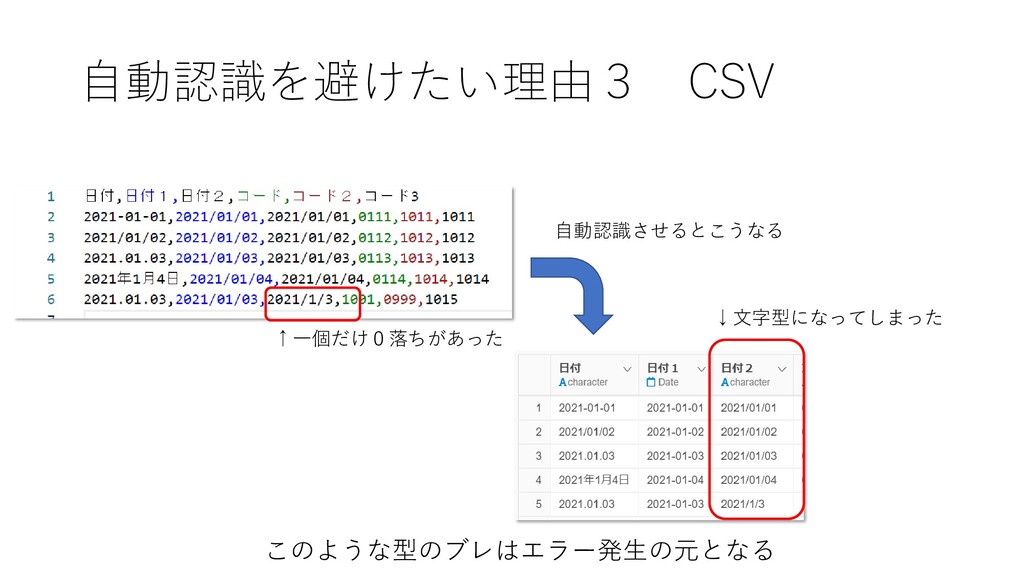
↑一個だけ0落ちがあった 自動認識させるとこうなる ↓文字型になってしまった このような型のブレはエラー発生の元となる 自動認識を避けたい理由3 CSV
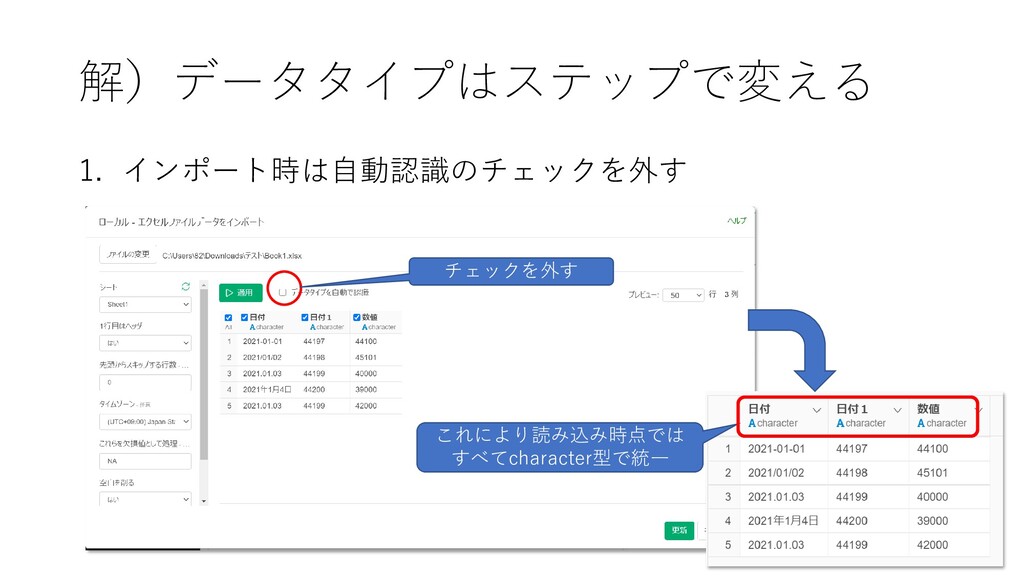
1. インポート時は自動認識のチェックを外す 解)データタイプはステップで変える チェックを外す これにより読み込み時点では すべてcharacter型で統一
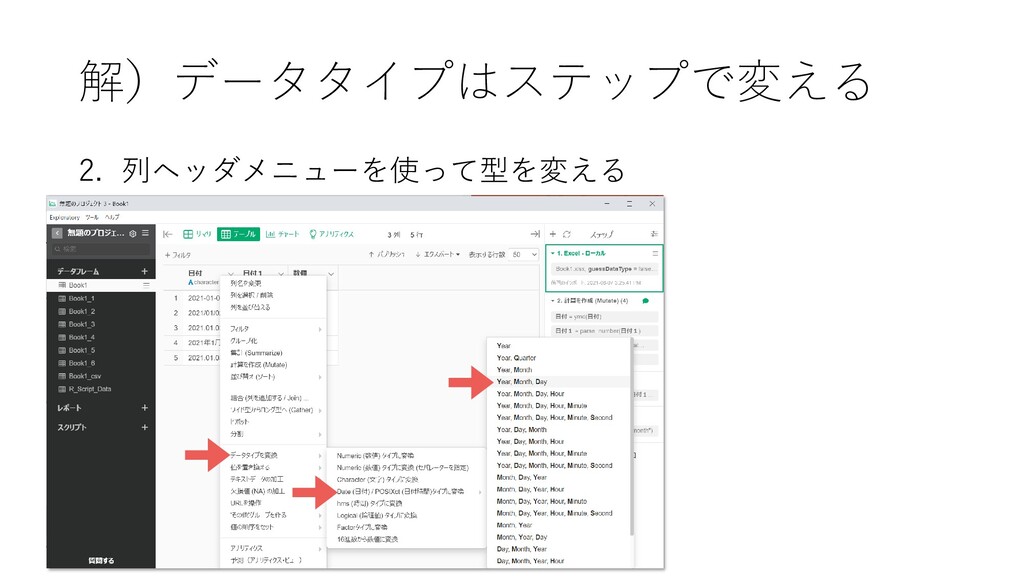
2. 列ヘッダメニューを使って型を変える 解)データタイプはステップで変える
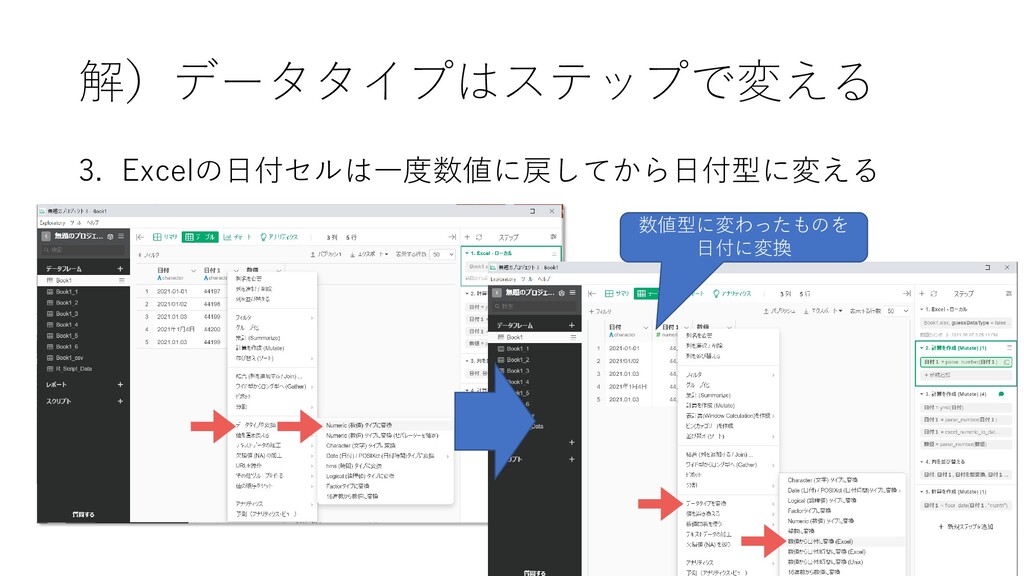
3. Excelの日付セルは一度数値に戻してから日付型に変える 解)データタイプはステップで変える 数値型に変わったものを 日付に変換
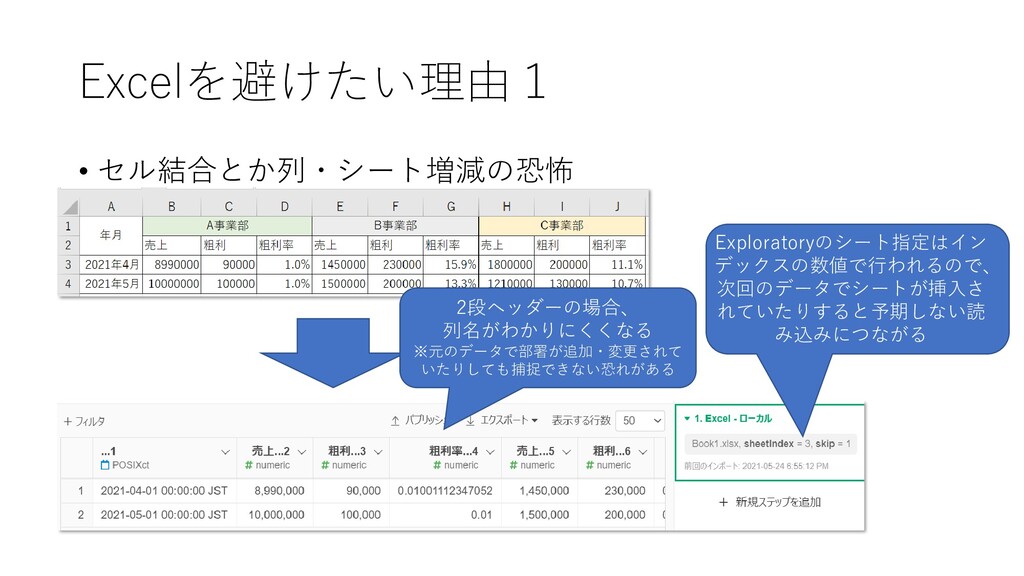
