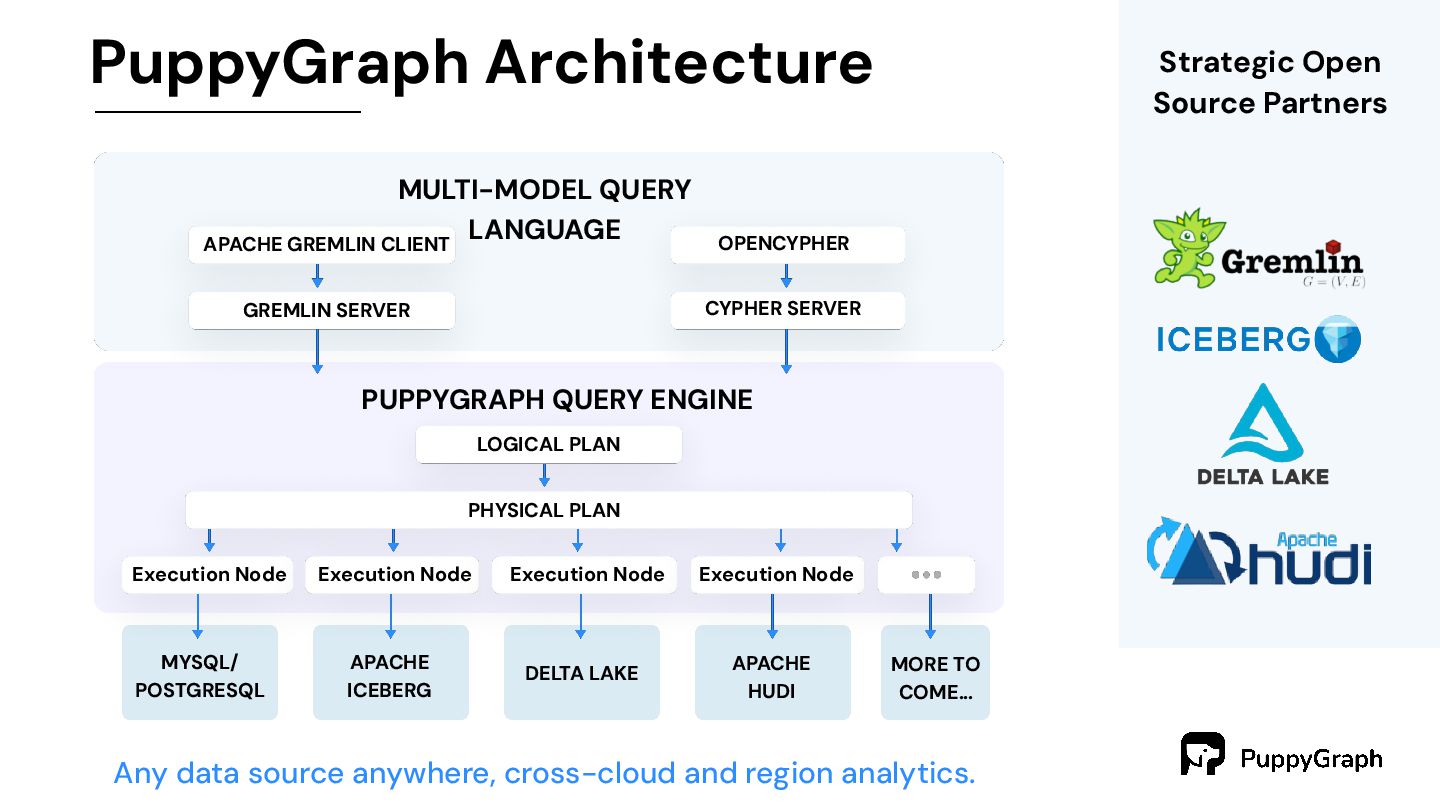
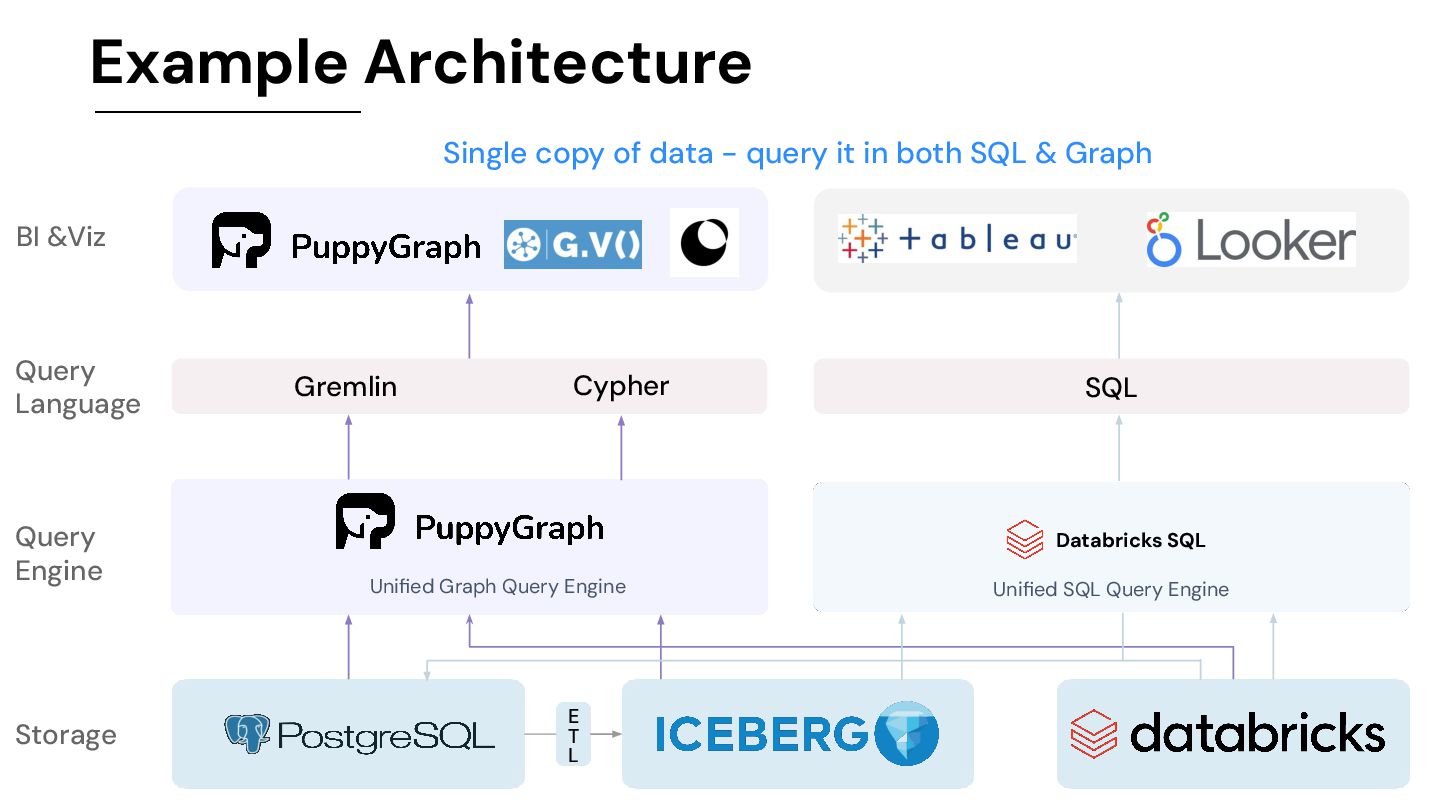
To Query One Or More Relational Data Stores As A Unified Graph Model. No separate graph database required with zero ETL. Scalable w/ PBs of data & billions nodes Deploy to query in 10 mins. Complex queries in seconds.
