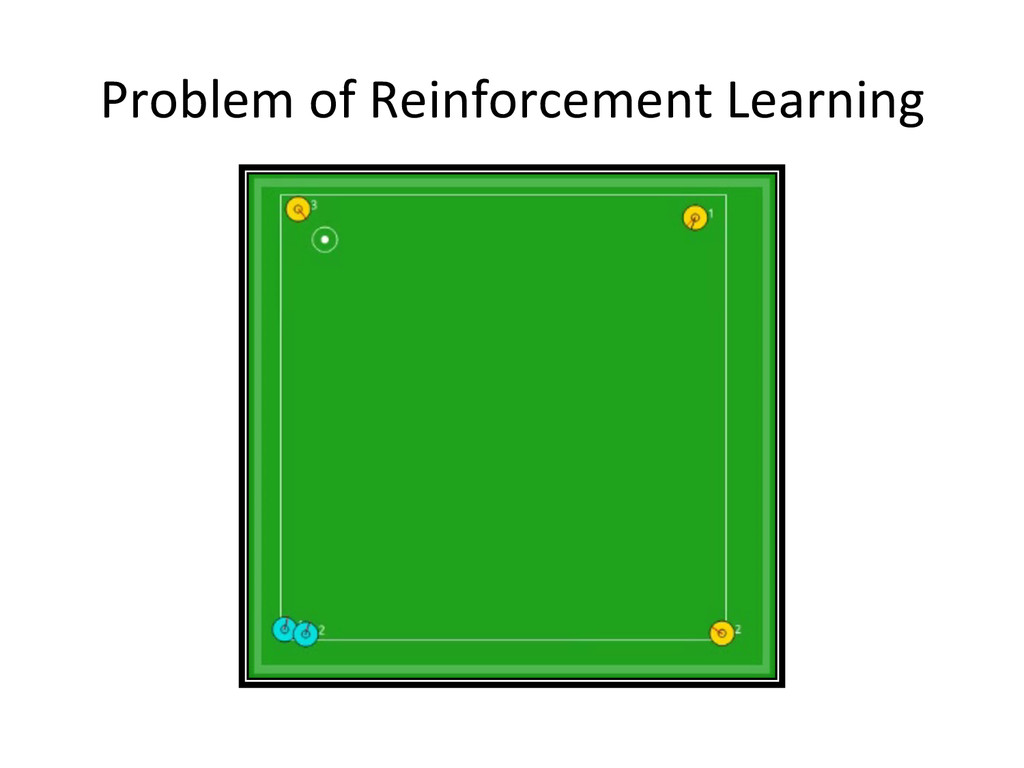
People use different methods to make decisions. “Trial and error”, for instance, is widely used by people to learn the best decisions from experiences. Also, arguing with other people, or even self-arguing, could help people to identify advantages and disadvantages of each choice. In this talk, I will introduce how these two techniques can be used jointly to help computers (autonomous agents) to make decisions.
