Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
テキストマイニング
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
katsutan
March 09, 2017
Technology
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
テキストマイニング
長岡技術科学大学 自然言語処理研究室 B3ゼミ発表7
katsutan
March 09, 2017
More Decks by katsutan
See All by katsutan
What does BERT learn about the structure of language?
katsutan
0
270
Simple and Effective Paraphrastic Similarity from Parallel Translations
katsutan
0
230
Simple task-specific bilingual word embeddings
katsutan
0
230
Retrofitting Contextualized Word Embeddings with Paraphrases
katsutan
0
290
Character Eyes: Seeing Language through Character-Level Taggers
katsutan
1
250
Improving Word Embeddings Using Kernel PCA
katsutan
0
250
Better Word Embeddings by Disentangling Contextual n-Gram Information
katsutan
0
350
Rotational Unit of Memory: A Novel Representation Unit for RNNs with Scalable Applications
katsutan
0
290
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
katsutan
0
320
Other Decks in Technology
See All in Technology
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
2
520
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
190
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1k
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
200
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
200
Amazon Quick 入門!
ysuzuki
2
130
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
780
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
150
41歳でAWSが好きすぎてITエンジニアになったおっさんの話
yama3133
1
730
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
300
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
260
Featured
See All Featured
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Side Projects
sachag
455
43k
The Curse of the Amulet
leimatthew05
2
13k
RailsConf 2023
tenderlove
30
1.5k
My Coaching Mixtape
mlcsv
0
170
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Transcript
テキストマイニング 長岡技術科学大学 自然言語処理研究室 学部3年 勝田 哲弘 1 2017/3/10
テキストマイニングとは • テキストの中の言葉どうしに見られるパターン や規則性を見つけ、知識・情報を取り出す。 ▫ 形態素の出現頻度、あるかないか。 ▫ 出現パターンや相関関係を分析 • 言葉どうしの共通性、類似性
2
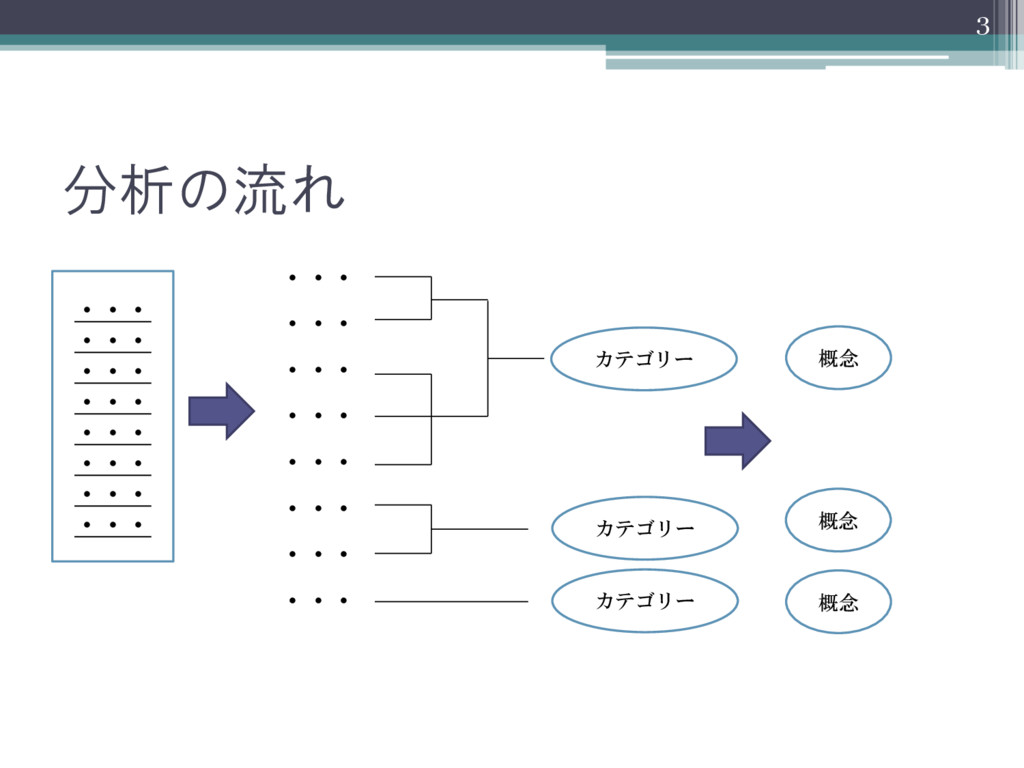
分析の流れ 3 ・・・ ・・・ ・・・ ・・・ ・・・ ・・・ ・・・ ・・・
・・・ ・・・ ・・・ ・・・ ・・・ ・・・ ・・・ ・・・ カテゴリー カテゴリー カテゴリー 概念 概念 概念
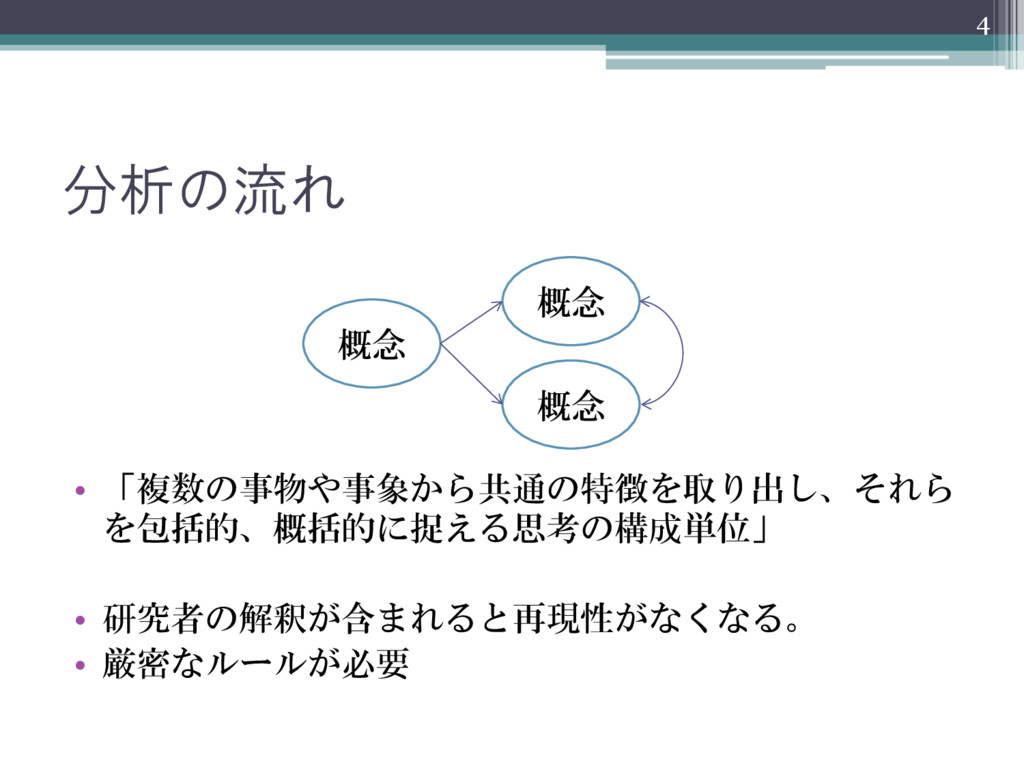
