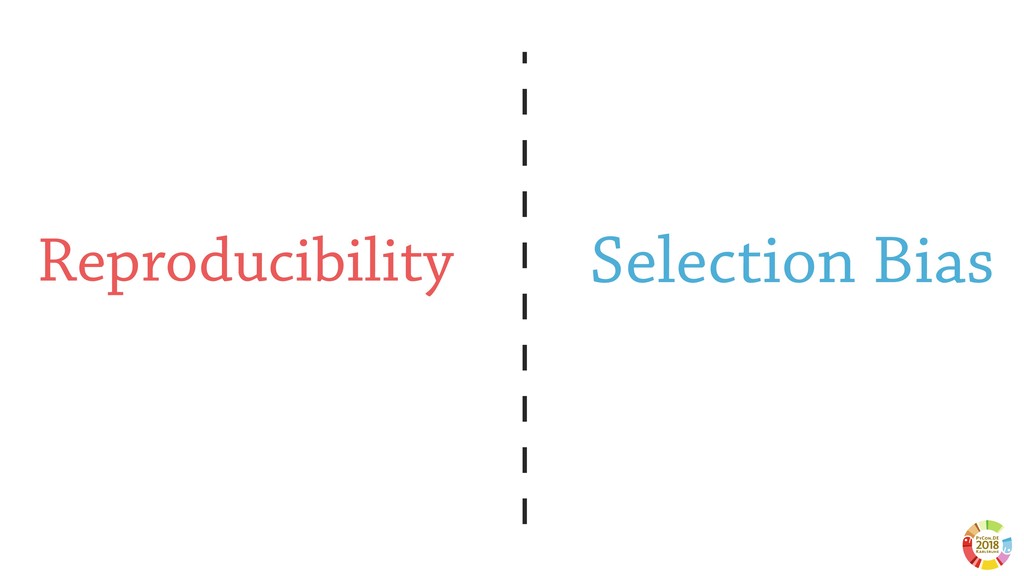
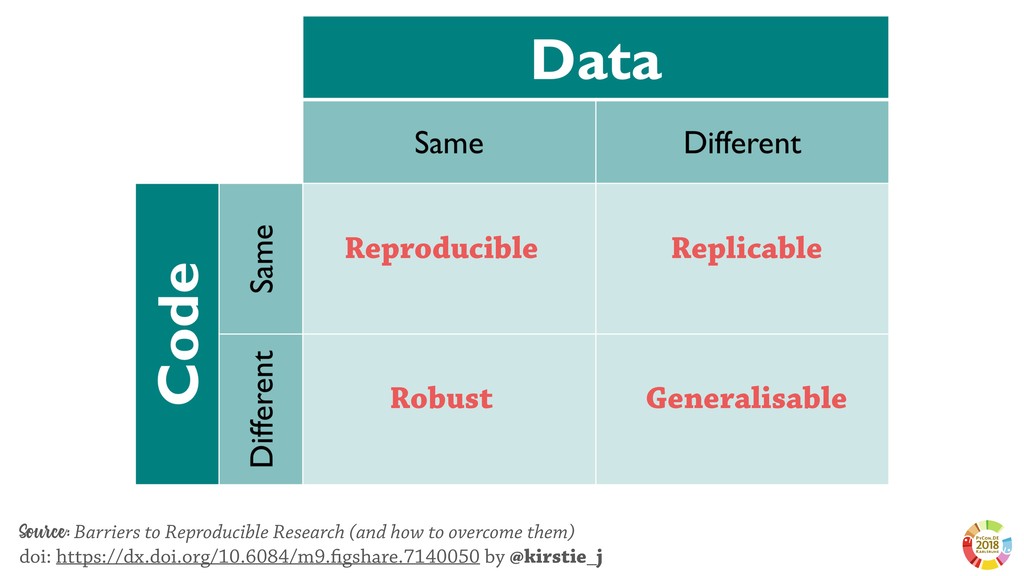
_Reproducibility_ - the ability to recompute results — and _replicability_— the chances other experimenters will achieve a consistent result[1]- are among the main important beliefs of the scientific method.
