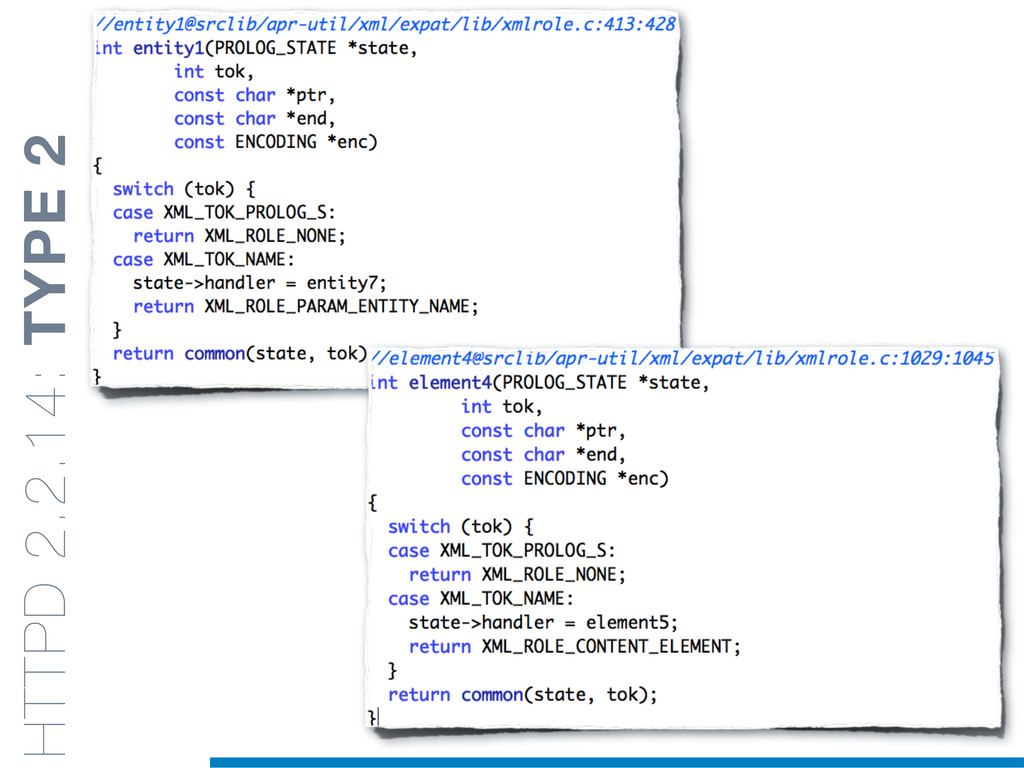
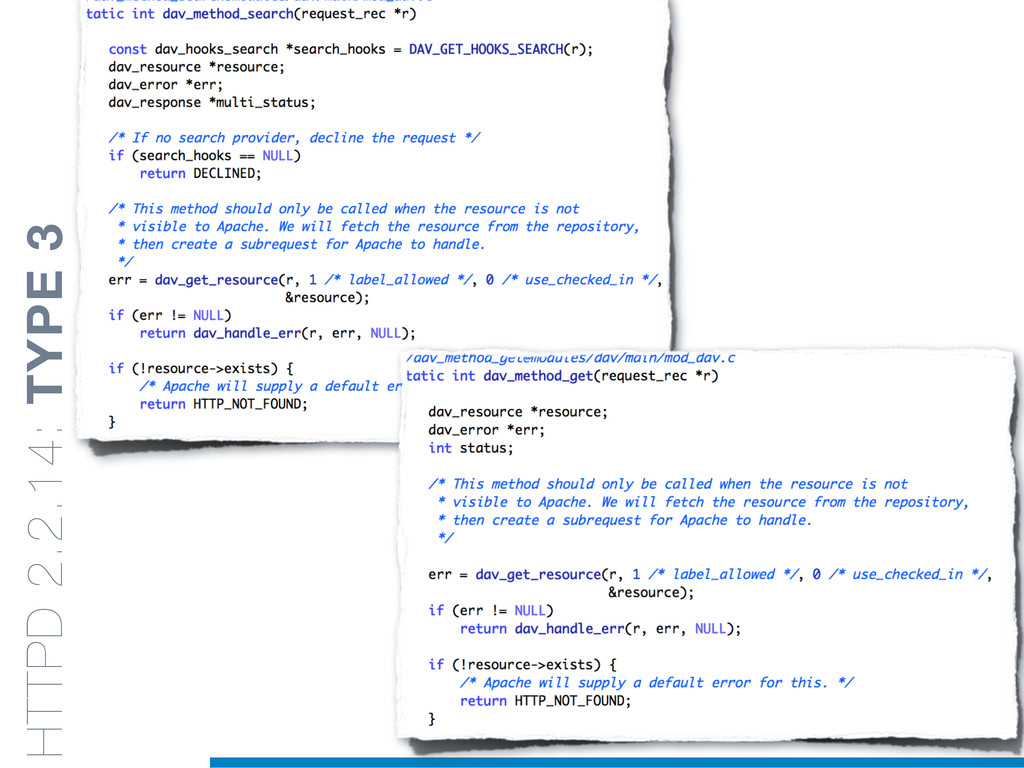
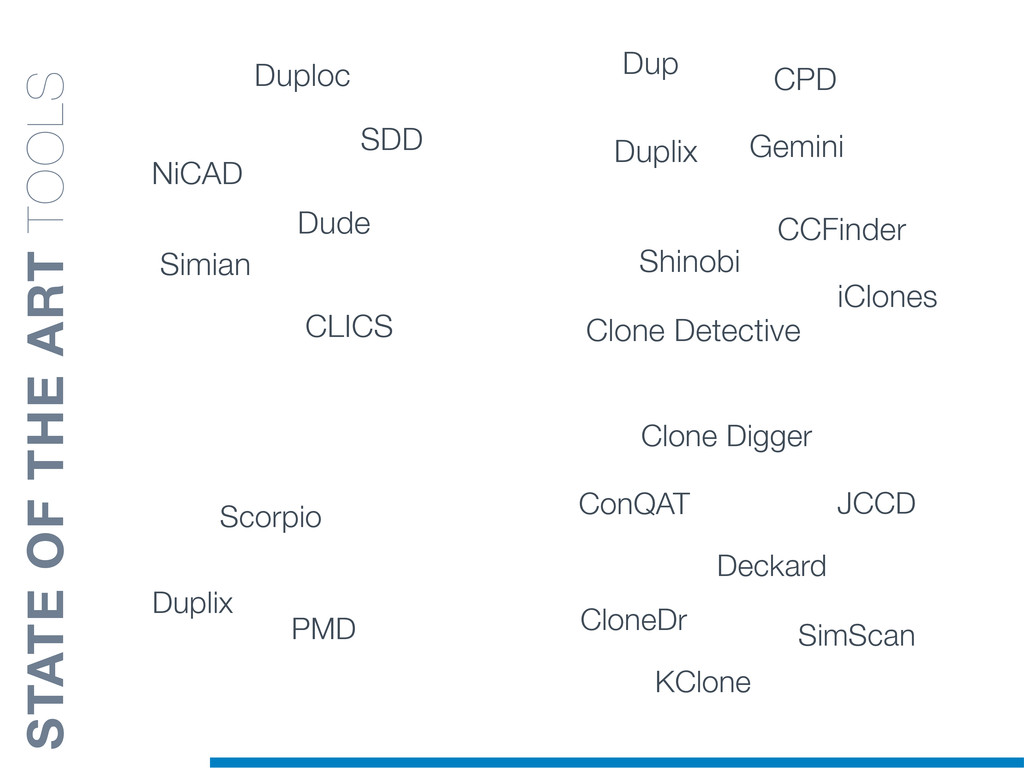
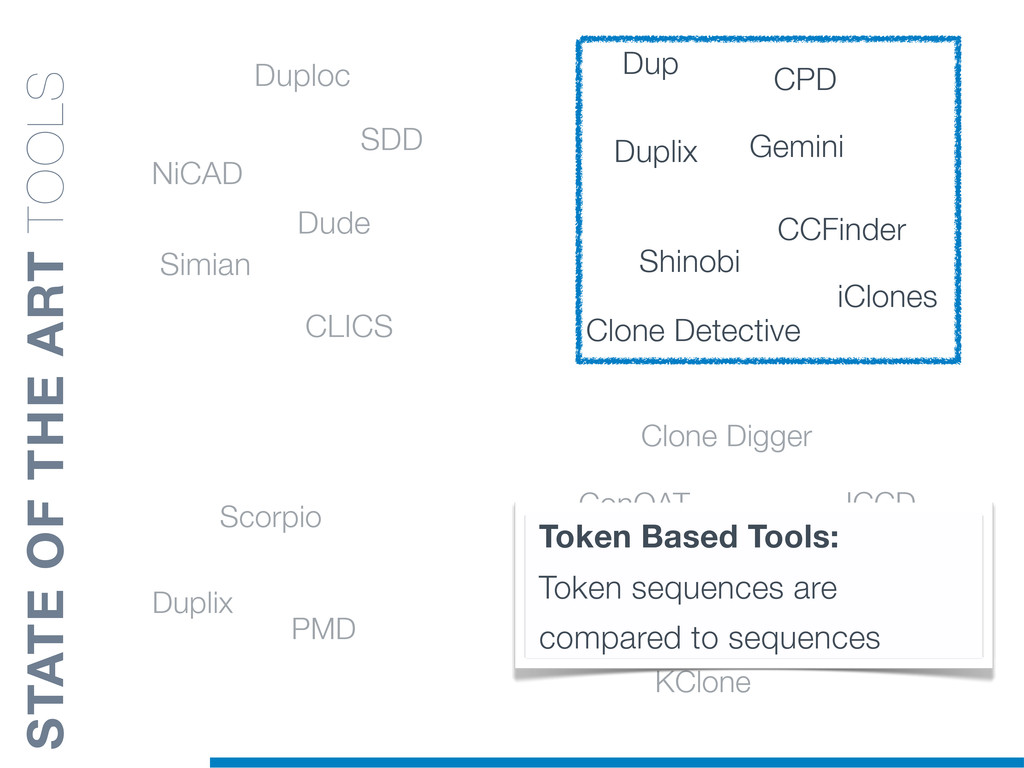
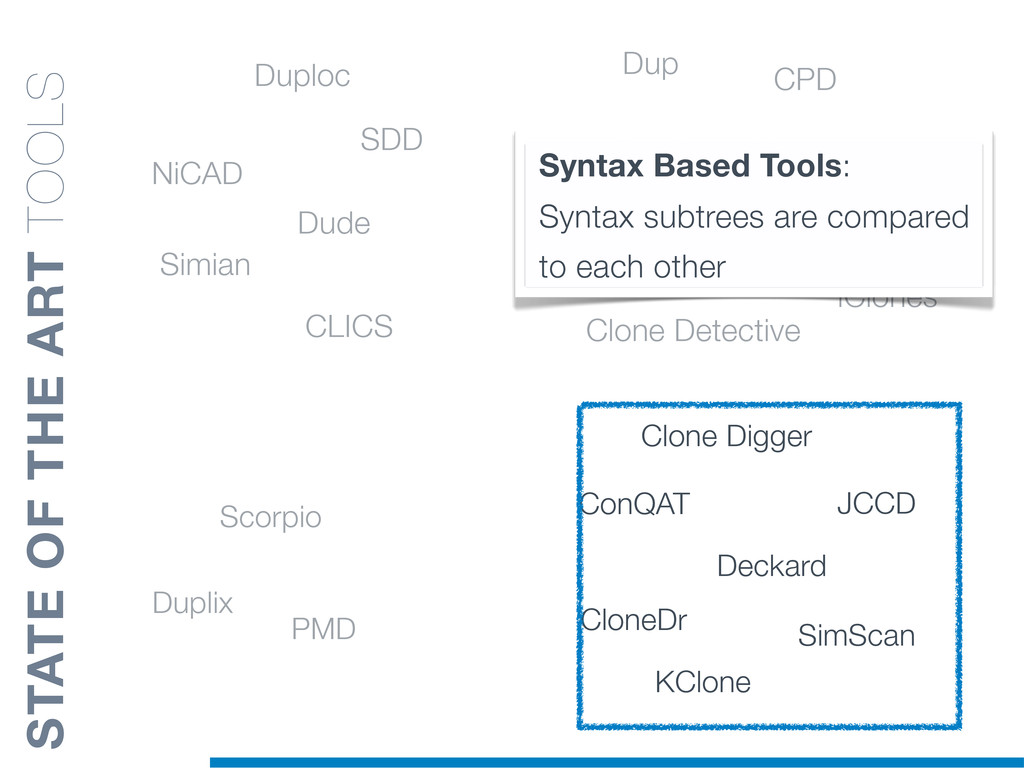
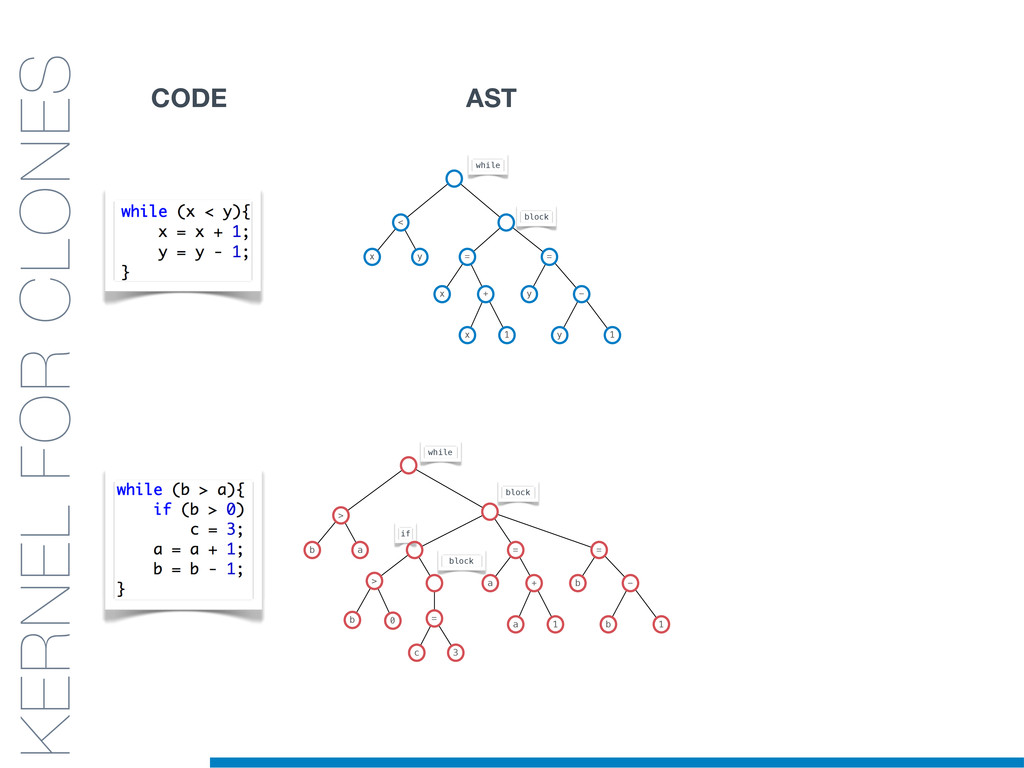
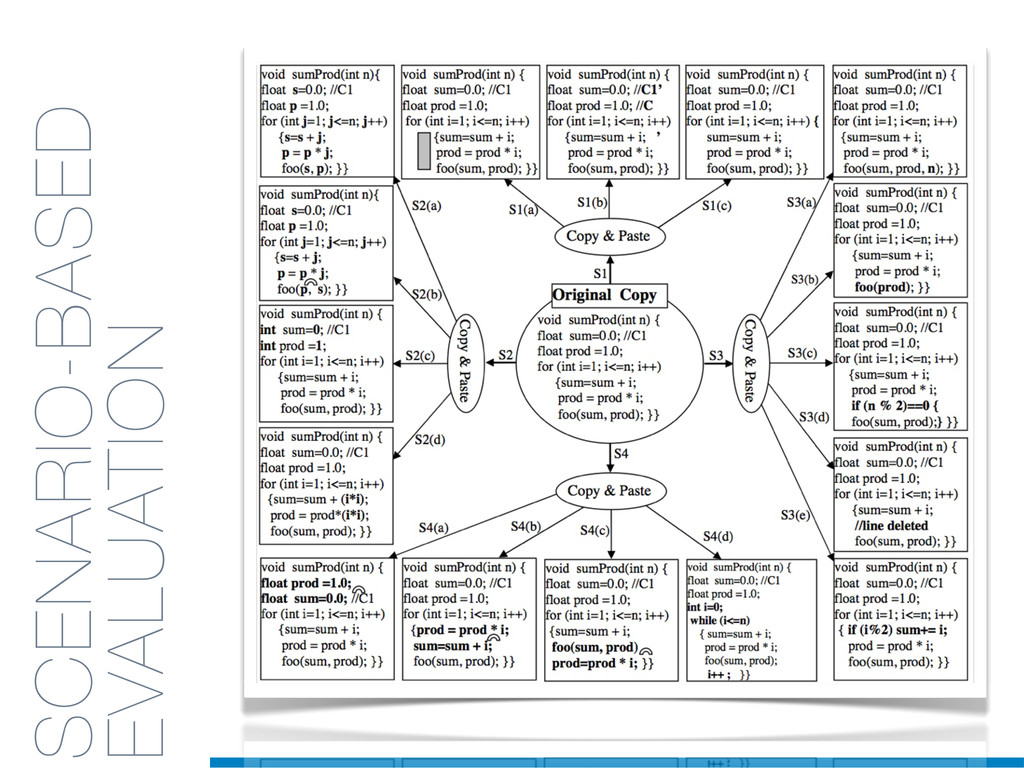
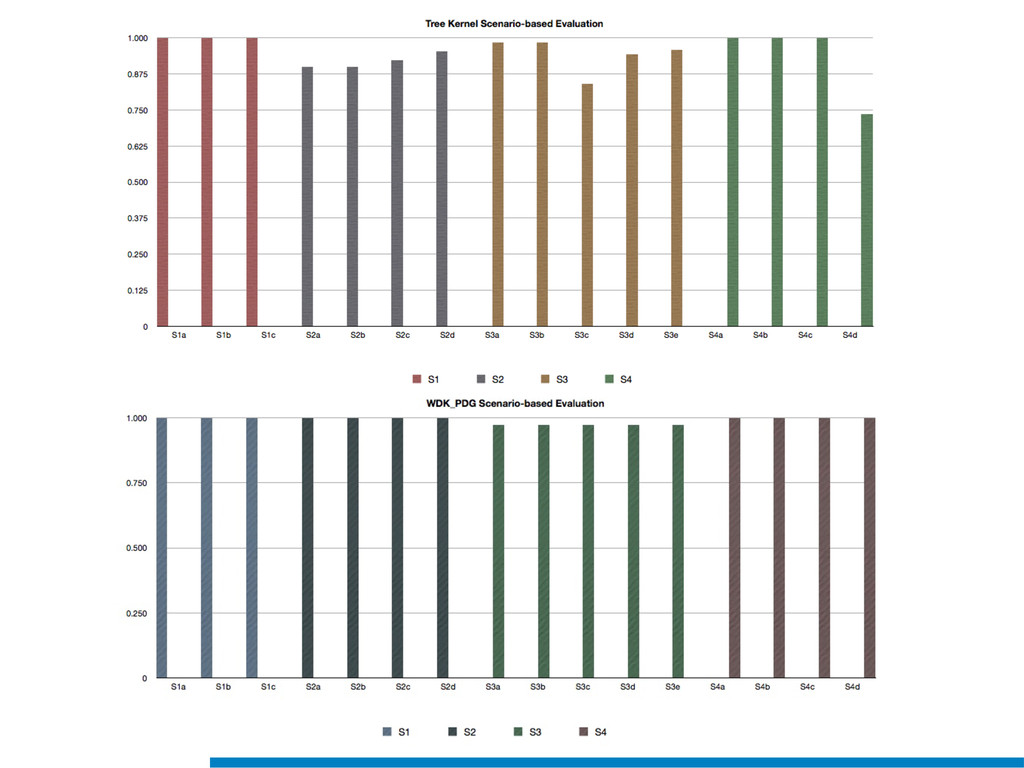
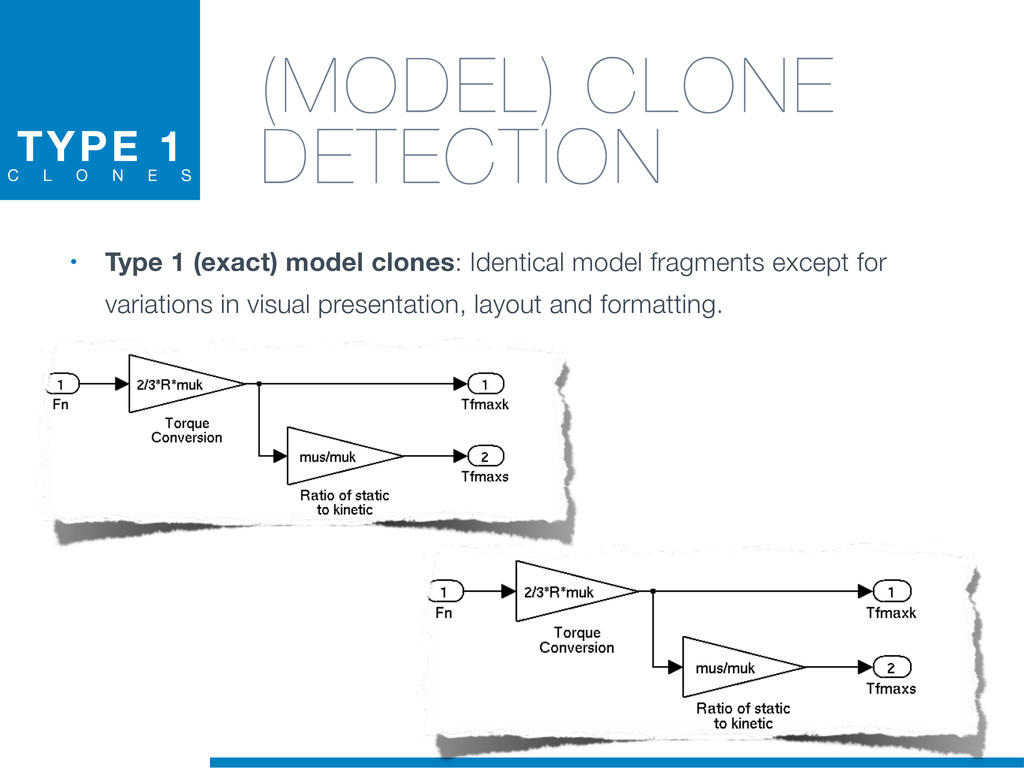
