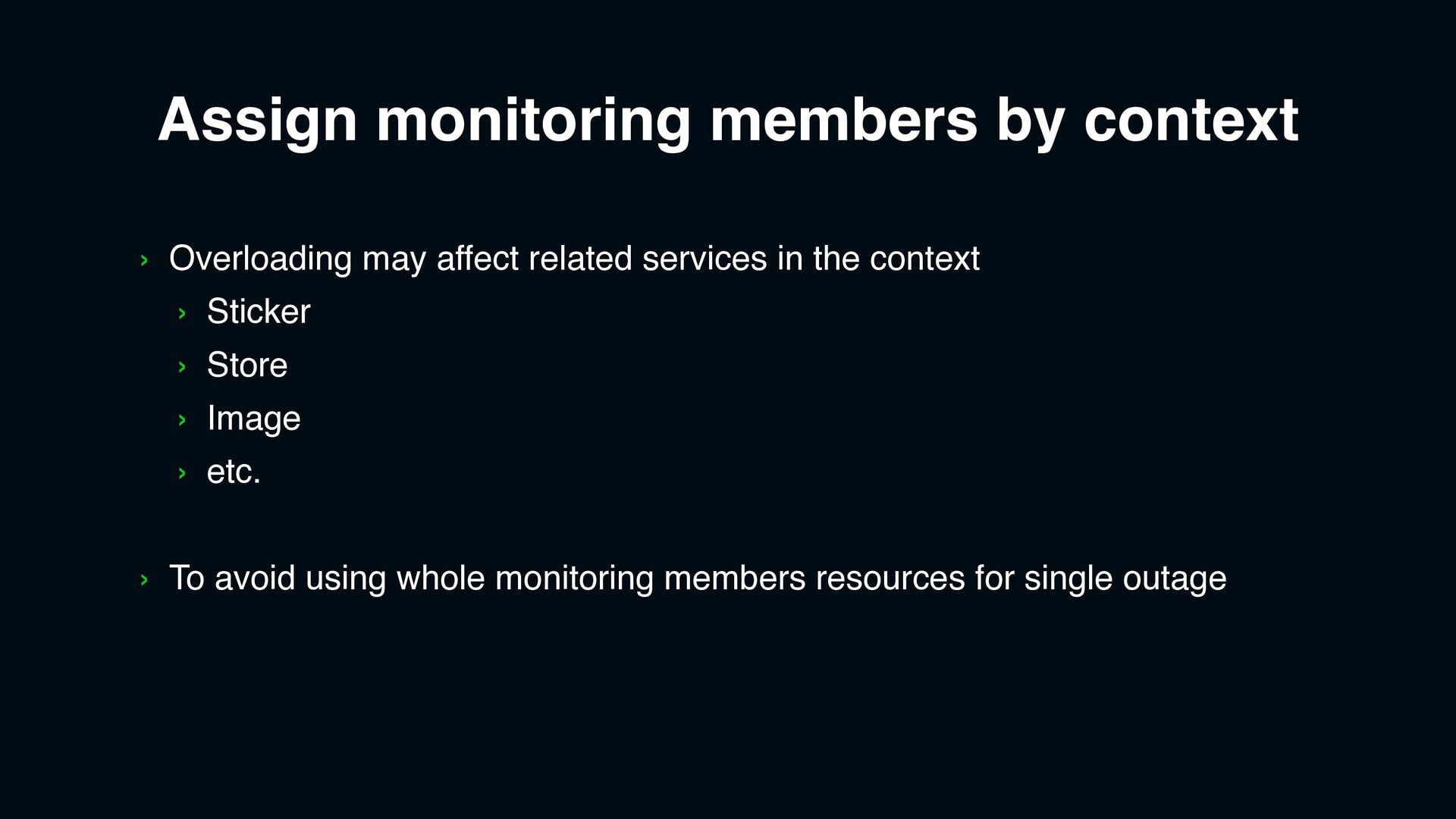
send recommendation or fetch the user information › It’s the biggest sticker campaign and we don’t want to affect our existing sticker services during new year season
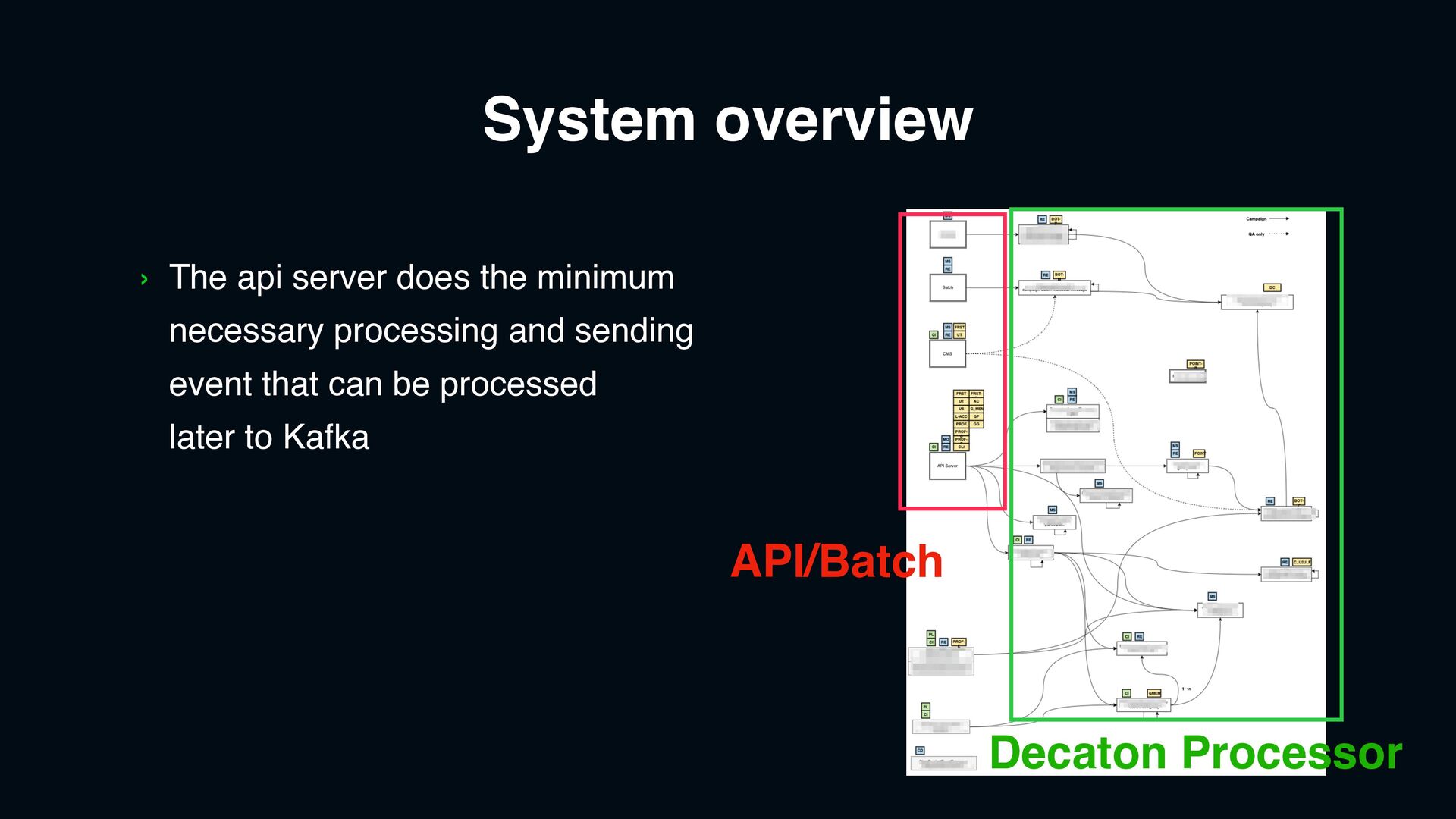
Can adjust configuration dynamically for throttling › Kafka message processing speed › External teams’ API like Messaging, Point, etc Isolated service › Separate modules rather than implementing functionality in existing services › Use Decaton to process Kafka event › Use RxJava/R2DBC to make our code fully asynchronous High throughput
client calling speed can be configured dynamically › Most APIs can be retried, and if not possible, logged and handled manually › Communicate with other teams to obey the maximum traffic can be handled by other teams › Perform load testing with other teams
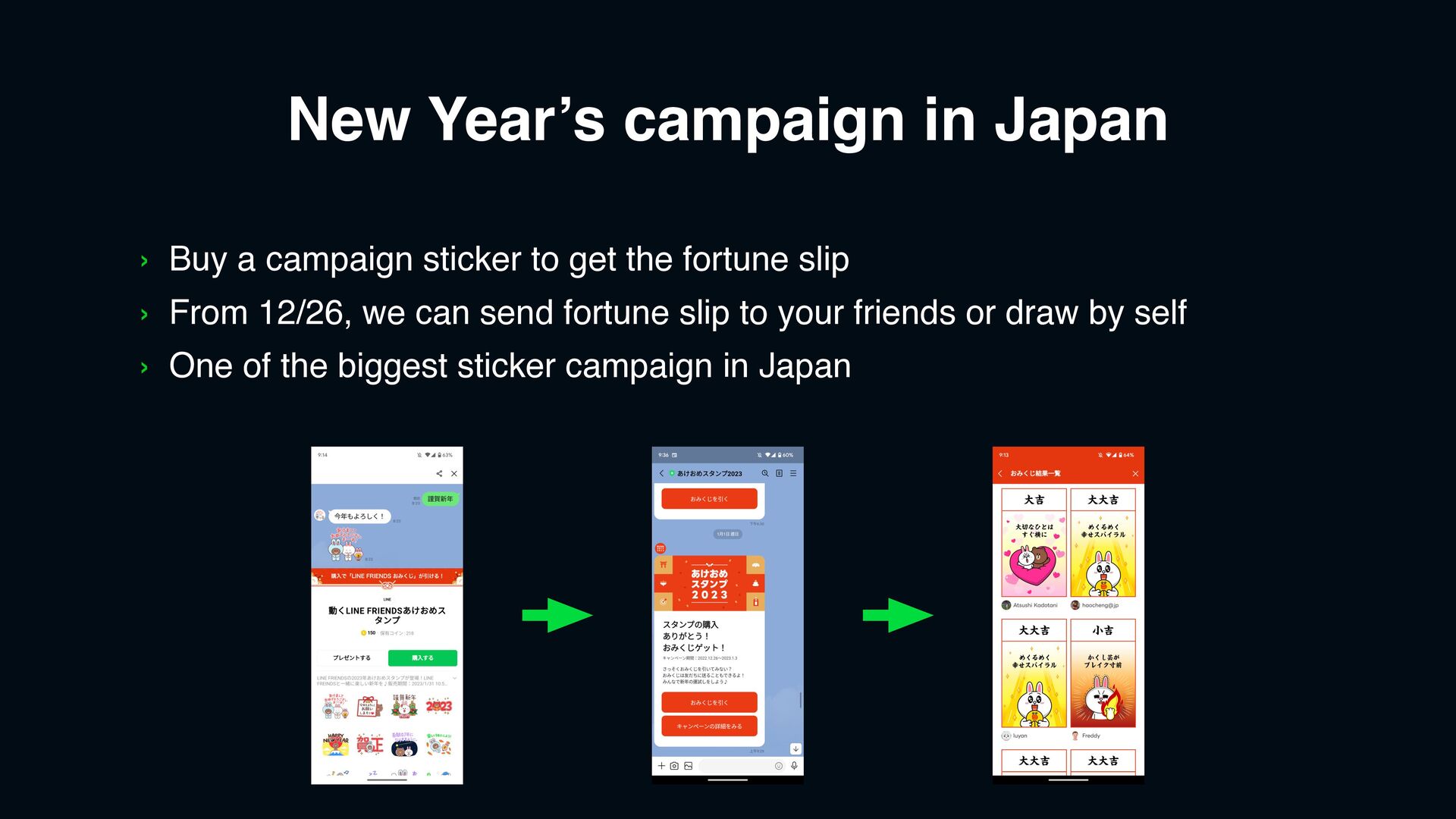
