Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MediaDo DynamoDB活用事例/mediado-dynamodb-usecase
Search
kent-hamaguchi
February 25, 2021
Technology
1.4k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MediaDo DynamoDB活用事例/mediado-dynamodb-usecase
ANDPAD & Media Do 〜BtoB開発の舞台裏〜 で発表したスライドです。
https://mediado-go.connpass.com/event/200014/
kent-hamaguchi
February 25, 2021
More Decks by kent-hamaguchi
See All by kent-hamaguchi
メディアドゥ Go Conference 2021 スポンサーセッション/gocon-2021-mediado
kenthamaguchi
1
12k
メディアドゥ Amazon Personalize in AWS メディアセミナー Q1/mediado-amazon-personalize-aws-media
kenthamaguchi
0
1.6k
MediaDo.go #2 Clean Architectureとの付き合い方/mediado-go-2-clean-architecture
kenthamaguchi
2
2k
Infra Study Meetup #5 メディアドゥスポンサーセッション/infra-study-meetup-5-mediado
kenthamaguchi
0
930
JAWS DAYS 2020 メディアドゥスポンサーセッション/jaws-days-2020-mediado
kenthamaguchi
1
2.1k
OOC 2020 メディアドゥ スポンサーセッション/ooc_2020_mediado
kenthamaguchi
0
690
MediaDo.go #1 レガシーに立ち向かう / mediado-go-1-vs-legacy
kenthamaguchi
0
1.3k
MediaDo.go #1 GopherCon 2019 参加レポート / mediado-go-1-gophercon-2019
kenthamaguchi
1
1.4k
Go conf 2019 spring, sponsor session "Go初導入の組織で、社内外へ貢献していくために実施した、2つのこと" / go-conf-2019-spring-sponsor-session-mediado
kenthamaguchi
1
600
Other Decks in Technology
See All in Technology
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
230
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
1
800
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.4k
ガバナンスの「ちょうどいい落とし所」を探れ!開発スピードを妨げない運用判断の勘所 / SRE NEXT 2026
genda
1
260
AICoEでAIネイティブ組織への進化
yukiogawa
0
200
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
0
170
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
0
280
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
290
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
880
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
2
430
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
1
580
Featured
See All Featured
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
Why Our Code Smells
bkeepers
PRO
340
58k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
400
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
290
Designing for Timeless Needs
cassininazir
1
380
Prompt Engineering for Job Search
mfonobong
0
380
Amusing Abliteration
ianozsvald
1
230
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
How STYLIGHT went responsive
nonsquared
100
6.2k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Transcript
Media Do DynamoDB Data Management
メディアドゥの電子書店構築システムにおいて、AWS の DynamoDB を利用しました。 今回はその活用事例を紹介します。 背景 1. バックエンドの抜本的な改修が必要となった 2. 対応コストとスケーラビリティから、既存の仕組みを改修するより、新規の仕組みの開発を選択した
3. 新規に開発するシステムのデータベースとして DynamoDB を選択した 概要
解決方法 DynamoDBの活用 業務 データ特性 データの種類と数 01 Read/Write の頻度 02 内容
03
データ特性 データの種類と数 01
