Shun Takagi (Kyoto University)
TsubasaTakahashi (LINECorporation)
Yang Cao (Kyoto University)
Masatoshi Yoshikawa (Kyoto University)
https://arxiv.org/abs/2006.12101
Presentation slide at ICDE 2021 (37th IEEE International Conference on Data Engineering)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
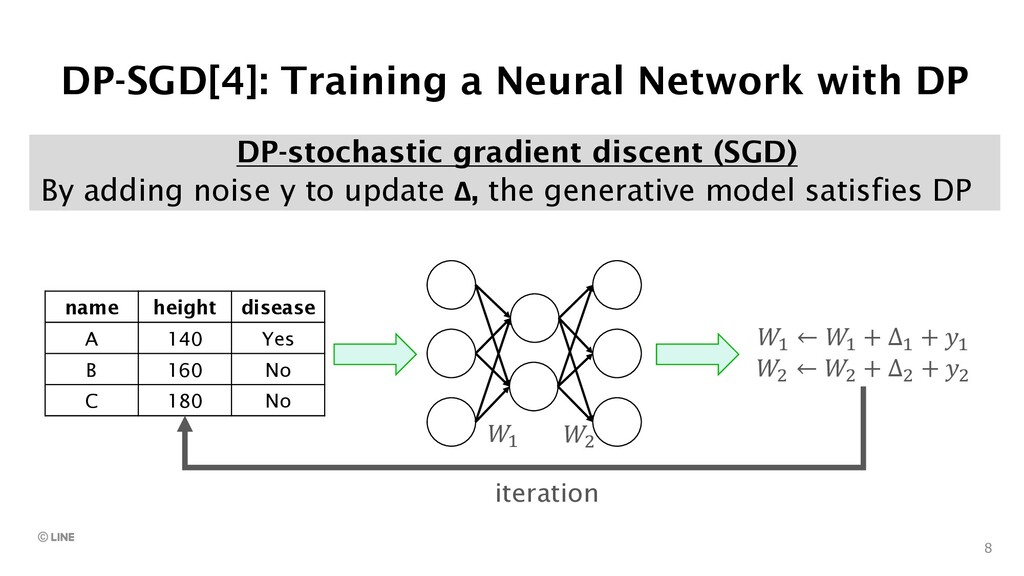{kind=link}
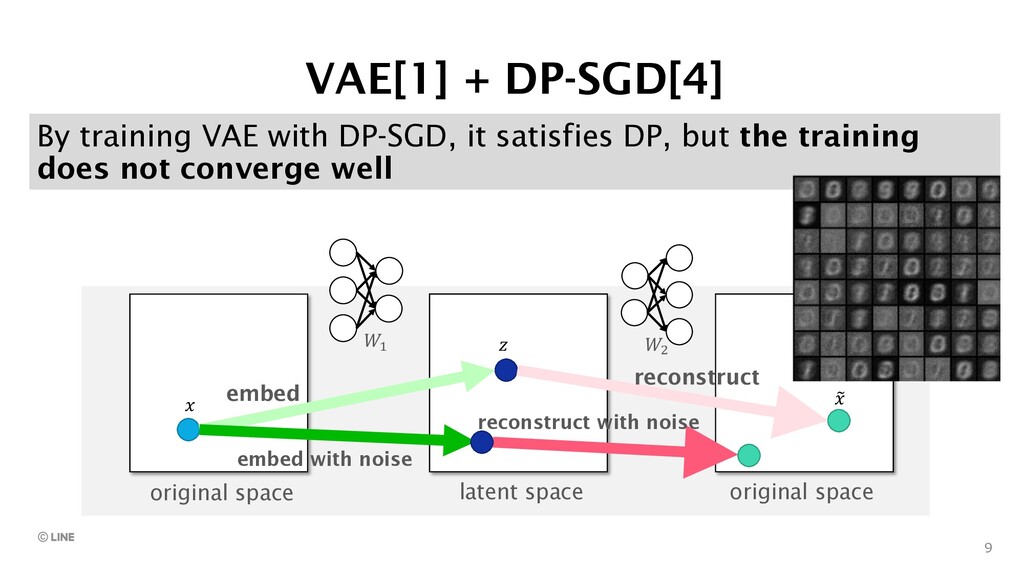{kind=link}
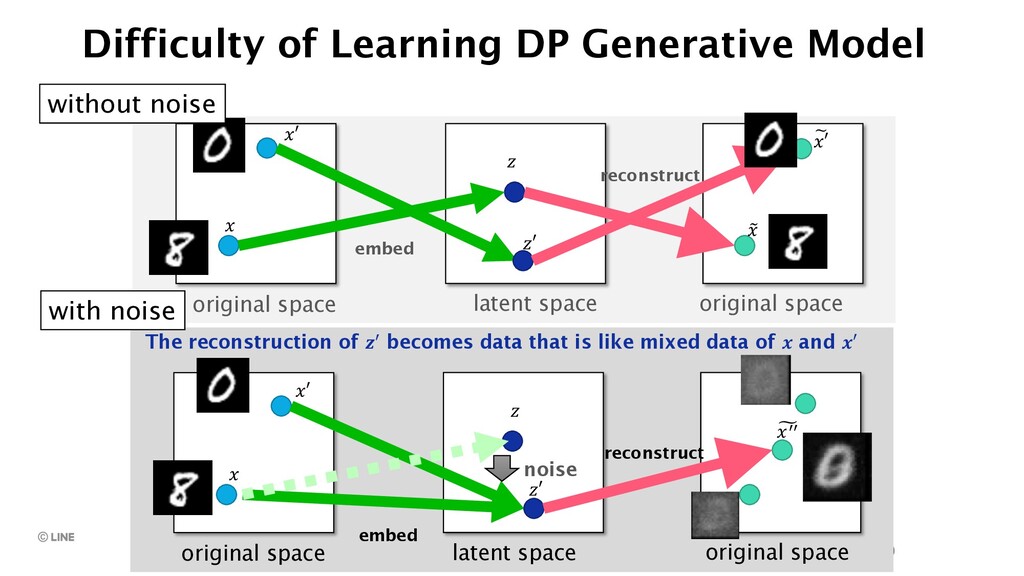{kind=link}
