Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[RSJ22] Collision Prediction and Visual Explana...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 06, 2022
Technology
1.9k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[RSJ22] Collision Prediction and Visual Explanation Generation Using Structural Knowledge in Object Placement Tasks
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 06, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
88
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
88
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
99
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
170
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
61
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.5k
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
340
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
530
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
160
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
340
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
190
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
390
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
520
人とエージェントが高め合う協業設計
kintotechdev
0
960
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
200
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
980
コンテナ・K8s研修【MIXI 26新卒技術研修】#2
mixi_engineers
PRO
1
200
Featured
See All Featured
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
The Language of Interfaces
destraynor
162
27k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.6k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Agile that works and the tools we love
rasmusluckow
331
22k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Transcript
物体配置タスクにおける構造的知識を用いた 衝突予測および視覚的説明生成 松尾榛夏¹ 畑中駿平¹ 平川翼² 山下隆義² 藤吉弘亘² 杉浦孔明¹ ¹慶應義塾大学 ²中部大学
1
背景:生活支援ロボットの物体配置には高い安全性が求められる • 介助従事者不足の解決策の一つとして生活支援ロボットが有望視 • 物体配置は生活支援ロボットの基本的動作の一つ – 高い安全性が必要 2
対象タスク:物体間の衝突に関する衝突予測タスク • 軽微な接触の連鎖による物体の転倒や落下の可能性 – 連鎖の予測は困難 • 物体間の衝突に関する衝突予測タスク – 衝突確率の予測
3 軽微な接触 (アームと物体) 軽微な接触 (物体と物体) 物体の落下
既存研究:物体配置分野はこれまでにも広く研究されている 4 代表的研究 概要 [Jiang+, IJRR12] 物体間の幾何学的関係や配置における人間の意向など 複数の性質を扱うグラフィカルなモデル [Gualtieri+, ICRA18]
深層強化学習に基づく物体配置動作計画の研究 PonNet [Magassouba+, AR21] Transformer PonNet [植田+, JSAI21] Attention Branch Network ( ABN ) [Fukui+, CVPR19] を 用いて物体同士の衝突確率を予測 [Jiang+, IJRR12] [Gualtieri+, ICRA18] Transformer PonNet
• Transformer PonNet [植田+, JSAI21] – 入力:対象物体と配置領域のRGBD画像 – 出力:衝突確率 •
