Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] GRES: Generalized Referring Expr...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
June 23, 2023
Technology
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] GRES: Generalized Referring Expression Segmentation
Semantic Machine Intelligence Lab., Keio Univ.
PRO
June 23, 2023
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
AI工学特論: MLOps・継続的評価
asei
4
1k
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
1
160
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
320
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
170
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
170
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
13
4.3k
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
930
_NIKKEI_Tech_Talk__勉強会は熱量では続かない___17回続いた輪読会の設計術.pdf
_awache
1
100
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.5k
穢れた技術選定について
watany
19
6.1k
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
970
Featured
See All Featured
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
The Invisible Side of Design
smashingmag
301
52k
The untapped power of vector embeddings
frankvandijk
2
1.8k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
It's Worth the Effort
3n
188
29k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Why Our Code Smells
bkeepers
PRO
340
58k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
Transcript
GRES: Generalized Referring Expression Segmentation 杉浦孔明研究室 九曜克之 Chang Liu† Henghui
Ding† Xudong Jiang Nanyang Technological University, Singapore CVPR2023 highlight Liu, Chang et al. "GRES: Generalized Referring Expression Segmentation." CVPR. 2023.
背景:既存のRESはno/malti-targetを考慮できていない 2 既存RES⼿法の制限 Lどのオブジェクトにもマッチしない場合を考慮していない(no target) L複数のインスタンスを指し⽰すマルチターゲット表現が含まれていない 既存のRESデータセットで学習された⼿法は、 このようなシナリオにうまく対応できない “two guys
in black jacket” “the bed with red sheet” 失敗例
関連研究:no-/multi-target設定に対しては不⼗分 3 PhraseCutにはmulti-target表現があるが,対象物が⼀意に定まらない場合にのみ使⽤ データセット no-target multi-target 形式 ReferIt [Kazemzadeh+, EMNLP14]
