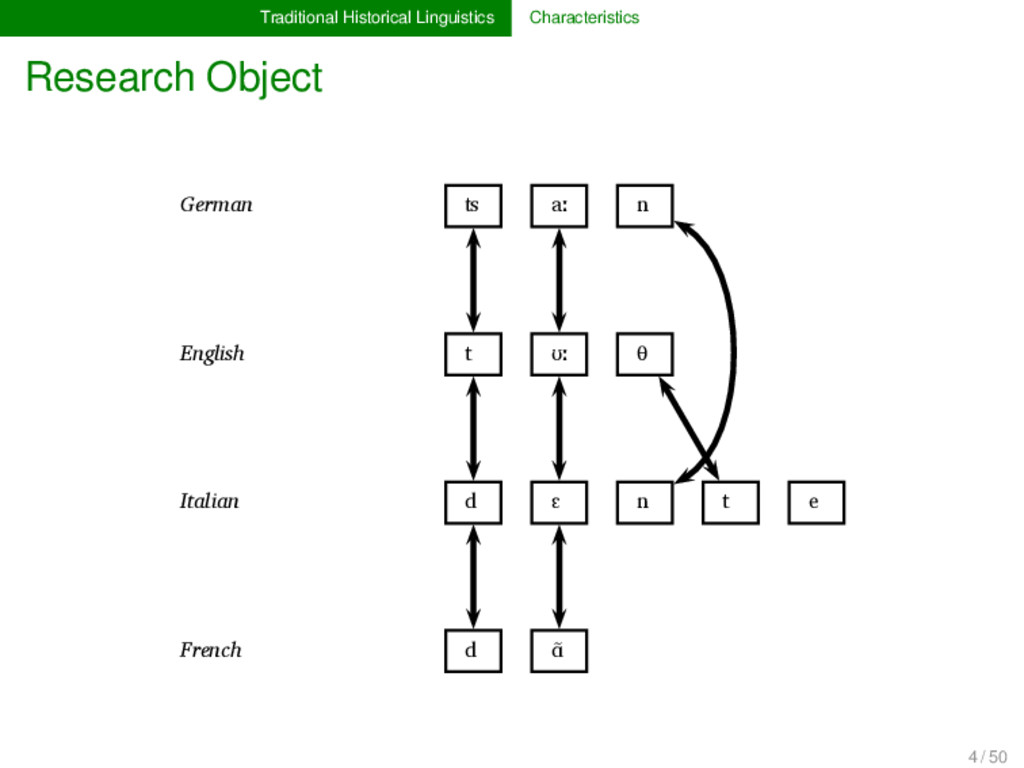
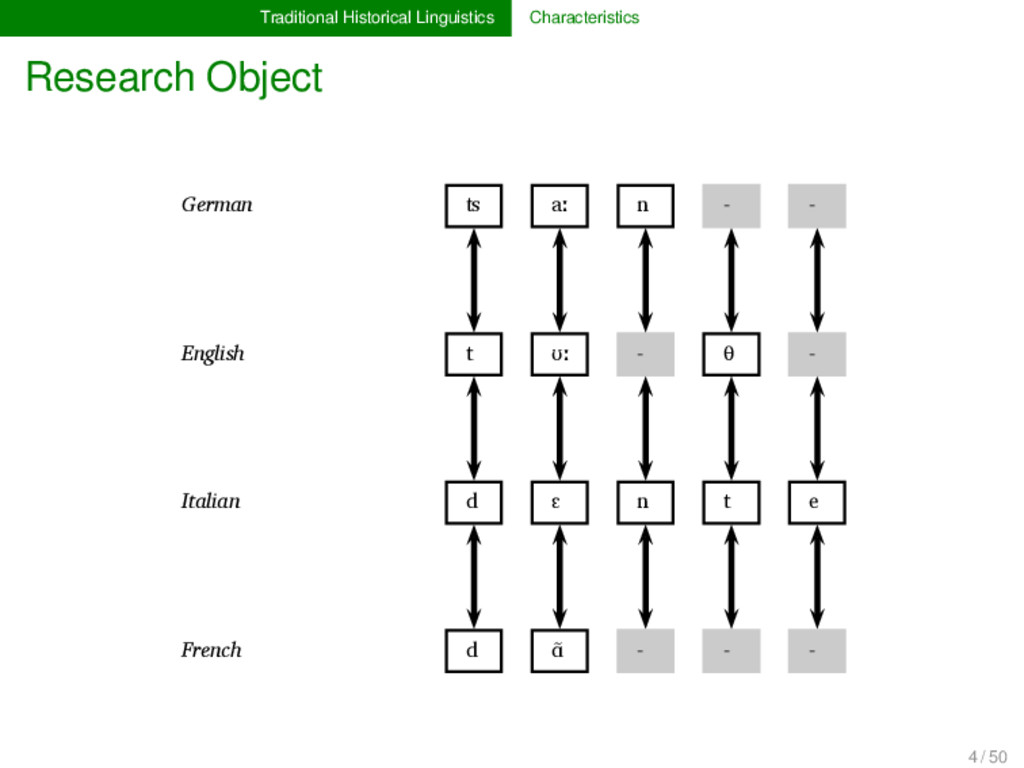
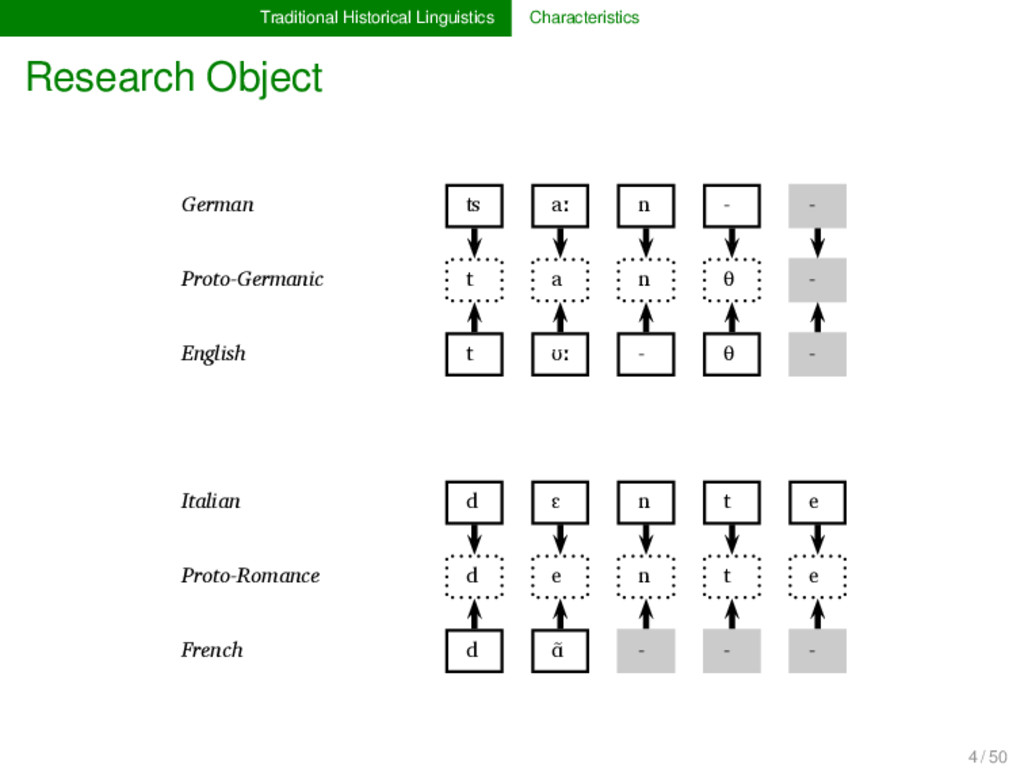
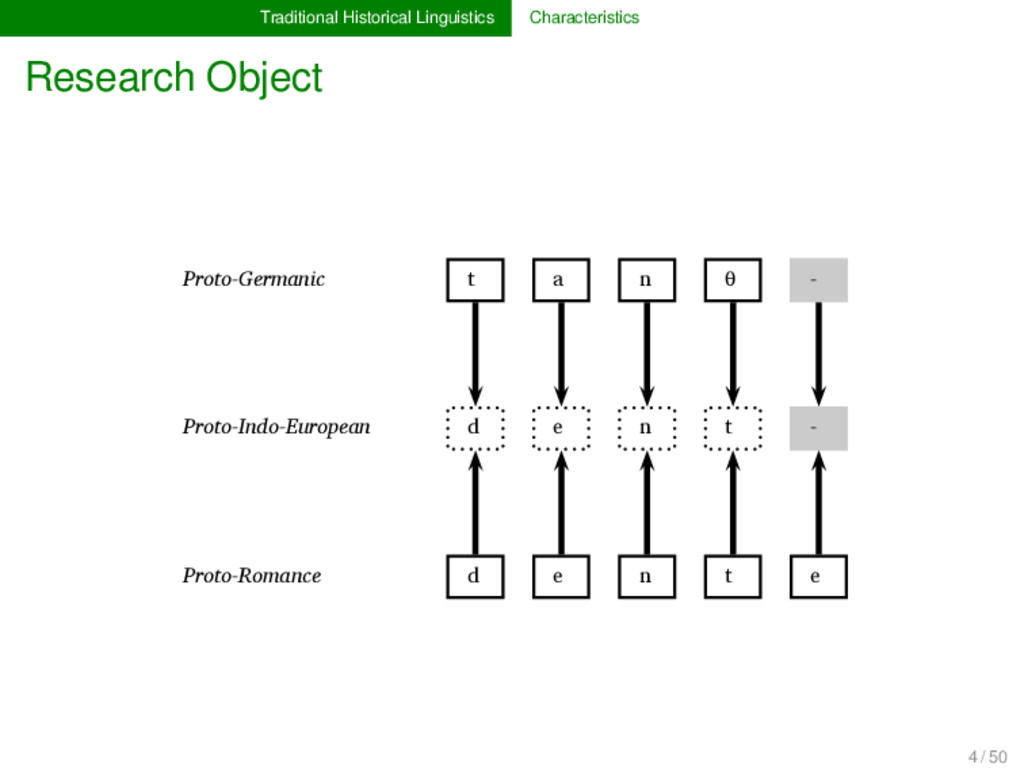
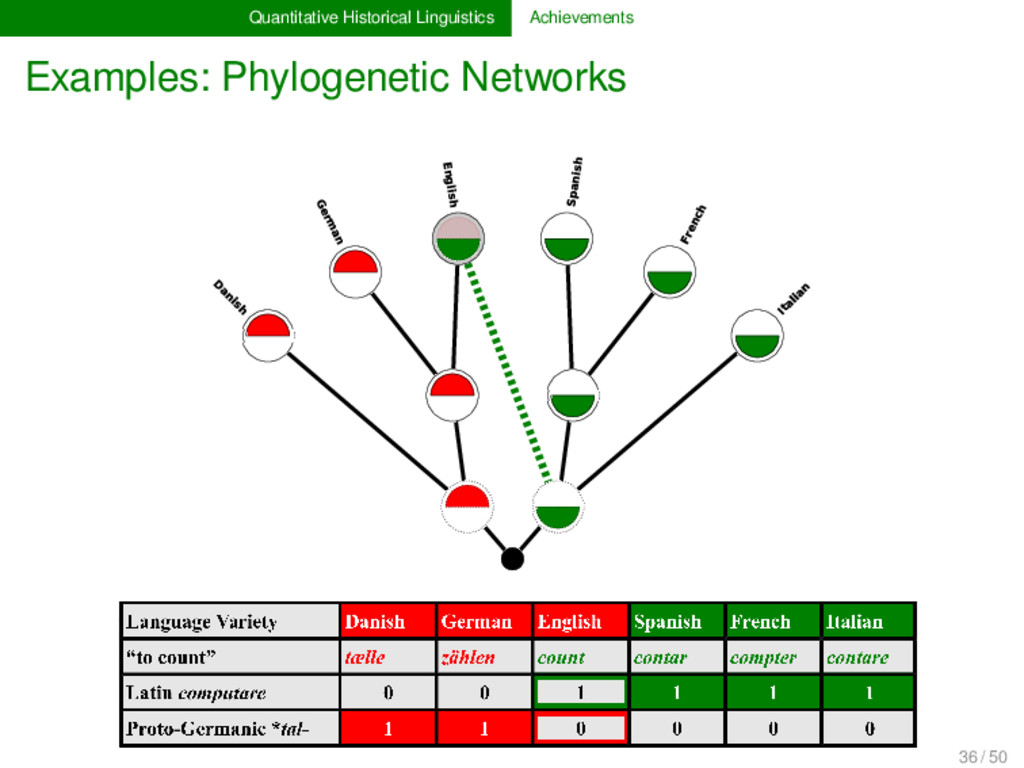
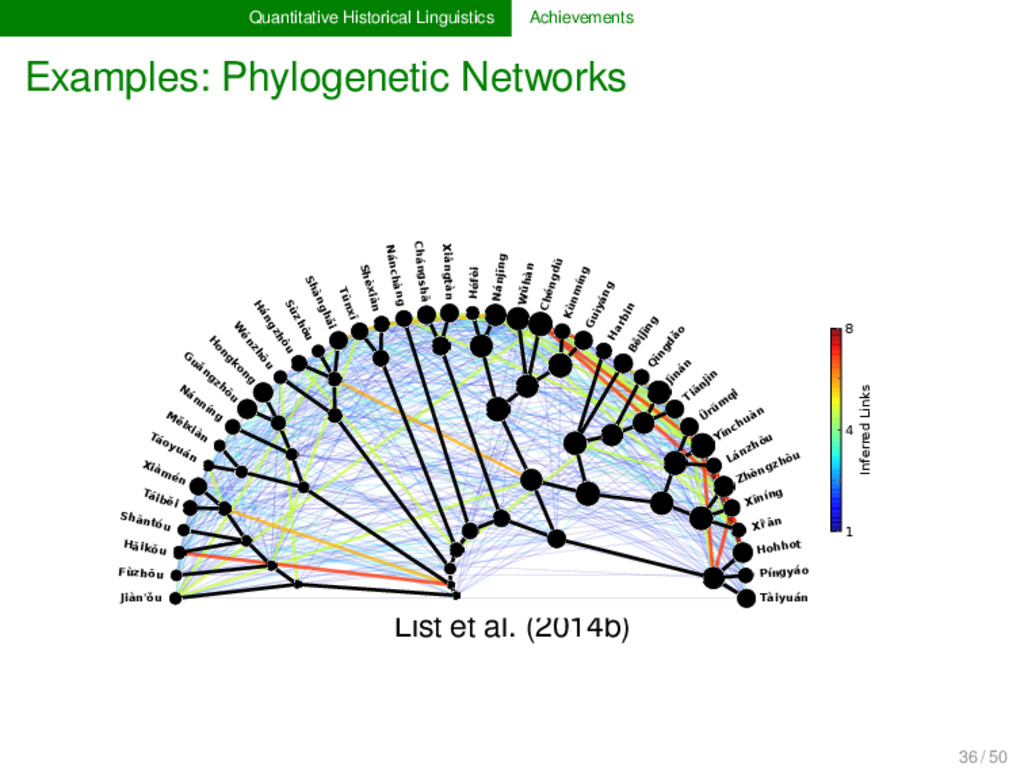
Proto-Germanic t a n θ English t ʊː θ Proto-Indo-European d e n t Italian d ɛ n t e Proto-Romance d e n t e French d ɑ̃ German ʦ aː n Proto-Germanic t a n θ English t ʊː θ Proto-Indo-European d e n t Italian d ɛ n t e Proto-Romance d e n t e French d ɑ̃ 1 4 / 50
individual processes (description) general processes (modeling, analysis) Language History individual language states (description of sound system, grammar, lexicon) individual instances of language development (description of sound change patterns, grammaticalization, lexical change) general language development (modeling and analysis of sound change processes, grammaticalization, lexical change) 5 / 50
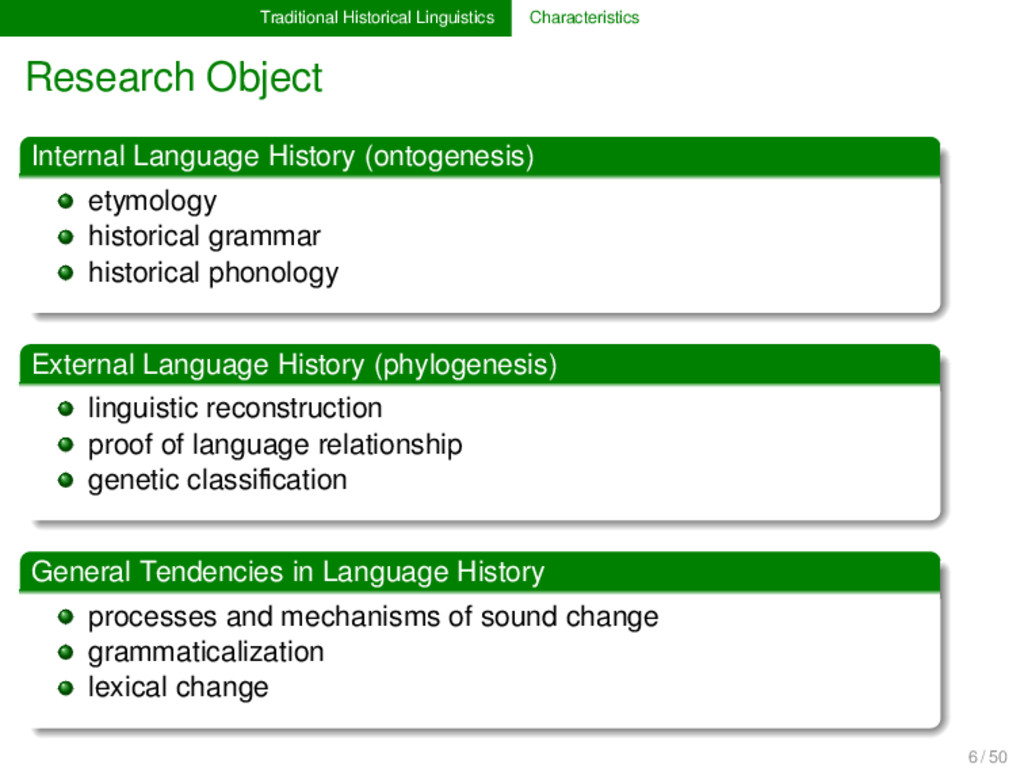
etymology historical grammar historical phonology External Language History (phylogenesis) linguistic reconstruction proof of language relationship genetic classification General Tendencies in Language History processes and mechanisms of sound change grammaticalization lexical change 6 / 50
change is independent of time and space “graduality of change” – change is neither abrupt nor chaotic “uniformity of change” – change is not heterogeneous, but uniform Founding Fathers Franz Bopp (1791–1867): language comparison (Bopp 1816) Rasmus Rask (1787-1832) and Jacob Grimm (1785-1863): sound law (Rask 1818, Grimm 1822) August Schleicher (1821–1868): family tree and linguistic reconstruction (Schleicher 1853 & 1861) 7 / 50
