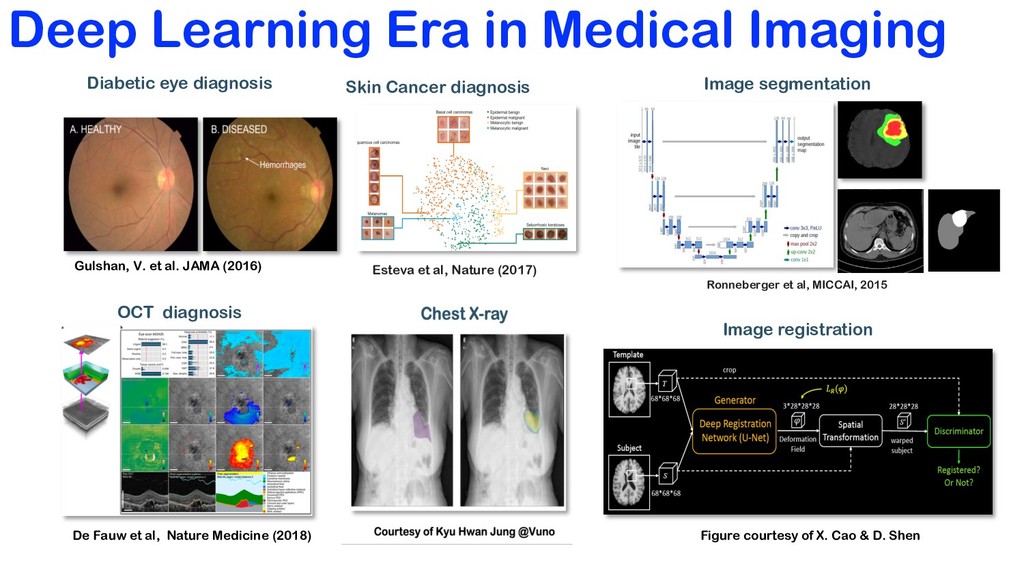
V. et al. JAMA (2016) Skin Cancer diagnosis Esteva et al, Nature (2017) OCT diagnosis De Fauw et al, Nature Medicine (2018) Figure courtesy of X. Cao & D. Shen Image registration Image segmentation Ronneberger et al, MICCAI, 2015
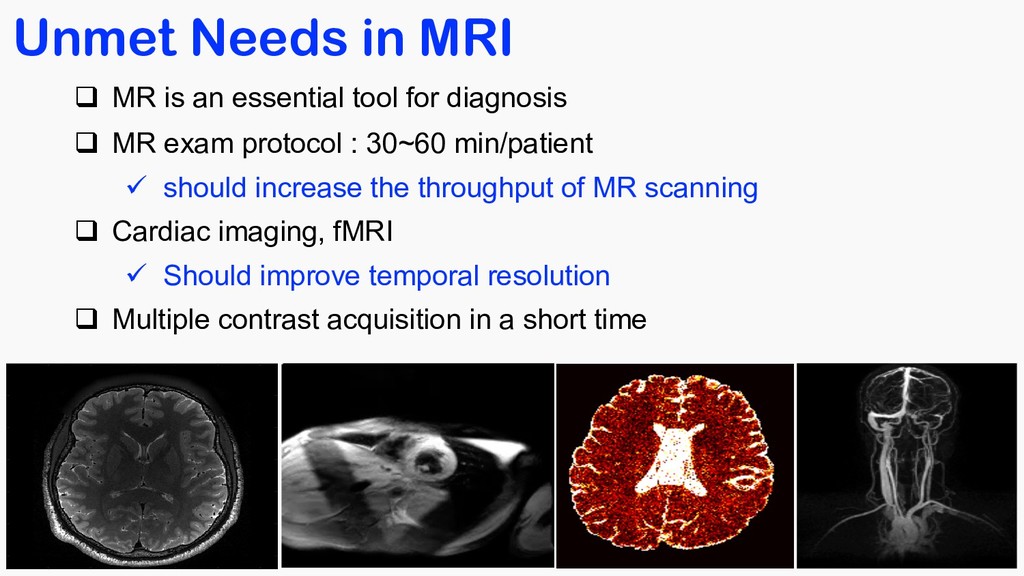
for diagnosis q MR exam protocol : 30~60 min/patient ü should increase the throughput of MR scanning q Cardiac imaging, fMRI ü Should improve temporal resolution q Multiple contrast acquisition in a short time
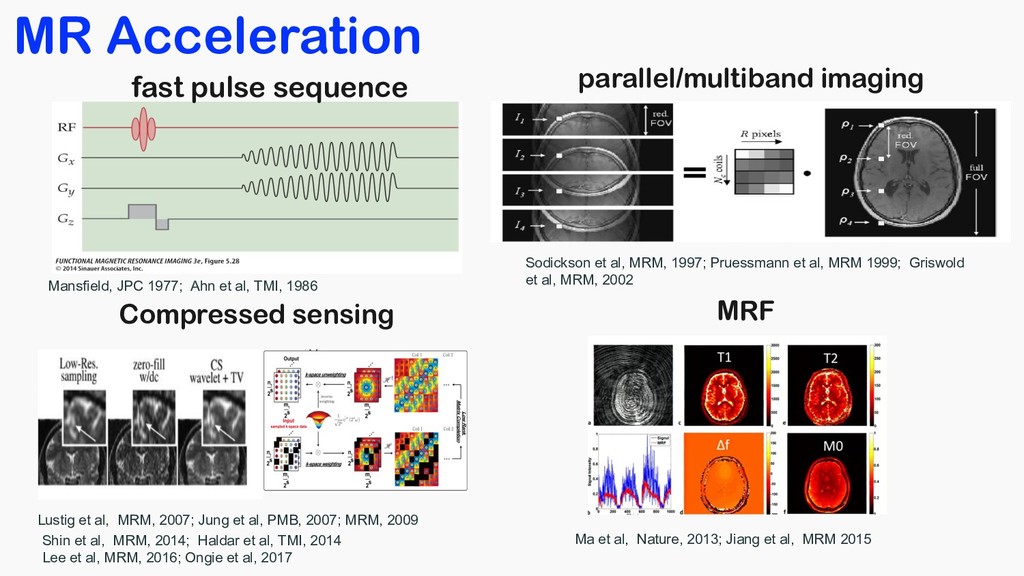
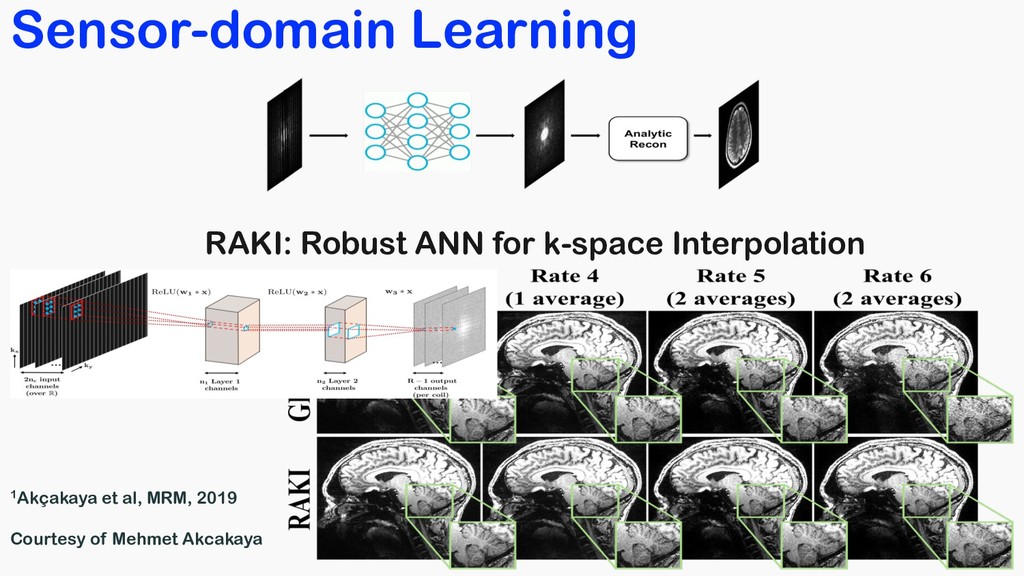