構造的知識を用いていない – 構造的知識:障害物の位置情報および画像特徴量同士の関係 • 配置方策を行っていない ⇒ 構造的知識も考慮した手法の提案 & 配置方策を導入 既存手法の問題点:構造的知識と配置方策を扱っていない 5 RGB depth 配置領域 対象物体 RGB depth
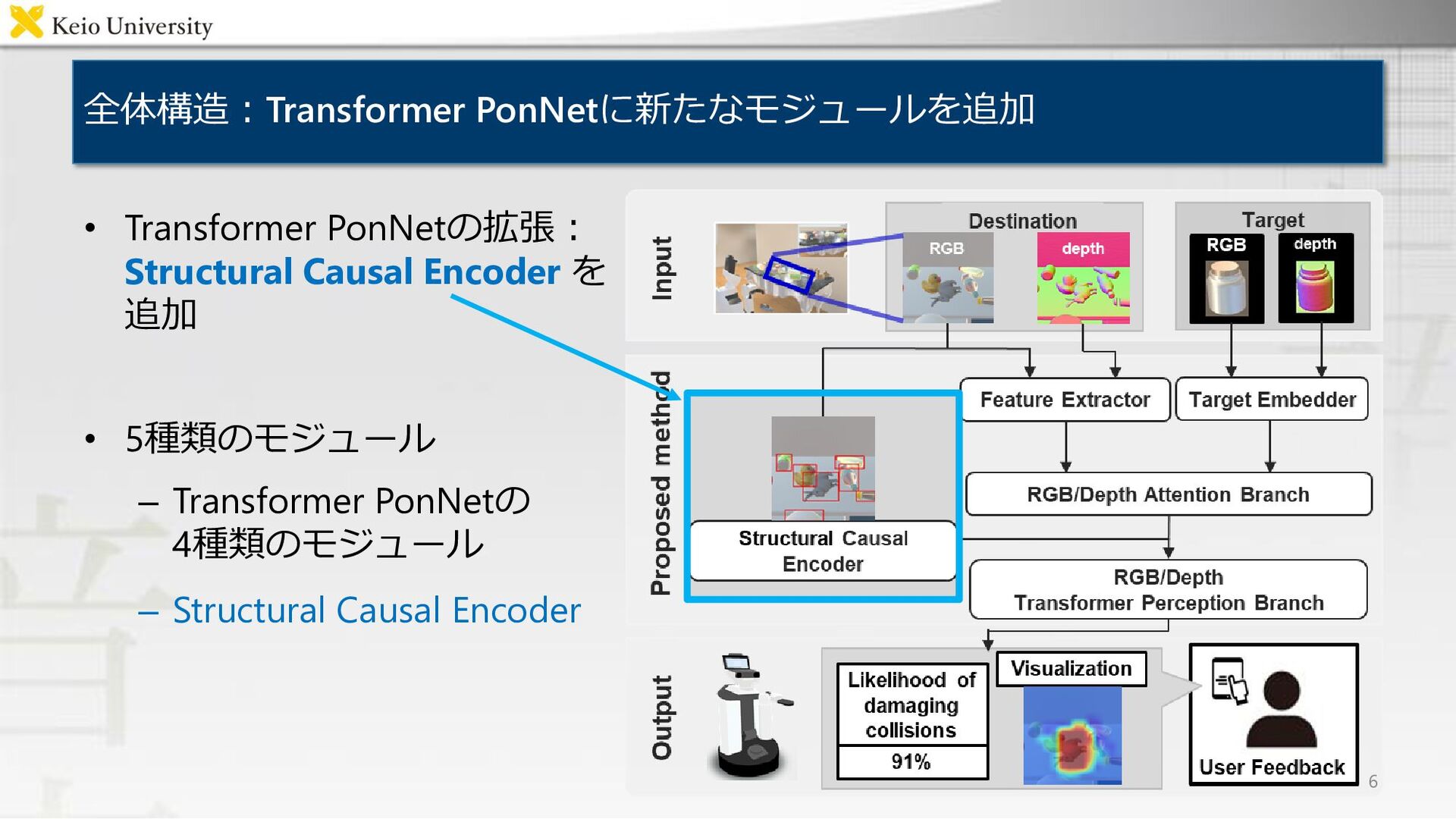
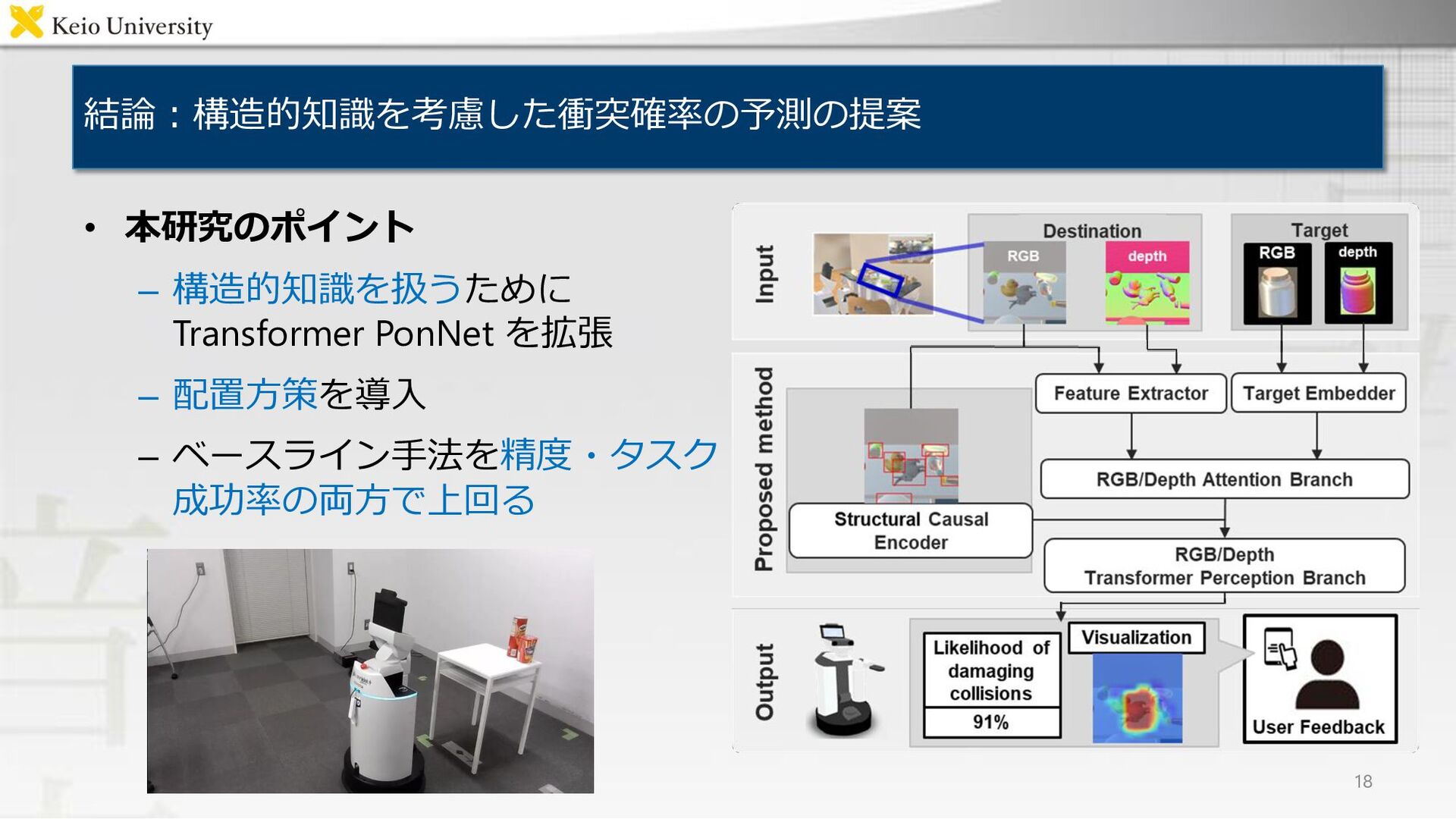
全体構造:Transformer PonNetに新たなモジュールを追加 • Transformer PonNetの拡張: Structural Causal Encoder を 追加
• 5種類のモジュール – Transformer PonNetの 4種類のモジュール – Structural Causal Encoder 6
• Attention Branch Network (ABN) [Fukui+, CVPR19] attention mapから特徴量に対して重み付けを行う 構造
(1/4):衝突に関連する部分に注目して重み付け 7 7 ABN [Fukui+, CVPR19] Attention Map 𝒘rgb = (1 + 𝒂rgb )⨀𝒉rgb <dest> 𝒘depth = (1 + 𝒂depth )⨀𝒉depth <dest>
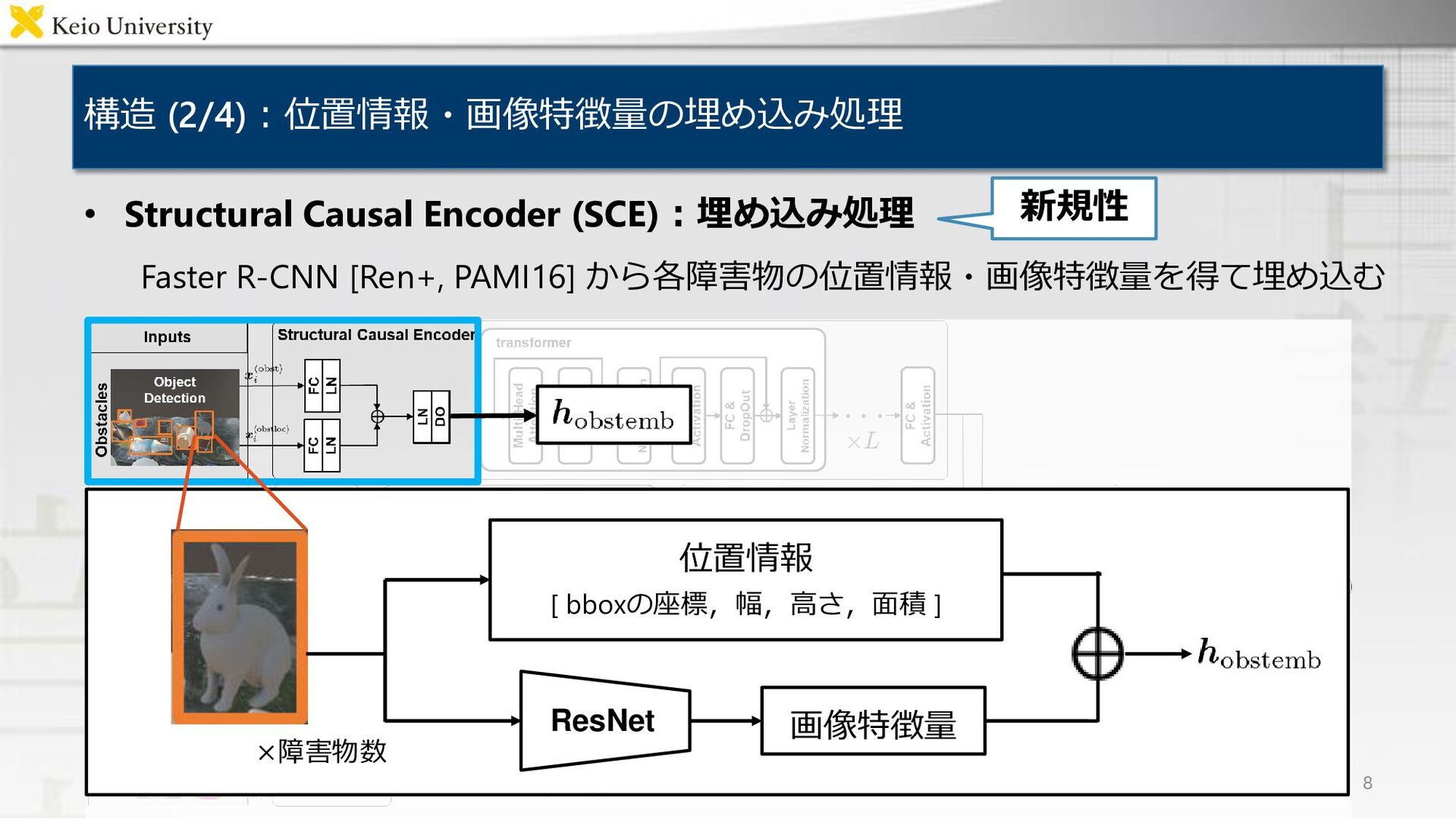
構造 (2/4):位置情報・画像特徴量の埋め込み処理 • Structural Causal Encoder (SCE):埋め込み処理 Faster R-CNN [Ren+,
PAMI16] から各障害物の位置情報・画像特徴量を得て埋め込む 8 画像特徴量 位置情報 ResNet ×障害物数 [ bboxの座標,幅,高さ,面積 ] 新規性
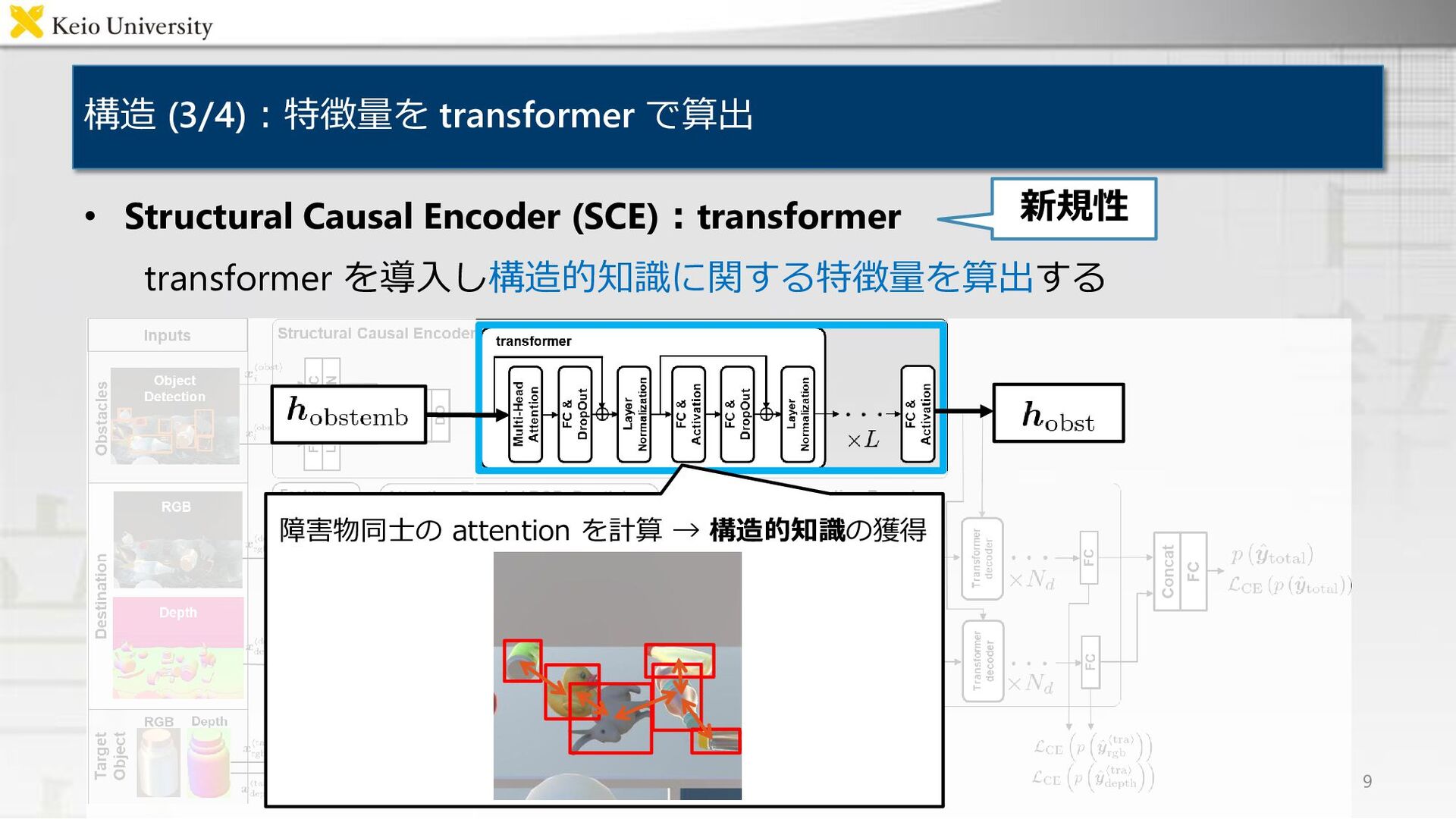
