GPUs Assemble Data from Disparate Sources Multi-Site, Hybrid-Cloud, Multi-Cloud Agility Efficiently Move Data to GPU Resources Automate Pipelines and Workflows Simplify Data Governance and Security Hammerspace Global Data Platform Hyperscale NAS Architecture Data-in-Place Assimilation Global File System Data Orchestration Programmable Metadata Advanced Data Services Deep Learning Generative AI Scientific Computing Video and Image Rendering Data Analytics LLM Training
in 2023 January: Added support for data on tape February: Unveiled Hyperscale NAS Architecture March: Meta publishes details on their use of Hammerspace as part of their Gen AI architecture April: Introduced erasure coding June: GPU Data Orchestration for S3 Applications
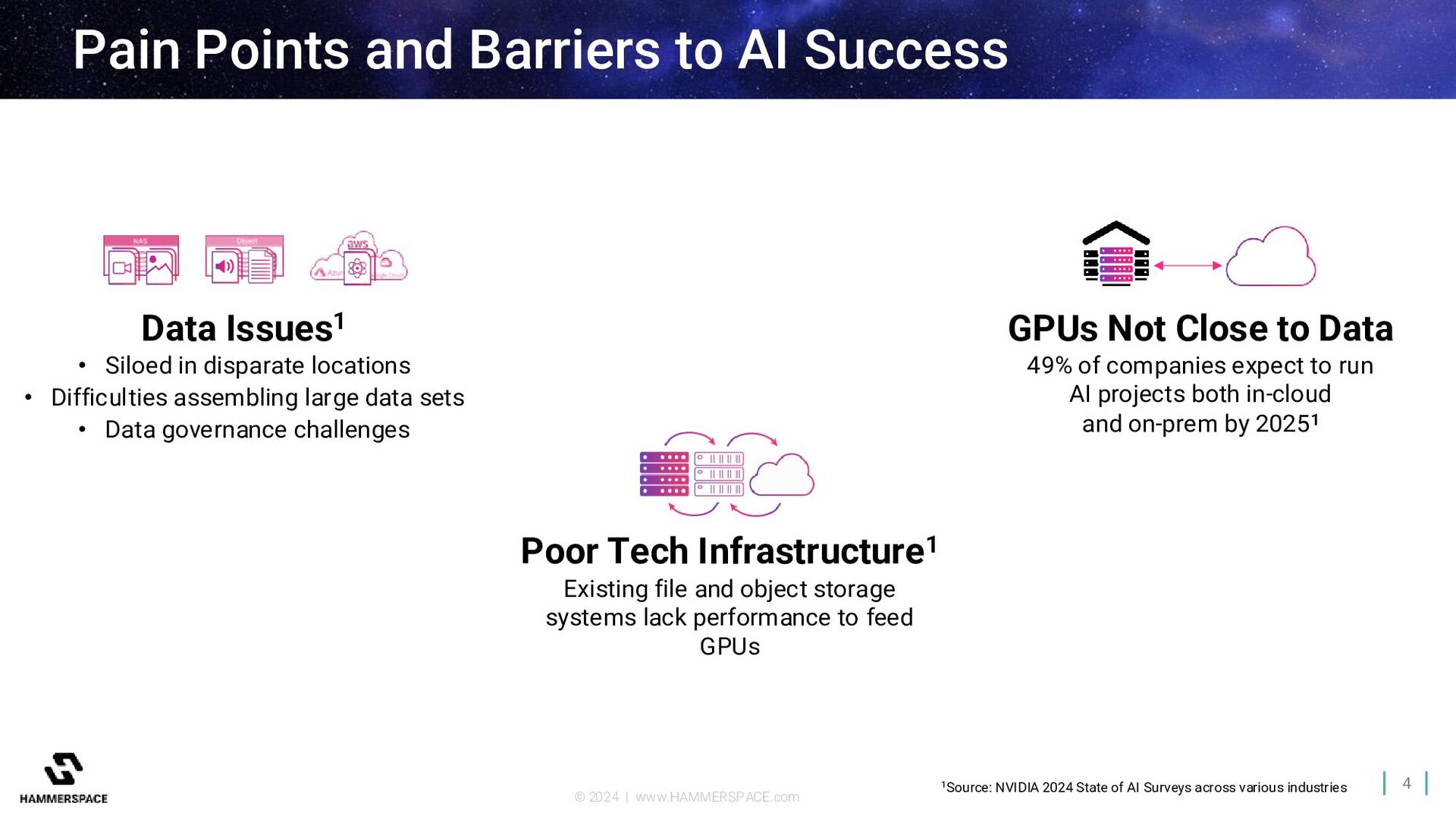
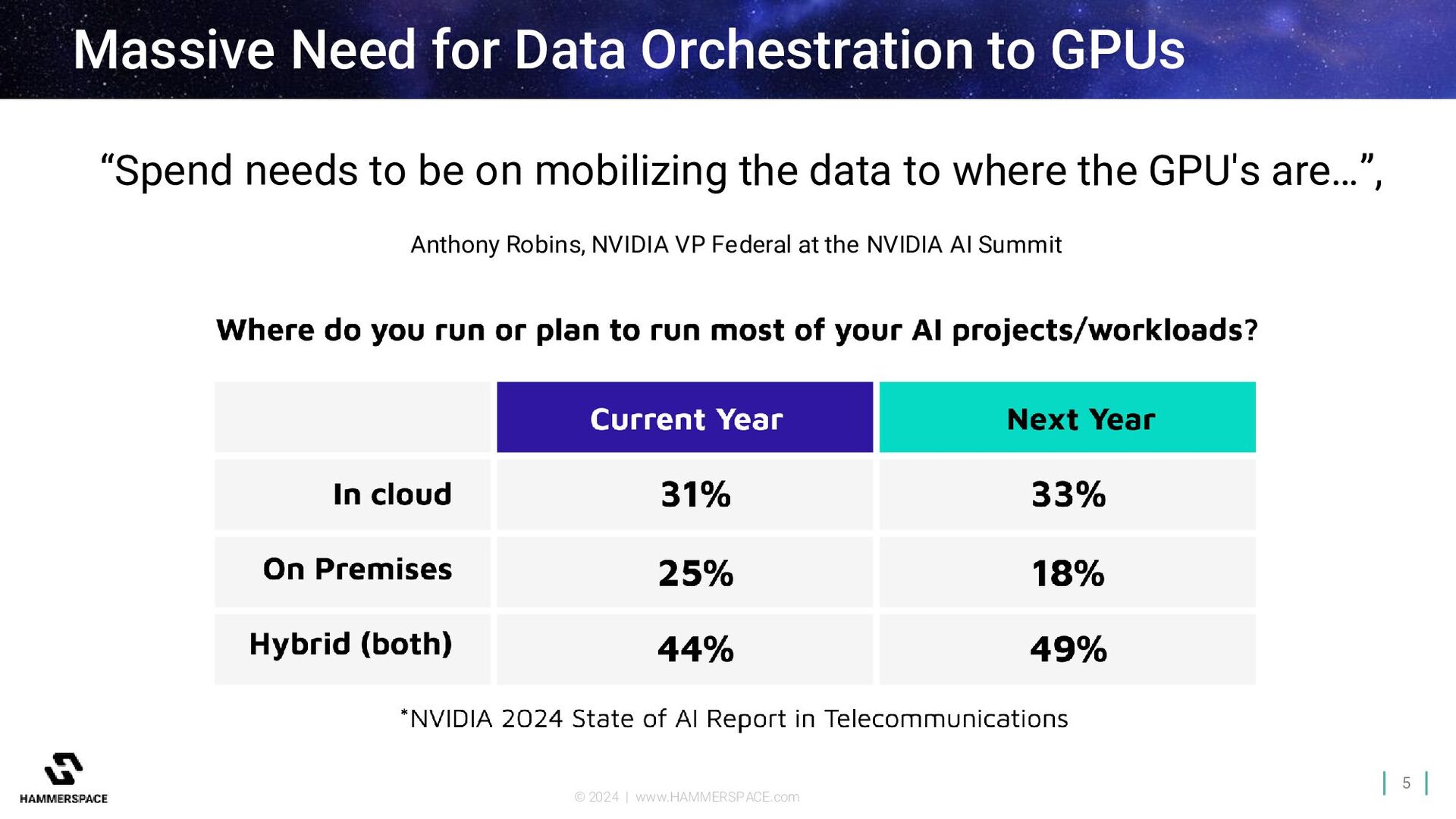
AI Success Data Issues1 • Siloed in disparate locations • Difficulties assembling large data sets • Data governance challenges 1Source: NVIDIA 2024 State of AI Surveys across various industries Poor Tech Infrastructure1 Existing file and object storage systems lack performance to feed GPUs GPUs Not Close to Data 49% of companies expect to run AI projects both in-cloud and on-prem by 20251
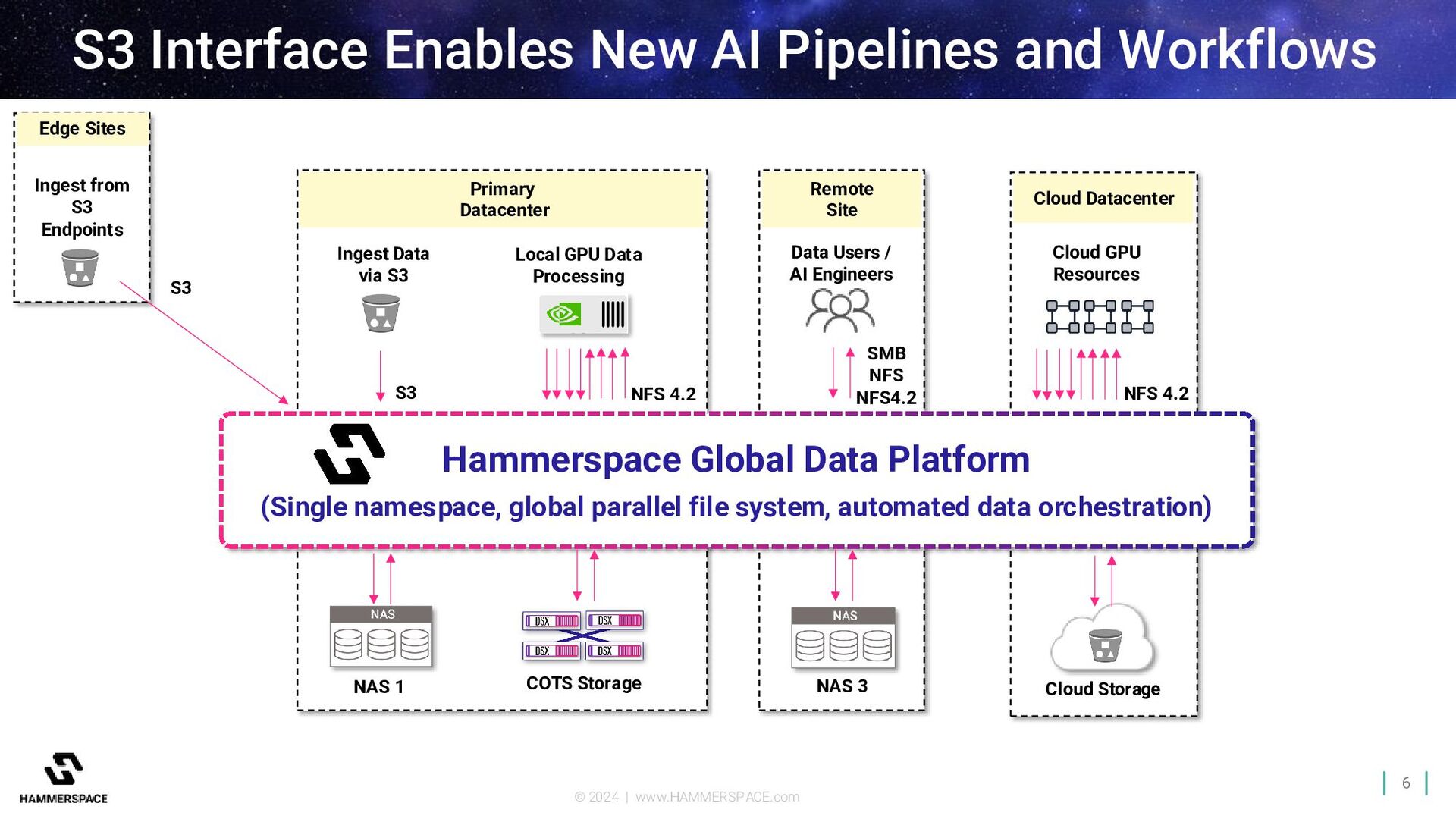
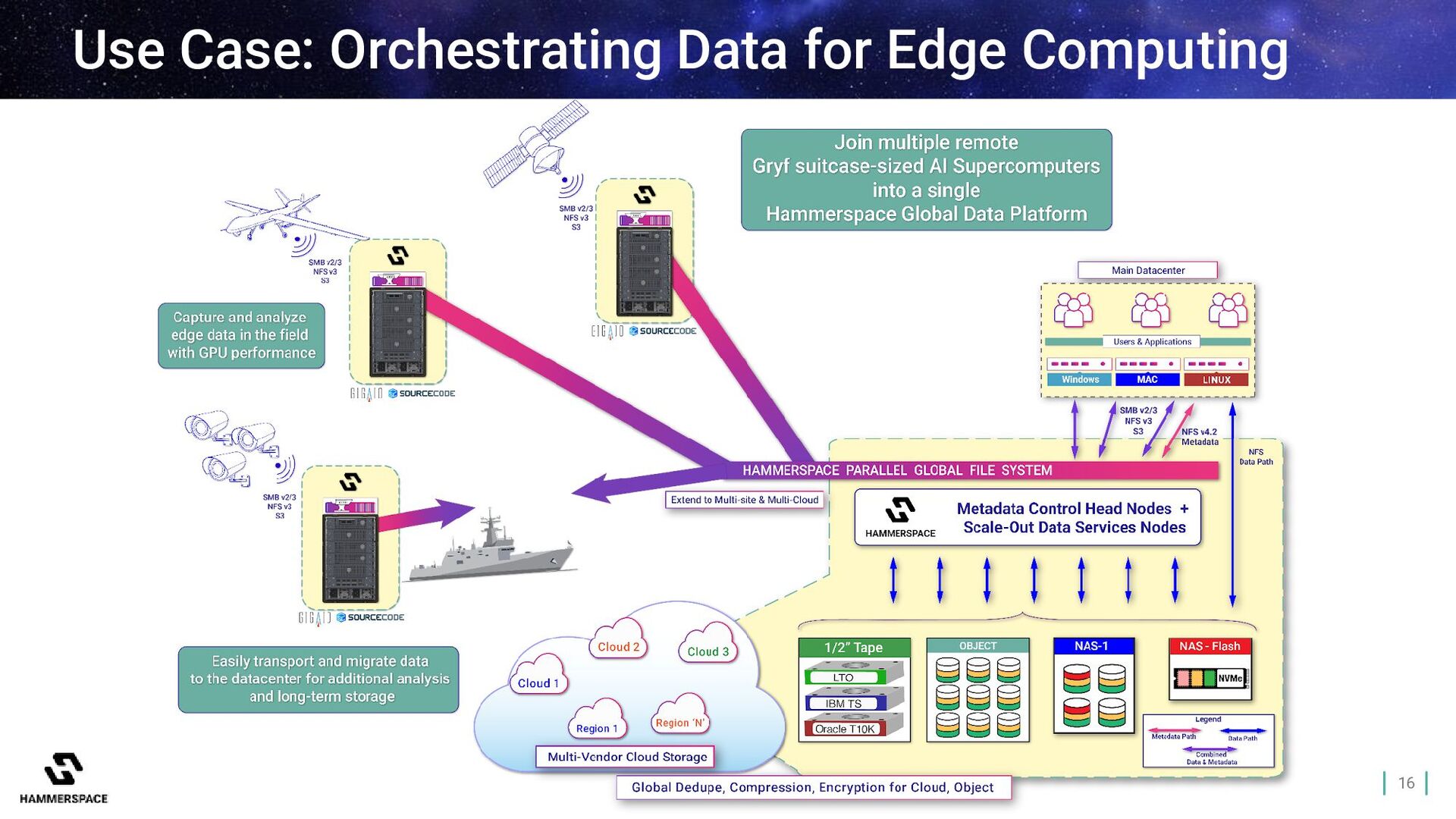
