Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
慶應義塾大学 機械学習基礎04 順伝播型ニューラルネット
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
October 08, 2021
Technology
1.9k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
慶應義塾大学 機械学習基礎04 順伝播型ニューラルネット
Semantic Machine Intelligence Lab., Keio Univ.
PRO
October 08, 2021
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club ] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
43
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
110
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
90
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
6.9k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
59
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
140
[Journal club] Improved Mean Flows: On the Challenges of Fastforward Generative Models
keio_smilab
PRO
0
200
Other Decks in Technology
See All in Technology
アラート調査向けAIエージェントの本番導入とその後/AI Agents for Alert Investigation: Production Deployment and After
taddy_919
1
280
飲食店もAIで。レジ締めやハンディシステムをつくってる話 / Using AI for restaurant management
vtryo
0
210
4人目のSREはAgent
tanimuyk
0
310
クラウドファンディング版StackChan 3体(4体)をインタラクティブな体験型作品にして展示もした話 / スタックチャンお誕生日会2026
you
PRO
0
250
從觀望到全公司落地:AI Agentic Coding 導入實戰 — 流程整合與安全治理
appleboy
0
240
AI Agentをシステムに組み込む前にゆるく向き合ってみる
hayama17
0
180
製造現場での生成AIの活用、およびエージェントAIの実装のあり方、AVEVAの取り組み
iotcomjpadmin
0
190
データレイクの「見えない問題」を可視化する
sansantech
PRO
1
250
秘密度ラベル初心者が第1歩でつまづかないための「設計・運用」ポイント
seafay
PRO
1
530
認証認可だけじゃない! ID管理の構成要素と ライフサイクルを意識しよう
ritou
1
360
ClaudeCodeの公式Memory Architecture
nagatsu
0
120
product engineering with qa
nealle
0
100
Featured
See All Featured
Accessibility Awareness
sabderemane
1
150
Site-Speed That Sticks
csswizardry
13
1.2k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
370
Into the Great Unknown - MozCon
thekraken
41
2.6k
Building an army of robots
kneath
306
46k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Designing Experiences People Love
moore
143
24k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
340
Marketing to machines
