Maximizing performance in data engineering is a daunting challenge. We present some of our work on designing faster indexes, with a particular emphasis on compressed indexes. Some of our prior work includes (1) Roaring indexes which are part of multiple big-data systems such as Spark, Hive, Druid, Atlas, Pinot, Kylin, (2) EWAH indexes are part of Git (GitHub) and included in major Linux distributions.
We will present ongoing and future work on how we can process data faster while supporting the diverse systems found in the cloud (with upcoming ARM processors) and under multiple programming languages (e.g., Java, C++, Go, Python). We seek to minimize shared resources (e.g., RAM) while exploiting algorithms designed for the single-instruction-multiple-data (SIMD) instructions available on commodity processors. Our end goal is to process billions of records per second per core.
The talk will be aimed at programmers who want to better understand the performance characteristics of current big-data systems as well as their evolution. The following specific topics will be addressed:
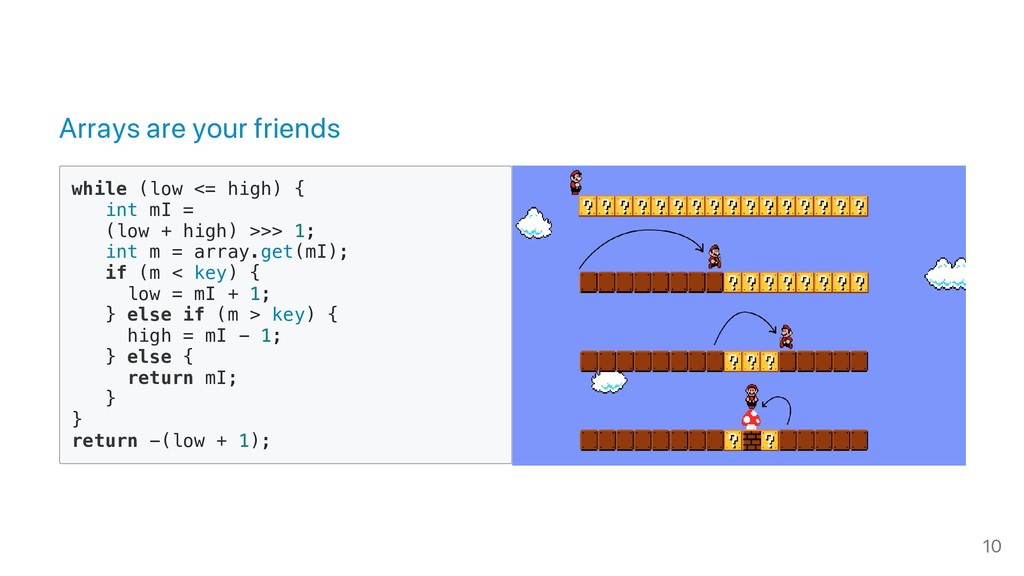
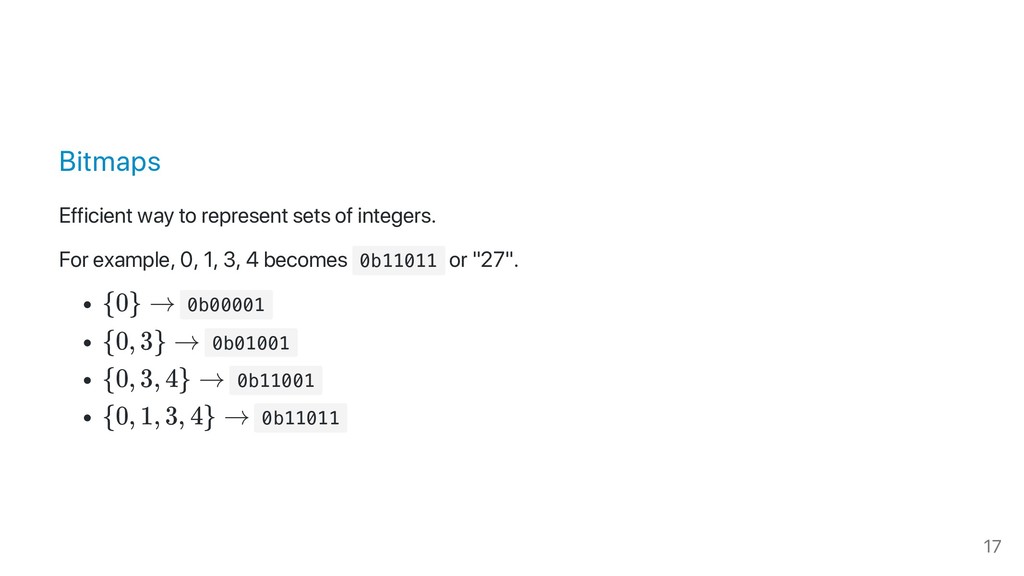
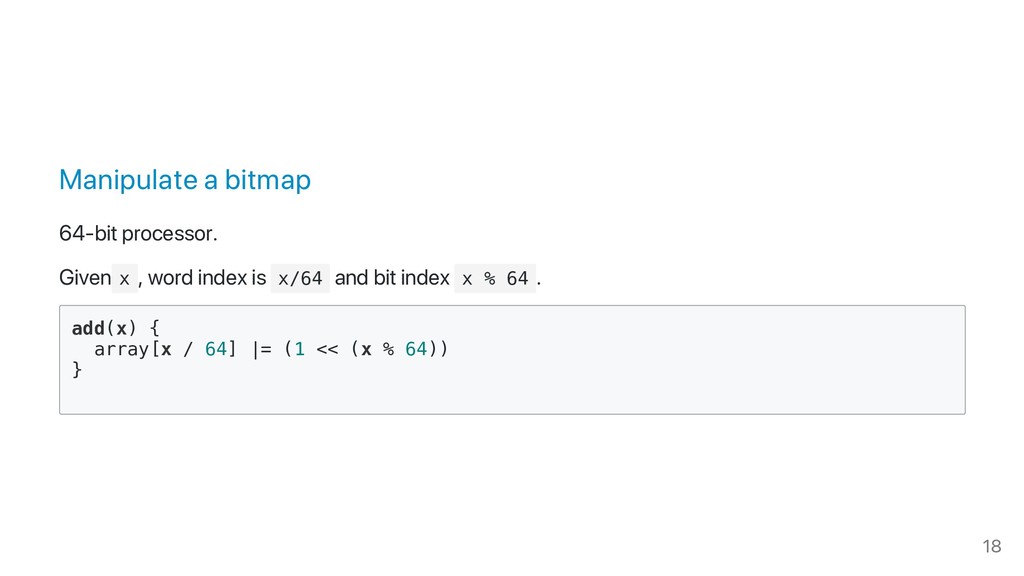
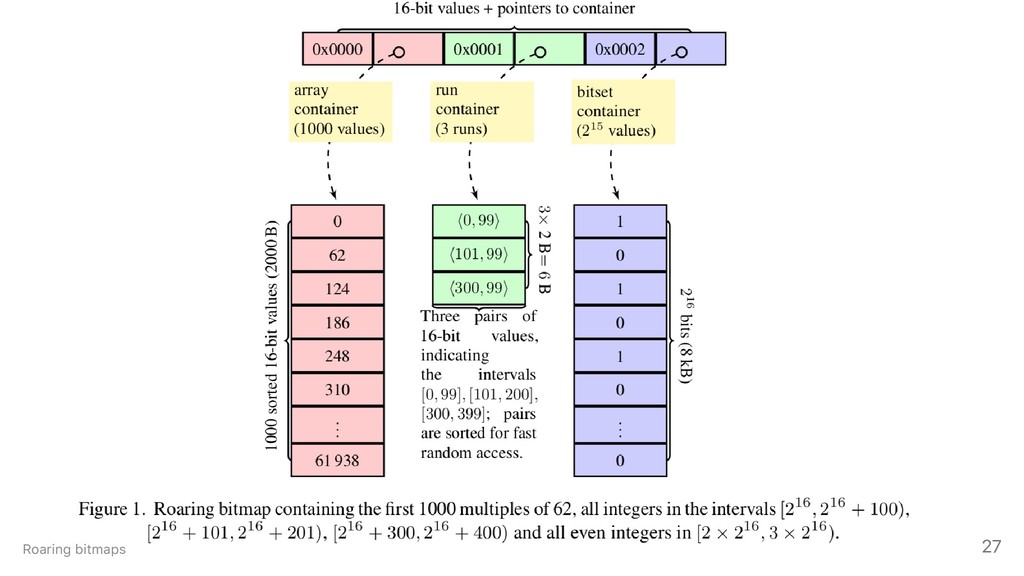
1. The various types of indexes and their performance characteristics and trade-offs: hashing, sorted arrays, bitsets and so forth.
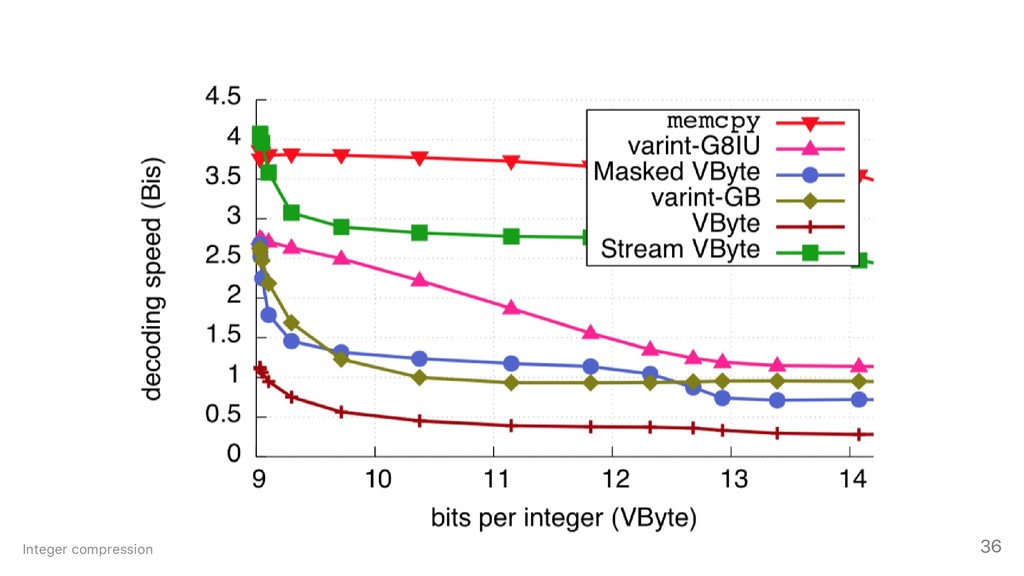
2. Index and table compression techniques: binary packing, patched coding, dictionary coding, frame-of-reference.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}