構造 (3/4):特徴量を transformer で算出 • Structural Causal Encoder (SCE):transformer transformer
を導入し構造的知識に関する特徴量を算出する 9 障害物同士の attention を計算 → 構造的知識の獲得 新規性
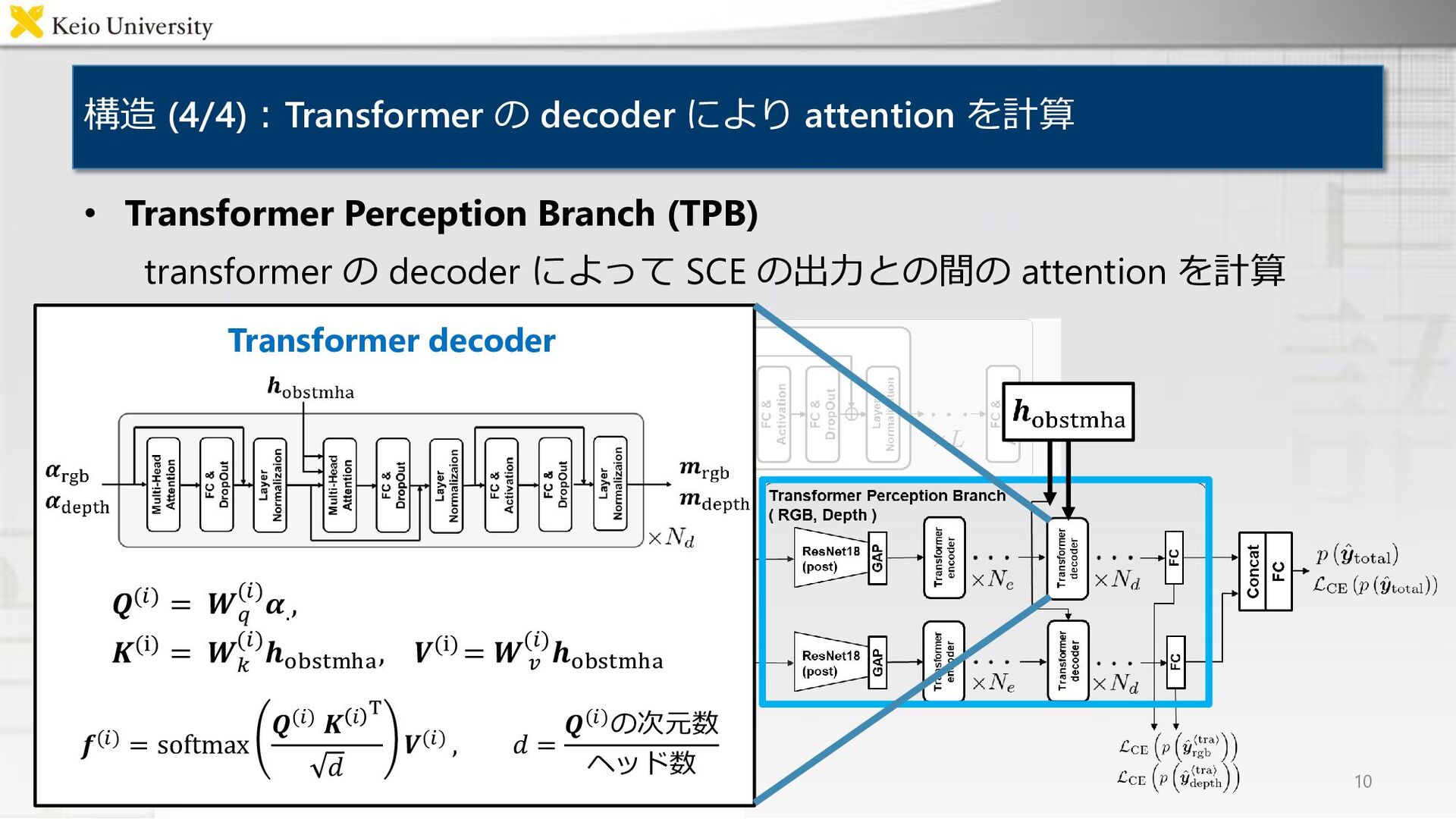
構造 (4/4):Transformer の decoder により attention を計算 • Transformer Perception
Branch (TPB) transformer の decoder によって SCE の出力との間の attention を計算 10 𝑸(𝑖) = 𝑾𝑞 (𝑖)𝜶. , 𝑲(i) = 𝑾 𝑘 (𝑖)𝒉obstmha , 𝑽(i)= 𝑾 𝑣 (𝑖)𝒉obstmha 𝒇(𝑖) = softmax 𝑸(𝑖) 𝑲 𝑖 T 𝑑 𝑽(𝑖) , 𝑑 = 𝑸(𝑖)の次元数 ヘッド数 Transformer decoder
配置方策:安全な位置に配置 • データセットを作成する際に配置方策を導入 – 既存手法より安全な位置に配置 – 実用時の条件に近いデータセット • Transformer PonNet
[植田+, JSAI21] を使用 • 衝突すると予測した場合 – Attentionが低い場所に配置 • 衝突しないと予測した場合 – Attentionが高い場所に配置 11
実験:Simulation データセット • BILA-S データセット – 配置方策を導入 – 約 12,000
サンプル – シミュレータによって自動的にラベル付け – Faster R-CNN [Ren+, PAMI16] による物体検出の学習 • COCOデータセットで事前学習済み Faster R-CNN を使用 • BILA-S データセットで finetuning 12
