Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
素性の相対性による分布類似度計算
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
自然言語処理研究室
March 31, 2010
Research
80
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
素性の相対性による分布類似度計算
朝倉 剛史. 素性の相対性による分布類似度計算. 長岡技術科学大学課題研究報告書 (2010.3)
自然言語処理研究室
March 31, 2010
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
410
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
120
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
LiDAR点群の地表面分類手法の比較・検証
vegapunkhiroshi79
0
120
2026 東京科学大 情報通信系 研究室紹介 (すずかけ台)
icttitech
0
3.8k
正規分布と最適化について
koide3
1
260
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
160
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
640
2026-01-30-MandSL-textbook-jp-cos-lod
yegusa
1
1.3k
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
610
LLM Compute Infrastructure Overview
karakurist
2
1.4k
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
520
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
200
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
290
Featured
See All Featured
WCS-LA-2024
lcolladotor
0
640
Design in an AI World
tapps
1
240
ラッコキーワード サービス紹介資料
rakko
1
3.7M
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
230
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
KATA
mclloyd
PRO
35
15k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
Documentation Writing (for coders)
carmenintech
77
5.4k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
The Language of Interfaces
destraynor
162
27k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
290
Transcript
素性の相対性による 分布類似度計算 長岡技術科学大学 電気電子情報工学課程 山本研究室 07310586 朝倉 剛史 1
発表の流れ 1.研究の背景 2.分布類似度とは 3.既存研究とその問題 4.提案手法の説明 5.実験及び考察 6.まとめ 2
発表の流れ 3 1.研究の背景 2.分布類似度とは 3.既存研究とその問題 4.提案手法の説明 5.実験及び考察 6.まとめ
背景 電子文書の増加に伴い、 機械処理の必要性が高まっている。 自動言い換え、テキスト分類などのため、 類似する単語を求めたい。 単語の類似度計算の必要性が高まっている。 4 1.研究の背景
類似する単語とは? 類似する単語は意味的に近いことを表す。 例えるならば、『醤油』と『味噌』は、調味料 の仲間であり、意味的に近い。 →類似度は高い しかし、『醤油』と『石』は、全く意味が違うも のであり、意味的に遠い。 →類似度は低い 5 1.研究の背景
類似度計算 シソーラスを用いた手法 単語の関係を人手で構築したシソーラス から、単語同士の関係を導き出す。 コーパスを用いた手法 単語のコーパスでの使われ方を比較して、 自動で単語同士の関係を導き出す。 →近年コーパスを用いた手法に注目 ⇒分布類似度 6
1.研究の背景
発表の流れ 7 1.研究の背景 2.分布類似度とは 3.既存研究とその問題 4.提案手法の説明 5.実験及び考察 6.まとめ
分布類似度とは? 「類似した文脈を持つ語は似ている」 という『分布仮説』に基づいた考え方。 単語が出現する文脈がどれだけ似ている かで、単語の類似度を計算する。 文脈を表す要素を素性として使用する → 単語の係り先など 8 2.分布類似度とは
分布類似度~例1~ ある単語と、その素性が以下の通りとする 『醤油』 「の:香り」「の:原料」「を:製造」・・・ 『味噌』 「の:香り」「の:原料」「を:製造」・・・ →単語の係り先で共通する部分が多い 類似度が高い! 9 2.分布類似度とは
