Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データベースと応用システム:障害回復
Search
自然言語処理研究室
June 27, 2014
Education
2.5k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データベースと応用システム:障害回復
自然言語処理研究室
June 27, 2014
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
540
データサイエンス12_分類.pdf
jnlp
0
380
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
180
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Education
See All in Education
Soluciones al examen de Geografía 2026. JUNIO (Convocatoria Ordinaria)
juanmartin2026
1
7.1k
Curso de Consagração ao Sagrado Coração de Jesus - O Sagrado Coração na História (Aula 01)
cm_manaus
0
250
Case Studies - Lecture 12 - Information Visualisation (4019538FNR)
signer
PRO
0
190
Data Physicalisation - Lecture 9 - Next Generation User Interfaces (4018166FNR)
signer
PRO
1
1.1k
Estimating Group × Time Interaction in Scale-Transformed CEFR-J Self-Assessment Scores: A Case in Study-Abroad Research
uranoken
0
150
解決策を教えても次期リーダーは育たない ─ 器の発達に伴走するために / Partnering with leaders in their vertical development
matsu0228
1
580
Laura Wilson - The Quarterly PR Pivot
laurawilsonbseo1
1
380
Soluciones al examen de Geografía 2026. JULIO (Convocatoria Extraordinaria)
juanmartin2026
1
16k
Info Session MSc Computer Science & MSc Applied Informatics
signer
PRO
0
300
[2026前期火5] 論理学(京都大学文学部 前期 第2回)「論理的な正しさはどこにあるのか」
yatabe
0
1k
Πλουτοκρατία: Η Τυραννία του Μαμμωνά και η Μεταανθρώπινη Δουλεία
amethyst1
0
280
教育現場から見た Ruby on Rails
yasslab
PRO
0
220
Featured
See All Featured
Abbi's Birthday
coloredviolet
3
8.8k
Done Done
chrislema
186
16k
How to train your dragon (web standard)
notwaldorf
97
6.7k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
430
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
KATA
mclloyd
PRO
35
15k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
470
Building Applications with DynamoDB
mza
96
7.1k
The SEO identity crisis: Don't let AI make you average
varn
0
520
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