× × ⾃由 RefCOCOg [Mao+, CVPR16] × × ⾃由 PhraseCut [Wu+, CVPR20] × △ テンプレート
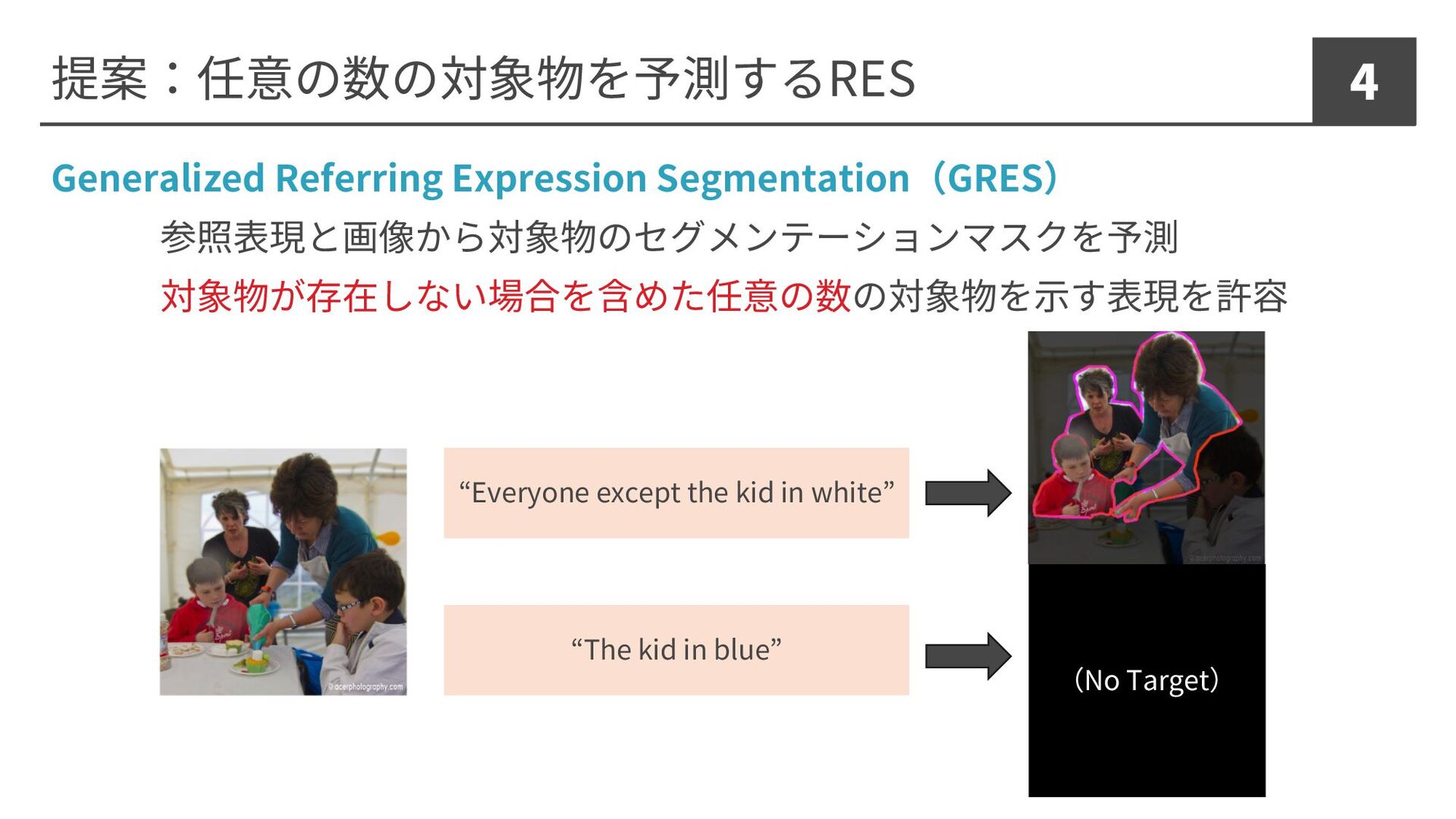
提案:任意の数の対象物を予測するRES 4 Generalized Referring Expression Segmentation(GRES) 参照表現と画像から対象物のセグメンテーションマスクを予測 対象物が存在しない場合を含めた任意の数の対象物を⽰す表現を許容 “Everyone except
the kid in white” “The kid in blue” (No Target)
データセット: RefCOCOを基にGRES⽤に新たに構築 5 gRefCOCO • RefCOCO [Kazemzadeh+, EMNLP14]を⽤いて構築 • 参照表現,対応する画像,対象物のマスク画像およびno-targetを⽰すラベル
画像数 インスタンス数 参照表現数 multi-target no-target 19,994 60,287 278,232 80,022 32,202 “horse on center and its rider” “the guy standing in back”(no target)
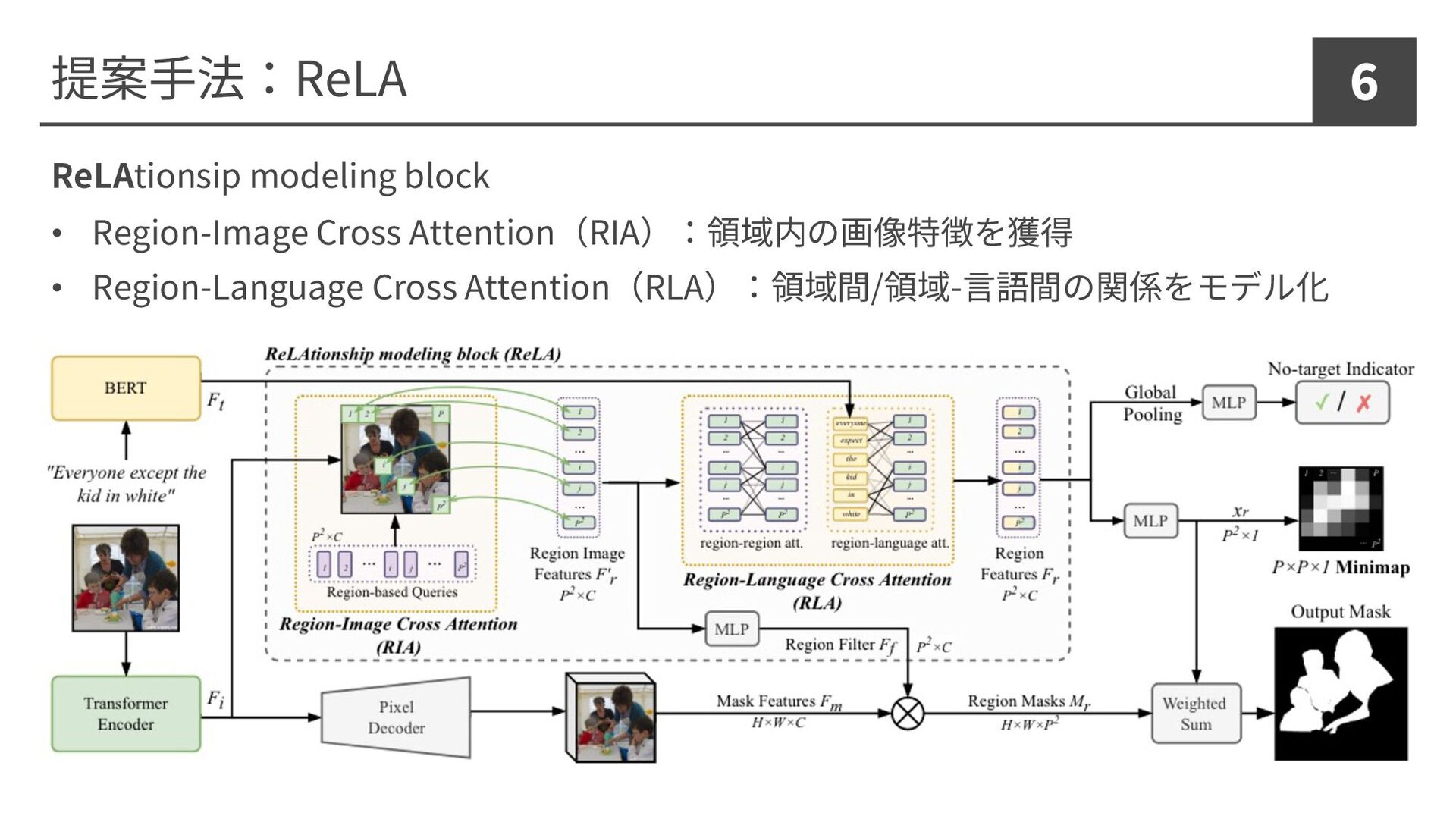
提案⼿法:ReLA 6 ReLAtionsip modeling block • Region-Image Cross Attention(RIA):領域内の画像特徴を獲得 •