Pipelines and Workflows Primary Datacenter Hammerspace Global Data Platform (Single namespace, global parallel file system, automated data orchestration) Ingest Data via S3 S3 Remote Site Data Users / AI Engineers SMB NFS NFS4.2 NAS 1 COTS Storage Cloud Storage NAS 3 NFS 4.2 Local GPU Data Processing Cloud Datacenter Cloud GPU Resources NFS 4.2 Ingest from S3 Endpoints S3 Edge Sites
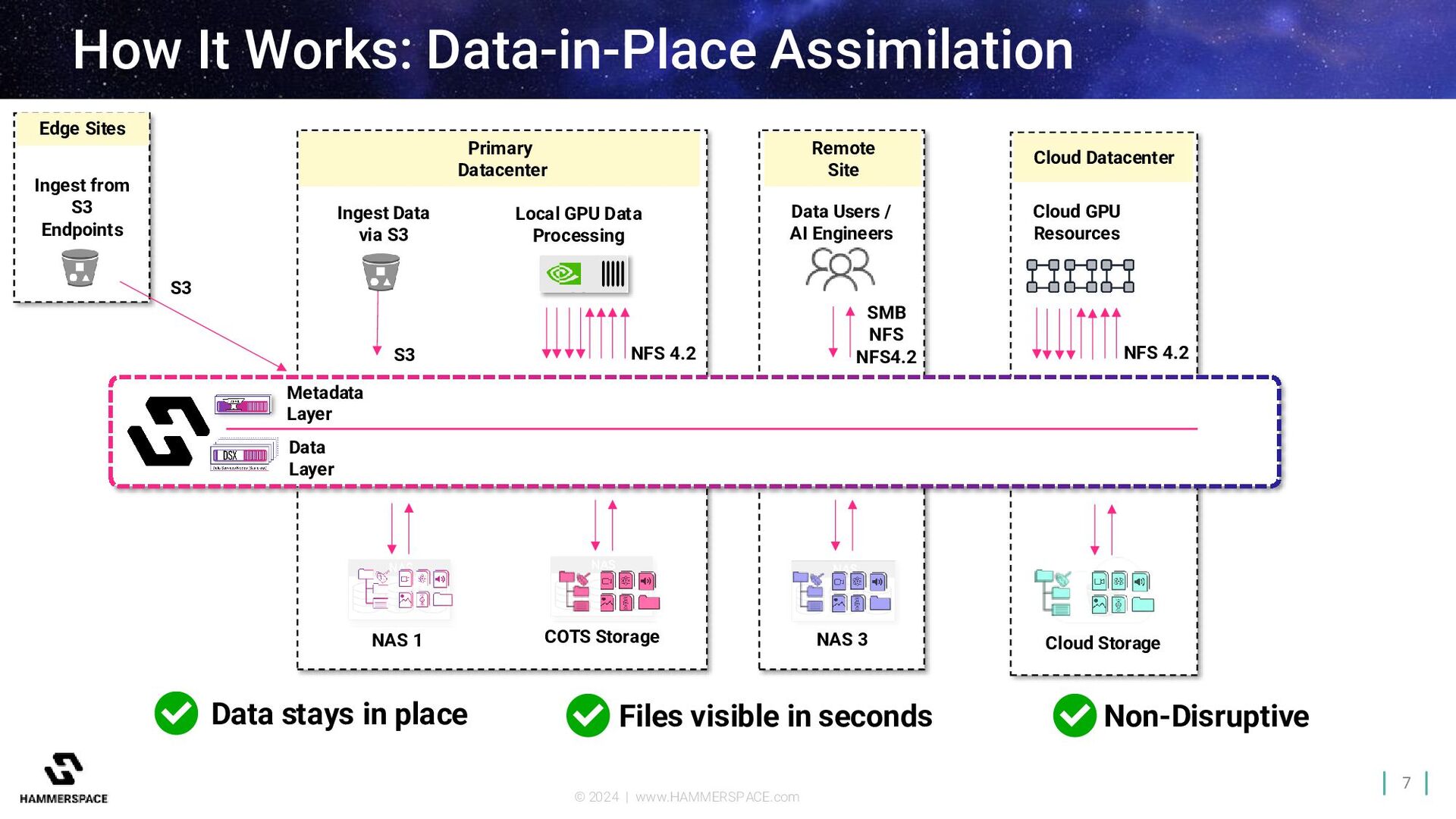
S3 S3 Remote Site Data Users / AI Engineers SMB NFS NFS4.2 NFS 4.2 Local GPU Data Processing Cloud Datacenter Cloud GPU Resources NFS 4.2 How It Works: Data-in-Place Assimilation NAS 1 Cloud Storage NAS 3 Metadata Layer Data Layer Data stays in place Files visible in seconds Non-Disruptive COTS Storage Ingest from S3 Endpoints S3 Edge Sites
