A Comparison of Unsupervised Bilingual Term Extraction Methods Using Phrase-Tables
Masamichi Ideue, Kazuhide Yamamoto, Masao Utiyama and Eiichiro Sumita. A Comparison of Unsupervised Bilingual Term Extraction Methods Using Phrase-Tables. Proceedings of the thirteenth Machine Translation Summit (MT Summit XIII), pp.346-351 (2011.9)
Masamichi Ideue† Kazuhide Yamamoto Masao Utiyama Eiichiro Sumita ‡ Nagaoka University of Technology, Japan † National Institutre of Information and Communications Technology † ‡ ‡
dictionary Tonoike et al. (2006) translated the number of word in each source language term using the bilingual dictionary and combined these translations to form term candidates. 2 Itagaki et al. (2007) proposed a supervised method for extracting bilingual terms from the phrase-table built from a parallel corpus. We usually do not have annotated data for training supervised methods nor bilingual dictionaries specific to the documents under translation.
the wrong pairs, respectively. : Significance of the candidates based on Fisher’s exact test. Score F : Strength of the alignment between words of the candidates. Score L : Termhood of the candidate based on C-value. Score C
scores 5 , 2 , 2 , , Score ( ) (Score ( )) (Score ( )) (Score ( )) 3 FLC J E F J E L J E C J E T R T R T R T = + + • Two methods for counting the number of occurrences of term T Method 1 : Counting without