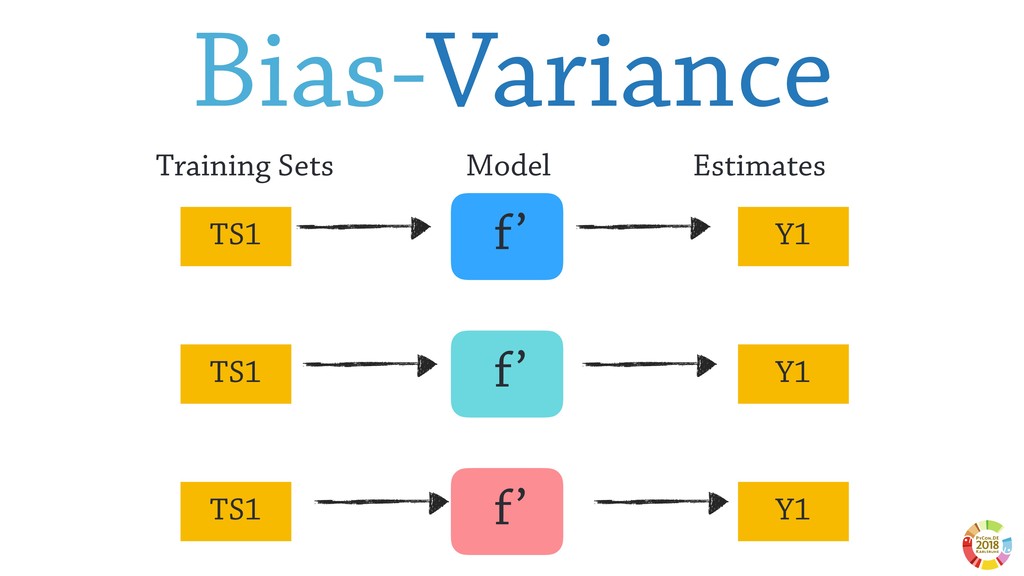
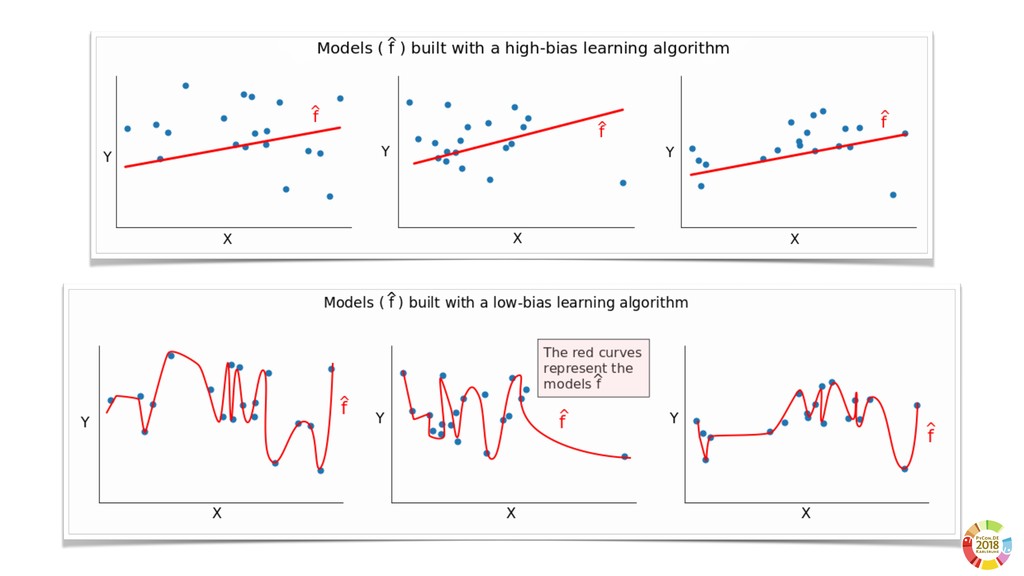
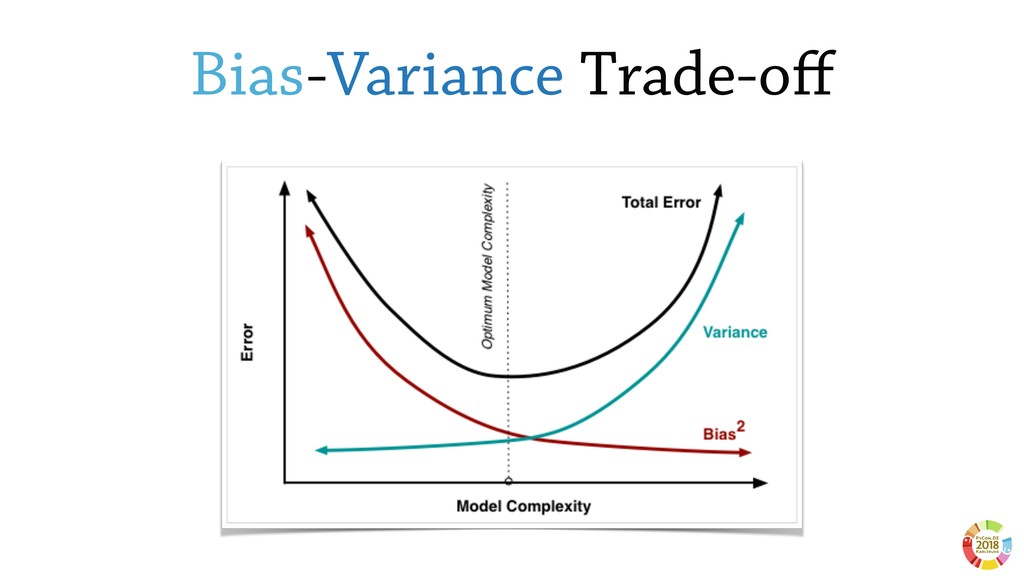
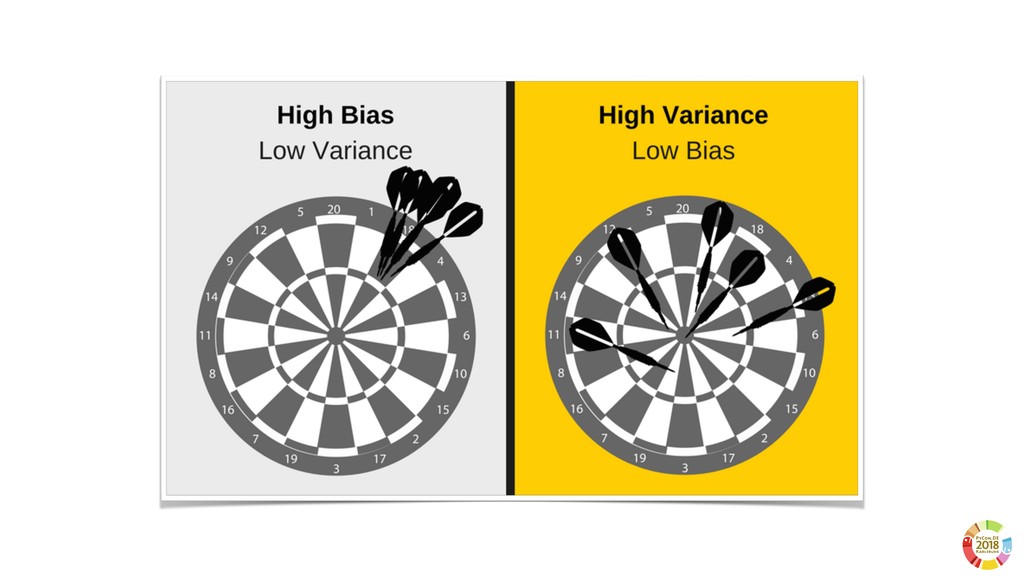
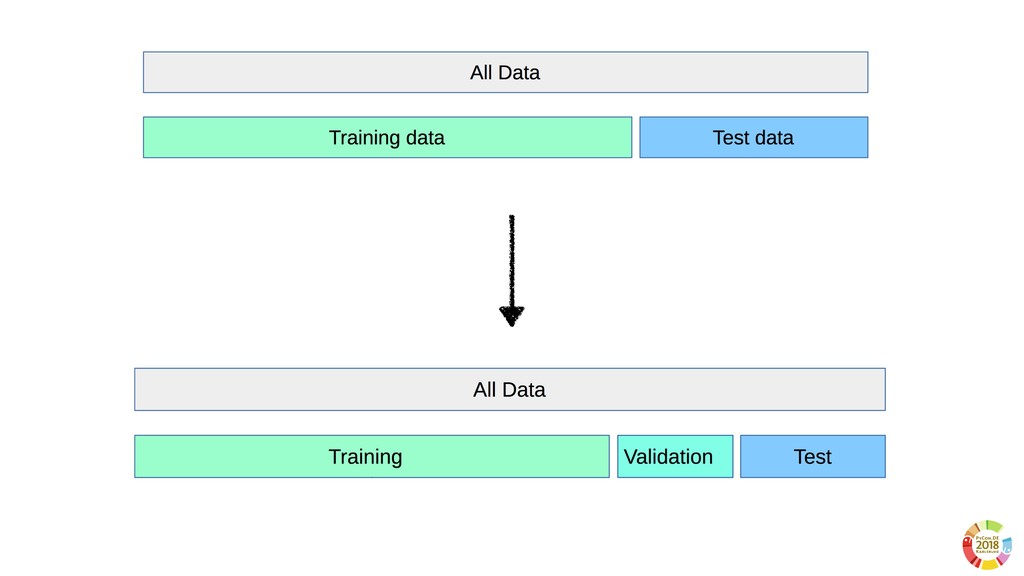
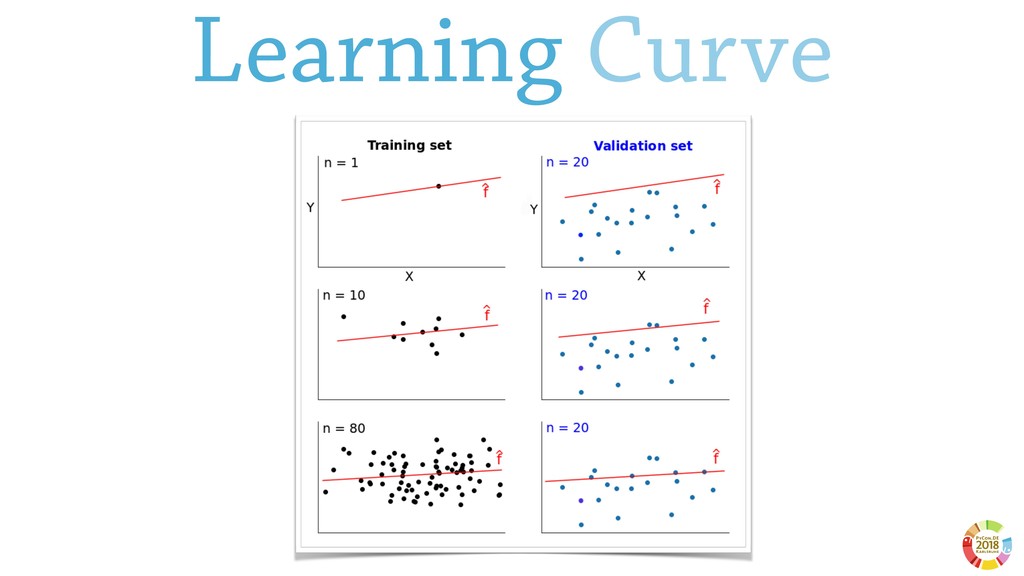
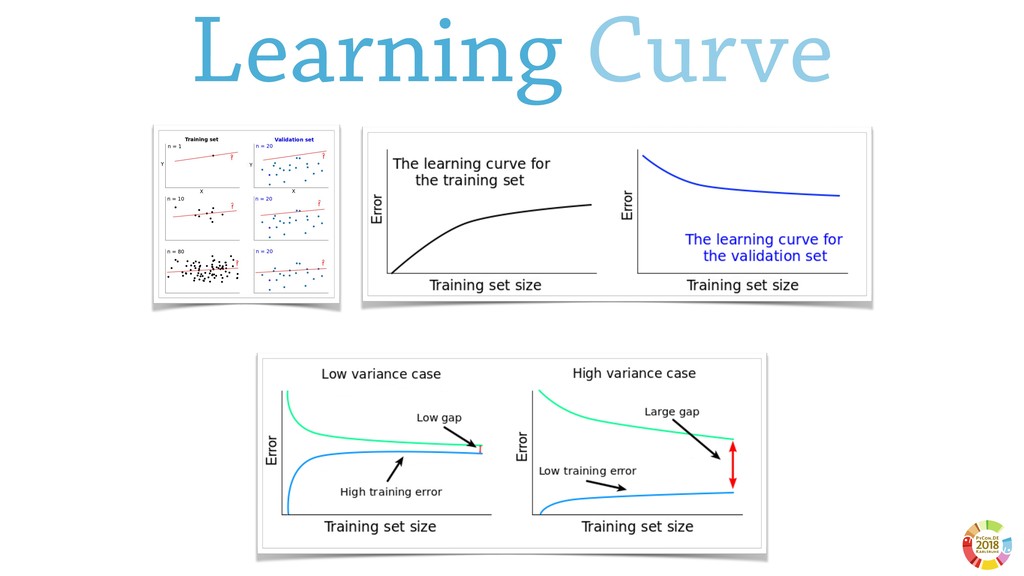
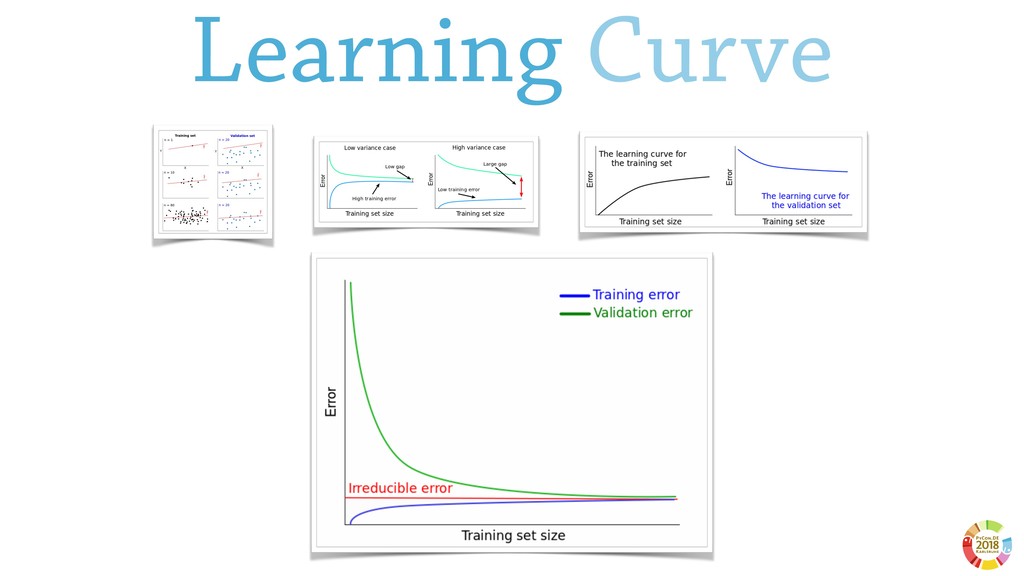
Surprisingly, these two aspects are often underestimated or not even considered when setting up scientific experimental pipelines. In this, one of the main threat to replicability is the selection bias, that is the error in choosing the individuals or groups to take part in a study. Selection bias may come in different flavours: the selection of the population of samples in the dataset (sample bias); the selection of features used by the learning models, particularly sensible in case of high dimensionality; the selection of hyper parameter best performing on specific dataset(s). If not properly considered, the selection bias may strongly affect the validity of derived conclusions, as well as the reliability of the learning model.