PMB, 2007; MRM, 2009 fast pulse sequence parallel/multiband imaging Compressed sensing Shin et al, MRM, 2014; Haldar et al, TMI, 2014 Lee et al, MRM, 2016; Ongie et al, 2017 Sodickson et al, MRM, 1997; Pruessmann et al, MRM 1999; Griswold et al, MRM, 2002 Mansfield, JPC 1977; Ahn et al, TMI, 1986 MRF Ma et al, Nature, 2013; Jiang et al, MRM 2015
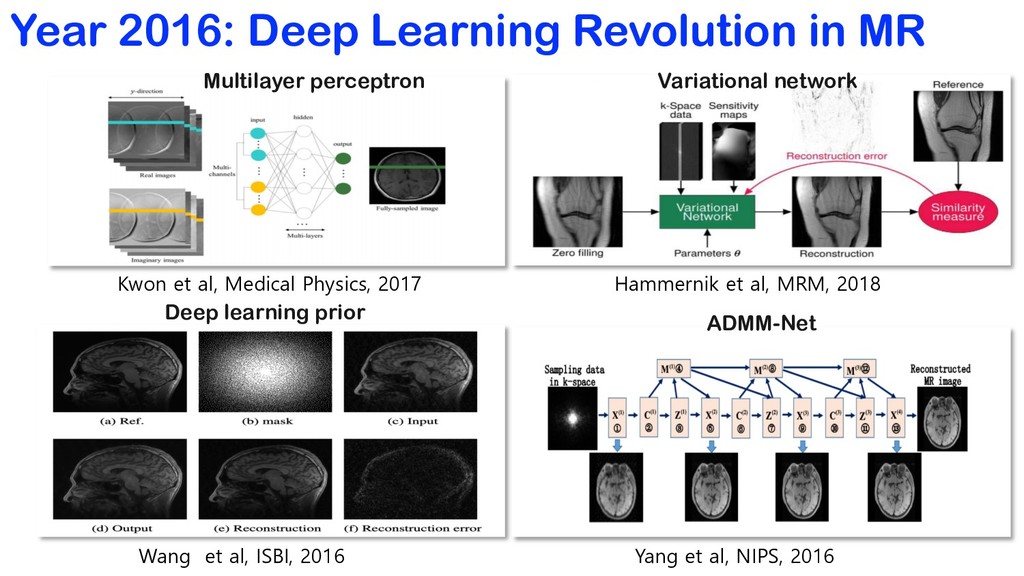
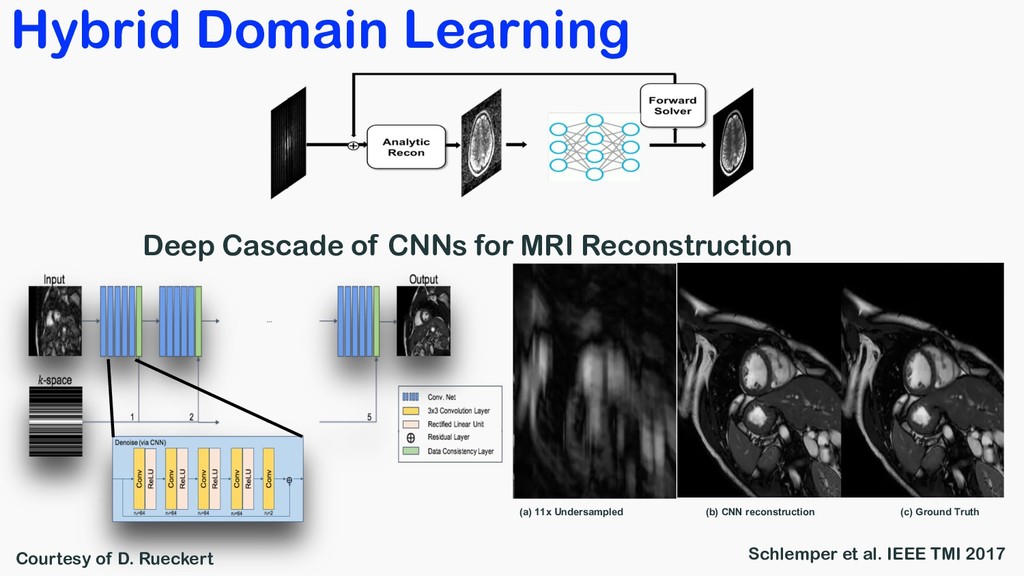
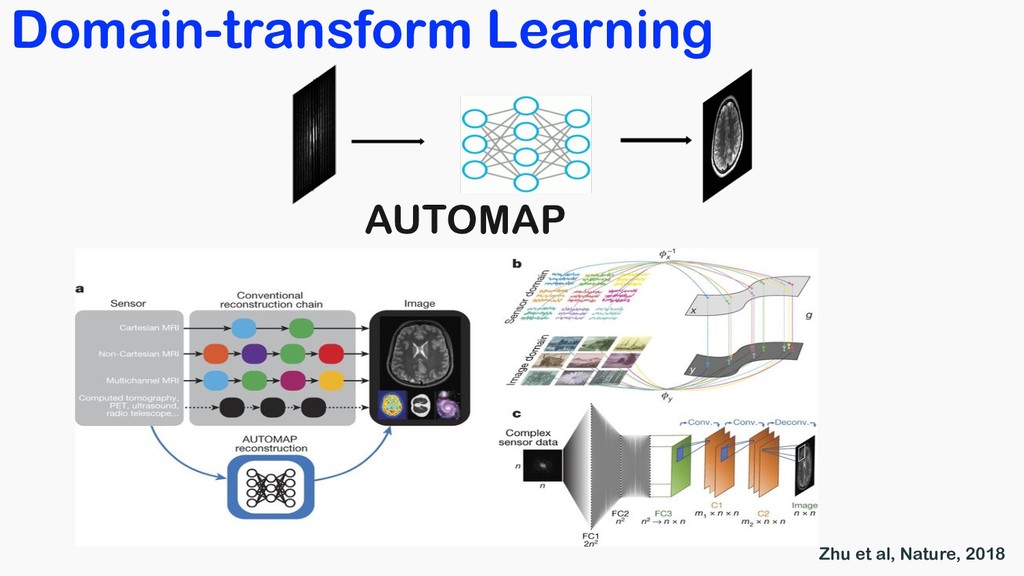
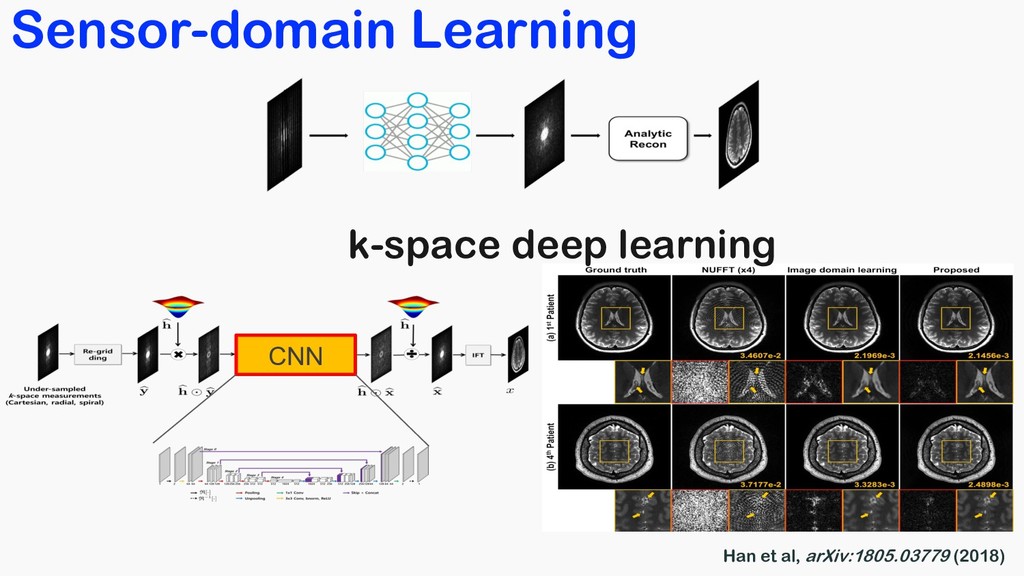
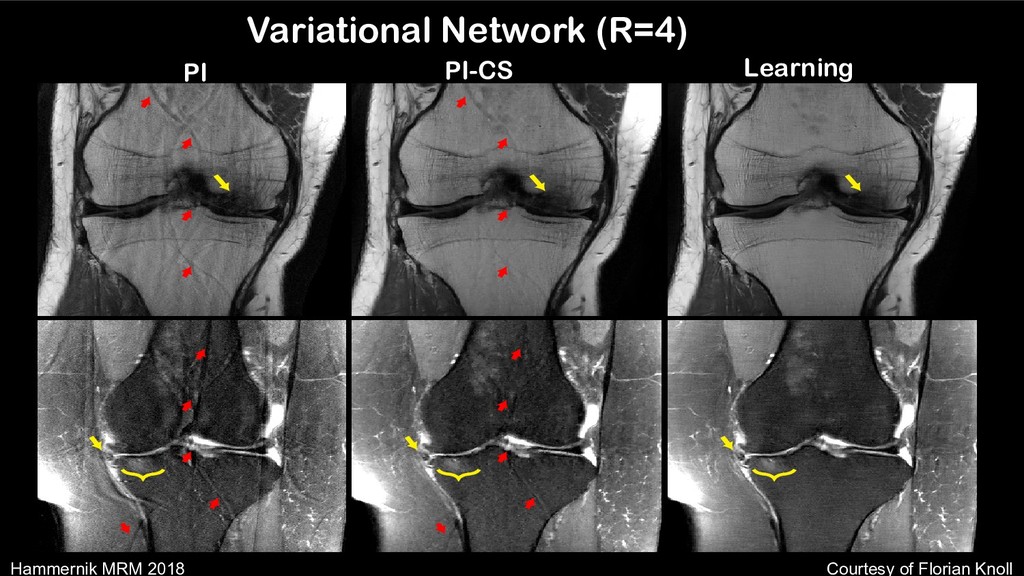
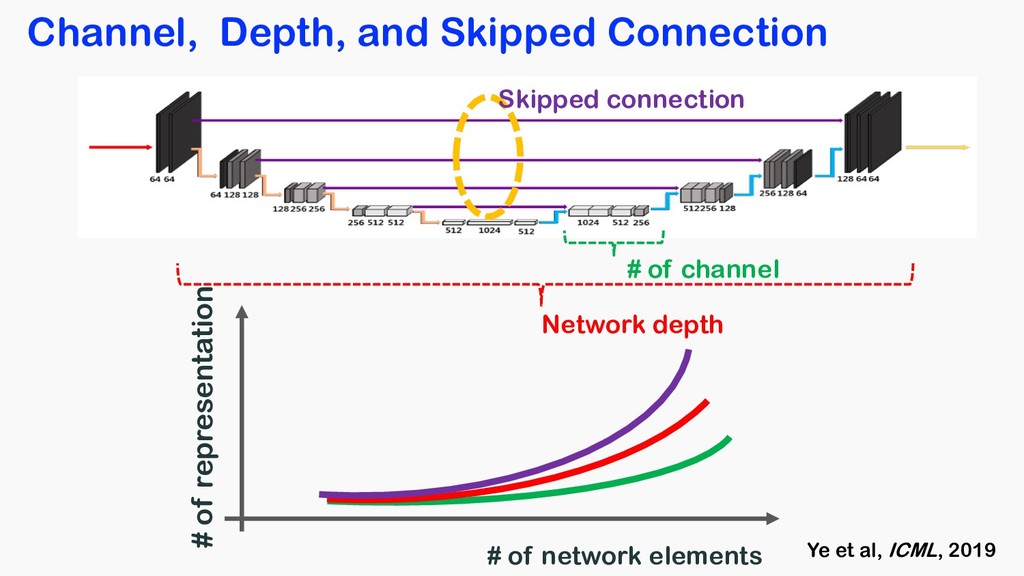
Medical Physics, 2017 Hammernik et al, MRM, 2018 Wang et al, ISBI, 2016 Yang et al, NIPS, 2016 Multilayer perceptron Variational network Deep learning prior ADMM-Net
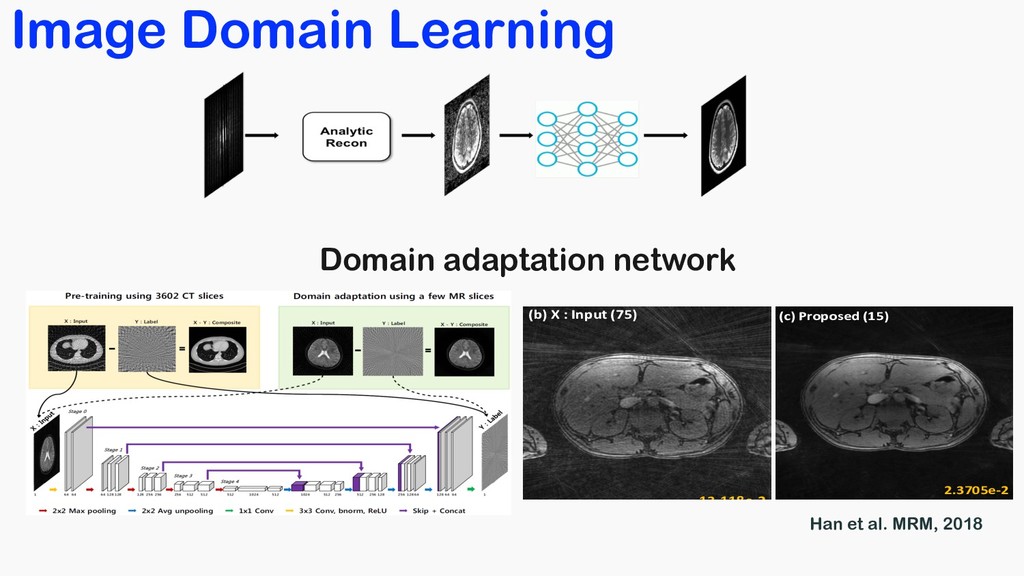