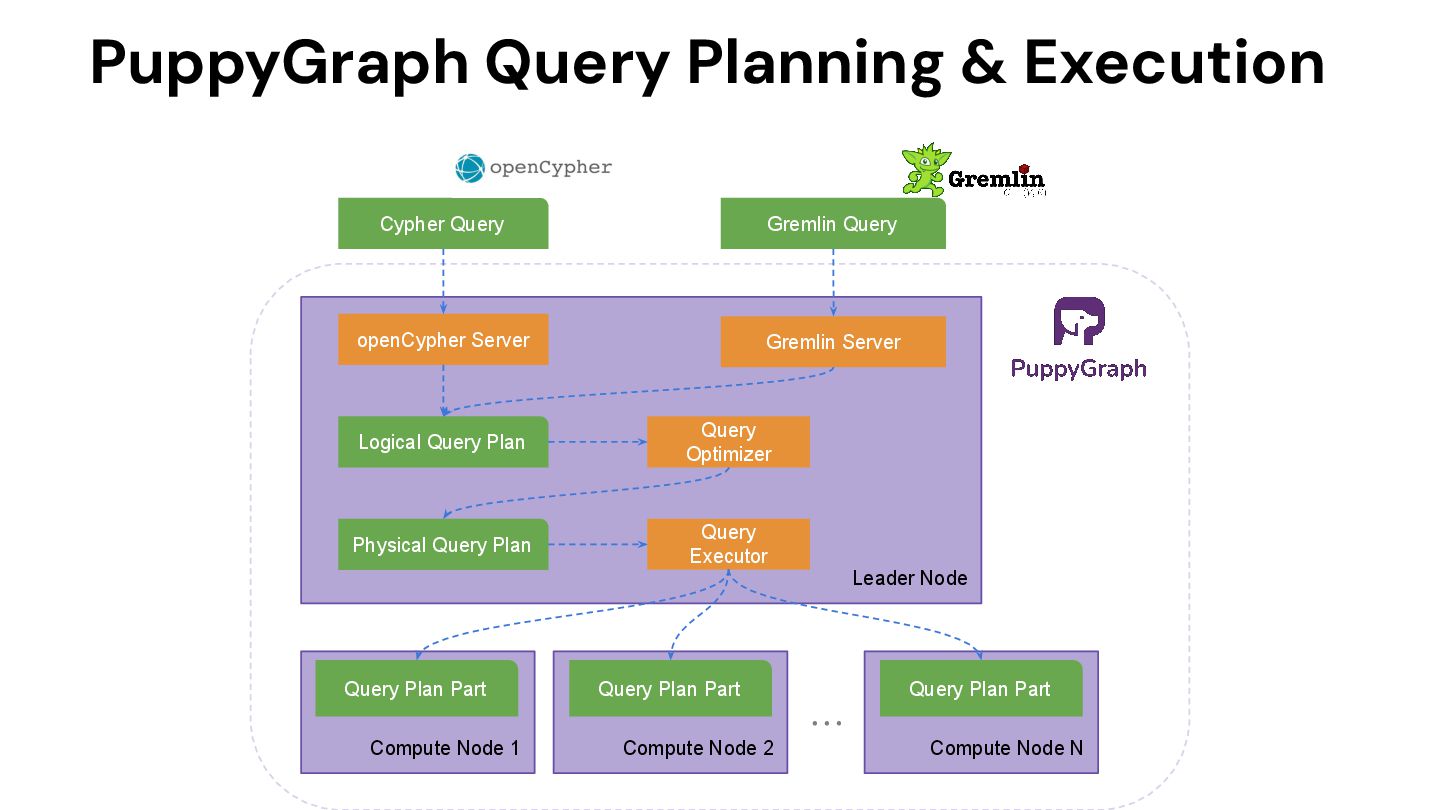
MORE TO COME… MULTI-MODEL QUERY LANGUAGE APACHE GREMLIN CLIENT GREMLIN SERVER LOGICAL PLAN PHYSICAL PLAN Execution Node Execution Node Execution Node Execution Node OPENCYPHER CYPHER SERVER Strategic Open Source Partners Any data source anywhere, cross-cloud and region analytics. PUPPYGRAPH QUERY ENGINE
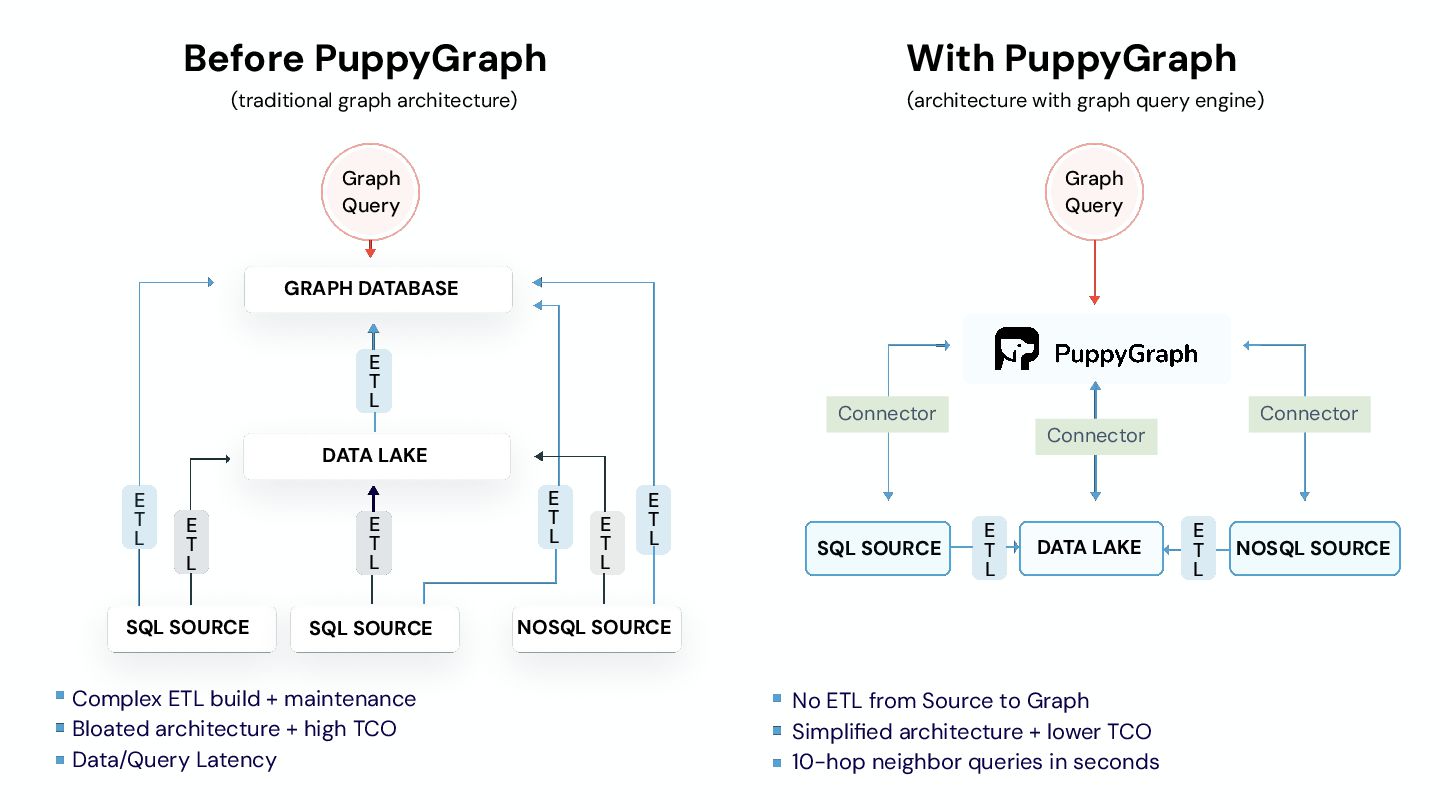
query engine) Graph Query DATA LAKE GRAPH DATABASE NOSQL SOURCE SQL SOURCE SQL SOURCE SQL SOURCE NOSQL SOURCE DATA LAKE E T L E T L E T L E T L E T L E T L E T L Graph Query Complex ETL build + maintenance Bloated architecture + high TCO Data/Query Latency No ETL from Source to Graph Simplified architecture + lower TCO 10-hop neighbor queries in seconds E T L E T L Connector Connector Connector
query engine) Graph Query DATA LAKE GRAPH DATABASE NOSQL SOURCE SQL SOURCE SQL SOURCE SQL SOURCE NOSQL SOURCE DATA LAKE E T L E T L E T L E T L E T L E T L E T L Graph Query Complex ETL build + maintenance Bloated architecture + high TCO Data/Query Latency No ETL from Source to Graph Simplified architecture + lower TCO 10-hop neighbor queries in seconds E T L E T L Connector Connector Connector