{kind=link}
{kind=link}
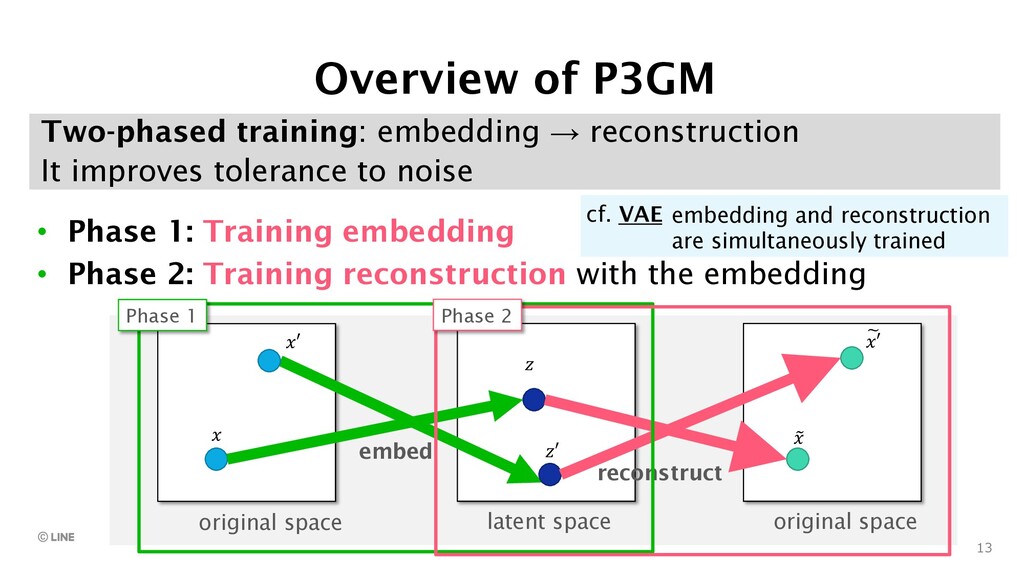{kind=link}
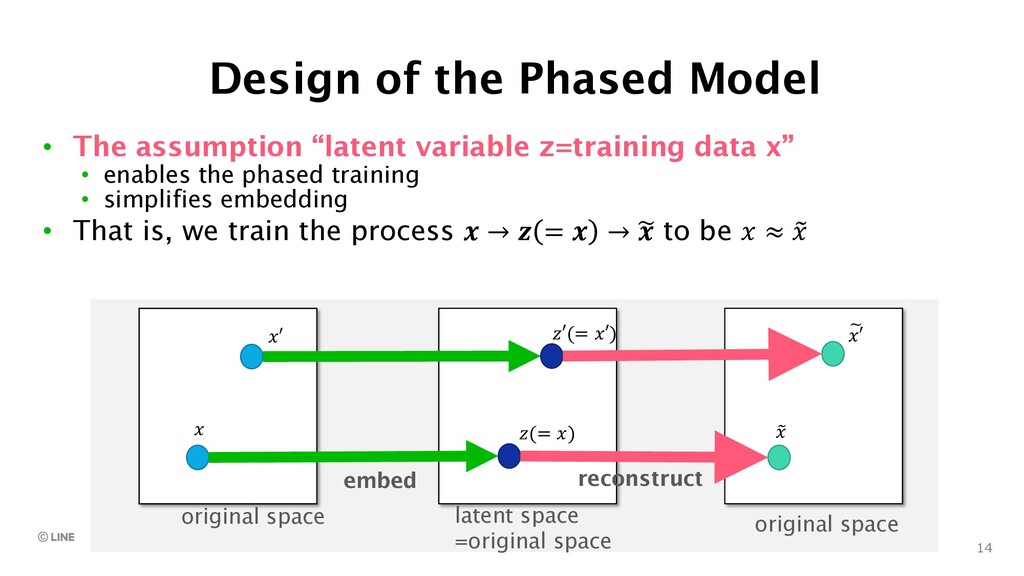{kind=link}
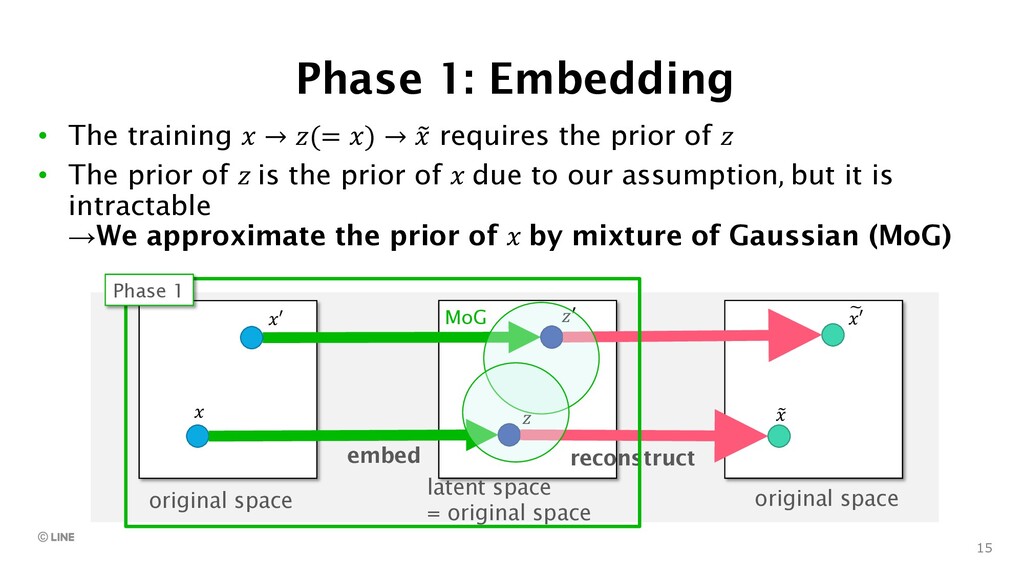{kind=link}
{kind=link}
