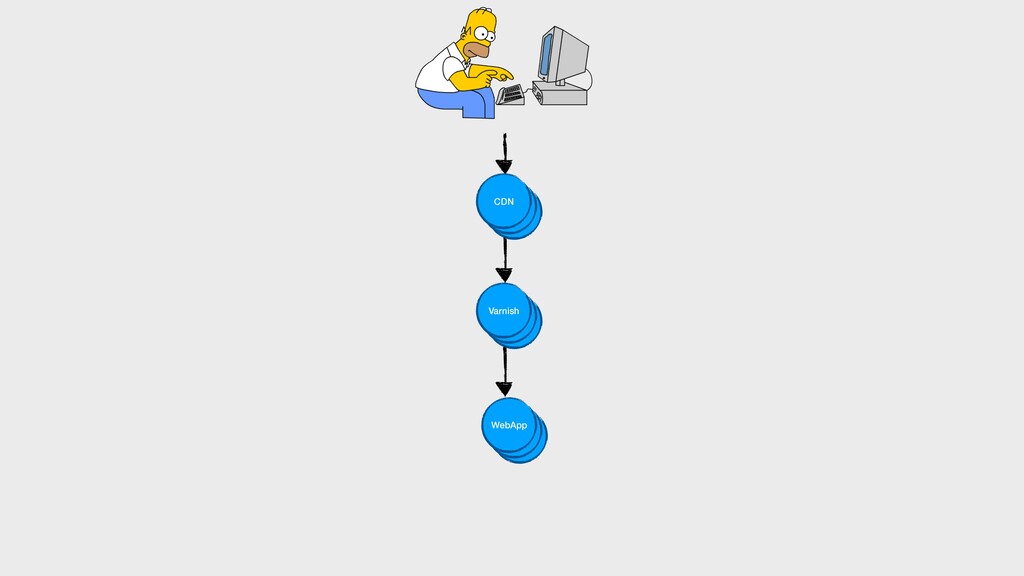
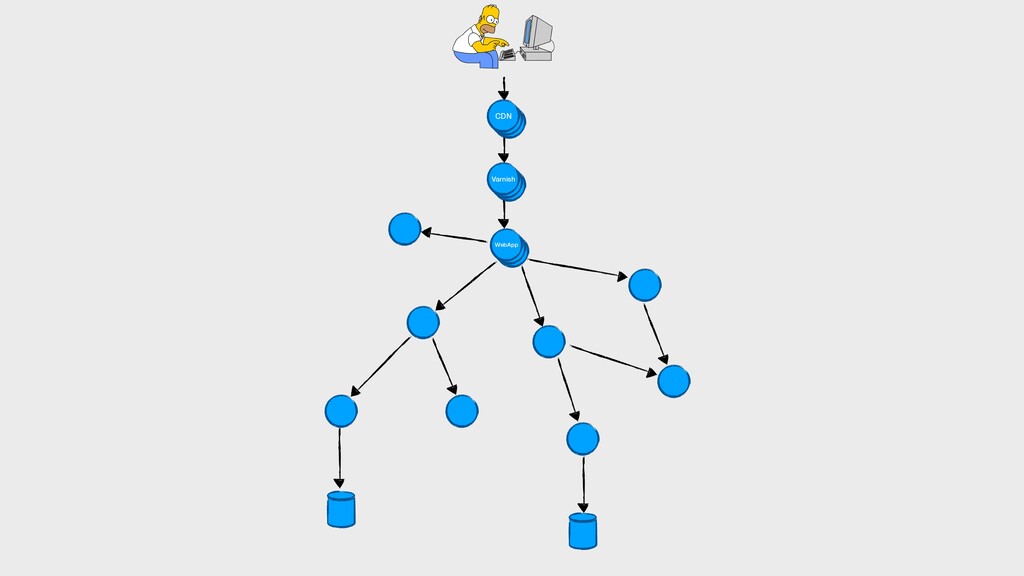
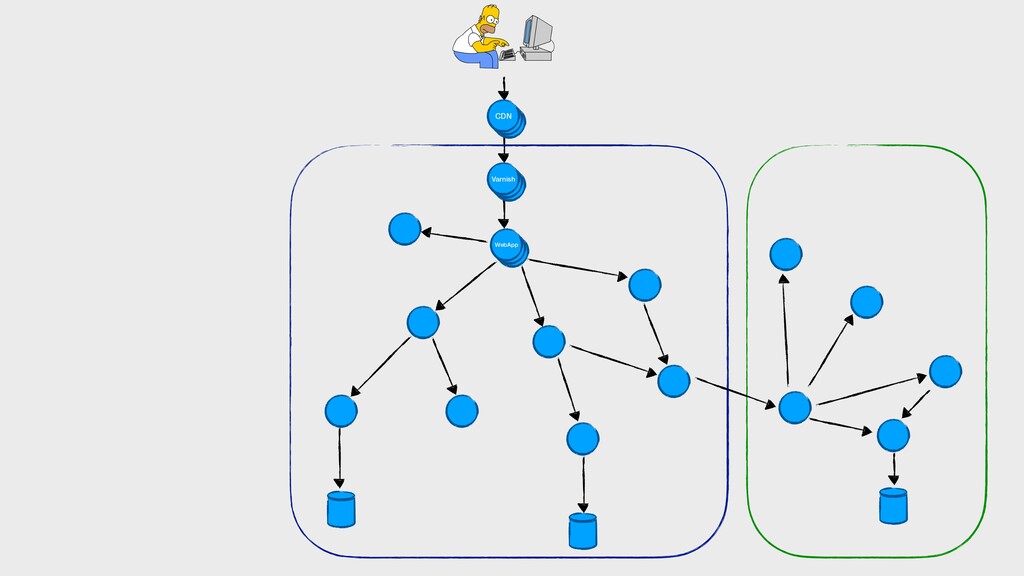
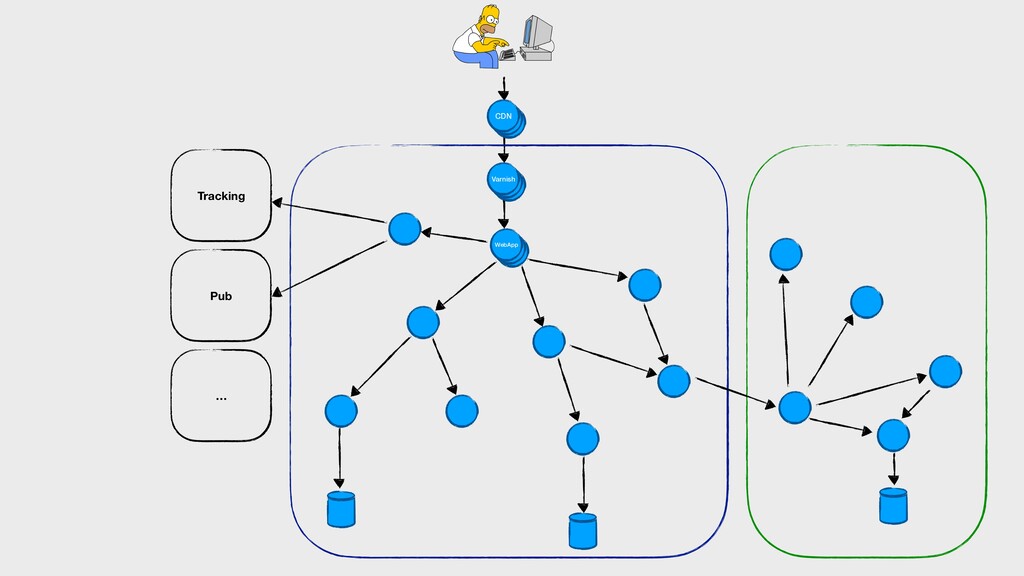
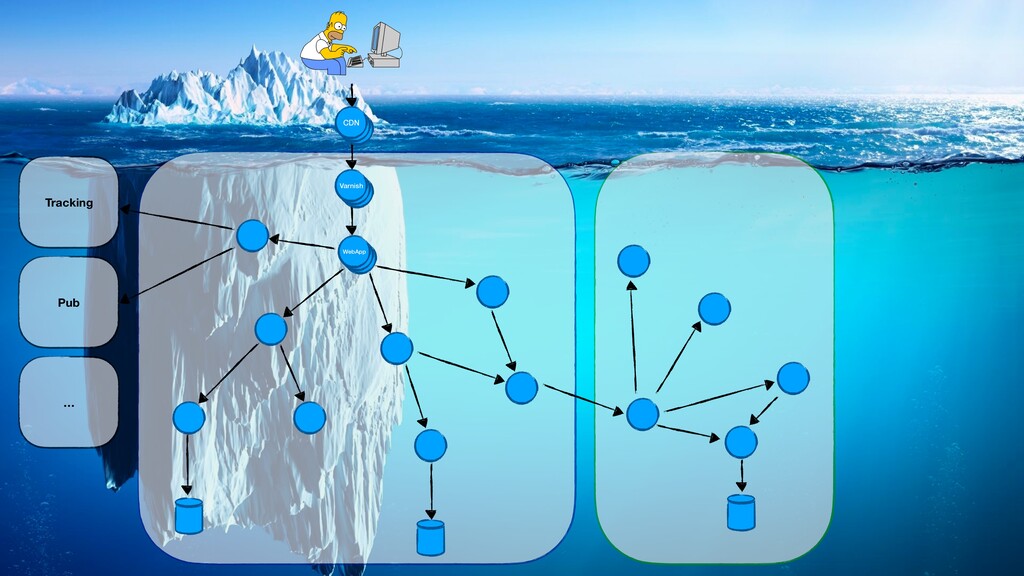
On parle souvent de nos pipelines de CI/CD, des rythmes de mise en production… Mais on oublie que dans une démarche DevOps, les développeurs sont également responsables de la vie de leurs applications en production. Dans des architectures microservices de plus en plus distribuées, il devient primordial de connaître le comportement des applications que l’on envoie en production, en intégrant ces considérations dès la phase de développement.