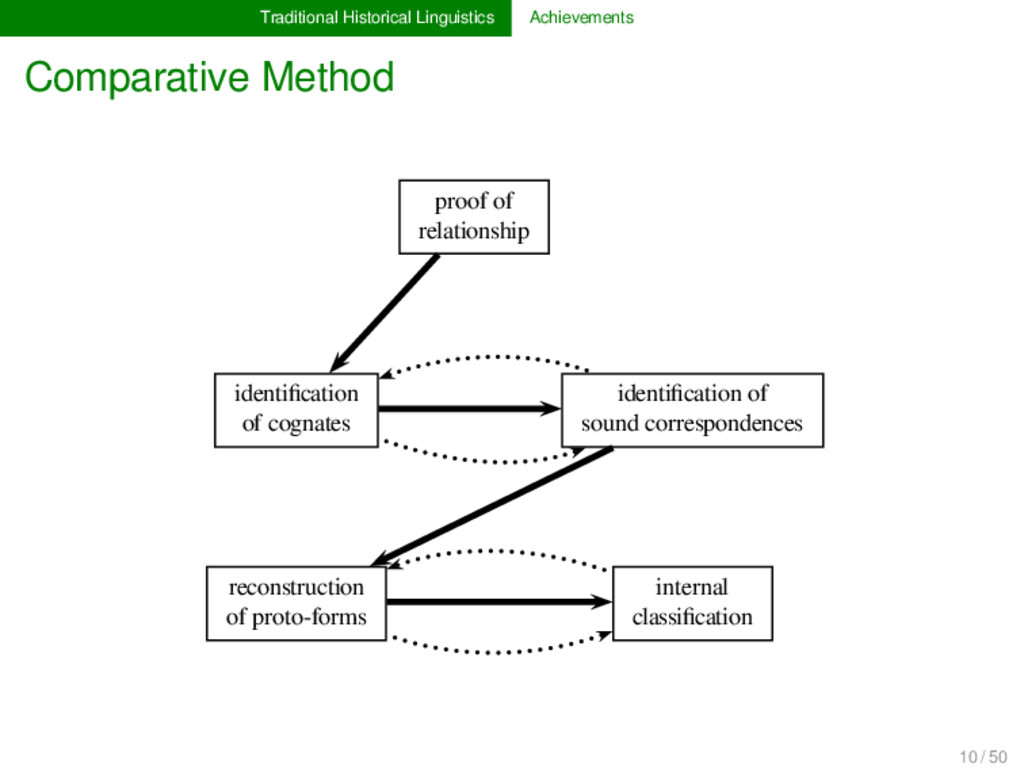
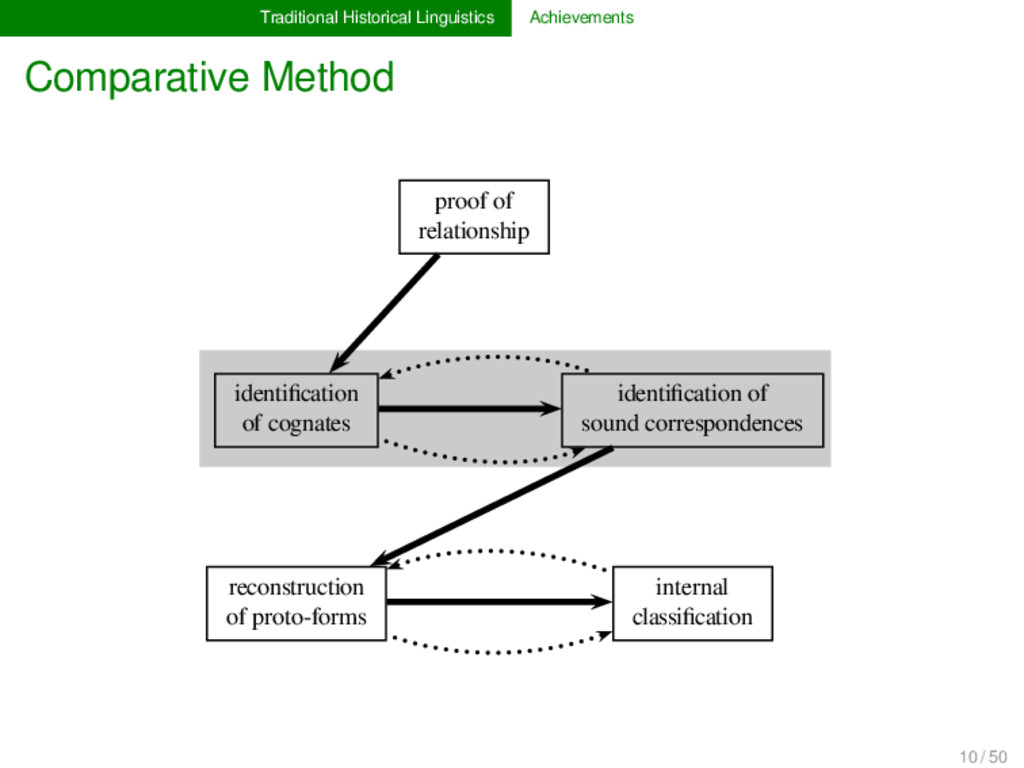
1925) Basic procedure for proving language relationship and reconstructing unattested ancestral language states, etymologies, and genetic classifications. Family Tree Model and Wave Theory (Schleicher 1853, Schmidt 1872) Two partially incompatible models to describe historical language relations. Regularity Hypothesis (Osthoff & Brugmann 1878) Fundamental working hypothesis that states that certain sound change processes proceed regularly (universally, gradually, and in a uniform manner). 9 / 50
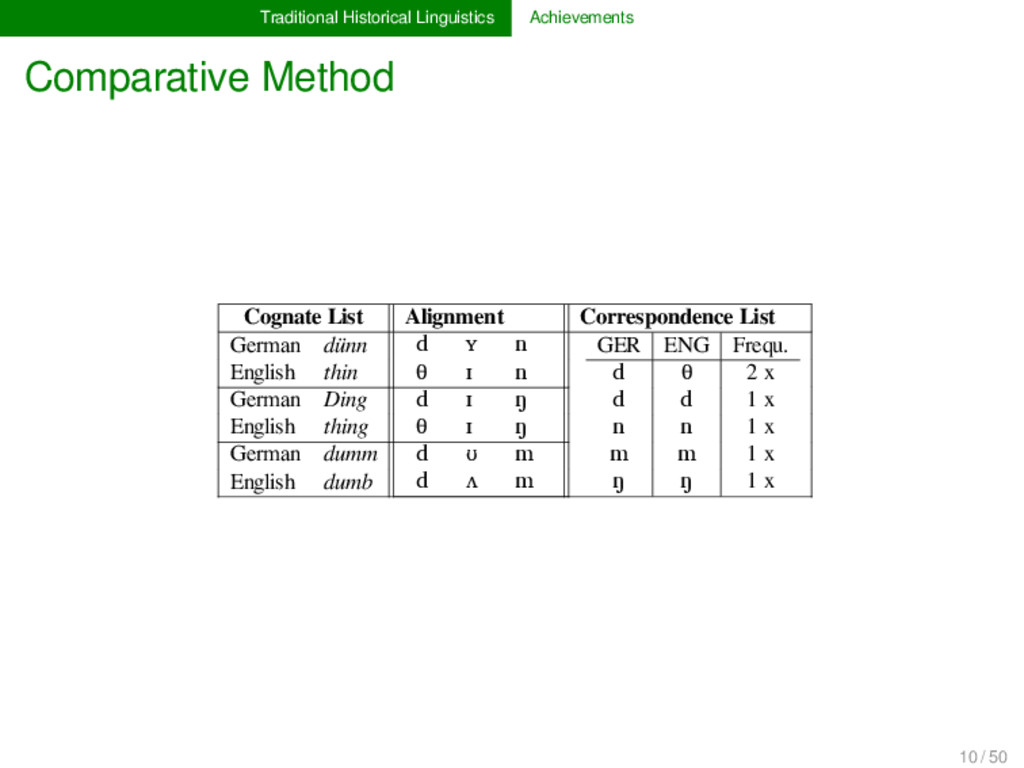
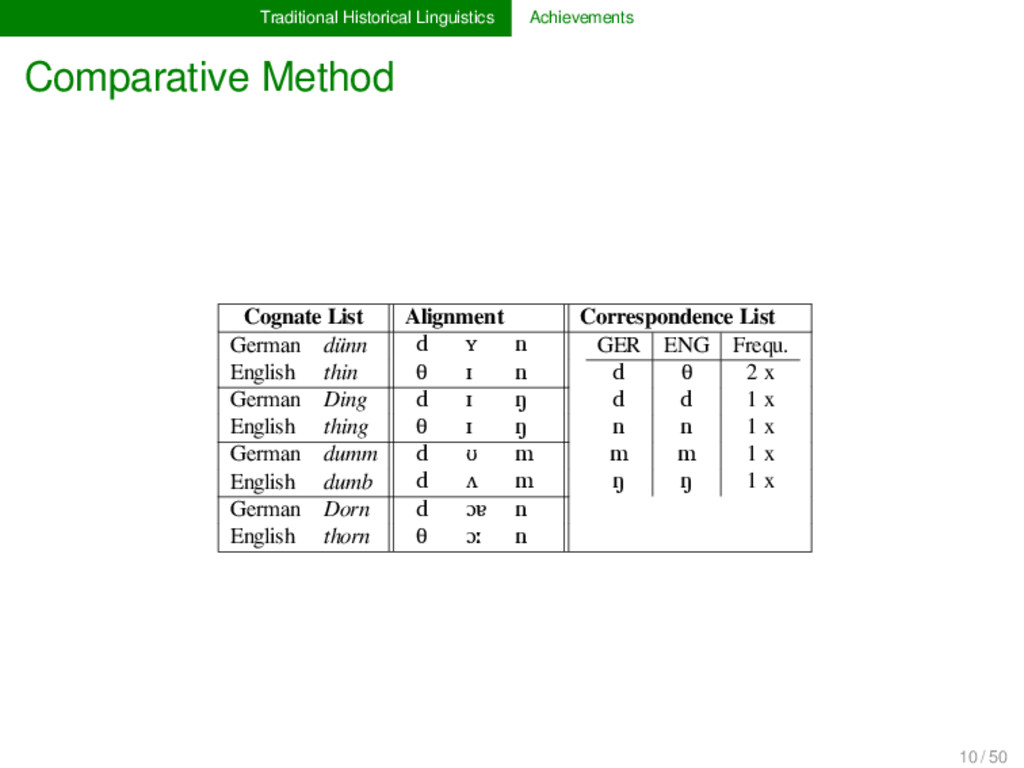
List German dünn d ʏ n GER ENG Frequ. d θ 3 x d d 1 x n n 1 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn d ɔː n 10 / 50
List German dünn d ʏ n GER ENG Frequ. d θ 3 x d d 1 x n n 1 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn d ɔː n 10 / 50
List German dünn d ʏ n GER ENG Frequ. d θ 2 x d d 1 x n n 1 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn d ɔː n 10 / 50
List German dünn d ʏ n GER ENG Frequ. d θ 2 x d d 1 x n n 1 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn θ ɔː n 10 / 50
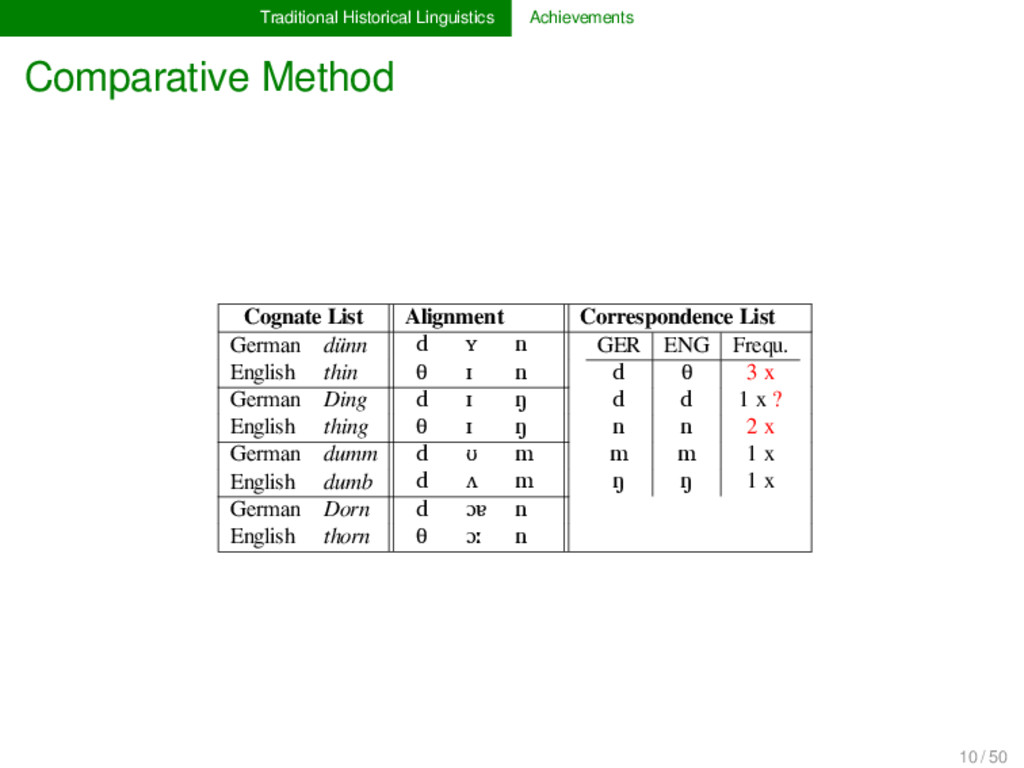
List German dünn d ʏ n GER ENG Frequ. d θ 3 x d d 1 x ? n n 2 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn θ ɔː n 10 / 50
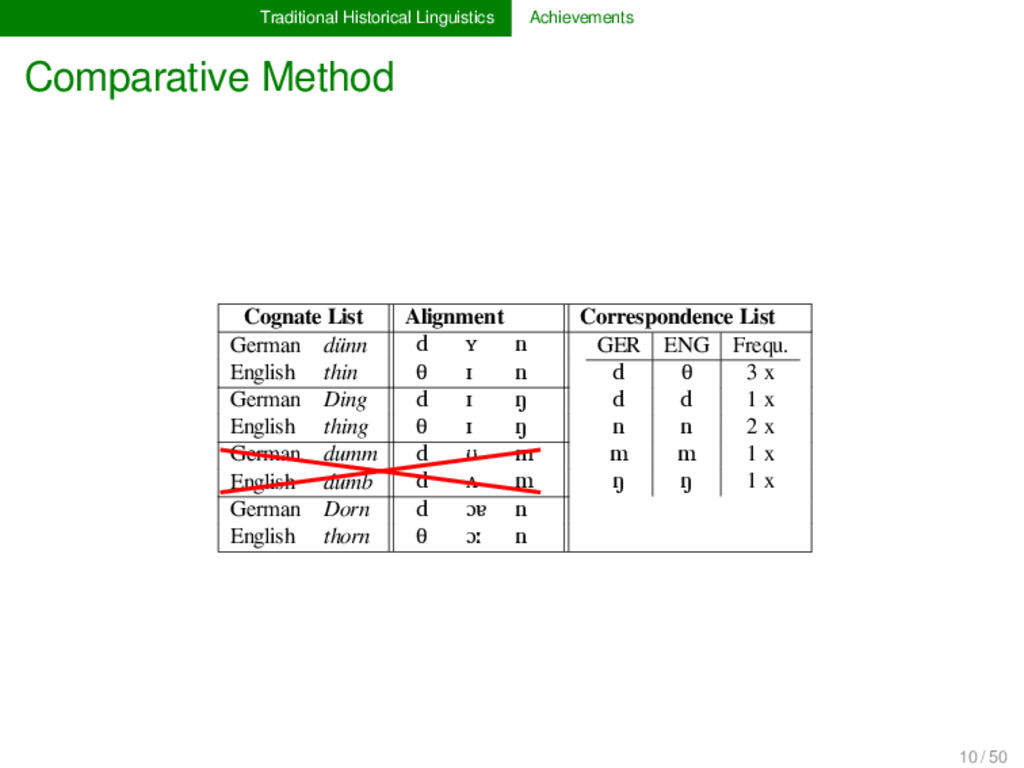
List German dünn d ʏ n GER ENG Frequ. d θ 3 x d d 1 x n n 2 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn θ ɔː n 10 / 50