jonoalderson
1
5.5k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.5k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
We Have a Design System, Now What?
morganepeng
55
8.2k
Transcript
情報工学科 教授 杉浦孔明
[email protected]
慶應義塾大学理工学部 機械学習基礎 第4回 順伝播型ニューラルネット
本講義の到達目標と今回の授業の狙い - - 2 本講義の到達目標 ▪ DNNの基礎理論と実装の関係を理解する ▪ 種々のDNNをコーディングできる 今回の授業の狙い
▪ 順伝播型ニューラルネットの基礎を習得する ▪ 出席確認: K-LMS上の機械学習基礎のMainページへアクセス
順伝播型ニューラルネット - - 3
線形回帰 1入力1出力の場合 - - 4 ▪ 前回扱った線形モデル 図で書くと↓ 入力 (input)
出力 (output) 常に値が1である ノード
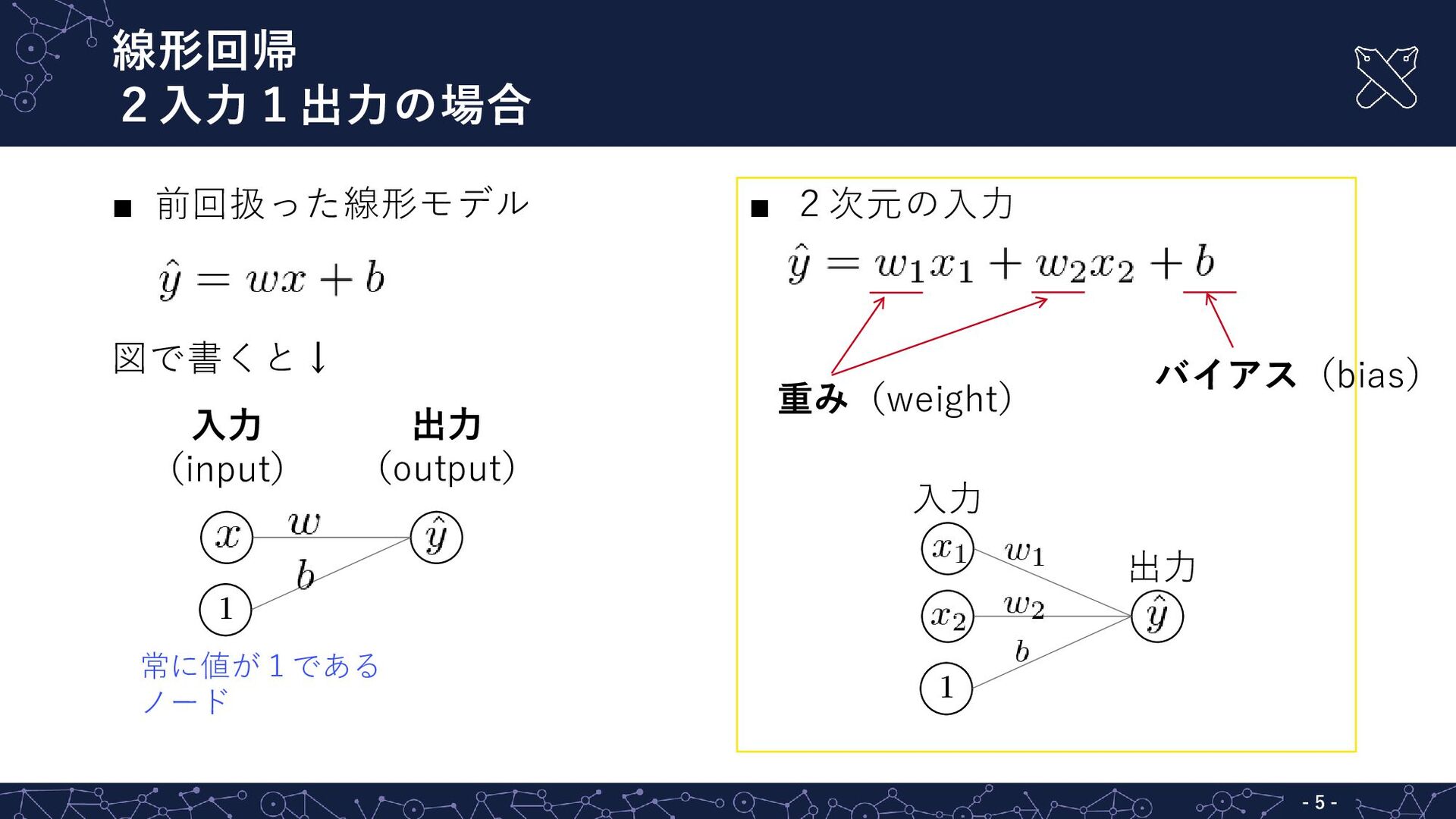
線形回帰 2入力1出力の場合 - - 5 ▪ 前回扱った線形モデル 図で書くと↓ ▪ 2次元の入力
入力 出力 重み(weight) バイアス(bias) 入力 (input) 出力 (output) 常に値が1である ノード
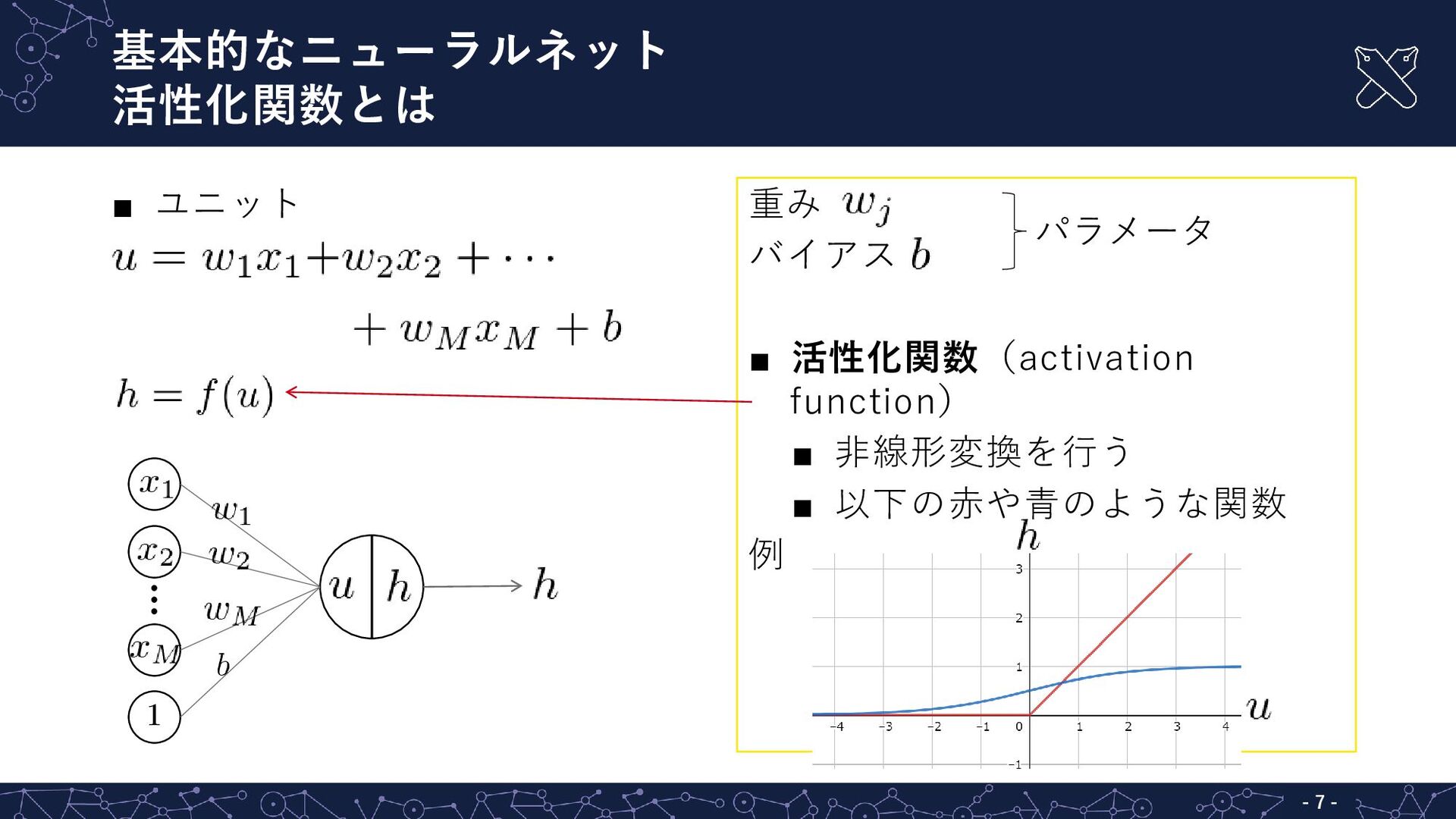
基本的なニューラルネット ユニットとは - - 6 ▪ ユニット ▪ 2次元の入力 重み(weight)
バイアス(bias) 入力 出力
基本的なニューラルネット 活性化関数とは - - 7 ▪ ユニット 重み バイアス ▪
活性化関数(activation function) ▪ 非線形変換を行う ▪ 以下の赤や青のような関数 例 パラメータ
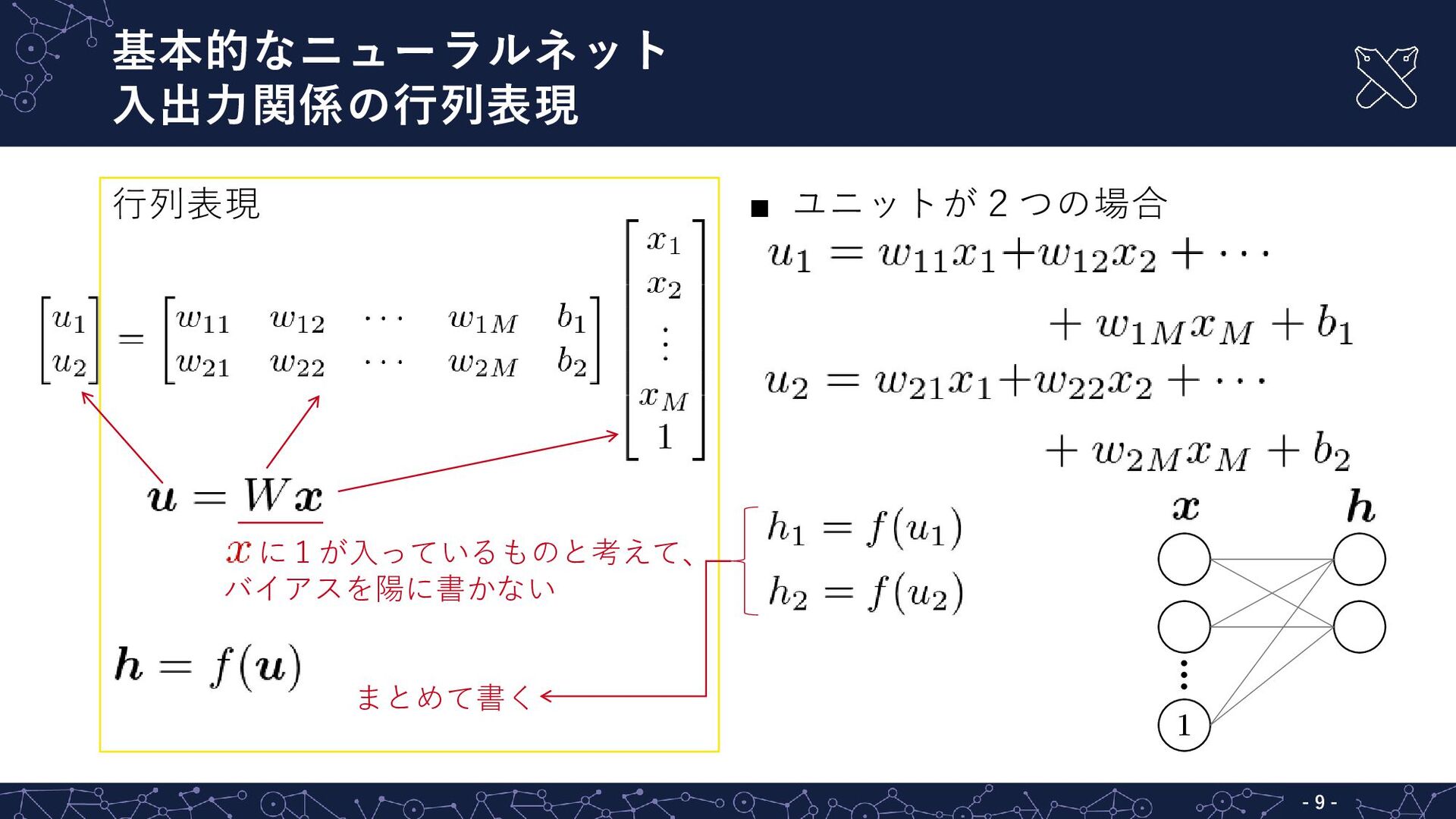
基本的なニューラルネット 複数のユニットを持つ場合 - - 8 ▪ ユニット ▪ ユニットが2つの場合
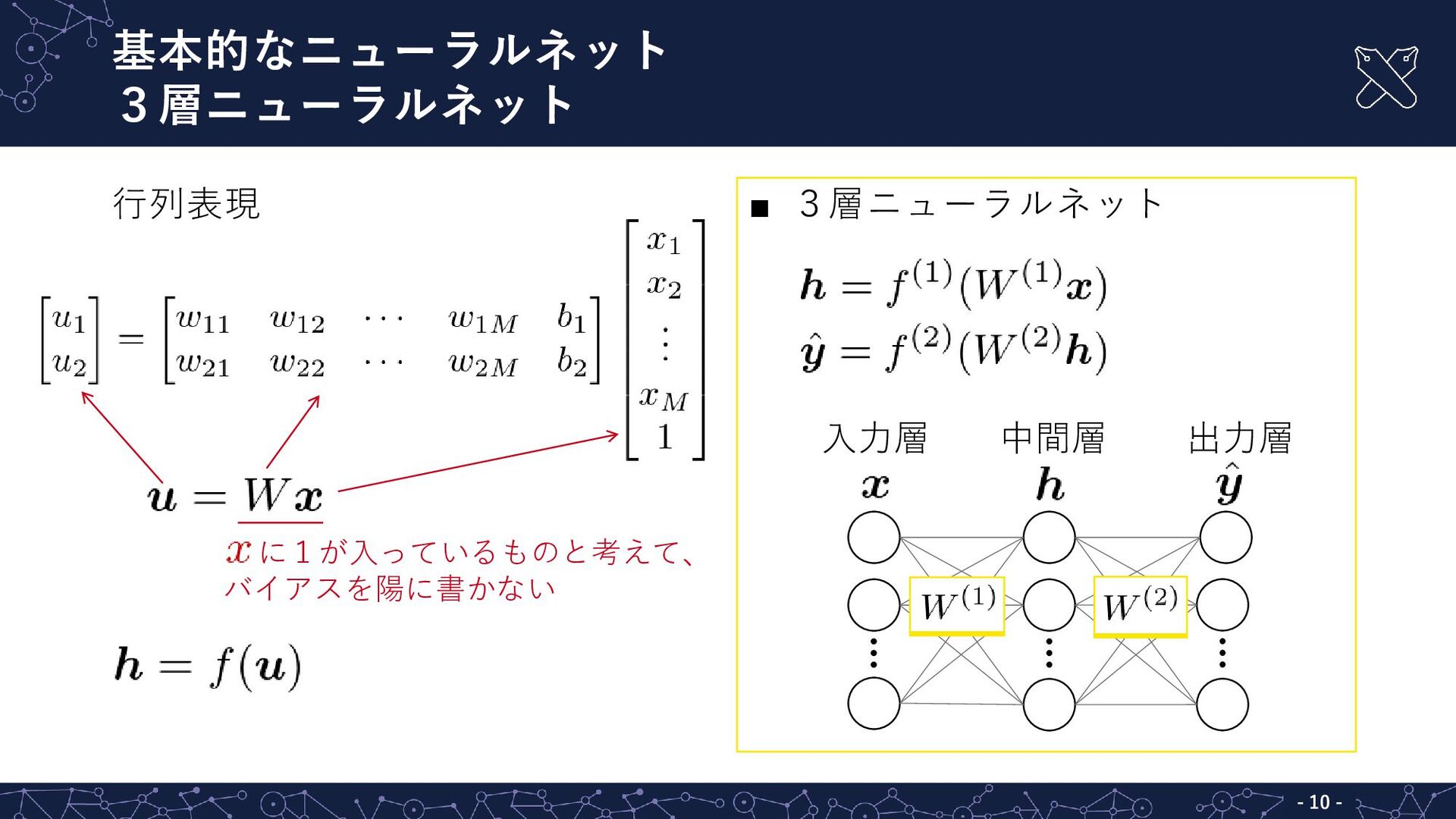