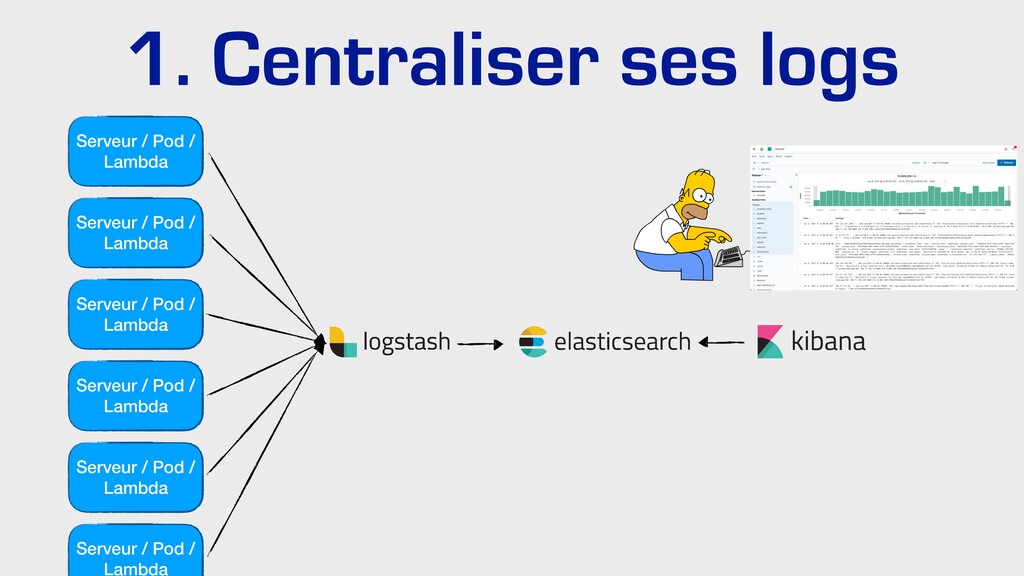
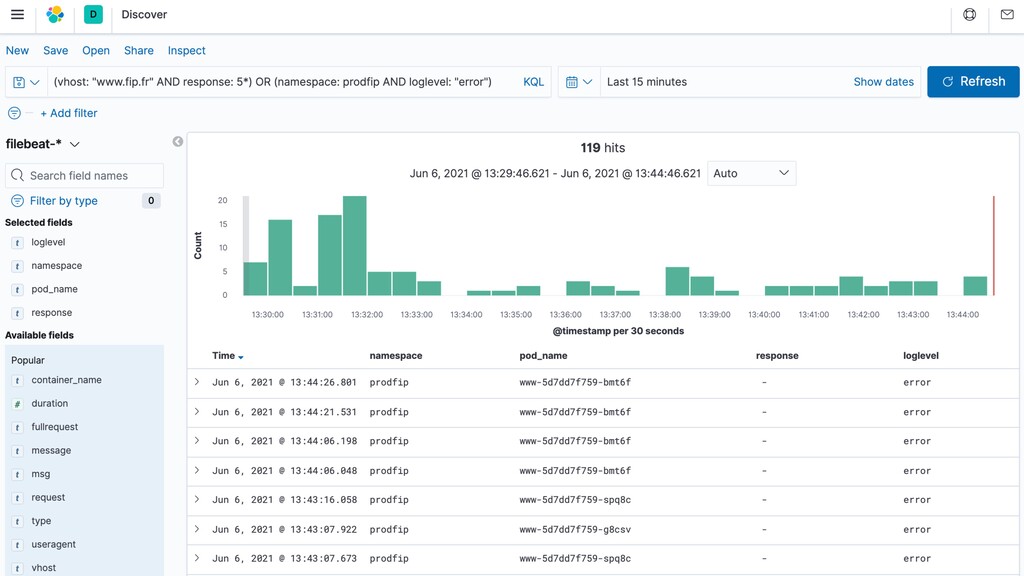
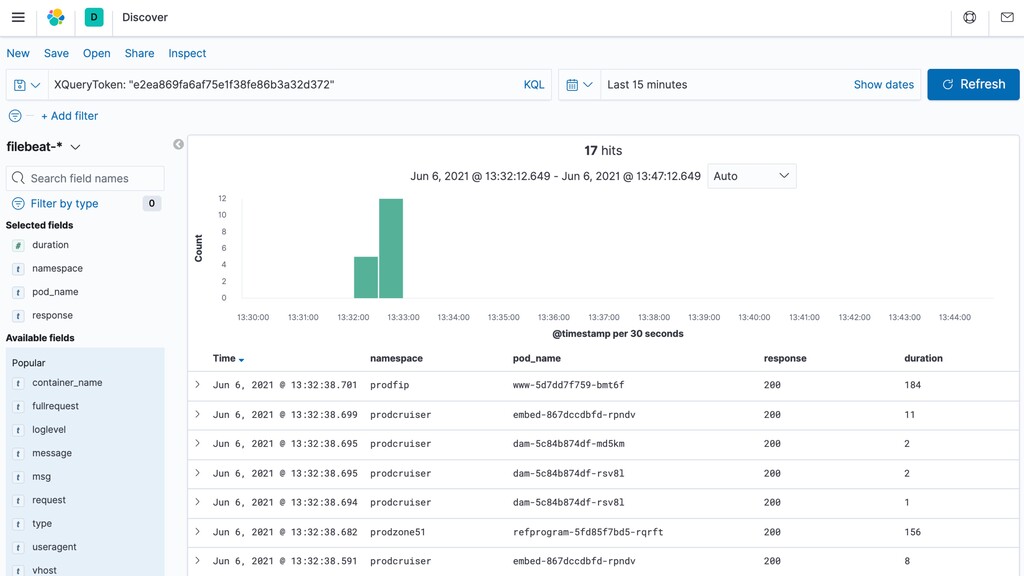
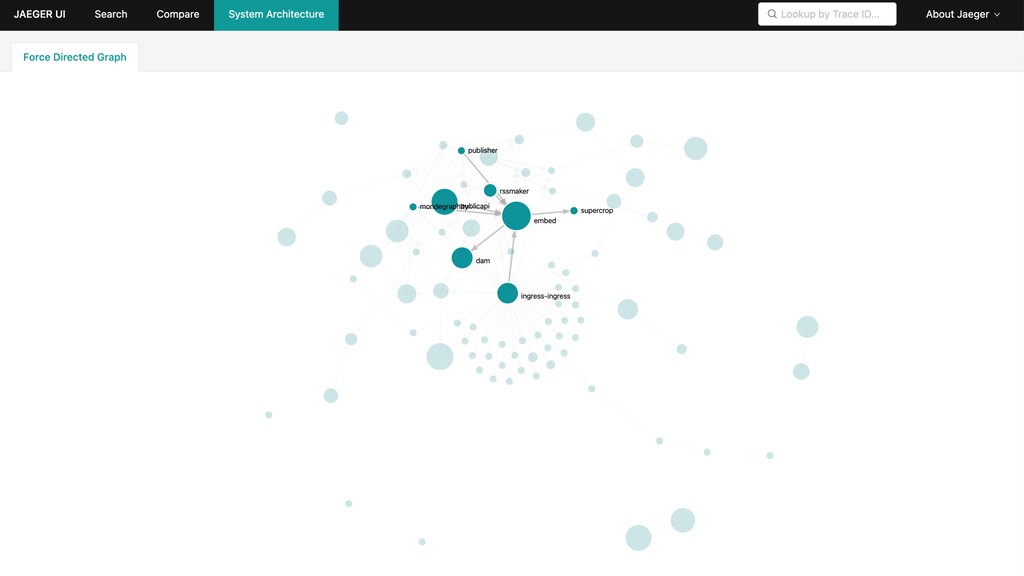
Comment corréler des logs dans un environnement distribué ? Quels indicateurs collecter, comment les visualiser, quand alerter ? Comment tracer les requêtes à travers les différents services ?
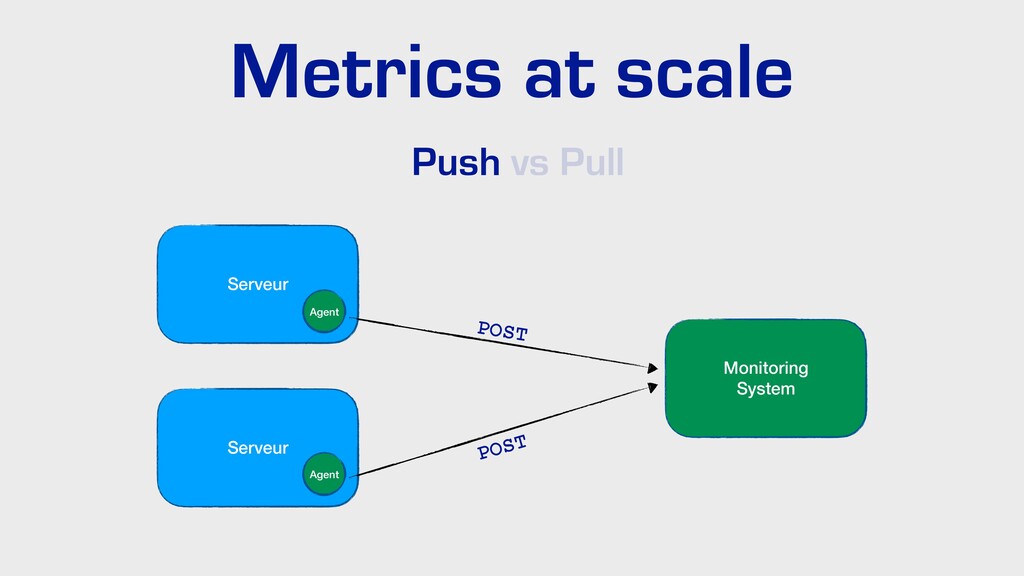
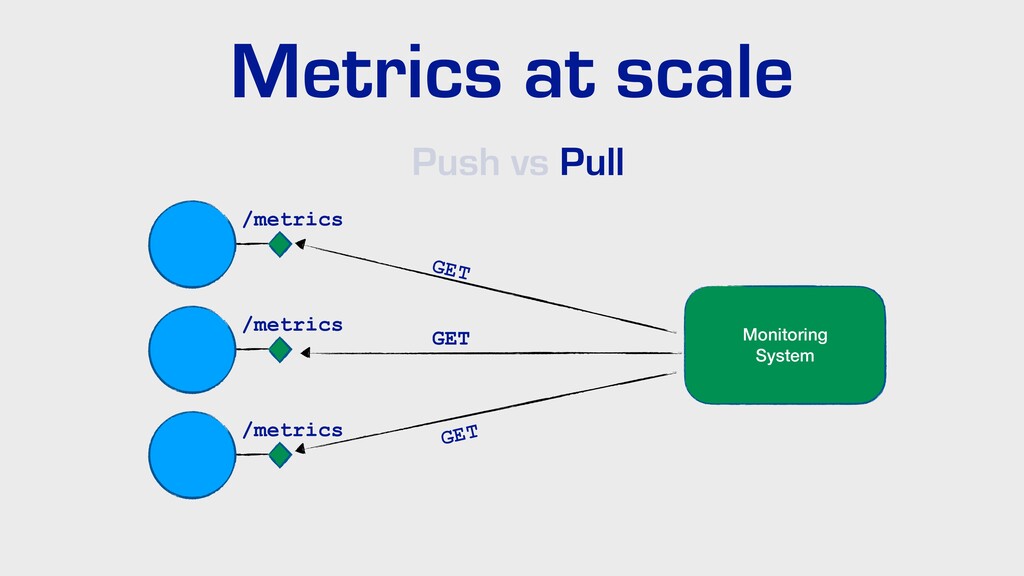