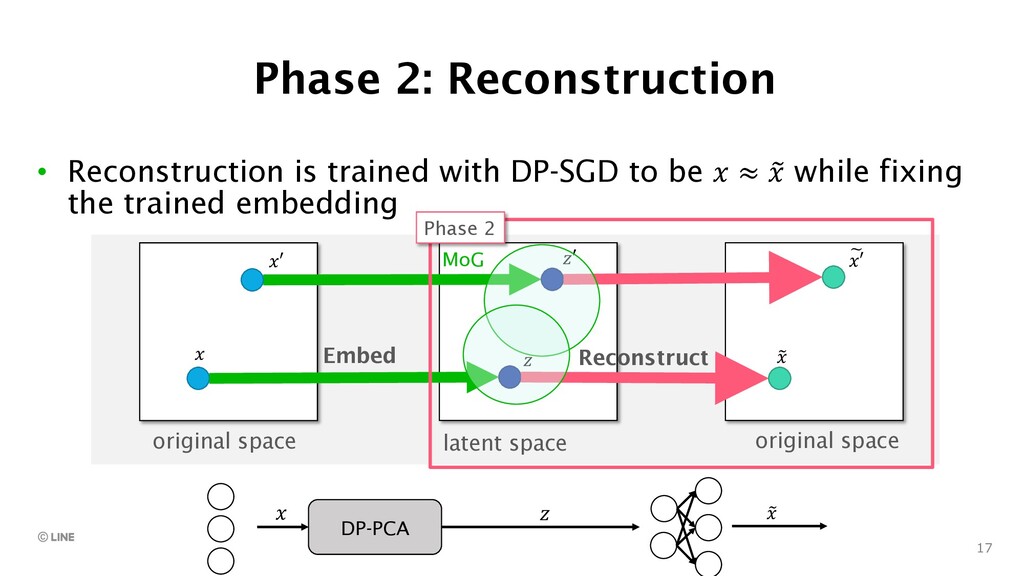{kind=link}
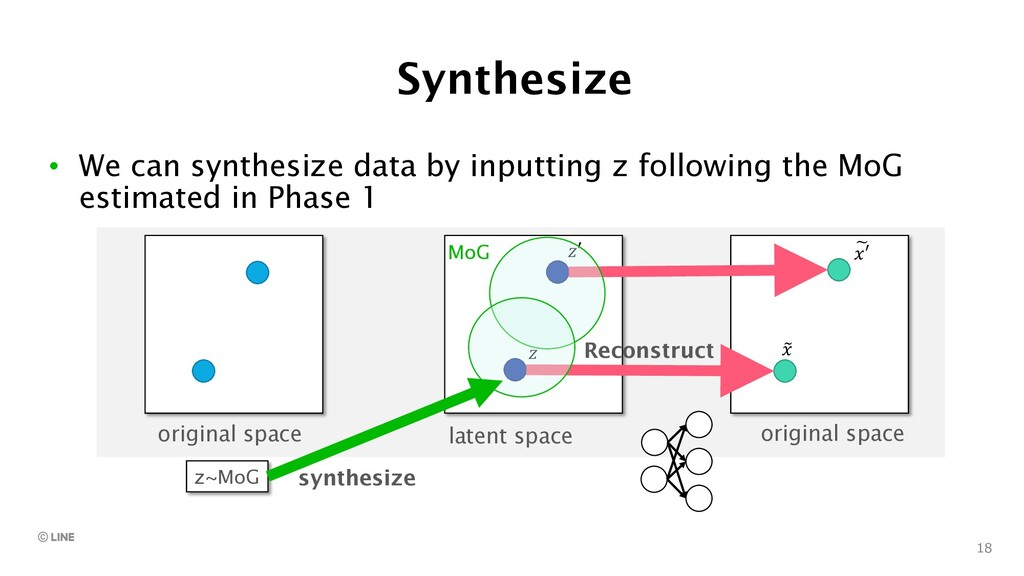{kind=link}
{kind=link}
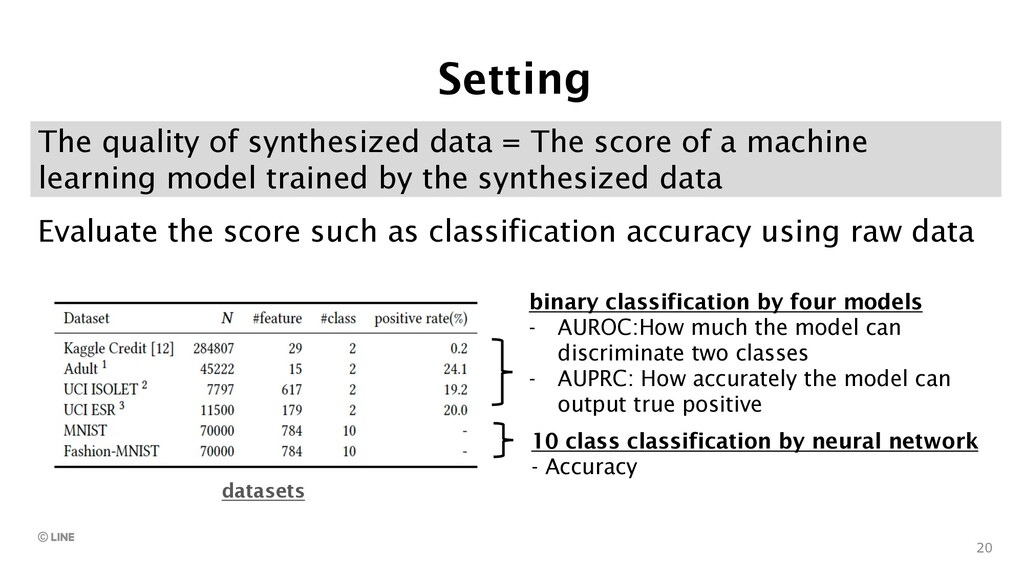{kind=link}
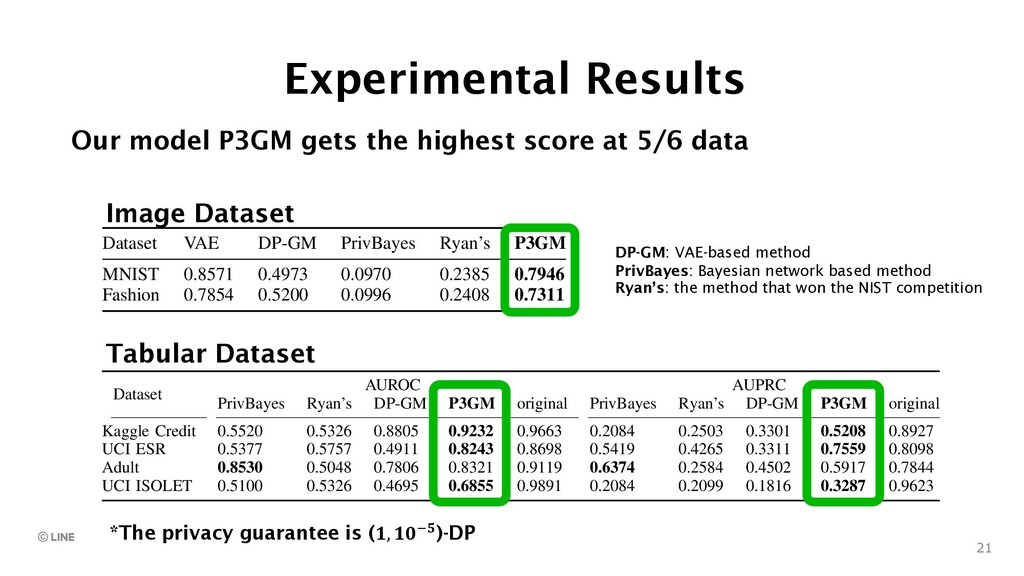{kind=link}
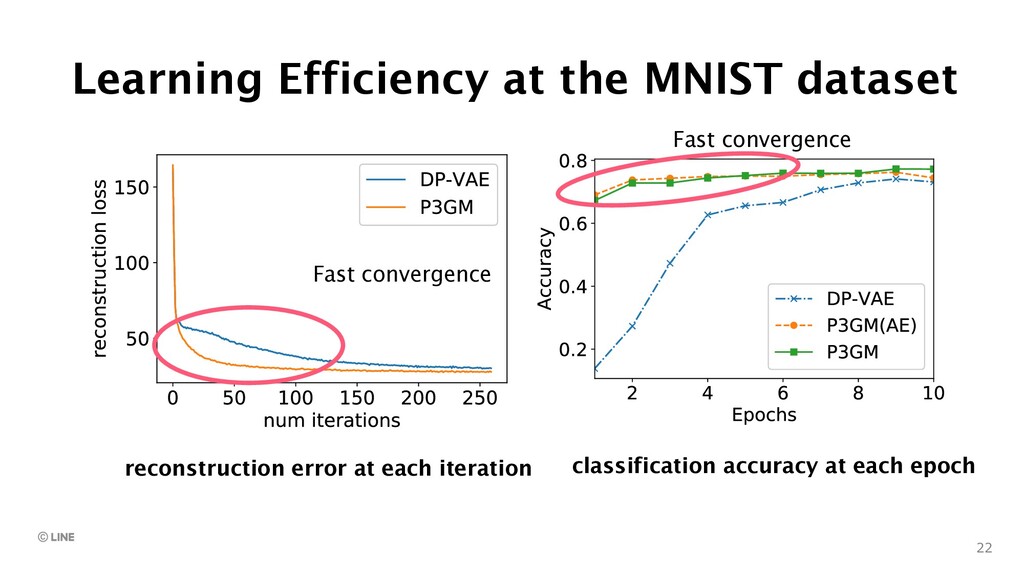{kind=link}
{kind=link}
{kind=link}
![25 References [1] DP Kingma and Max Welling. "Auto-encoding variational](https://files.speakerdeck.com/presentations/4c54696f60b740cebaa686238b7981cb/slide_24.jpg){kind=link}