historical linguistics, the history of a considerable (but still small) amount of languages has been thoroughly investigated. External Language History Thanks to historical linguistics, a considerable amount of the languages in the world has been genetically classified (although there remain many unsolved and controversially discussed questions). General Language History Some work on general processes of language history has been done, yet many questions still remain unsolved or are controversially debated. 11 / 50
“becoming” a competent Indo-Europeanist has always been recognized as coming to grasp “intuitively” concepts and types of changes in language so as to be able to pick and choose between alternative explanations for the history and development of specific features of the reconstructed language and its offspring. Schwink (1994) 13 / 50
data for the lan- guages of the world is growing from day to day, while there are only a few historical linguists who are trained to carry out the comparison of these languages. It seems impossible to handle this task when relying only on the traditional, time- consuming manual procedures developed in tra- ditional historical linguistics. 14 / 50
linguistics has some clear shortcomings, such as a lack of transparency in methodology, the “philological” form of knowledge representation, and the questionable validity of certain results. 16 / 50
Sf std. (9. Jh.), mhd. vruht, ahd. fruht, as. fruht. Ent- lehnt aus l. frūctus m. gleicher Bedeutung (zu l. fruī “ge- nieße”). Das deutsche Wort ist Femininum geworden im Anschluß an die ti- Abstrakta wie Flucht² usw. Adjekti- ve: fruchtig, fruchtbar; Verb: (be-)fruchten. Ebenso nndl. vrucht, ne. fruit, nfrz. fruit, nschw. frukt, nnorw. frukt; frugal. (Kluge und Seebold 2002) 17 / 50
Warnow and Taylor 2002) “Language-tree divergence times support the Anatolian theory of Indo-European origin” (Gray und Atkinson 2003) “Language classification by numbers” (McMahon und McMahon 2005) “Curious Parallels and Curious Connections: Phylogenetic Thinking in Biology and Historical Linguistics” (Atkinson und Gray 2005) “Automated classification of the world’s languages” (Brown et al. 2008) “Computational Feature-Sensitive Reconstruction of Language Relationships: Developing the ALINE Distance for Comparative Historical Linguistic Reconstruction” (Downey et al. 2008) “Networks uncover hidden lexical borrowing in Indo-European language evolution” (Nelson-Sathi et al. 2011) “A pipeline for computational historical linguistics” (Steiner, Stadler, und Cysouw 2011) 20 / 50
reconstruction sequence comparison general questions of language development Goals If we cannot guarantee getting the same results from the same data considered by different linguists, we jeopardize the essential scientific criterion of repeatability. (McMahon & McMahon 2005) 21 / 50
among others, Gray & Atkinson 2003 Ringe et al. 2002, Brown et al. 2008) phonetic alignment (cf., among others, Kondrak 2000, Prokić et al. 2009, List 2012a) cognate detection (cf. Steiner et al. 2011, List 2012b) borrowing detection (cf. Nelson-Sathi et al. 2011, List et al. 2014a) 22 / 50