Dans cette présentation, je vous parlerai de l’évolution de nos pratiques et outils pour améliorer l’observabilité de nos applications dans un environnement distribué. Nous parlerons de collecte de logs avec Elastic, de métriques avec Prometheus, ainsi que de tracing distribué avec Jaeger… tout ça du point de vue d’un développeur.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![A x-correlation-id: headers['x-correlation-id'] || uuid.v4()](https://files.speakerdeck.com/presentations/3be6519e6feb40a8a9113b1c78d25ade/slide_41.jpg){kind=link}
![A x-correlation-id: headers['x-correlation-id'] || uuid.v4() log.info(headers['x-correlation-id'] + 'Running in service](https://files.speakerdeck.com/presentations/3be6519e6feb40a8a9113b1c78d25ade/slide_42.jpg){kind=link}
![A x-correlation-id: headers['x-correlation-id'] || uuid.v4() log.info(headers['x-correlation-id'] + 'Running in service](https://files.speakerdeck.com/presentations/3be6519e6feb40a8a9113b1c78d25ade/slide_43.jpg){kind=link}
![A x-correlation-id: headers['x-correlation-id'] || uuid.v4() log.info(headers['x-correlation-id'] + 'Running in service](https://files.speakerdeck.com/presentations/3be6519e6feb40a8a9113b1c78d25ade/slide_44.jpg){kind=link}
![A x-correlation-id: headers['x-correlation-id'] || uuid.v4() log.info(headers['x-correlation-id'] + 'Running in