Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Toeplitz Neural Network for Sequ...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
December 21, 2023
Technology
1.1k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Toeplitz Neural Network for Sequence Modeling
慶應義塾⼤学 杉浦孔明研究室 M1 和田唯我 / Yuiga Wada
Semantic Machine Intelligence Lab., Keio Univ.
PRO
December 21, 2023
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Evo-1: Lightweight Vision-Language-Action Model with Preserved Semantic Alignment
keio_smilab
PRO
0
13
[MIRU26] To What Extent Does MLLM-as-a-Judge Exhibit Cross-Model Preference Bias?
keio_smilab
PRO
0
6
[Journal club] DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models
keio_smilab
PRO
1
13
[Journal club] SpecVLM: Enhancing Speculative Decoding of Video LLMs via Verifier-Guided Token Pruning
keio_smilab
PRO
0
9
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
89
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
90
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
120
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
100
Other Decks in Technology
See All in Technology
書籍セキュアAPIについて
riiimparm
0
360
Flutter研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
220
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
1.1k
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.8k
Power Automateアップデート情報
miyakemito
0
260
『モンスターストライク』 の運営に伴走する! データ民主化への 解析グループの3つのアプローチ
mixi_engineers
PRO
0
130
AI工学特論: MLOps・継続的評価
asei
11
2.9k
人手不足への挑戦:車両保全を支えるIoTとクラウド内製化の道【SORACOM Discovery 2026】
soracom
PRO
0
110
コンテナ・K8s研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
400
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
210
数値で見る Microsoft MVP 〜Spec Kit と GitHub Copilot Agent で作るデータ可視化ダッシュボード〜
yutakaosada
0
150
ソフトウェアアーキテクチャ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
740
Featured
See All Featured
My Coaching Mixtape
mlcsv
0
180
The Cost Of JavaScript in 2023
addyosmani
55
10k