Region-Language Cross Attention(RLA):領域間/領域-⾔語間の関係をモデル化
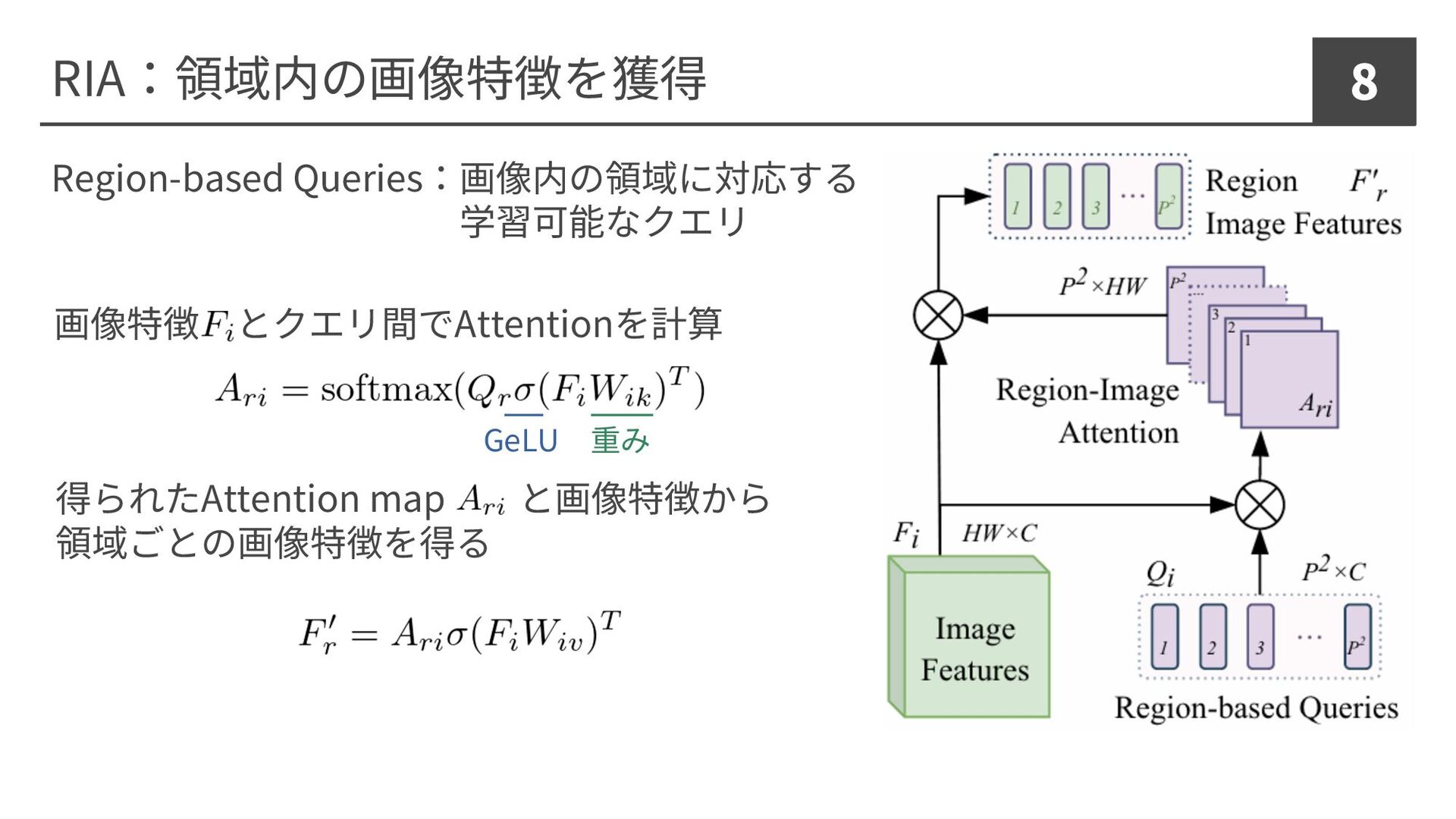
RIA:領域内の画像特徴を獲得 8 Region-based Queries:画像内の領域に対応する 学習可能なクエリ 画像特徴 とクエリ間でAttentionを計算 得られたAttention map と画像特徴から
領域ごとの画像特徴を得る GeLU 重み
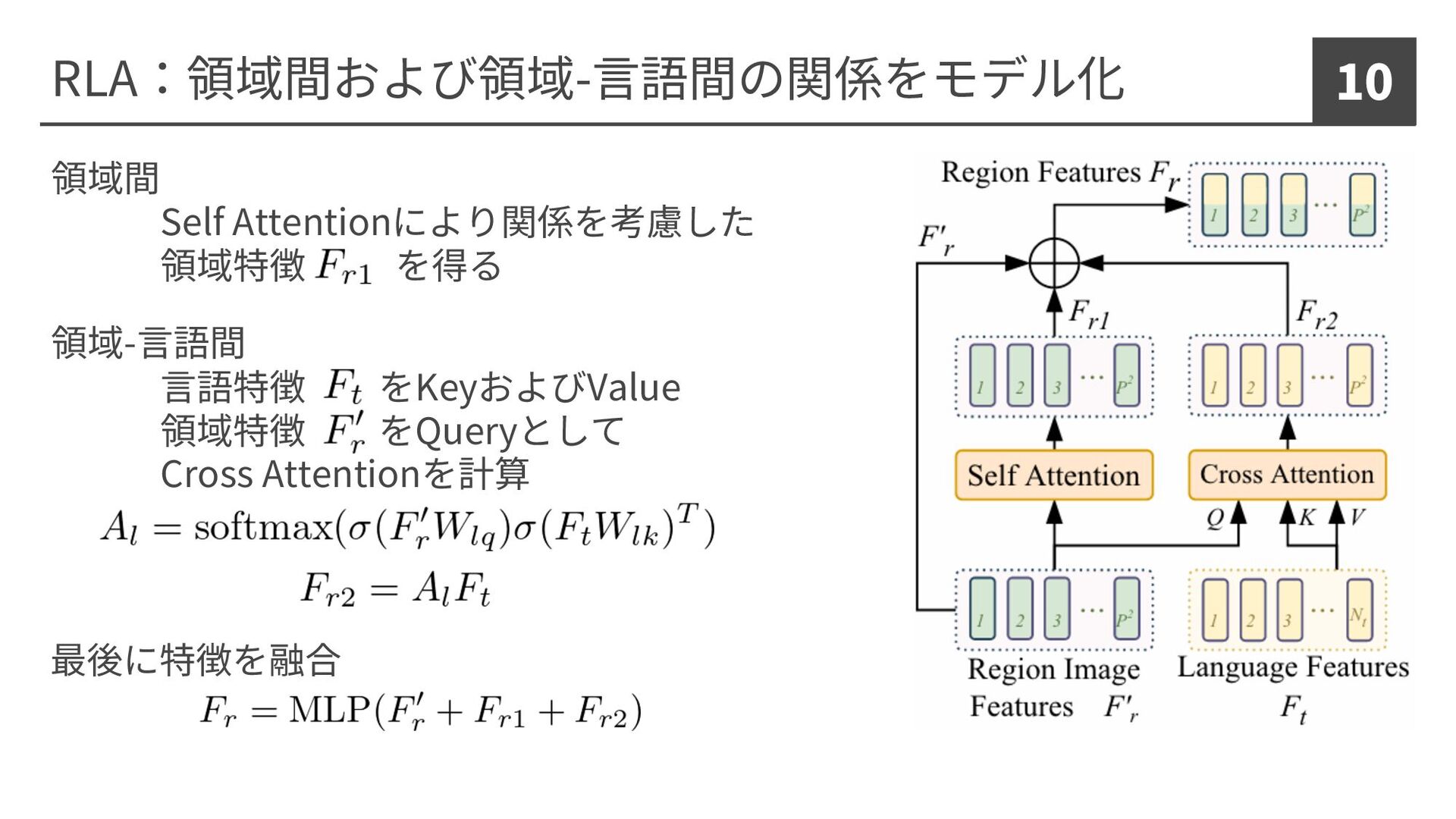
RLA:領域間および領域-⾔語間の関係をモデル化 10 領域間 Self Attentionにより関係を考慮した 領域特徴 を得る 領域-⾔語間 ⾔語特徴 をKeyおよびValue
領域特徴 をQueryとして Cross Attentionを計算 最後に特徴を融合
実験設定:no-targetに拡張した標準的な尺度で評価 11 評価尺度 • cIoU(=oIoU),Precision@k • generalized IoU(≒mIoU) • no-target
sampleについて拡張 • TPの場合:gIoU = 1 • FNの場合:gIoU = 0 • N-acc/T-acc:no-target sample識別における評価尺度 実際にno-target,targetをどれだけ取りこぼさず予測できたかを表す
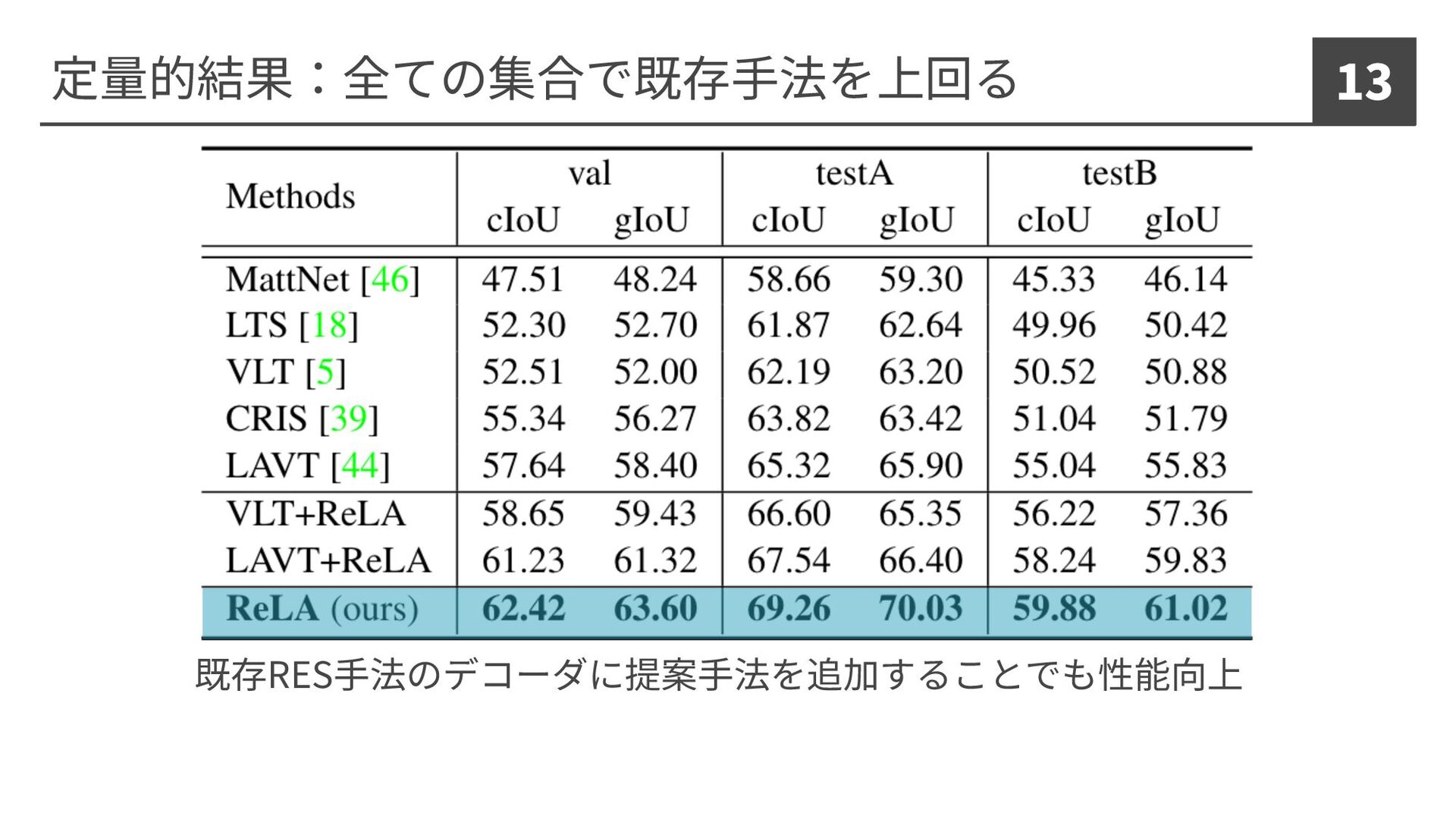