分布類似度~例2~ ある単語と、その素性が以下の通りとする 『醤油』 「の:香り」「の:原料」「を:製造」・・・ 『石』 「を:投げる」「を:蹴る」「の:色」・・・ →単語の係り先で共通する部分が少ない 類似度が低い! 10 2.分布類似度とは
▪『醤油』 「の:香り」「の:原料」「を:製造」 「の:道」「を:投げる」 ・・・ ▪『味噌』 「の:香り」「の:原料」「を:製造」 「から:行く」「を:投げる」・・・ ▪『石』 「を:投げる」「を:蹴る」「の:色」「の:紙」「を:ゴミ」・・・ 素性の問題
類似度計算に悪影響を及ぼすものも多い! →素性選択の必要性 11 2.分布類似度とは
発表の流れ 12 1.研究の背景 2.分布類似度とは 3.既存研究とその問題 4.提案手法の説明 5.実験及び考察 6.まとめ
▪『醤油』 「の:香り」「の:原料」「を:製造」 「の:道」「を:投げる」 ・・・ ▪『味噌』 「の:香り」「の:原料」「を:製造」 「から:行く」「を:投げる」・・・ ▪『石』 「を:投げる」「を:蹴る」「の:色」「の:紙」「を:ゴミ」・・・ 既存研究の素性選択
13 3.既存研究とその問題 各単語の素性について、単語の特徴を強く 表している要素以外は一律に除外[相澤(08)]。
問題点 ▪『醤油』 「の:香り」「の:原料」「を:製造」 「の:道」「を:投げる」 ・・・ ▪『味噌』 「の:香り」「の:原料」「を:製造」 「から:行く」「を:投げる」・・・ ▪『石』 「を:投げる」「を:蹴る」「の:色」「の:紙」「を:ゴミ」・・・
単語の特徴を強く表さない要素が共通している場合、 2単語間の類似度計算に有効であると考える。 →除外されることで精度に影響を与える。 14 3.既存研究とその問題
提案手法 比較対象の単語の素性を用いて 相対的に素性を取捨選択する 素性の各要素について、比較対象の単語と 共通している要素に関して、 既存手法:特徴を強く表すかどうか 提案手法:特徴を表す度合いが近いかどうか で取捨選択を行う。 15 3.既存研究とその問題
予想される効果 16 3.既存研究とその問題 ▪『醤油』 「の:香り」「の:原料」「を:製造」 「の:道」「を:投げる」 ・・・ ▪『味噌』 「の:香り」「の:原料」「を:製造」 「から:行く」「を:投げる」・・・
▪『石』 「を:投げる」「を:蹴る」「の:色」「の:紙」「を:ゴミ」・・・ 例えば『醤油』と『味噌』の時は「を:投げる」を 除外しないため、有効な要素を残すことが可能 どちらも特徴を表していないが、 その度合いが近いので有効
予想される効果 ▪『醤油』 「の:香り」「の:原料」「を:製造」 「の:道」「を:投げる」 ・・・ ▪『味噌』 「の:香り」「の:原料」「を:製造」 「から:行く」「を:投げる」・・・ ▪『石』 「を:投げる」「を:蹴る」「の:色」「の:紙」「を:ゴミ」・・・