Duplicated source code is a phenomenon that frequently occurs in large software systems. Reasons why programmers duplicate code are manifold. The most well-known is a common bad programming practice, the copy and paste, that gives rise to software clones, or simply clones. Software clones may affect the reliability and the maintainability of software systems. For example, errors affecting a fragment of code must be fixed in everyone of its duplications.
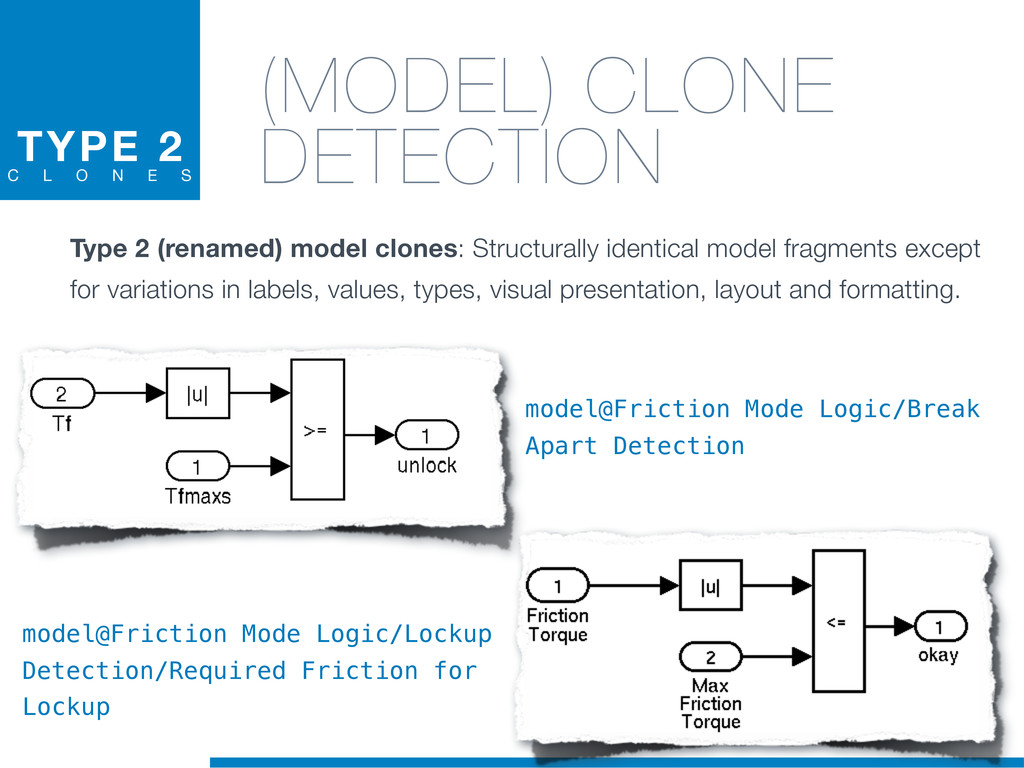
Clones are usually not documented, and their identification is usually complicated since programmers adapt software copies by applying multiple modifications (e.g., adding/removing statements, renaming variables). Therefore, automatic approaches are required in order to reliably tackle this problem.