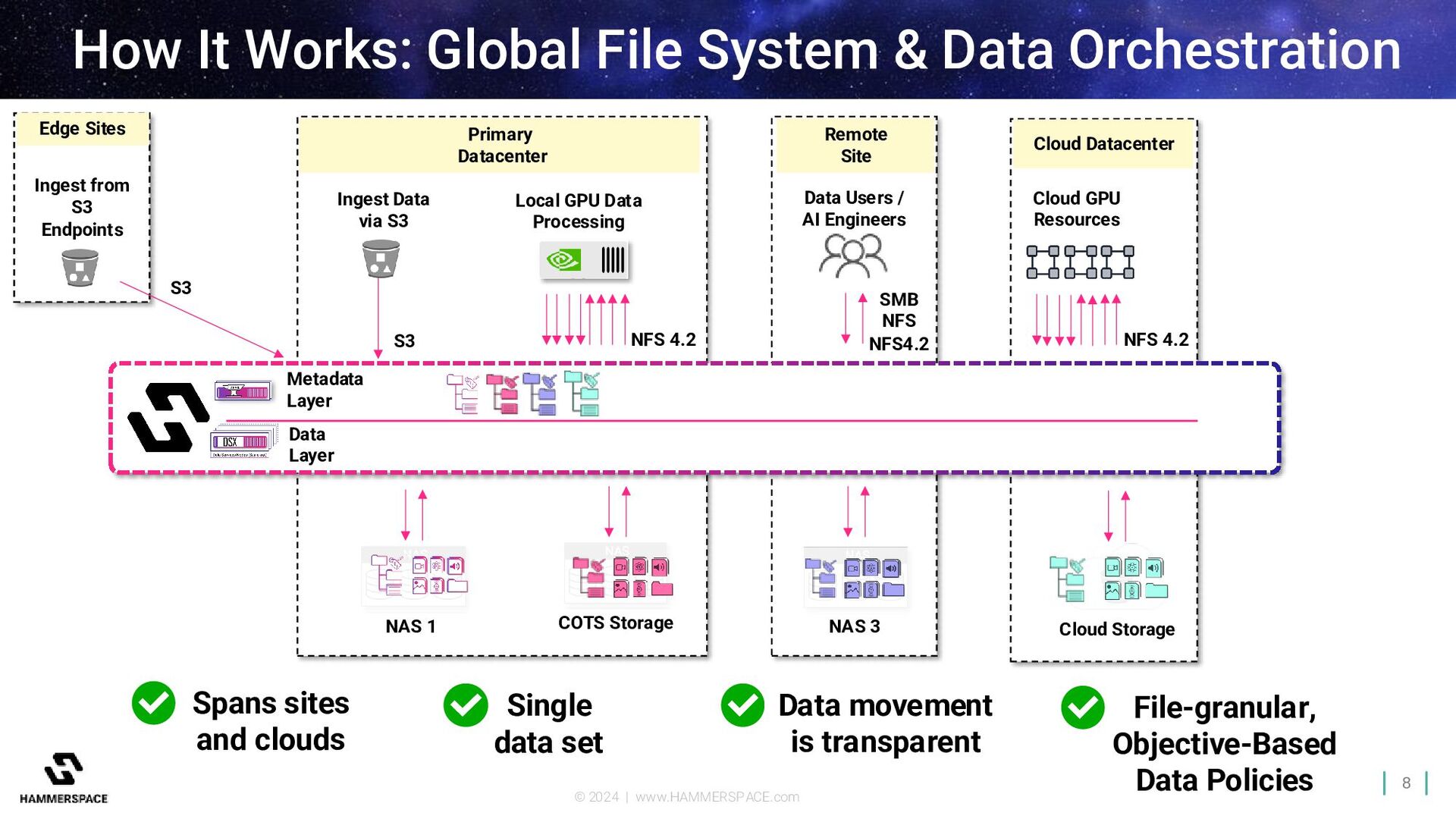
S3 S3 Remote Site Data Users / AI Engineers SMB NFS NFS4.2 NFS 4.2 Local GPU Data Processing Cloud Datacenter Cloud GPU Resources NFS 4.2 Metadata Layer Data Layer How It Works: Global File System & Data Orchestration NAS 1 Cloud Storage NAS 3 Spans sites and clouds Data movement is transparent File-granular, Objective-Based Data Policies Single data set COTS Storage Ingest from S3 Endpoints S3 Edge Sites
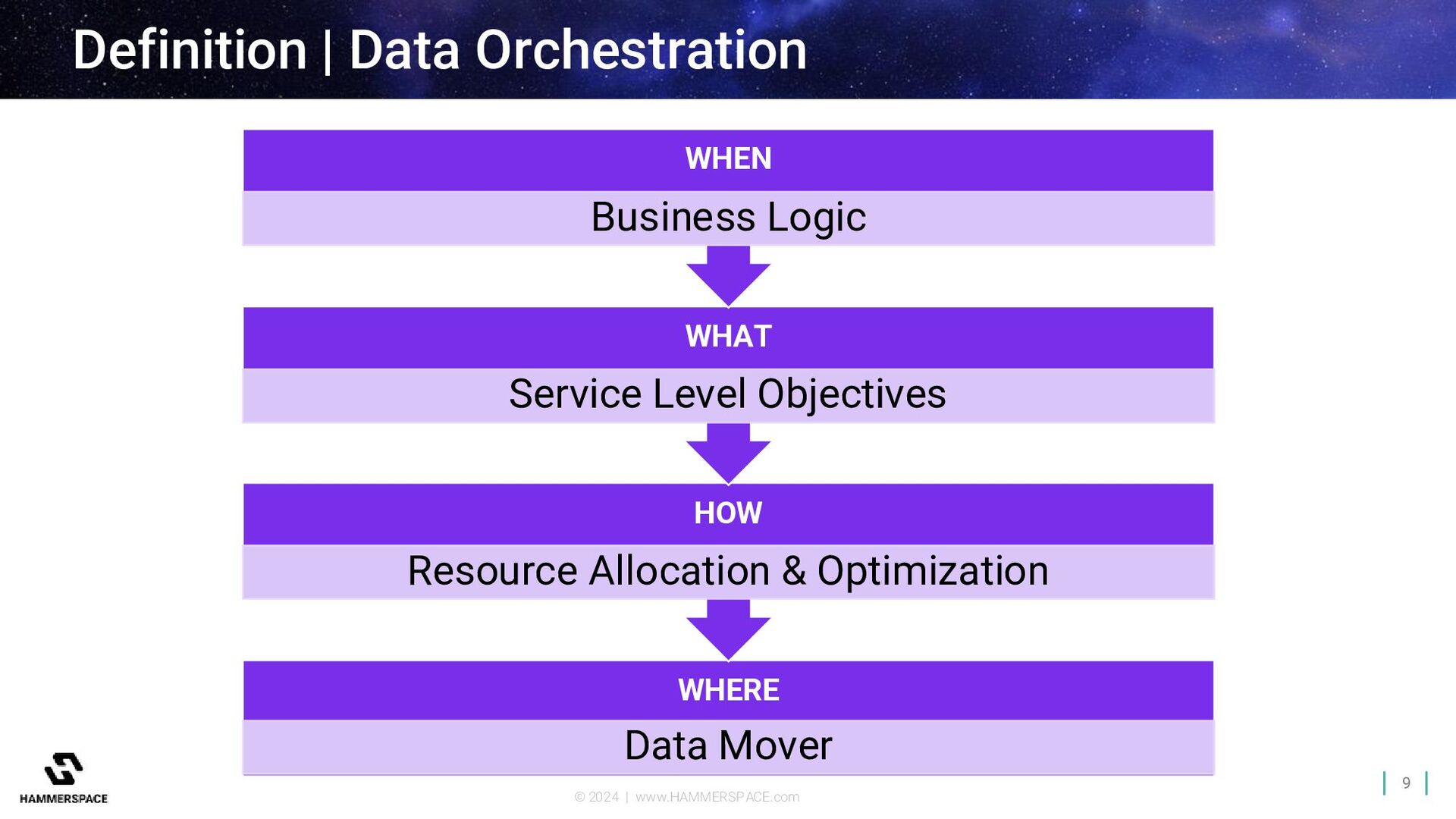
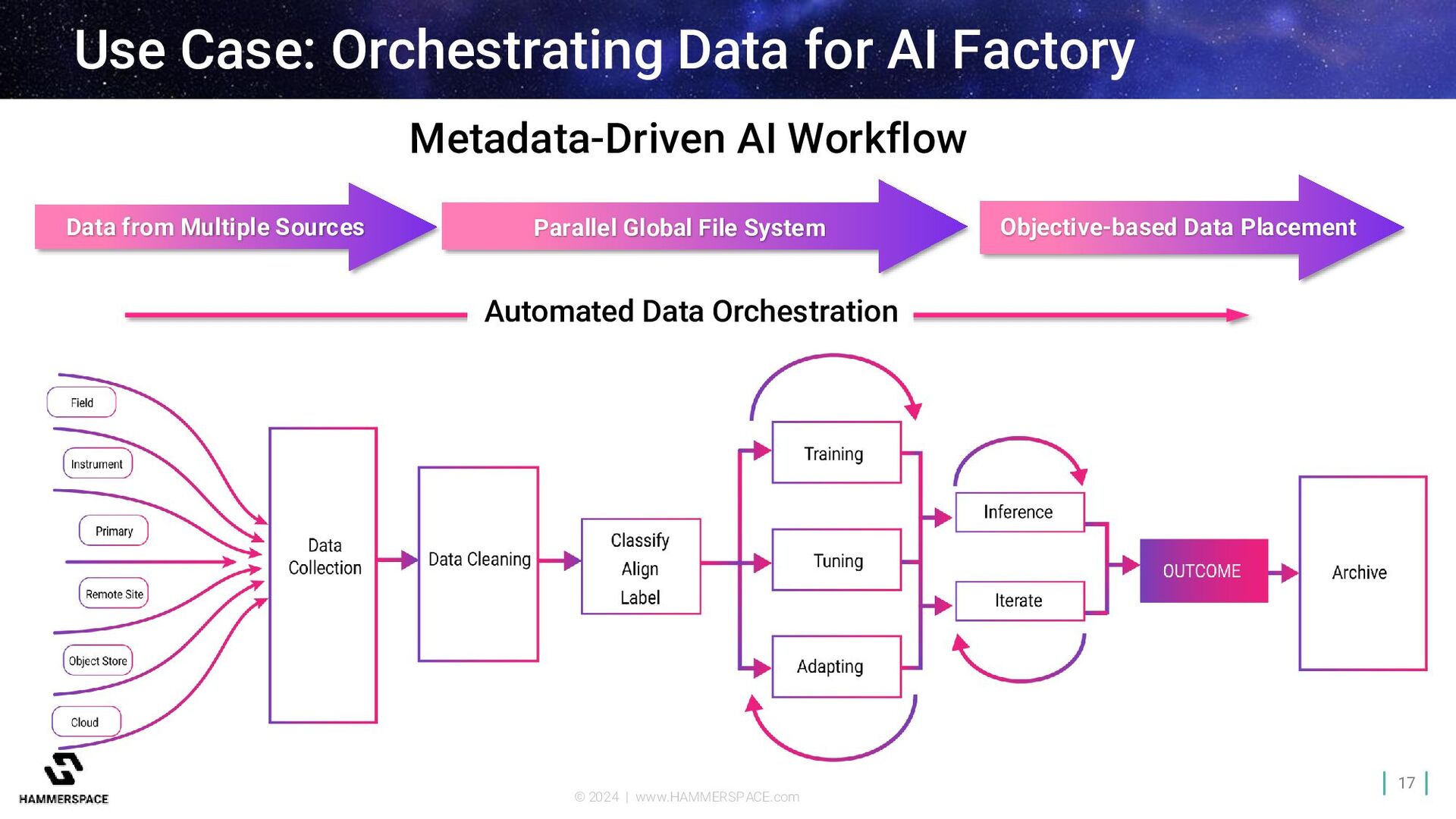