In this talk I will provide a solid introduction to the topics of reproducibility and selection bias, with examples taken from the biomedical research, in which reliability is paramount.
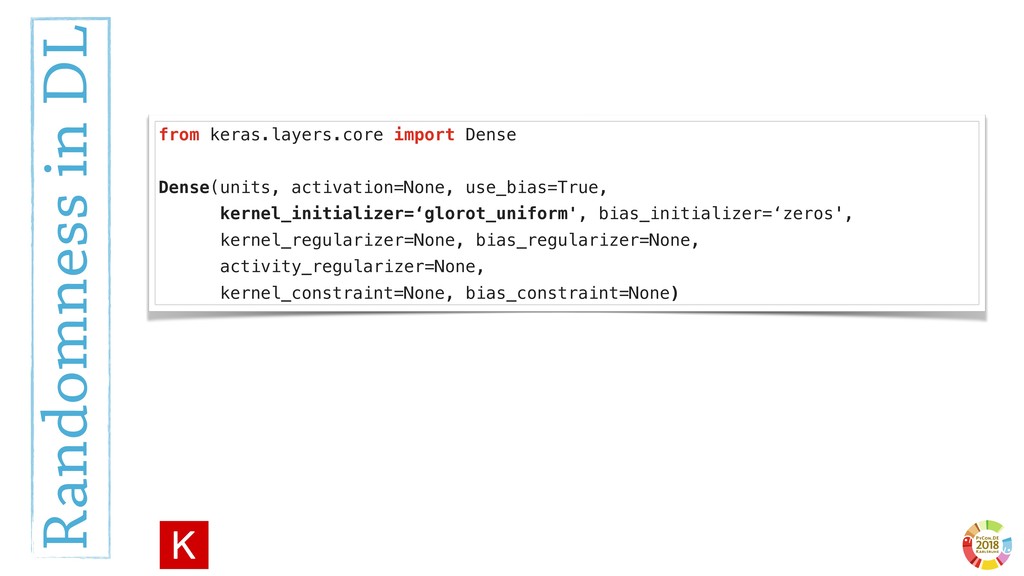
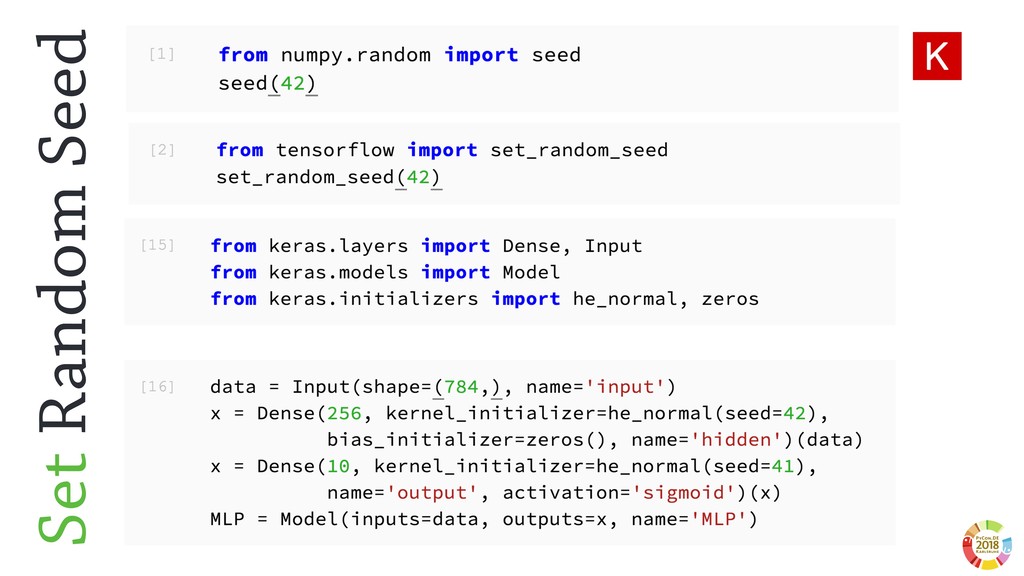
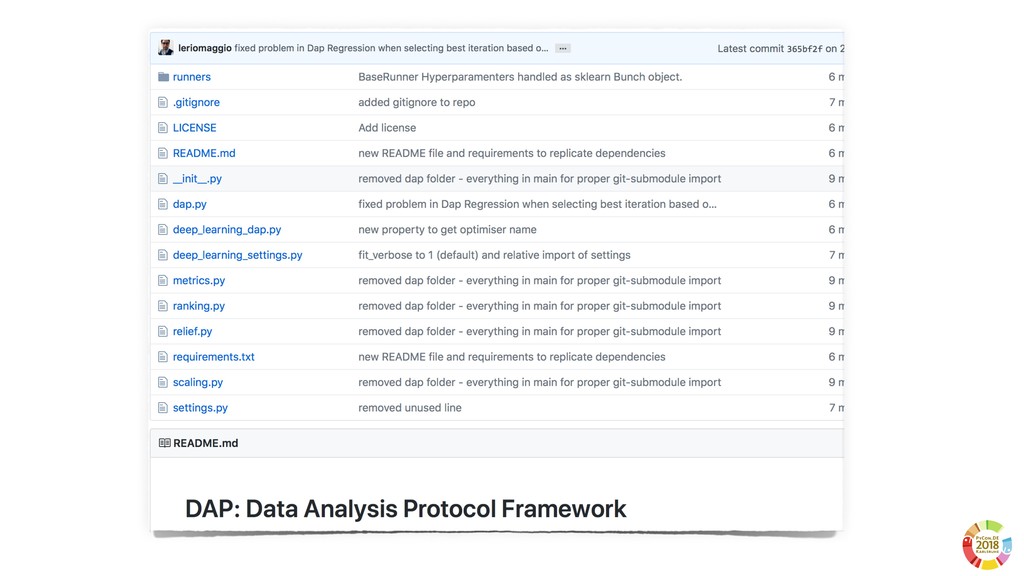