more attention than before “Indo-Euro-Centrism” is replaced by a more cross-linguistic paradigm new questions regarding general language history new proposals to model language history 24 / 50
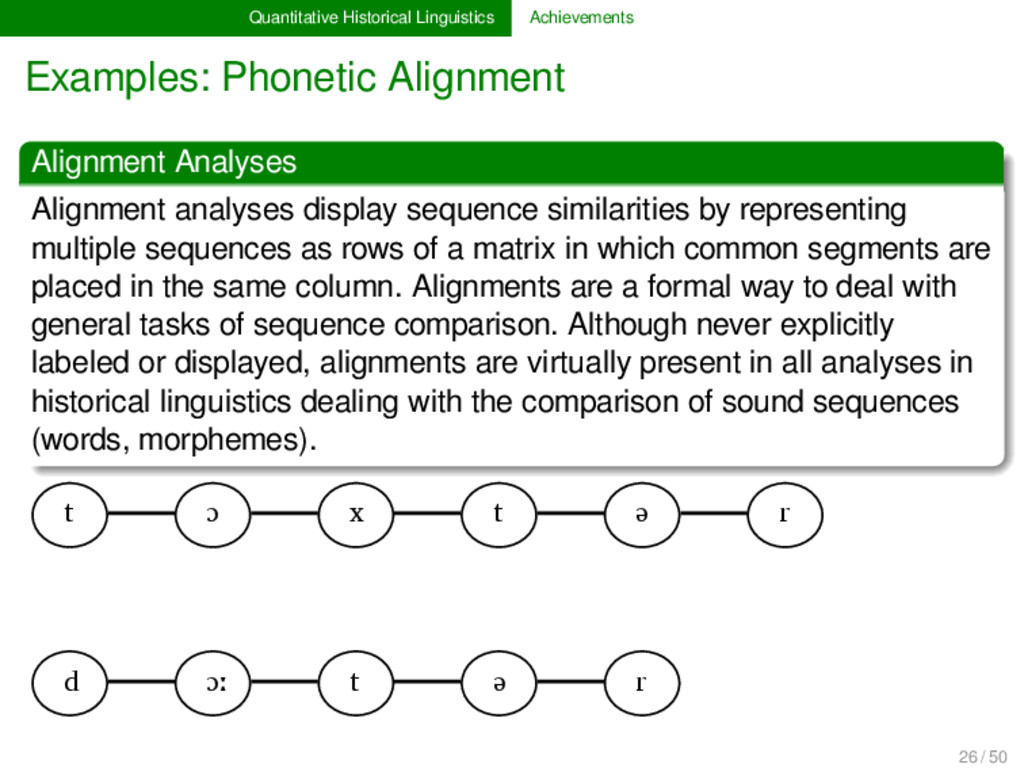
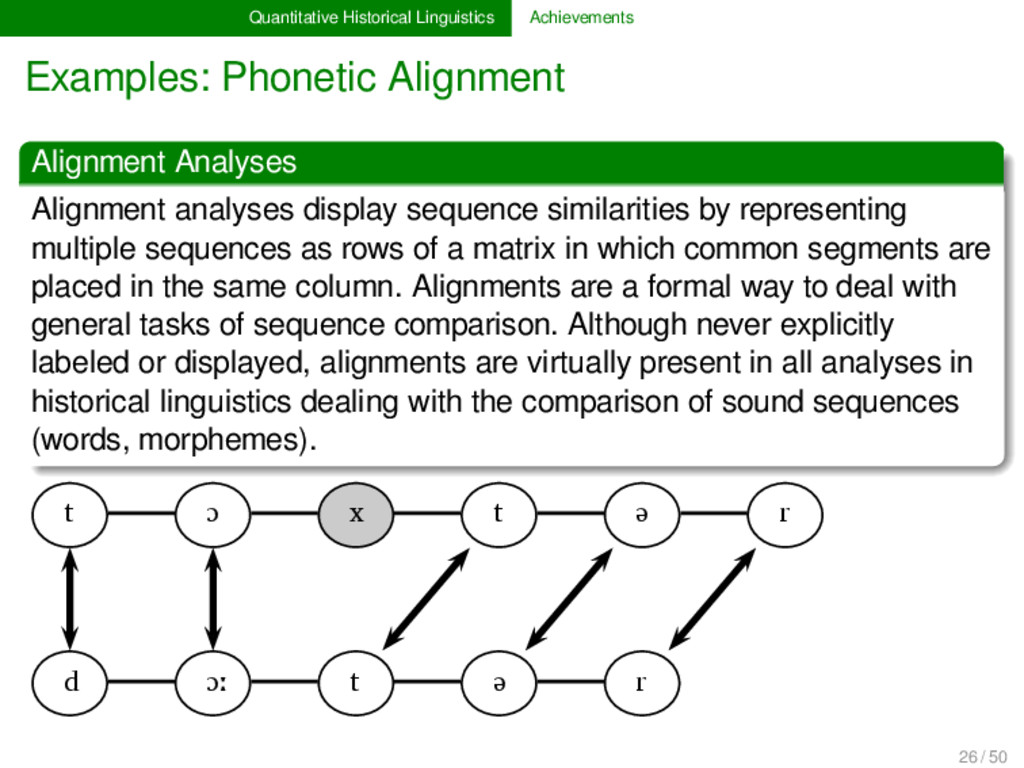
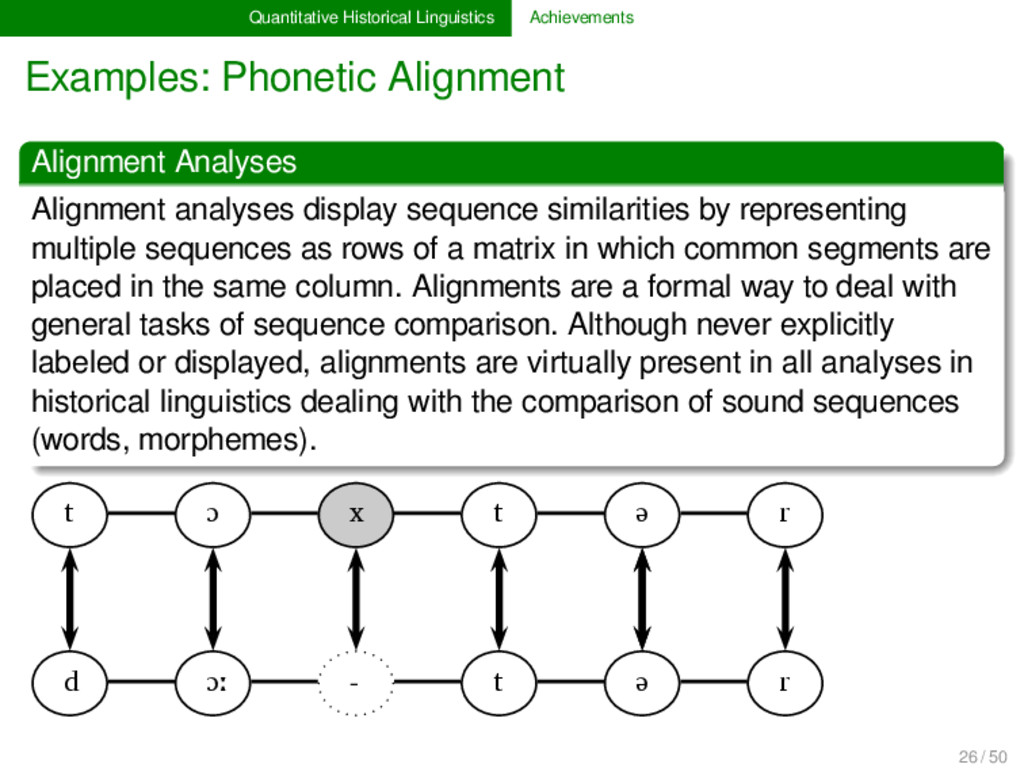
analyses display sequence similarities by representing multiple sequences as rows of a matrix in which common segments are placed in the same column. Alignments are a formal way to deal with general tasks of sequence comparison. Although never explicitly labeled or displayed, alignments are virtually present in all analyses in historical linguistics dealing with the comparison of sound sequences (words, morphemes). 26 / 50
analyses display sequence similarities by representing multiple sequences as rows of a matrix in which common segments are placed in the same column. Alignments are a formal way to deal with general tasks of sequence comparison. Although never explicitly labeled or displayed, alignments are virtually present in all analyses in historical linguistics dealing with the comparison of sound sequences (words, morphemes). t ɔ x t ə r d ɔː t ə r 26 / 50
analyses display sequence similarities by representing multiple sequences as rows of a matrix in which common segments are placed in the same column. Alignments are a formal way to deal with general tasks of sequence comparison. Although never explicitly labeled or displayed, alignments are virtually present in all analyses in historical linguistics dealing with the comparison of sound sequences (words, morphemes). t ɔ x t ə r d ɔː t ə r 26 / 50