Producing Creativity
orderedlist
PRO
348
40k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
The agentic SEO stack - context over prompts
schlessera
0
850
Chasing Engaging Ingredients in Design
codingconduct
0
240
Deep Space Network (abreviated)
tonyrice
0
230
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
How to Ace a Technical Interview
jacobian
281
24k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
360
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
Transcript
Toeplitz Neural Network for Sequence Modeling Zhen Qin2, Xiaodong Han2,
Weixuan Sun3, Bowen He2, Dong Li1, Dongxu Li3, Yuchao Dai4, Lingpeng Kong5, Yiran Zhong1 (1Shanghai AI Laboratory, 2SenseTime Research, 3Australian National University, 4Northwestern Polytechnical University, 5The University of Hong Kong) 慶應義塾⼤学 杉浦孔明研究室 M1 和⽥唯我 Zhen Qin et al., “Toeplitz Neural Network for Sequence Modeling” in ICLR (2023) ICLR23 notable top 25%
概要 2 ü 背景 • Transformerは①トークン間の関係を捉え,②位置情報を埋め込む • Transformerの問題点: 系列⻑に対してquadraticな計算量が掛かる ü
提案⼿法 • Toeplitz⾏列によりモデリングされたTNNを提案 • 時間計算量: O 𝑑𝑛log 𝑛 / 空間計算量: O 𝑑𝑛 を実現 ü 結果 • 様々なベンチマークにおいて⾼速かつSOTA⼿法に匹敵する性能
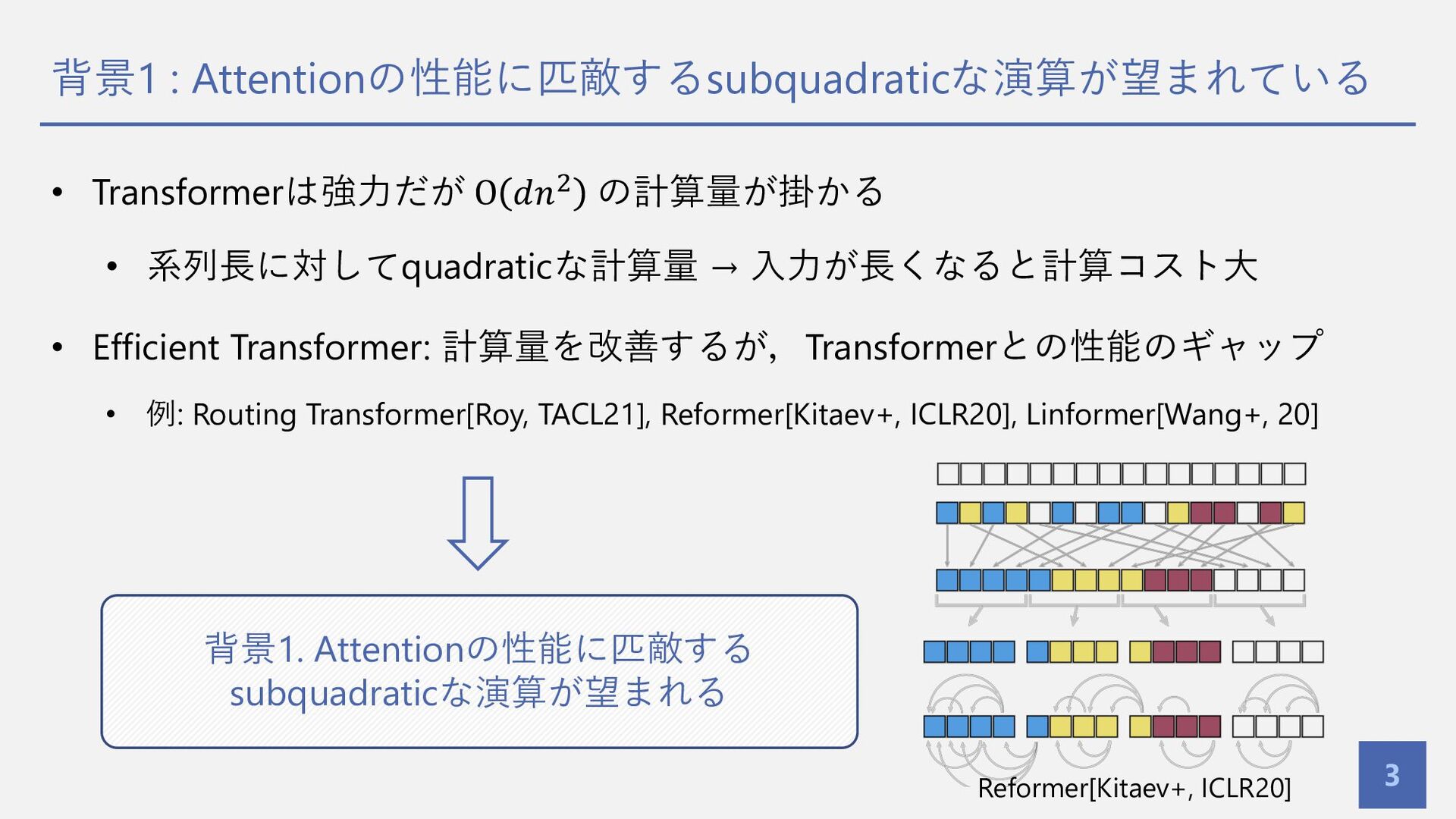
背景1 : Attentionの性能に匹敵するsubquadraticな演算が望まれている 3 • Transformerは強⼒だが O 𝑑𝑛! の計算量が掛かる •
系列⻑に対してquadraticな計算量 → ⼊⼒が⻑くなると計算コスト⼤ • Efficient Transformer: 計算量を改善するが,Transformerとの性能のギャップ • 例: Routing Transformer[Roy, TACL21], Reformer[Kitaev+, ICLR20], Linformer[Wang+, 20] 背景1. Attentionの性能に匹敵する subquadraticな演算が望まれる Reformer[Kitaev+, ICLR20]
背景2 : 相対的な位置情報に焦点を当てたアーキテクチャ 4 o Transformerの2つの特性 ① 任意の⼆点におけるトークン同⼠の関係を学習 ② Positional
Encodingにより位置情報を学習 o Attentionには様々な種類が存在 (c.f., Linear Attention) • ①は常に満たされているわけではない (計算コストとのtrade-off) • ⼀⽅で,どのバリエーションのAttentionでも②は常に満⾜ 背景2. トークンの内容ではなく相対的な位置情報に 焦点を当てたアーキテクチャを⽬指す (not ① but ②) cosFormer [Qin+, ICLR22]
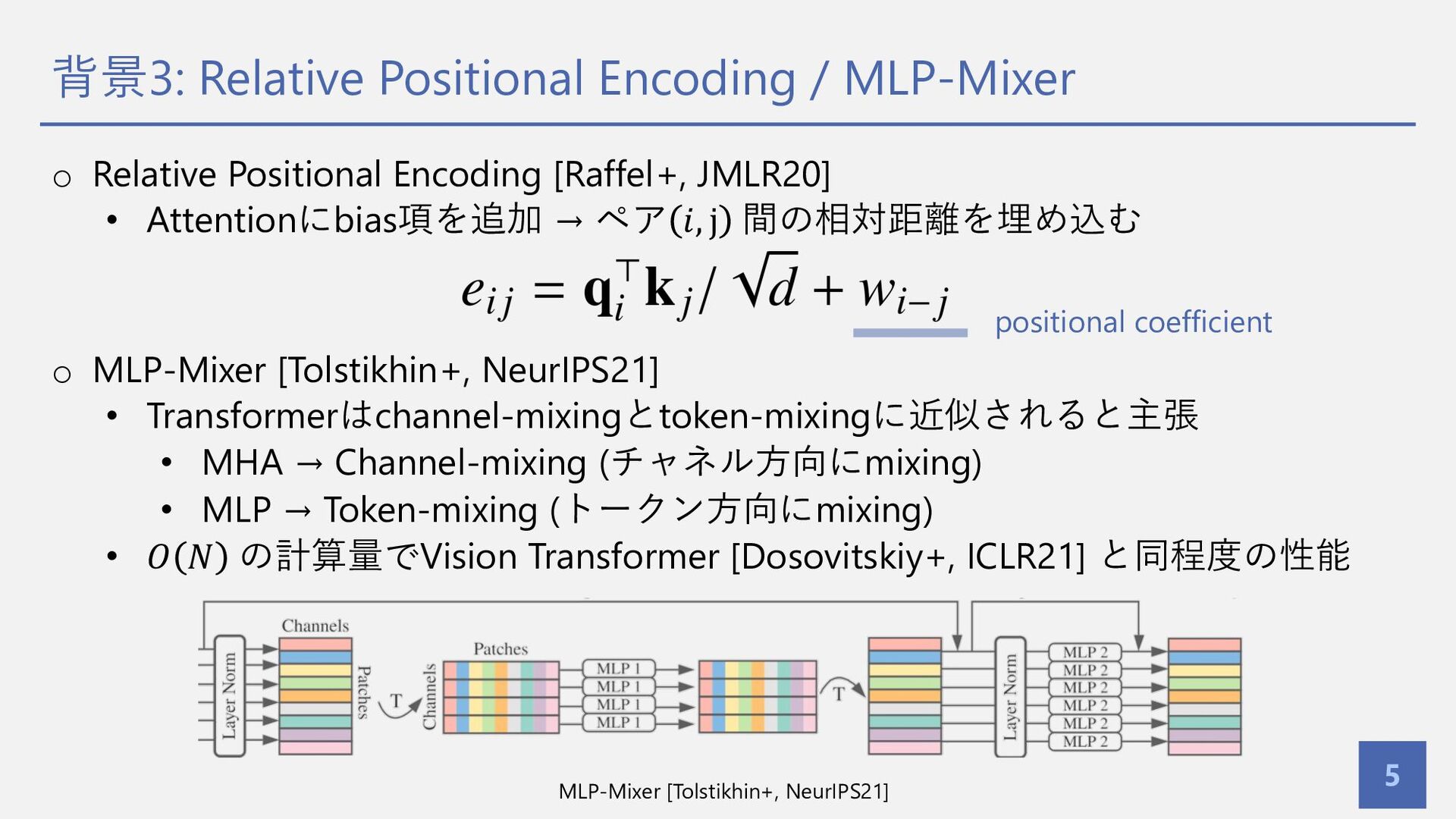
背景3: Relative Positional Encoding / MLP-Mixer 5 o Relative Positional