AI Factory Data from Multiple Sources Parallel Global File System Metadata-Driven AI Workflow Objective-based Data Placement Automated Data Orchestration
• Market Perspective • Many customers have developed applications that use S3 interface • Estimated 100+ Exabytes of data created and stored with S3 today (100 trillions+ objects with estimate file size of 1MB) • Pricing • No added cost, part of standard license • Availability • Early access – customers are already using today • Late 2024 – GA Release
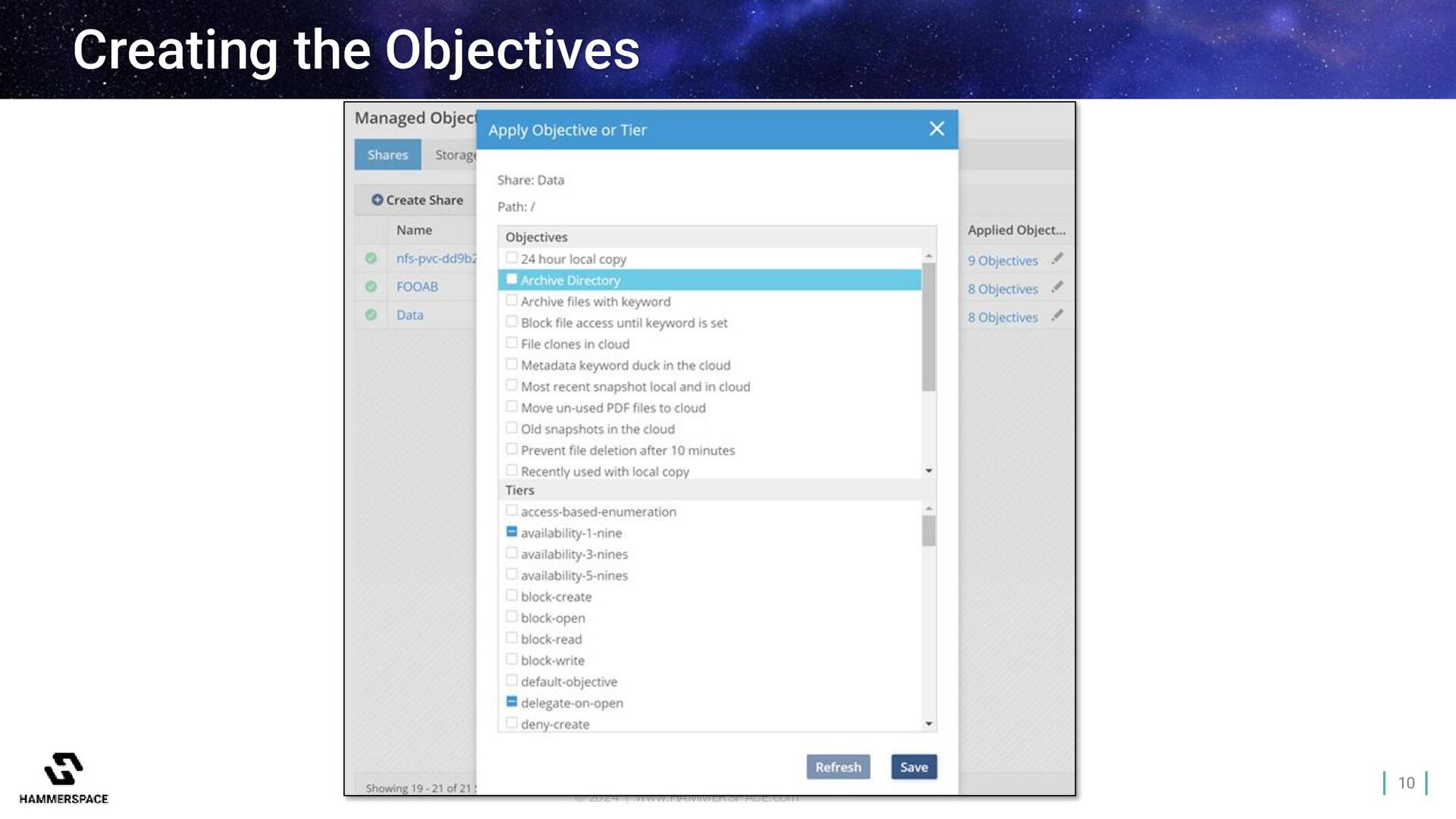
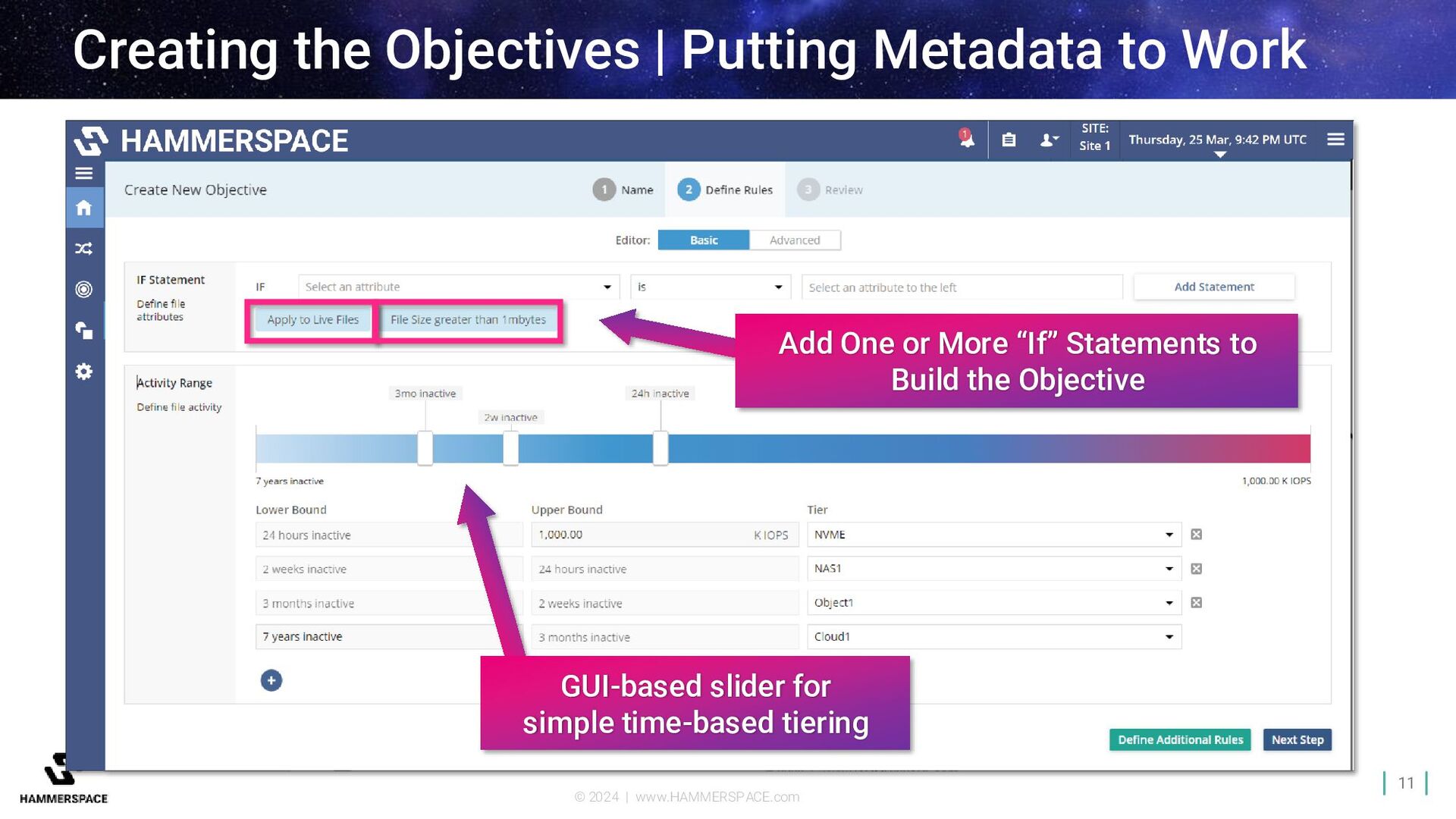
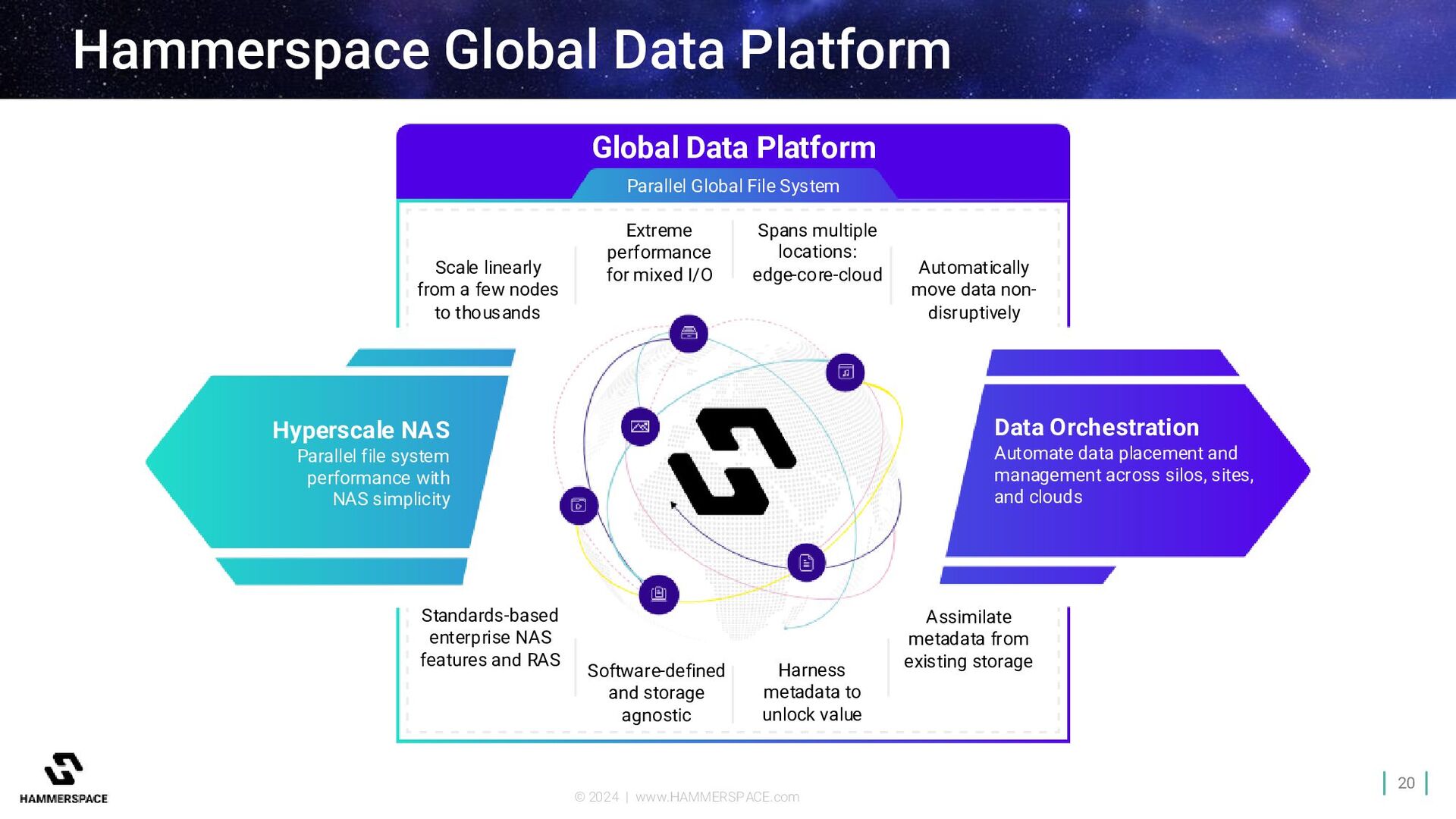