Server Logical Query Plan Compute Node 1 Compute Node 2 Compute Node N Physical Query Plan Query Plan Part Query Optimizer Query Executor Query Plan Part Query Plan Part … Cypher Query Gremlin Query
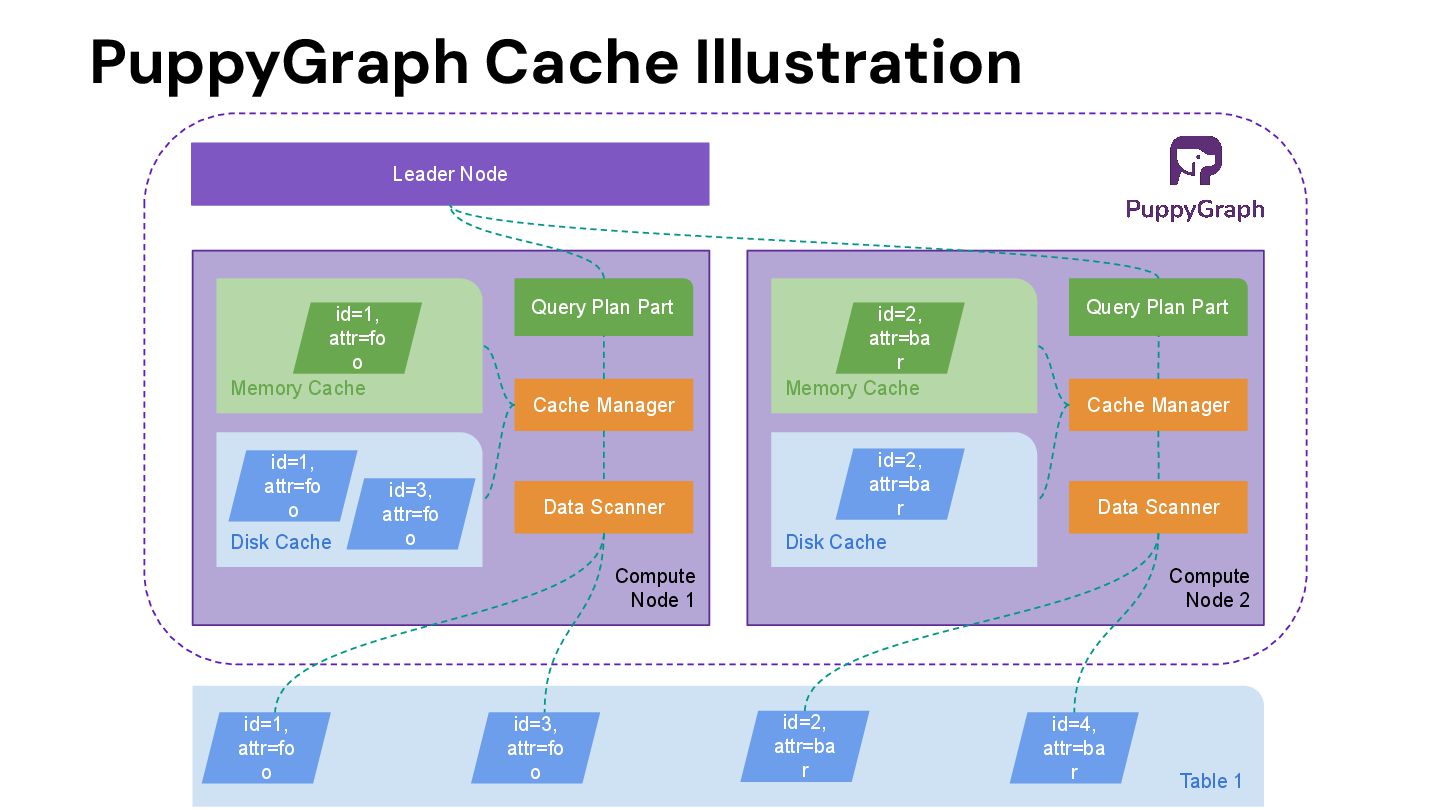
id=1, attr=fo o id=3, attr=fo o id=2, attr=ba r id=1, attr=fo o Leader Node Query Plan Part Cache Manager Data Scanner Disk Cache id=1, attr=fo o id=3, attr=fo o Compute Node 2 Memory Cache id=2, attr=ba r Query Plan Part Cache Manager Data Scanner Disk Cache id=2, attr=ba r id=4, attr=ba r
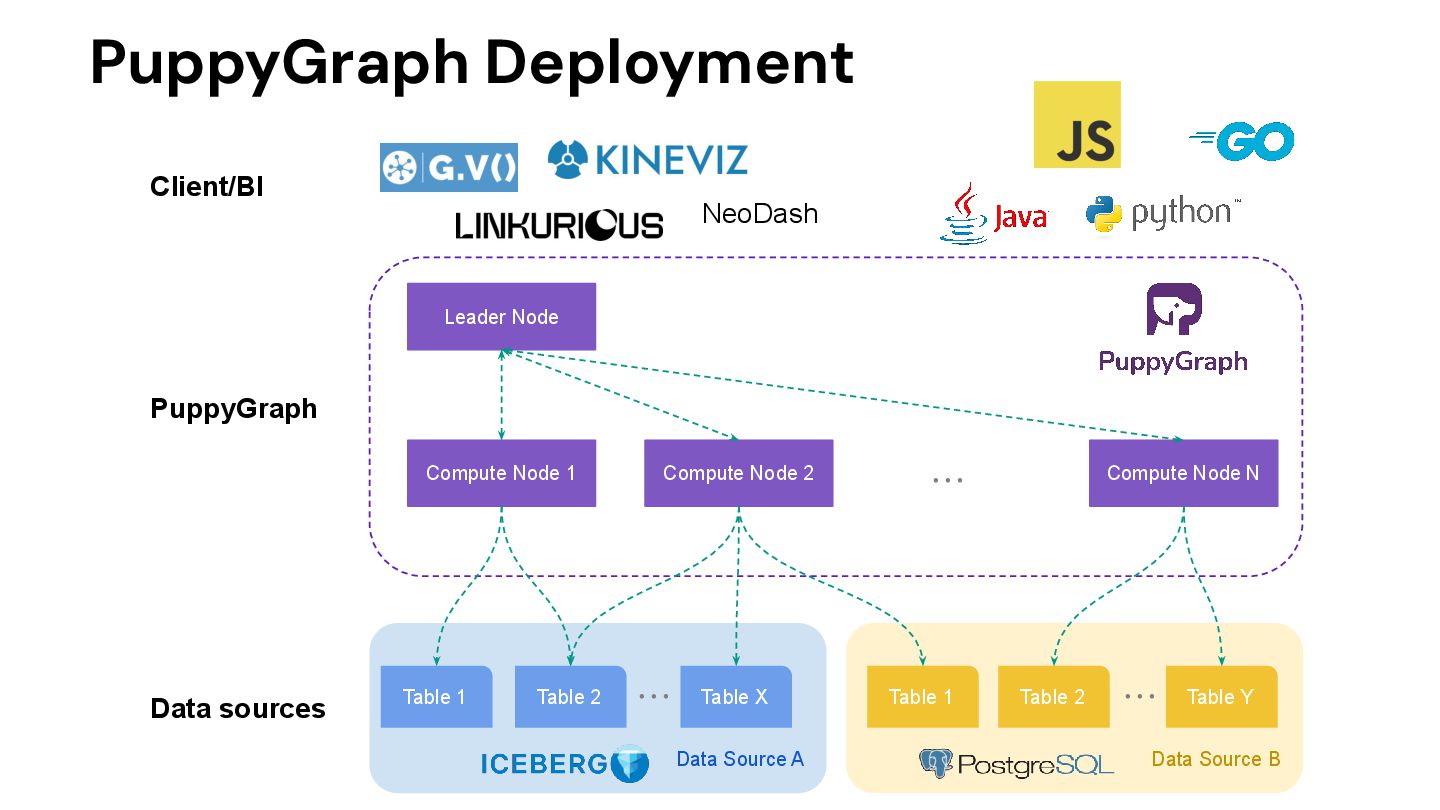
query your data as a graph by directly connecting to your data warehouses and lakes. This eliminates the need to build and maintain time-consuming ETL pipelines needed with a traditional graph database setup. Deploy to query in 10 minutes. • Column-based data file format: While a graph database usually have row-based storage or key-value storage, it is good at adding/updating/removing a vertex/edge rather than running a complex query to do data analysis. PuppyGraph doesn’t have its own storage. Instead, it’s the only graph solution that leverages the column-based storage to speed up complex queries at scale. • Optimized query execution: On top of column-based storage, PuppyGraph offers massively parallel