Encoding [Raffel+, JMLR20] • Attentionにbias項を追加 → ペア 𝑖, j 間の相対距離を埋め込む o MLP-Mixer [Tolstikhin+, NeurIPS21] • Transformerはchannel-mixingとtoken-mixingに近似されると主張 • MHA → Channel-mixing (チャネル⽅向にmixing) • MLP → Token-mixing (トークン⽅向にmixing) • 𝑂 𝑁 の計算量でVision Transformer [Dosovitskiy+, ICLR21] と同程度の性能 positional coefficient MLP-Mixer [Tolstikhin+, NeurIPS21]
背景3: Relative Positional Encoding / MLP-Mixer 6 o Relative Positional
Encoding [Raffel+, JMLR20] • Attentionにbias項を追加 → ペア 𝑖, j 間の相対距離を埋め込む o MLP-Mixer [Tolstikhin+, NeurIPS21] • Transformerはchannel-mixingとtoken-mixingに近似されると主張 • MHA → Channel-mixing (チャネル⽅向にmixing) • MLP → Token-mixing (トークン⽅向にmixing) • 𝑂 𝑁 の計算量でVision Transformer [Dosovitskiy+, ICLR21] と同程度の性能 positional coefficient MLP-Mixer [Tolstikhin+, NeurIPS21] 背景3. Relative PEおよびMLP-Mixerを 踏襲したアーキテクチャを⽬指す
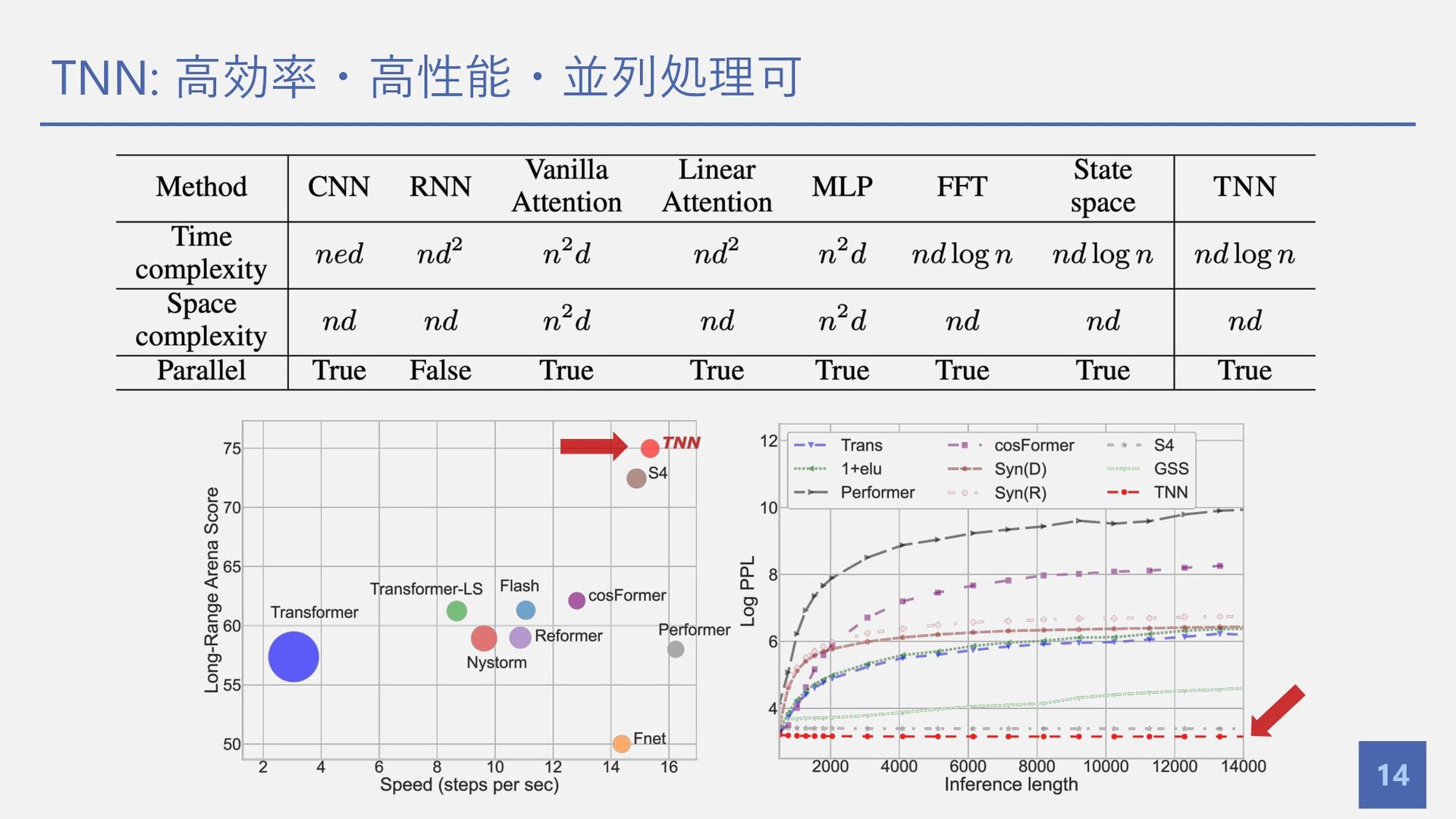
復習: Toeplitz⾏列によるモデリングは利点が多い 7 o Toeplitz⾏列 • 対⾓線に沿って値が⼀定である⾏列 • ⾏列積は O