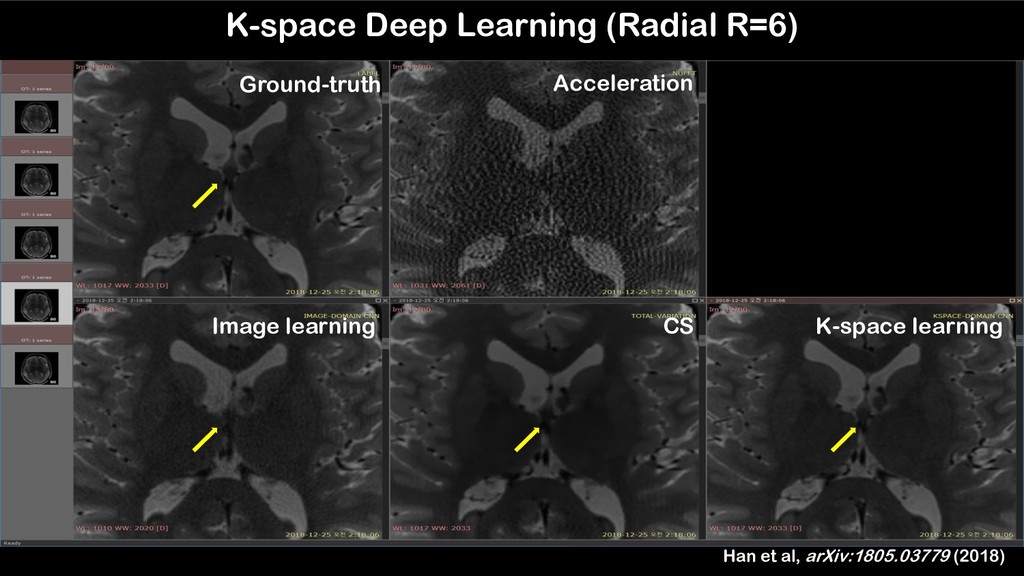
(collaboration with KH Sung at UCLA) Object # of views Ground truth 302 views X : Input 75 views Target : abdomen Acceleration factor : x4 Training dataset : 15 slices 13.118e-2 (a) Ground truth (2nd slice) (b) X : Input (75) Accelerated Projection Reconstruction MR imaging using Deep Residual Learning MRM Highlight September 2018 2.3705e-2 (a) Ground truth (2nd slice) (c) Proposed (15) Object # of views Ground truth 302 views X : Input 75 views Target : abdomen Acceleration factor : x4 Training dataset : 15 slices In vivo golden angle radial acquisition results (collaboration with KH Sung at UCLA) Han et al. MRM, 2018 Domain adaptation network