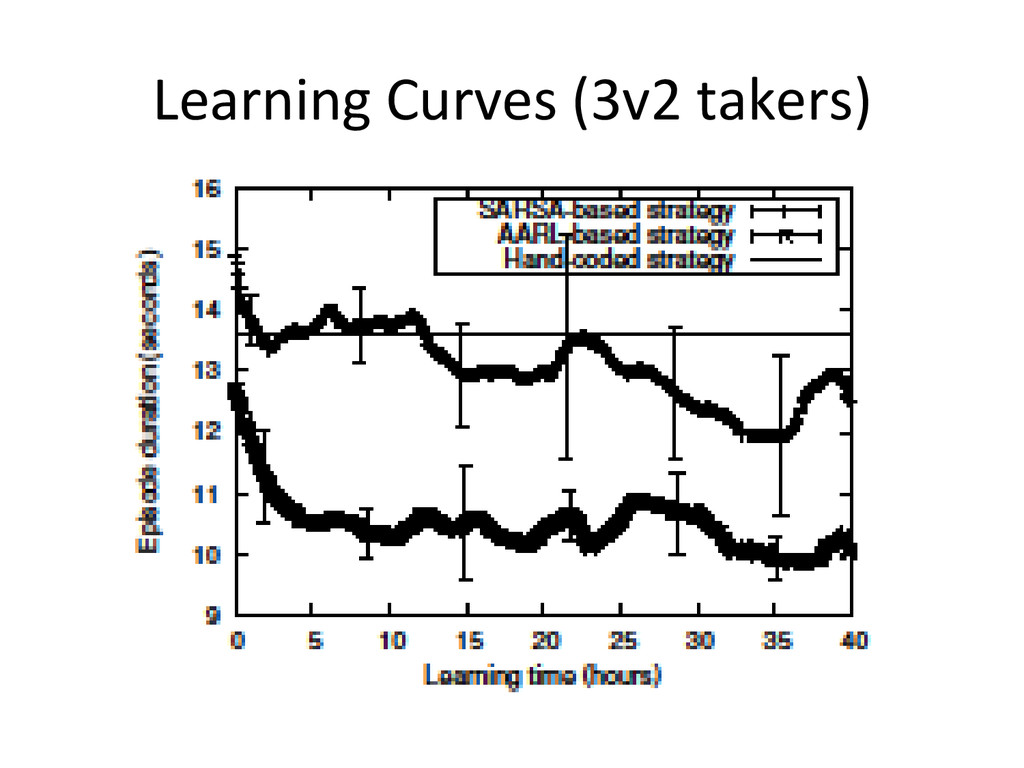
First I will motivate my research, followed by a high-level description of our integration technique. Also, I will compare the performances of my technique and standard Reinforcement Learning on RoboCup Soccer games, under both single-agent and multi-agent settings. Potential application domains and future work will also be briefly discussed. Videos and concrete examples will be running throughout this talk to instantiate my ideas and techniques.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