Data Platform Parallel Global File System Scale linearly from a few nodes to thousands Extreme performance for mixed I/O Spans multiple locations: edge-core-cloud Automatically move data non- disruptively Standards-based enterprise NAS features and RAS Assimilate metadata from existing storage Software-defined and storage agnostic Harness metadata to unlock value Data Orchestration Automate data placement and management across silos, sites, and clouds Hyperscale NAS Parallel file system performance with NAS simplicity
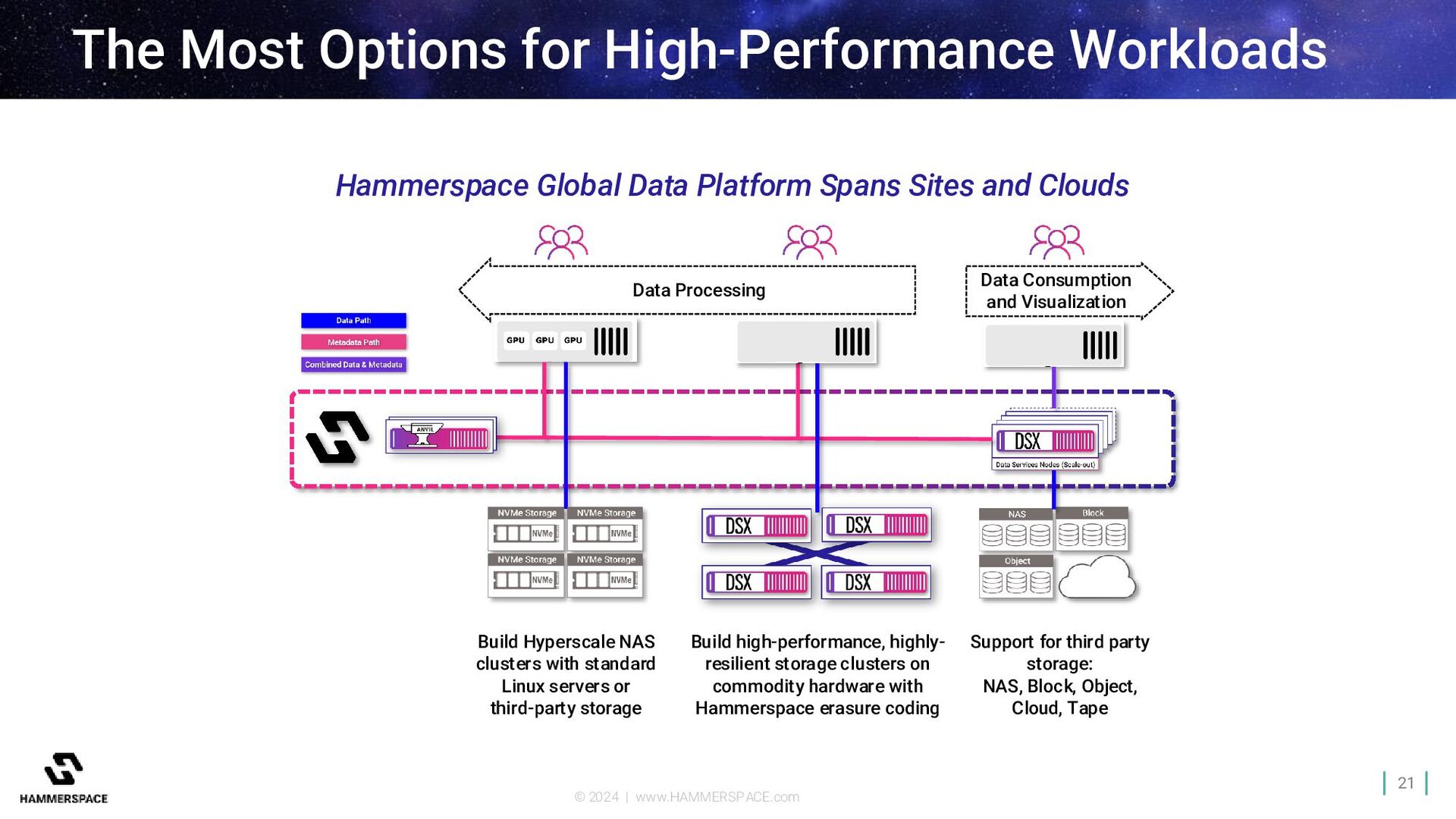
Workloads Data Processing Data Consumption and Visualization Hammerspace Global Data Platform Spans Sites and Clouds Build Hyperscale NAS clusters with standard Linux