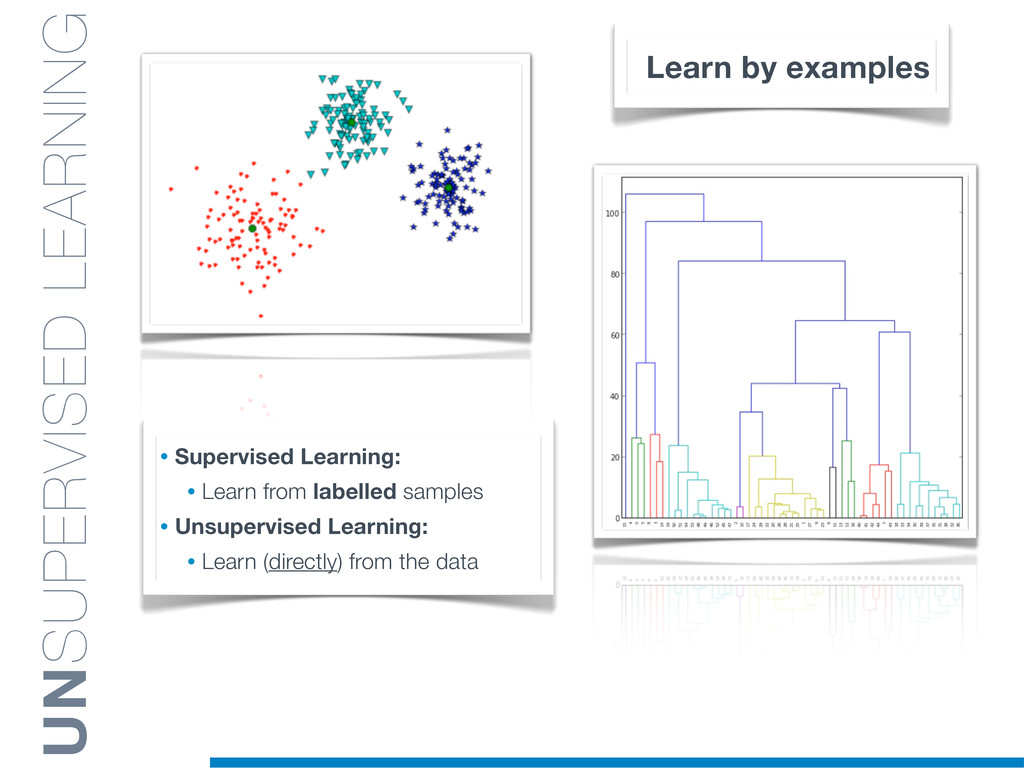
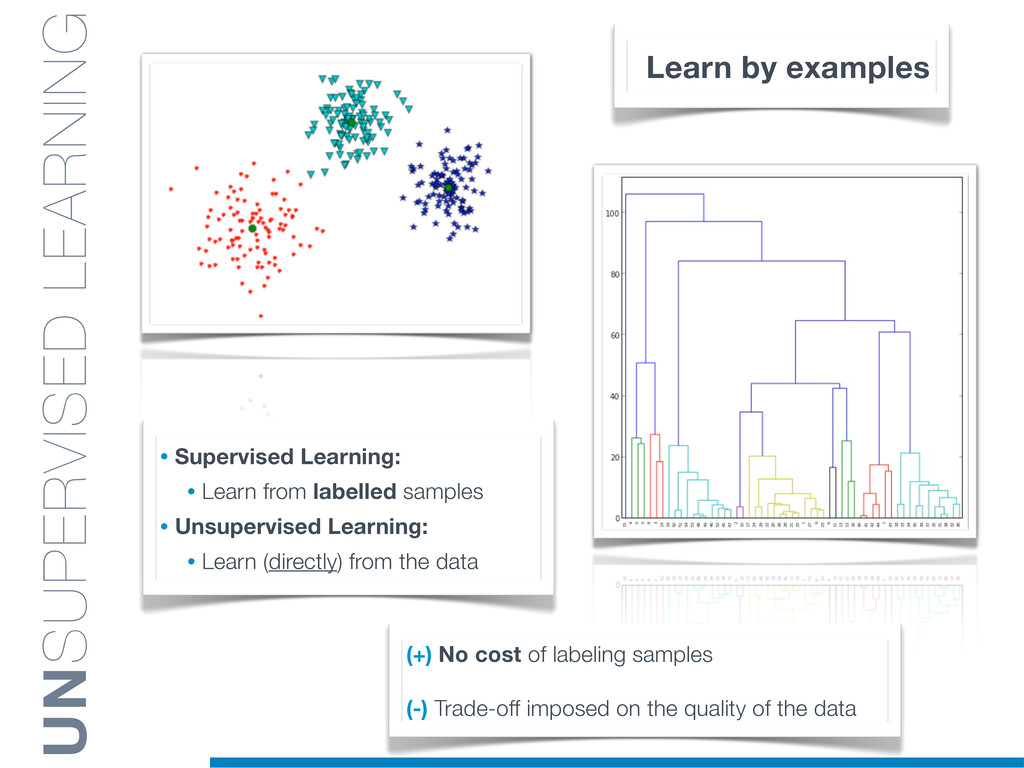
Machine Learning (ML) algorithms have proven to be of great practical value in a variety of application domains, providing flexible solutions able to analyse large data set with an affordable computational efficiency.