- 9 - ▪ ユニットが2つの場合 基本的なニューラルネット 入出力関係の行列表現 - - 9
行列表現 に1が入っているものと考えて、 バイアスを陽に書かない まとめて書く
基本的なニューラルネット 3層ニューラルネット - - 10 行列表現 ▪ 3層ニューラルネット 入力層 出力層
中間層 に1が入っているものと考えて、 バイアスを陽に書かない
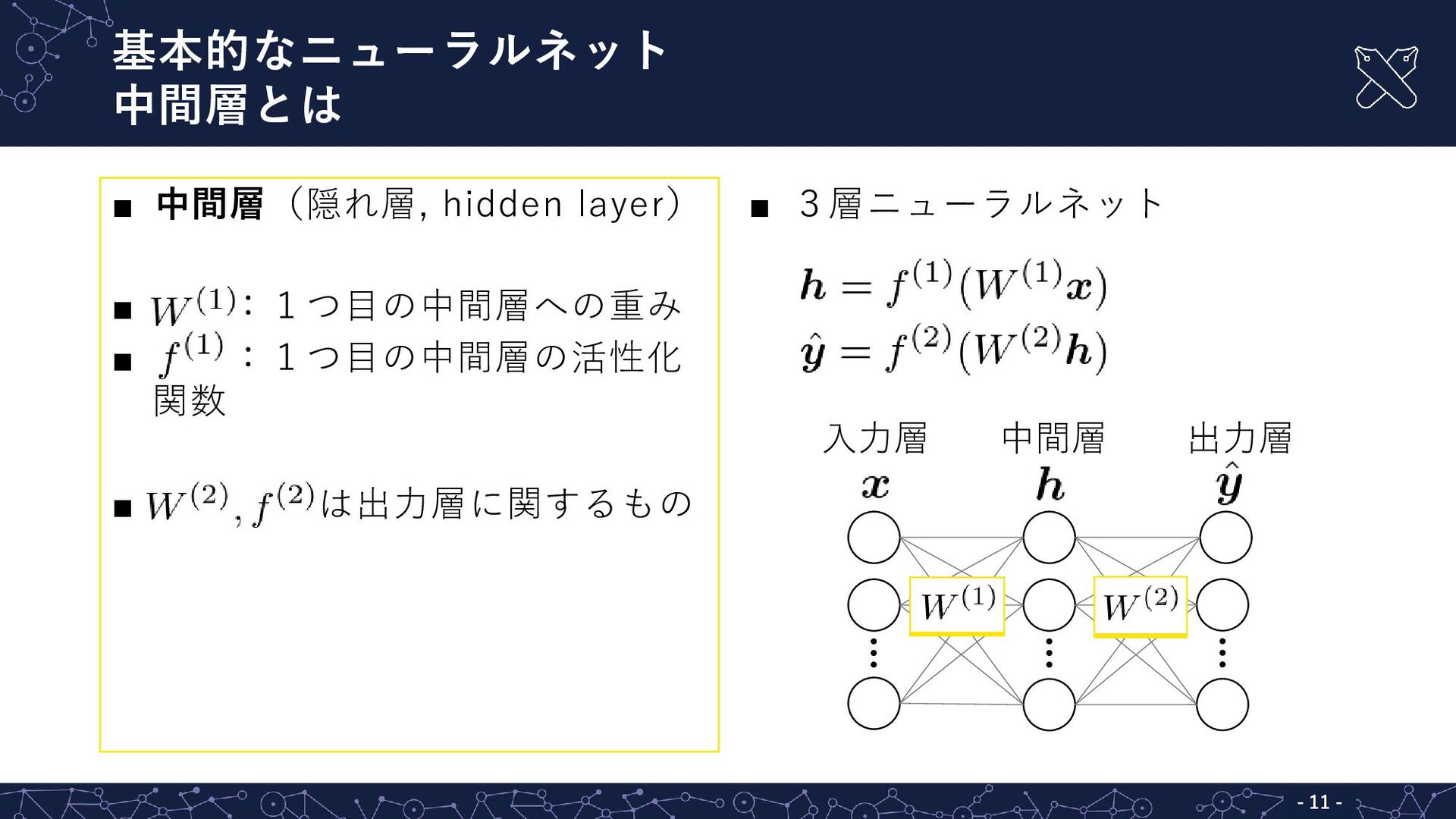
基本的なニューラルネット 中間層とは - - 11 ▪ 中間層(隠れ層, hidden layer) ▪
:1つ目の中間層への重み ▪ :1つ目の中間層の活性化 関数 ▪ は出力層に関するもの ▪ 3層ニューラルネット 入力層 出力層 中間層
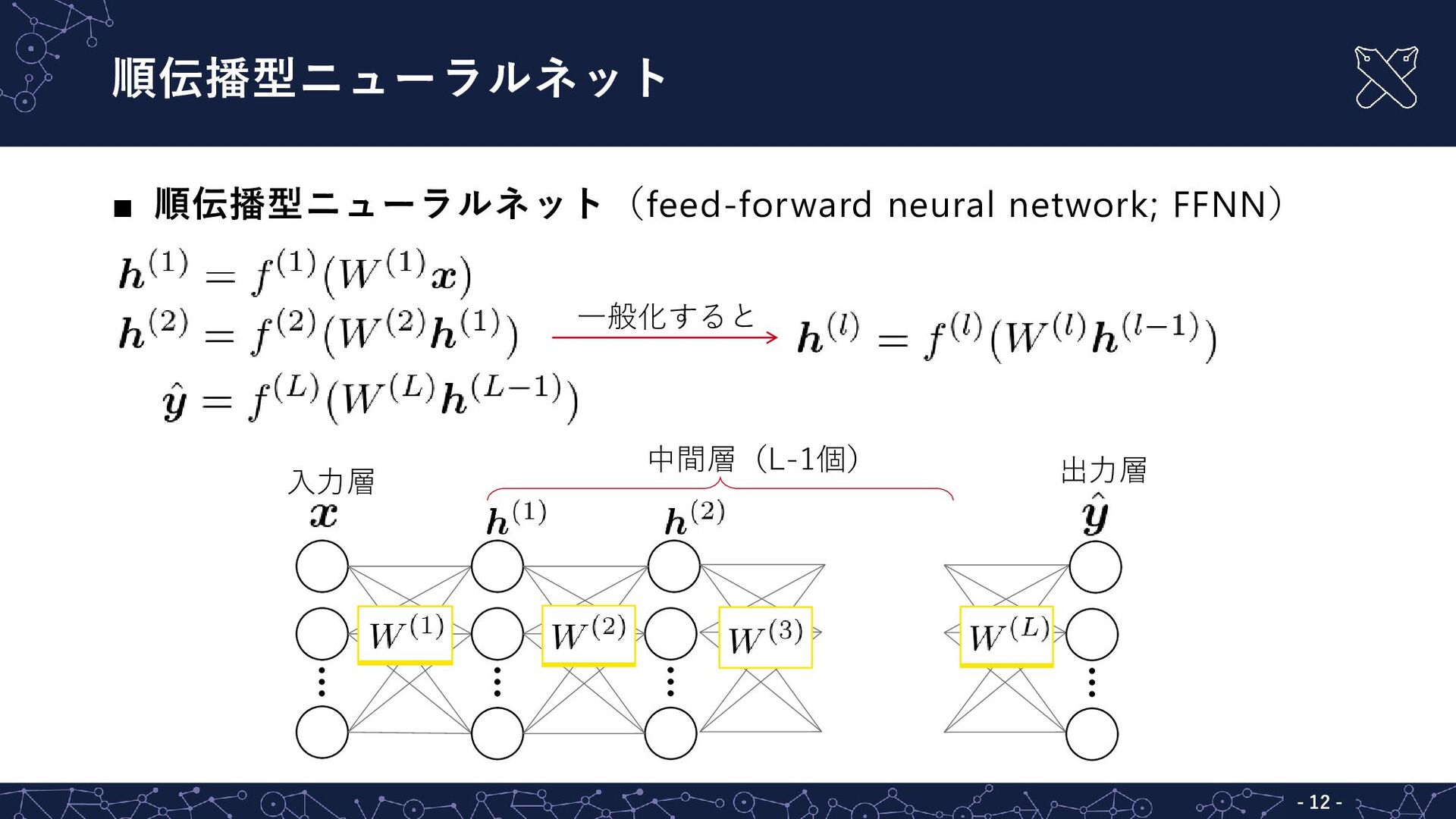
順伝播型ニューラルネット - - 12 ▪ 順伝播型ニューラルネット(feed-forward neural network; FFNN) 入力層
出力層 中間層(L-1個) 一般化すると
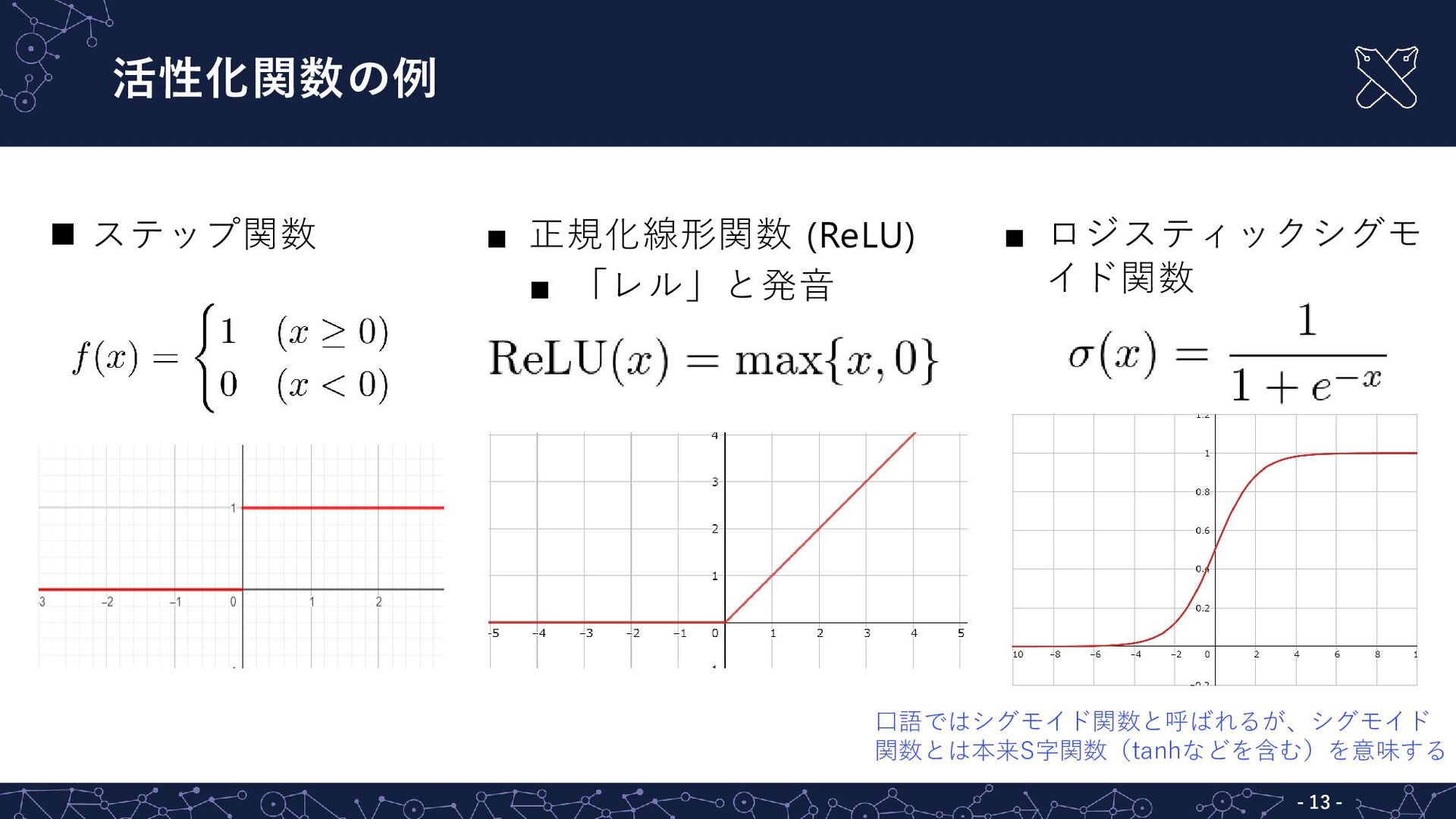
活性化関数の例 - - 13 ▪ 正規化線形関数 (ReLU) ▪ 「レル」と発音 ▪
ロジスティックシグモ イド関数 ステップ関数 口語ではシグモイド関数と呼ばれるが、シグモイド 関数とは本来S字関数(tanhなどを含む)を意味する
ニューラルネットによる回帰 例題:大気汚染物質の濃度を予測したい - - 14 ▪ 観測データを集める 1. 訓練集合を構築する 2.
損失関数を最小化するパラメー タを反復的に求める 重みやバイアスをまとめたもの ID 濃度 (今) 風速 (今) 濃度 (未来) 1 5 2.0 4 2 7 1.2 5 3 10 1.6 11 … … … 999 10 1.8 10 1000 9 2.6 10 新規 8 1.8 ???
ニューラルネットによる2値分類 例題 - - 15 ▪ 画像を「かぼちゃ」か 「かぼちゃ以外」に分けたい ▪ 正解ラベルは1または0
▪ を予測するのではなく、 を予測する 入力された画像に対し、 予測ラベルが1である 確率の予測値 ラベル:1 ラベル:0