メディアドゥではマルチテナント型の電子書店構築システムを提供しています。それを用いて運営している電子書店は 数 十 にも及び、それぞれにコンテンツや履歴データが蓄積されます。 前述の背景に関連して、新規に開発する仕組みで扱うデータは下記が対象でした。 1. 1つの書店に対して、 数万 〜 数十万
のコンテンツに対するメタデータ (書誌データ) 2. それぞれのコンテンツに対するユーザの購入履歴 データ特性
データの種類 電子書籍のメタデータ ユーザの購入履歴データ
46,720,000 現在のデータ数 (現在も増加中)
業務 Read/Write の頻度 02
データ自体はバッチとWebサーバの両方から随時利用されます。 コンテンツのメタデータはバッチ処理で追加され、購入履歴データはWebサーバから追加されます。 Webサーバからの利用があることにより、データベースは高可用性を保ちつつ、大量に 書込 / 読込 が実行されたとして も、スループットの低下を避けるべき、という運用が求められます。 また、データを削除するという運用が無く、蓄積される一方という業務が求められるため、保存容量の上限などが制約とし て関わると、リスク等にも繋がりました。
業務
データの 読込 / 書込 履歴データ Webサーバが随時 書き込みと読み込み メタデータ書込 数十書店分のデータを バッチが大量追加
メタデータ読込 数十書店分のデータを Webサーバが随時読み込む
解決方法 DynamoDBの活用 03
前述の課題を解決する上で、AWS の RDS や Aurora などの RDBMS よりも、 DynamoDB を選択した方が
メリットを多く受けることが出来ました。 • 高可用性 ◦ AWS の複数のリージョンへ分散され、非常に高い可用性を持つ ◦ 高いスケーラビリティも持つ • ストレージ容量 ◦ 無制限 • スループット ◦ ミリ秒単位での応答 ◦ データが増加してもパフォーマンスが変化しない • 運用の手軽さ ◦ ネットワーク や サーバインスタンス の管理が不要 ◦ プログラムからは AWS SDK を介して直接操作をすることができる • コスト効率も高い 解決方法
非常に多くの メリット
ここから ざっくりと DynamoDBの仕様
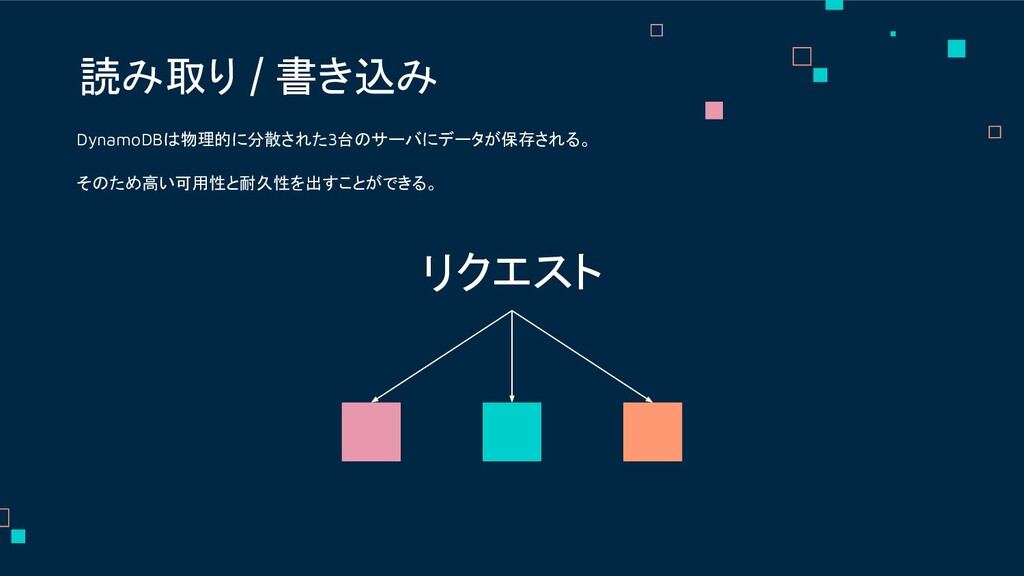
DynamoDBは物理的に分散された3台のサーバにデータが保存される。 そのため高い可用性と耐久性を出すことができる。 読み取り / 書き込み リクエスト
しかし、どれか1台に書き込んだ結果が、まだ他のディスクに反映されていない場合、古い情報が返る。 一貫性が一時的に保たれず、これを結果整合性という。 読み取り / 書き込み リクエスト1 書き込み 読み込み (まだ古い) リクエスト2
複数のディスクを読み込むことで、結果整合性に対して新しいデータを取得できるようになる。 しかし負荷はかかるので、キャパシティユニットは倍消費する。 読み取り / 書き込み リクエスト1 書き込み 読み込み リクエスト2
書き込み 強力な整合性 読み取り 結果整合性 読み取り 01 02 読み取り / 書き込み
03
他には、複数の 読み取り / 書き込み の結果を保証するトランザクション機能というのがある。 単一のデータだけではなく、複数のデータに対して一貫性が必要な場合はそれらを利用する。 • TransactGetItems • TransactWriteItems
読み取り / 書き込み
DynamoDB には、EC2 や RDS のようなインスタンスタイプが存在しない。 読み取り / 書き込み リクエストの データ容量
と 回数 の利用回数で DynamoDB の利用状況を管理する。 これを キャパシティ ユニットという。 キャパシティ ユニットの管理方法は2種類 • プロビジョニング • オンデマンド キャパシティ ユニットを使い切ると性能に上限がかかり、DynamoDB の応答が遅延したりする。 キャパシティ ユニット
• プロビジョニング ◦ 事前にどの程度利用するのか見積もり、キャパシティユニットを決めておく ◦ 決めておいた範囲であれば性能が保証される ◦ 確保したキャパシティ ユニットをどのくらい維持したかで請求金額が決まる ◦
状況に応じて自動スケールも設定できる • オンデマンド ← 前述した電子書店構築システムでは、オンデマンドを使っている ◦ プロビジョニングの後に追加された新しい仕様 ◦ キャパシティ ユニットを事前に決める必要がない ◦ リクエスト状況に応じて柔軟にスケールする ◦ 利用した分に応じて後から請求額が決まる ◦ 非常にコスト効率の良い設定 キャパシティ ユニット
• セカンダリインデックス ◦ テーブルに保存されたデータの項目を指定して、インデックスを作成する ◦ データの逆引きや特定のデータによるソートが可能になる ◦ 種類 ▪ グローバル
セカンダリ インデックス (GSI) ▪ ローカル セカンダリ インデックス (LSI) • ポイントインタイムリカバリ ◦ テーブルの連続的なバックアップ ◦ 過去35日間の任意のタイミングのデータに戻すことができる その他
まとめ
• RDBMS を 自身で運用するよりも、セットアップと運用が手軽 • 高いコストパフォーマンスと、スケーラビリティを得られる • 強い整合性読み取り や トランザクション書き込み
など、新しい機能が年々追加されている • データの一貫性が求められる業務でも DynamoDB は活用できる • セカンダリインデックスを用いた、柔軟で高速な検索も可能 まとめ
以上で紹介した機能を利用し、電子書店構築システムのバックエンドを運用しています。 DynamoDB を活用することで、データベースの構築や運用の手間から開放されつつ、高い業務パフォーマンスを出すこと ができました。 AWSによるマネージドサービスであるため、ディスク容量や性能などの管理がほぼ必要なくなり、本番稼働開始から1年間 で問題が出ていません。 書籍のメタデータを扱う部分などでは、一貫性を持ったデータ運用が必要となりましたが、強力な整合性読み取りなどの機 能により、ID採番などの一意なデータの発行も実現できました。 DynamoDB は年々アップデートされており、多種多様な業務範囲をカバーできる機能と性能を備えています。
まとめ
THANKS
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}