分析の流れ • 「複数の事物や事象から共通の特徴を取り出し、それら を包括的、概括的に捉える思考の構成単位」 • 研究者の解釈が含まれると再現性がなくなる。 • 厳密なルールが必要 4 概念
概念 概念
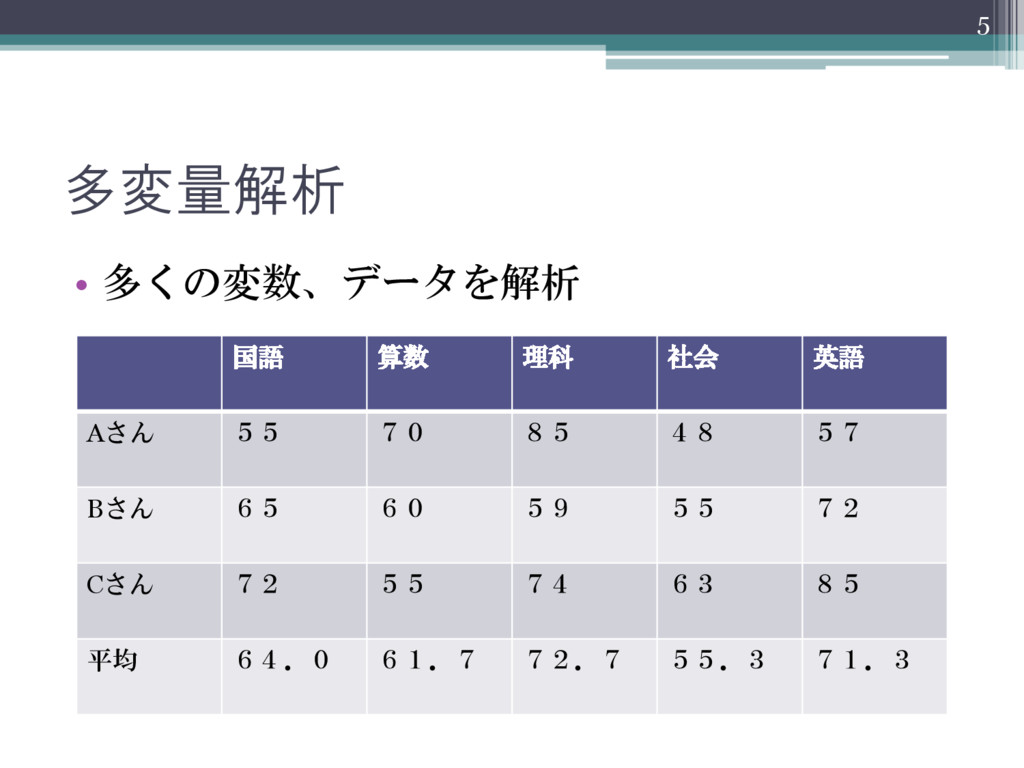
多変量解析 • 多くの変数、データを解析 5 国語 算数 理科 社会 英語 Aさん
55 70 85 48 57 Bさん 65 60 59 55 72 Cさん 72 55 74 63 85 平均 64.0 61.7 72.7 55.3 71.3
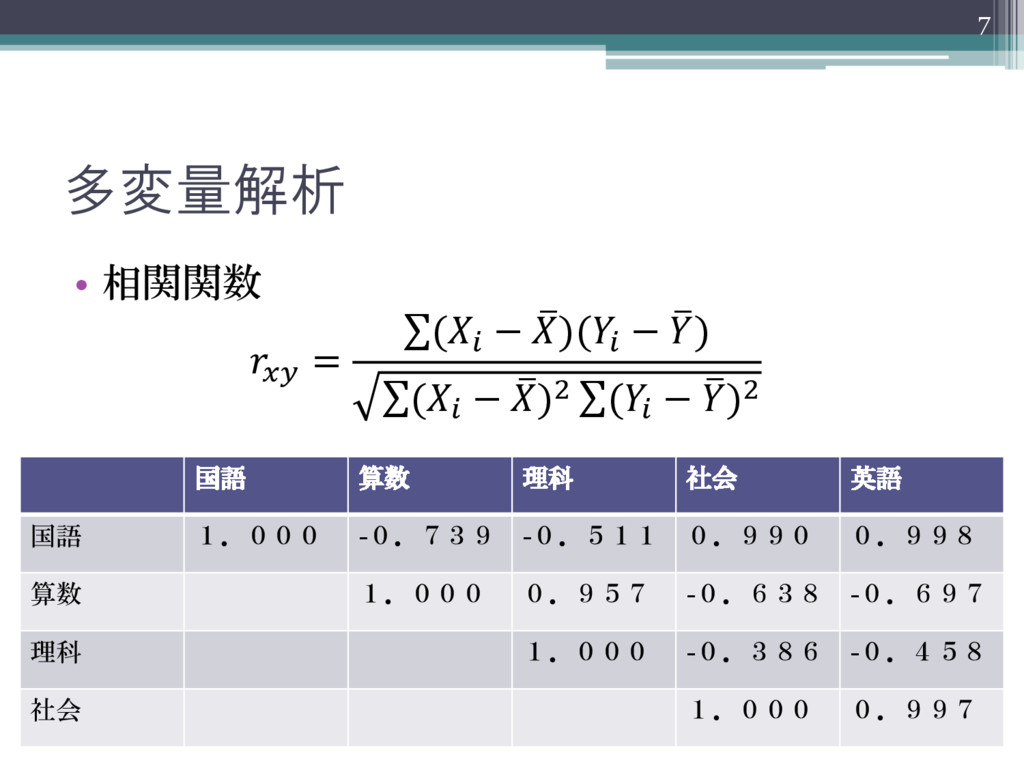
多変量解析 • 相関関数 = ( − )( − ) (
− )2 ( − )2 6
多変量解析 • 相関関数 = ( − )( − ) (
− )2 ( − )2 7 国語 算数 理科 社会 英語 国語 1.000 -0.739 -0.511 0.990 0.998 算数 1.000 0.957 -0.638 -0.697 理科 1.000 -0.386 -0.458 社会 1.000 0.997
Χ2値 • 共変動の強さ(分散の大きさ) = 実測値、 = 期待値 2 = −