実験:実機環境によるデータセット • トヨタの生活支援ロボット Human Support Robot (HSR) を使用 • BILA-Real
データセット – 中心領域のみに配置 – 約 2,000 サンプル 13 x100
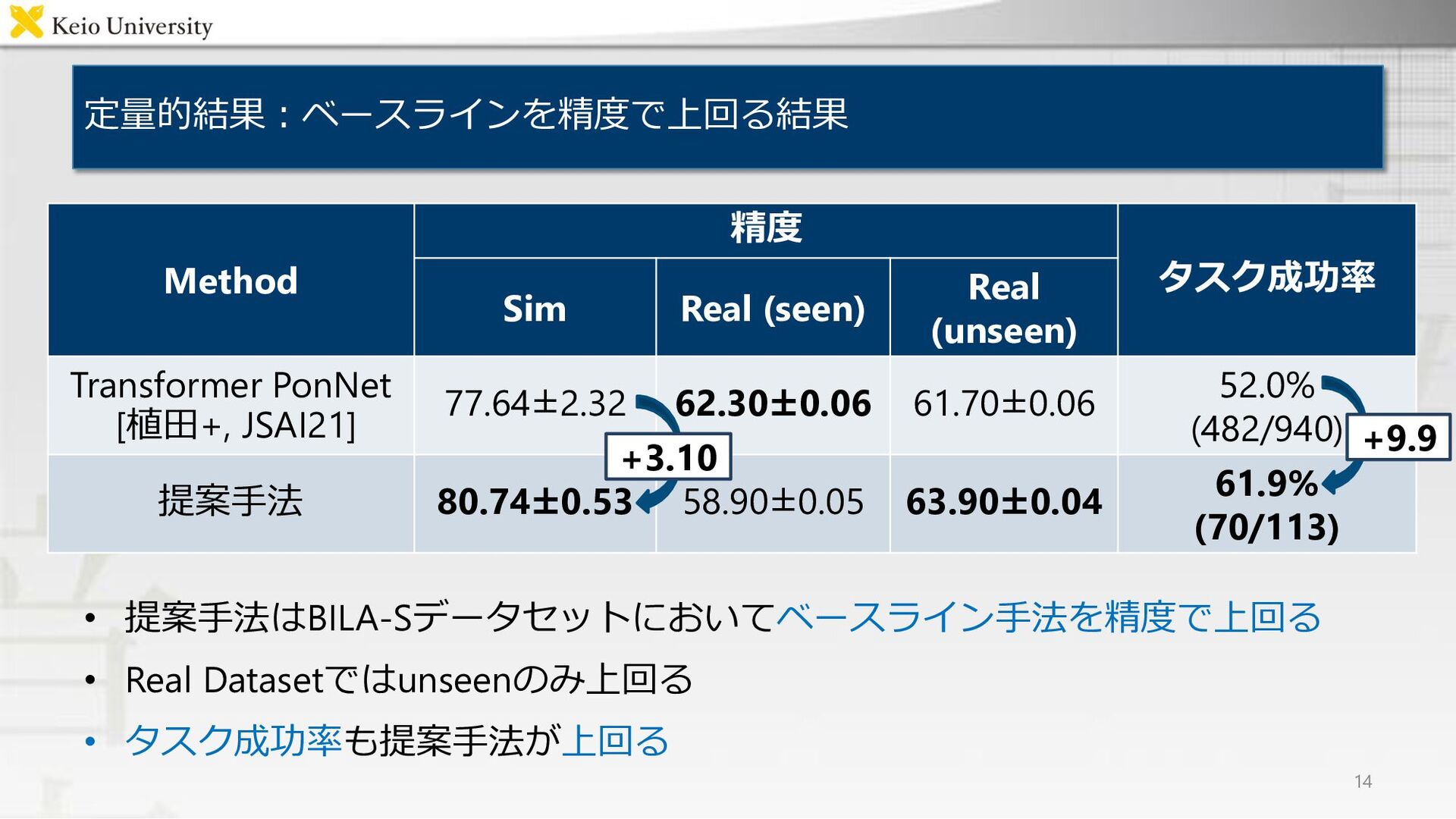
定量的結果:ベースラインを精度で上回る結果 • 提案手法はBILA-Sデータセットにおいてベースライン手法を精度で上回る • Real Datasetではunseenのみ上回る • タスク成功率も提案手法が上回る Method 精度
タスク成功率 Sim Real (seen) Real (unseen) Transformer PonNet [植田+, JSAI21] 77.64±2.32 62.30±0.06 61.70±0.06 52.0% (482/940) 提案手法 80.74±0.53 58.90±0.05 63.90±0.04 61.9% (70/113) 14 +3.10 +9.9
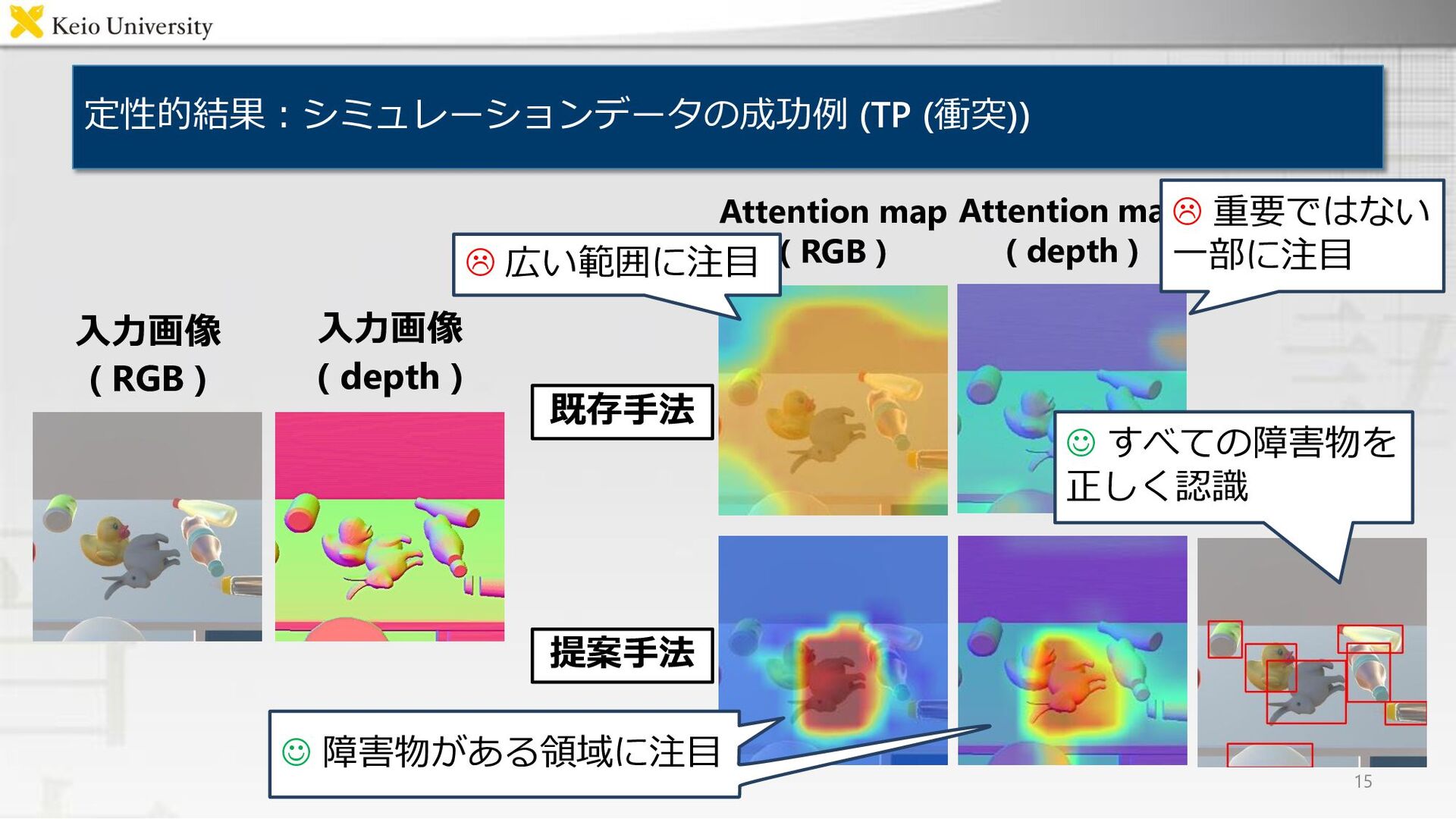
定性的結果:シミュレーションデータの成功例 (TP (衝突)) 15 入力画像 ( RGB ) 物体検出した 矩形領域
Attention map ( RGB ) Attention map ( depth ) 入力画像 ( depth ) 既存手法 提案手法 広い範囲に注目 重要ではない 一部に注目 ☺ 障害物がある領域に注目 ☺ すべての障害物を 正しく認識
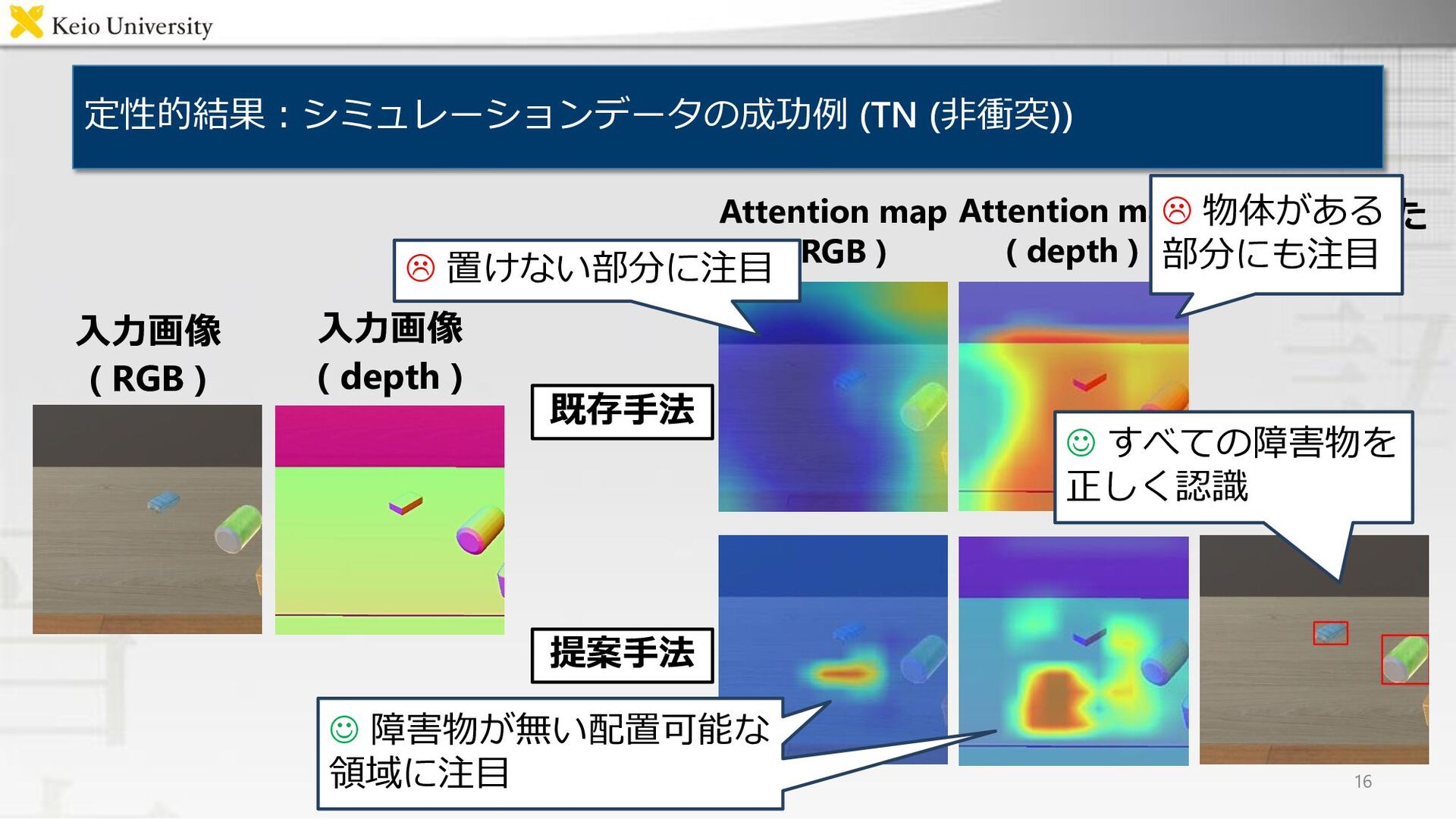
定性的結果:シミュレーションデータの成功例 (TN (非衝突)) 16 入力画像 ( RGB ) Attention map
( RGB ) Attention map ( depth ) 入力画像 ( depth ) 物体検出した 矩形領域 既存手法 提案手法 ☺ すべての障害物を 正しく認識 置けない部分に注目 物体がある 部分にも注目 ☺ 障害物が無い配置可能な 領域に注目
