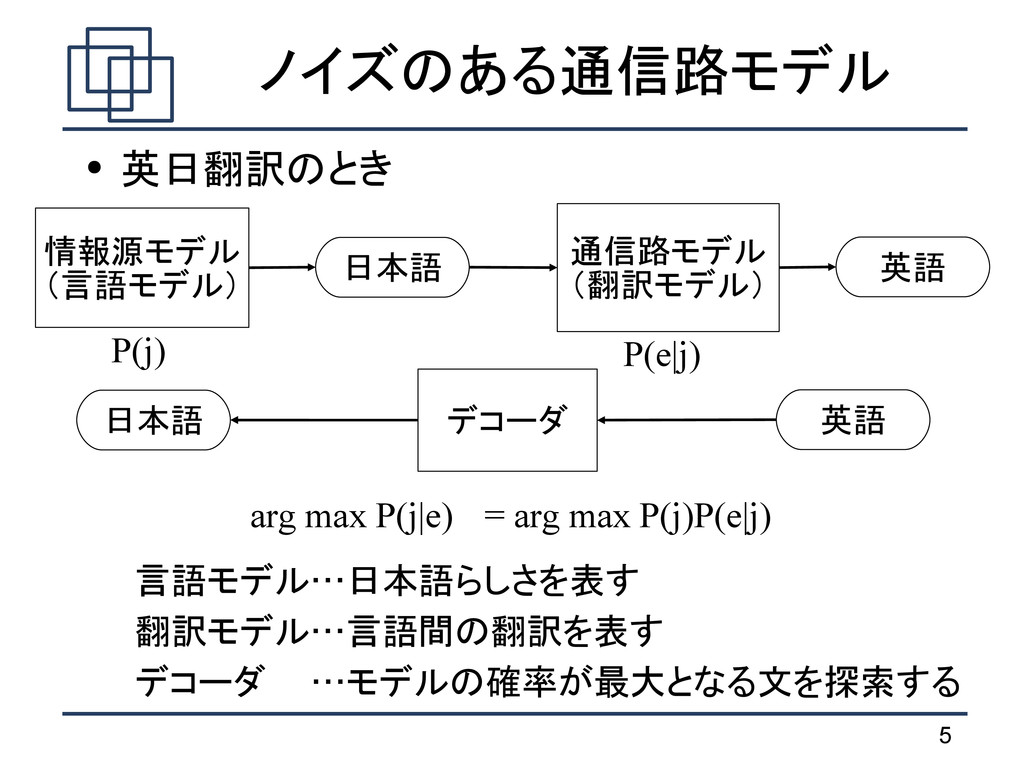
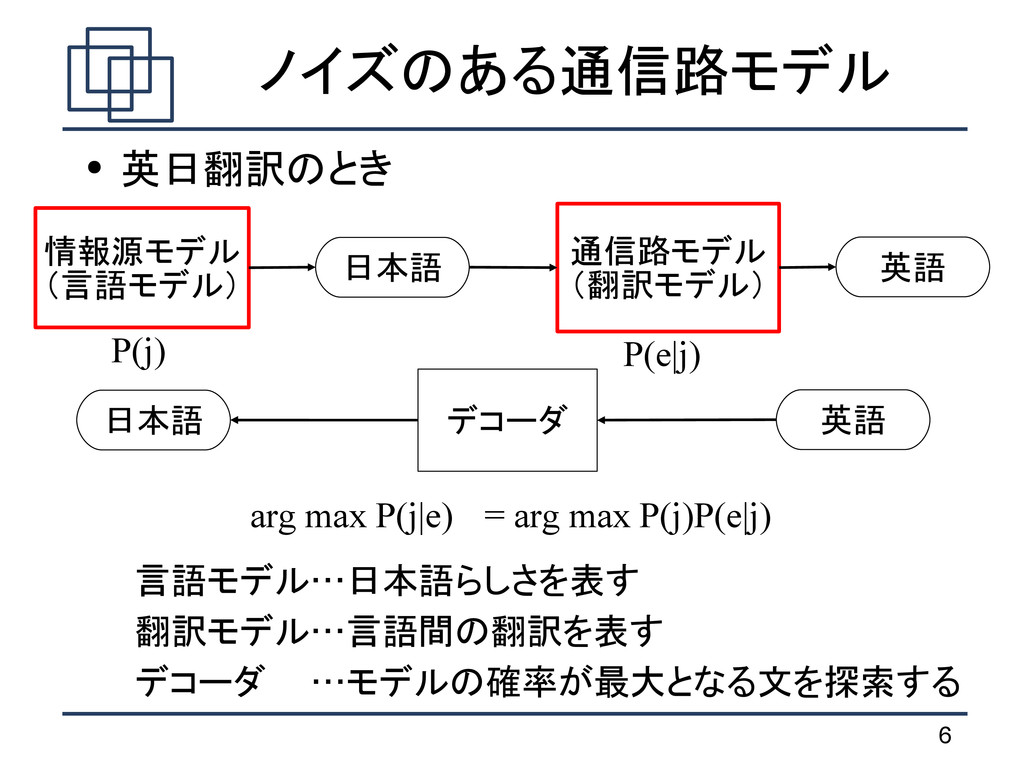
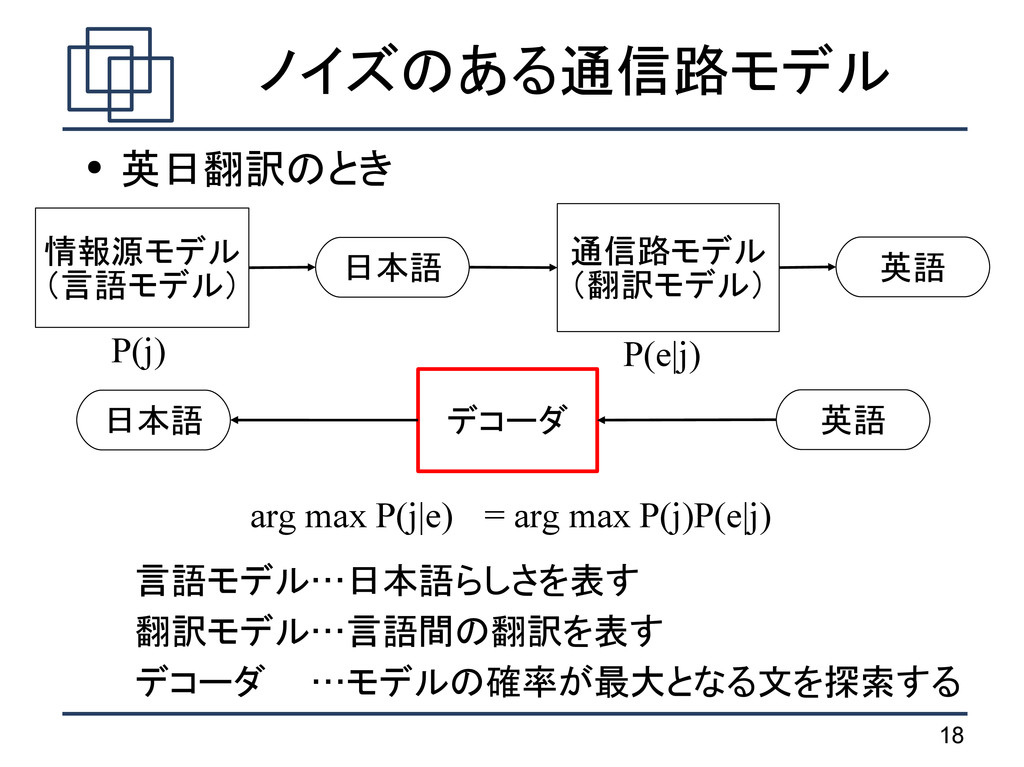
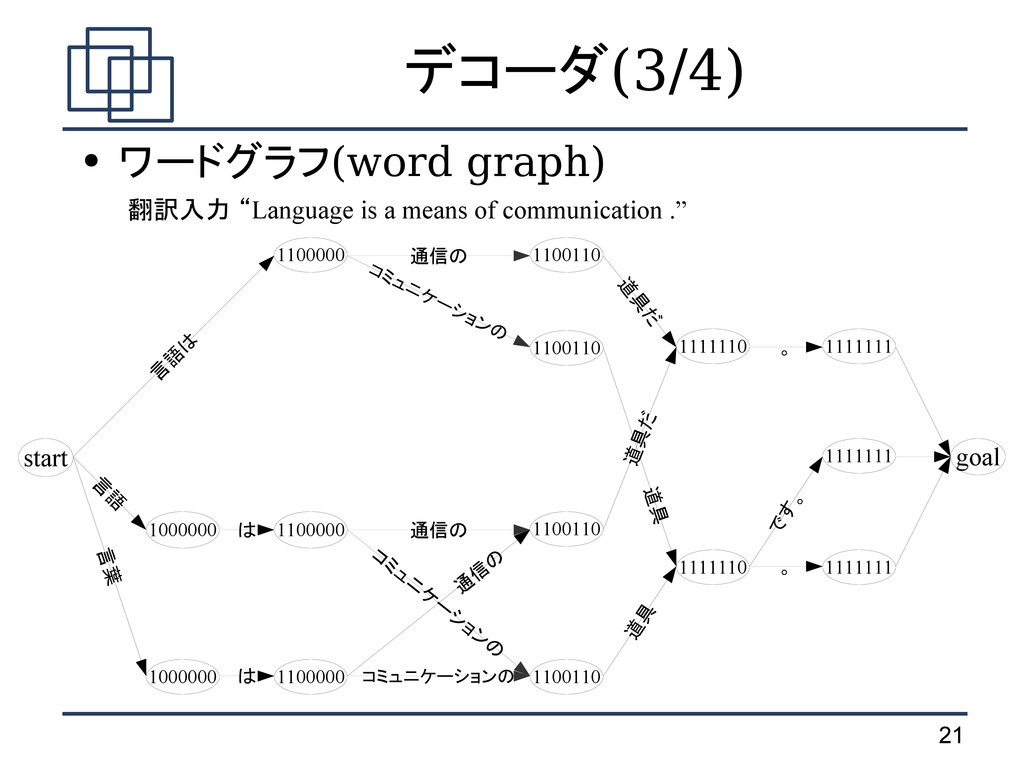
は句 に分解される argmax j pe∣j p j e 1 I p e 1 I∣ j 1 I =∏ i=1 I e i ∣ j i d a i −b i−1 e i ∣ j i d a i −b i−1 翻訳確率 歪み確率 j 1 I ノイズのある通信路モデル