processing and vectorized evaluation technology that makes the computation fast even when lacking efficient indexing and caching. The performance can be even faster by leveraging our internal (in-memory of PuppyGraph compute node) and external (user’s existing storage) indexing and caching technologies. While the relation data warehouse’s query engine is optimized for SQL queries, PuppyGraph is optimized for graph queries. • Distributed design: PuppyGraph’s compute engine is distributed - it means more machines = better performance. The distributed design allows PuppyGraph to handle huge size of data and complex queries like 10-hop neighbor with ease.
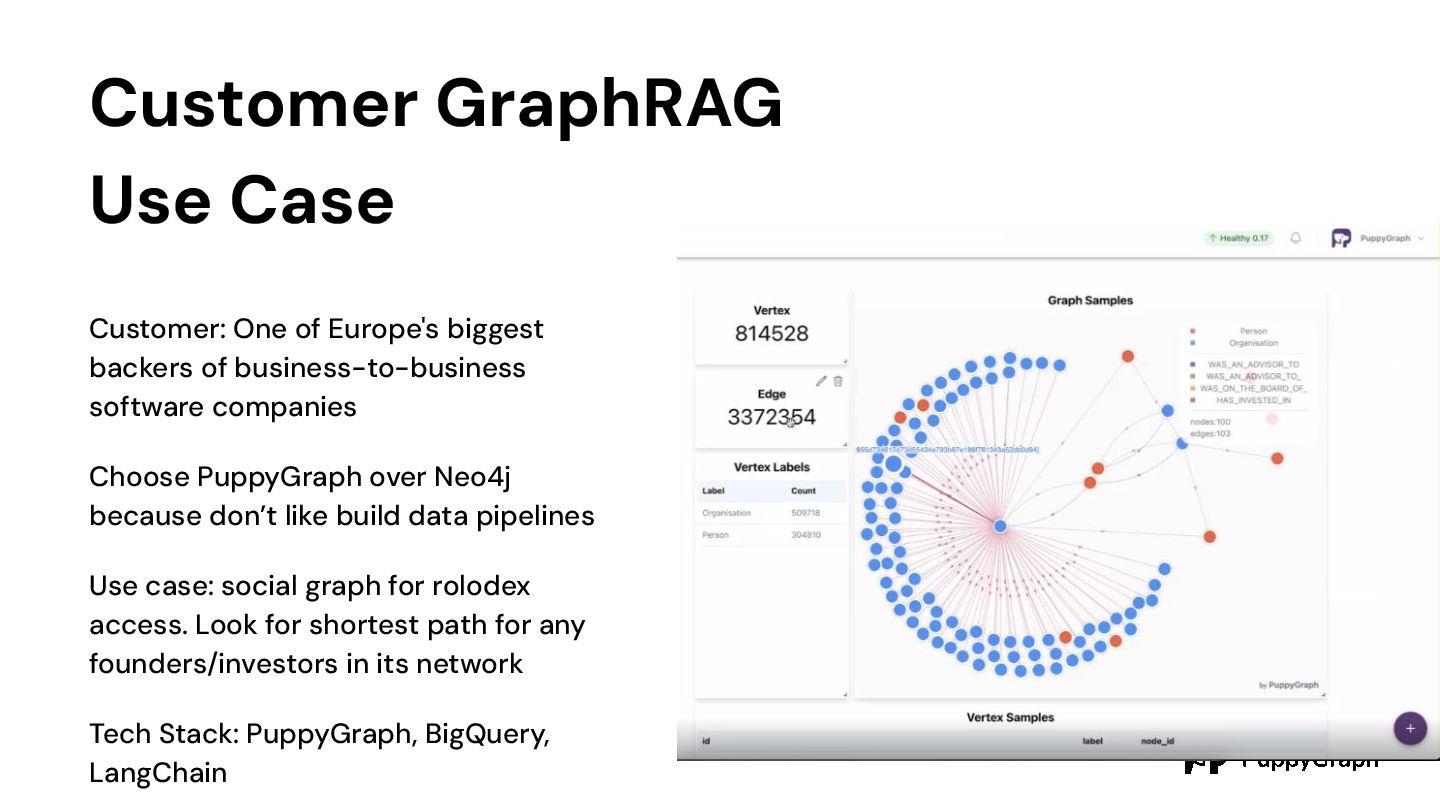
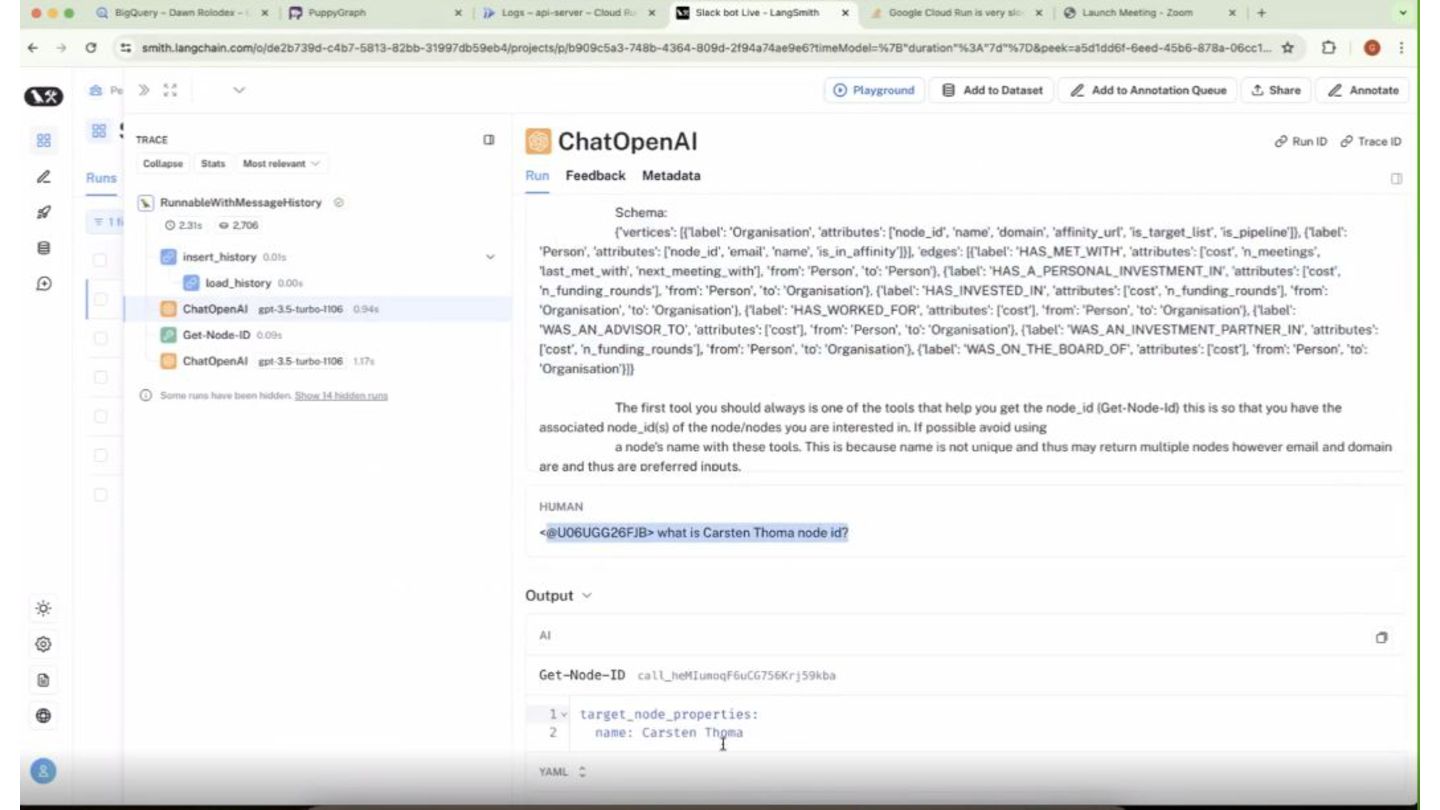
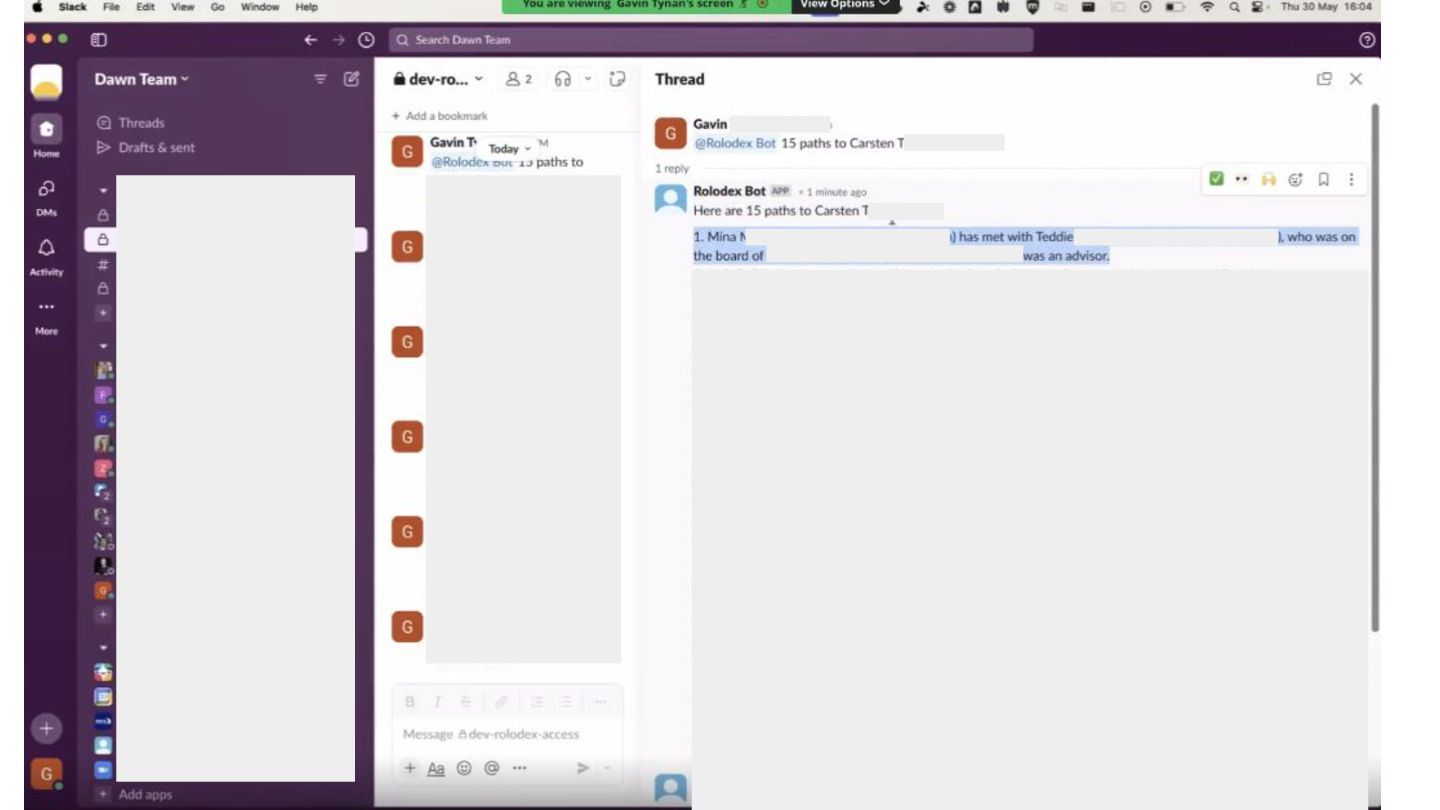
of business-to-business software companies Choose PuppyGraph over Neo4j because don’t like build data pipelines Use case: social graph for rolodex access. Look for shortest path for any founders/investors in its network Tech Stack: PuppyGraph, BigQuery, LangChain A simple knowledge graph example
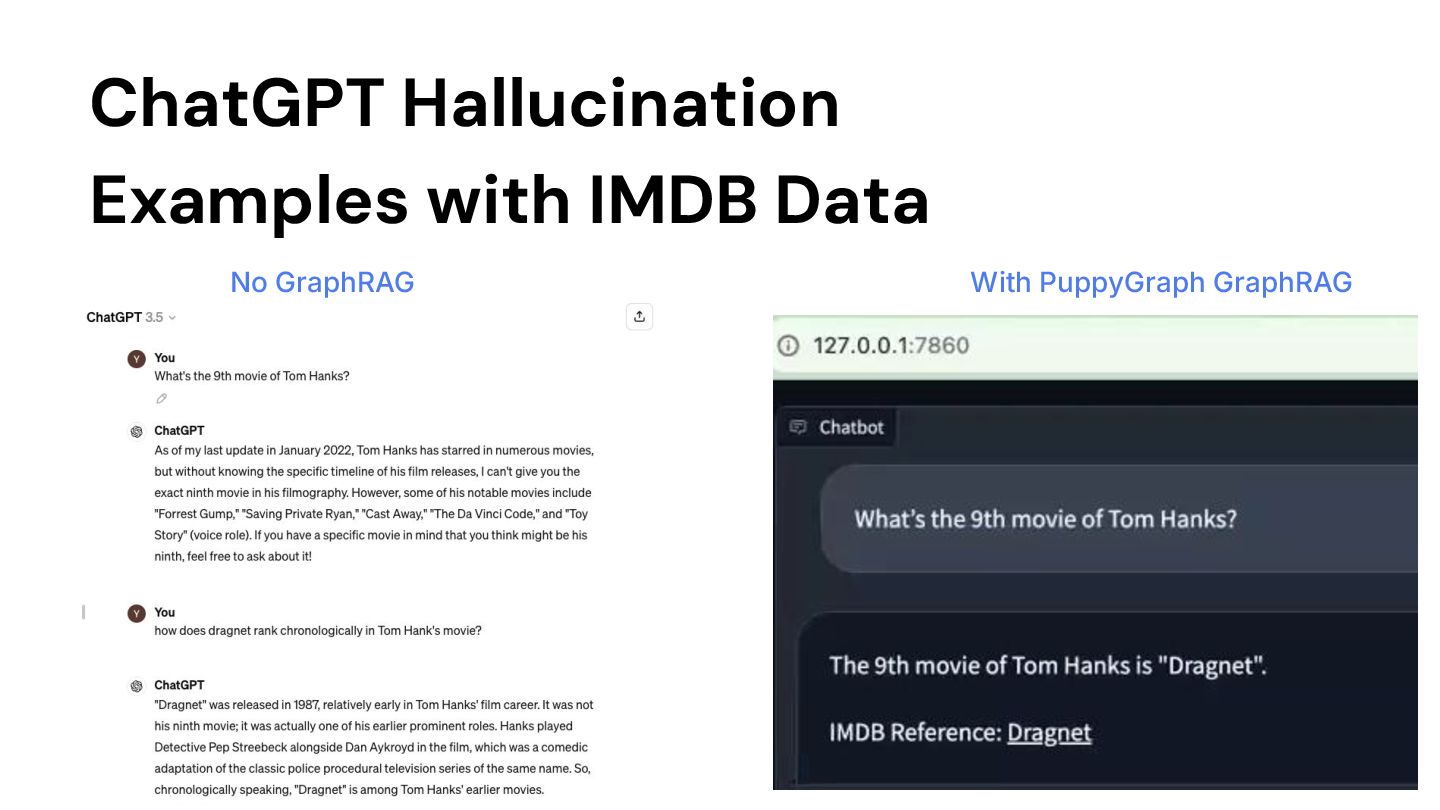
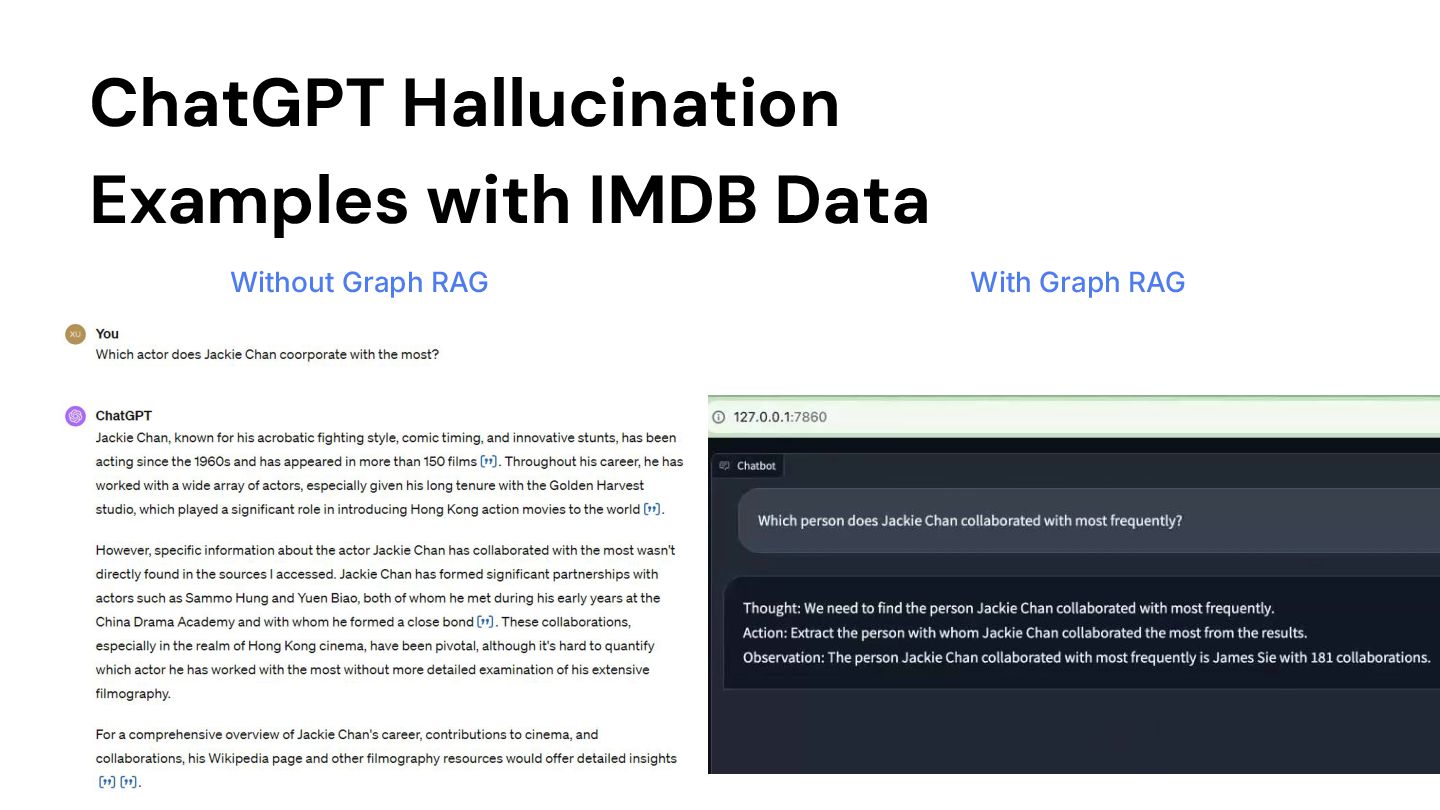