𝑛log 𝑛 で計算可 • SSMや畳み込みはToeplitz⾏列で表現可 • これらの⼿法を⼀般化したモデリングが可 o Toeplitz⾏列によるモデリングは利点が多い • 𝑛 × 𝑛で 2𝑛 − 1のパラメタ → 低コスト • O 𝑛log 𝑛 の計算量で⾏列積が計算可能 → ⾼効率 → Toeplitz⾏列によりモデリングされたTNNを提案
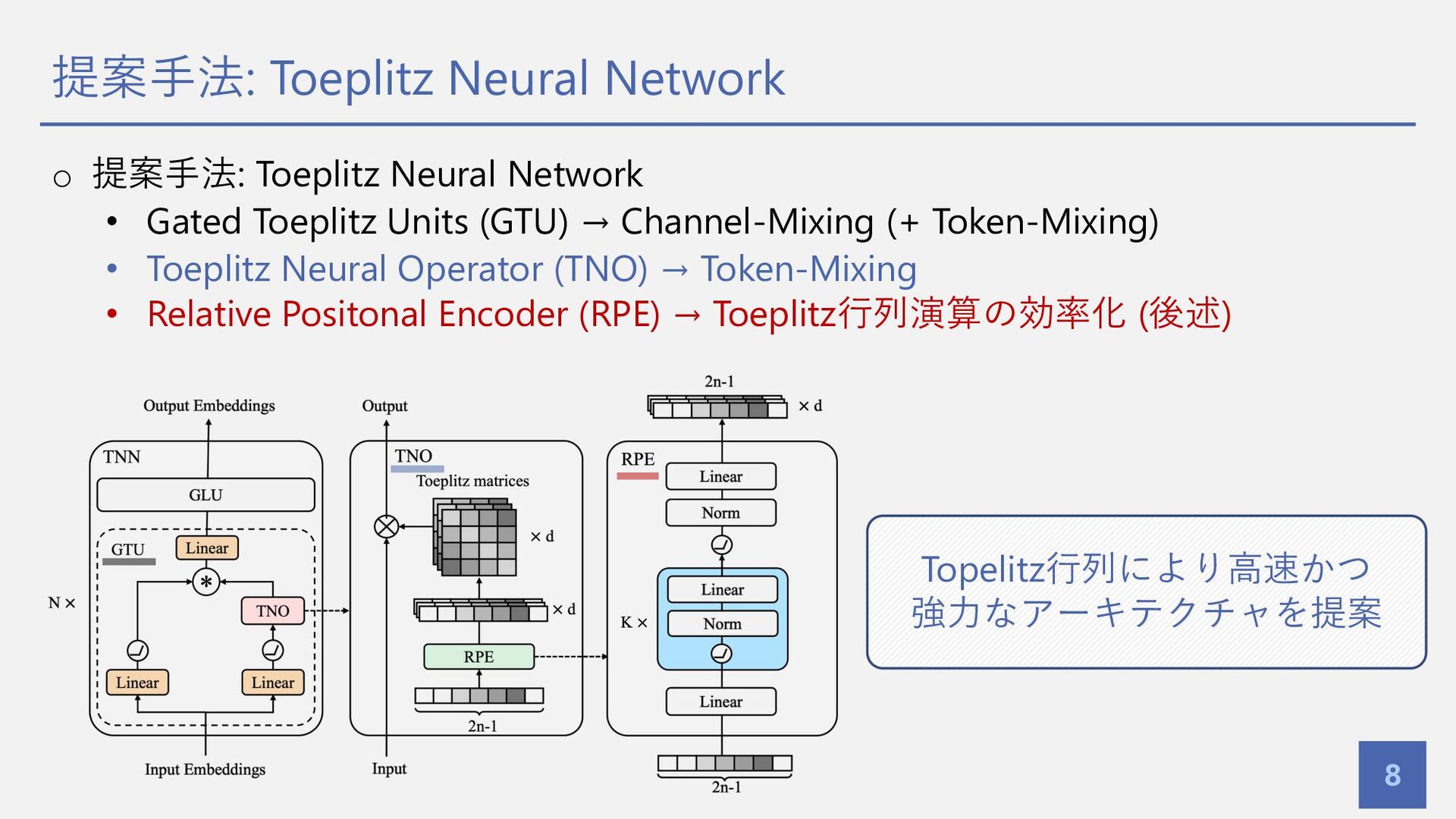
提案⼿法: Toeplitz Neural Network 8 o 提案⼿法: Toeplitz Neural Network
• Gated Toeplitz Units (GTU) → Channel-Mixing (+ Token-Mixing) • Toeplitz Neural Operator (TNO) → Token-Mixing • Relative Positonal Encoder (RPE) → Toeplitz⾏列演算の効率化 (後述) Topelitz⾏列により⾼速かつ 強⼒なアーキテクチャを提案
None
None
提案⼿法: Toeplitz Neural Network 11 o 𝑻を如何に学習させるか? • 仮案: Naiveな⽅法として,全てを学習可能パラメタに
… ? o 仮案の問題点 問題点1. Parameter explosion • 𝑑次元のトークンが 𝑛 個あった場合のToeplitzのパラメタ数 • 2𝑛 − 1 𝑑 = O 𝑑𝑛 ← 𝑛 によってパラメタ数が増⼤ 問題点2. Fixed input sequence • 系列⻑ 𝑛 が固定されるため,可変⻑の⼊⼒に対応できない 𝑻を効率的かつ効果的に学習させる⽅法が必要 → Relative Positonal Encoder (RPE)
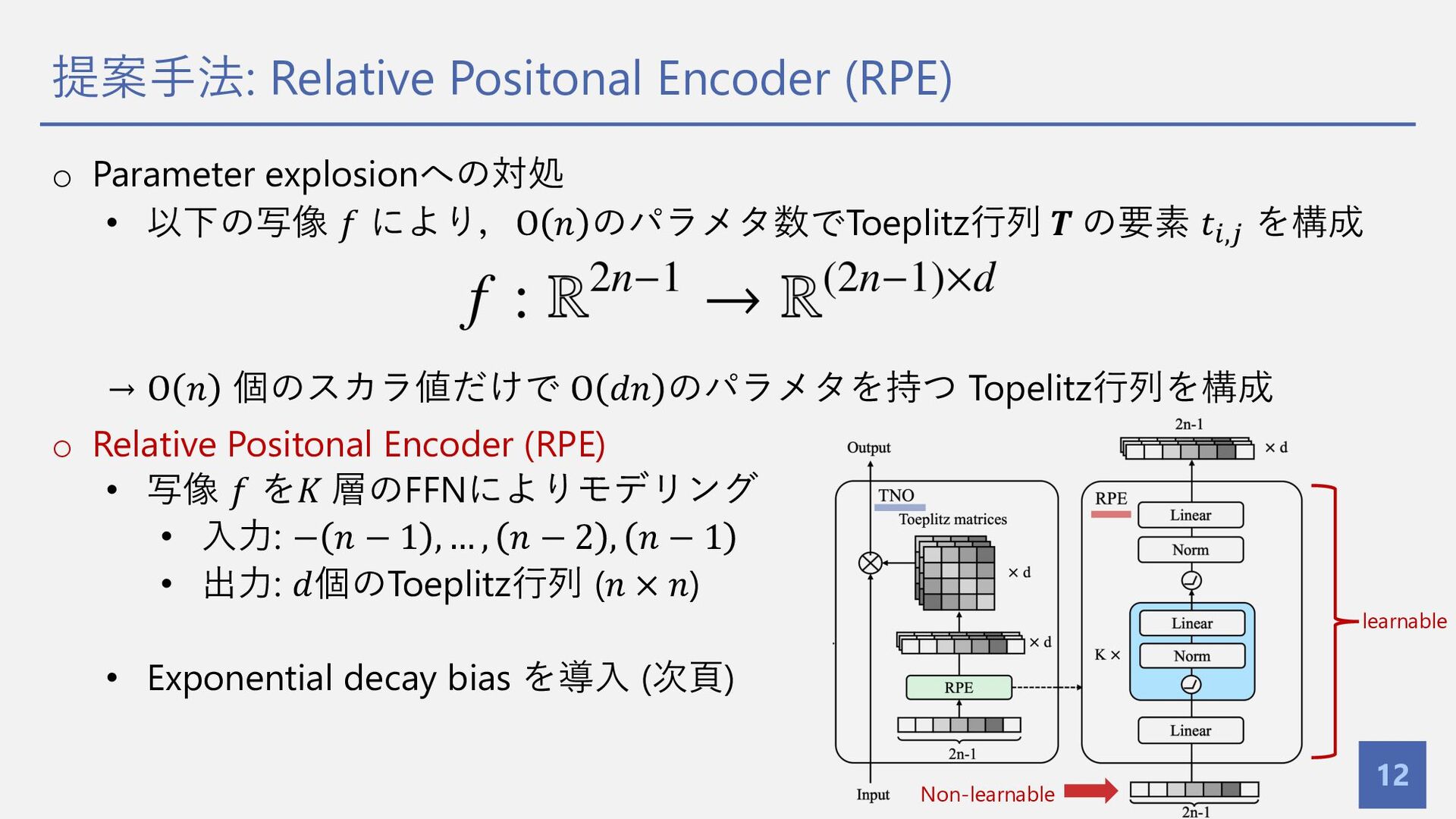
提案⼿法: Relative Positonal Encoder (RPE) 12 o Parameter explosionへの対処 •
以下の写像 𝑓 により,O 𝑛 のパラメタ数でToeplitz⾏列 𝑻 の要素 𝑡",$ を構成 → O 𝑛 個のスカラ値だけで O 𝑑𝑛 のパラメタを持つ Topelitz⾏列を構成 o Relative Positonal Encoder (RPE) • 写像 𝑓 を𝐾 層のFFNによりモデリング • ⼊⼒: − 𝑛 − 1 , … , 𝑛 − 2 , 𝑛 − 1 • 出⼒: 𝑑個のToeplitz⾏列 (𝑛 × 𝑛) • Exponential decay bias を導⼊ (次⾴) learnable Non-learnable