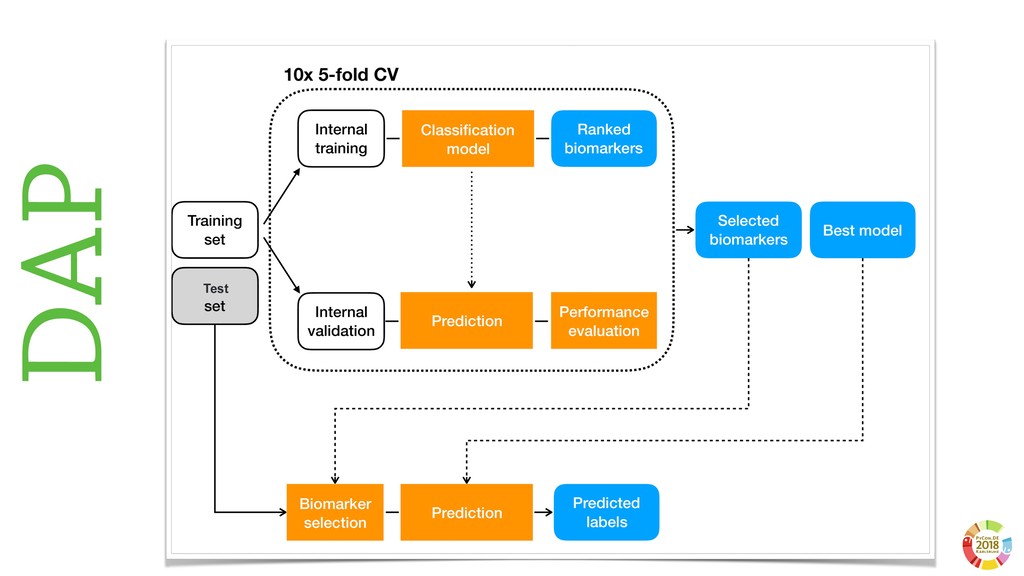
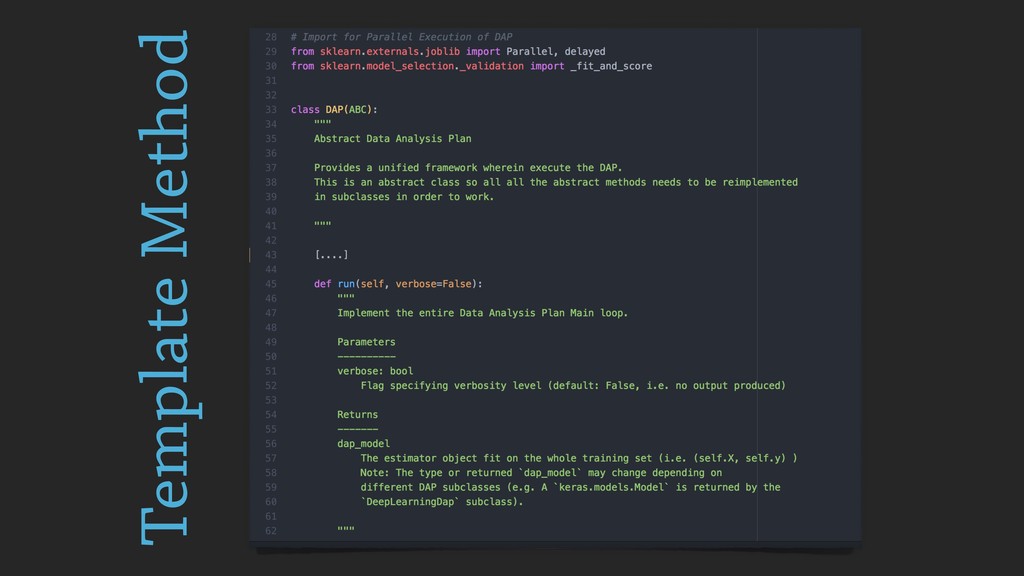
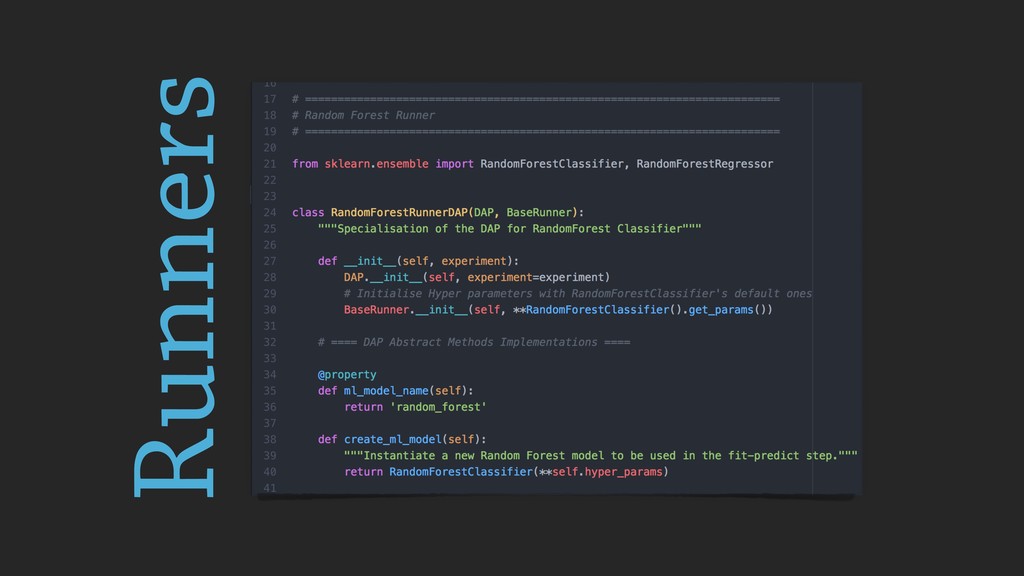
From a more technological perspective, to date the scientific Python ecosystem still misses tools to consolidate the experimental pipelines in in