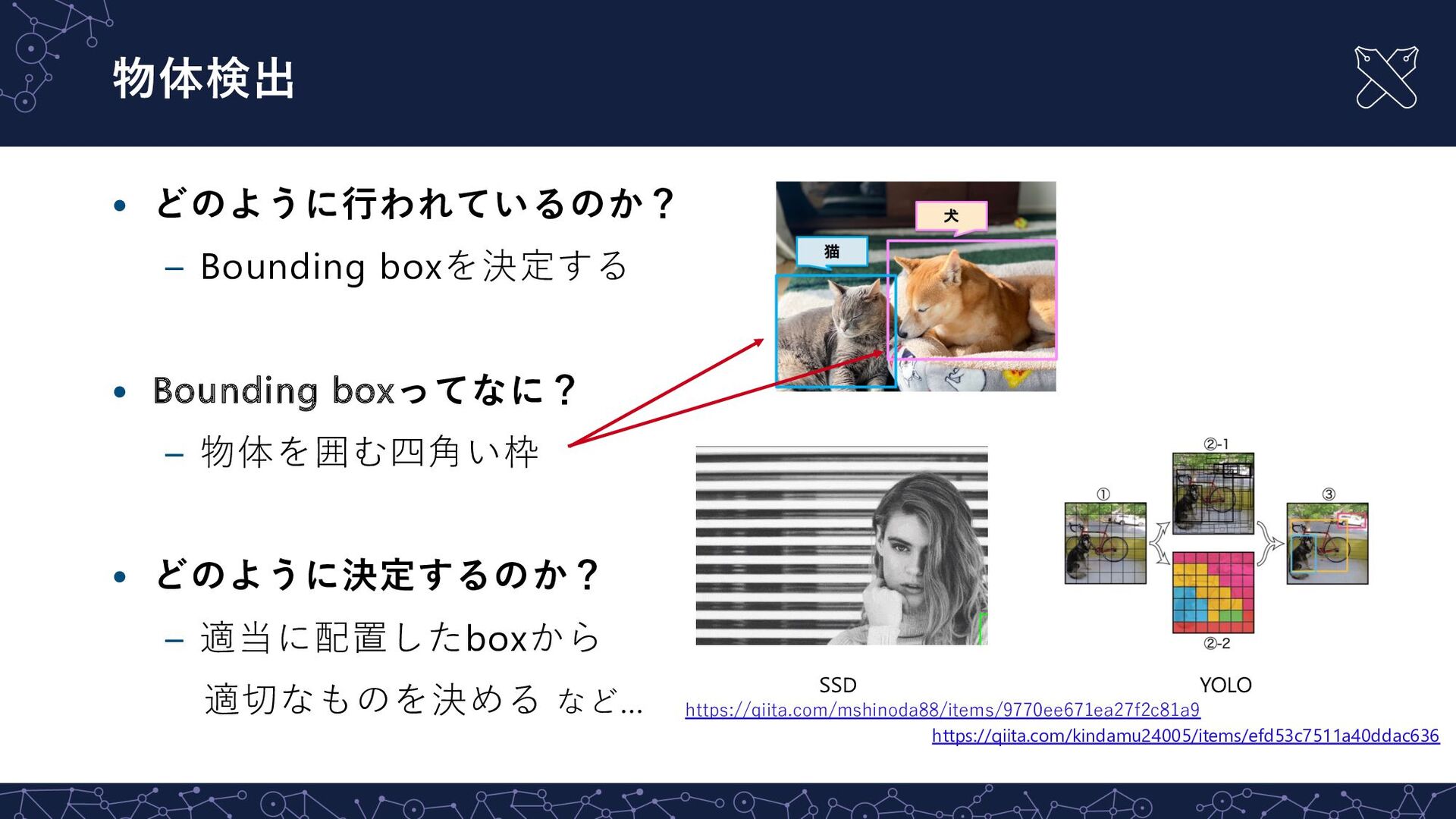
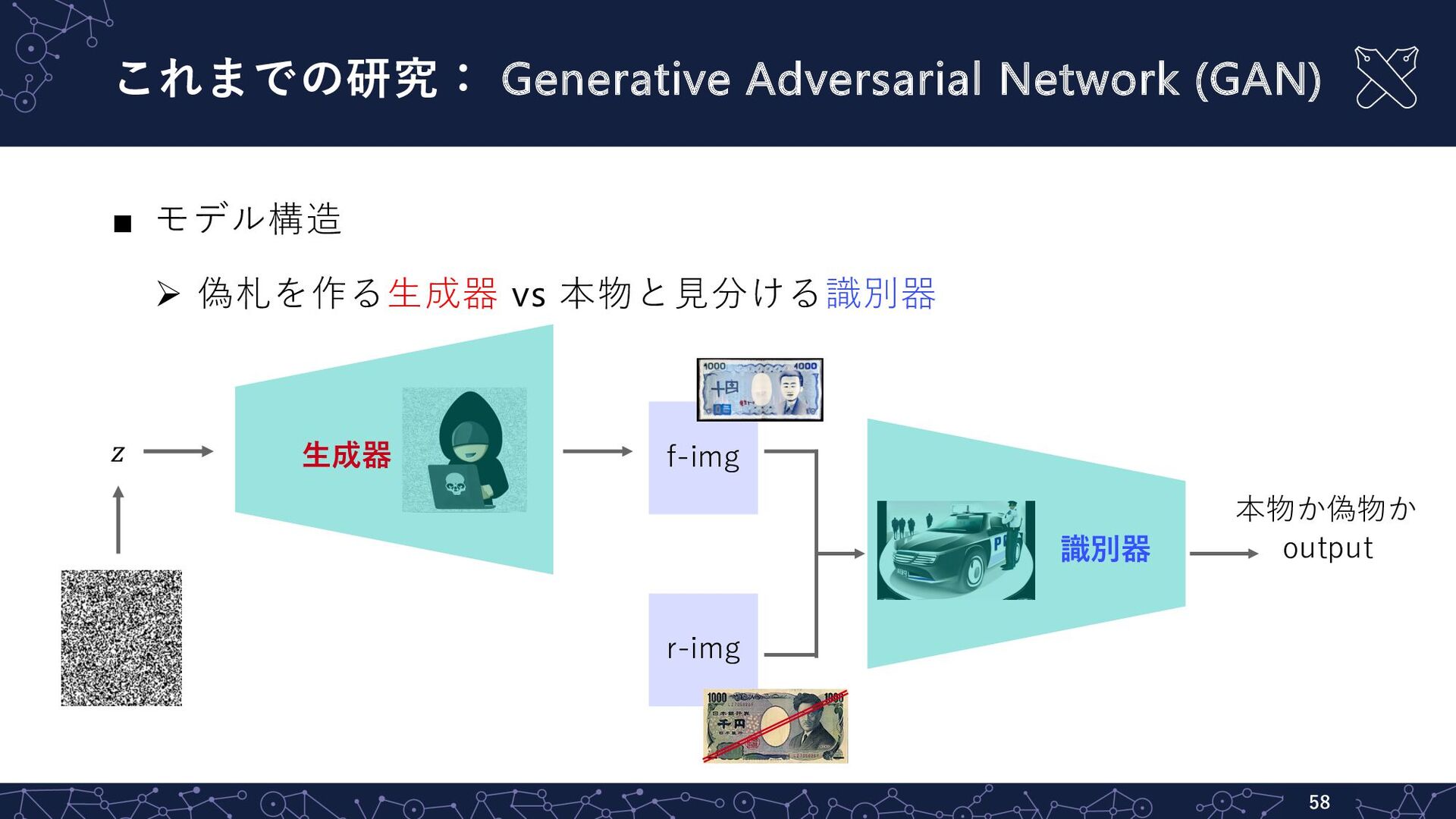
J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In CVPR (pp. 779-788). 物体検出⼿法:YOLOを使ってみよう
of a hedgehog wearing a red coat reading a book sitting on a lounge chair in the middle of a lush forest. https://imagen.research.google/ ▪ Imagen [Chitwan+, May, 2022] ⾚いコートをまとい,本を読 みながら,ラウンジチェアに 座り,⼤森林の中にいる, ハリネズミの写真 Google
of a hedgehog wearing a red coat reading a book sitting on a lounge chair in the middle of a lush forest. https://imagen.research.google/ ▪ Imagen [Chitwan+, May, 2022] Google
Ø 昨今,世間を騒がせているモデル Ø 前⼆つと異なり,だれでも無料で使⽤可能 Ø コンピュータの計算量を減らして,より⾼速に 62 Googleでの 検索ヒット数が 約 178,000,000 件! A photo of a hedgehog wearing a red coat reading a book sitting on a lounge chair in the middle of a lush forest. • 前の⼆つと⽐べると少し 微妙な⽣成 • そろそろアップデートさ れるらしい • さらに期待…!