2 =1 • 分散が大きい程データには何らかの意味を持っ ている 8
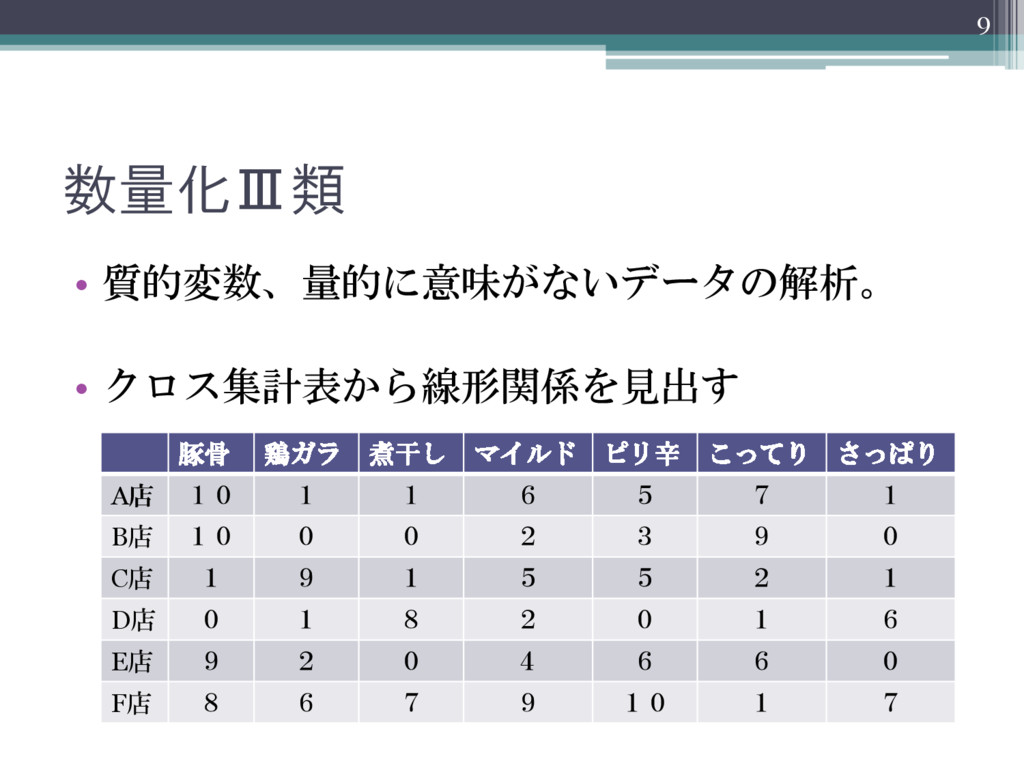
数量化Ⅲ類 • 質的変数、量的に意味がないデータの解析。 • クロス集計表から線形関係を見出す 9 豚骨 鶏ガラ 煮干し マイルド
ピリ辛 こってり さっぱり A店 10 1 1 6 5 7 1 B店 10 0 0 2 3 9 0 C店 1 9 1 5 5 2 1 D店 0 1 8 2 0 1 6 E店 9 2 0 4 6 6 0 F店 8 6 7 9 10 1 7
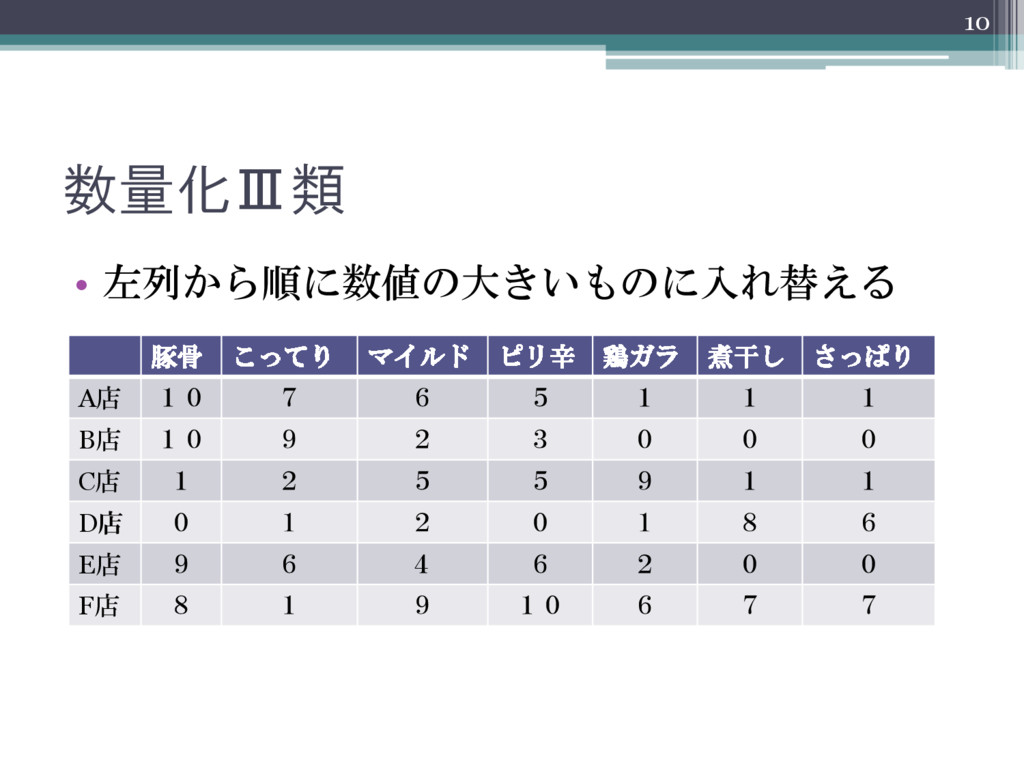
数量化Ⅲ類 • 左列から順に数値の大きいものに入れ替える 10 豚骨 こってり マイルド ピリ辛 鶏ガラ 煮干し
さっぱり A店 10 7 6 5 1 1 1 B店 10 9 2 3 0 0 0 C店 1 2 5 5 9 1 1 D店 0 1 2 0 1 8 6 E店 9 6 4 6 2 0 0 F店 8 1 9 10 6 7 7
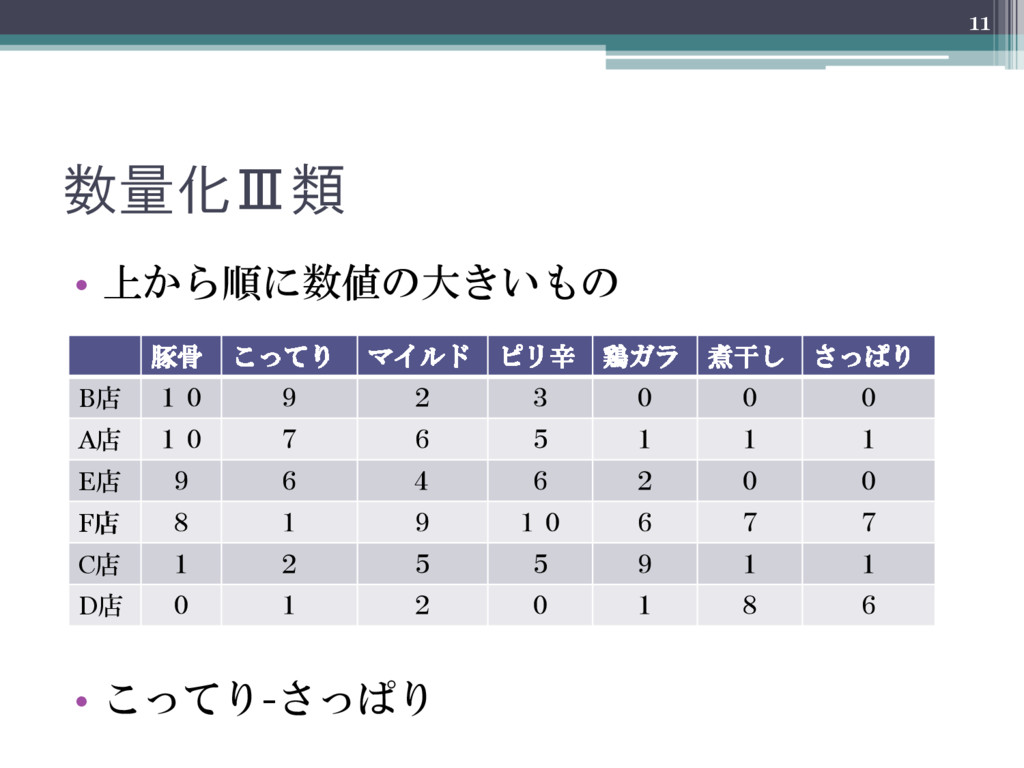
数量化Ⅲ類 • 上から順に数値の大きいもの • こってり-さっぱり 11 豚骨 こってり マイルド ピリ辛