models are not easy to query your private data: ◦ GPT models are not trained on the private data ◦ Enterprise also don’t want to share any private data with OpenAI • ChatGPT can lead to hallucination when answering data oriented questions: ◦ Provide wrong answers ◦ Give a long block of text but doesn’t really answer the questions
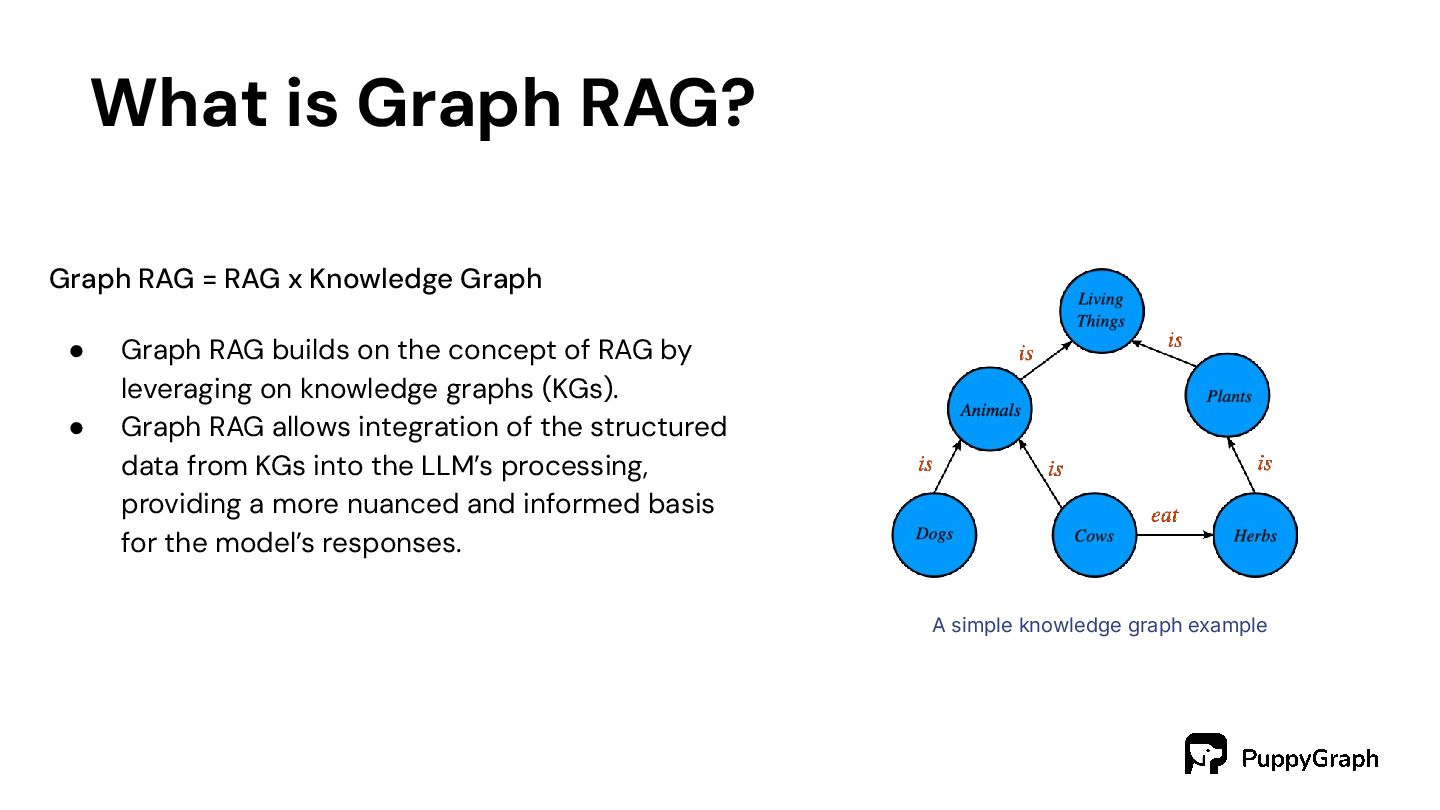
Graph • Graph RAG builds on the concept of RAG by leveraging on knowledge graphs (KGs). • Graph RAG allows integration of the structured data from KGs into the LLM’s processing, providing a more nuanced and informed basis for the model’s responses. A simple knowledge graph example
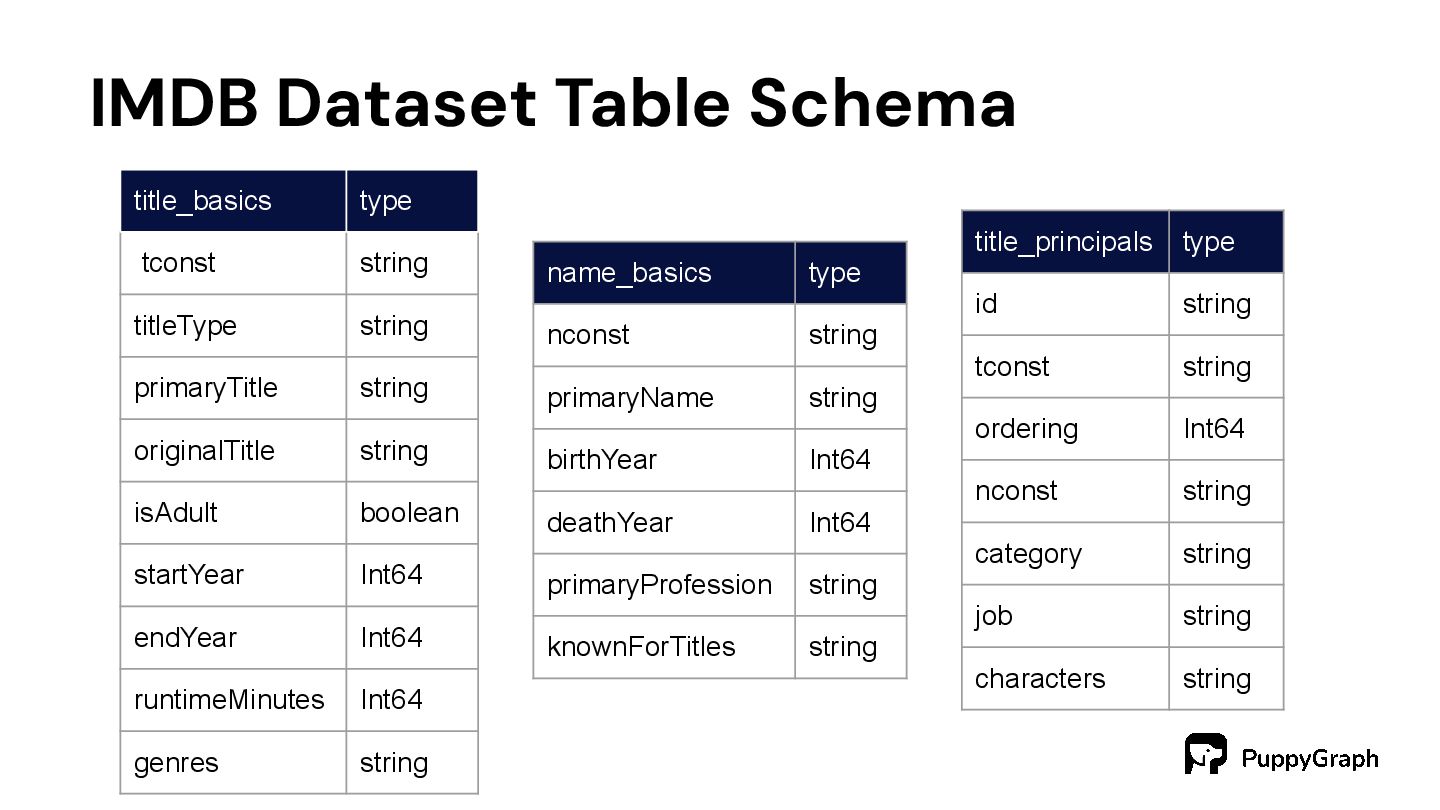
types of vertices: 1. `person`. This type of vertex can be directors, producers or actors/actresses. It has 3 major attributes: `primaryName`, `birthYear` and `deathYear`. 2. `title`. This type of vertex can be movies, TV episodes or TV movies, etc. It has 3 major attributes: `titleType`, `primaryTitle` and `startYear`. The IMDB knowledge graph has one type of edge: `cast_and_crew`. Note this edge is directed, pointing from `title` vertices to `person` vertices,