just single day but whole month › From 2022/12/1 to 2023/1/13 › Well estimated OA messages › Send campaign relation information during the campaign › The system is stable during the campaign period
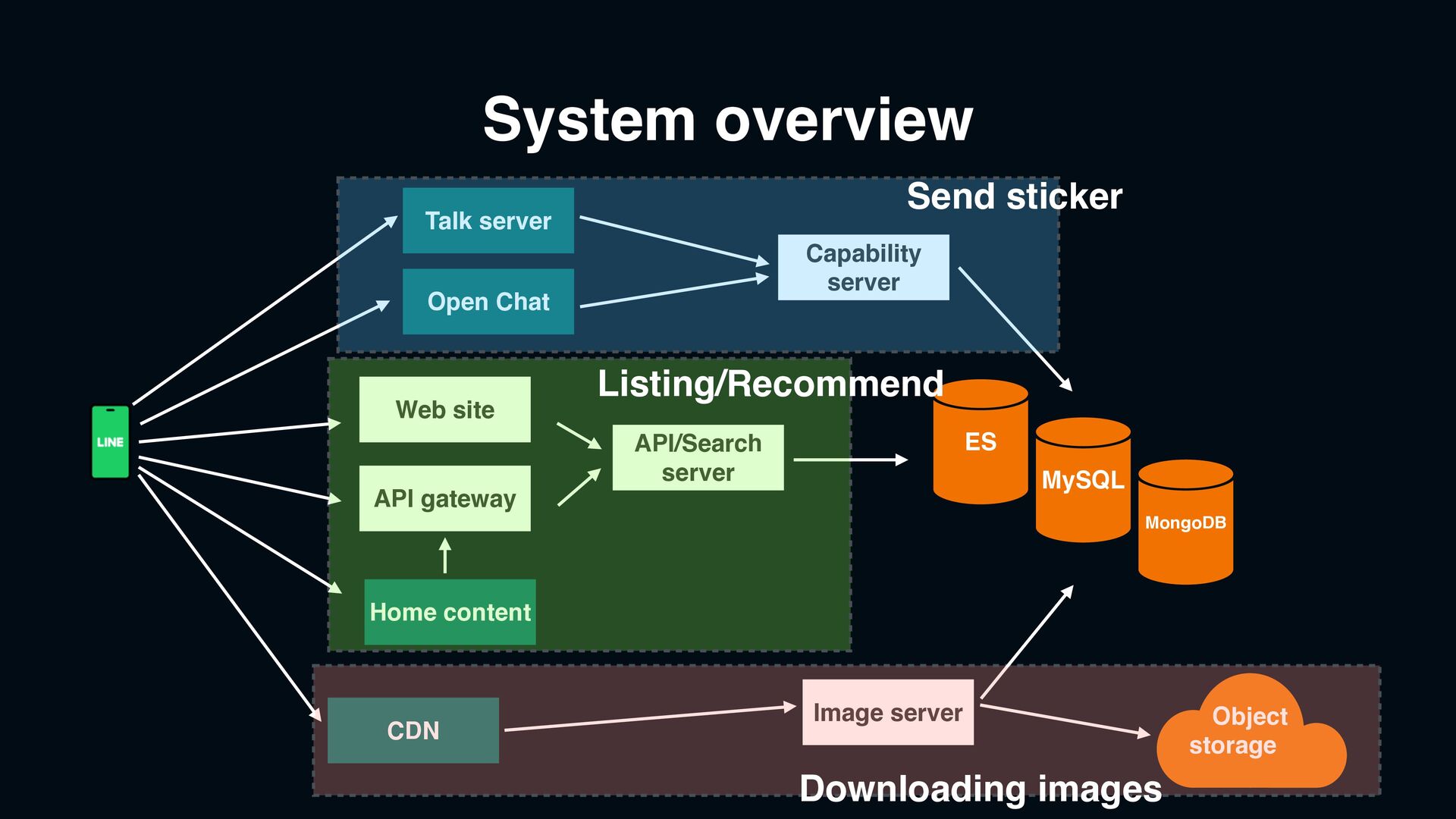
product Provider side(Official & Creator) › Listing including search and recommendation › Purchase and download the resources › Send and receive stickers User side
to estimate the load due to implementation or architecture changes › Not easy to figure out the traffic of new features › Spike all at once in a short time › About 9 times what it was a minute ago › Increased sales for a few hours › Japan(UTC+9)→Taiwan(UTC+8)→Thai(UTC+7)
conditions Calculate the ratio of peak accesses on the weekday of November of the previous year and this year. Consider this ratio as a growth rate and multiply it by the number of accesses on New Year's Day of the previous year. If the previous year's number of accesses is not reliable, it is not predictable. 