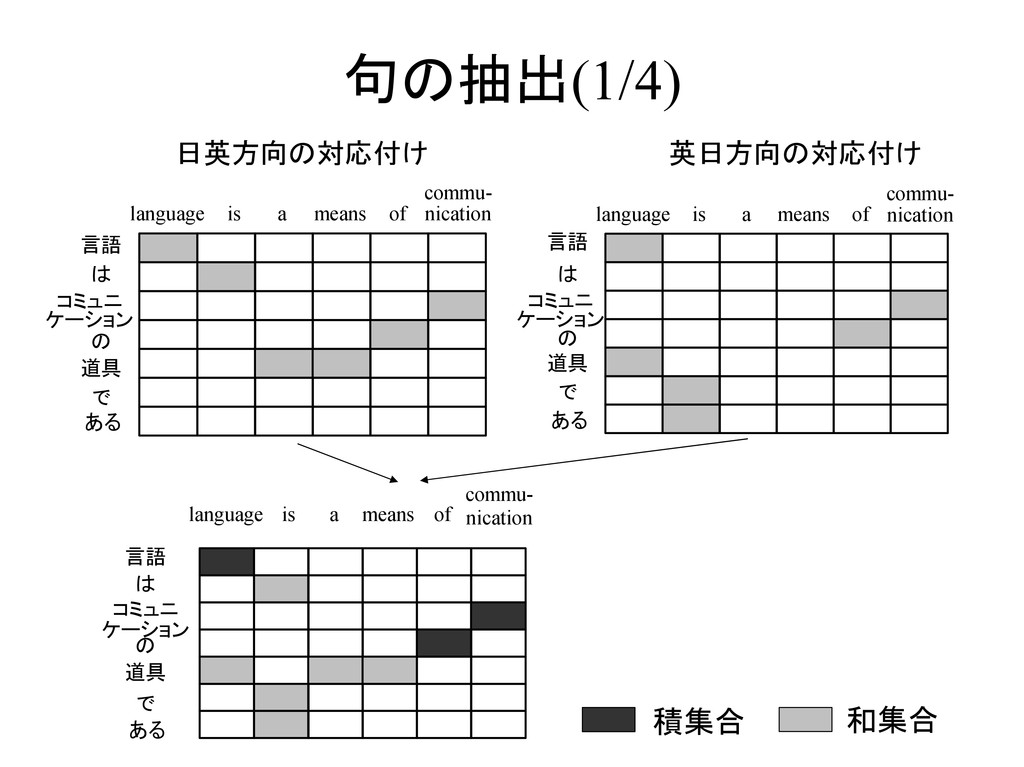
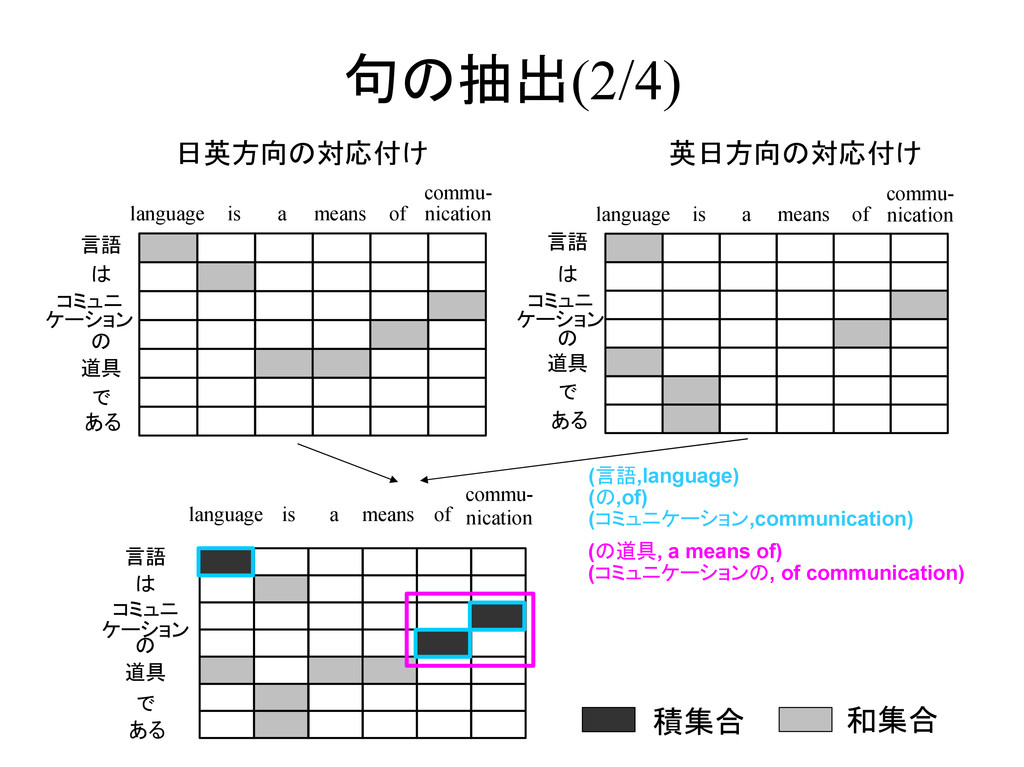
is a means commu- nication of 言語 は コミュニ ケーション の 道具 で ある language is a means commu- nication of 日英方向の対応付け 英日方向の対応付け 積集合 和集合 言語 は コミュニ ケーション の 道具 