例えば『醤油』と『石』の時は「を:投げる」を 除外するため、不要な要素を除外することが可能 3.既存研究とその問題 17 『石』では特徴を強く表しているが、 その度合いが遠いので無効
発表の流れ 1.研究の背景 2.分布類似度とは 3.既存研究とその問題 4.提案手法の説明 5.実験及び考察 6.まとめ 18
手法の流れ (1) 単語の素性を自動収集 (2) 集めた素性の足切り (3) 素性の特徴量を求める (4) 特徴量を考慮した素性選択(←本手 法)
(5) 関数を用いた類似度計算 19 4.提案手法の説明
手法の流れ(1/5) (1) 単語の素性を自動収集 (2) 集めた素性の足切り (3) 素性の特徴量を求める (4) 特徴量を考慮した素性選択 (5)
関数を用いた類似度計算 20 4.提案手法の説明
単語の素性を自動収集 コーパスより、ある単語wとw’が格要素rで繋がっ ている三つ組(w,r,w’) を収集する[Lin98]。 例)「お金,が,必要」 「EU,に,加盟」 例えば、『お金』の共起要素を「が:必要」とし、全て の単語wについて、共起要素を収集し、素性を作成 する。 21
4.提案手法の説明
手法の流れ(2/5) (1) 単語の素性を自動収集 (2) 集めた素性の足切り (3) 素性に特徴量を求める (4) 特徴量を考慮した素性選択 (5)
関数を用いた類似度計算 22 4.提案手法の説明
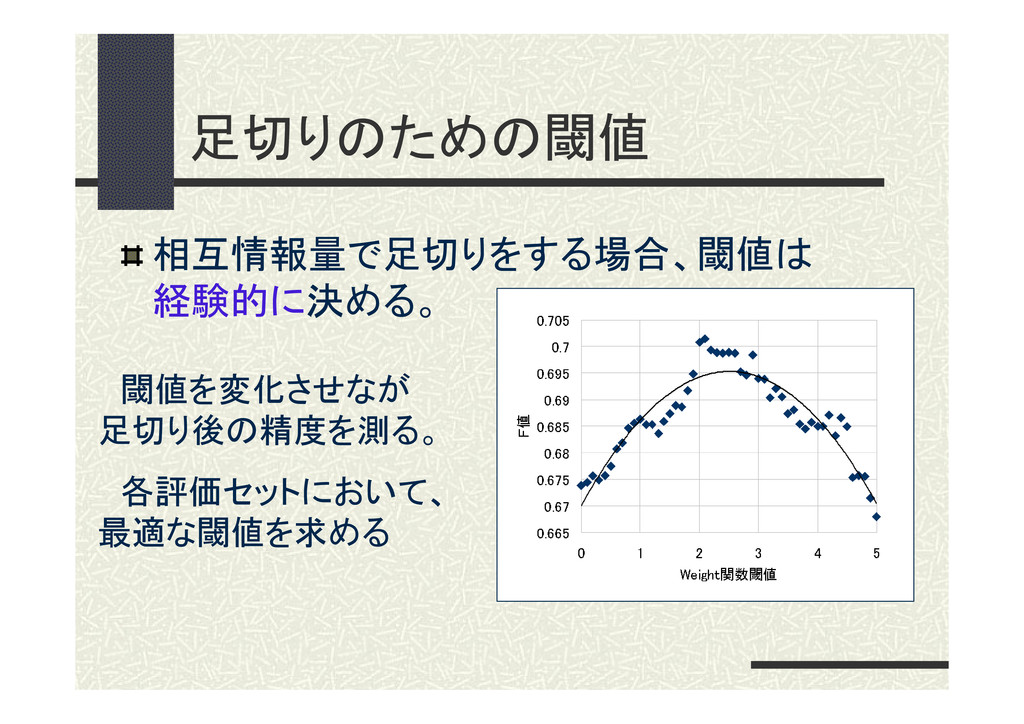
集めた素性の足切り あきらかにノイズと判断されるようなものは、 あらかじめ足切りしておく。 共起要素の出現頻度を用いて、相互情報量 (MI)が閾値βに満たないものは、除外する。 閾値βは評価セットによって異なり、経験的 に決める[相澤(08)]。 23 4.提案手法の説明
手法の流れ(3/5) (1) 単語の素性を自動収集 (2) 集めた素性の足切り (3) 素性の特徴量を求める (4) 特徴量を考慮した素性選択 (5)
関数を用いた類似度計算 24 4.提案手法の説明
素性の特徴量を求める 特徴量=共起要素が単語wの特徴を表す度合い 分類語彙表を用いて単語wの類義語集合を作成する。 ▪例:『少年』の類義語 →「子供」「少女」「児童」「女の子」「青少年」 その類義語集合の中で共通する共起要素ほど、特徴 量を高くする[Zhitomirisky-Geffet and Dagan(09)]。 25
4.提案手法の説明
特徴量の計算例 『少年』と類義語集合の各語と類似度を求める。 「子供(0.13)」「少女(0.27)」「児童(0.14)」 「女の子(0.14)」「青少年(0.15)」 『少年』の共起要素「を:保護」が、『子供』『少女』『児 童』に含まれる場合、「を:保護」の『少年』における特 徴量は 特徴量=0.13+0.27+0.14=0.54 単語ごとに、最大値を1として正規化する。 26