ロジスティック回帰との関係 - - 16 ロジスティック回帰 (logistic regression): ロジット(logit)uをxの線形関数と してモデル化
ロジスティック回帰との関係 - - 17 ロジスティック回帰 (logistic regression): ロジット(logit)uをxの線形関数と してモデル化 用語
▪ pの例:画像xが「かぼちゃ」である 確率の予測値 ▪ オッズ ▪ pのロジット 対数オッズとも呼ばれる
ロジスティック回帰との関係 - - 18 ロジスティックシグモイド関数に よるuの変換を考える 用語 ▪ pの例:画像xが「かぼちゃ」である 確率の予測値
▪ オッズ ▪ pのロジット xが「かぼちゃ」である確率を予測する 簡単なニューラルネットと等価
多クラス分類 例題:MNIST - - 19 ▪ 手書き数字のデータセット ▪ 深層学習分野でMNISTを 知らない人はいないはず
▪ 28×28ピクセル画像 ▪ 訓練集合:6万枚 テスト集合:1万枚 ▪ 1-of-K表現 ▪ 特定の次元のみ1であり、残 りの次元は0 ▪ テキスト処理において単語を 表現する方法でもある ▪ Zero: (1, 0, 0, 0, 0, 0, 0, 0, 0, 0) ▪ One: (0, 1, 0, 0, 0, 0, 0, 0, 0, 0) ▪ Two: (0, 0, 1, 0, 0, 0, 0, 0, 0, 0)
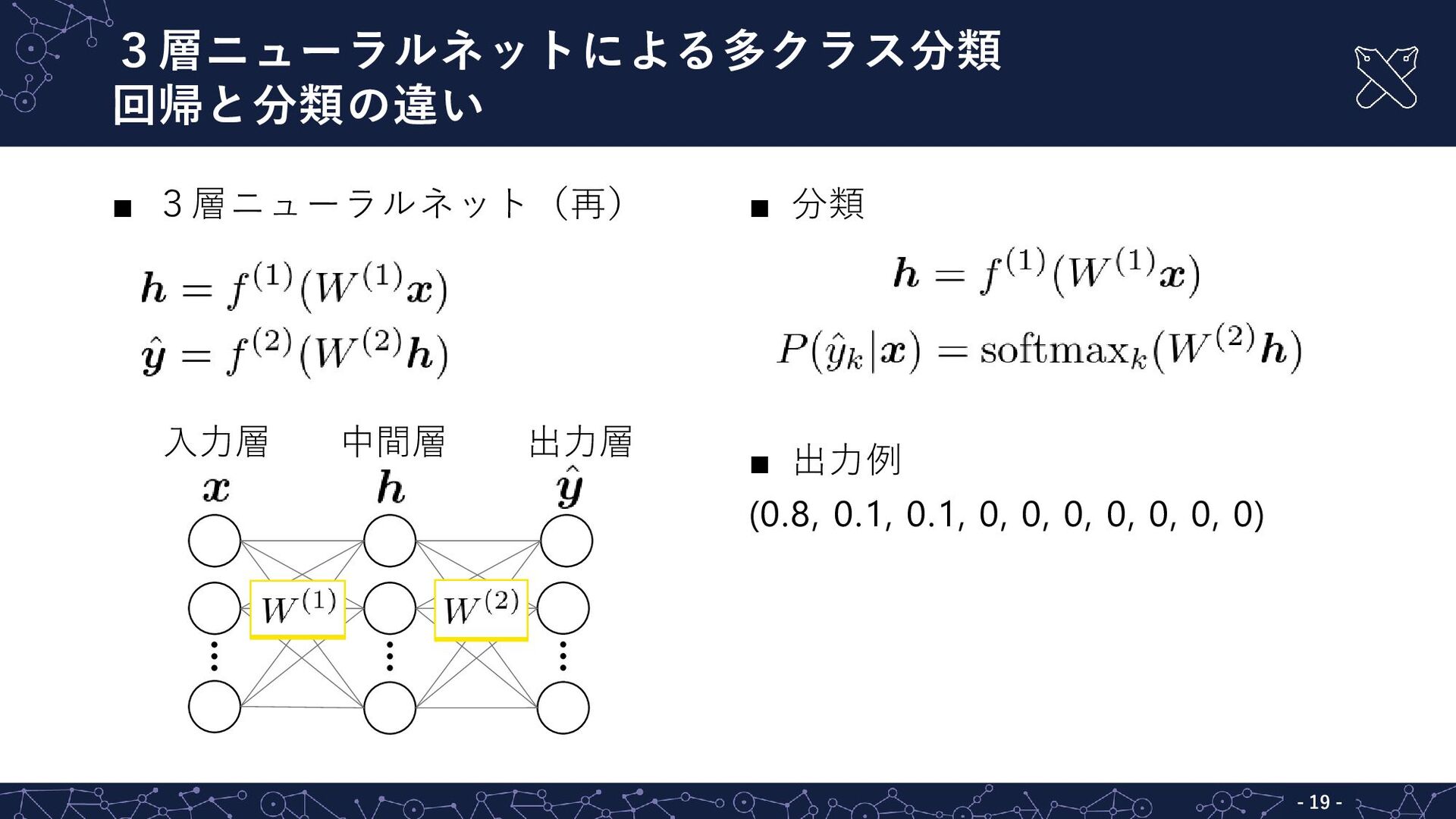
3層ニューラルネットによる多クラス分類 回帰と分類の違い - - 20 ▪ 3層ニューラルネット(再) ▪ 分類 ▪
出力例 (0.8, 0.1, 0.1, 0, 0, 0, 0, 0, 0, 0) 入力層 出力層 中間層
3層ニューラルネットによる多クラス分類 ソフトマックス関数とは - - 21 ▪ ソフトマックス関数(softmax function) ▪ の例
▪ 分類 指数関数で変換したのち、 規格化している
3層ニューラルネットによる多クラス分類 交差エントロピー誤差関数とは - - 22 ▪ 情報理論における離散分布 間の交差エントロピー ▪ 交差エントロピー誤差関数
(cross-entropy error function) 正解ラベル は固定値なので 確率で表す必要がない (普通の)エントロピー サンプル番号 のラベルの 次元目の値 (クラスkであれば1であり、そうでなければ0)