で ある language is a means commu- nication of
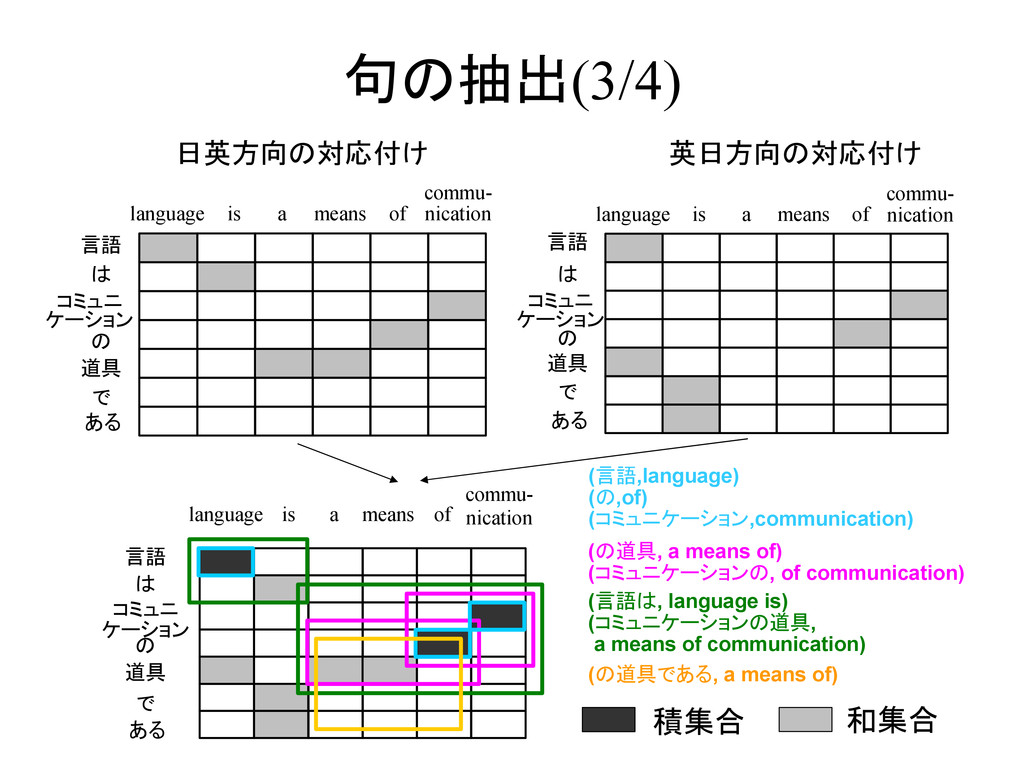
is a means commu- nication of 言語 は コミュニ ケーション の 道具 で ある language is a means commu- nication of 日英方向の対応付け 英日方向の対応付け (言語,language) (の,of) (コミュニケーション,communication) (の道具, a means