Discover your Explorer Soul
emna__ayadi
2
1.2k
Transcript
(c)長岡技術科学大学 電気系 1 データベースと応用システム 障害回復 山本和英 長岡技術科学大学 電気系
(c)長岡技術科学大学 電気系 2 障害の種類と復旧 • トランザクション障害 – データの不備、デッドロック、資源不足、通信障害等 – ロールバックしてやり直し
• システム障害 – ソフトウェアや(データ部以外の)ハードウェアのトラブル – DBの一貫性が保証されるまでロールバック – +コミットしたトランザクションはロールフォワード • メディア(媒体)障害 – データベースの損傷 – バックアップを使って復活
(c)長岡技術科学大学 電気系 3 障害を回復する機能 • ログファイル – すべての操作の履歴記録 • チェックポイント
– メモリとディスクの内容を一致させるタイミング • バックアップ
(c)長岡技術科学大学 電気系 4 ログファイル
(c)長岡技術科学大学 電気系 5 ログファイル(log file) • トランザクションが行った更新などの操作履歴 は、障害に備えてログファイルに記録される – ジャーナルファイル(journal
file)とも呼ぶ • 後退復帰と前進復帰の両者に備える – 更新前ログと更新後ログがある • データベースとログファイルは別のディスクに書き込 む – データベース本体よりも信頼性の高い装置に保存、ある いはログを二重化する
(c)長岡技術科学大学 電気系 6 ログに書きこむ情報 • トランザクション開始・終了ログ • データ挿入 – 更新後データログ
• データ削除 – 更新前データログ • データ更新 – 更新前・更新後データログ • コミット・ロールバックログ
(c)長岡技術科学大学 電気系 7 WALプロトコル (Write Ahead Logging) • データベースの更新よりもログファイルへの記録を 先にする手順
– トランザクション障害が発生してもいいように • 更新処理手順 1.ログファイルへbegin transactionレコードを記録 2.ログファイルへ更新前レコードの記録 3.ログファイルへ更新後レコードの記録 4.データベースの更新 5.commitレコードを記録 6.end transactionレコードを記録