recon > CS q Fast reconstruction time q Business model: vendor-driven training q Interpretable models q Flexibility: more than recon Imaging time Reconstruction time Conventional Compressed Sensing Machine Learning
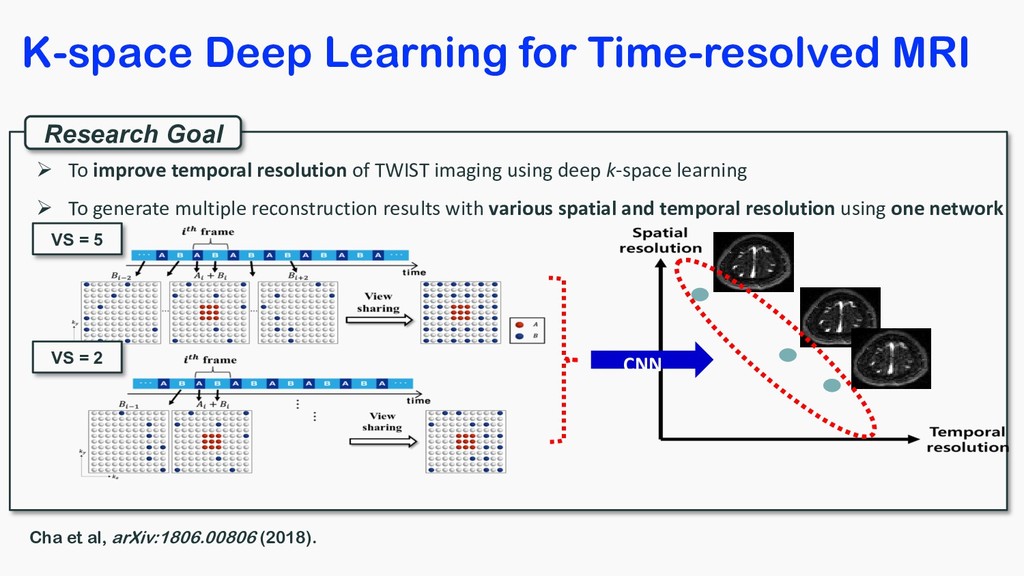
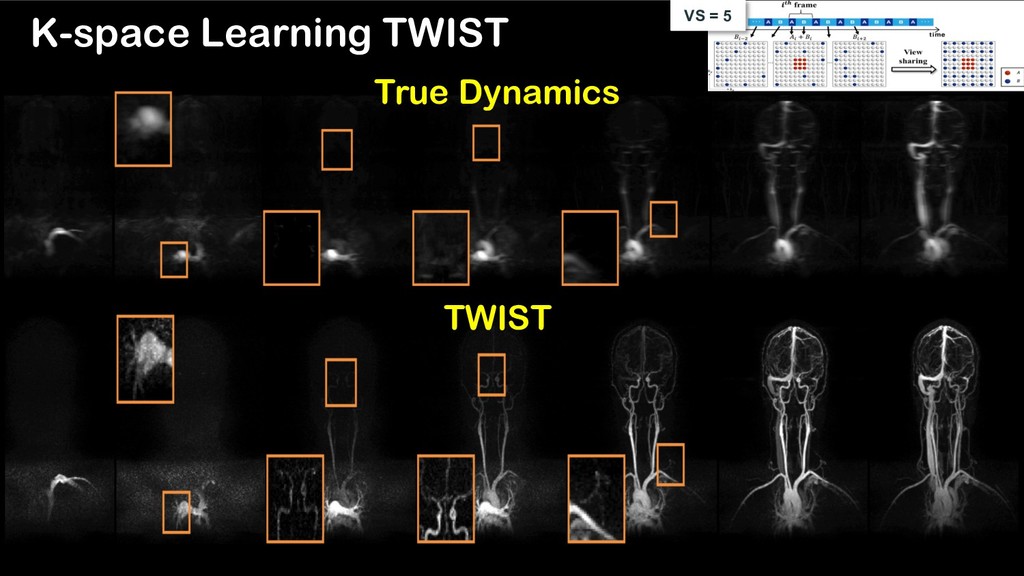
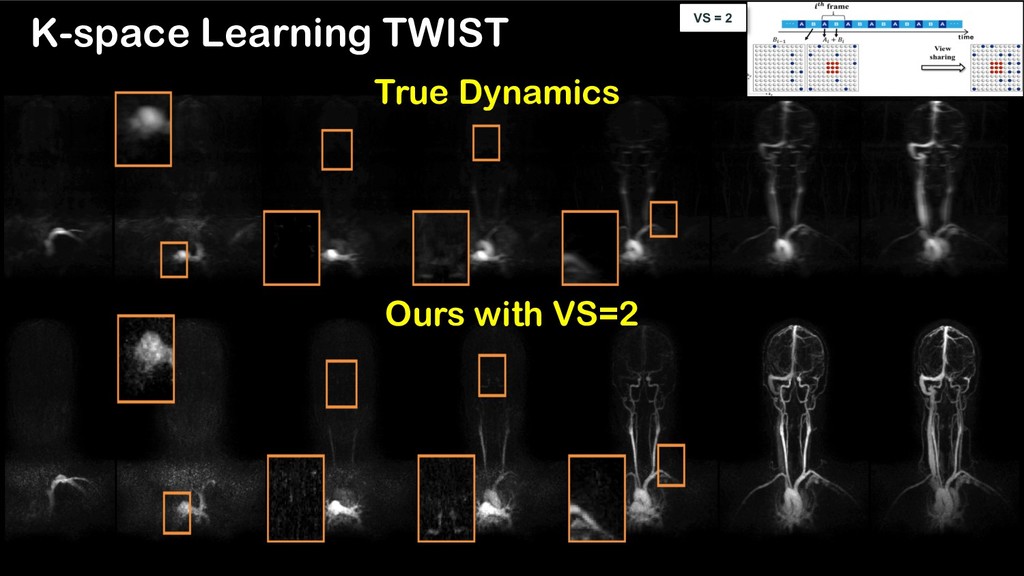
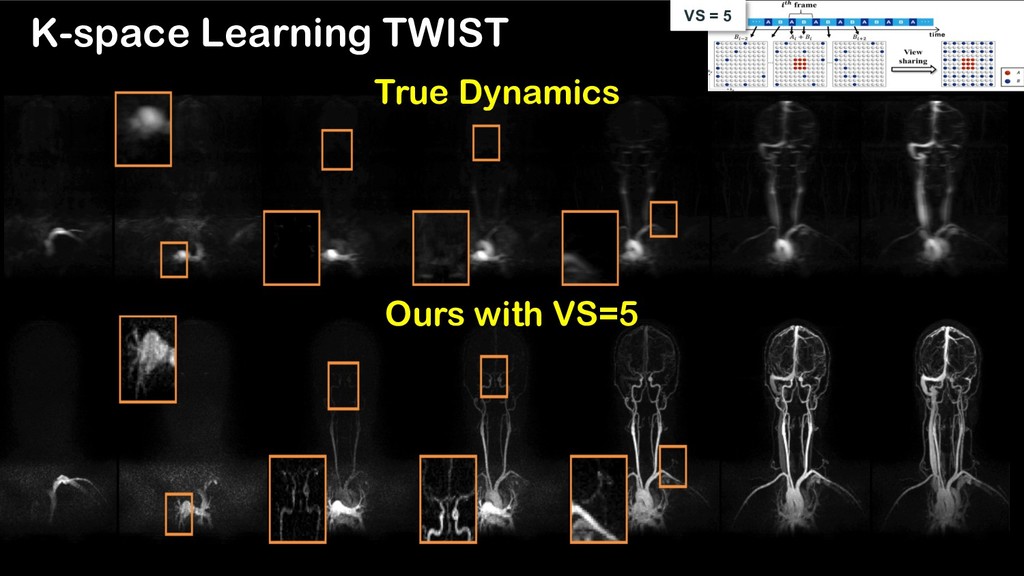
using deep k-space learning Ø To generate multiple reconstruction results with various spatial and temporal resolution using one network VS = 5 VS = 2 CNN K-space Deep Learning for Time-resolved MRI Cha et al, arXiv:1806.00806 (2018).
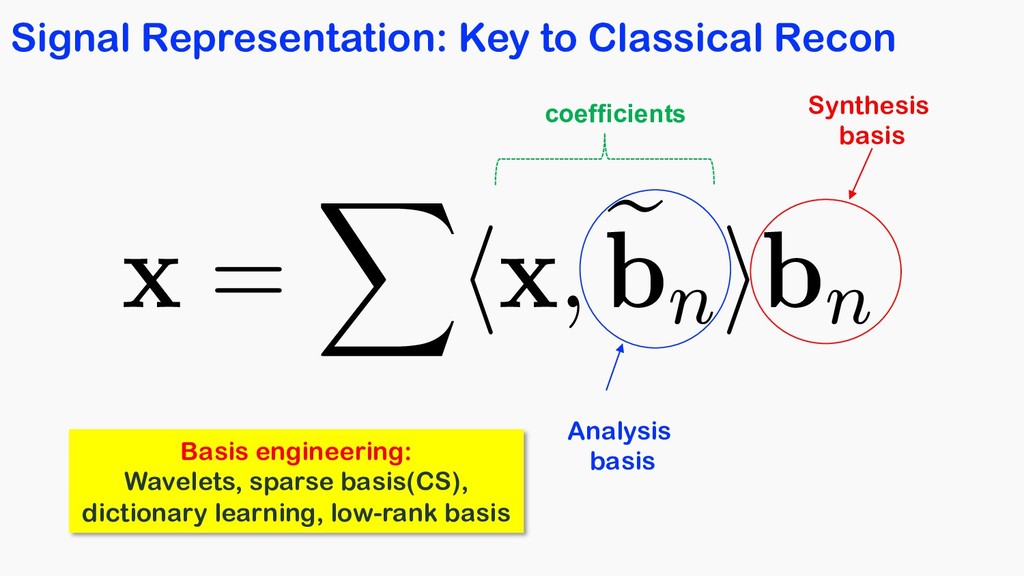
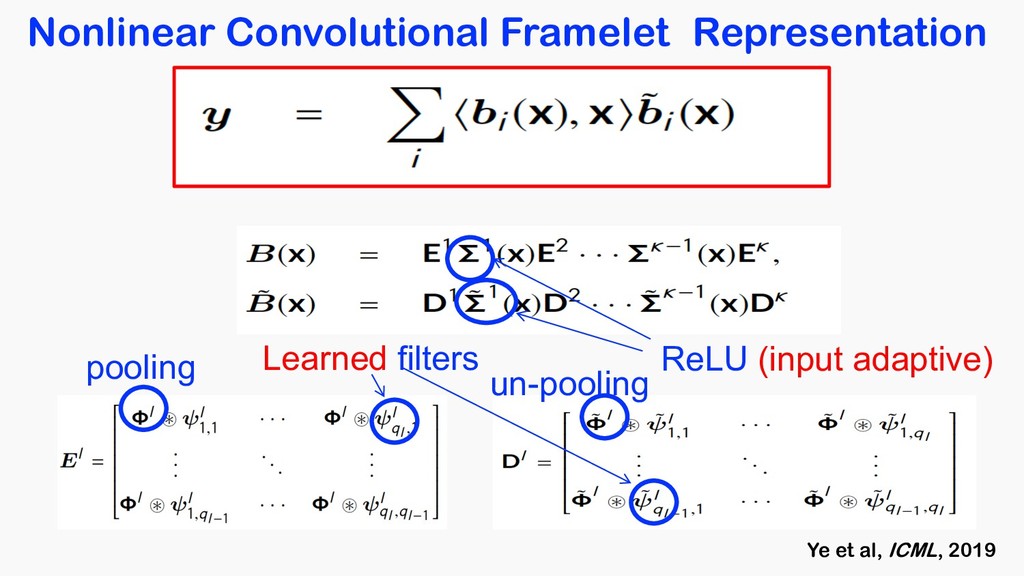