research, that can be used together with Machine and Deep learning frameworks (e.g. `sklearn` and `keras`).
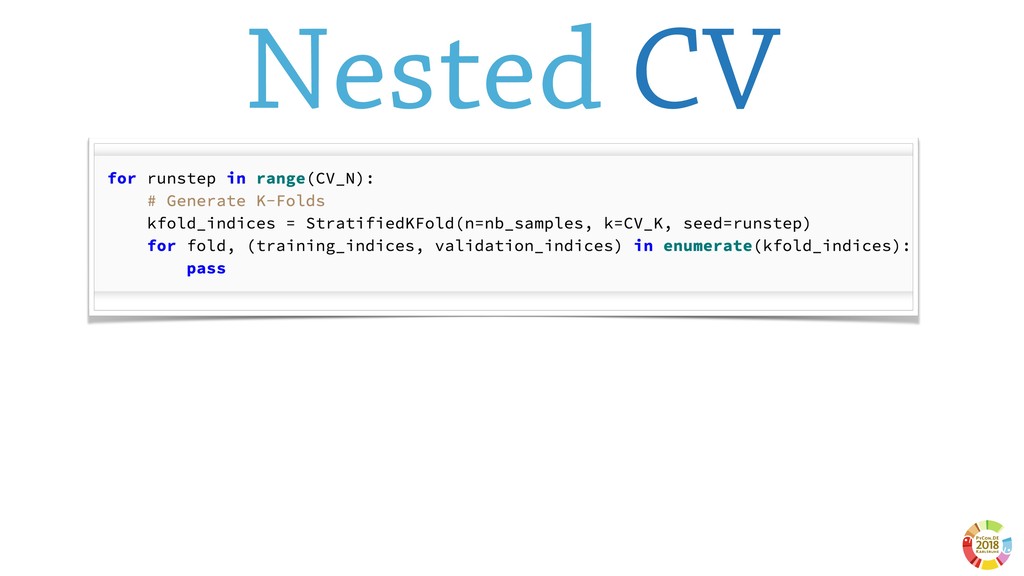
In this talk, I will introduce `reproducible-lern`, a new Python frameworks for reproducible research to be used for machine and deep learning.