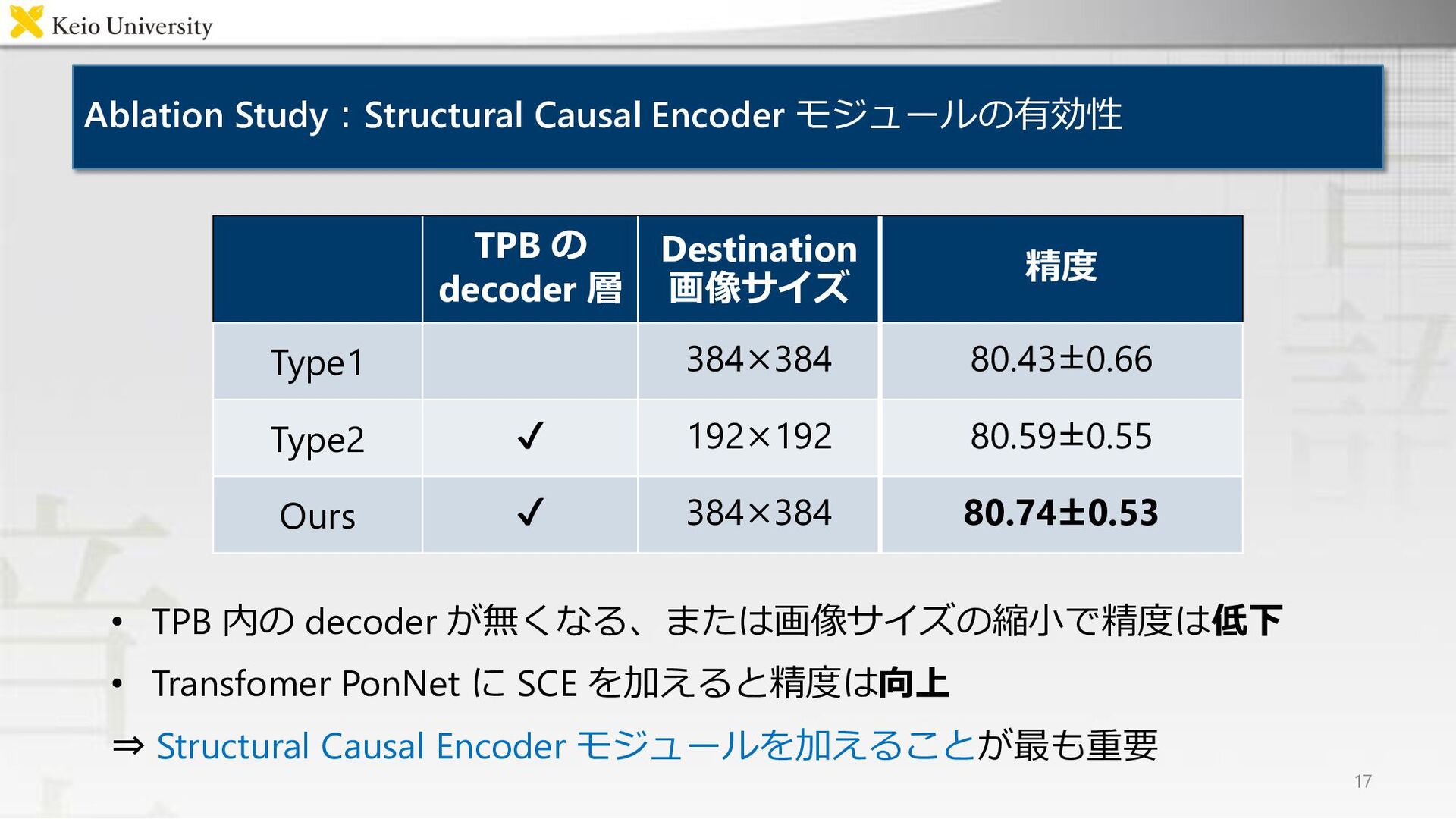
Ablation Study:Structural Causal Encoder モジュールの有効性 • TPB 内の decoder が無くなる、または画像サイズの縮小で精度は低下
• Transfomer PonNet に SCE を加えると精度は向上 ⇒ Structural Causal Encoder モジュールを加えることが最も重要 17 TPB の decoder 層 Destination 画像サイズ 精度 Type1 384×384 80.43±0.66 Type2 ✔ 192×192 80.59±0.55 Ours ✔ 384×384 80.74±0.53
結論:構造的知識を考慮した衝突確率の予測の提案 • 本研究のポイント – 構造的知識を扱うために Transformer PonNet を拡張 – 配置方策を導入
– ベースライン手法を精度・タスク 成功率の両方で上回る 18
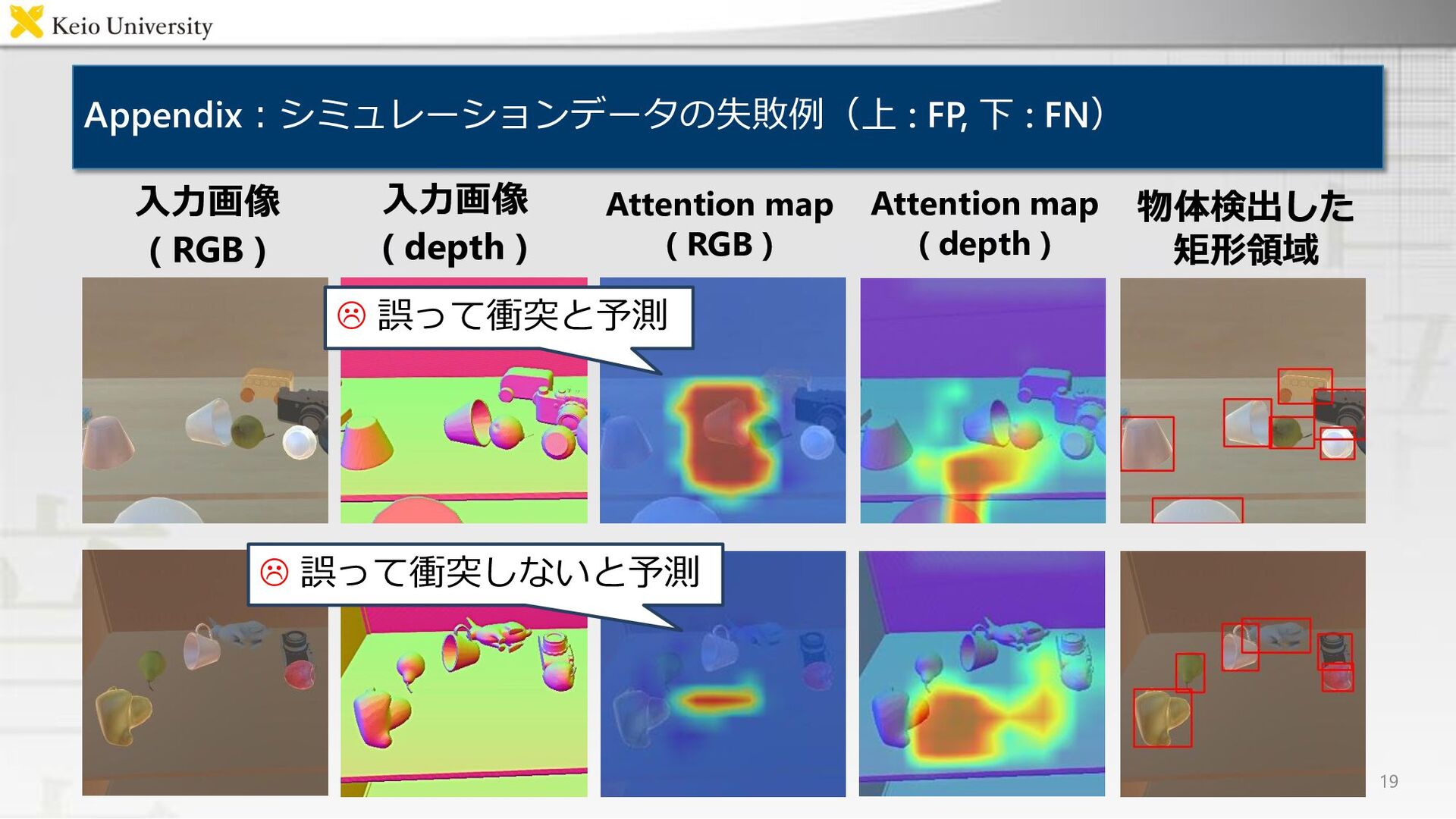
Appendix:シミュレーションデータの失敗例(上 : FP, 下 : FN) 19 物体検出した 矩形領域 Attention
map ( RGB ) Attention map ( depth ) 入力画像 ( RGB ) 入力画像 ( depth ) 誤って衝突と予測 誤って衝突しないと予測
Appendix:エラー分析(人間が見ても判断が難しい例、透過物体) • 衝突と予測した予測誤り – 軽微な接触 • 衝突しないと予測した予測誤り – 障害物と対象物体の衝突 –
障害物とアームの衝突 • 透過物体との衝突 – depth画像で透過部分が消える 20 入力画像 ( RGB ) 入力画像 ( depth )
Appendix : タスク成功率に関する定性的結果 21 Attention map ( RGB ) Attention
map ( depth ) 物体検出した 矩形領域 既存手法 提案手法 ☺ 缶に注目できている → 予測成功=配置成功 物体に注目できていない → 予測失敗=配置失敗
{kind=link}
{kind=link}
{kind=link}
![既存研究:物体配置分野はこれまでにも広く研究されている 4 代表的研究 概要 [Jiang+, IJRR12] 物体間の幾何学的関係や配置における人間の意向など 複数の性質を扱うグラフィカルなモデル [Gualtieri+, ICRA18]](https://files.speakerdeck.com/presentations/d29e29bf483d4161823b4ac418e5c984/slide_3.jpg){kind=link}
![• Transformer PonNet [植田+, JSAI21] – 入力:対象物体と配置領域のRGBD画像 – 出力:衝突確率 •](https://files.speakerdeck.com/presentations/d29e29bf483d4161823b4ac418e5c984/slide_4.jpg){kind=link}
{kind=link}
![• Attention Branch Network (ABN) [Fukui+, CVPR19] attention mapから特徴量に対して重み付けを行う 構造](https://files.speakerdeck.com/presentations/d29e29bf483d4161823b4ac418e5c984/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}