= X hx, e bn ibn <latexit sha1_base64="tCLG2nbXwywzwFFUoqMNNZJmas8=">AAACOnicbVDLSsNAFJ34rPVVdelmsAgupCQq6EYounHZgn1AU8pkctMOnUzCzEQtod/lxq9w58KNC0Xc+gFO2oBaPTBwOOdc5t7jxZwpbdtP1tz8wuLScmGluLq2vrFZ2tpuqiiRFBo04pFse0QBZwIammkO7VgCCT0OLW94mfmtG5CKReJaj2LohqQvWMAo0UbqlepuSPTAC9K7MT53VRJilxPR54C/jUPs3jIfNOM+pLmMvXFPuPJ3NNNwr1S2K/YE+C9xclJGOWq90qPrRzQJQWjKiVIdx451NyVSM8phXHQTBTGhQ9KHjqGChKC66eT0Md43io+DSJonNJ6oPydSEio1Cj2TzJZUs14m/ud1Eh2cdVMm4kSDoNOPgoRjHeGsR+wzCVTzkSGESmZ2xXRAJKHatF00JTizJ/8lzaOKc1yx6yfl6kVeRwHtoj10gBx0iqroCtVQA1F0j57RK3qzHqwX6936mEbnrHxmB/2C9fkFVQWu8g==</latexit> basis 1 1 x coefficient
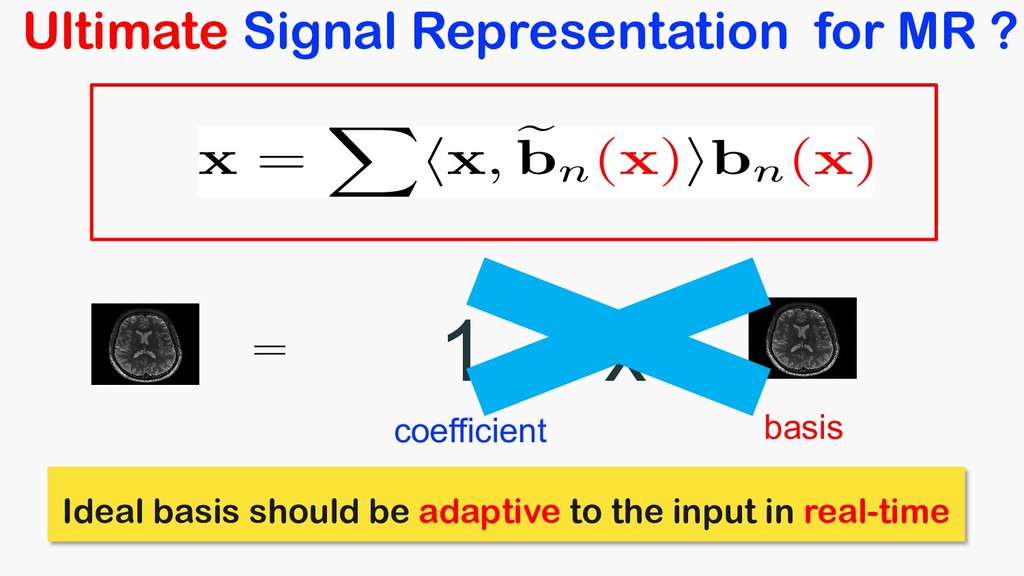
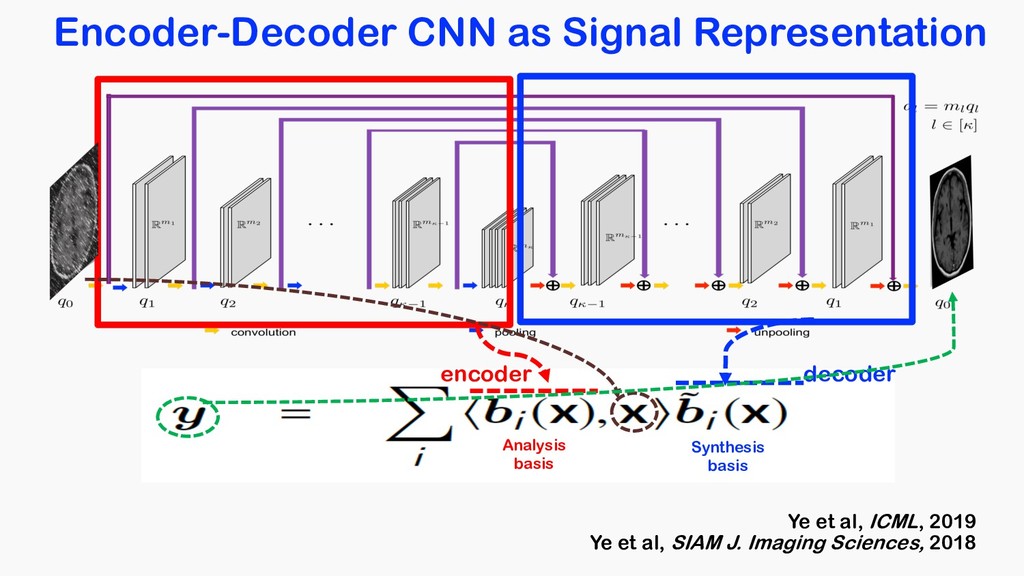