Excelを避けたい理由1 • セル結合とか列・シート増減の恐怖 2段ヘッダーの場合、 列名がわかりにくくなる ※元のデータで部署が追加・変更されて いたりしても捕捉できない恐れがある Exploratoryのシート指定はイン デックスの数値で行われるので、 次回のデータでシートが挿入さ
れていたりすると予期しない読 み込みにつながる
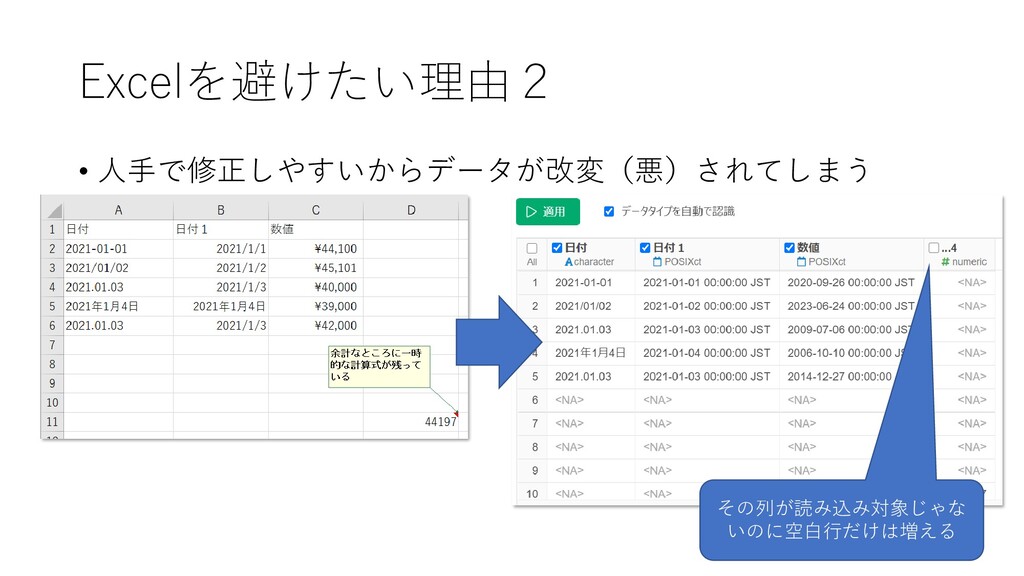
Excelを避けたい理由2 • 人手で修正しやすいからデータが改変(悪)されてしまう その列が読み込み対象じゃな いのに空白行だけは増える
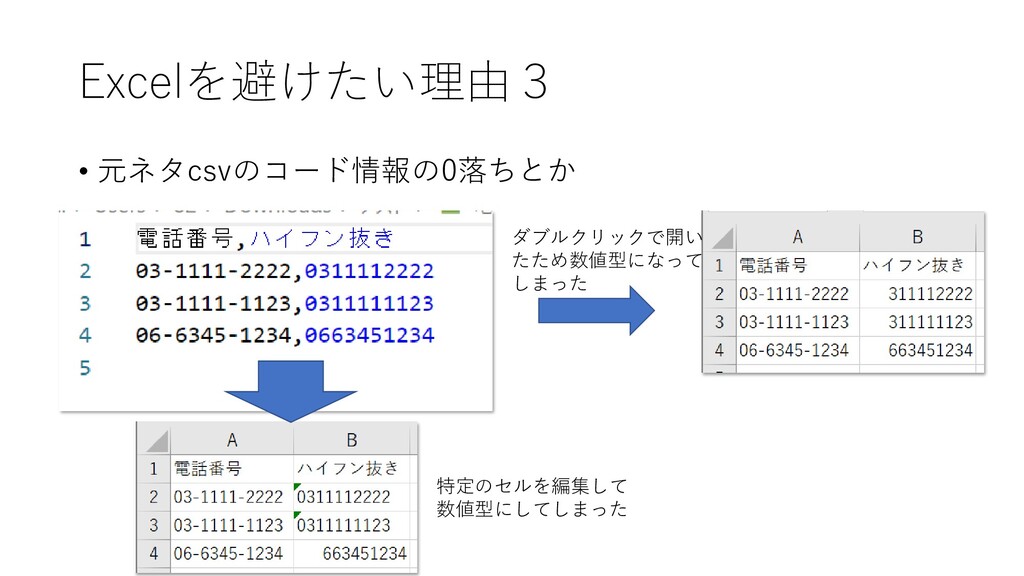
Excelを避けたい理由3 • 元ネタcsvのコード情報の0落ちとか ダブルクリックで開い たため数値型になって しまった 特定のセルを編集して 数値型にしてしまった
Excel自体が悪いわけではない、が… • ソフトウェア自体が悪いわけでは全くありません • 小学生の宿題からデータサイエンス、果てはプログラミングか ら芸術に至るまで幅広く使える素晴らしいツールだと思ってい ます • 使い方というかデータとしての扱い方の問題です