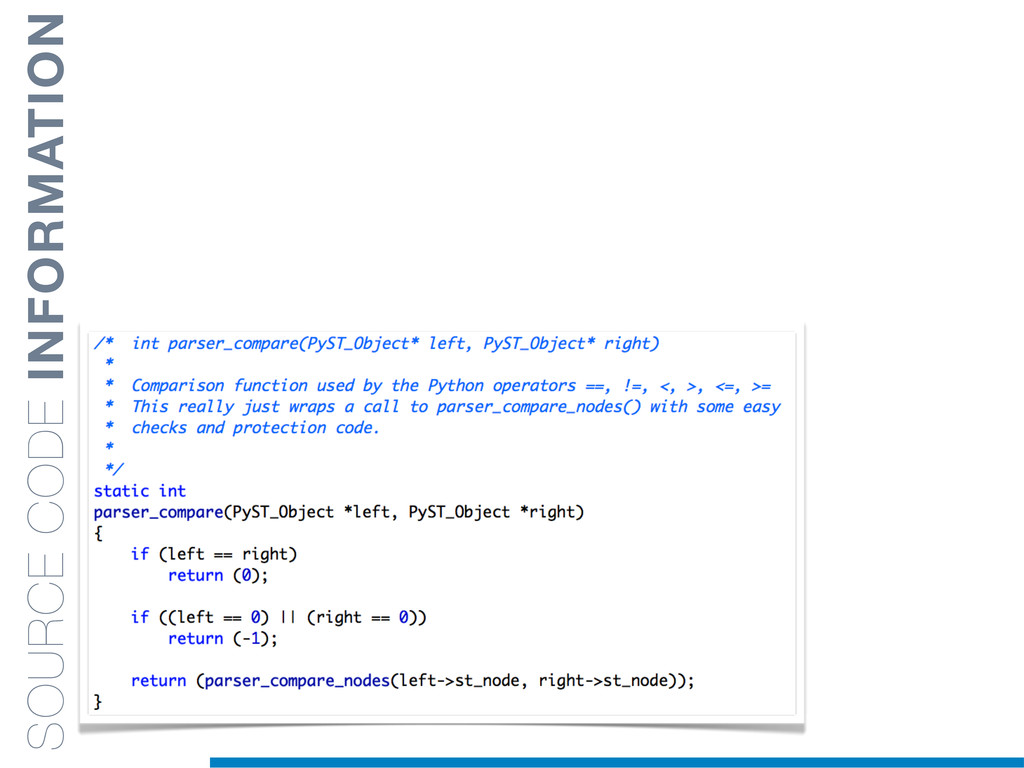
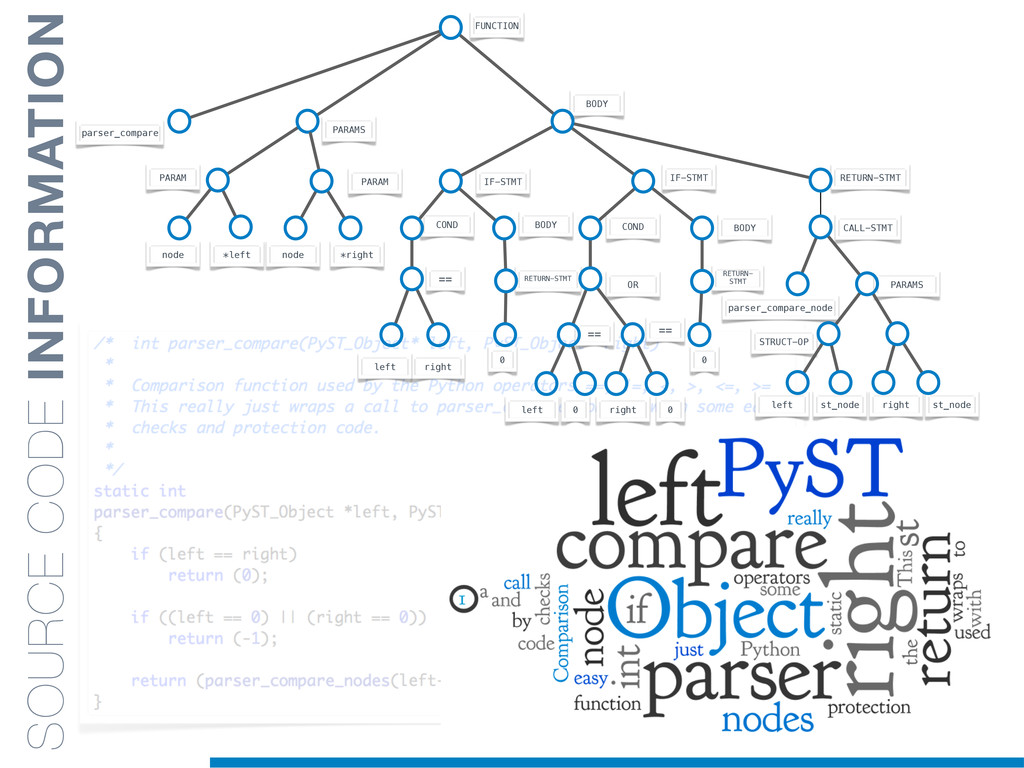
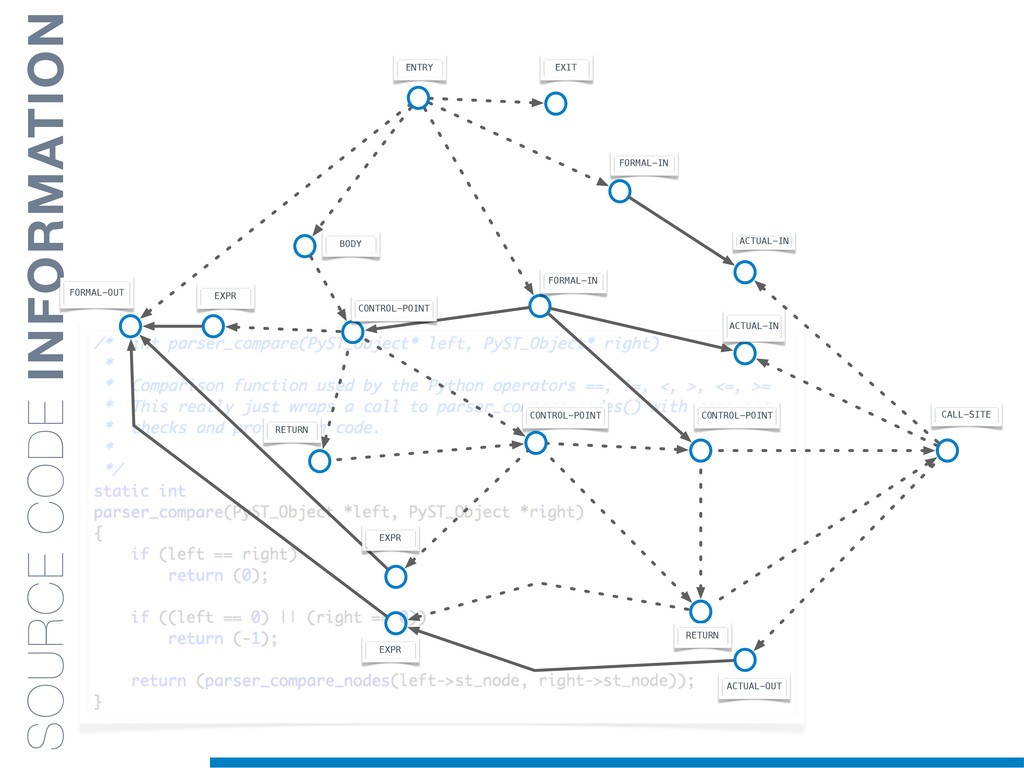
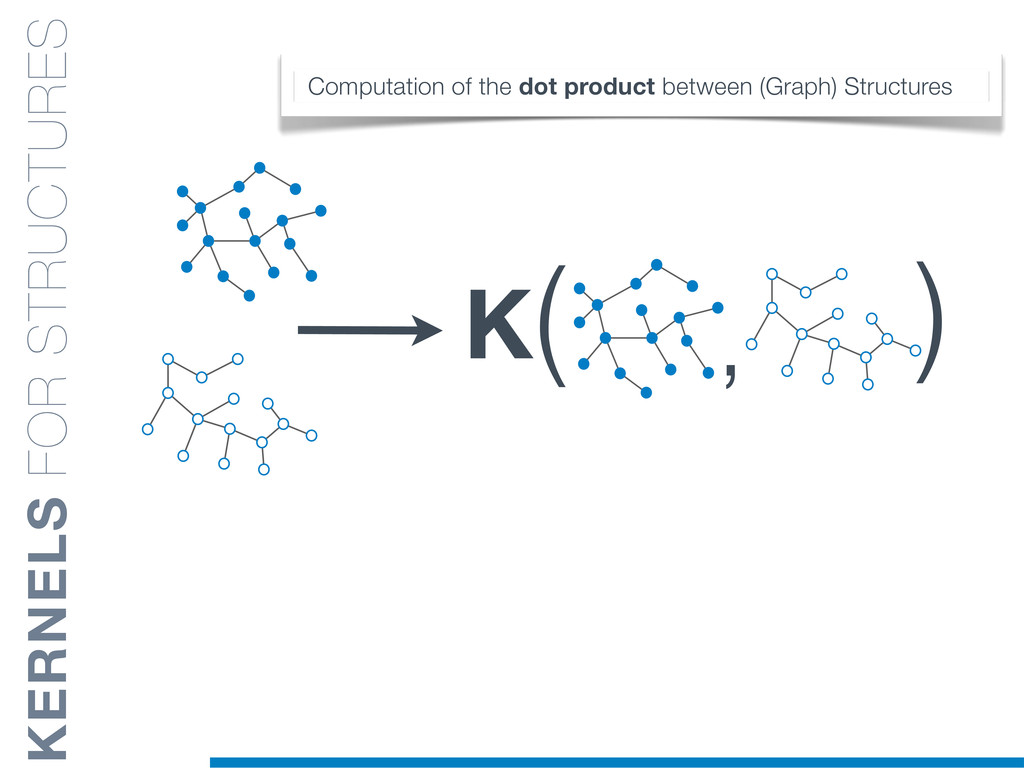
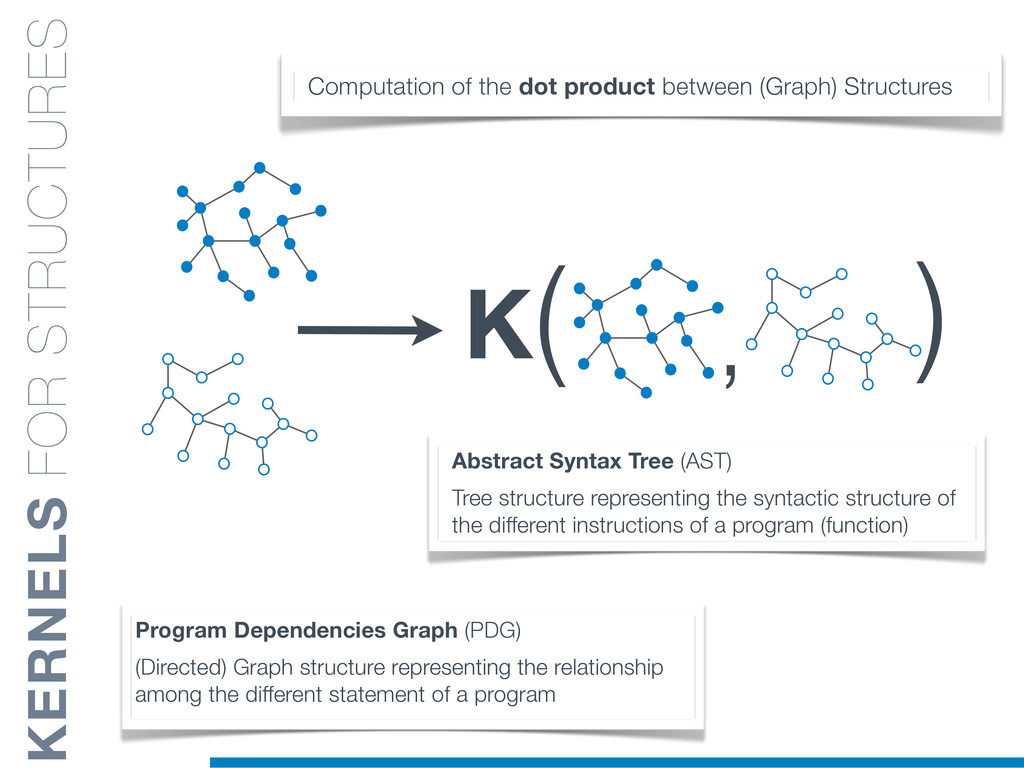
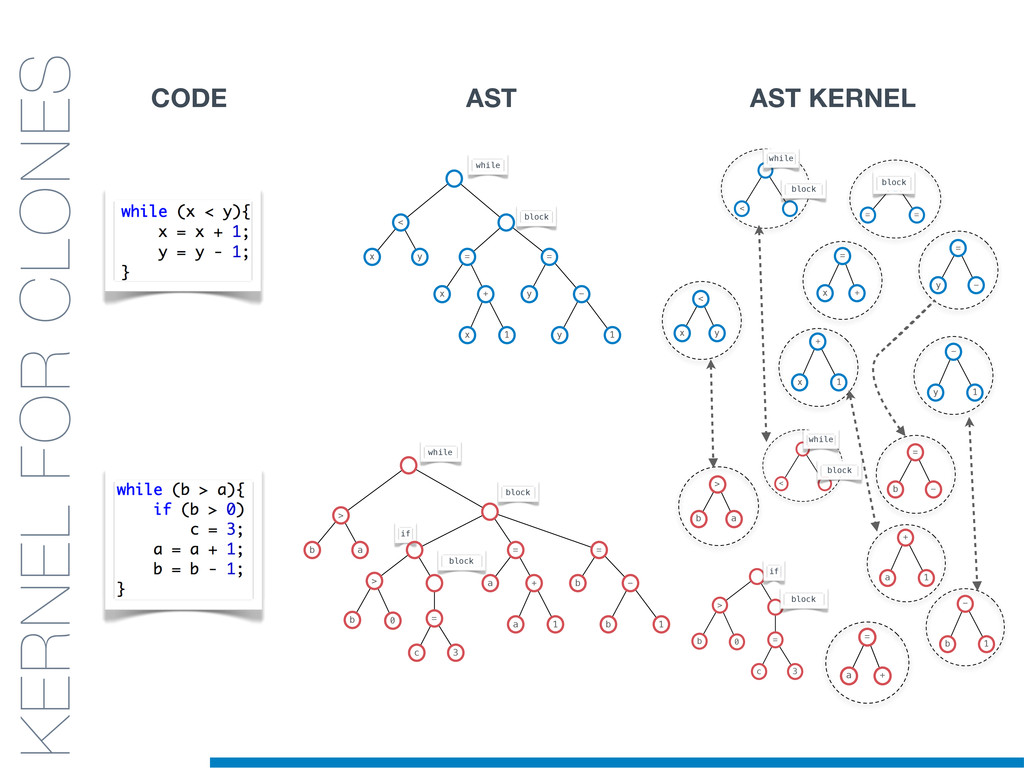