3層ニューラルネットによる多クラス分類 2値分類の場合の交差エントロピー誤差関数 - - 23 ▪ クラス ▪ 2クラス( =2)
サンプル番号 のラベル(1または0) 高校数学で言うと 余事象の考え方
理解度確認 - - 24
理解度確認 以下について周りと相談して1分以内に答えよ - - 25 1. 訓練集合とテスト集合の違いは何か? 2. 訓練集合と訓練サンプルの違いは何か? 3.
ミニバッチ確率的勾配降下法の英語名は何か? 4. 損失関数の例を挙げよ。 ※LLMに聞いても良いが、ハルシネーションの場合に「LLMが誤った (のであって自分は悪くない)」という回答は不適切 =検証が必要
交差エントロピー誤差関数 と最尤推定 - - 26
ベルヌーイ分布(Bernoulli distribution) - - 27 ひしゃげたコインの分布 ▪ ▪ 2値をとる実現値 を生成するための確率分布
▪ 1個のパラメータ(母数) によって分布の 性質が決まる 例: のとき ▪ 期待値: ▪ 分散: ▪ 同時確率 べき乗で場合分けを 表現するトリック が1の確率 が0の確率
最尤推定 - - 28 ▪ 観測値 の同時確率 を最大化したい ▪ サンプルは母集団から独立同分布
で抽出されたものとする (i.i.d.; independent and identically distributed)
尤度とは - - 29 ▪ 観測値 の同時確率 を最大化したい ▪ サンプルは母集団から独立同分布
で抽出されたものとする (i.i.d.; independent and identically distributed) ▪ 「 が既知で、 が未知」 から 「 が既知で、 が未知」に 見方を変える ▪ 尤度(likelihood, ゆうど) ▪ データが与えられたうえでの モデルの尤もらしさ ▪ 規格化(=足して1)されて いないので確率ではない
交差エントロピー誤差の最小化は尤度最大化を意味する - - 30 ▪ 2値分類の場合の尤度関数 ▪ 尤度最大化 =対数尤度最大化 =負の対数尤度最小化
損失関数として最小化 ▪ 「 が既知で、 が未知」 から 「 が既知で、 が未知」に 見方を変える ▪ 尤度(likelihood, ゆうど): ▪ データが与えられたうえでの モデルの尤もらしさ ▪ 規格化(=足して1)されて いないので確率ではない