解)Excelの使いどころ • ファクトテーブル(集計対象となる数値データなどが入ってい るもの)はできるだけExcelで扱わない →情報システム等への抽出依頼もできるだけcsvを要求する • データはできるだけロング型にするような文化の醸成 • マスタのような、形が決まっていてあまり変更がないものはメ ンテナンス性のよいExcelもありかもしれません
2.徹底的な工数整理 こまかい改善の繰り返し
ステップを減らす、処理効率を考える • 必ず最初にやること • 型定義 • 列名の変更 • 列の削除 あとからステップを差し込むのは勇気がいるので、このあたりはほぼ
必ず入れておく • 処理効率を考える • グループ化した場合は計算が終わったら必ず解除する • 複数ステップの処理が、スクリプトやカスタムRコマンドで1ステッ プにできる場合はそちらも検討 • データフレームをエクスポートして使う場合のTips
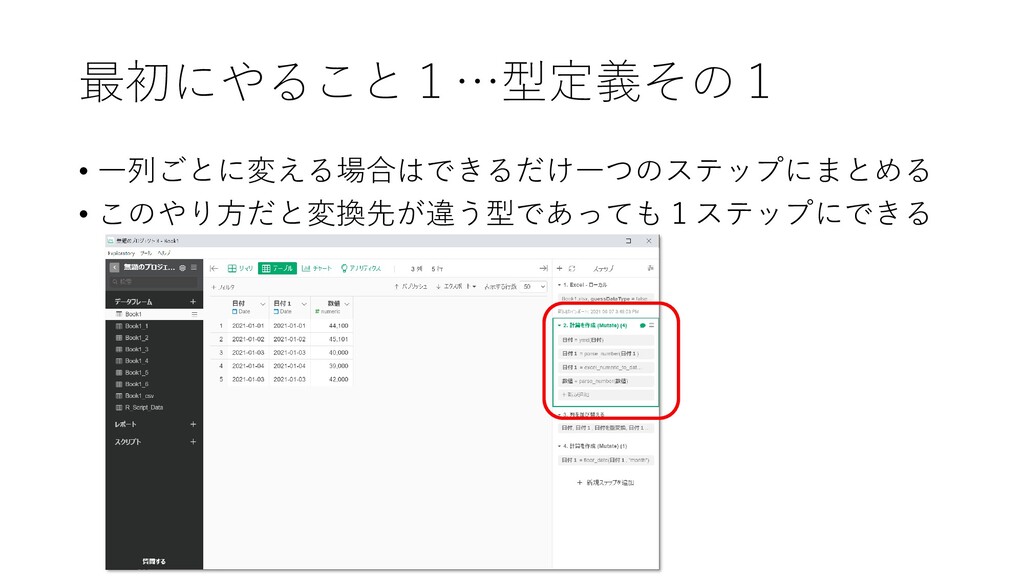
最初にやること1…型定義その1 • 一列ごとに変える場合はできるだけ一つのステップにまとめる • このやり方だと変換先が違う型であっても1ステップにできる
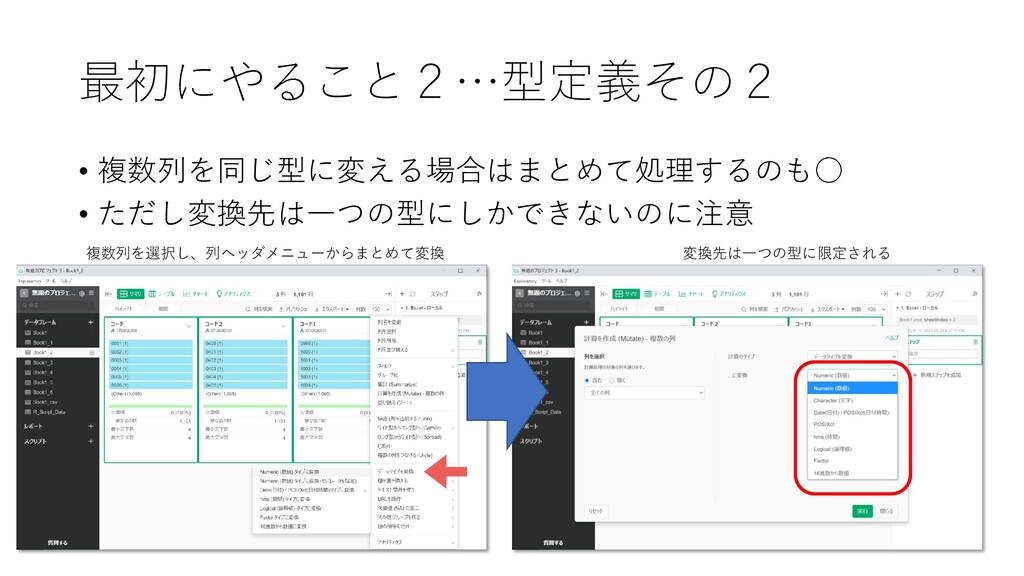