analyses display sequence similarities by representing multiple sequences as rows of a matrix in which common segments are placed in the same column. Alignments are a formal way to deal with general tasks of sequence comparison. Although never explicitly labeled or displayed, alignments are virtually present in all analyses in historical linguistics dealing with the comparison of sound sequences (words, morphemes). t ɔ x t ə r d ɔː - t ə r 26 / 50
which frequently occur in correspondence relations in genetically related languages can be clustered into classes. It is thereby assumed that “phonetic correspondences inside a ‘type’ are more regular than those between different ‘types’” (Dolgopolsky 1986[1964]: 35). 27 / 50
which frequently occur in correspondence relations in genetically related languages can be clustered into classes. It is thereby assumed that “phonetic correspondences inside a ‘type’ are more regular than those between different ‘types’” (Dolgopolsky 1986[1964]: 35). k g p b ʧ ʤ f v t d ʃ ʒ θ ð s z 1 27 / 50
which frequently occur in correspondence relations in genetically related languages can be clustered into classes. It is thereby assumed that “phonetic correspondences inside a ‘type’ are more regular than those between different ‘types’” (Dolgopolsky 1986[1964]: 35). k g p b ʧ ʤ f v t d ʃ ʒ θ ð s z 1 27 / 50
which frequently occur in correspondence relations in genetically related languages can be clustered into classes. It is thereby assumed that “phonetic correspondences inside a ‘type’ are more regular than those between different ‘types’” (Dolgopolsky 1986[1964]: 35). k g p b ʧ ʤ f v t d ʃ ʒ θ ð s z 1 27 / 50