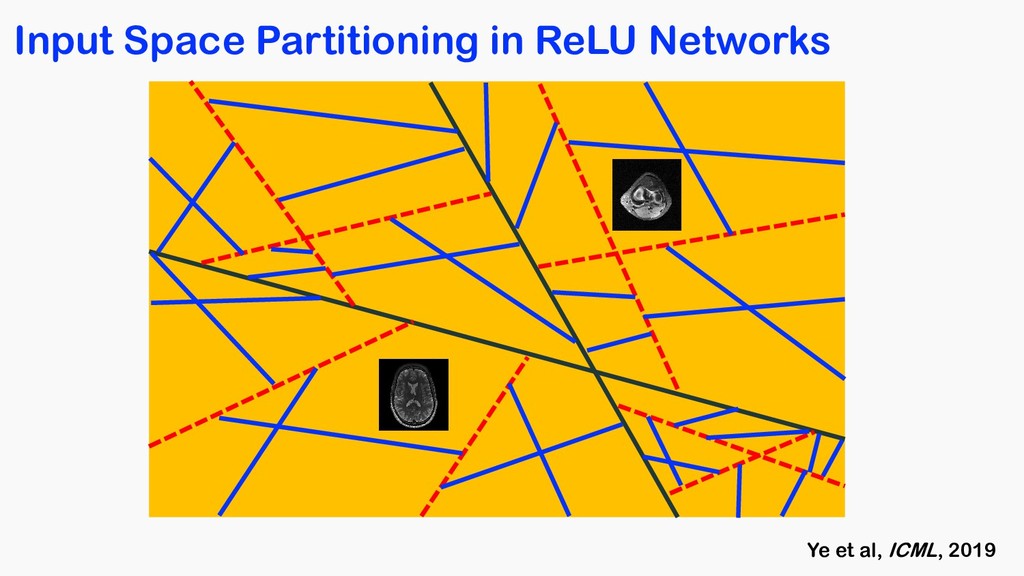
<latexit sha1_base64="tCLG2nbXwywzwFFUoqMNNZJmas8=">AAACOnicbVDLSsNAFJ34rPVVdelmsAgupCQq6EYounHZgn1AU8pkctMOnUzCzEQtod/lxq9w58KNC0Xc+gFO2oBaPTBwOOdc5t7jxZwpbdtP1tz8wuLScmGluLq2vrFZ2tpuqiiRFBo04pFse0QBZwIammkO7VgCCT0OLW94mfmtG5CKReJaj2LohqQvWMAo0UbqlepuSPTAC9K7MT53VRJilxPR54C/jUPs3jIfNOM+pLmMvXFPuPJ3NNNwr1S2K/YE+C9xclJGOWq90qPrRzQJQWjKiVIdx451NyVSM8phXHQTBTGhQ9KHjqGChKC66eT0Md43io+DSJonNJ6oPydSEio1Cj2TzJZUs14m/ud1Eh2cdVMm4kSDoNOPgoRjHeGsR+wzCVTzkSGESmZ2xXRAJKHatF00JTizJ/8lzaOKc1yx6yfl6kVeRwHtoj10gBx0iqroCtVQA1F0j57RK3qzHqwX6936mEbnrHxmB/2C9fkFVQWu8g==</latexit> basis 1 1 x coefficient x = X hx, e bn(x)ibn(x) <latexit