service](https://files.speakerdeck.com/presentations/3be6519e6feb40a8a9113b1c78d25ade/slide_45.jpg){kind=link}
![A x-correlation-id: headers['x-correlation-id'] || uuid.v4() log.info(headers['x-correlation-id'] + 'Running in service](https://files.speakerdeck.com/presentations/3be6519e6feb40a8a9113b1c78d25ade/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
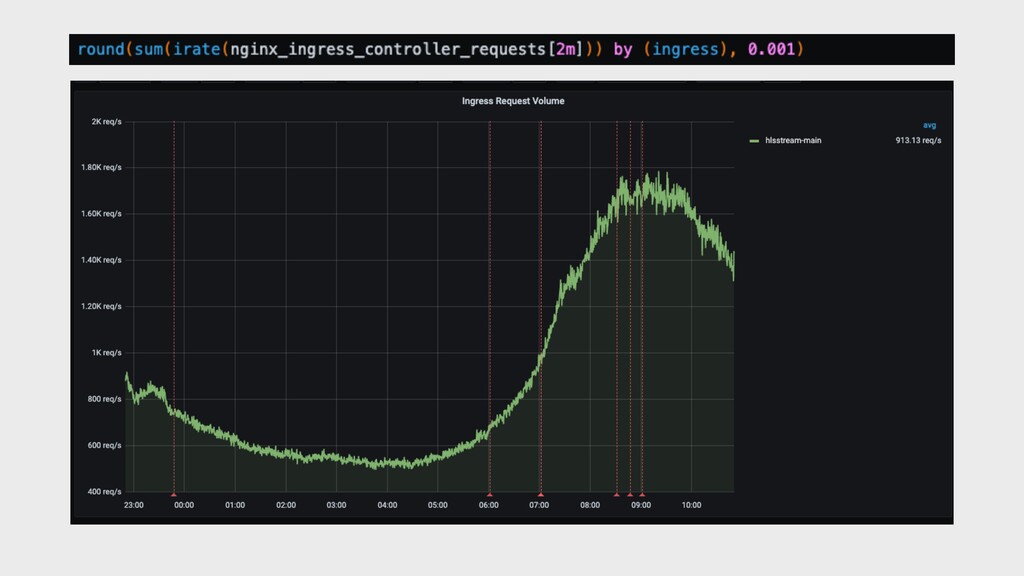{kind=link}
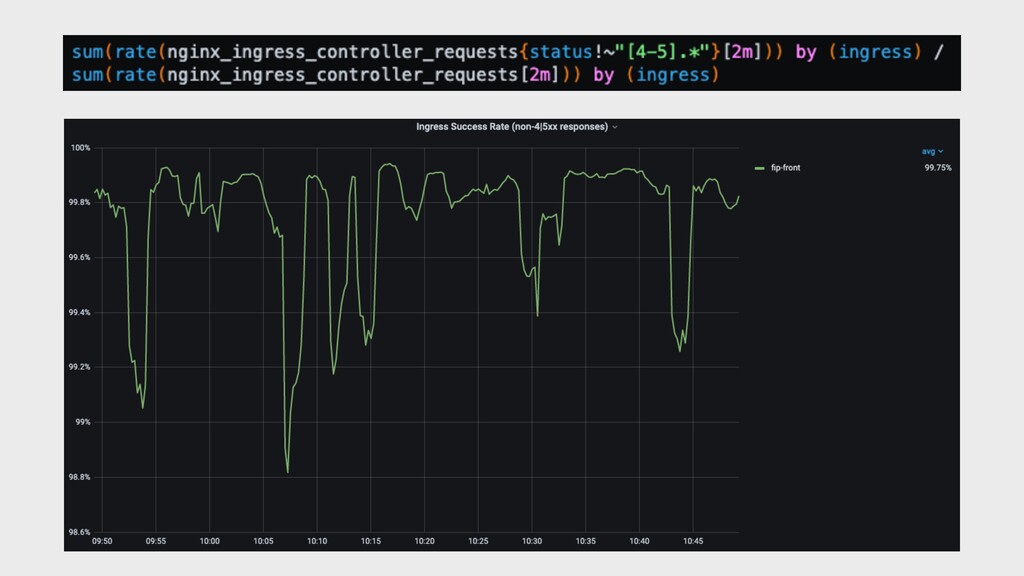{kind=link}