鶏ガラ 煮干し さっぱり B店 10 9 2 3 0 0 0 A店 10 7 6 5 1 1 1 E店 9 6 4 6 2 0 0 F店 8 1 9 10 6 7 7 C店 1 2 5 5 9 1 1 D店 0 1 2 0 1 8 6
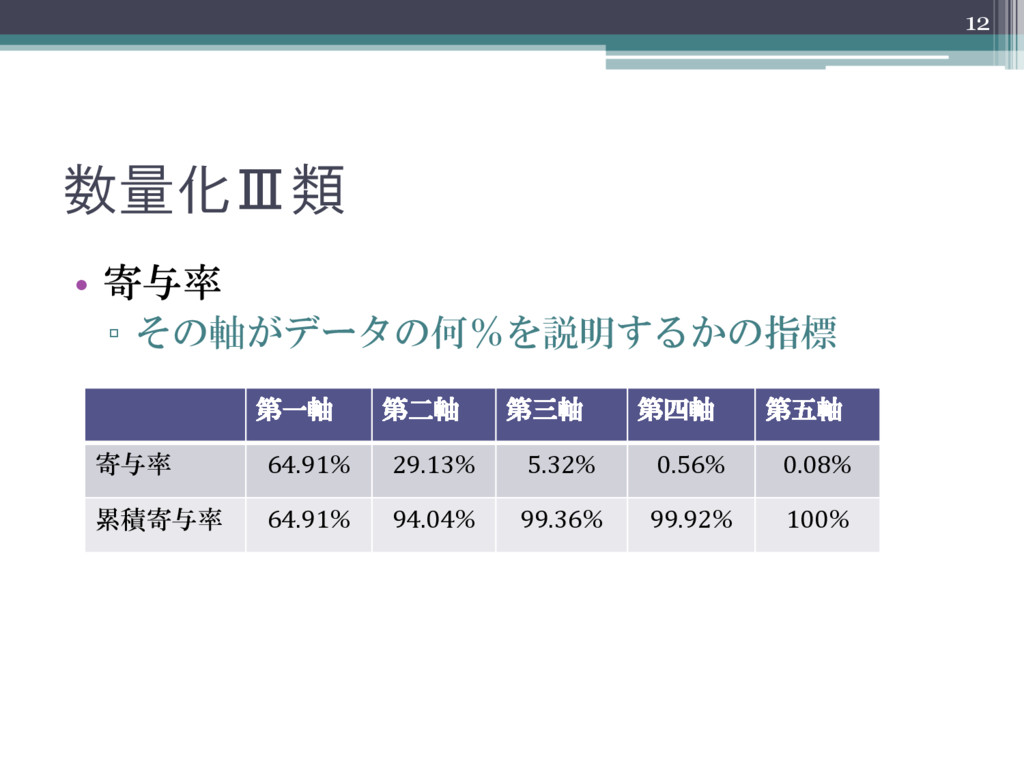
数量化Ⅲ類 • 寄与率 ▫ その軸がデータの何%を説明するかの指標 12 第一軸 第二軸 第三軸 第四軸
第五軸 寄与率 64.91% 29.13% 5.32% 0.56% 0.08% 累積寄与率 64.91% 94.04% 99.36% 99.92% 100%
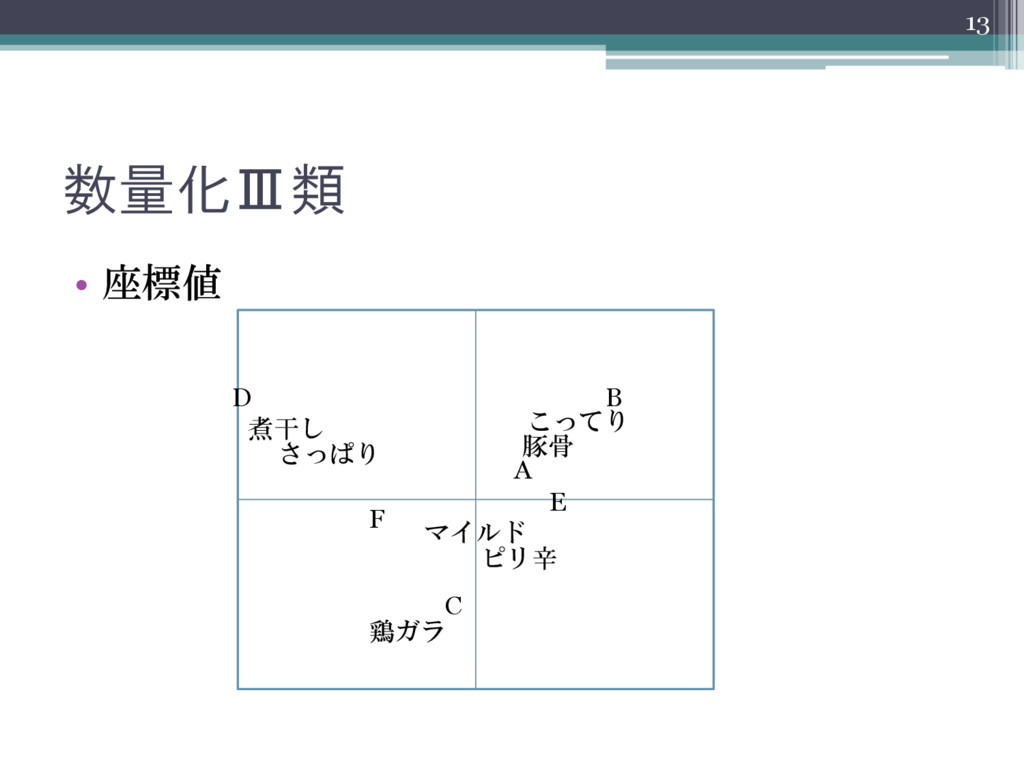
数量化Ⅲ類 • 座標値 13 B C D A E F
煮干し さっぱり こってり 豚骨 マイルド 鶏ガラ ピリ辛
まとめ • 言葉などの質的データに対する客観的な分析方 法はすでに確立している。 • 言葉のデータはどれをキーワードにするか、析 出するかという点は、恣意的、主観的になる。 14
参考文献 • 福祉・心理・看護のテキストマイニング入門 藤井美和・小杉考司・李政元 編著 中央法規 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}