sha1_base64="erKoPFMSsbyGoza+nkJyT8tbnTk=">AAACdHicfVFNa9tAEF0pTeu4SeM2hx7awzbG4EIxUltoL4GQXnJ0of4Ay5jVauQsWa3E7qi1EfoF+Xe55WfkknNWjsC1XTqw8Hhv3szsTJhJYdDz7hx379n+8xeNg+bLw6NXx63Xb4YmzTWHAU9lqschMyCFggEKlDDONLAklDAKr39U+ug3aCNS9QuXGUwTNlciFpyhpWatmyBheBXGxaKkZ4HJExpIpuYS6Fr4RIM/IgIUMoKipmlYzlSAsMDVDIWGqCy6a8/HMtCbdSoD/a9j1mp7PW8VdBf4NWiTOvqz1m0QpTxPQCGXzJiJ72U4LZhGwSWUzSA3kDF+zeYwsVCxBMy0WLUvaccyEY1TbZ9CumL/dhQsMWaZhDazmtFsaxX5L22SY/x9WgiV5QiKPzWKc0kxpdUFaCQ0cJRLCxjXws5K+RXTjKO9U9Muwd/+8i4Yfu75X3rez6/t84t6HQ3yjpySLvHJN3JOLkmfDAgn985bhzofnAf3vdt2O0+prlN7TshGuL1HHSHCMQ==</latexit> Ideal basis should be adaptive to the input in real-time Ultimate Signal Representation for MR ?
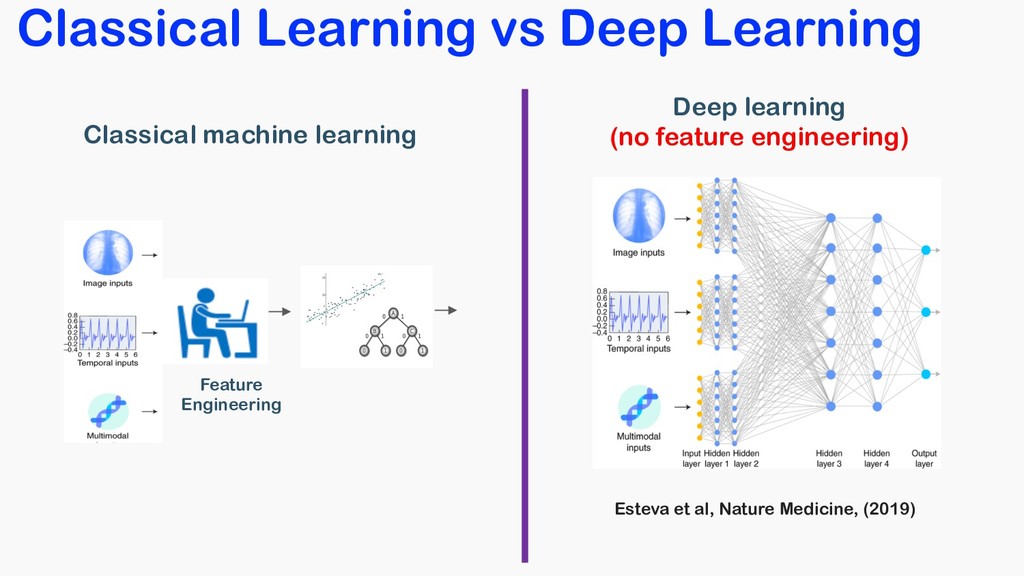
• Deep learning is a novel image representation with automatic input adaptivity. • Extension of classical regression, CS, PCA, etc • More training data gives better representation Don’t be afraid of using it !
• Fang Liu (Univ. of Wisconsin) • Mehmet Akcakaya (Univ. of Minnesota) • Dong Liang (SIAT, China) • Dinggang Shen (UNC) • Peder Larson (UCSF) • Grant – NRF of Korea – Ministry of Trade Industry and Energy • Hyunwook Park (KAIST) • Sung-hong Park (KAIST) • Jongho Lee (SNU) • Doshik Hwang (Yonsei Univ) • Won-Jin Moon (KonkukUniv Medical Center) • Eungyeop Kim (Gachon Univ. Medical Center) • Leonard Sunwoo (SNUBH) • Kyuhwan Jung (Vuno)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}