(c)長岡技術科学大学 電気系 8 ロールバックとロールフォワード ロールバック(後退復帰, undo) • トランザクション中で実行したすべての更新を取り 消して、障害回復を行うこと ロールフォワード(前進復帰,
redo) • (バックアップ復旧などの際に)コミット済のトラン ザクションを再実行すること
(c)長岡技術科学大学 電気系 9 障害と処理の関係 • トランザクション障害 – ロールバックしてトランザクション開始時に戻す • システム障害
– コミットされていればロールフォワード – コミットされていなければロールバック • メディア障害 – 交換やバックアップ復元したあとロールフォワード
(c)長岡技術科学大学 電気系 10 チェックポイント
(c)長岡技術科学大学 電気系 11 チェックポイント • データベースの内容は常にディスクに読み書きして いる訳ではなく、一部はメモリ上で更新している。 • よって、メモリとディスクの内容は一致しているとは 限らない。
• DBMSはあるタイミングでチェックポイントを設定し てメモリ上の内容を書き込んでいる。 – 一定時間ごと – 一定のトランザクション実行数ごと – 一定のログ量ごと
(c)長岡技術科学大学 電気系 12 チェックポイントと回復処理の関係 • チェックポイント前にコミット – 回復処理は不要 • チェックポイント後にコミットし、障害発生前
– チェックポイント後の操作をロールフォワード • チェックポイント前に開始し、障害時も実行中 – ロールバック • チェックポイント後に開始し、障害時も実行中 – ロールバック
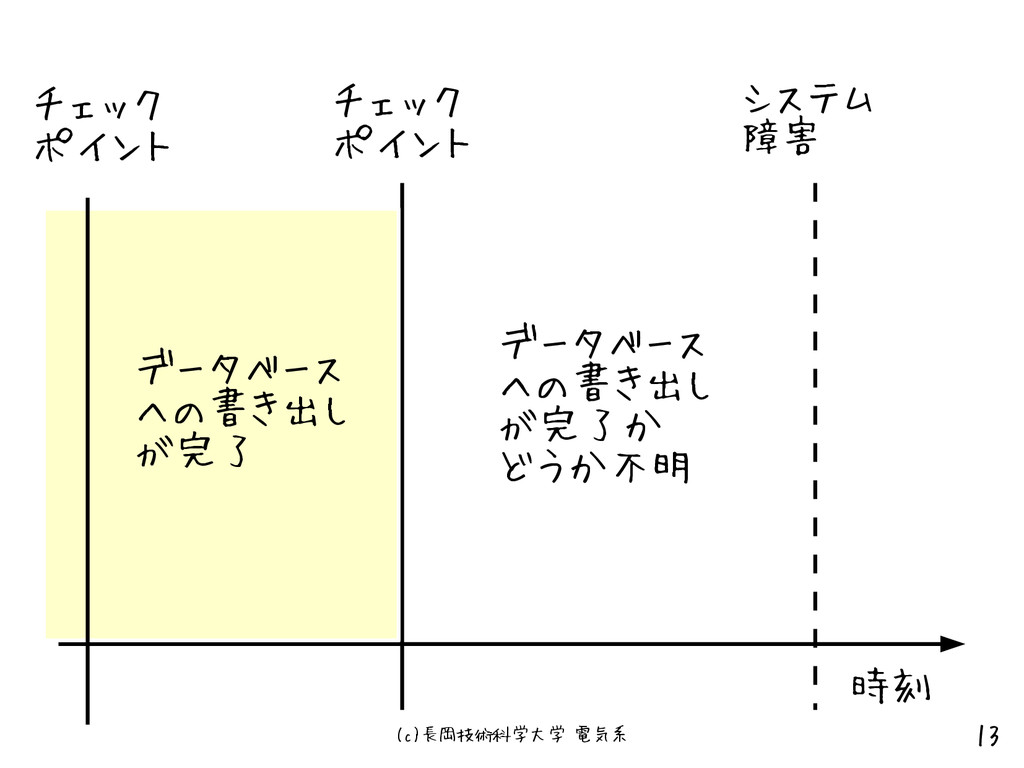
(c)長岡技術科学大学 電気系 13 チェック ポイント システム 障害 データベース への書き出し が完了
データベース への書き出し が完了か どうか不明 チェック ポイント 時刻
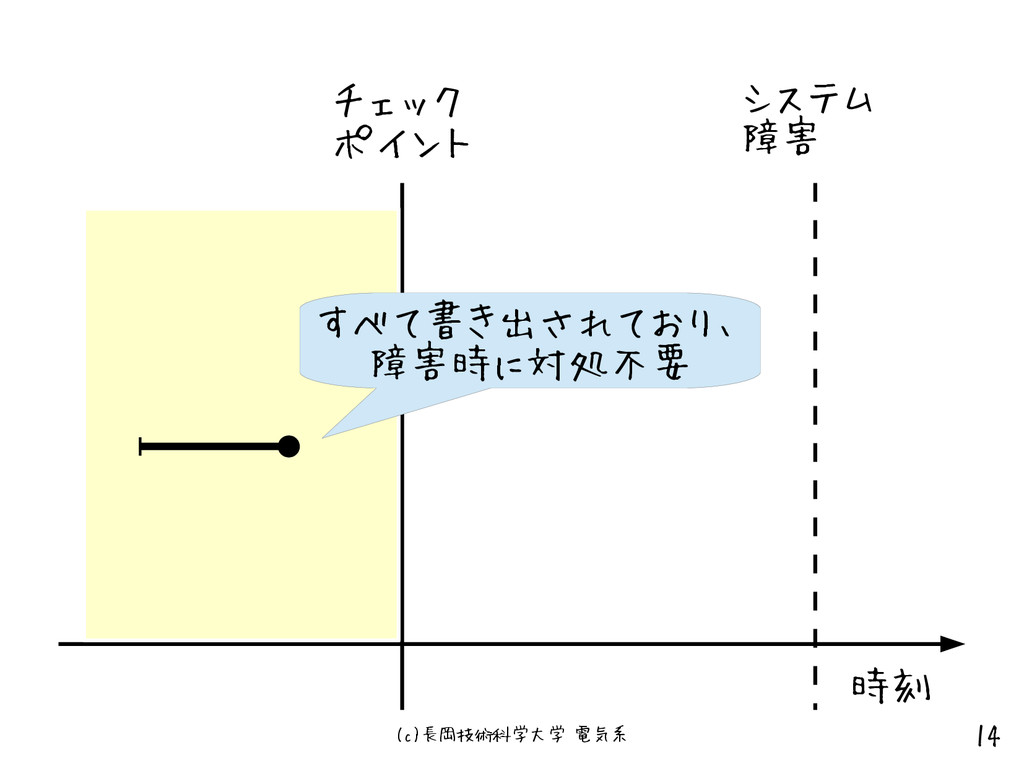
(c)長岡技術科学大学 電気系 14 チェック ポイント システム 障害 すべて書き出されており、 障害時に対処不要 時刻