交差エントロピー誤差の最小化は尤度最大化を意味する - - 31 ▪ 2値分類の場合の尤度関数 ▪ 尤度最大化 =対数尤度最大化 =負の対数尤度最小化
損失関数として最小化 ↑交差エントロピー誤差 確率のように小さい数を何度も 掛け合わせるより、対数をとって 足し算にしたほうが楽
本講義全体の参考図書 - - 32 ▪ ★機械学習スタートアップシリーズ これならわかる深層学習入門 瀧雅人著 講談社 ▪
★Dive into Deep Learning (https://d2l.ai/) ▪ 深層学習 改訂第2版 (機械学習プロフェッショナルシリーズ) 岡谷貴之著 講談社 ▪ ディープラーニングを支える技術 岡野原大輔著 技術評論社 ▪ 画像認識 (機械学習プロフェッショナルシリーズ) 原田達也著 講談社 ▪ 深層学習による自然言語処理 (機械学習プロフェッショナルシリーズ) 坪井祐太、海野裕也、 鈴木潤 著、講談社 ▪ IT Text 自然言語処理の基礎 岡﨑直観、荒瀬由紀、鈴木潤、鶴岡慶雅、宮尾祐介 著、オー ム社 ▪ 東京大学工学教程 情報工学 機械学習 中川 裕志著、東京大学工学教程編纂委員会編 丸善 出版 ▪ パターン認識と機械学習 上・下 C.M. ビショップ著 丸善出版 ▪ Bishop, Christopher M. and Bishop, Hugh, "Deep Learning: Foundations and Concepts", Springer, ISBN-13:978-3031454677
小レポート①の準備 - - 33
小レポート①の準備 - - 34 ▪ Kaggleとは ▪ 機械学習コンペを開催するプラットフォーム ▪ 次回講義までの宿題
▪ 「Kaggleへのユーザ登録」を行ってください ▪ 次回講義で行うこと ▪ 小レポート①の内容・締切の説明
ユーザ登録(1/4) - - 35 ① 以下へアクセス https://www.kaggle.com/ ② Googleアカウント等でログイン
[email protected]
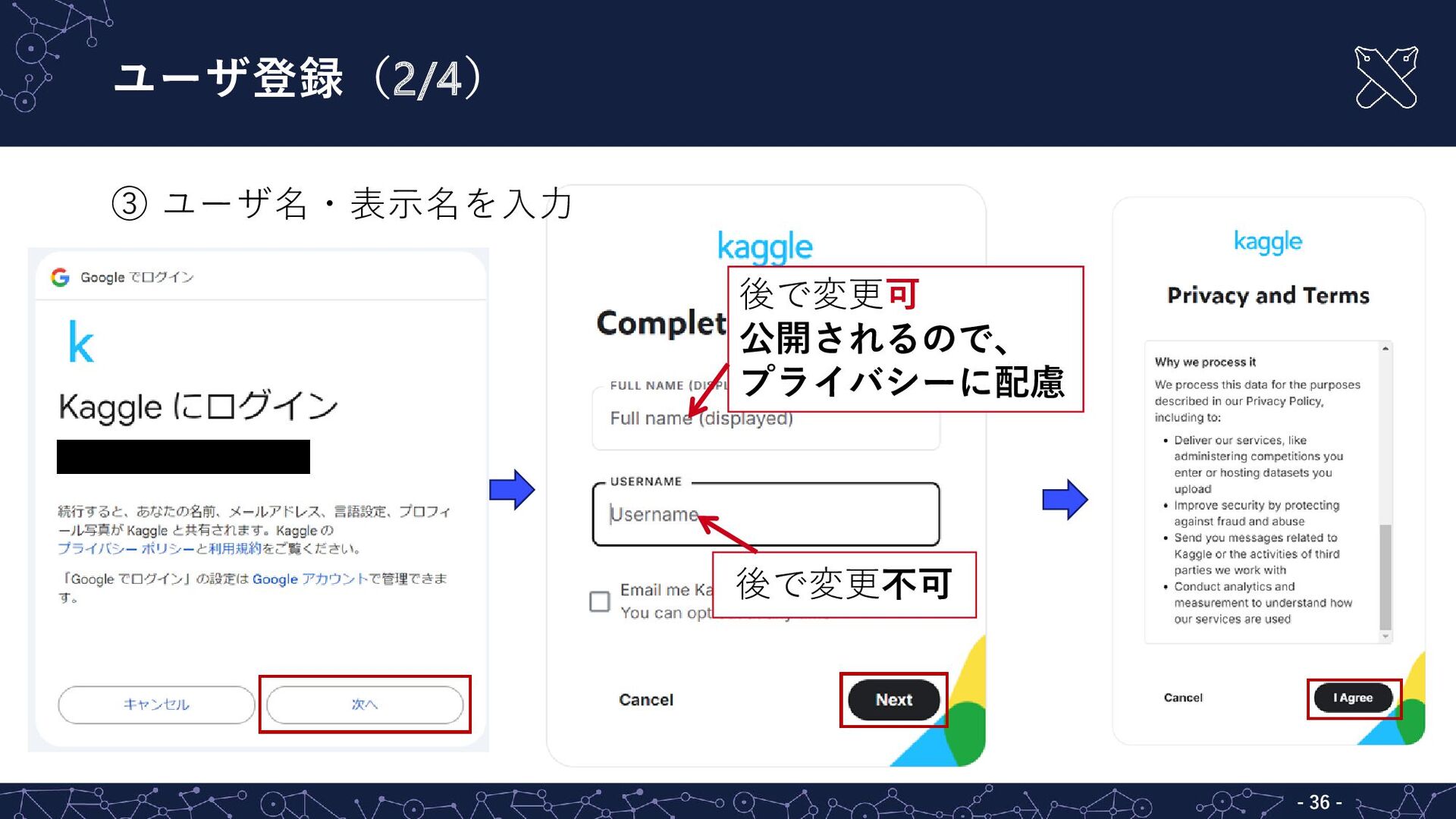