of) (コミュニケーションの, of communication) 積集合 和集合 言語 は コミュニ ケーション の 道具 で ある language is a means commu- nication of
is a means commu- nication of 言語 は コミュニ ケーション の 道具 で ある language is a means commu- nication of 日英方向の対応付け 英日方向の対応付け (言語,language) (の,of) (コミュニケーション,communication) (の道具, a means of) (コミュニケーションの, of communication) (言語は, language is) (コミュニケーションの道具, a means of communication) 積集合 和集合 言語 は コミュニ ケーション の 道具 で ある language is a means commu- nication of (の道具である, a means of)
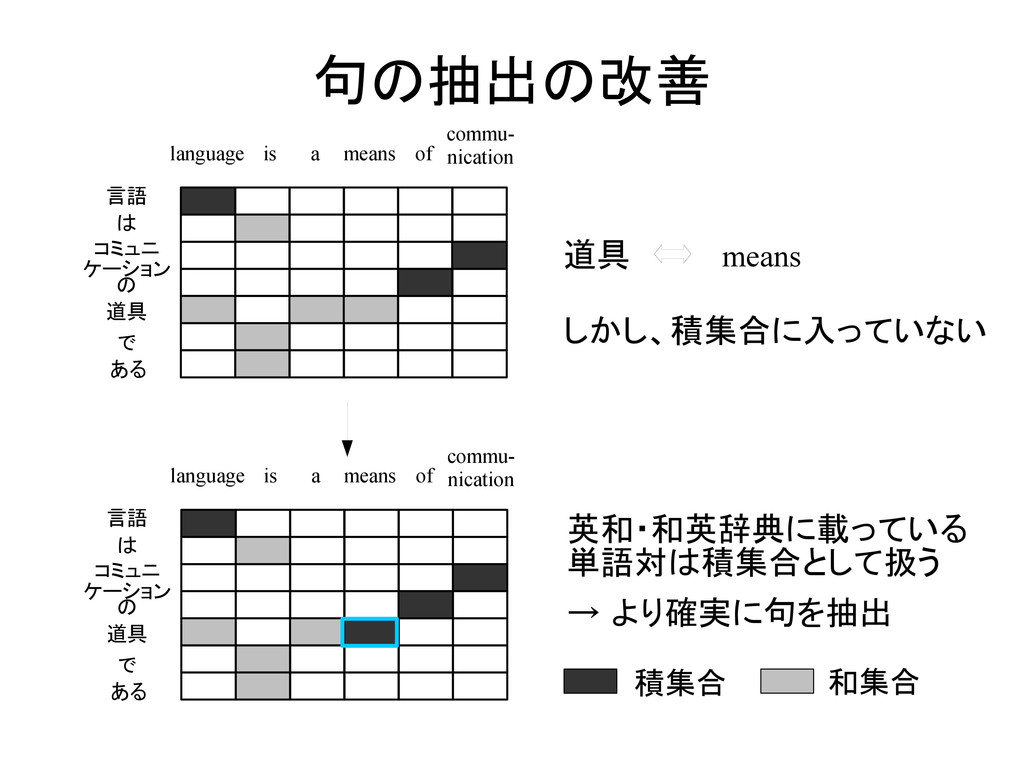