定量的結果:全ての集合で既存⼿法を上回る 13 既存RES⼿法のデコーダに提案⼿法を追加することでも性能向上
既存RESデータセットでも提案⼿法が⾼い性能 14 ほとんどの集合でLAVT [Yang+, CVPR22]よりも⾼い性能 J提案⼿法が既存RES⼿法にも有効
定性的結果:複雑な参照表現に適したマスクの⽣成 15 “two bowls on right” “Everyone except the blurry
guy” Jtwo bowlsという数の表現および on rightを正確に理解 Jexcept(除外関係)を理解
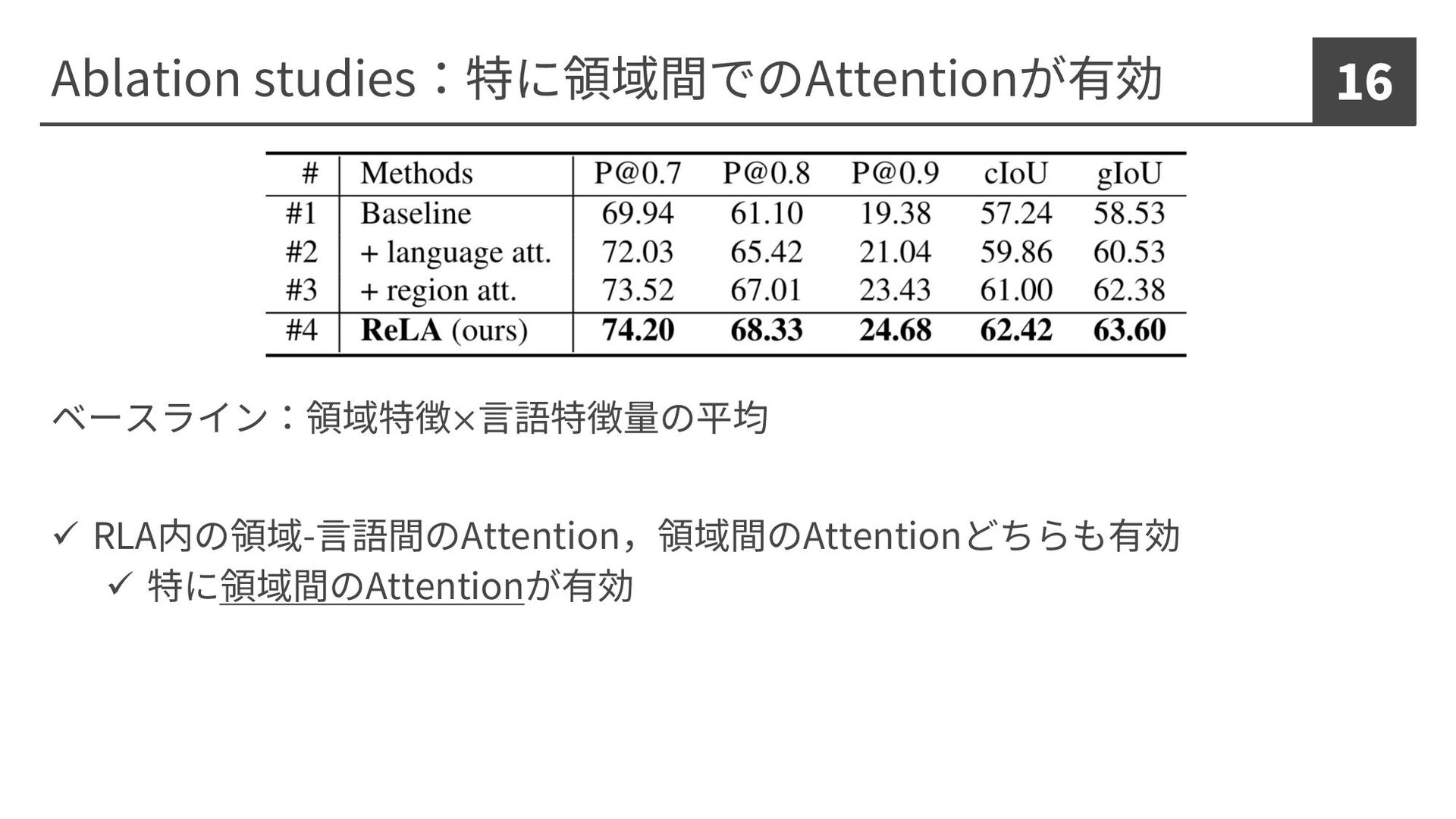
Ablation studies:特に領域間でのAttentionが有効 16 ベースライン:領域特徴×⾔語特徴量の平均 ü RLA内の領域-⾔語間のAttention,領域間のAttentionどちらも有効 ü 特に領域間のAttentionが有効
所感 17 Strengths • データセットと⼿法両⽅ • 標準データセットでも実験し性能向上している • ReLAは既存モデルと組み合わせても有⽤ Weaknesses
• no targetサンプルとして許容する/しないの基準が曖昧 • 画像に無いものを表現するとなると個⼈間のばらつきが⼤きそう Others • 改善するならRegion-based QueriesにSAMのマスクを導⼊ • 命名はどうにかならなかったのか…(gRefCOCO vs G-Ref)