提案⼿法: Relative Positonal Encoder (RPE) 13 o Exponential decay bias
• 先⾏研究: ALiBi [Press+, ICLR22] • 𝑄𝐾%にペナルティを付与 → Transformerが⻑系列を扱えることを実証 • ペナルティ: トークン間の距離に応じて減衰するバイアス → ペナルティを加えた新たなToeplitz⾏列 𝑻&を定義
TNN: ⾼効率・⾼性能・並列処理可 14
実験設定: 多様なベースライン・ベンチマークで実験 15 o ベースライン (パラメタ数を揃えて学習) • Attention-based • Transformer-LS
[Zhu+, NeurIPS21] • Performer [Choromanski+, 2020] • cosFormer [Qin+, ICLR22] • FLASH [Hua+, PMLR22] • MLP-based • gMLP [Liu+, NeurIPS21] • Synthesizer [Tay+, PMLR21] • SSM-based • S4 [Gu+, ICLR22] • DSS [Gupta+, NeurIPS22] • GSS [Mehta+, ICLR23] o データセット / ベンチマーク • Language Modeling • Wikitext103 [Merity+, ICLR17] • Long-range dependencies • Long-Range Arena [Tay+, ICLR20] • Image Classification • ImageNet1K [Deng+, CVPR09] ↑ DeiT [Touvron+, ICML21] にTNT を組み込み実験
定量的結果: Autoregressive LMでcompetitiveな性能 16 o Autoregressive LM • データセット: Wikitext103