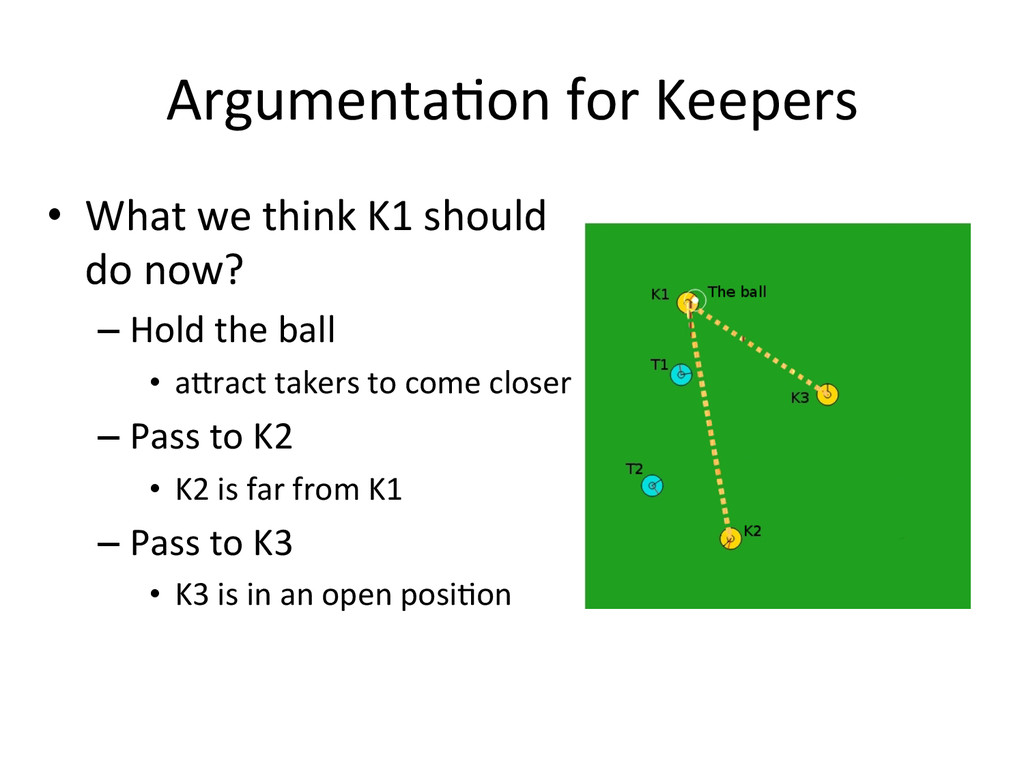
{kind=link}
{kind=link}
{kind=link}
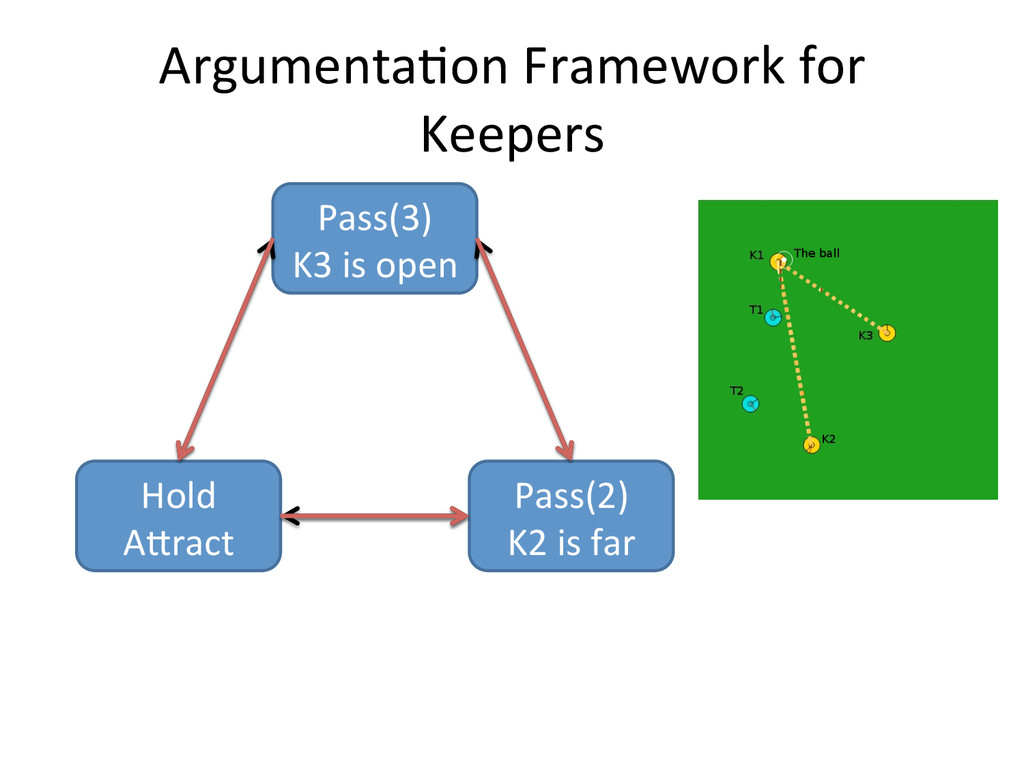
{kind=link}
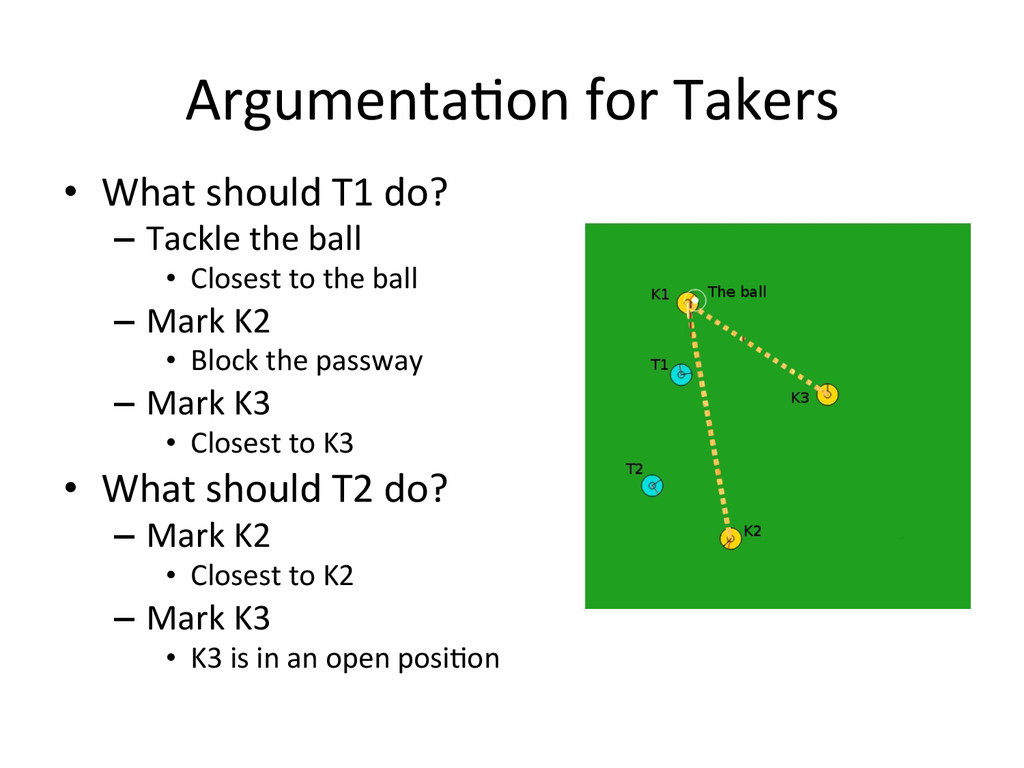
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Reference [1] P. Stone et al., ‘Reinforcement learning for robocup](https://files.speakerdeck.com/presentations/dae0d9c0abcd0131cef36ad81164bb43/slide_21.jpg){kind=link}
{kind=link}