internal & paying customers for fraud-detection Data set is billions of nodes & TBs of metadata, and can’t achieve real-time beyond 3+ hops Pain points: Released a new online, automated system powered by PuppyGraph (in production) Achieved 5-hop paths between A and B in 3 seconds across a few hundred millions of edges POC with PuppyGraph < 1 day and shipped the production in < 6 months After adopting PuppyGraph: It couldn’t support large requests & batch timed out issues Confidential* One of the largest crypto trading platforms in the world
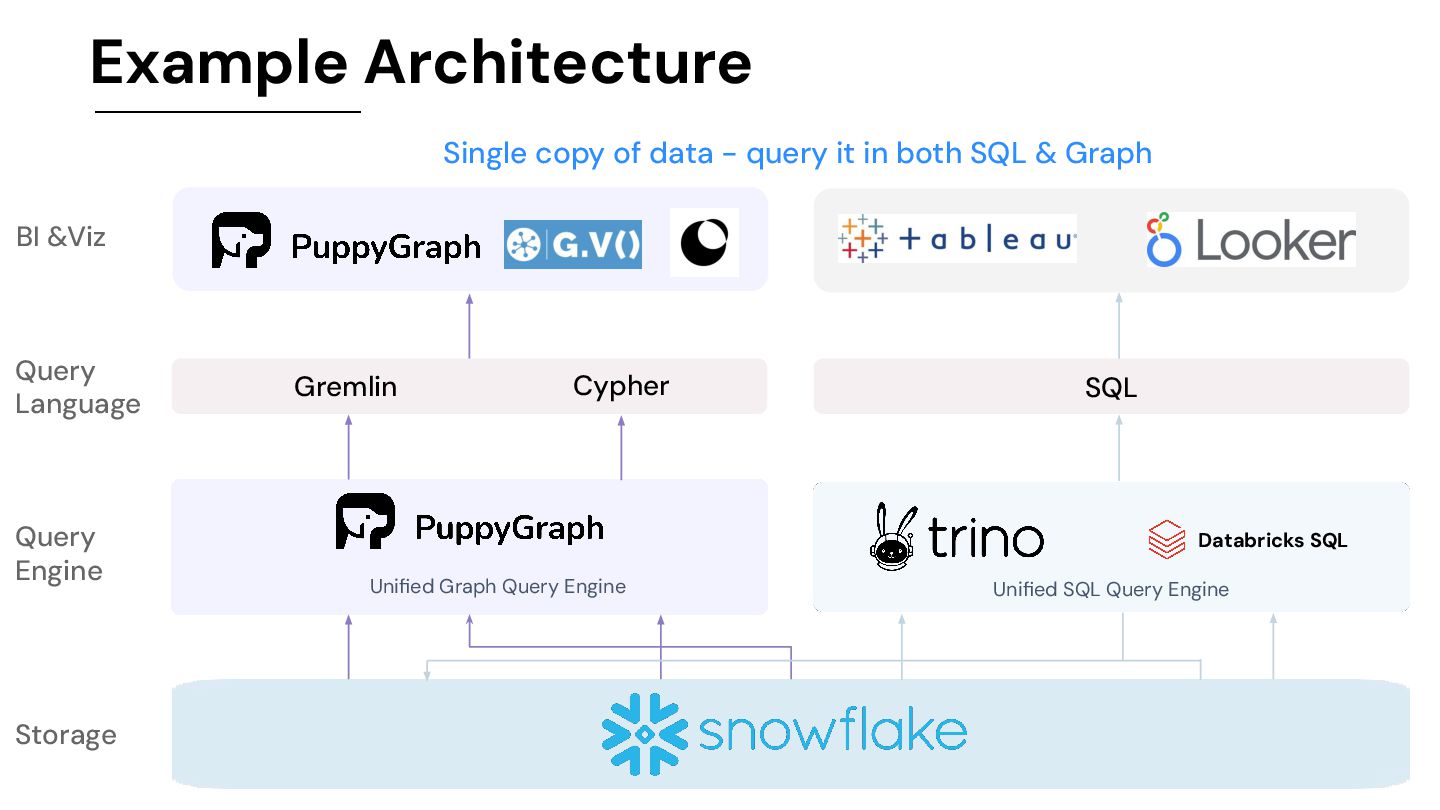
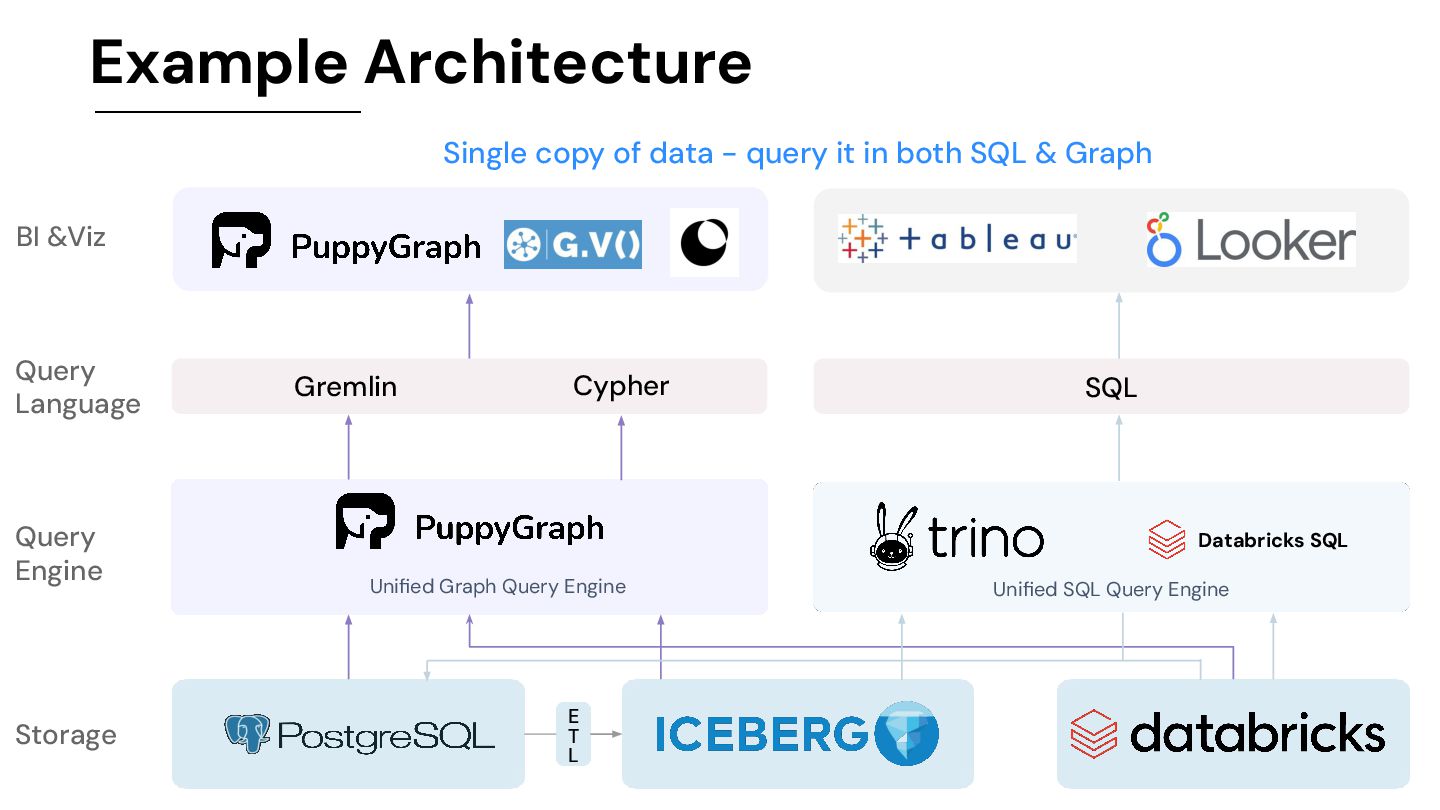
from Data+AI Summit 2024 "PuppyGraph is a very interesting graph query engine. It doesn't require us to load or ETL any data into a specialized or proprietary database storage layer for graphs. We can simply query everything directly on our data lake—whether it’s Delta, Iceberg, or just plain Parquet files. PuppyGraph can integrate this data into a graph model and another distributed computation engine to render all the results. We use it in conjunction with Unity Catalog to unlock all our transactional and crypto data already on our Delta Lake. PuppyGraph then queries this data directly to perform all sorts of graph-based exploration and aggregation. This capability is so powerful, and our users really enjoy this level of flexibility.”