最初にやること2…型定義その2 • 複数列を同じ型に変える場合はまとめて処理するのも◦ • ただし変換先は一つの型にしかできないのに注意 複数列を選択し、列ヘッダメニューからまとめて変換 変換先は一つの型に限定される
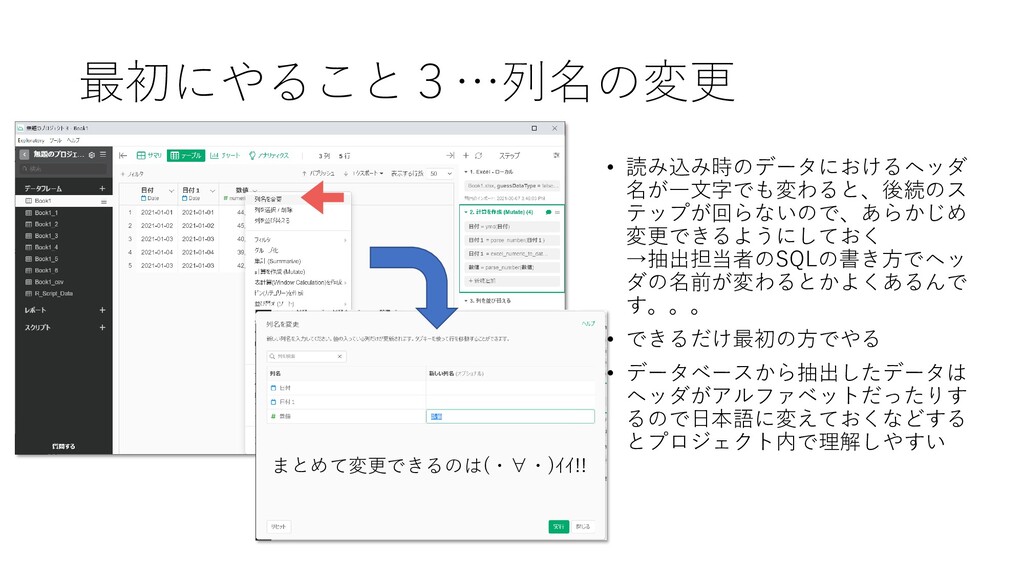
最初にやること3…列名の変更 • 読み込み時のデータにおけるヘッダ 名が一文字でも変わると、後続のス テップが回らないので、あらかじめ 変更できるようにしておく →抽出担当者のSQLの書き方でヘッ ダの名前が変わるとかよくあるんで す。。。 •
できるだけ最初の方でやる • データベースから抽出したデータは ヘッダがアルファベットだったりす るので日本語に変えておくなどする とプロジェクト内で理解しやすい まとめて変更できるのは(・∀・)イイ!!
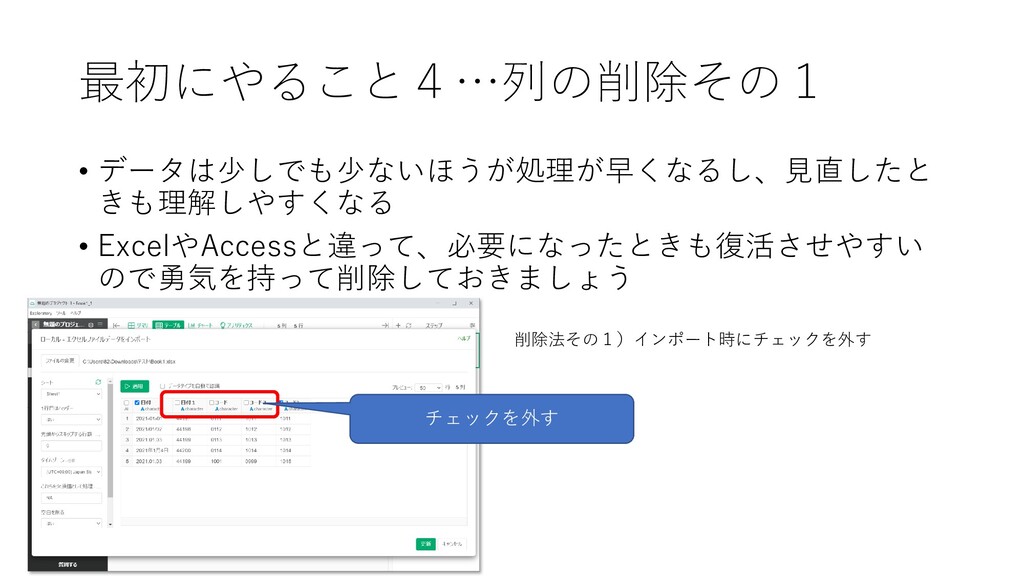
最初にやること4…列の削除その1 • データは少しでも少ないほうが処理が早くなるし、見直したと きも理解しやすくなる • ExcelやAccessと違って、必要になったときも復活させやすい ので勇気を持って削除しておきましょう 削除法その1)インポート時にチェックを外す チェックを外す