4.提案手法の説明
手法の流れ(4/5) (1) 単語の素性を自動収集 (2) 集めた素性の足切り (3) 素性の特徴量を求める (4) 特徴量を考慮した素性選択 (5)
関数を用いた類似度計算 27 4.提案手法の説明
特徴量を考慮した素性選択 ▪『醤油』 「の:香り(1.0)」「の:原料(0.9)」「を:製造(0.8)」 「の:道(0.4)」「を:投げる(0.1)」・・・ ▪『味噌』 「の:香り(1.0)」「の:原料(0.8)」「を:製造(0.7)」 「から:行く(0.4)」「を:投げる(0.1)」・・・ 28 4.提案手法の説明 比較対象の単語の素性と比較する。
共通している要素について特徴量の差が大きければ 除外し、小さければ除外しない。 特徴量が小さくても差も小さいため除外しない ※数字は特徴量
手法の流れ(5/5) (1) 単語の素性を自動収集 (2) 集めた素性の足切り (3) 素性の特徴量を求める (4) 特徴量を考慮した素性選択 (5)
関数を用いた類似度計算 29 4.提案手法の説明
関数を用いた類似度計算 素性の重なりを見る関数である以下の関数 を使用する。 これらの関数を相加平均した値を類似度と する[柴田ら(09)]。 30 4.提案手法の説明
発表の流れ 1.研究の背景 2.分布類似度とは 3.既存研究とその問題 4.提案手法の説明 5.実験及び考察 6.まとめ 31
実験条件 使用したコーパス 日本経済新聞全記事データーベース 1990-2004年度版 使用した単語数 ※共起要素数が20以上 40,678語 平均共起要素数 114.2個(最小20、最大20,205) 32
5.実験及び考察
評価セットの自動作成 コーパスから「AやB」という定型表現を収集、 「A:B」を類義語候補にする[相澤(08)]。 「A:B」より、分類語彙表を用いて「強」「中」 「弱」「非」類義語ペアを作成し、各800ペアづ つランダムにサンプリングする。 各ペアを「強+中」「中+弱」「弱+非」で組み 合わせ、評価セットとする。 5.実験及び考察 33
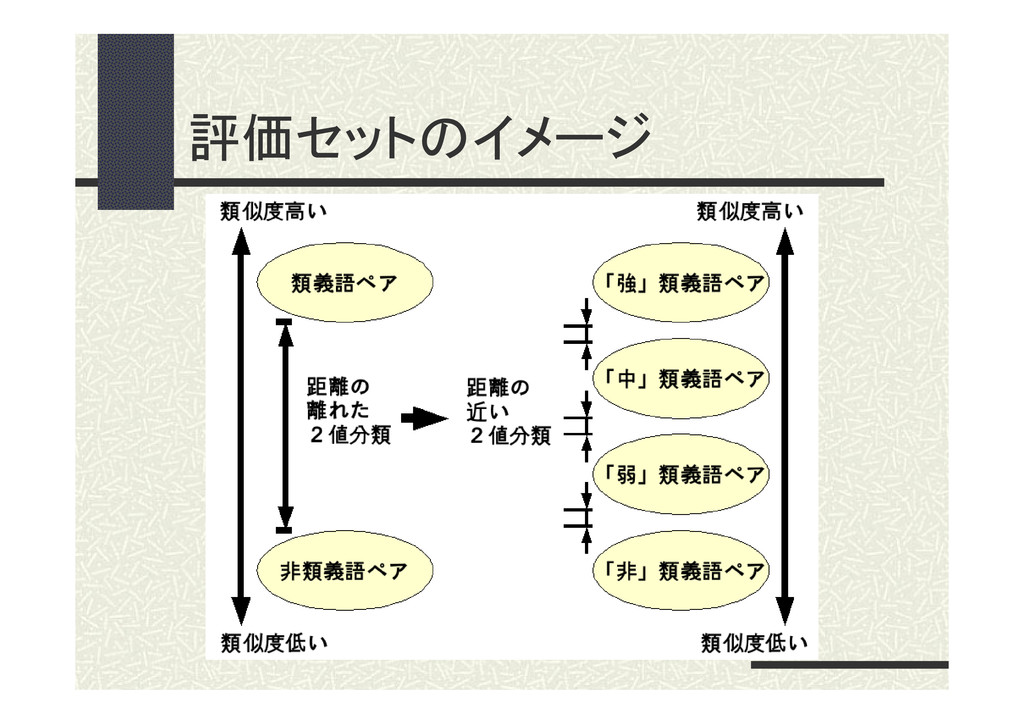
評価方法 類似度水準の違う類義語ペアを、 類似度計算した結果で2値分類する。 「 強 」 類 義 語 ペ
ア 集 合 「 中 」 類 義 語 ペ ア 集 合 判定閾値 類似度高 類似度低 34 5.実験及び考察 類義語ペア 類 似 度 「強」 「中」
実験 実験は3手法を比較した。 (1)柴田らの手法 相互情報量による足切りのみ行い類似度計算 (2)Zhitomirisky-Geffet and Daganの手法 特徴量を求め、その値で一律に除外 (3)本手法 特徴量を、比較対象と共通部分について値の差