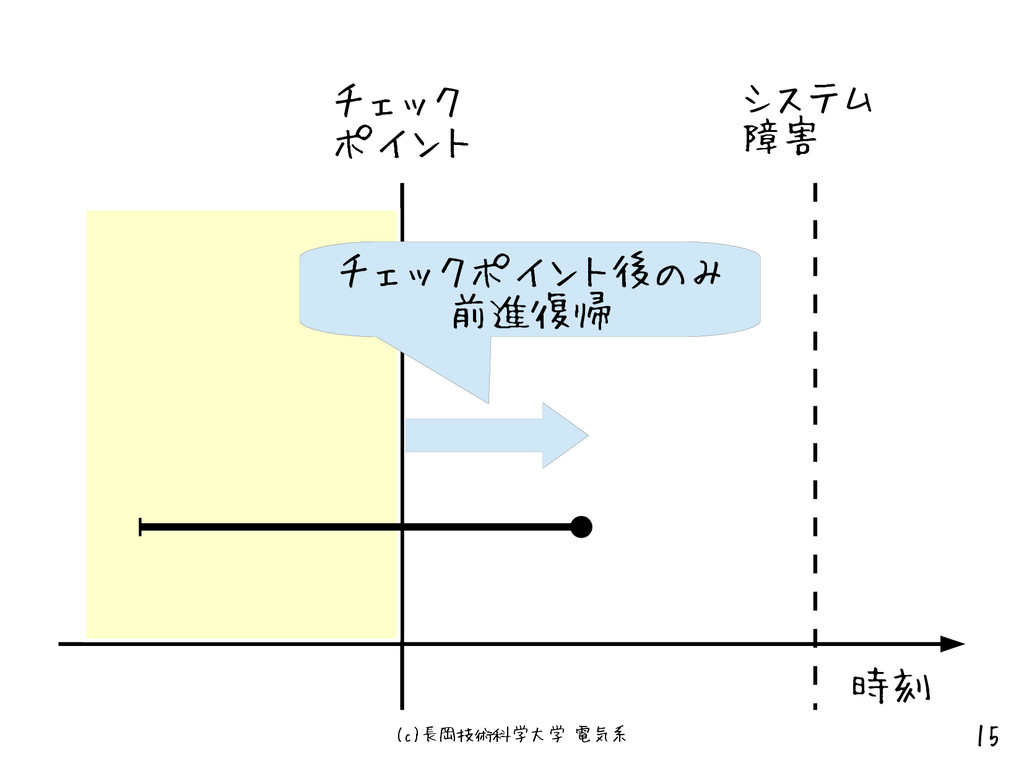
(c)長岡技術科学大学 電気系 15 チェック ポイント システム 障害 チェックポイント後のみ 前進復帰 時刻
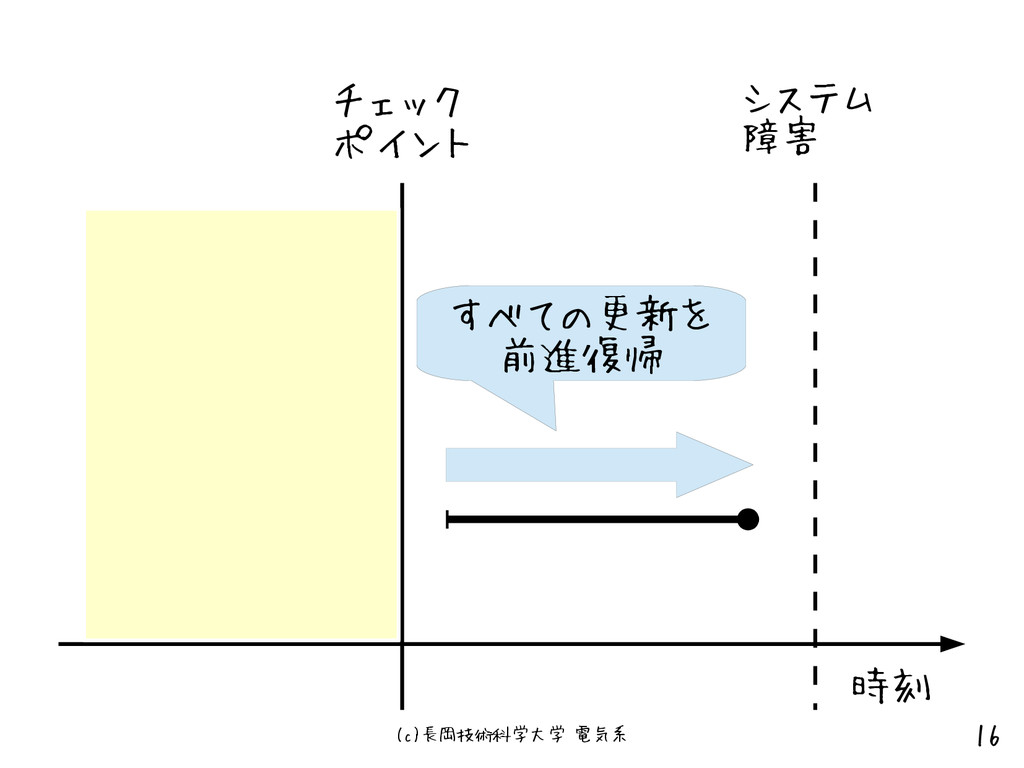
(c)長岡技術科学大学 電気系 16 チェック ポイント システム 障害 すべての更新を 前進復帰 時刻
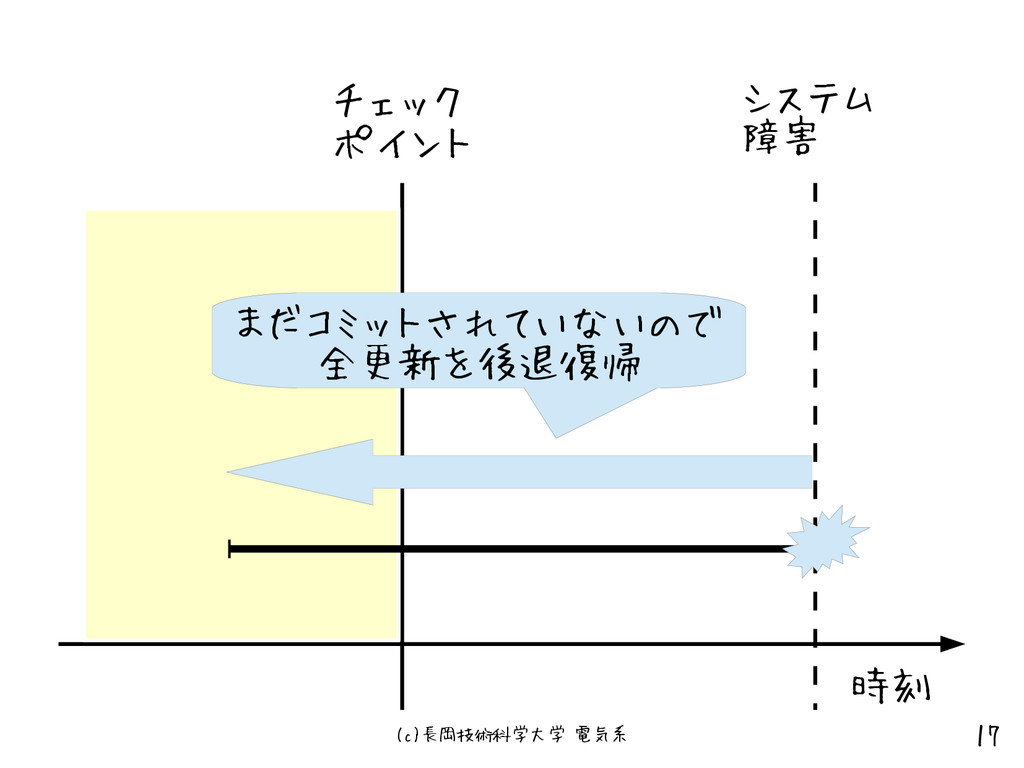
(c)長岡技術科学大学 電気系 17 時刻 チェック ポイント システム 障害 まだコミットされていないので 全更新を後退復帰
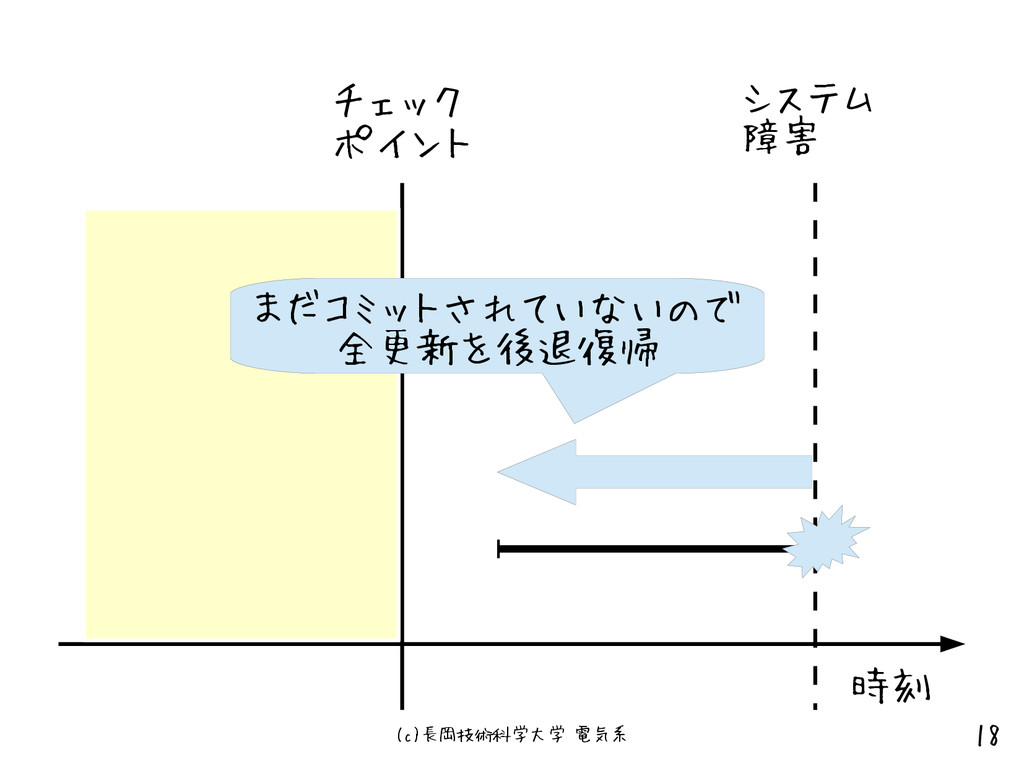
(c)長岡技術科学大学 電気系 18 時刻 チェック ポイント システム 障害 まだコミットされていないので 全更新を後退復帰
(c)長岡技術科学大学 電気系 19 バックアップ
(c)長岡技術科学大学 電気系 20 バックアップ • ある時点でのデータベースのコピーを磁気テープな どに保存すること • システムの障害復旧の他、操作ミスなどに対処する ことが目的
• バックアップ間隔の長さに比例して、ログファイル からの復旧処理時間が長くなる。
(c)長岡技術科学大学 電気系 21 バックアップの種類 • フルバックアップ • 差分バックアップ:フルバックアップからの差分のみ保存 • 増分バックアップ:前回の増分バックアップからの差分の
み保存 • 通常はフルバックアップを定期的(例:週1回)に行い、さ らに細かく差分・増分バックアップを行う(例:毎日)とい う使い分けをする。 • 差分バックアップはバックアップ時間は短く、復旧時間は 長くなる。増分バックアップはさらにこの傾向が顕著。
(c)長岡技術科学大学 電気系 22 メディア障害からの回復 バックアップしてあることが大前提 1.装置の交換 2.バックアップ状態の復元 3.ログファイルを使ってコミットされたすべてのトラン ザクションを前進復帰
(c)長岡技術科学大学 電気系 23 RAID
(c)長岡技術科学大学 電気系 24 RAID • Redundant Array of Inexpensive Disks