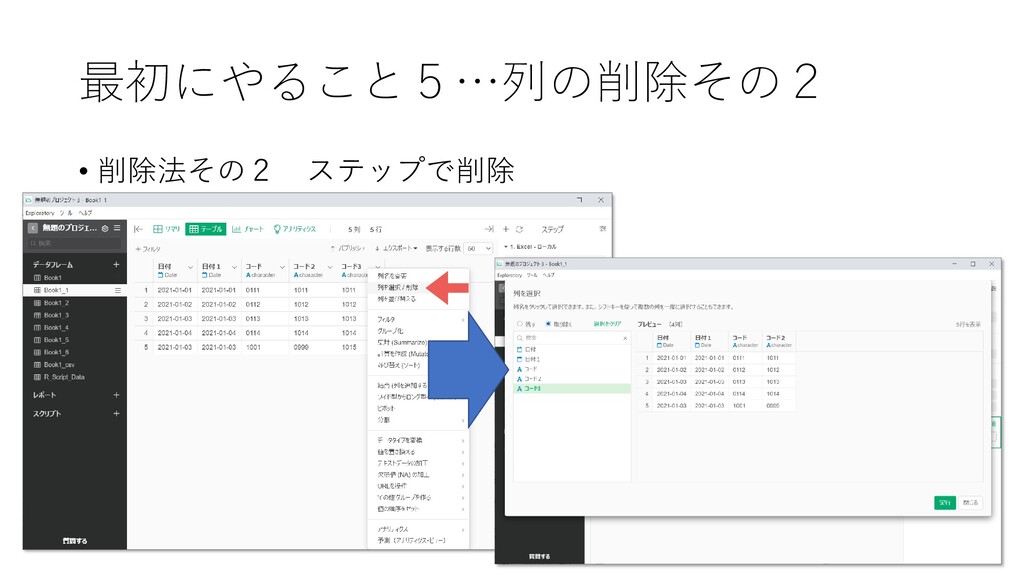
最初にやること5…列の削除その2 • 削除法その2 ステップで削除
「インポート時の削除」or ステップで「残す」「取り除く」 • 事業環境等の変化により元データのカラムが増えるなどがあり 得る • ステップの「取り除く」でやっておくと、このときの変化を捕 捉しやすい(新しく増えたカラムが処理の中に割り込んでくる ため) •
逆にもう完全な定型作業で他の活用はないことがわかっている なら、インポート時の削除やステップの「残す」を使ったほう がエラーにならないという考え方もある
処理の効率化 • グループ化した場合、その計算が終わったら必ずグループを解除す る • グループ化はわりと重い処理だと思う • 複数ステップで実現できることがスクリプトやカスタムRコマンド により1ステップにできるならそちらも検討 •
最近のお気に入りは複数の「値」列を一気にピボットできる、 tidyr::pivot_wider https://speakerdeck.com/yutannihilation/tidy • データフレームをエクスポートして別のところで使う場合、最後に もう一度型定義や列名を調整しアウトプットの一貫性を保つ • 小数の桁数調整 • 利用するシステムに合わせて列名をアルファベット表記に変えるなど
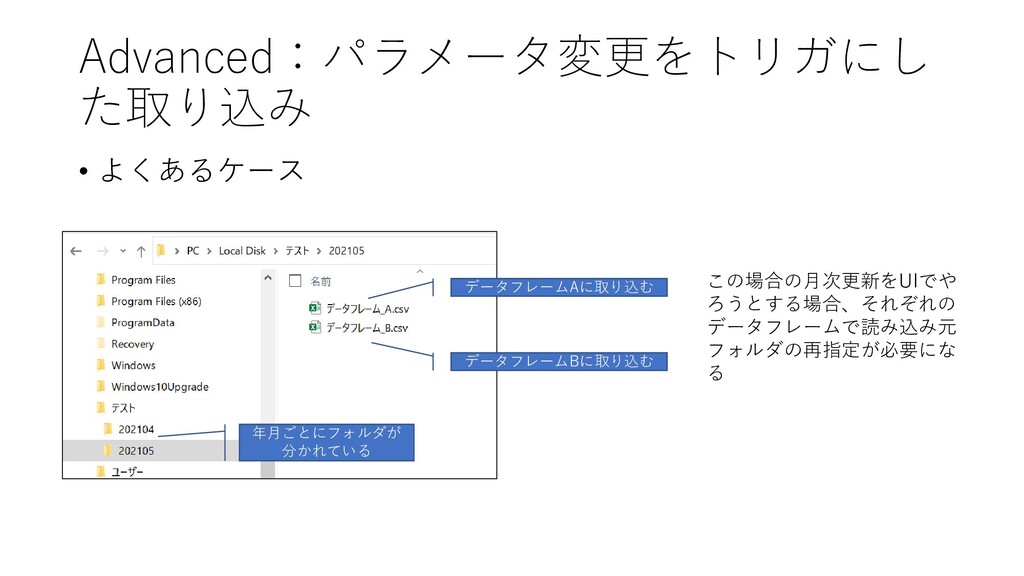
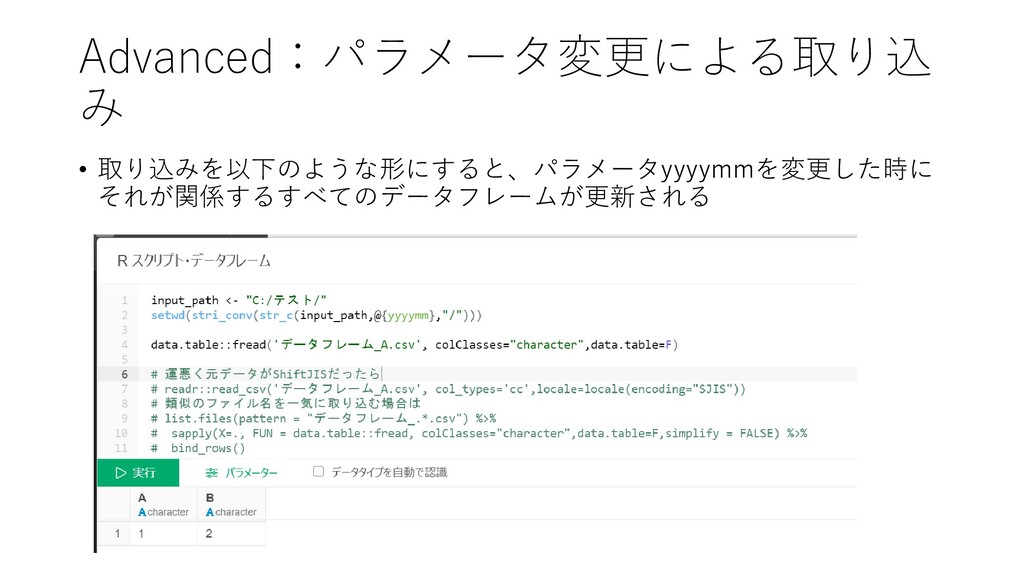
• よくあるケース Advanced:パラメータ変更をトリガにし た取り込み データフレームAに取り込む データフレームBに取り込む 年月ごとにフォルダが 分かれている この場合の月次更新をUIでや ろうとする場合、それぞれの
データフレームで読み込み元 フォルダの再指定が必要にな る
Advanced:パラメータ変更による取り込 み • 取り込みを以下のような形にすると、パラメータyyyymmを変更した時に それが関係するすべてのデータフレームが更新される
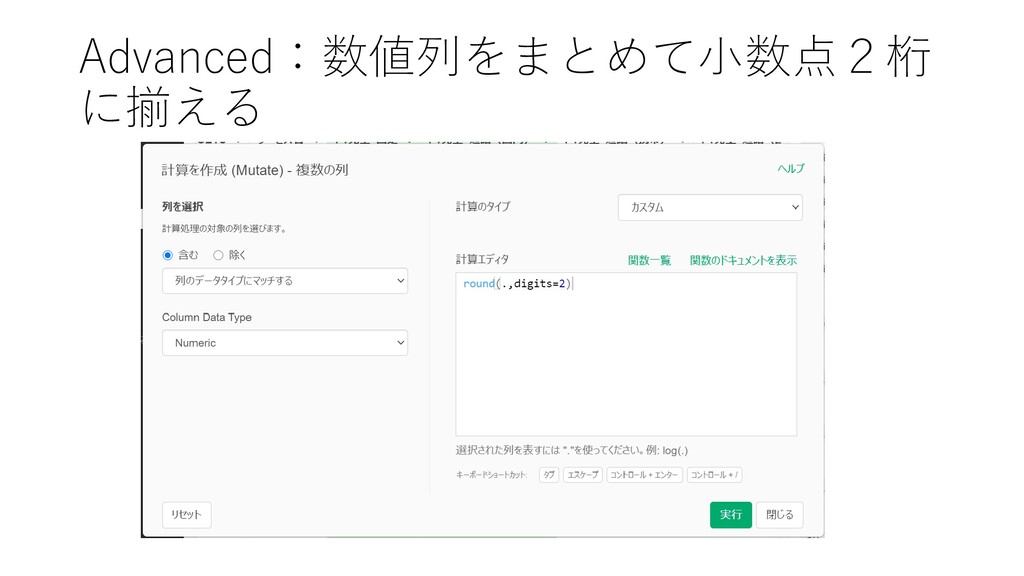
Advanced:数値列をまとめて小数点2桁 に揃える
3.可読性と気付きの仕掛け 1ヶ月後の自分は別人だと思って、わかりやすく整理する