regarding where T occurs Method 2 : Counting T only when it occurs alone, i.e., we do not count the number of occurrences of term T when it occurs as a substring of a longer term.
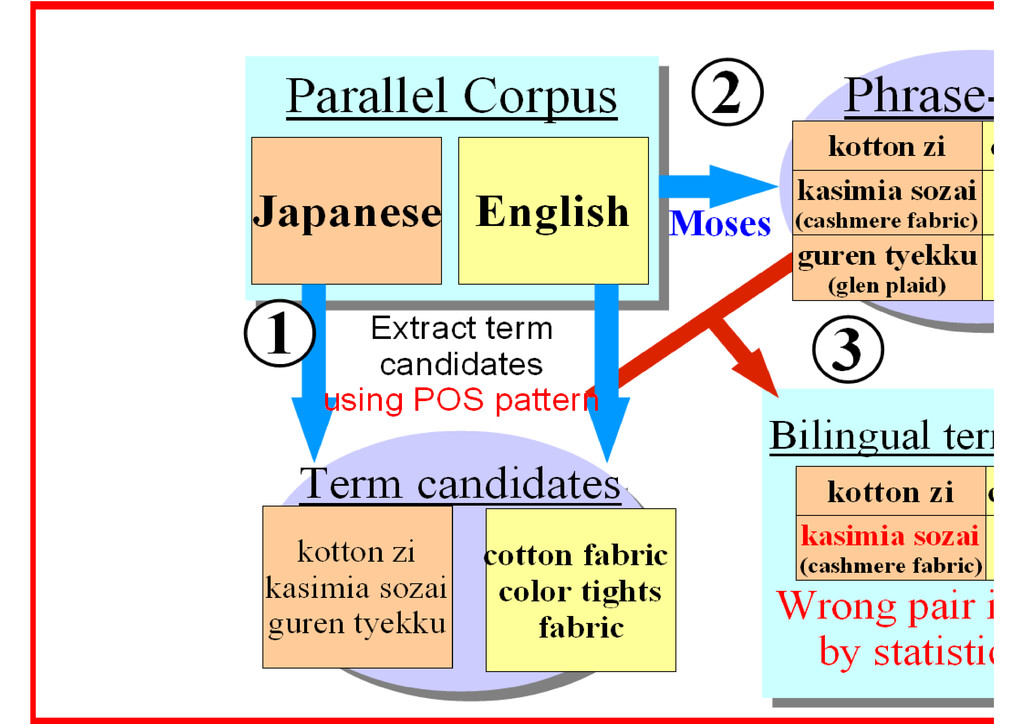
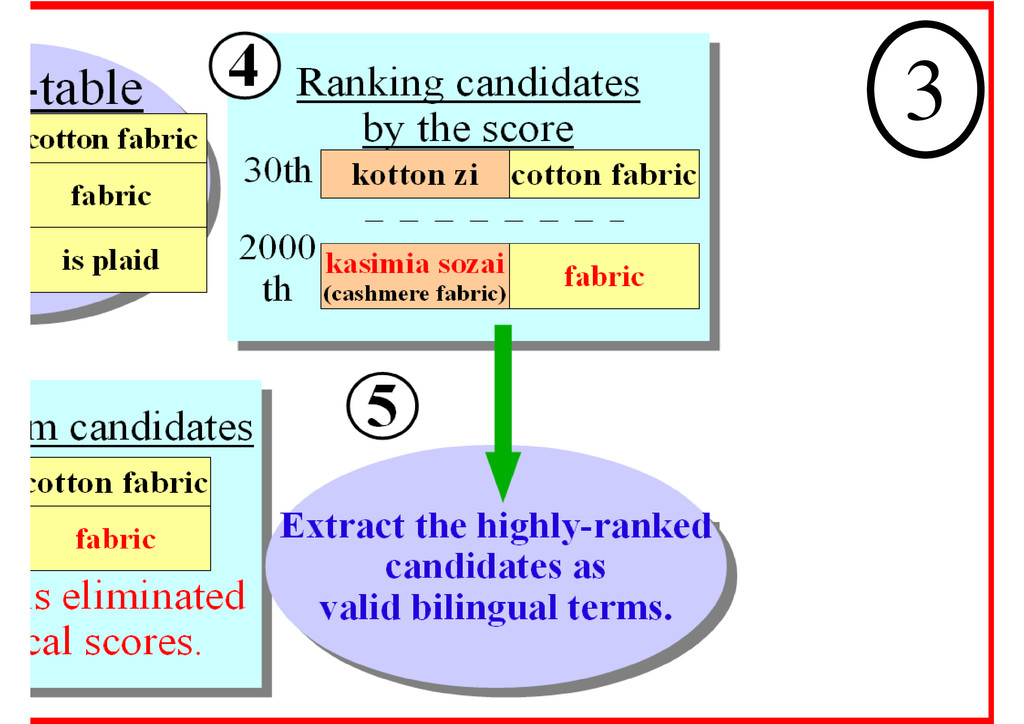
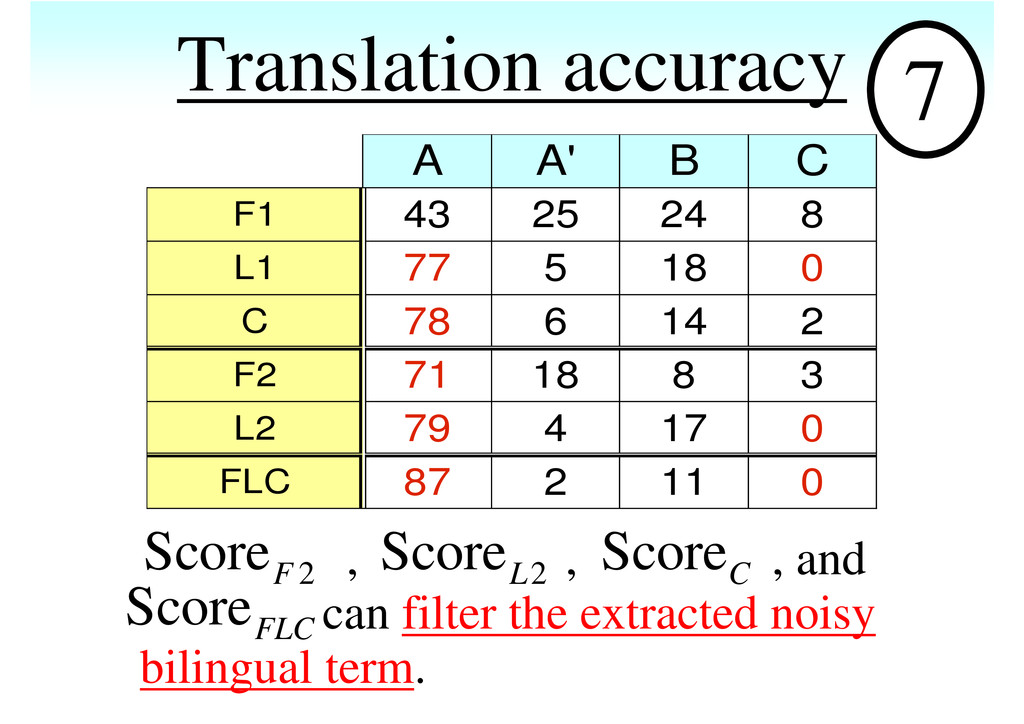
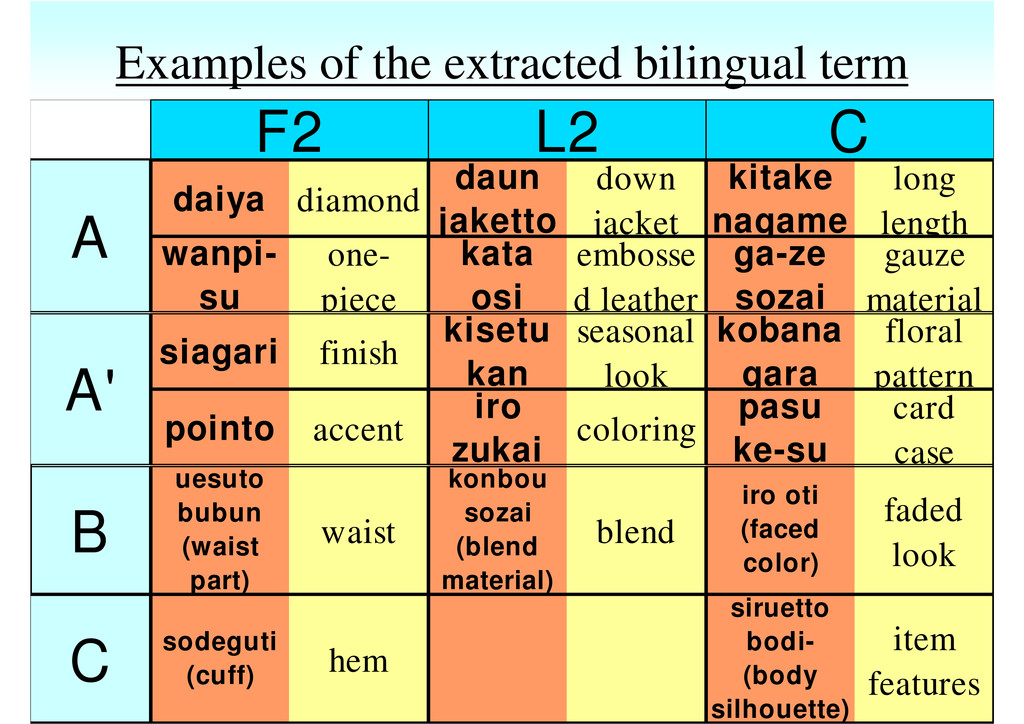
the top 1,000 candidates were manually evaluated for each score. A : correct A' : correct depending on contexts B : partly correct C : incorrect Evaluation criterion 6 • 22,543 bilingual term candidates were extracted from the Phrase-table. • Training corpus : Japanese-English parallel corpus, consisting of about 60,000 pairs, related to apparel products.