を見ることで、素性を相対的に取捨選択 5.実験及び考察 35
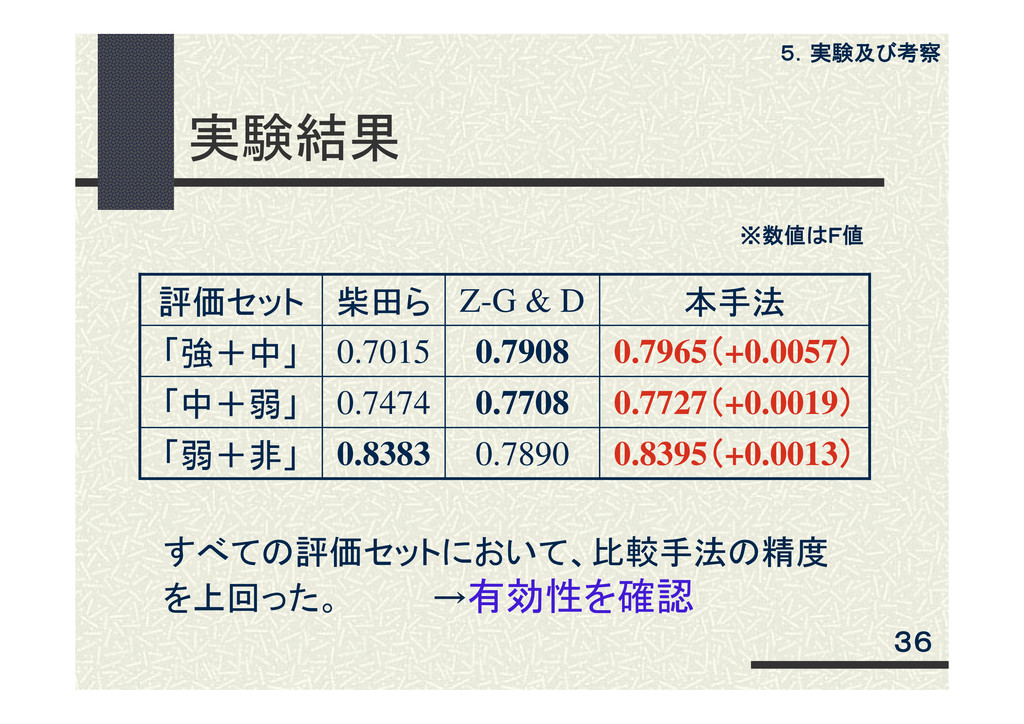
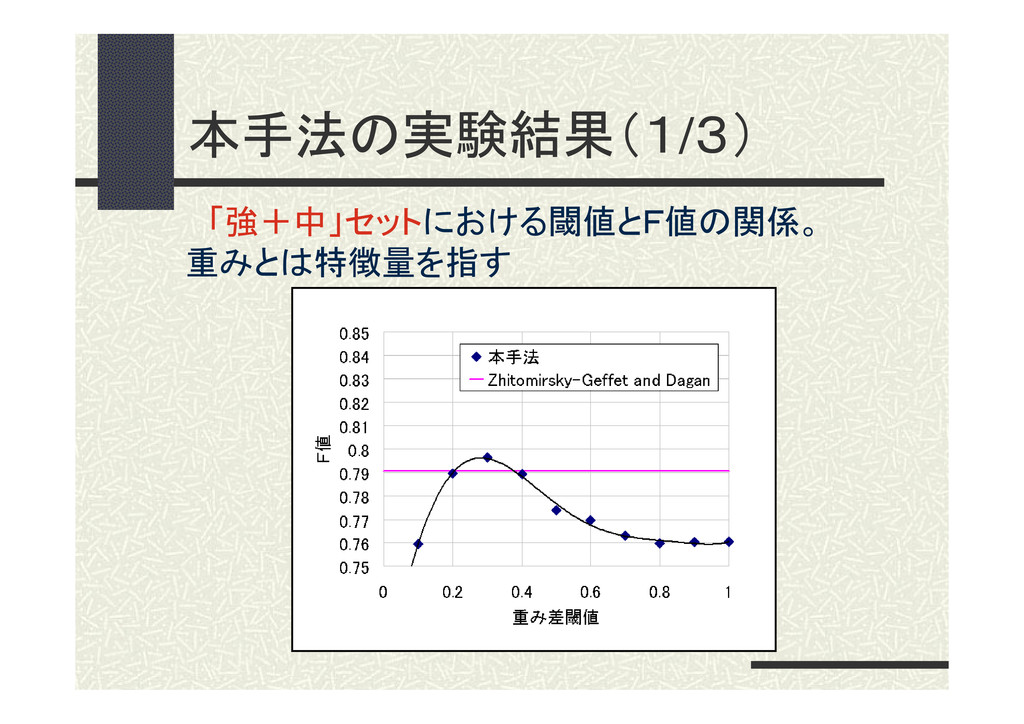
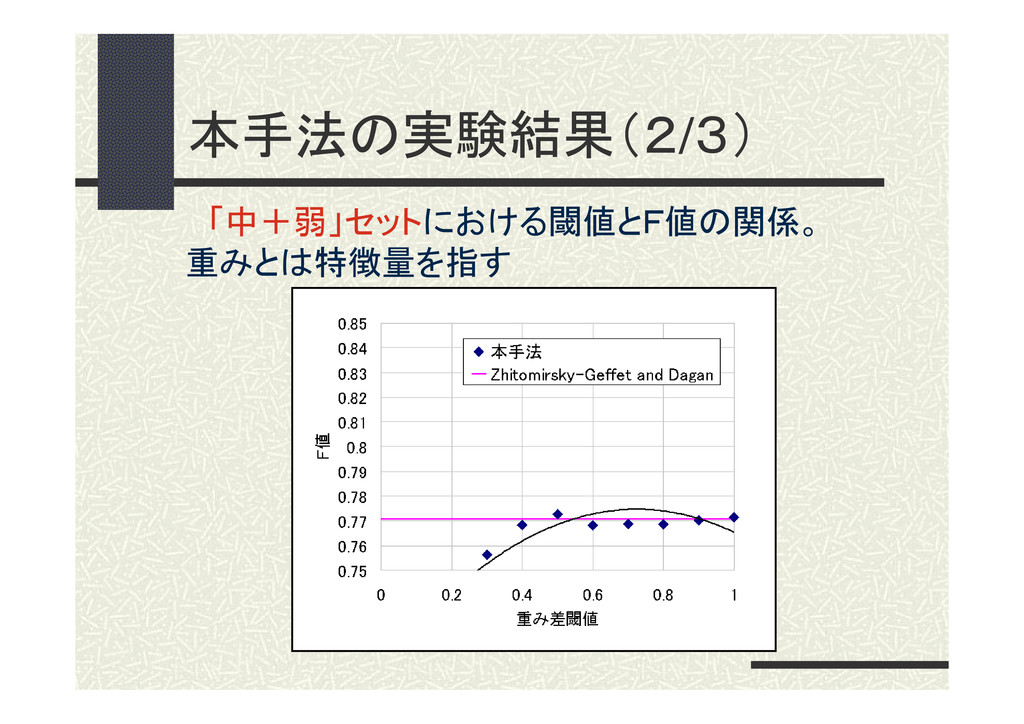
実験結果 評価セット 柴田ら Z-G & D 本手法 「強+中」 0.7015 0.7908
0.7965(+0.0057) 「中+弱」 0.7474 0.7708 0.7727(+0.0019) 「弱+非」 0.8383 0.7890 0.8395(+0.0013) すべての評価セットにおいて、比較手法の精度 を上回った。 →有効性を確認 5.実験及び考察 36 ※数値はF値
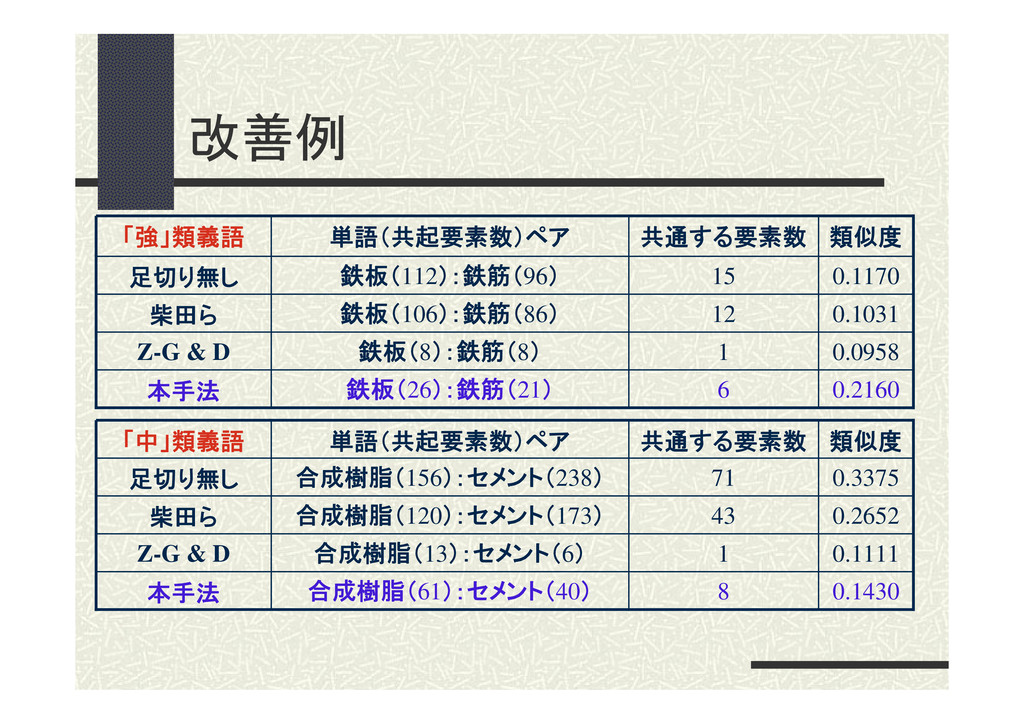
改善例(1/2) 「強+中」セットを例に挙げる 「強」類義語ペア → 『鉄板:鉄筋』 「中」類義語ペア → 『合成樹脂:セメント』 比較手法では『合成樹脂:セメント』の方が類 似度が高くなってしまった。
本手法では適正な類似度水準を実現できた。 5.実験及び考察 37
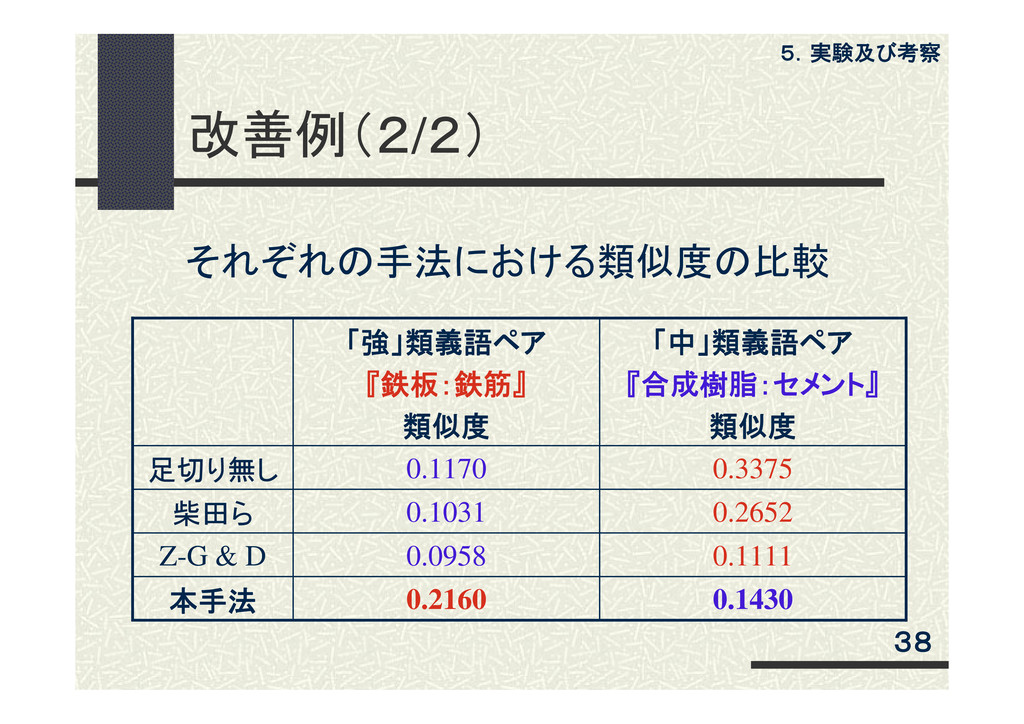
改善例(2/2) 「強」類義語ペア 『鉄板:鉄筋』 類似度 「中」類義語ペア 『合成樹脂:セメント』 類似度 足切り無し 0.1170 0.3375
柴田ら 0.1031 0.2652 Z-G & D 0.0958 0.1111 本手法 0.2160 0.1430 それぞれの手法における類似度の比較 5.実験及び考察 38
考察(1/3) 類似度が高い水準の評価セット(「強+ 中」)ほど精度が低く、適性な特徴量の差の 閾値は小さくなった。 →類似度が高い領域の評価セットの方が、 分類が難しい。 →特徴量の度合いが近いものを使用するこ とが有効。 5.実験及び考察 39
考察(2/3) 低頻度ペアは誤りの中に多く分布していた。 →本手法は共起要素を除外するのみであ り、元々含まれなかったが本来あるべき共起 要素をカバーできない。 ⇒超大規模コーパスを用いたり、素性を 補間するような手法が求められる。 5.実験及び考察 40
考察(3/3) 今回用いた特徴量では、精度を維持しながら 削減できる量は、最大約98%に上った。 →類似度計算に必要な素性は非常に限ら れている 5.実験及び考察 41
今後の課題 対象とする単語の範囲を広くする。つまり、 低頻度問題や多義性問題に踏み込んだ手 法へと工夫が必要。 2単語間の素性の共通していない部分にお いては、相対性を用いた素性選択が行えて いない。 →2単語間のみならず、対象の類義語集合 の素性と比べるなどの工夫が求められる。 5.実験及び考察