which frequently occur in correspondence relations in genetically related languages can be clustered into classes. It is thereby assumed that “phonetic correspondences inside a ‘type’ are more regular than those between different ‘types’” (Dolgopolsky 1986[1964]: 35). K T P S 1 27 / 50
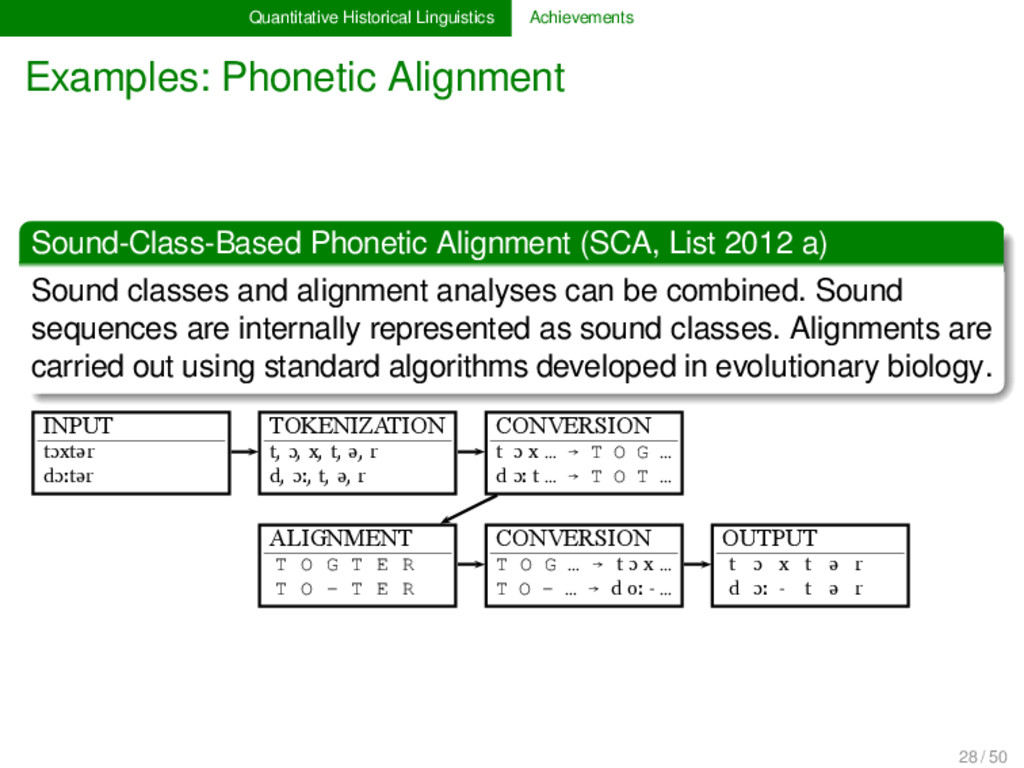
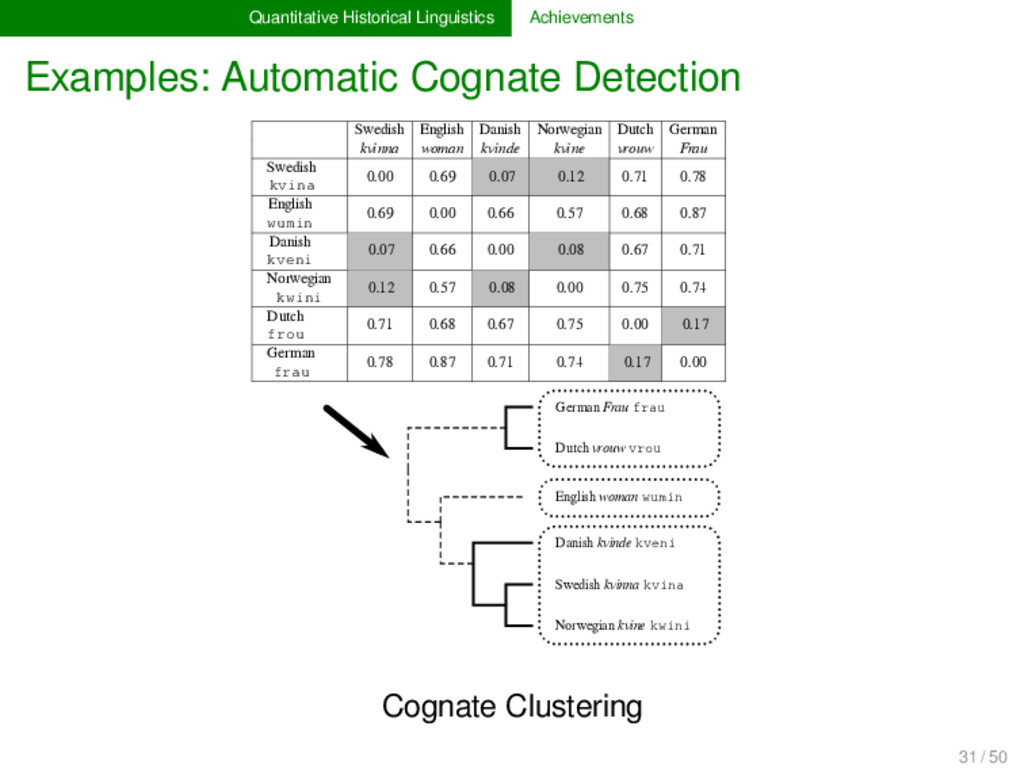
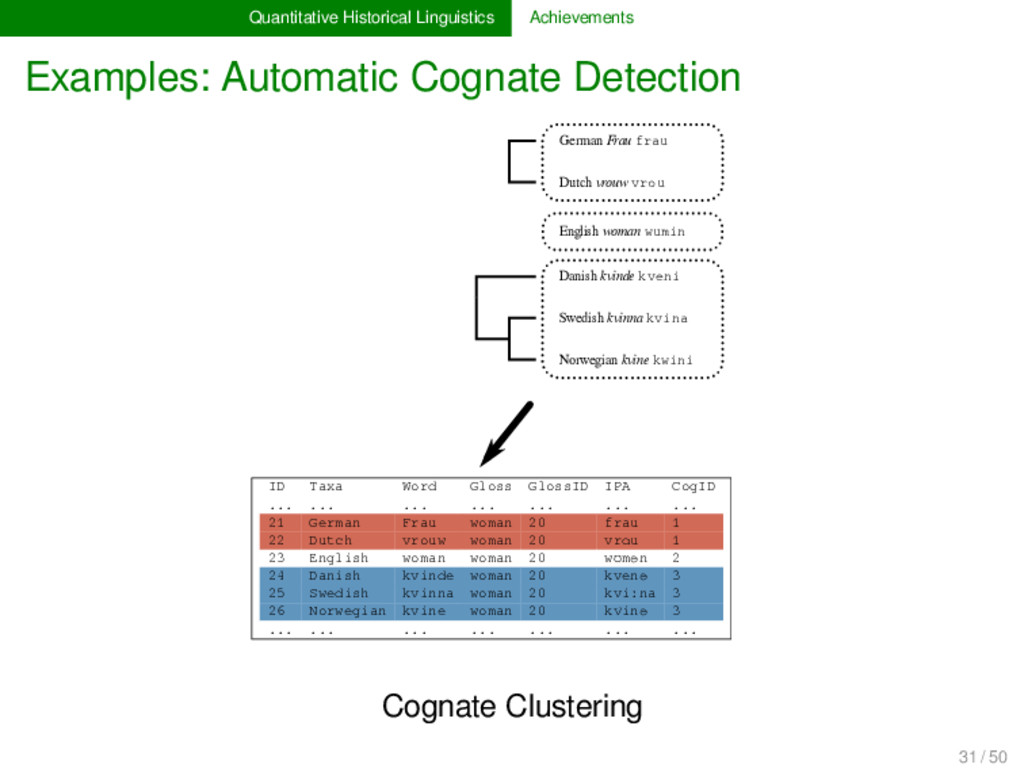
(SCA, List 2012 a) Sound classes and alignment analyses can be combined. Sound sequences are internally represented as sound classes. Alignments are carried out using standard algorithms developed in evolutionary biology. 28 / 50
(SCA, List 2012 a) Sound classes and alignment analyses can be combined. Sound sequences are internally represented as sound classes. Alignments are carried out using standard algorithms developed in evolutionary biology. INPUT tɔxtər dɔːtər TOKENIZATION t, ɔ, x, t, ə, r d, ɔː, t, ə, r CONVERSION t ɔ x … → T O G … d ɔː t … → T O T … ALIGNMENT T O G T E R T O - T E R CONVERSION T O G … → t ɔ x … T O - … → d oː - … OUTPUT t ɔ x t ə r d ɔː - t ə r 1 28 / 50
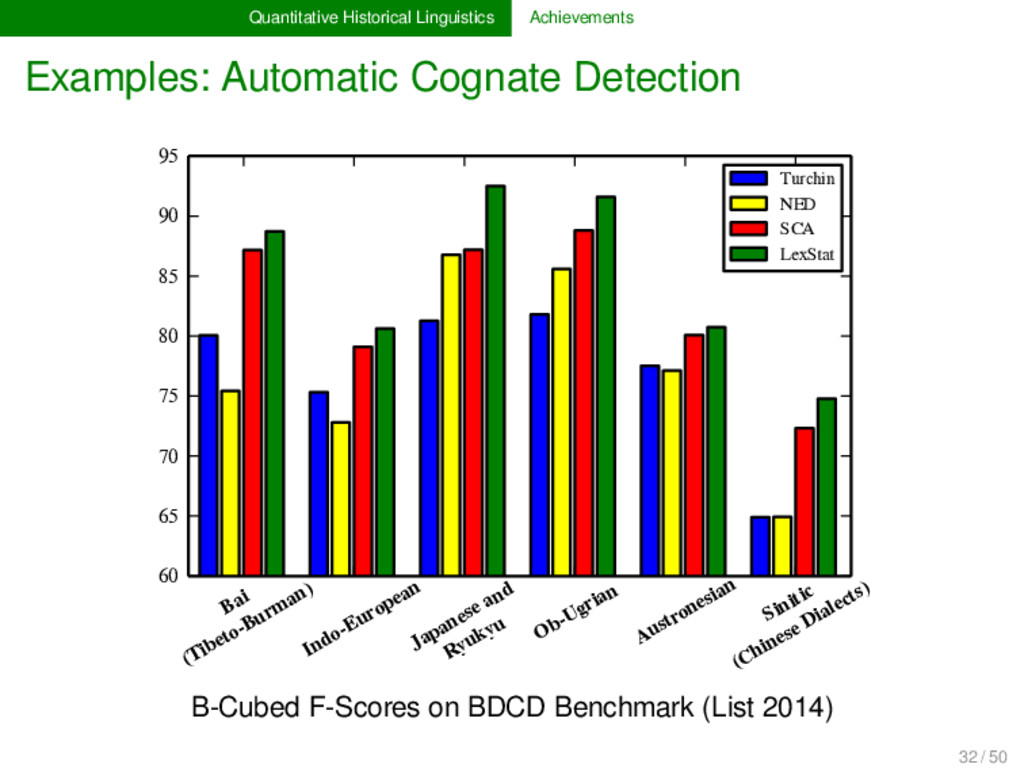
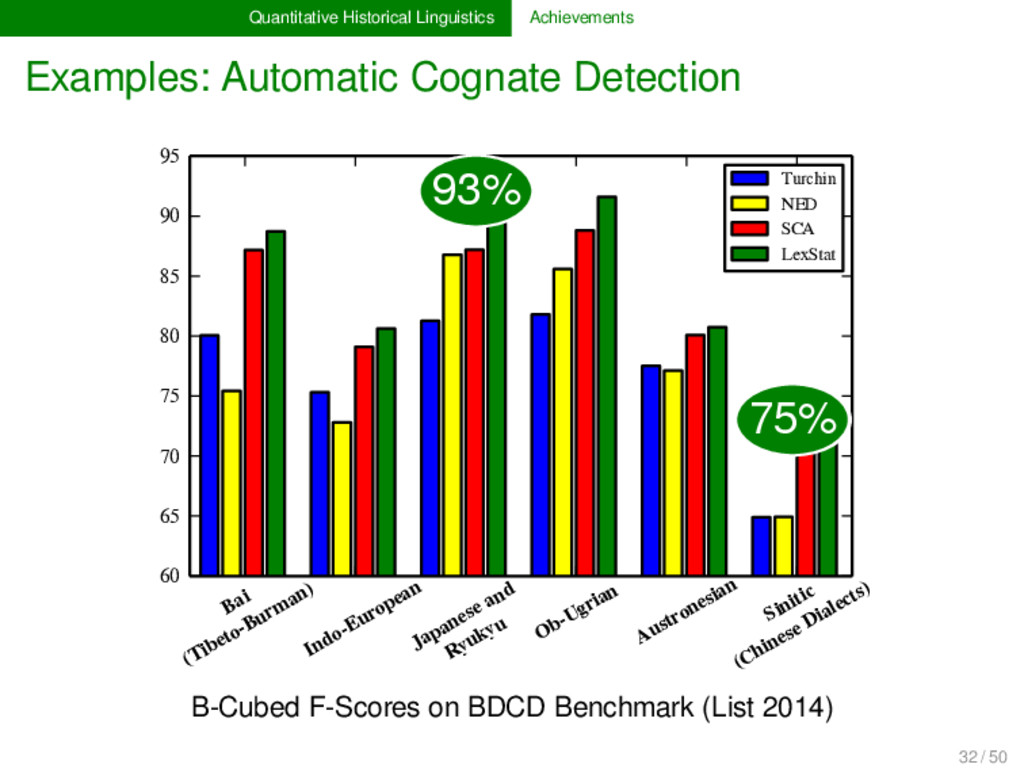
accuracy of more than 90 % for multiple alignment analyses, using the conservative column scores as evaluation scores. SCA can be applied to almost all languages, including tone languages (clicks are not yet supported), provided the data is given in regular phonetic