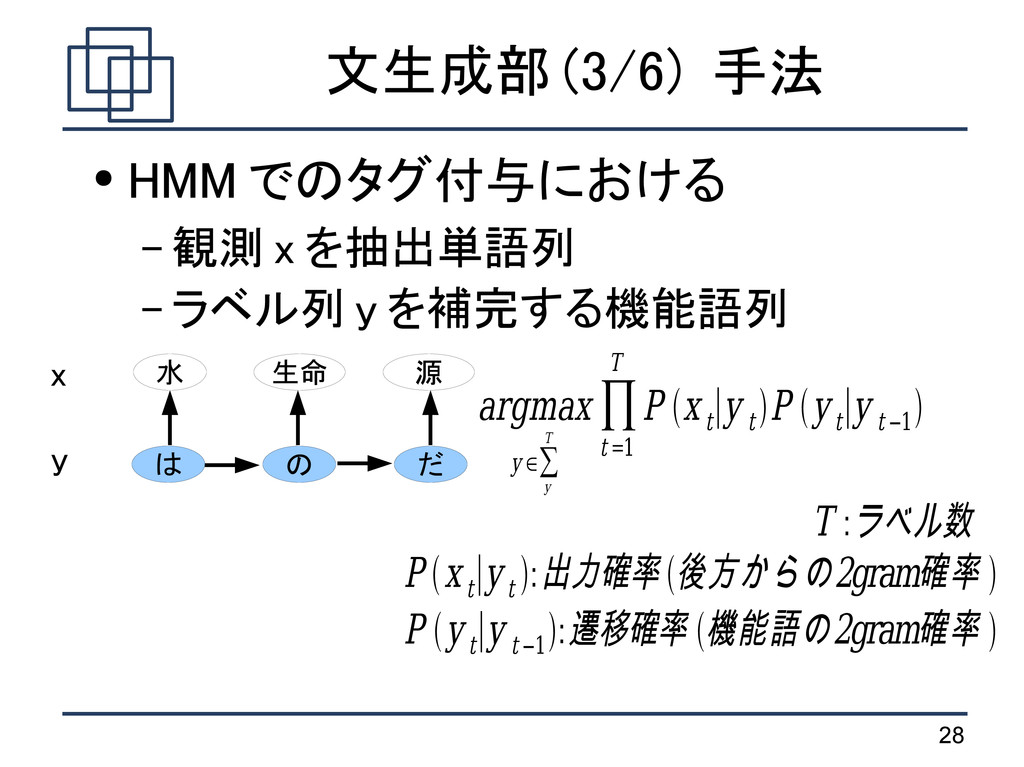
を抽出単語列 – ラベル列 y を補完する機能語列 水 は 生命 の 源 だ x y argmax y ∈∑ y T ∏ t =1 T P x t ∣y t P y t ∣y t −1 T :ラベル数 P x t ∣y t :出力確率 2gram 後方からの 確率 P y t ∣y t −1 :遷移確率 2gram 機能語の 確率
∈∑ y T ∏ t =1 T P x t ∣y t P y t ∣y t −1 = argmin y ∈∑ y T ∑ t=q T {C x t ∣y t C y t ∣y t−1 } T :ラベル数 P x t ∣y t :出力確率 2gram 後方からの 確率 P y t ∣y t −1 :遷移確率 2gram 機能語の 確率 C x t ∣y t : P x t ∣y t のコスト化した値 対数の絶対値
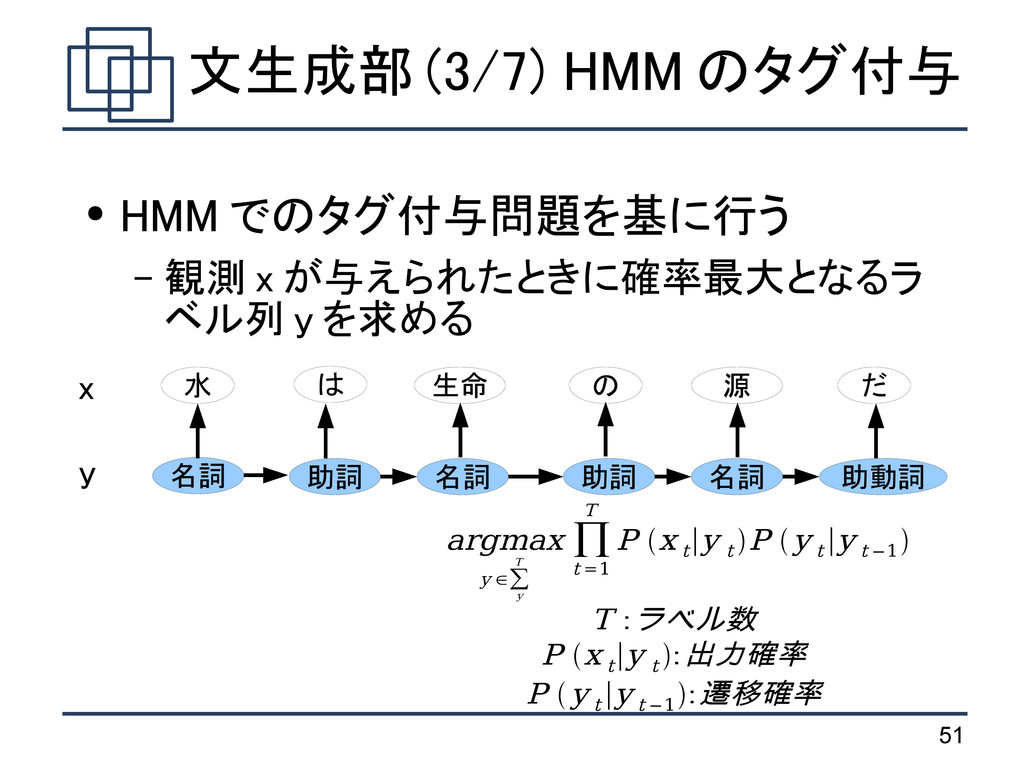
x が与えられたときに確率最大となるラ ベル列 y を求める 水 は 生命 の 源 だ 名詞 名詞 名詞 助詞 助詞 助動詞 x y argmax y ∈∑ y T ∏ t =1 T P x t ∣y t P y t ∣y t −1 T :ラベル数 P x t ∣y t :出力確率 P y t ∣y t −1 :遷移確率
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}