• {Attention, MLP, SSM}-basedな既存⼿法 よりも⾼い性能 • Transformer-LS [Zhu+, NeurIPS21]に のみ僅差で低い性能 Best Second Best ⾔語処理タスクにおいて competitiveな結果
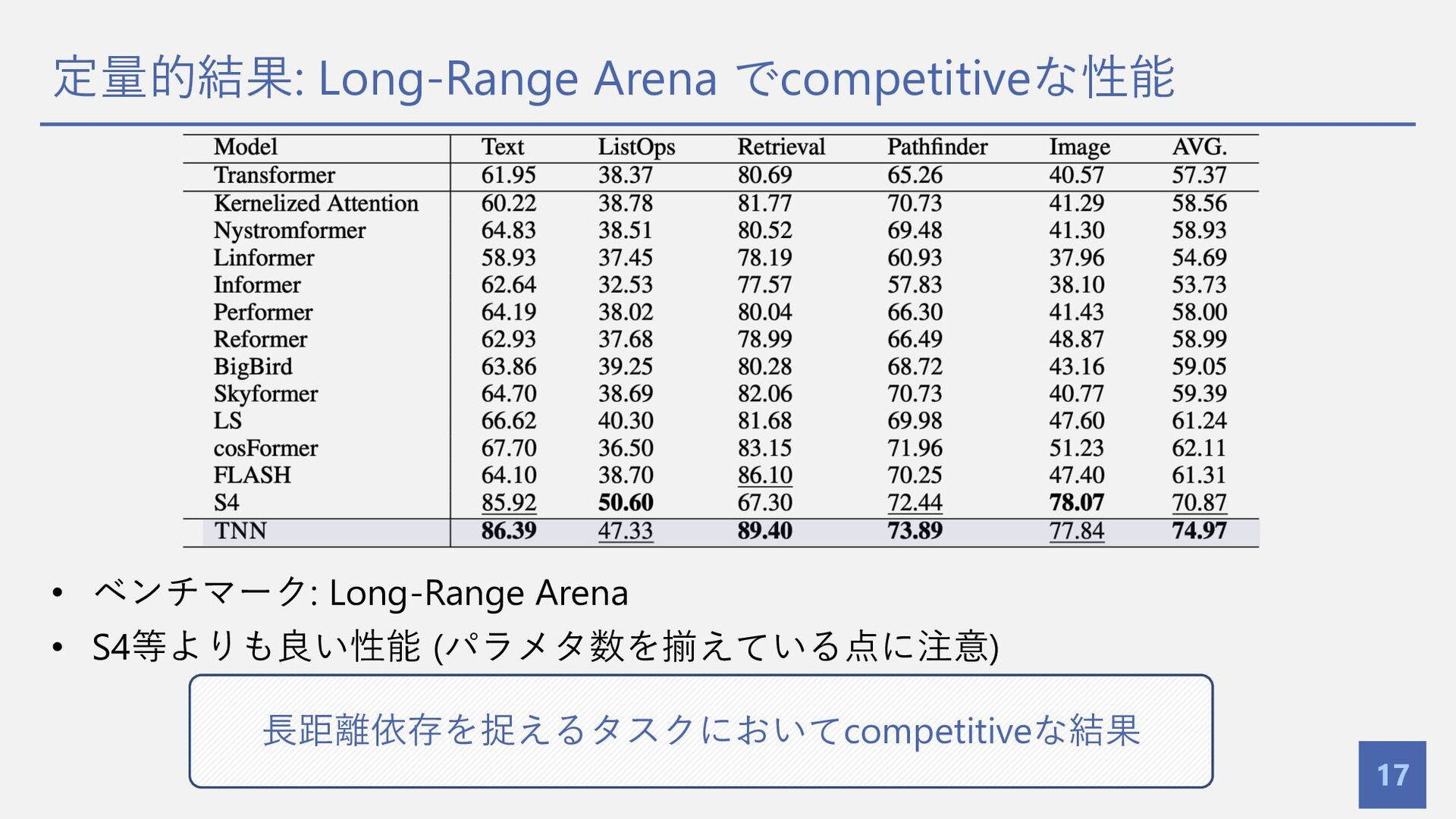
定量的結果: Long-Range Arena でcompetitiveな性能 17 • ベンチマーク: Long-Range Arena •
S4等よりも良い性能 (パラメタ数を揃えている点に注意) ⻑距離依存を捉えるタスクにおいてcompetitiveな結果
Ablation Study: RPEの有効性を確認 18 o RPEの⼊⼒は最良か? • NeRF [Mildenhall+, ECCV20]の指摘
• ⾼次元空間への写像が重要である と指摘 →PEにsin / cosが有効であると主張 → 実際は,ほとんど性能には寄与しないことを確認 ⇒ ⼊⼒ − 𝑛 − 1 , … , 𝑛 − 2 , 𝑛 − 1 が最良 o RPEは有効か? → RPEがないことで性能が極端に低下 RPEの有効性を確認
まとめ 20 ü 背景 • Transformerは①トークン間の関係を捉え,②位置情報を埋め込む • Transformerの問題点: 系列⻑に対してquadraticな計算量が掛かる ü
提案⼿法 • Toeplitz⾏列によりモデリングされたTNNを提案 • 時間計算量: O 𝑑𝑛log 𝑛 / 空間計算量: O 𝑑𝑛 を実現 ü 結果 • 様々なベンチマークにおいて⾼速かつSOTA⼿法に匹敵する性能
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Ablation Study: RPEの有効性を確認 18 o RPEの⼊⼒は最良か? • NeRF [Mildenhall+, ECCV20]の指摘](https://files.speakerdeck.com/presentations/0af857011a0b4641bf0a47a6161ac60a/slide_17.jpg){kind=link}
{kind=link}