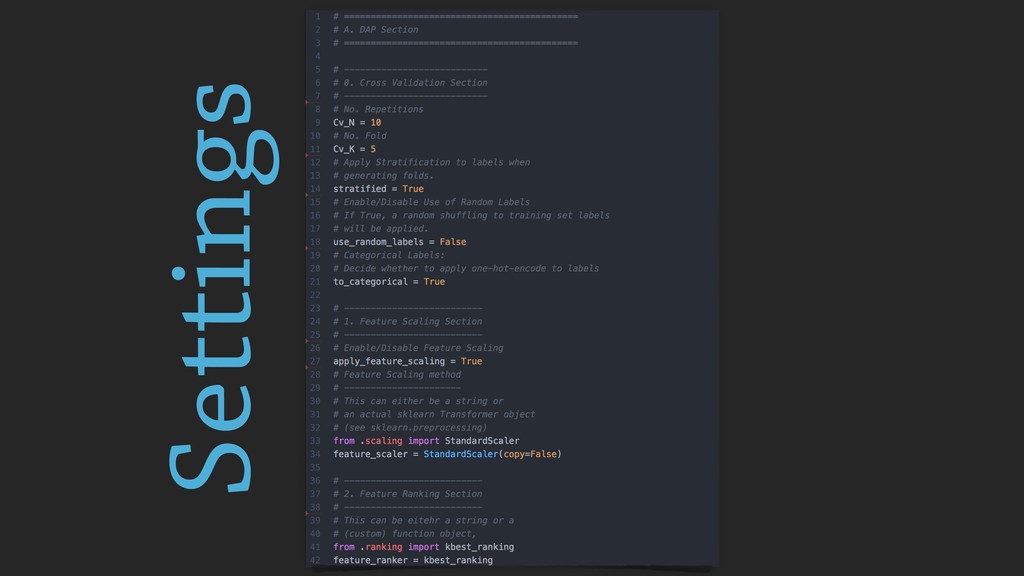
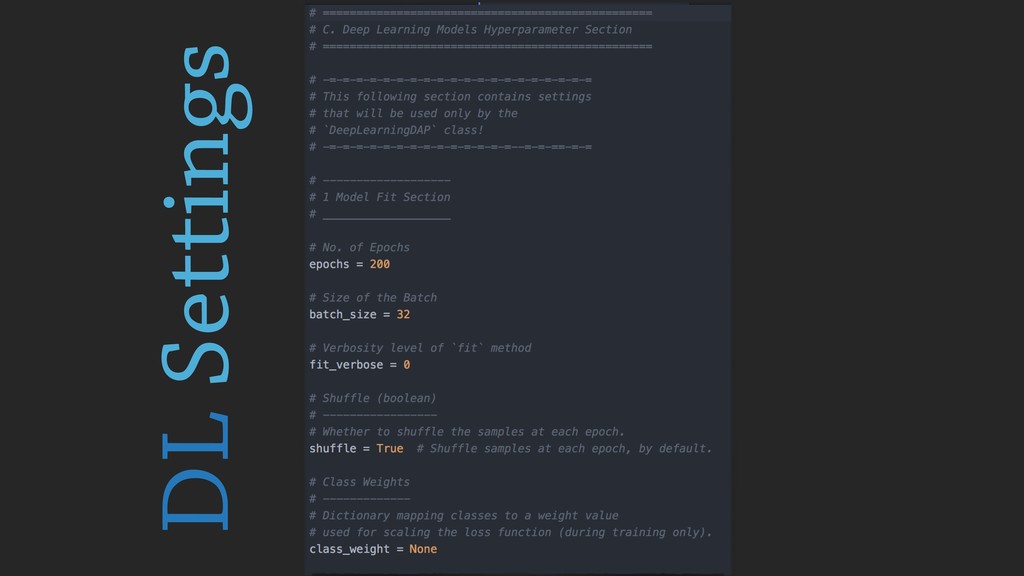
During the talk, the main features of the framework will be presented, along with several examples, technical insights and implementation choices to be discussed with the audience.
The talk is intended for intermediate PyData researchers and practitioners. Basic prior knowledge of the main Machine Learning concepts is assumed for the first part of the talk. On the other hand, good proficiency with the Python language and with scientific python libraries (e.g. numpy, sklearn) are required for the second part.
---
1 Reproducible research can still be wrong: Adopting a prevention approach by Jeffrey T. Leek, and Roger D. Peng
2 Dictionary of Cancer Terms -> "selection bias"
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}