to identify fraudulent account for money transactions & pull relevant account data for human review Explored with Spark-based system but it failed to meet the real-time requirement Pain points: Achieved real time alerting in product by delivering 100-200ms for quick alerting queries and single digit secs for extremely complex queries that pulls review info for human investigation Scaled up to 3-5 TBs of data and plan to increase the data to 100TB by the end of next year by gradually adding more data sources After adopting PuppyGraph: The Spark-based system “hard-coded” a lot of query logic and lack of the flexibility as human reviewers need large varieties of criteria for effective investigation and exploration Confidential* One of the leading financial technology companies
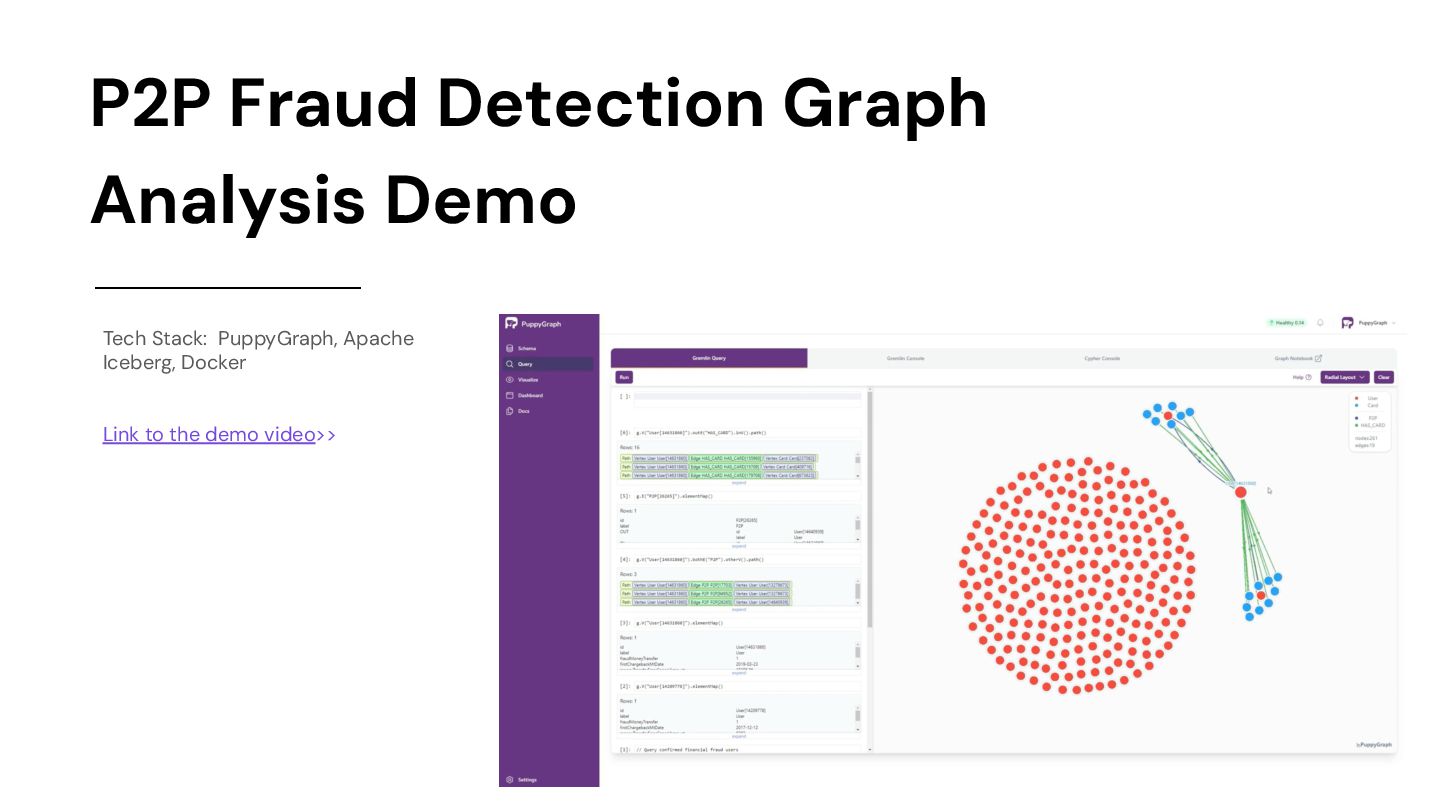
Investigate a real anonymized data sample from a peer-to-peer (P2P) payment platform, identify fraud patterns, resolve high risk fraud communities, and apply recommendation methods. Recreated from Neo4j’s example. • We will identify new fraud risks that went undetected with non-graph methods, increasing the number of flagged users by 87.5%. • Graph Schema: credit cards, devices, and IP addresses. • Each user node has an indicator variable for money transfer fraud (named MoneyTransferFraud) that is 1 for known fraud and 0 otherwise. This indicator is determined by a combination of credit card chargeback events and manual review. • Analysis/queries we’ll run: ◦ Query confirmed financial fraud users ◦ Show a relational pattern if one user transfer money to another user who shares the same credit card ◦ Group accounts with transfer records and shared credit cards using Weakly Connected Components (WCC) algorithm ◦ Find out if there are confirmed fraudulent users within a specific group ◦ Query users within the specific group: if there are confirmed fraudulent users in the group, or other user in the group may be fraudulent users • Tech Stack: PuppyGraph, Apache Iceberg, Docker
to show complete visibility from diverse sources like SIEM, vulnerability scanners, EDR, VPN, IAM, IGA, ITSM, CMDB & cloud sources. Pain points: • Unable to analyze pass 7 days of data with SQL-based solution • Couldn’t support large requests & batch timed out issues • Need to achieve real-time for certain queries while balance the cost of infrastructure Confidential* An ISTARI Collective member and a Cybersecurity leader
over Apache Druid because due to scalability & performance & cost advantages • PuppyGraph helped Prevalent AI to increase the amount of handled data volume by 30x • Able to achieve query speed for last 7 day data in <3 seconds and last 30 day data in < 10 seconds Tech Stack: • PuppyGraph + Apache Iceberg Prevalent AI write up on the knowledge graph for crisis readiness>>
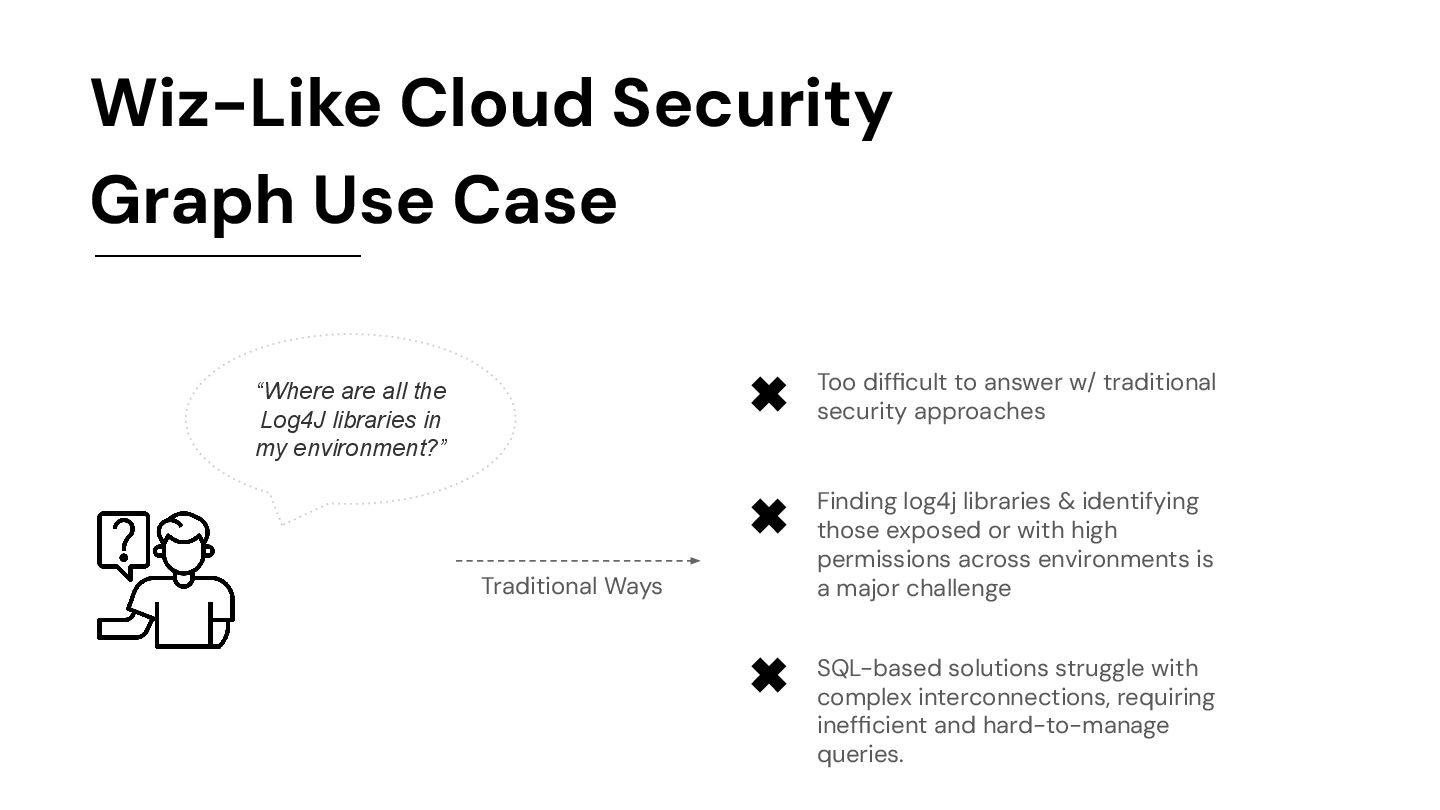
Log4J libraries in my environment?” Too difficult to answer w/ traditional security approaches Finding log4j libraries & identifying those exposed or with high permissions across environments is a major challenge ✖ ✖ SQL-based solutions struggle with complex interconnections, requiring inefficient and hard-to-manage queries. ✖ Traditional Ways
toxic combination of risk factors that represent critical risks through a graph model. Wiz scans the entire tech stack w/o agents and stores a graph of relevant security metadata. The Wiz Risk Engines traverse the graph & weave together interconnected risk factors in seconds. Wiz’s security graph can make the interconnection visulizable & queryable for users. Through a simple graph query, customers can identify critical risks such as: • Resources open to the AllUser predefined group • Publicly exposed containers with high Kubernetes privileges • Externally exposed and unpatched VM instances with cleartext SSH private keys “The world is a graph, not a table. It’s time our tooling reflected this.” Ami Luttwak CTO Wiz Wiz CTO’s blog on their Cloud Security Graph
adopting a specialized graph storage system that require complex ETL process, PuppyGraph is a graph query engine that can sit on top of existing relational data stores - with zero ETL. Deploy PuppyGraph in as little as 10 minutes and create graph schemas across all tables in your one or more of relational storage. Supporting most popular graph query languages, Cypher & Gremlin, and easily query complex relationships such as “resources open to the AllUser predefined group” or “publicly exposed containers with high Kubernetes privileges” with ease. Link to cloud security graph demo recording
and load balancers • Query and visualize the paths from a specific server node to all downstream load balancers and server node • Query and visualize the paths from failed server node to all downstream load balancers Tech Stack: PuppyGraph, Apache Iceberg, Docker Link to the network topology demo recording