servers or third-party storage Build high-performance, highly- resilient storage clusters on commodity hardware with Hammerspace erasure coding Support for third party storage: NAS, Block, Object, Cloud, Tape
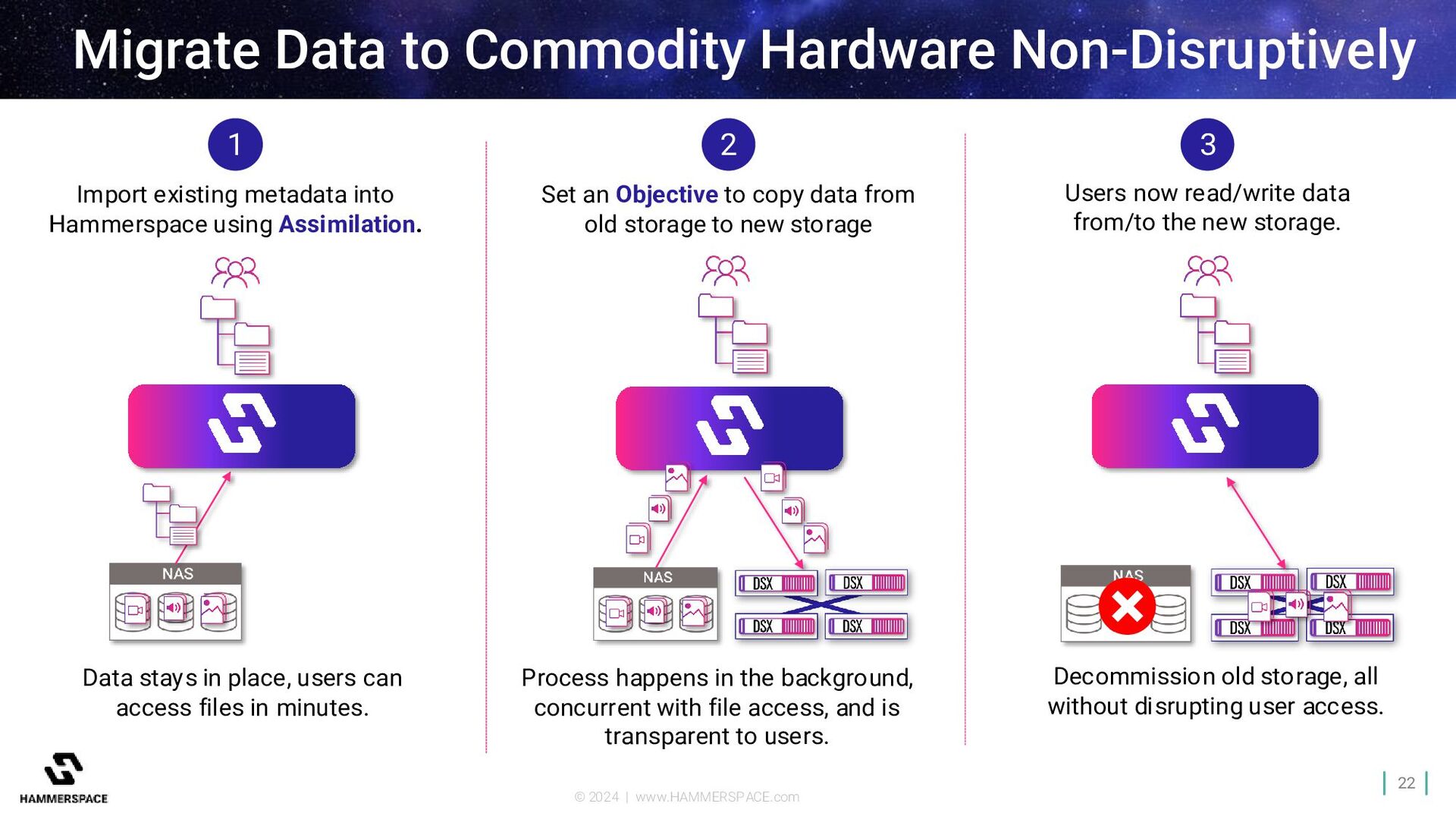
Non-Disruptively 1 Import existing metadata into Hammerspace using Assimilation. Data stays in place, users can access files in minutes. 3 Decommission old storage, all without disrupting user access. Users now read/write data from/to the new storage. 2 Set an Objective to copy data from old storage to new storage Process happens in the background, concurrent with file access, and is transparent to users.