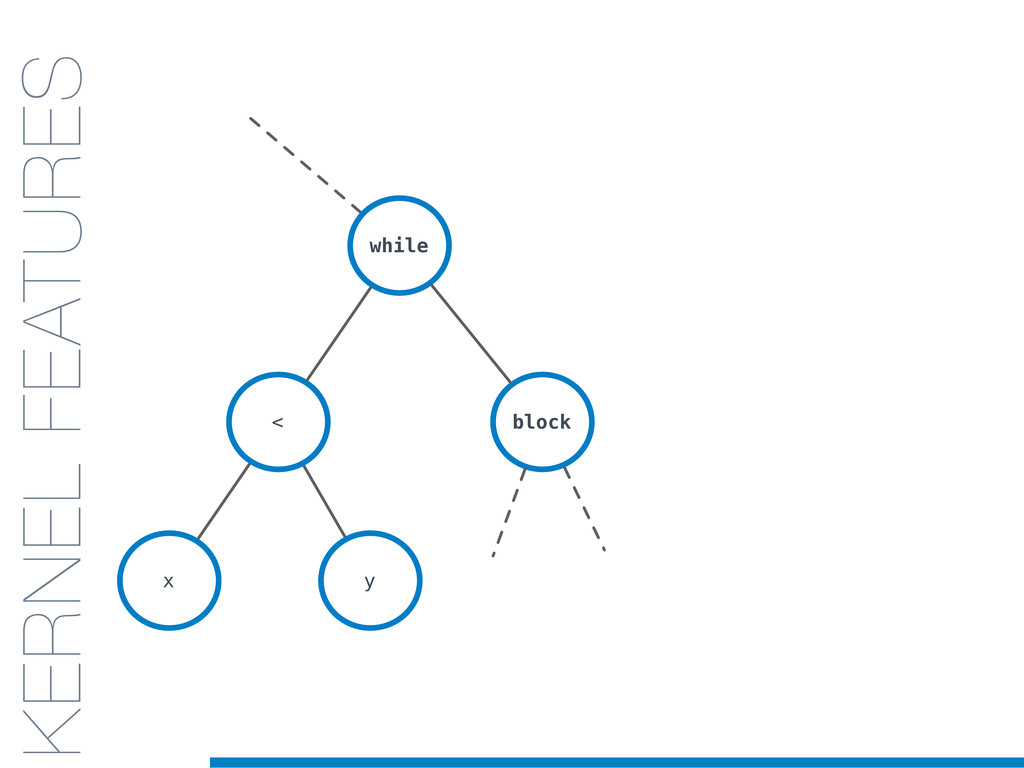
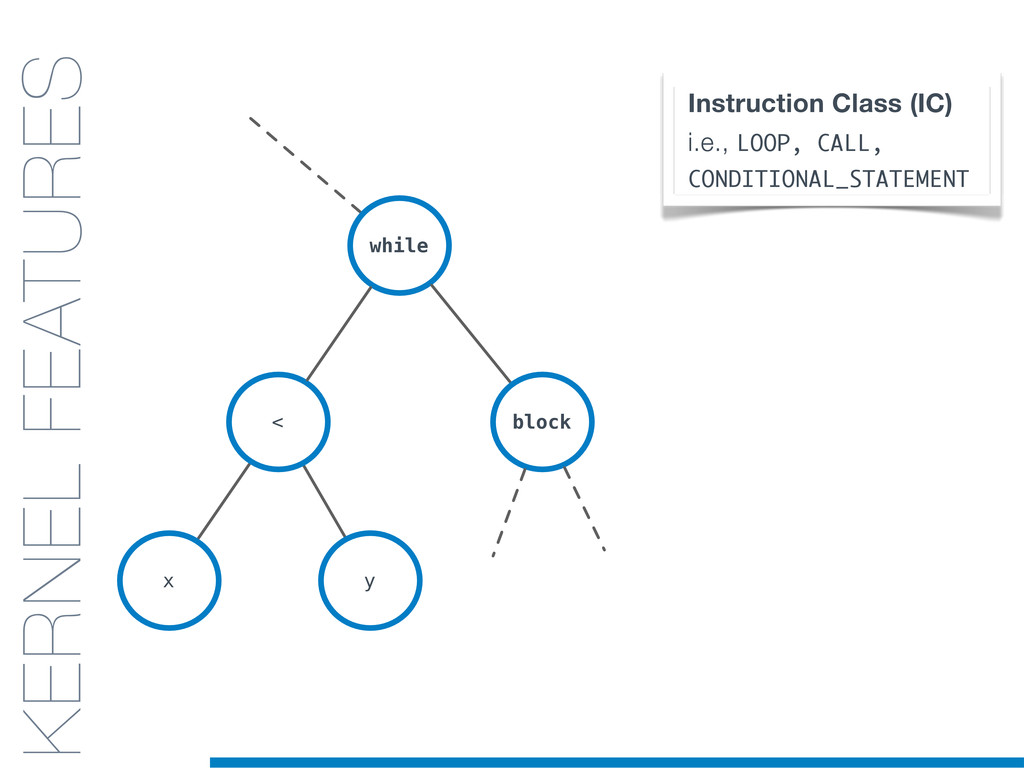
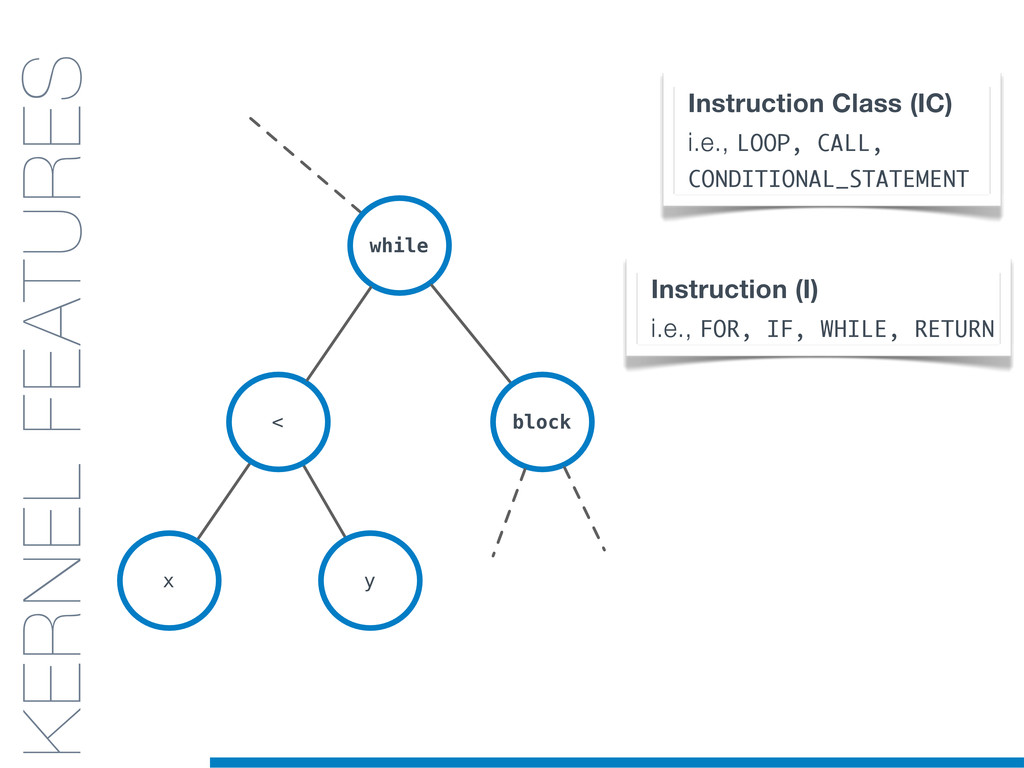
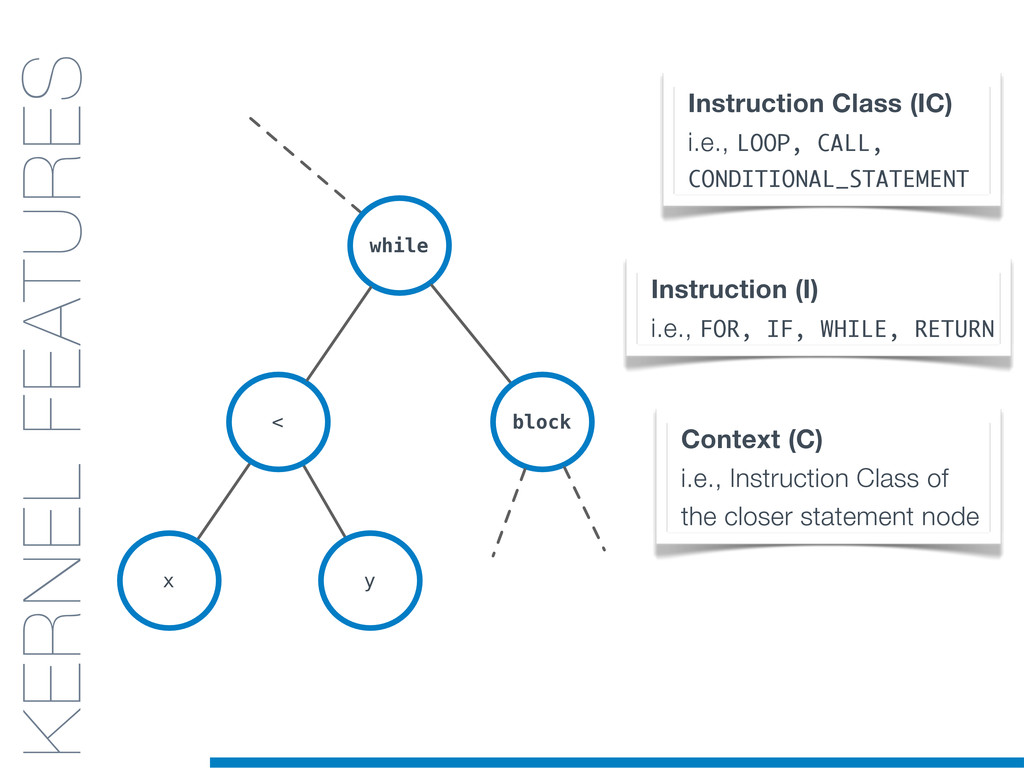
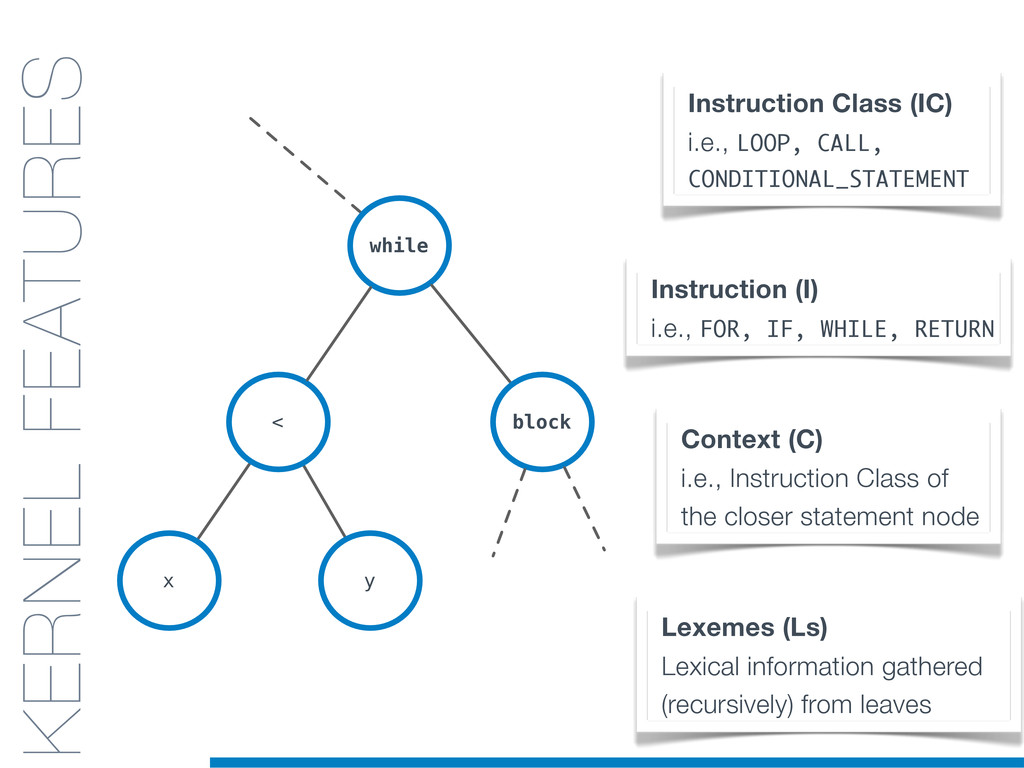
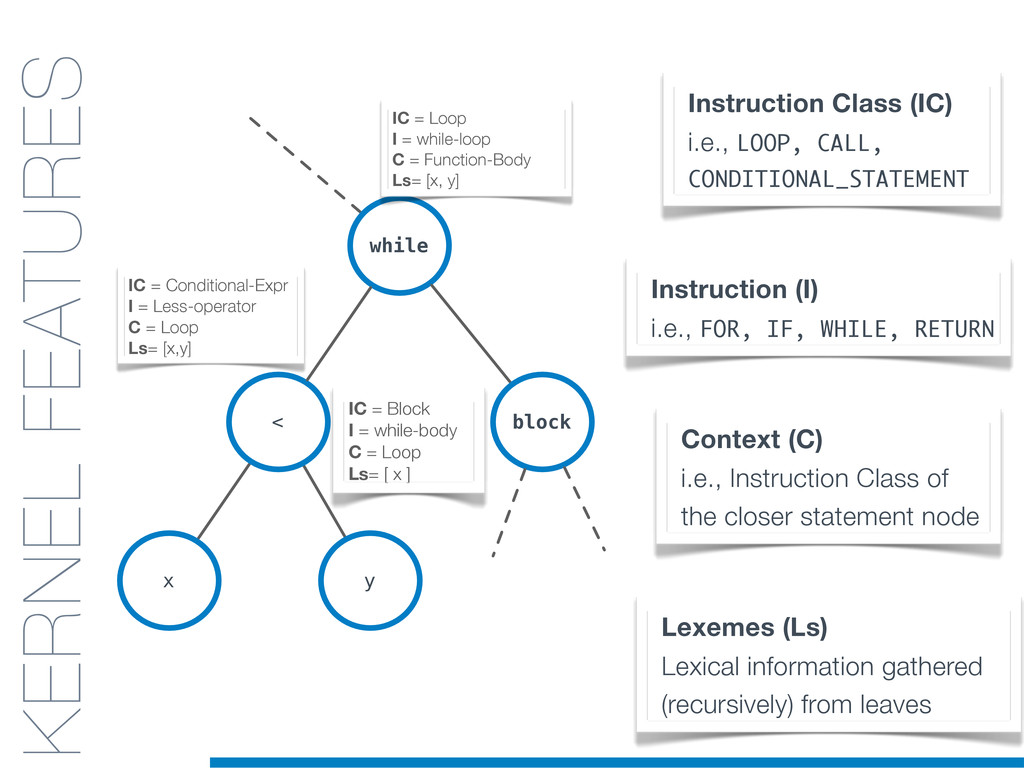
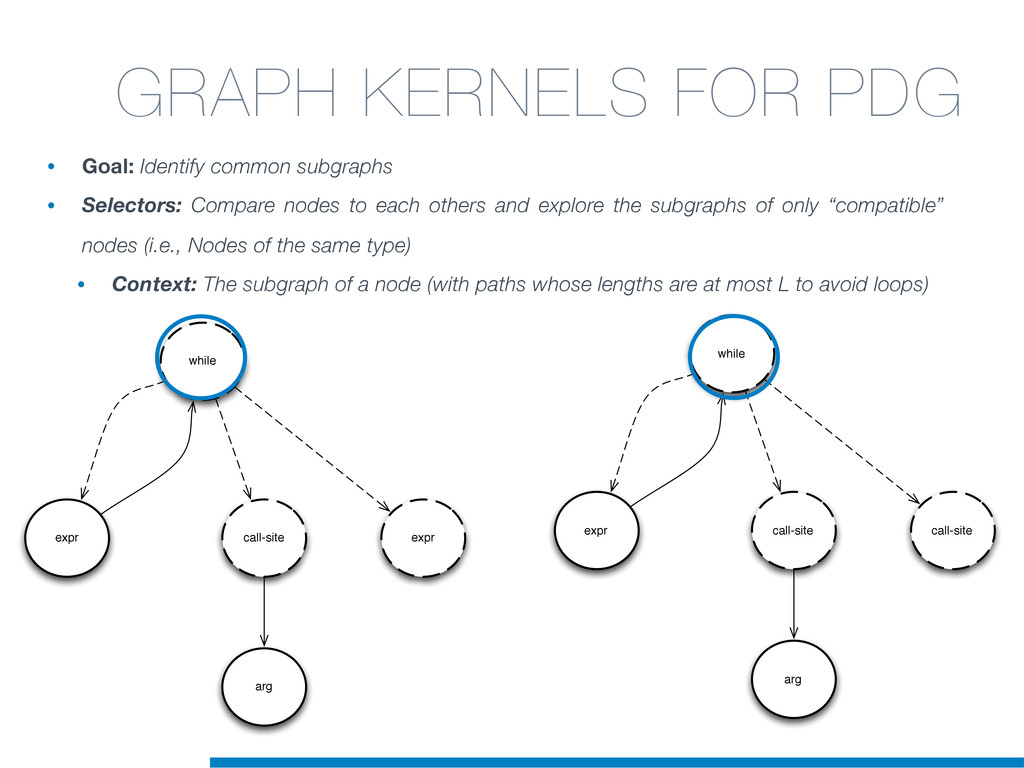