a black ship, fairy tale style background, a beautiful half body illustration, top lighting, perfect shadow, soft painting, reduce saturation, leaning towards watercolor, art by hidari and krenz cushart and wenjun lin and akihiko yoshida,highly detailed, elaborate, digital painting hyper quality, 8k Ø ペリーがかっこよくなりすぎたが, 現代版のペリーっぽくなったのでア リ
Zhu-ge Liang performing dj at a live music venue, perfect lighting, by CASPAR DAVID FRIEDRICH and CLAUDE LORRAIN, 8k Ø やはり杉浦孔明研なので,諸葛亮孔 明がDJをしているところを⽣成. 発 想は「パリピ孔明」から得ました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
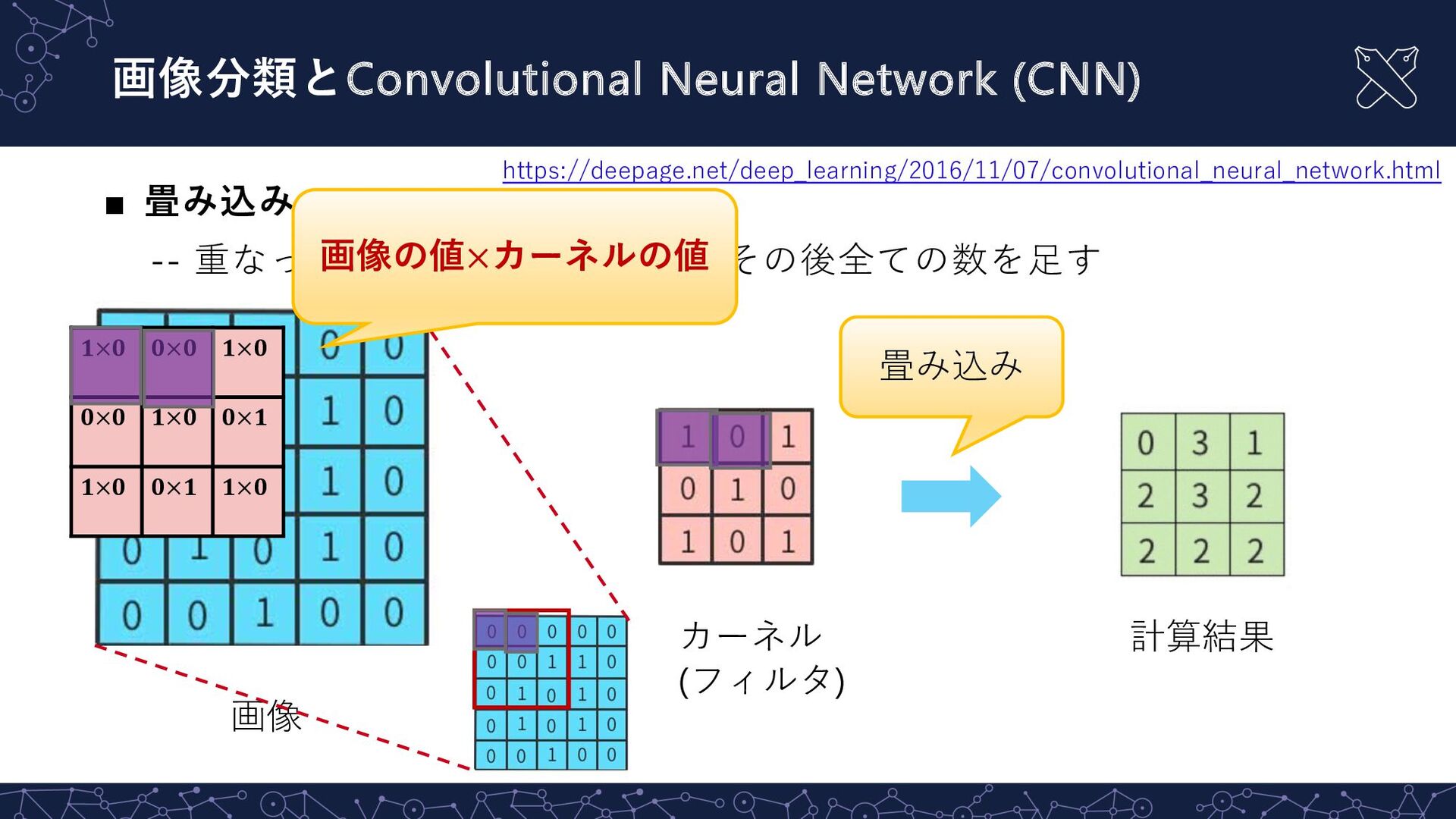{kind=link}
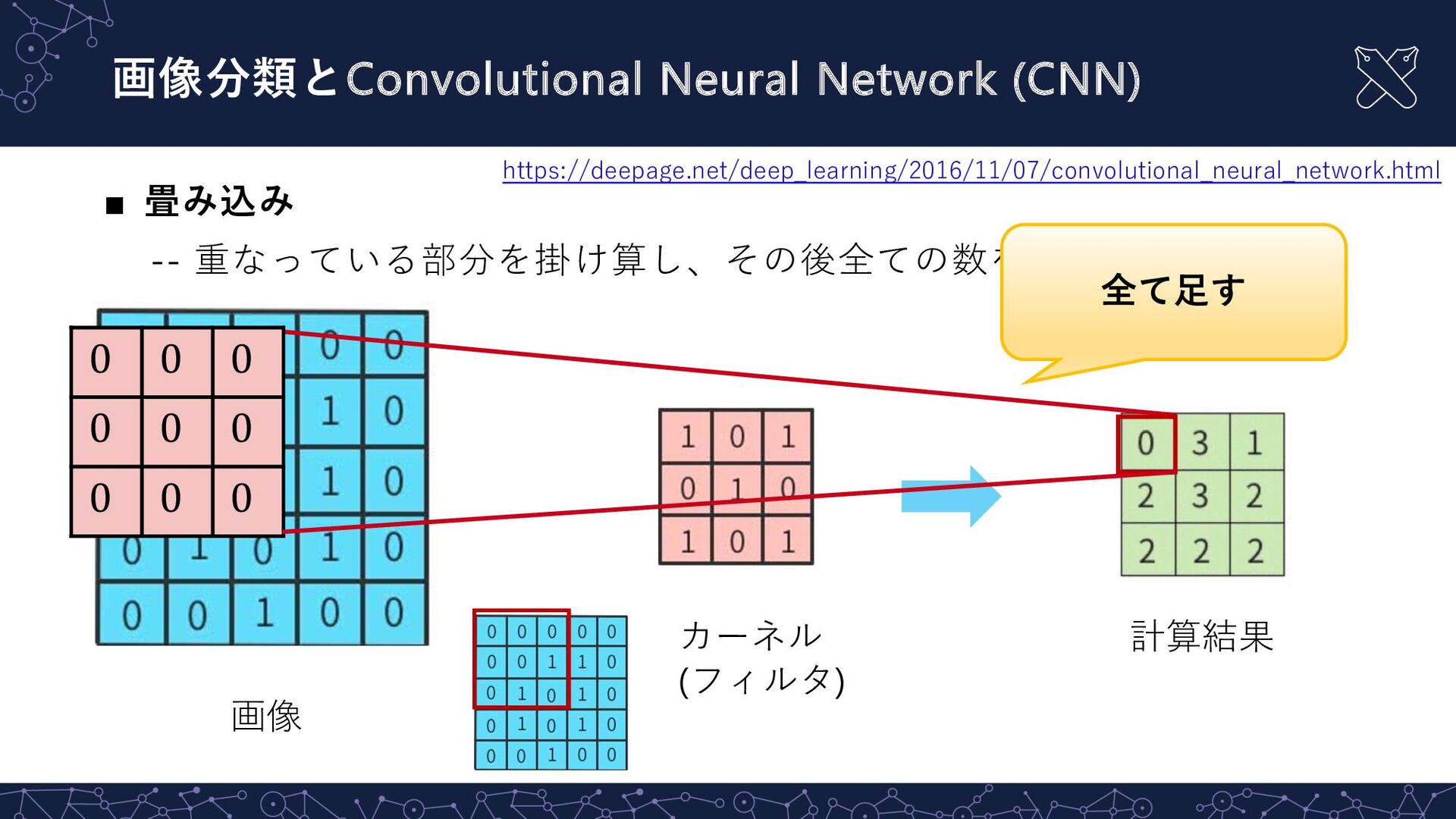{kind=link}
{kind=link}
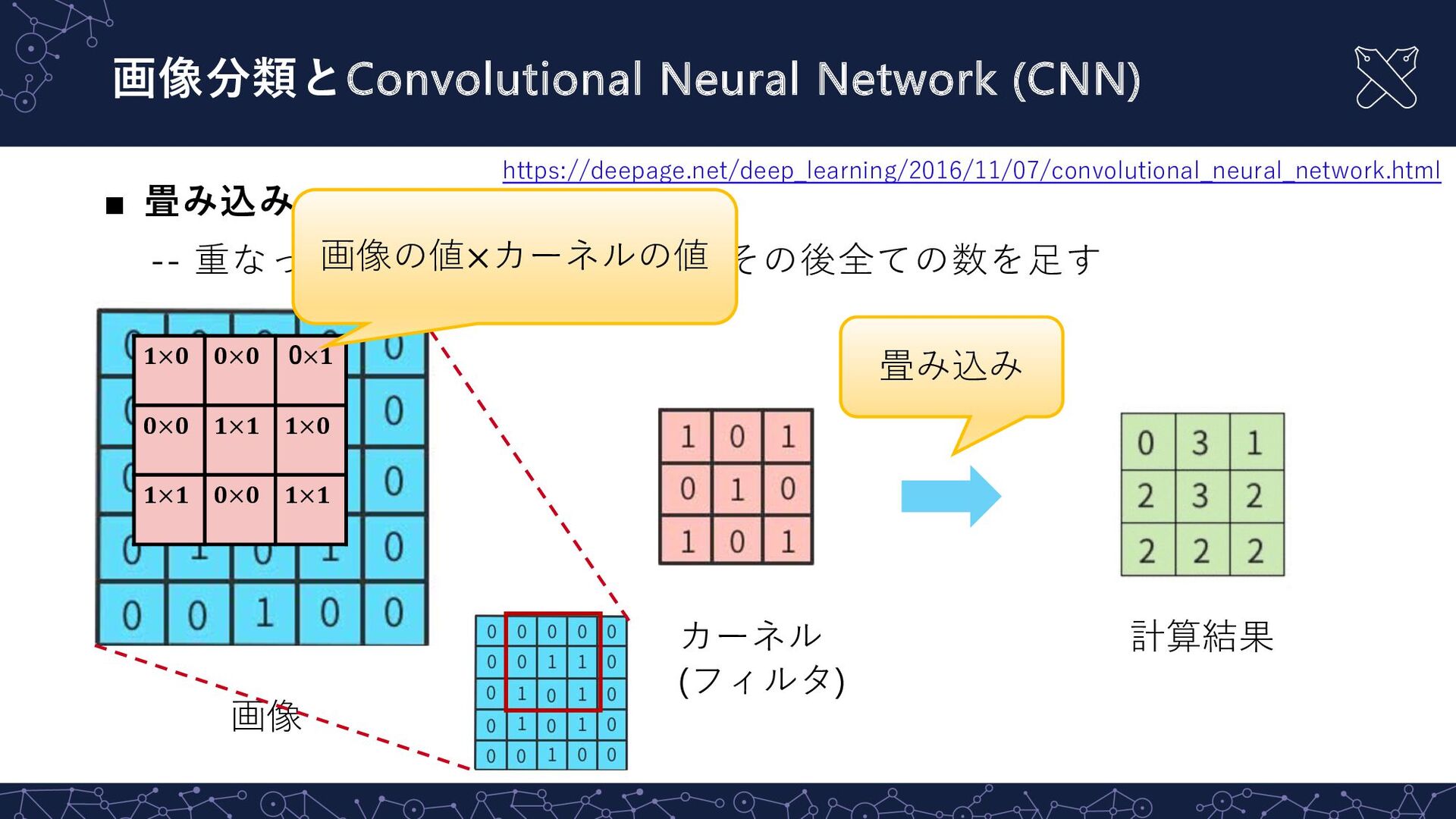{kind=link}
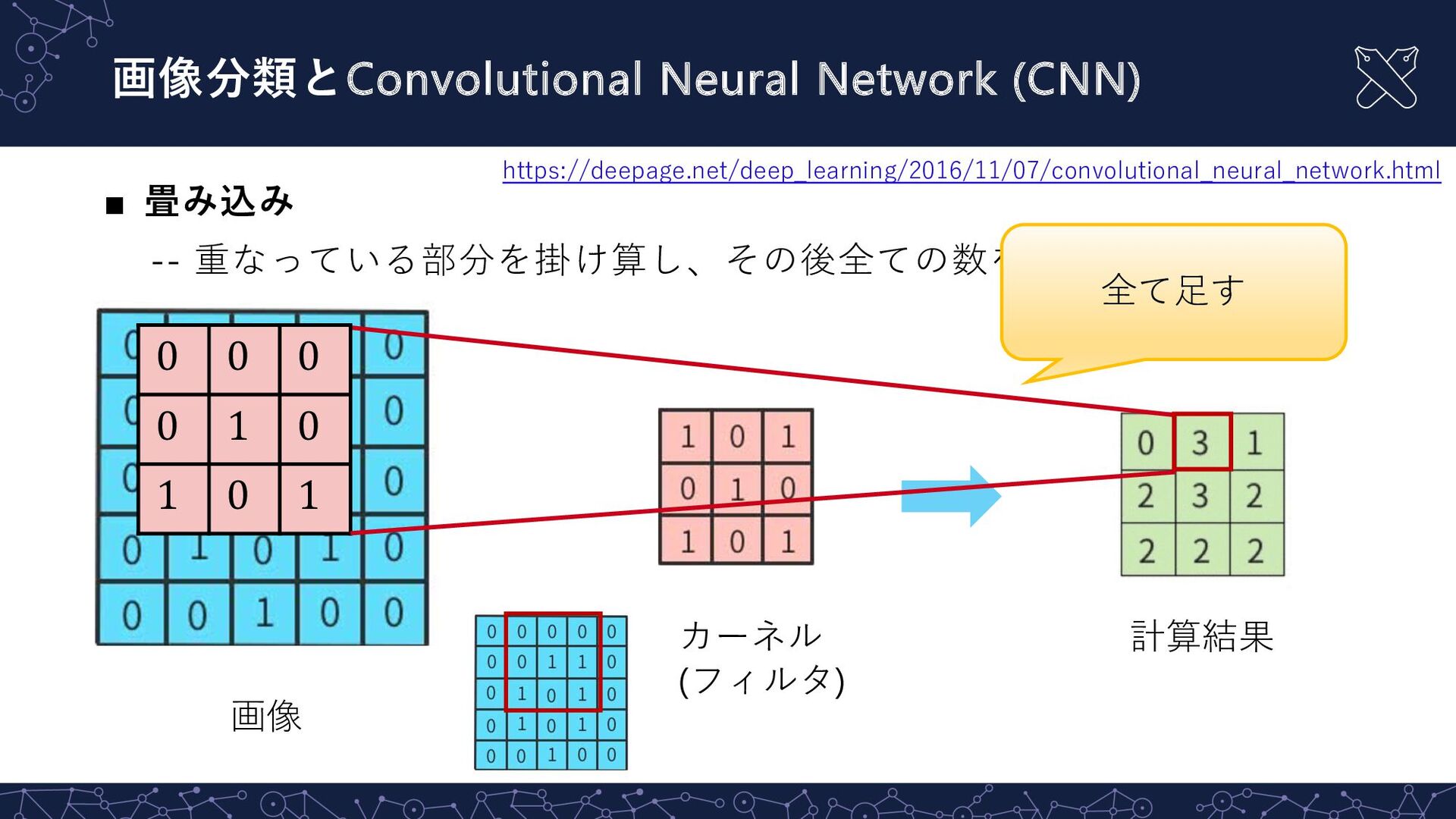{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![最近すごいのが現れた! [txt2img] ▪ DALL·E-2 [Aditya+, April, 2022] 60 A photo](https://files.speakerdeck.com/presentations/5bd631d474b54c298fa02d31358ca5ad/slide_59.jpg){kind=link}
![最近すごいのが現れた! [txt2img] ▪ DALL·E-2 [Aditya+, April, 2022] 61 A photo](https://files.speakerdeck.com/presentations/5bd631d474b54c298fa02d31358ca5ad/slide_60.jpg){kind=link}
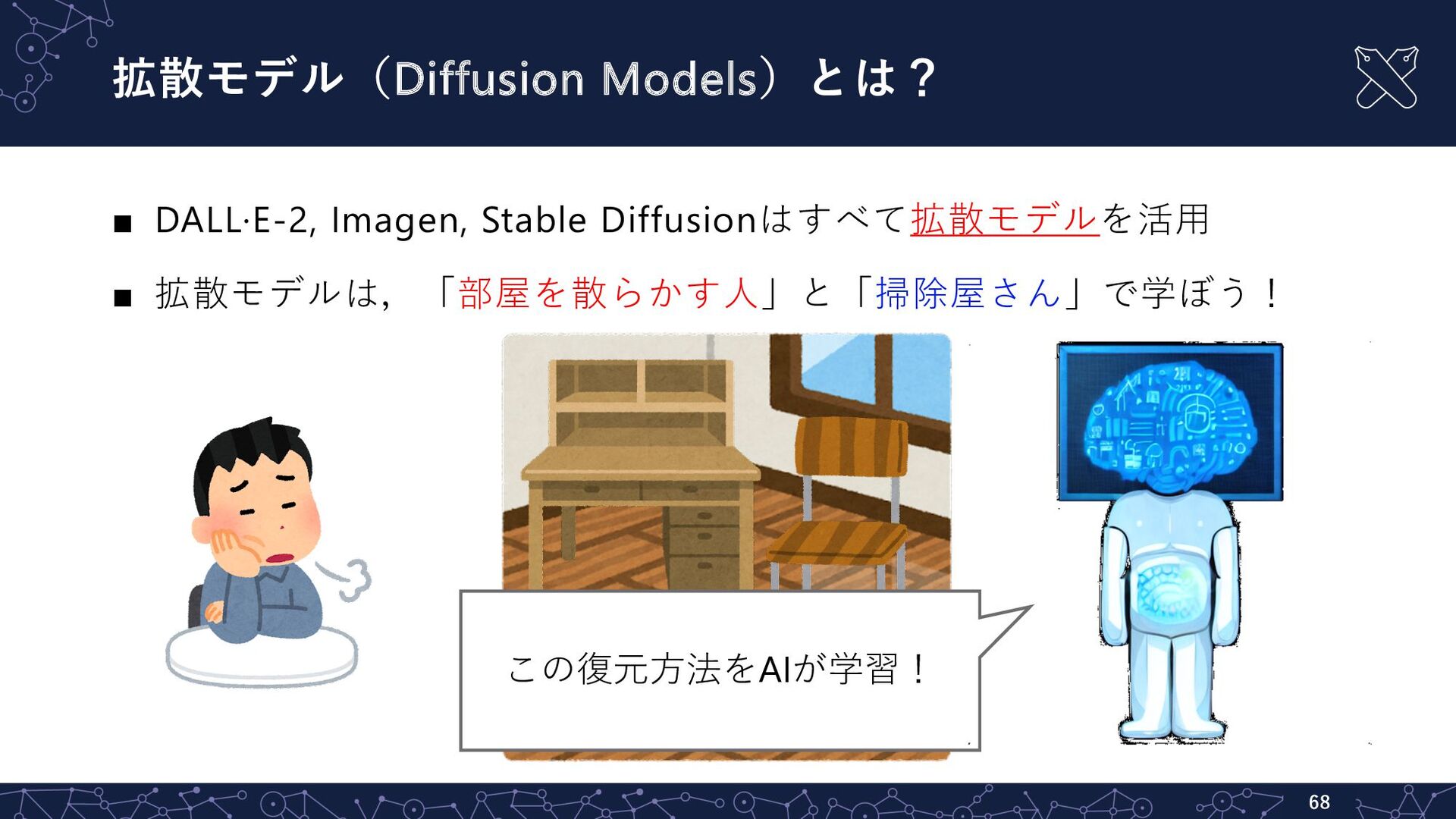
![最近すごいのが現れた! [txt2img] ▪ Stable Diffusion [Robin+, June, 2022, in CVPR]](https://files.speakerdeck.com/presentations/5bd631d474b54c298fa02d31358ca5ad/slide_61.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}