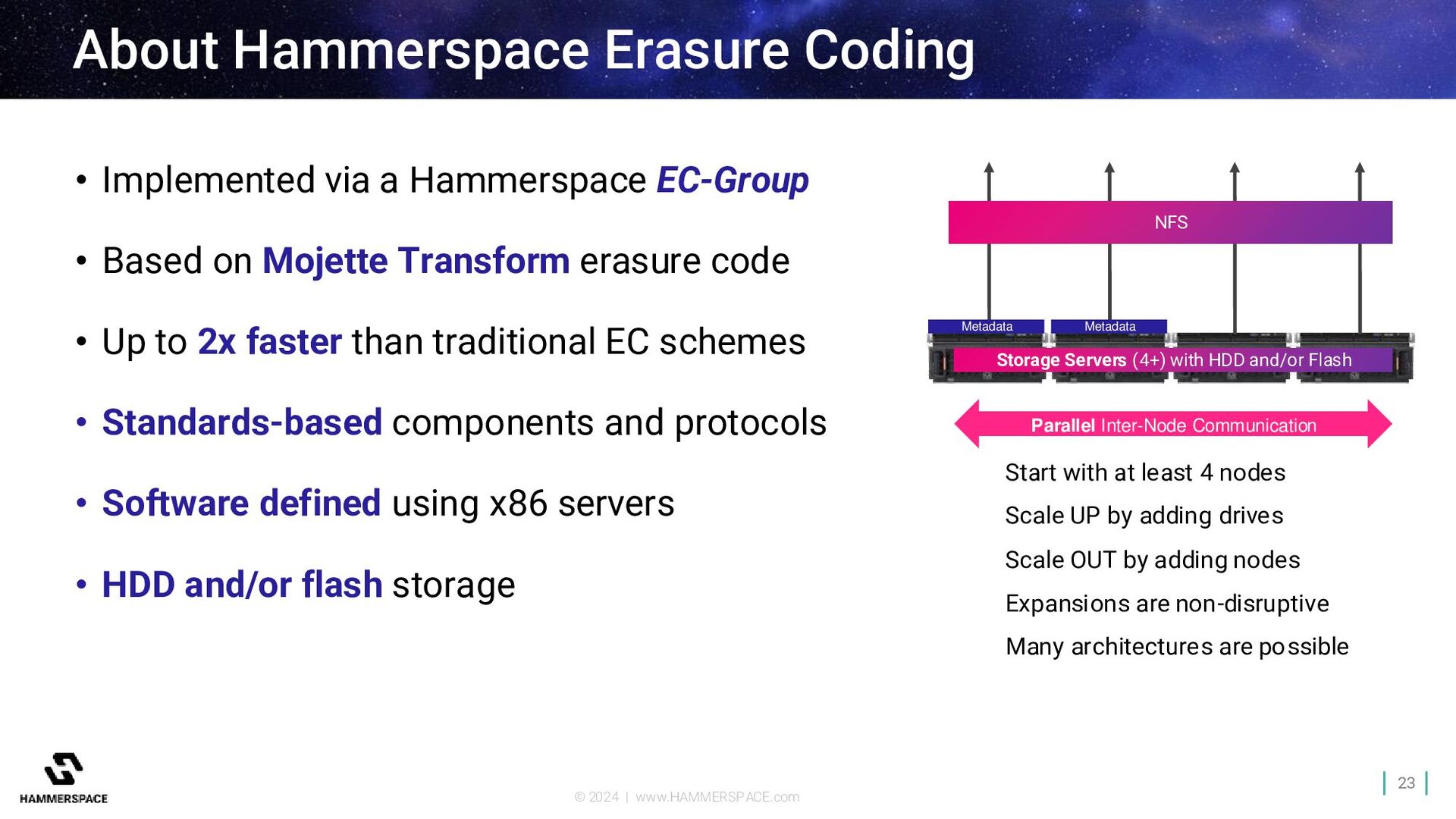
Implemented via a Hammerspace EC-Group • Based on Mojette Transform erasure code • Up to 2x faster than traditional EC schemes • Standards-based components and protocols • Software defined using x86 servers • HDD and/or flash storage Storage Servers (4+) with HDD and/or Flash NFS Metadata Metadata Parallel Inter-Node Communication Start with at least 4 nodes Scale UP by adding drives Scale OUT by adding nodes Expansions are non-disruptive Many architectures are possible
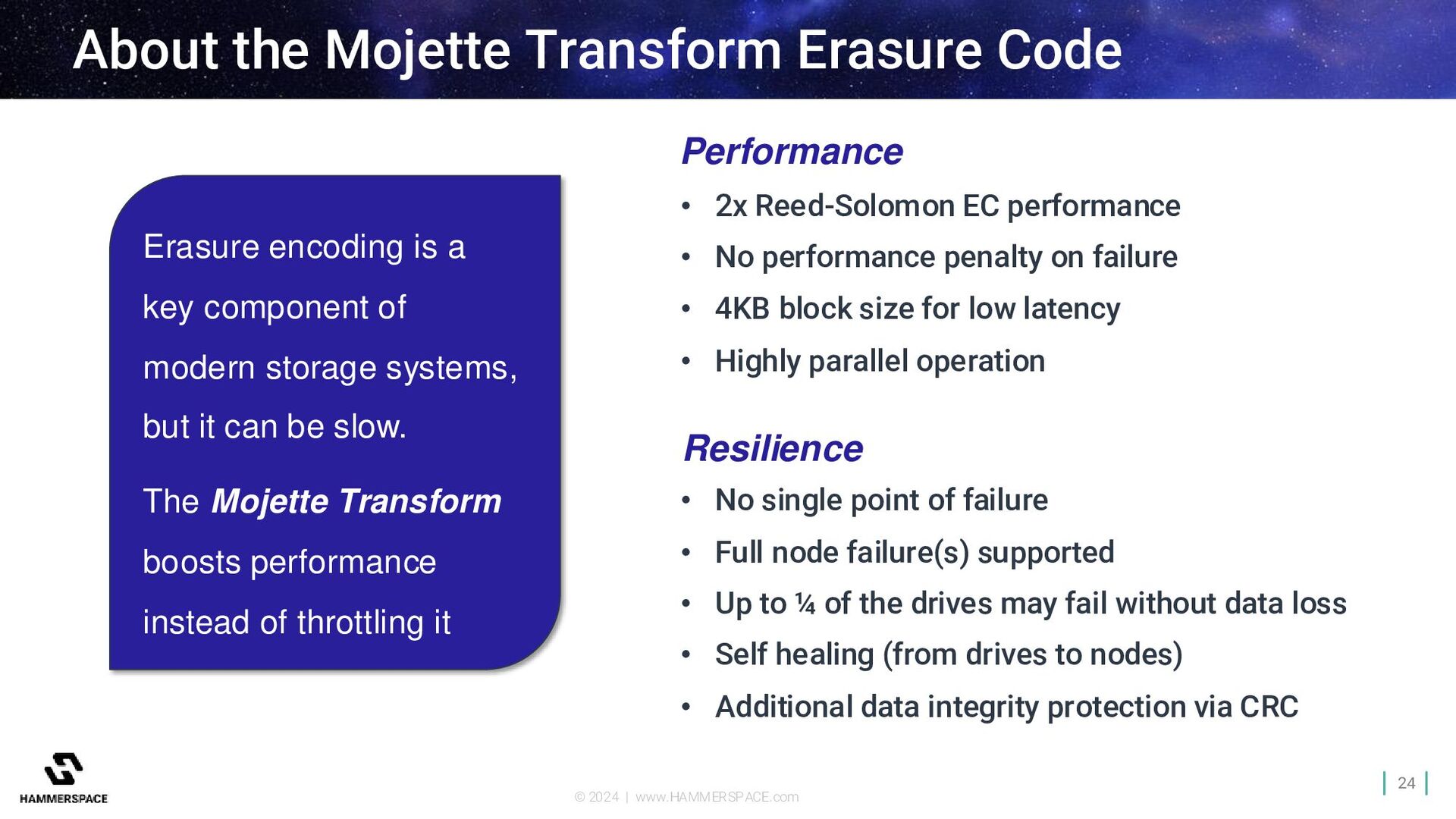
• No performance penalty on failure • 4KB block size for low latency • Highly parallel operation • No single point of failure • Full node failure(s) supported • Up to ¼ of the drives may fail without data loss • Self healing (from drives to nodes) • Additional data integrity protection via CRC Erasure encoding is a key component of modern storage systems, but it can be slow. The Mojette Transform boosts performance instead of throttling it Performance Resilience About the Mojette Transform Erasure Code
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}