delivery company • Singapore - Hong Kong - Taiwan - Japan • Malaysia - Philippines - Indonesia - Thailand • Wide range of supermarkets and boutique stores • Referral: GIVE $20 GET $10 honestbee https:/ /honestbee.sg/r/DATL8886 Let me know!
don’t know until the bee is picking the item Why? • Customer happiness • Business profitability How? • Predictive Model (Binary Classification) • Communicate with our customers before they even make a purchase Item Availability Prediction
Machine • Available in Python, R, and Julia • State-of-the-art, winning algorithm for lots of Kaggle’s data science challenges: • 1st @ Crowdflower Search Results Relevance • 1st @ Microsoft Malware Classification Challenge (BIG 2015) • 1st @ Tradeshift Text Classification • 1st @ Otto Group Product Classification Item Availability Prediction
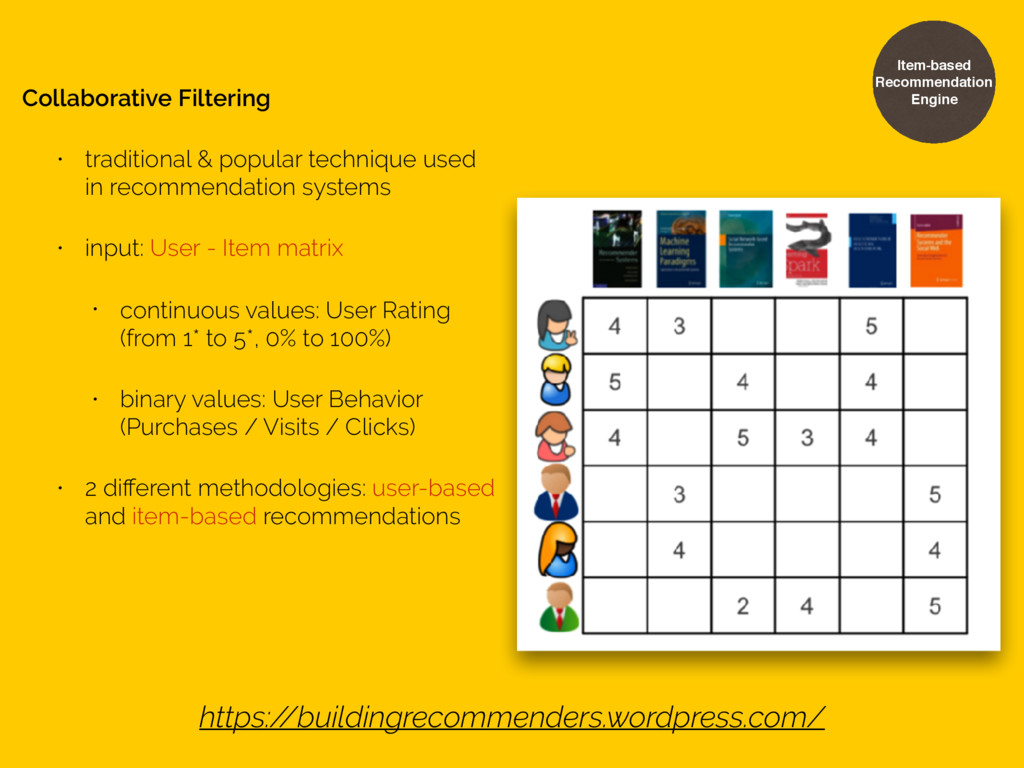
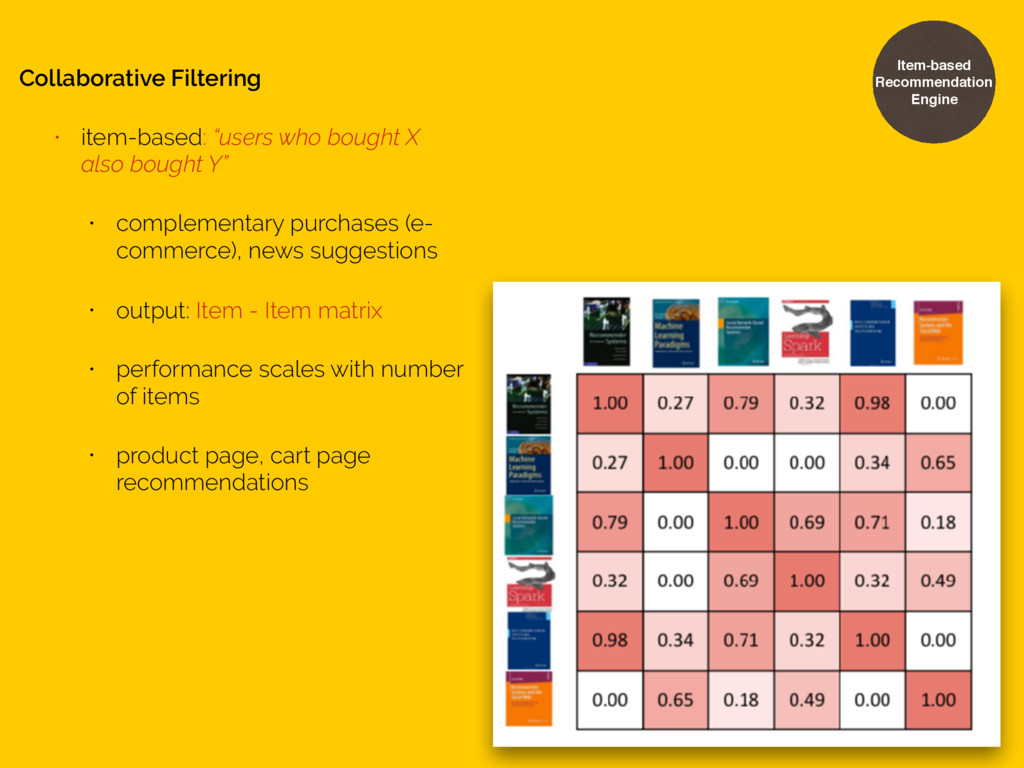
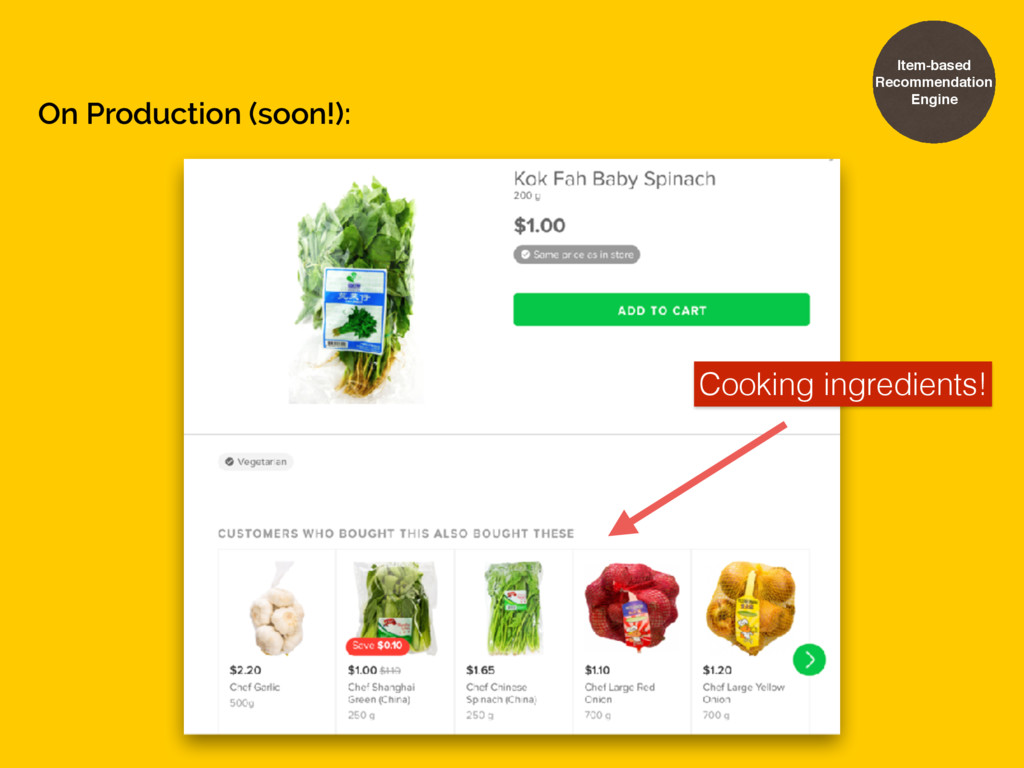
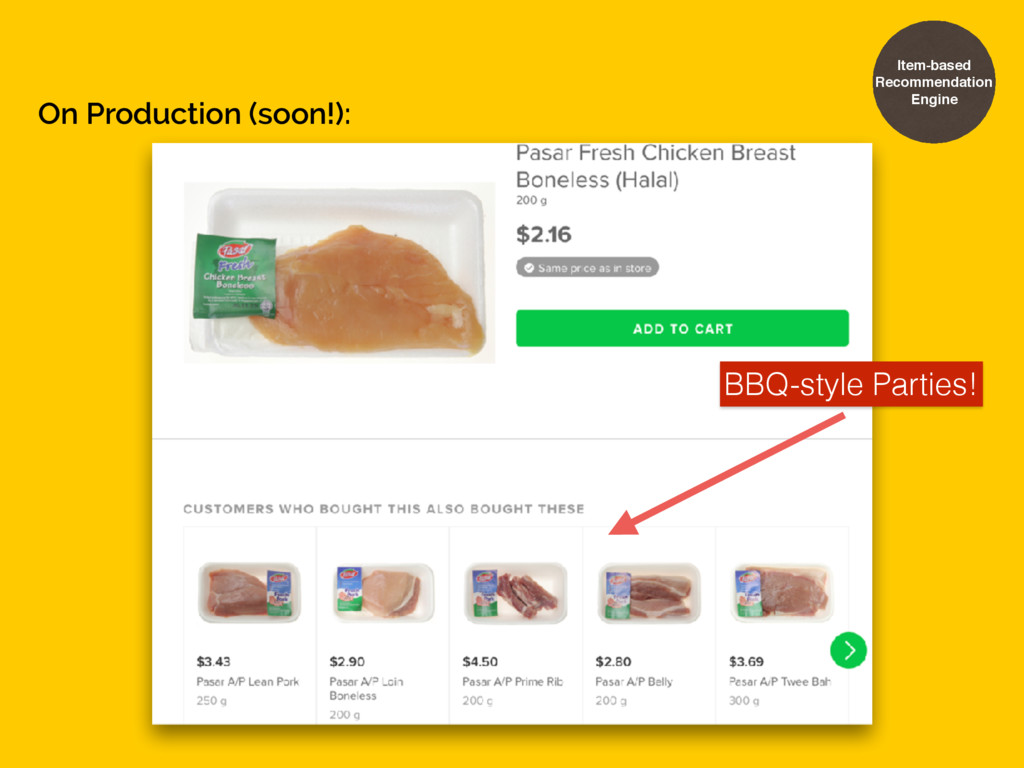
• works for social networks • works for “taste”-like recommendations (i.e movies, fashions, social networks) • output: User - User matrix • performance scales with number of users • user home page, emails, in-app notification Item-based Recommendation Engine
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}