2021 2022 2023 Weekday of November 1000rps 2500rps 5000rps NY’s Day 2000rps 4500rps ???rps
growth rate and year-on-year ratio › If both data are not available, refer to other similar services Have Data No Data Have Data Max(A, B) B No Data A refer to other similar services A B
70% CPU usage as target › Services that have concerns about estimation › 50% CPU usage as target › Had outage last year or not enough information or we have concerns › Use metrics to find services where the rate of increase in CPU is far greater than the rate of increase in requests. › Adjust the configuration and checking the code to find problems
the latency and error rate › Achieve the 70% CPU usage › Resolve bottlenecks when they are easy to resolve LB Server 1 Server 2 Server 3 Server 4 Server 5
the most used services like sending/receiving, listing, image downloading related API › Make a panel for each service to avoid overloading of grafana › We use rps per node due to total rps is not meaningful if we can scale out easily
› Share inside the team › Check if it will increase more in short time › More than what we can handled › Share to emergency channel in the company › Immediate action taken as planned
for each API › How can we know which API affects which service, screen, API, etc. › What is the UX when an error occurs? › Workshop with stakeholders like engineer, QA, planner, etc. › Try from the most requested API › Checking the result at dev environment › It is not necessary to check all APIs, but only to identify those that have the greatest impact
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}