ユーザ登録(2/4) - - 36 後で変更不可 後で変更可 公開されるので、 プライバシーに配慮 ③ ユーザ名・表示名を入力
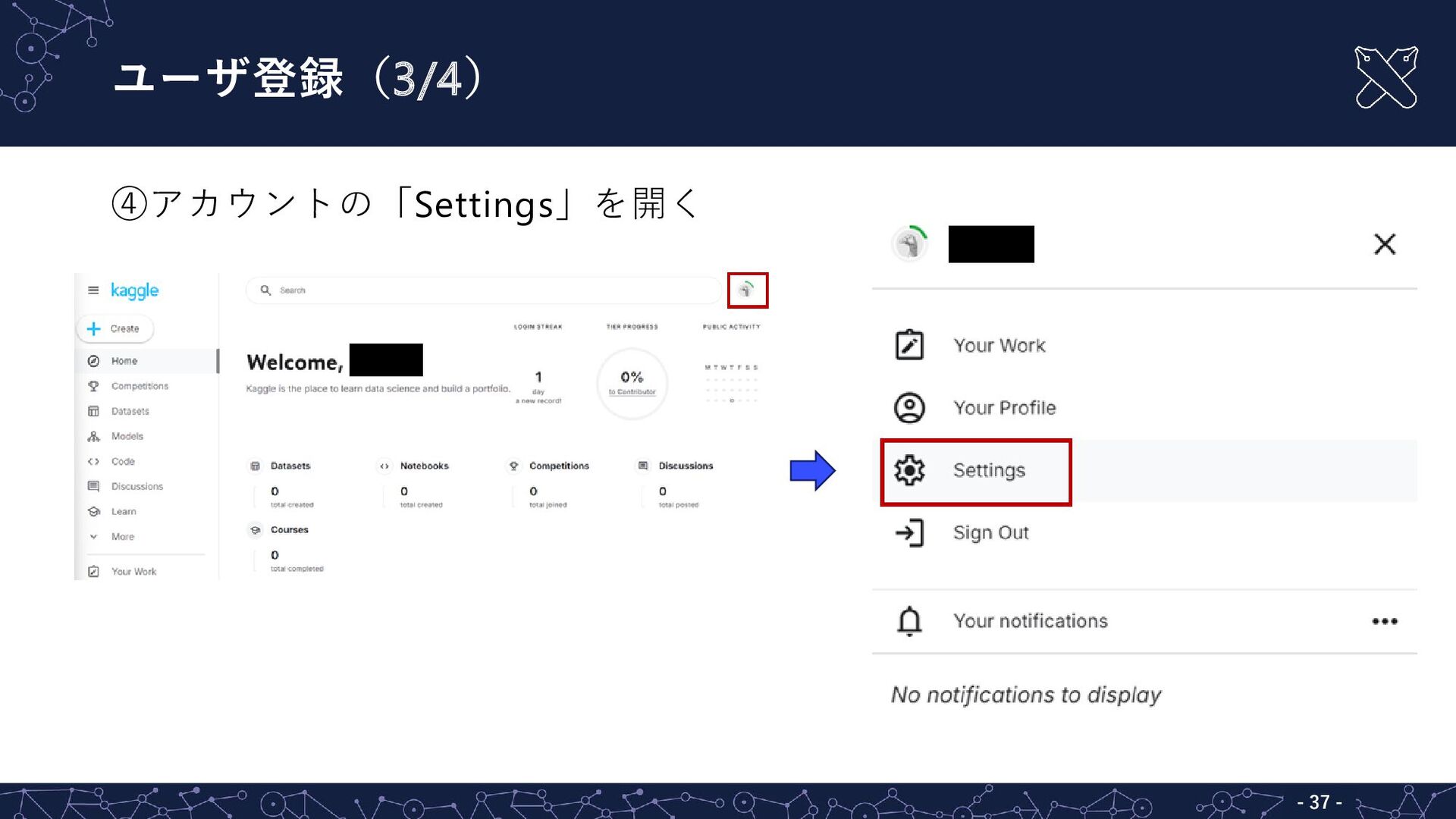
ユーザ登録(3/4) - - 37 ④アカウントの「Settings」を開く
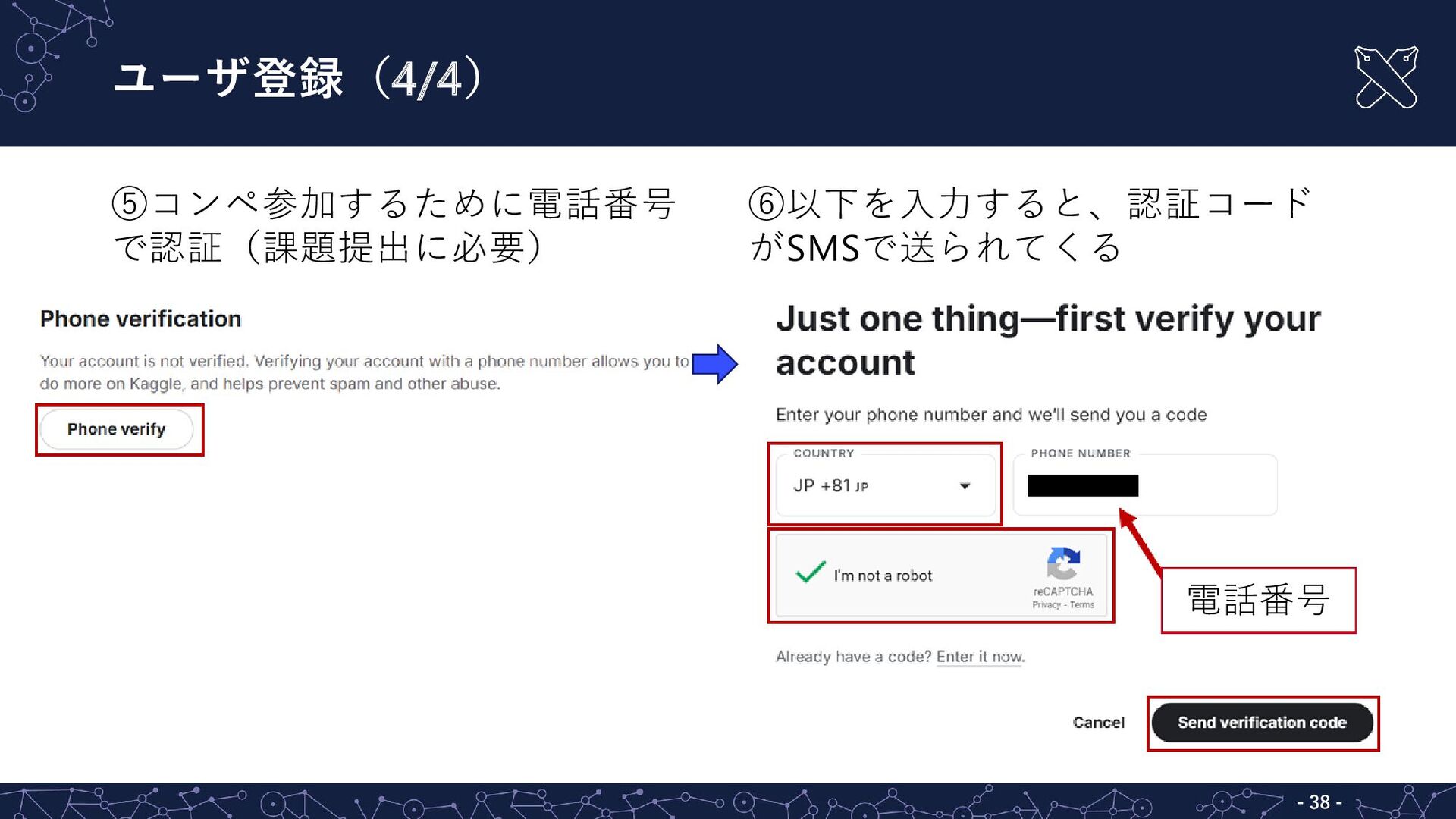
ユーザ登録(4/4) - - 38 ⑤コンペ参加するために電話番号 で認証(課題提出に必要) ⑥以下を入力すると、認証コード がSMSで送られてくる 電話番号
実習 - - 39
実習 MNISTへの3層ニューラルネットの適用 - - 40 ▪ ニューラルネットの出力:10次元 ▪ 10次元の出力のうち、最大のものを予測ラベルとする ▪
損失関数:交差エントロピー誤差関数 ▪ ミニバッチSGDで反復的に損失を最小化 ▪ 理工学基礎実験との違いは、コーディングが多いJ科向けか否か ▪ 理工学基礎実験: 視覚的にわかりやすいが自由度は低いコード ▪ 機械学習基礎: 各自が改変しやすいように不要な関数を削除
実習 - - 41 実習の目的 ▪ コーディングと基礎理論の関係を学ぶ 実習課題の場所 ▪ K-LMSから辿る
実習に関する質問 ▪ ChatGPTに説明させる ▪ 教科書で調べる・検索・周囲と相談(私語禁止ではありません) ▪ 上記で解消しなければ挙手
![情報工学科 教授 杉浦孔明 [email protected] 慶應義塾大学理工学部 機械学習基礎 第4回 順伝播型ニューラルネット](https://files.speakerdeck.com/presentations/a603b1b3e17b4b55a4ef866d44815452/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ユーザ登録(1/4) - - 35 ① 以下へアクセス https://www.kaggle.com/ ② Googleアカウント等でログイン [email protected]](https://files.speakerdeck.com/presentations/a603b1b3e17b4b55a4ef866d44815452/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}