ある language is a means commu- nication of 英和・和英辞典に載っている 単語対は積集合として扱う → より確実に句を抽出 言語 は コミュニ ケーション の 道具 で ある language is a means commu- nication of 道具 means しかし、積集合に入っていない
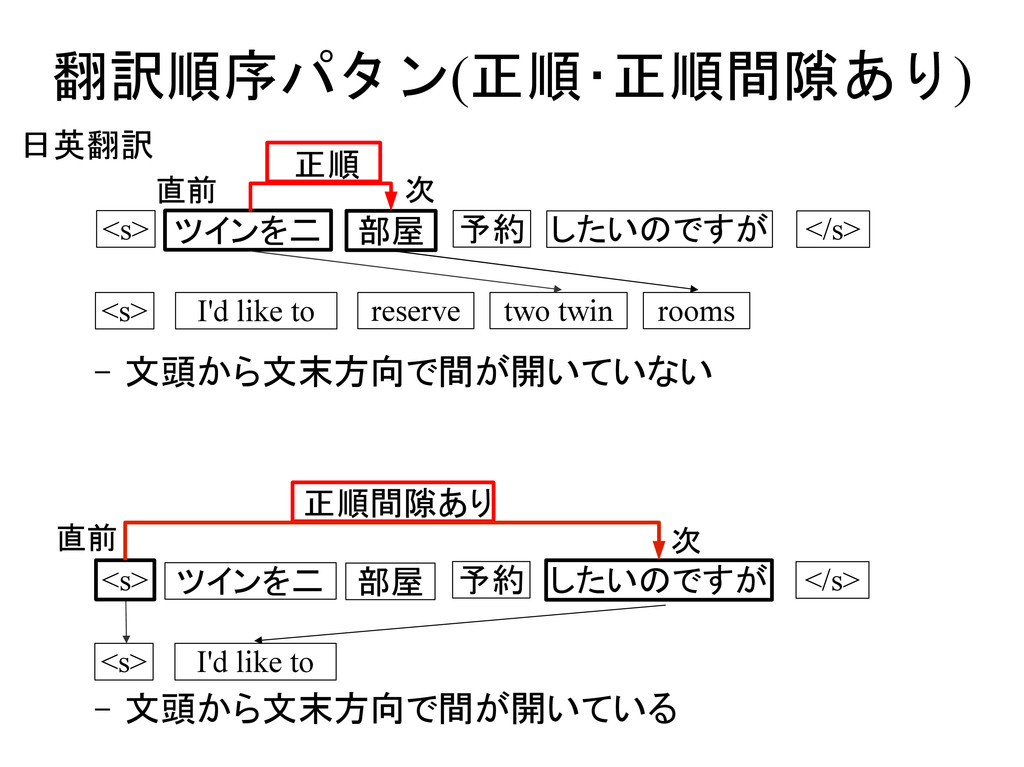
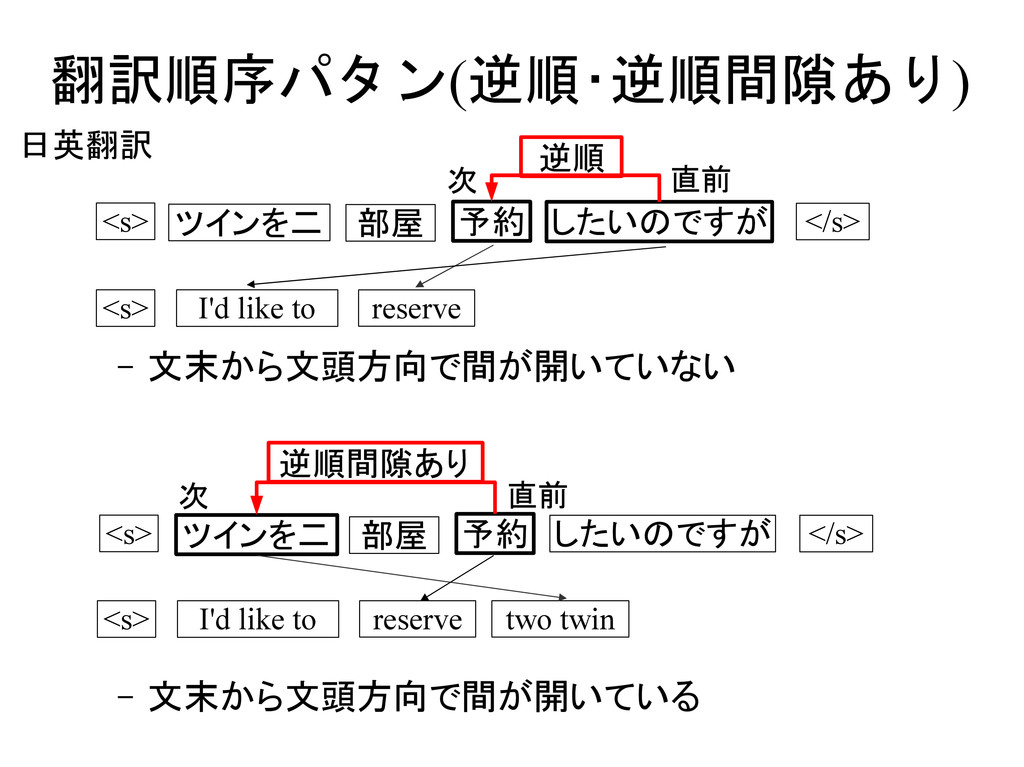
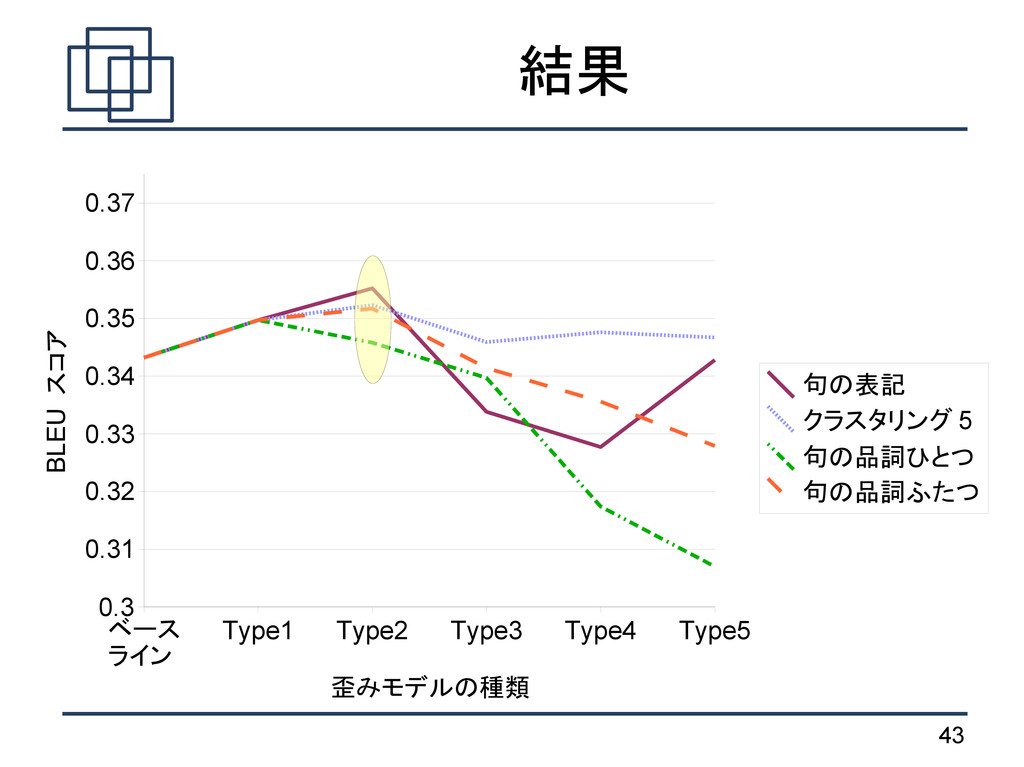
i−1 , f i pd pd∣ e i−1 , f i−1 , f i pd∣ e i−1 , e i , f i−1 , f i Type1: Type2: Type3: Type4: Type5: 翻訳元言語 翻訳先言語 e i−1 f i−1 f i e i ツインを二 予約 I'd like to two twin <s> <s> </s> したいのですが reserve 部屋 rooms 正順 直前 次 e i−1 e i f i−1 f i 語に基づく翻訳モデルにおける 歪みモデルとのアナロジー d j− j'∣classe i−1 ,class f j d j− j'∣class f j
Type 3 -1 あいつ を 捕まえ て .|0.4|2 -1 あそこ for the two girls|1|2 -1 あそこ we can buy cds cheaper|1|1 -1 あそこ に ある レストラン do you see|1|1 pd∣ e i−1 , f i pd
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}