42
発表の流れ 1.研究の背景 2.分布類似度とは 3.既存研究とその問題 4.提案手法の説明 5.実験及び考察 6.まとめ 43
まとめ 素性の相対性を考慮した、分布類似度計 算の新しい素性選択手法を提案した。 比較対象の単語の素性と共通する要素に ついて、特徴量の差を考慮した。 既存手法を上回る精度であり、有効性を示 した。 6.まとめ 44
発表は以上です。 ありがとうございました。 45
評価セットのイメージ
各類義語ペアの例 「強」類義語 「中」類義語 「弱」類義語 「非」類義語 JAL:NTT NTT:銀行 NTT:国立大学 NTT:導入 IC:LSI
IC:太陽電池 IC:カード IC:国土庁 アジア:ヨーロッパ アジア:アメリカ アジア:我が国 アジア:システム アニメ:映画 アニメ:紙芝居 アニメ:SF アニメ:清酒 居酒屋:パブ 居酒屋:コンビニ 居酒屋:駅 居酒屋:地名 関西:四国 関西:アジア 関西:首都圏 関西:事前 生活費:交際費 生活費:物価 生活費:家賃 生活費:東日本 米国:イギリス 米国:アフリカ 米国:フランス人 米国:企業
足切りのための閾値 相互情報量で足切りをする場合、閾値は 経験的に決める。 閾値を変化させなが 足切り後の精度を測る。 各評価セットにおいて、 最適な閾値を求める
本手法の実験結果(1/3) 「強+中」セットにおける閾値とF値の関係。 重みとは特徴量を指す
本手法の実験結果(2/3) 「中+弱」セットにおける閾値とF値の関係。 重みとは特徴量を指す
本手法の実験結果(3/3) 「弱+非」セットにおける閾値とF値の関係。 重みとは特徴量を指す
改善例 「強」類義語 単語(共起要素数)ペア 共通する要素数 類似度 足切り無し 鉄板(112):鉄筋(96) 15 0.1170 柴田ら
鉄板(106):鉄筋(86) 12 0.1031 Z-G & D 鉄板(8):鉄筋(8) 1 0.0958 本手法 鉄板(26):鉄筋(21) 6 0.2160 「中」類義語 単語(共起要素数)ペア 共通する要素数 類似度 足切り無し 合成樹脂(156):セメント(238) 71 0.3375 柴田ら 合成樹脂(120):セメント(173) 43 0.2652 Z-G & D 合成樹脂(13):セメント(6) 1 0.1111 本手法 合成樹脂(61):セメント(40) 8 0.1430
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![単語の素性を自動収集 コーパスより、ある単語wとw’が格要素rで繋がっ ている三つ組(w,r,w’) を収集する[Lin98]。 例)「お金,が,必要」 「EU,に,加盟」 例えば、『お金』の共起要素を「が:必要」とし、全て の単語wについて、共起要素を収集し、素性を作成 する。 21](https://files.speakerdeck.com/presentations/be2de3b0c5e701305ff7269f0d7f5fd0/slide_20.jpg){kind=link}