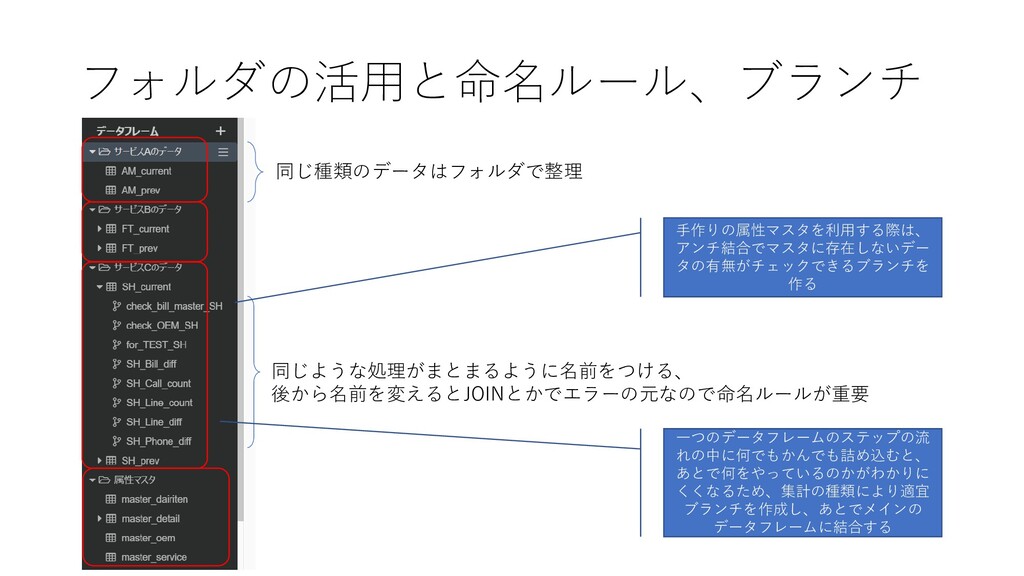
フォルダの活用と命名ルール、ブランチ 同じ種類のデータはフォルダで整理 同じような処理がまとまるように名前をつける、 後から名前を変えるとJOINとかでエラーの元なので命名ルールが重要 手作りの属性マスタを利用する際は、 アンチ結合でマスタに存在しないデー タの有無がチェックできるブランチを 作る 一つのデータフレームのステップの流 れの中に何でもかんでも詰め込むと、
あとで何をやっているのかがわかりに くくなるため、集計の種類により適宜 ブランチを作成し、あとでメインの データフレームに結合する
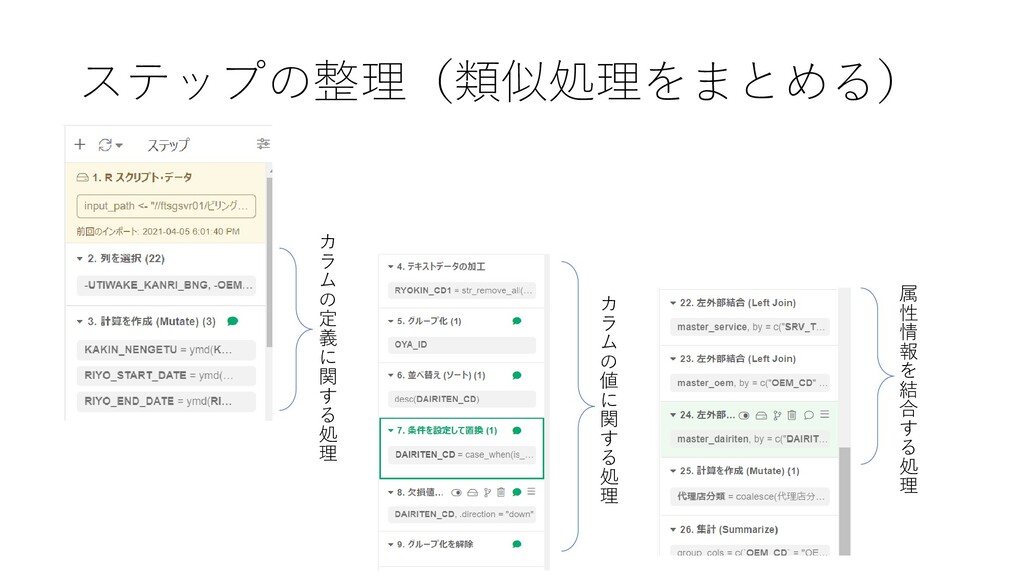
ステップの整理(類似処理をまとめる) カ ラ ム の 定 義 に 関 す
る 処 理 カ ラ ム の 値 に 関 す る 処 理 属 性 情 報 を 結 合 す る 処 理
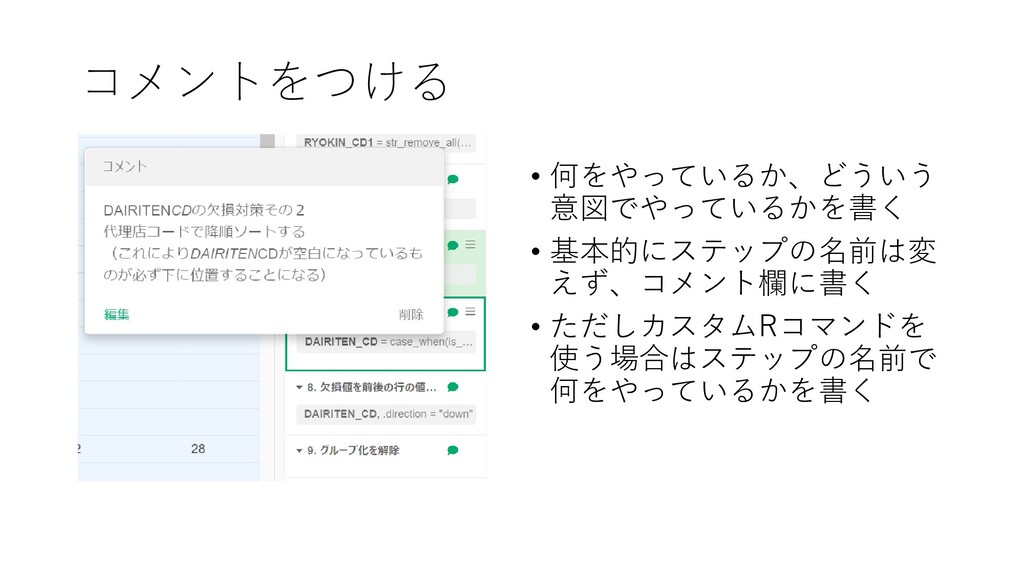
コメントをつける • 何をやっているか、どういう 意図でやっているかを書く • 基本的にステップの名前は変 えず、コメント欄に書く • ただしカスタムRコマンドを 使う場合はステップの名前で
何をやっているかを書く
4.アップデートへの対応 • 方法の再現性はアップデートで崩れてしまう場合もある • しかし機能向上による生産性向上はぜひ取り入れたい • 個人的に「条件を設定して置換」のUI化はツボ • Exploratory Hourやオンラインセミナーでキャッチアップを!
• データカタログが用意されている場合はハンズオン的に取り組んでみ るとさらに効果的
まとめ 1. 定期的な運用に落とし込むというのは、究極的にはゼロオペレー ションを目指すということ →リロード一発、それ以外は何もしなくても終わらせる、ぐらい の「めんどくさい」の感性が大事 2. 一度できたら完成、ではなくそこからの(エンドレスな)改善 →結果として、見やすく、わかりやすく、エラーが起きにくいロ バストな仕組みになっていく
3. ラングリングにおける後顧の憂いをなくすことで前(分析)を向 いて進むことに集中できる →考え、作る、そのための時間を創造する一助になれば幸いです
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}