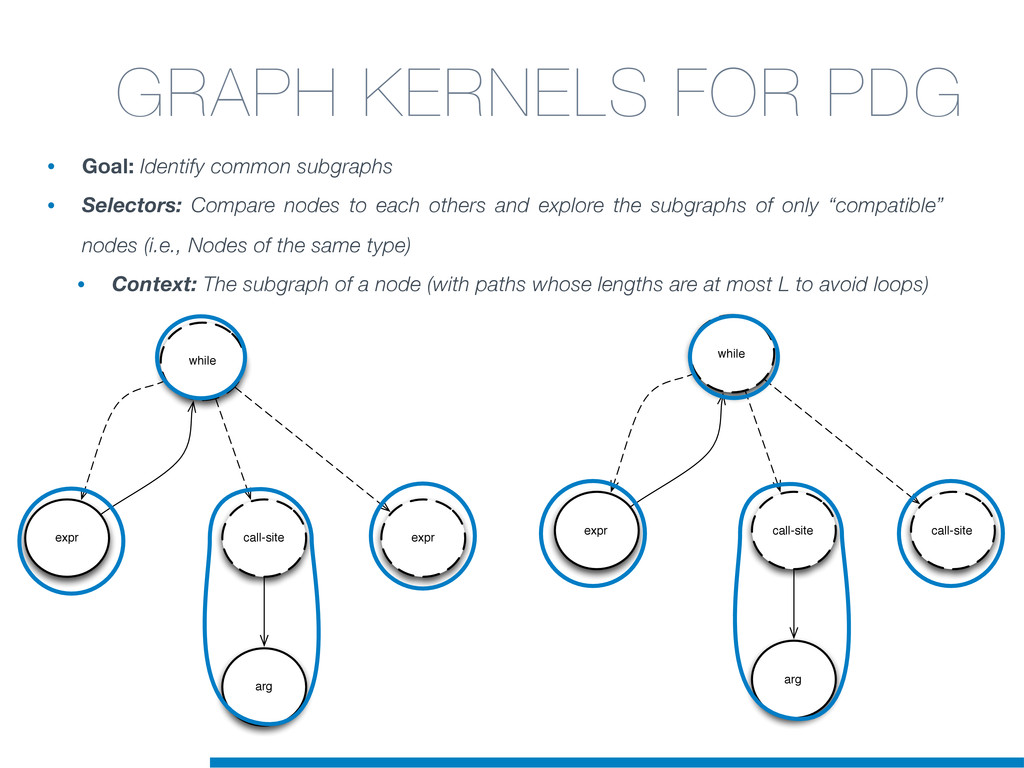
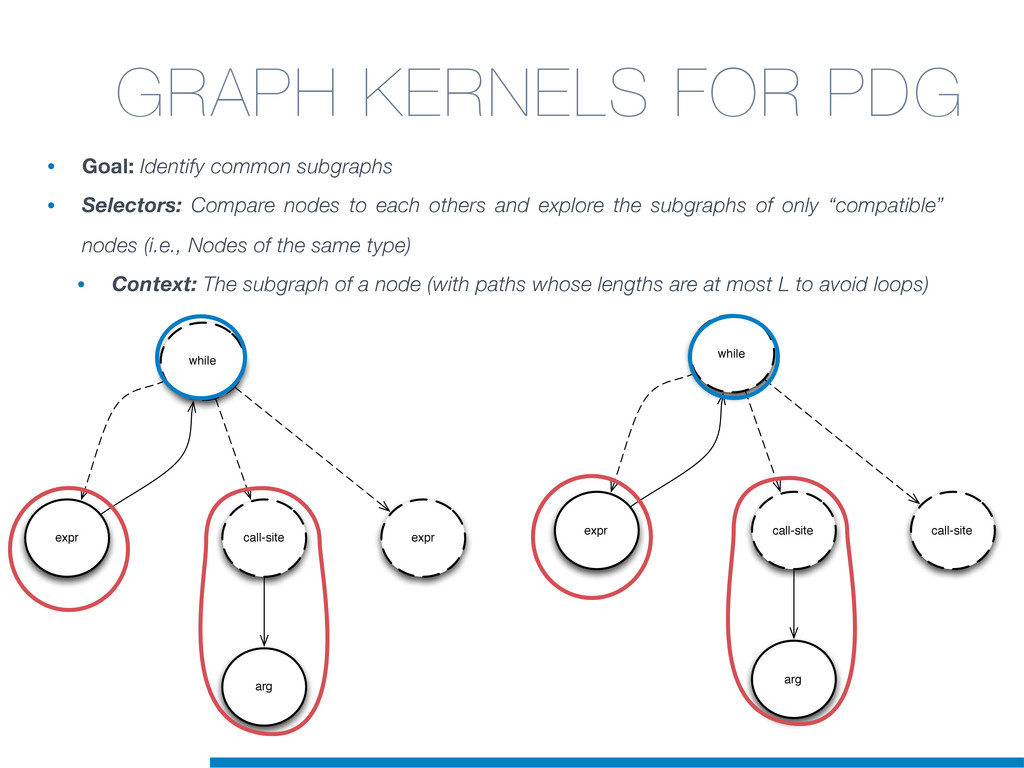
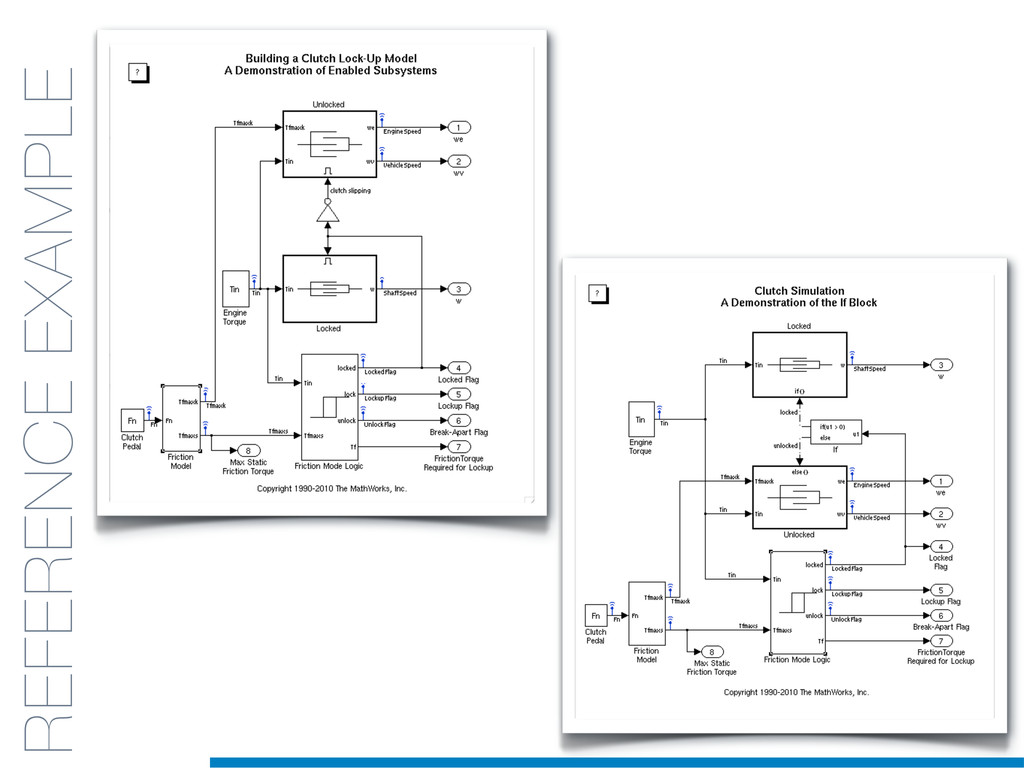
In this talk an approach that exploits structural (e.g., AST) and lexical information in the code (e.g., name of methods, variables) for the identification of clones will be presented. In particular, the proposed contribution leverages the benefits of ML algorithms, which have been properly tailored and customised in order to make them suitable for the considered task/domain.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}