is a Dependency of type Artifact. Create a graph for all dependencies for artifact for faster troubleshooting • Query all direct and indirect dependencies of an artifact • Query which artifacts directly or indirectly depend on a certain artifact • Query all failing build records and dependencies related to a certain build Tech Stack: PuppyGraph, Apache Iceberg, Docker Link to the CI/CD demo recording
Business use case: how to analyze and visualize high CPU utilization across components within a large call graph • Query historical records and related components with a CPU load ratio greater than 0.9 • Query historical records of components with CPU usage exceeding 90%, as well as corresponding component and invocation info • Rank the importance of each component using the PageRank algorithm Tech Stack: PuppyGraph, Apache Iceberg, Docker Link to the workload demo recording
Logs play a crucial role by capturing detailed traffic data, which is pivotal for identifying security threats, optimizing network performance, and ensuring regulatory compliance. While SQL remains a common tool for data analysis, graph-based analytics offer a superior alternative for managing VPC Flow Log data, excelling in rapidly identifying relationships between data points such as IP address connections. Link to the Upsolver tutorial blog
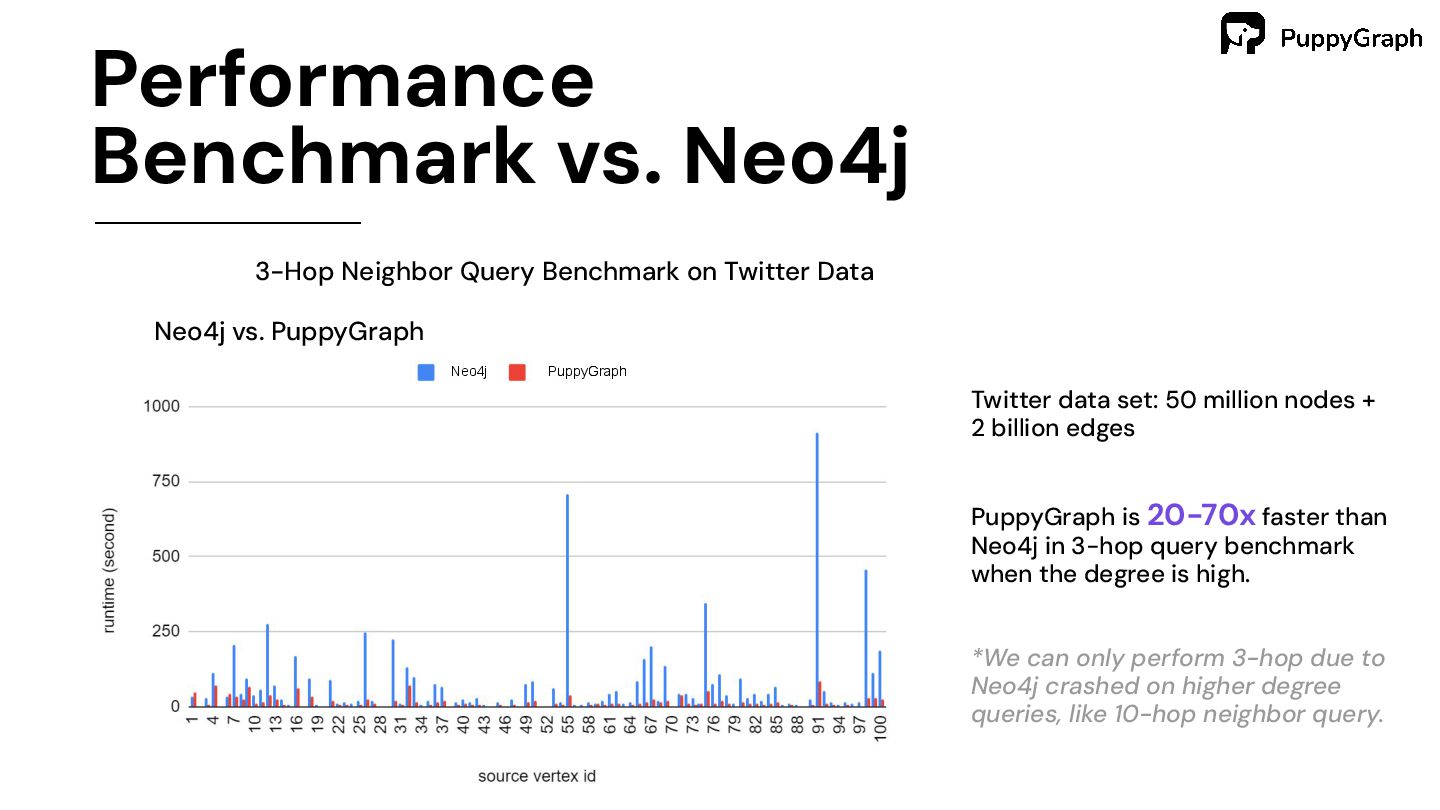
Data Neo4j vs. PuppyGraph Neo4j PuppyGraph Twitter data set: 50 million nodes + 2 billion edges PuppyGraph is 20-70x faster than Neo4j in 3-hop query benchmark when the degree is high. *We can only perform 3-hop due to Neo4j crashed on higher degree queries, like 10-hop neighbor query.
of Vertices # of Edges Graph500(sf22) 2,396,657 64,155,735 Graph500(sf25) 17,062,472 523,602,831 Twitter 52,579,678 1,963,263,508 Results: PuppyGraph can answer 10-hop neighbor query across half billion edges in 2.26 seconds on a four machine cluster Datasets: Cluster: • Leader node: t3.xlarge • Computer nodes: m6i.4x • Number of compute nodes: 4
be run in any Linux box, any Cloud. www.puppygraph.com • Can be deployed on-prem or any major clouds: GCP, AWS, Azure • Available on AWS AMI, and GCP Marketplace • Our customers use k8s to deploy a cluster of PuppyGraph and use DataDog to monitoring the status of the cluster and scale in/scale out. • Users can use PuppyGraph’s Java/Go/Python client to set up alerts based on graph outcomes to the ops team
queries the synthetic data mimic the patient journey usually needed by healthcare or insurance organizations. • Analysis/queries we run: ◦ Query the information of the first 10 patients ◦ Query the complete path from a specific patient to their related admissions, diagnoses, and the corresponding ICD diagnosis details ◦ Query all patients diagnosed with "Aphasia" and then to find their other diagnosis records. ◦ Query the top 10 most common diagnoses among patients ◦ Modify data through Trino and read data using PuppyGraph by query and modify a specific patient data • Tech Stack: PuppyGraph, Trino, Apache Iceberg, Docker Link to the demo recording
queries the public Drug Central data using PuppyGraph. Drug Central provides information on active ingredients, chemical entities, pharmaceutical products, drug mode of action, indications, pharmacologic action. • We downloaded the Drug Central data in one copy of data (in Postgres format), and purposefully stored different tables in two different data sources to show PuppyGraph can query one or more SQL data stores: Apache Iceberg (e.g., bioactivity, target): 24 tables, and PostgreSQL (e.g., drugs, mechanisms of action and human action targets): 41 tables • Analysis/queries we run: ◦ List drugs approved by FDA, limiting the number of returned results. ◦ Get drugs with mechanisms of action for human targets. Returning 50 results. This query actually leverages both (Iceberg and Postgres) data source • Tech Stack: PuppyGraph, Apache Iceberg, PostgreSQL, Docker Link to the voiceover demo recording
Create graph schema using PuppyGraph UI • PuppyGraph dashboard demo • Instant schema change feature demo Book a meeting with the PuppyGraph Team: https://bit.ly/Meet-PuppyGraph
(with voice over) • Blog: Integrating Unity Catalog with PuppyGraph for Real-time Graph Analysis • Blog: GraphRAG with Databricks and PuppyGraph • Blog: Databricks Knowledge Graph: Everything You Need To Know Databricks CTO gave PuppyGraph a shoutout on LinkedIn
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Stay Connected! Weimo Liu, CEO & Co-Founder at PuppyGraph [email protected]](https://files.speakerdeck.com/presentations/5297d57f224845498948bc687fe8df8d/slide_62.jpg){kind=link}