まとめ 18 背景 既存のRESはno/malti-targetを考慮できていない 提案 no/malti-targetを許容したRESタスクGRES GRESタスクのためのデータセットgRefCOCO ベースラインモデルReLA 結果 gRefCOCOにおいて全ての評価尺度で既存RES⼿法を上回る
RESの標準データセットにおいて既存RES⼿法と同等以上の性能
Appendix
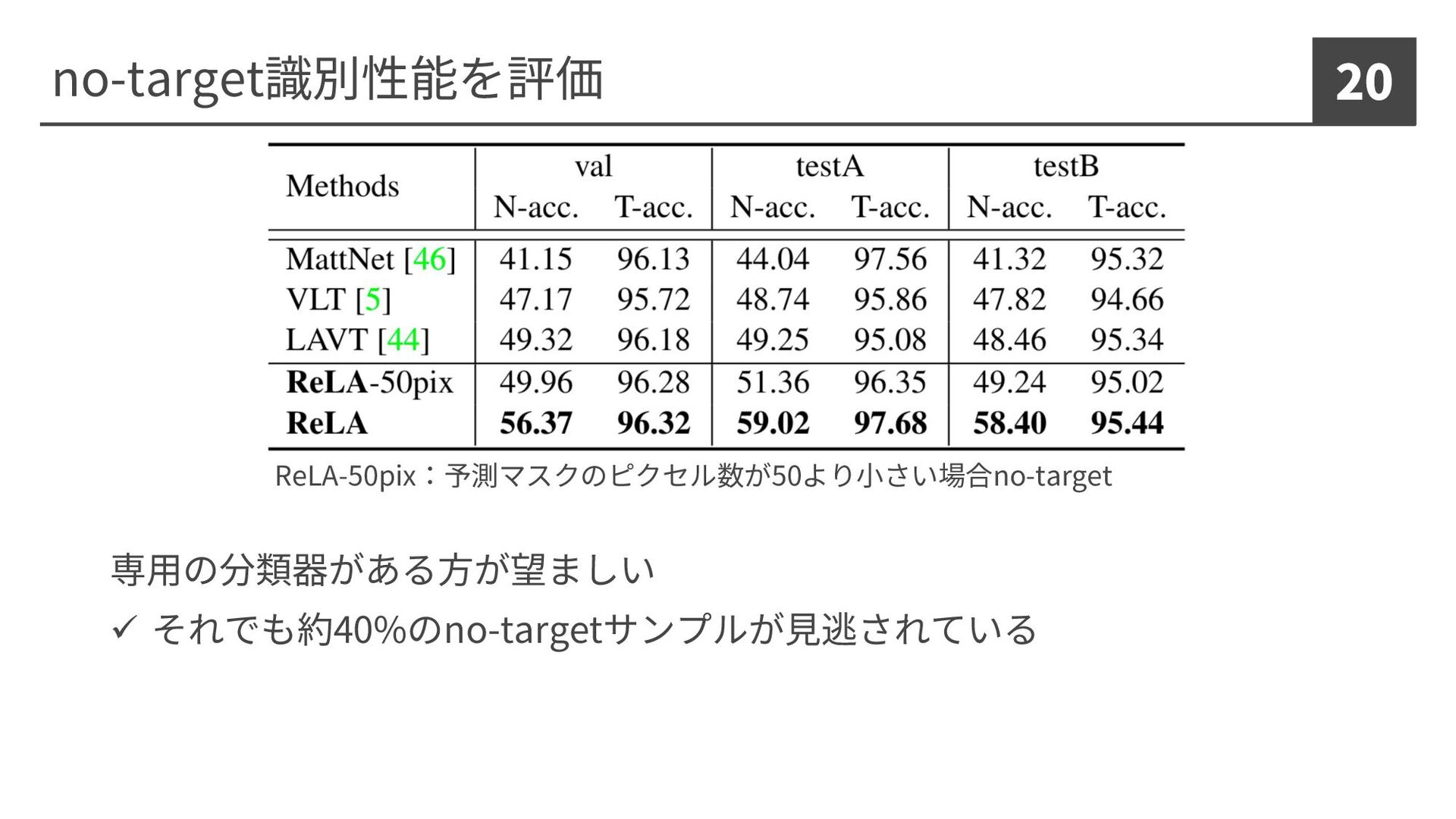
no-target識別性能を評価 20 専⽤の分類器がある⽅が望ましい ü それでも約40%のno-targetサンプルが⾒逃されている ReLA-50pix:予測マスクのピクセル数が50より⼩さい場合no-target
multi-targetがもたらす課題 21 1. 計数表現(序数詞と基数詞) 2. 幾何学的関係を持たない複合⽂構造( “A except B”, “A
with B or C”) 3. 属性の範囲(multi-targetにおいて属性がどこまで修飾するか) 4. より複雑な関係(代名詞)
no-targetサンプル作成時の条件 22 1. 画像と全く無関係な表現の禁⽌ 2. 1で必要な表現が思いつきにくい場合、RefCOCOの同じデータ集合に含まれる 他の画像から引き出された表現を選ぶことができる
gRefCOCOその他の例 23
定性的結果(失敗例) 24
学習設定 25 学習時間:記載なし デバイス:4 × V100 GPUs
{kind=link}
{kind=link}
![関連研究:no-/multi-target設定に対しては不⼗分 3 PhraseCutにはmulti-target表現があるが,対象物が⼀意に定まらない場合にのみ使⽤ データセット no-target multi-target 形式 ReferIt [Kazemzadeh+, EMNLP14]](https://files.speakerdeck.com/presentations/bdc73c44ea9a4d38903e4897e7864cb1/slide_2.jpg){kind=link}
{kind=link}
![データセット: RefCOCOを基にGRES⽤に新たに構築 5 gRefCOCO • RefCOCO [Kazemzadeh+, EMNLP14]を⽤いて構築 • 参照表現,対応する画像,対象物のマスク画像およびno-targetを⽰すラベル](https://files.speakerdeck.com/presentations/bdc73c44ea9a4d38903e4897e7864cb1/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![既存RESデータセットでも提案⼿法が⾼い性能 14 ほとんどの集合でLAVT [Yang+, CVPR22]よりも⾼い性能 J提案⼿法が既存RES⼿法にも有効](https://files.speakerdeck.com/presentations/bdc73c44ea9a4d38903e4897e7864cb1/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}