• データを複数のHDDに冗長に記録する仕組み • 1987年UCB(University of California, Berkeley)のDavid A. Pattersonらの論文 • 当初は RAID1~RAID5で、その後 RAID0とRAID6が 追加された
(c)長岡技術科学大学 電気系 25 RAID0(ストライピング) • 複数のディスクを見かけ上連結させて、ひとつの ディスクに見せる • ディスク容量の効率的な利用が可能 •
複数ディスクのどれかが故障するとすべて損失 – 信頼性の向上には無関係
(c)長岡技術科学大学 電気系 26 RAID1(ミラーイング) • ディスクの二重化 • どちらかのディスクが故障してもデータは保持され る。
(c)長岡技術科学大学 電気系 27 RAID5 • RAID0と同様にデータを複数のディスクに分散して書き込 むが、この際に(今データを書いたディスクとは別の)ディ スクにパリティ(誤り訂正符号)も書き込む。 – パリティを書き込むディスクは毎回変える
• これによって、例えば4ディスクで3ディスク分の容量を書 き込みできる。 • どれか1ディスクが故障してもデータは保持される – 2ディスク以上が故障したら終わり • ディスクが分散されているので、読み込み速度は速い – パリティを計算するため書き込み速度は比較的遅い
(c)長岡技術科学大学 電気系 28 その他のRAID • RAID2、3、4、6 – 定義されているが、実用上はあまり使われない • RAID10
(RAID1+0) – RAID1と0の組み合わせ。最低4ディスク必要 • RAID50 (RAID5+0) – RAID5と0の組み合わせ。最低6ディスク必要
(c)長岡技術科学大学 電気系 29 RAID関連技術 ホットスワップ(hot swap) • システムを停止させることなく(=通電したままで) ディスクを交換することができる処理・技術 –
自動でアクセス停止して電気信号を切り離す等 ホットスペア(hot spare)/ホットスタンバイ • ディスクの故障に備えて、予備のディスクを通電状 態で待機させておく技術 • 故障した機器は自動で切り離し、予備のディスクの 動作を自動で開始する
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}