{kind=link}
![集めた素性の足切り あきらかにノイズと判断されるようなものは、 あらかじめ足切りしておく。 共起要素の出現頻度を用いて、相互情報量 (MI)が閾値βに満たないものは、除外する。 閾値βは評価セットによって異なり、経験的 に決める[相澤(08)]。 23 4.提案手法の説明](https://files.speakerdeck.com/presentations/be2de3b0c5e701305ff7269f0d7f5fd0/slide_22.jpg){kind=link}
{kind=link}
![素性の特徴量を求める 特徴量=共起要素が単語wの特徴を表す度合い 分類語彙表を用いて単語wの類義語集合を作成する。 ▪例:『少年』の類義語 →「子供」「少女」「児童」「女の子」「青少年」 その類義語集合の中で共通する共起要素ほど、特徴 量を高くする[Zhitomirisky-Geffet and Dagan(09)]。 25](https://files.speakerdeck.com/presentations/be2de3b0c5e701305ff7269f0d7f5fd0/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![関数を用いた類似度計算 素性の重なりを見る関数である以下の関数 を使用する。 これらの関数を相加平均した値を類似度と する[柴田ら(09)]。 30 4.提案手法の説明](https://files.speakerdeck.com/presentations/be2de3b0c5e701305ff7269f0d7f5fd0/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
![評価セットの自動作成 コーパスから「AやB」という定型表現を収集、 「A:B」を類義語候補にする[相澤(08)]。 「A:B」より、分類語彙表を用いて「強」「中」 「弱」「非」類義語ペアを作成し、各800ペアづ つランダムにサンプリングする。 各ペアを「強+中」「中+弱」「弱+非」で組み 合わせ、評価セットとする。 5.実験及び考察 33](https://files.speakerdeck.com/presentations/be2de3b0c5e701305ff7269f0d7f5fd0/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}