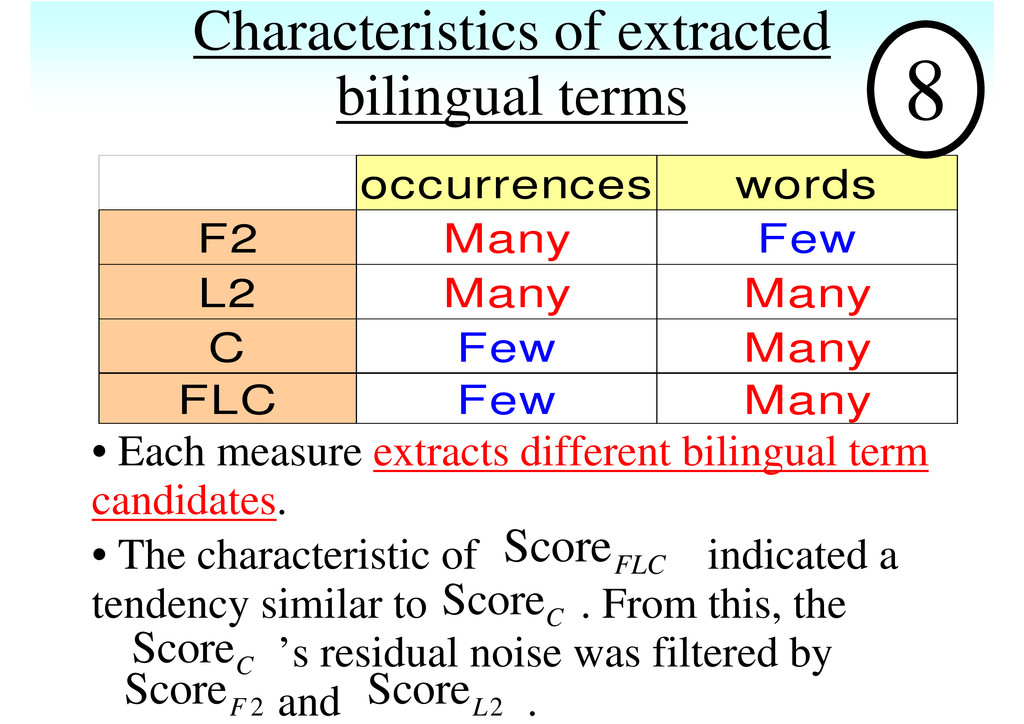
L2 Many Many C Few Many FLC Few Many • Each measure extracts different bilingual term candidates. • The characteristic of indicated a tendency similar to . From this, the ’s residual noise was filtered by and . 8 Score FLC 2 Score F 2 Score L Score C Score C
from the phrase- table built from a parallel corpus. Each method differs in the number of words and the occurrences of bilingual terms. The combination of these measures ranks valid bilingual terms highly. 9
exact test has been used by Johnson et al. (2007) to select valid phrase pairs from the phrase-table for statistical machine translation. We use the statistic of Fisher’s exact test as Score_F to measure the validity of each bilingual term candidate. If Score_F of a bilingual term candidate is high, the candidate has the validity. Score F
N : All parallel sentences C(J) : Japanese sentences containing J C(E): English sentences containing E C(J,E) : The number of parallel sentences containing J and E • P_h (C(J, E)) is the probability of observing the contingency table under the null hypothesis of J and E being independent of each other.
a component of the term is useful for automatic bilingual term extraction. : Strength of the alignment Score L Using the word alignments of each candidate term to measure the validity of the candidates.
ranked in C-value ranking, the bilingual term candidate has validity. : Termhood of the candidate color denim pants (C-Value = 6.34) color denim (2.0) denim pants (60.33) Score C The C-value (Frantzi et al., 1996) has been used to measure the stability of nested multi- word term candidates.
that the counting method is better than normal counting and characteristics of each measure are different. Therefore, we combine them. • Combination of measures • Two methods for counting the number of occurrences of term T Method 1 : Counting without regarding where T occurs Method 2 : Counting T only when it occurs alone, i.e., we do not count the number of occurrences of term T when it occurs as a substring of a longer term. 2 , 2 , , , (Score ( )) (Score ( )) (Score ( )) Score ( ) 3 F J E L J E C J E FLC J E R T R T R T T + + =
down jacket kitake nagame long length wanpi- su one- piece kata osi embosse d leather ga-ze sozai gauze material siagari finish kisetu kan seasonal look kobana gara floral pattern pointo accent iro zukai coloring pasu ke-su card case B uesuto bubun (waist part) waist konbou sozai (blend material) blend iro oti (faced color) faded look C sodeguti (cuff) hem siruetto bodi- (body silhouette) item features A' F2 L2 C A
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}