• For business requirements – Delivery status, order status for food delivery – Fraud detection in financial transaction • For better performance – Contents recommendation
Input and output are Kafka topics – (Kafka is widely used for streams in LINE) • Build stream processing systems easily – Let data engineers build their systems by themselves
expertise – Every data engineer knows SQL • Prototyped using various SQL engines – ksqlDB, FlinkSQL, Spark structured streaming – Left join stream-stream – Query a table and write to Kafka topic
User Defined Function (UDF) • Based on Kafka Streams API – Easy to understand • Only for stream processing – No extra parts for batch processing • Everything on Kafka – Good Kafka team in LINE
Right topic p1 p2 Joined topic p1 p1 Join partition1 p2 p2 Join partition2 p1 p2 Left changelog topic Local state store Local state store p1 p2 Right changelog topic
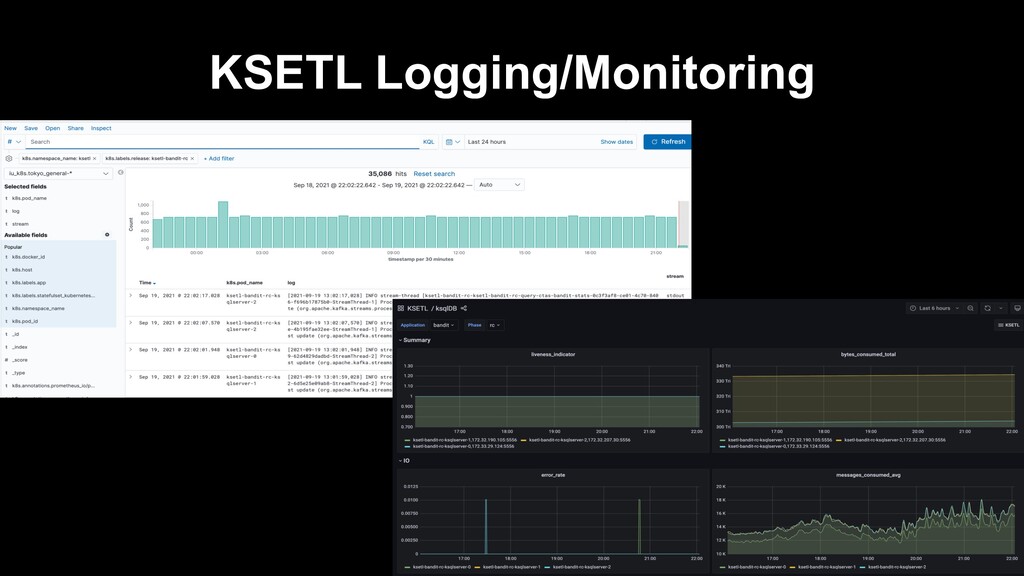
tests before releasing new features – Request logs from LINE server • 50k / sec logs at peak time – Event(impression, click) logs from LINE client – Find client reaction for request and aggregate – Stream join and windowed aggregation required
– Event log and request log with the same key – Store event(impression,click) logs to Redis – Delay request logs and lookup Redis to implement join window
• ksqlDB – Some features are missed (Still in active development) – FlinkSQL may be an alternative • Company-wide Kafka – Good support for all Kafka in LINE – But dynamic topic creation is prohibited
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}