{kind=link}
{kind=link}
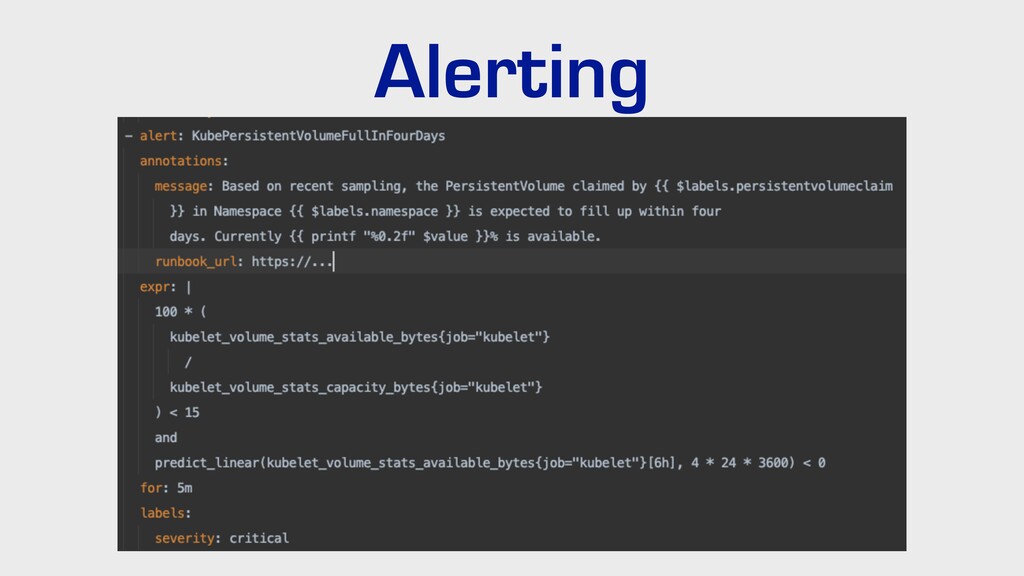{kind=link}
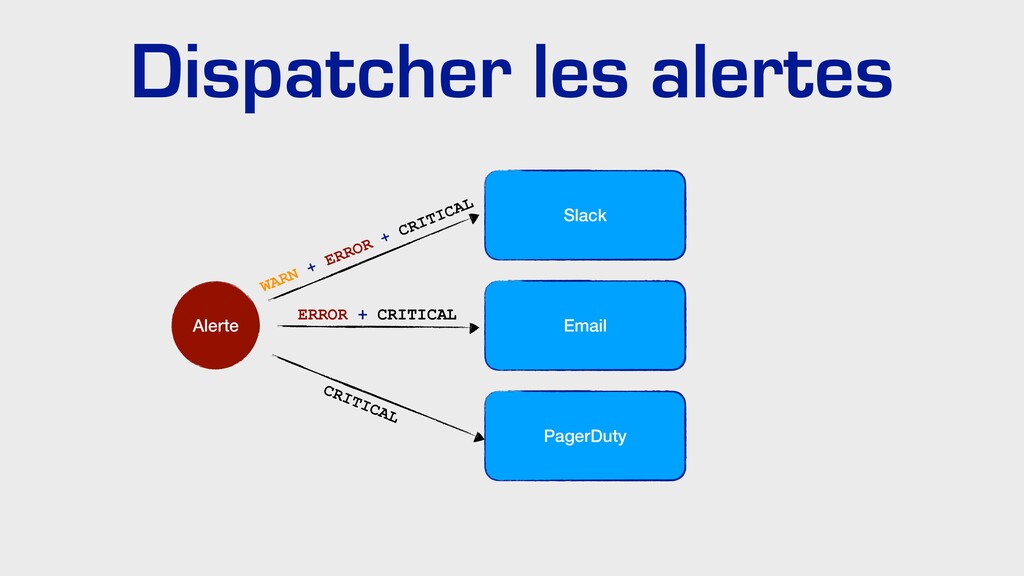{kind=link}
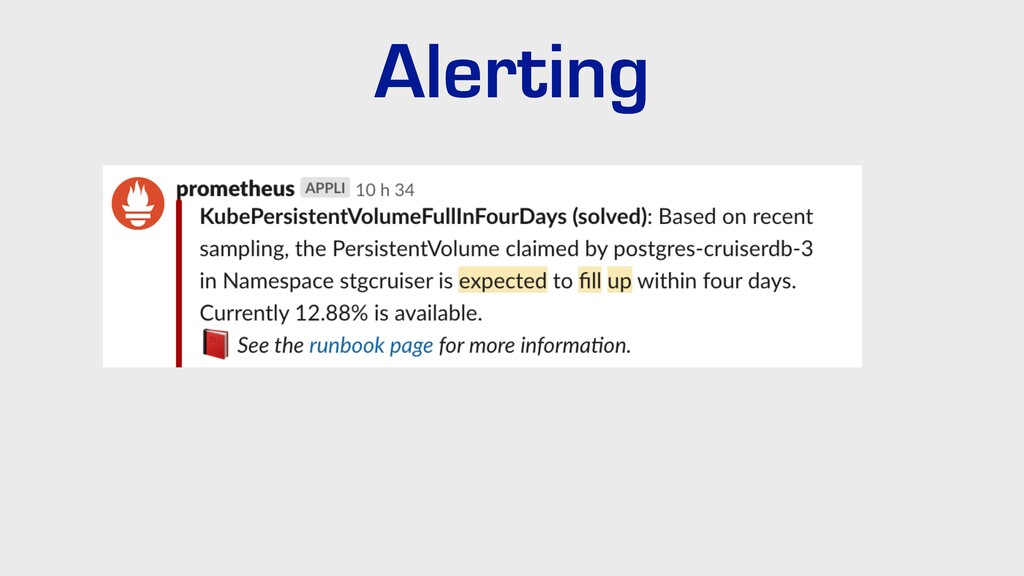{kind=link}
{kind=link}
{kind=link}
{kind=link}
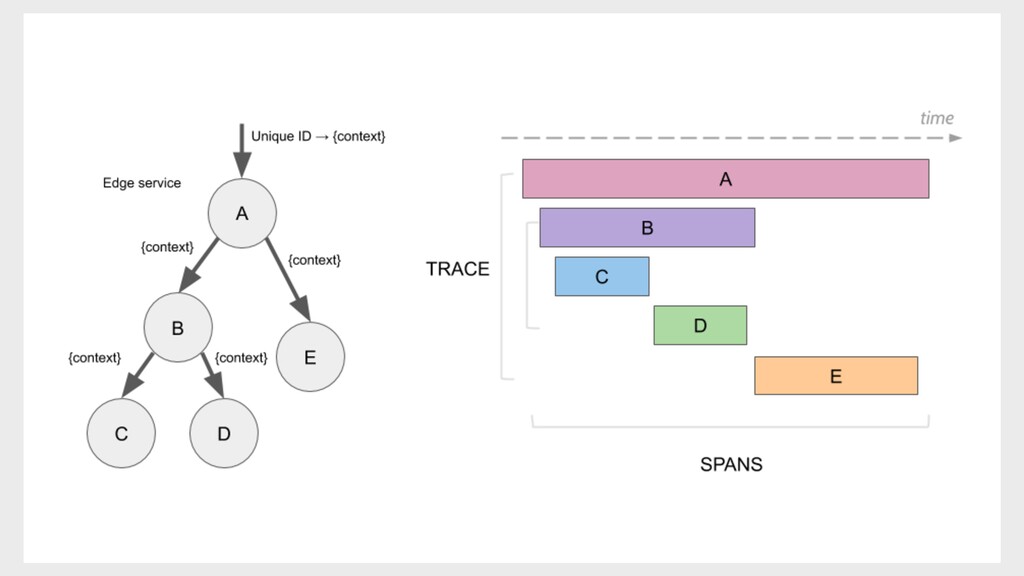{kind=link}
{kind=link}
{kind=link}
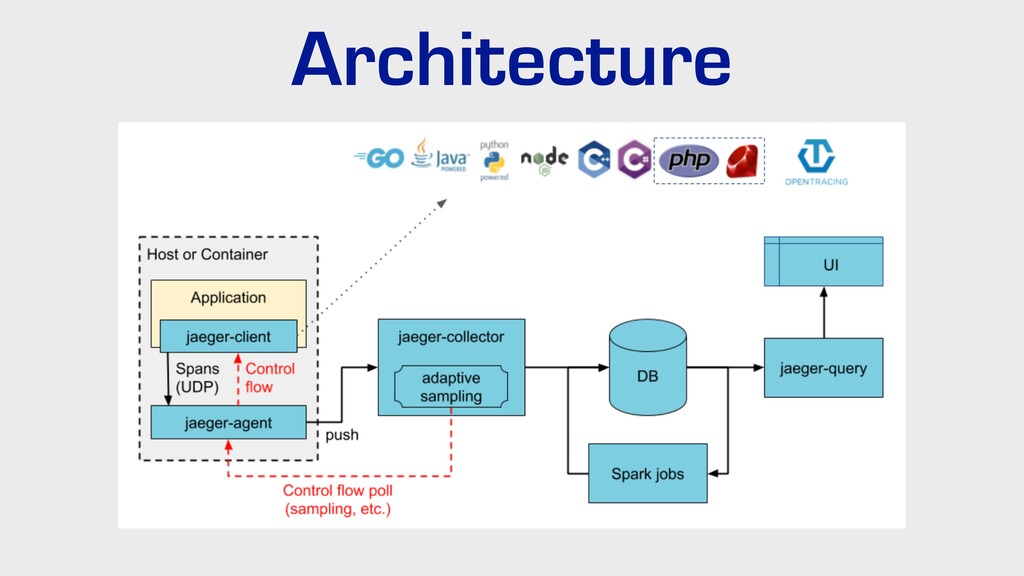{kind=link}
{kind=link}
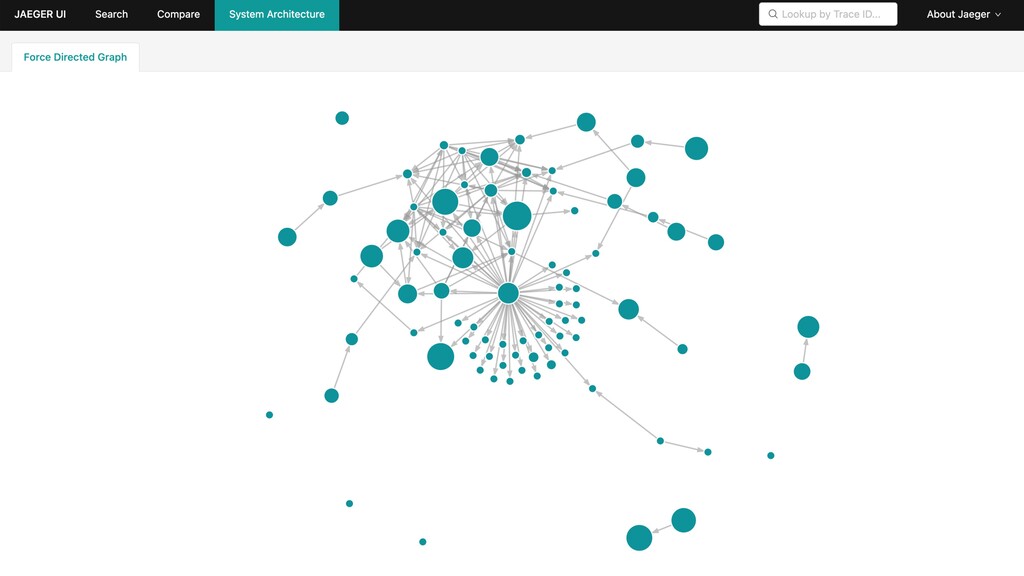{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}