transcription. SCA models prosodic properties of sound sequences and scores sound segments differently, depending on their position in the sequence, thereby accounting for general theories of prosodic strength . SCA is integrated in LingPy (http://lingpy.org, List & Moran 2013, an open source Python toolkit for quantitative tasks in historical linguistics and has been successfully tested on all major platforms (Mac, Linux, Microsoft). 29 / 50
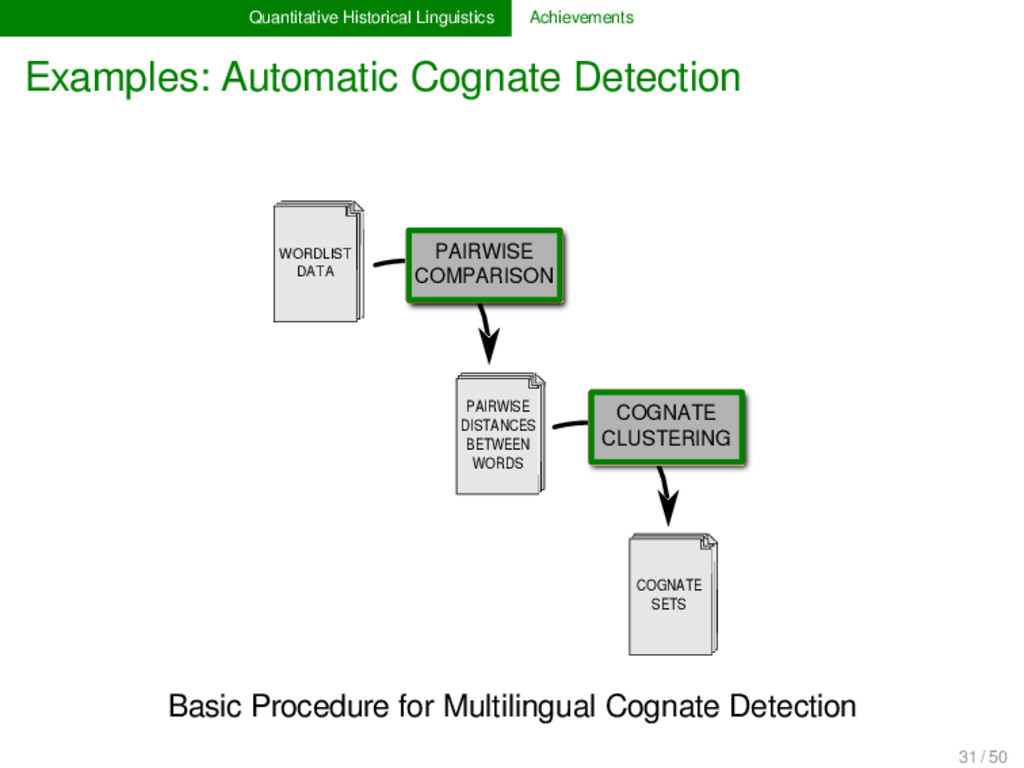
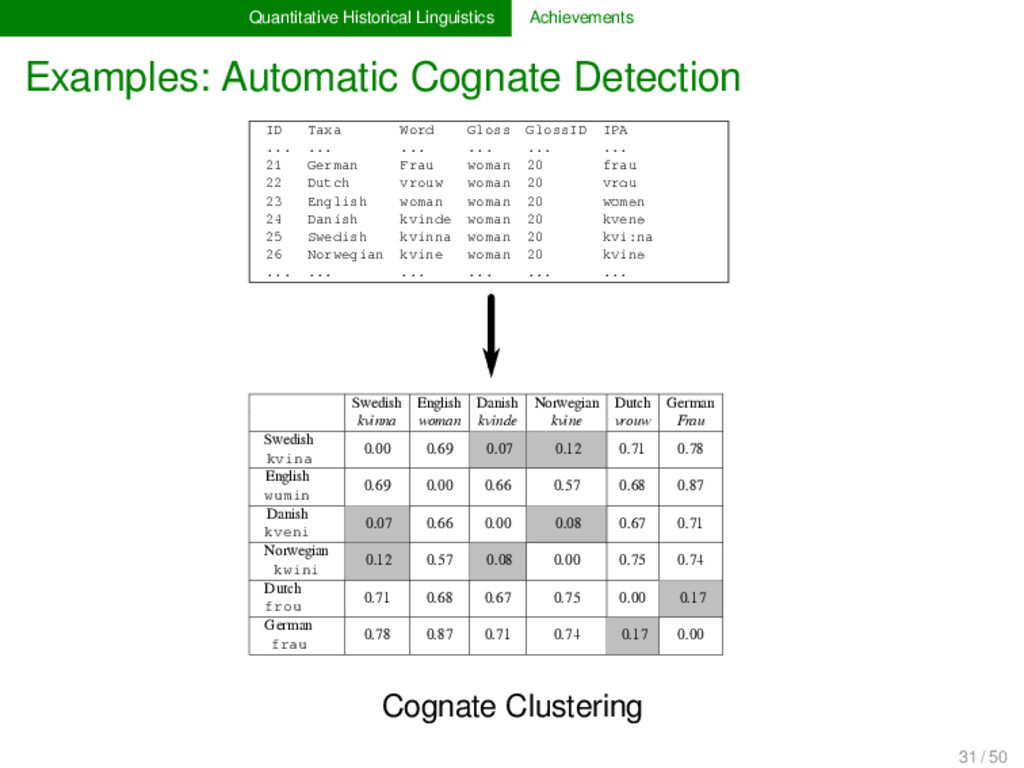
2012, List 2014) LexStat is a method for automatic cognate detection in multilingual wordlists. It uses on sound-class-based sequence alignment (SCA) analyses as a proxy to infer language-specific sound similarities (similar to the notion of sound correspondences in historical linguistics). Using the automatically inferred sound similarities, LexStat partitions words into cognate sets. 30 / 50
& Martin 2007, Dagan et al. 2008) 1 collect phyletic pattern data (shared gene families) of the taxa that shall be investigated 2 use gain-loss mapping techniques with different weighting models, allowing for different amounts of gain events to analyze how the gene families evolved along a given reference tree 3 use ancestral genome sizes as an external criterion to determine the best weighting model 4 assume that all patterns for which the best model yields more than one gain event result from lateral gene transfer 5 reconstruct a minimal lateral network (MLN) by connecting multiple gains for the same gene family by lateral edges 34 / 50
et al. 2011, List et al. 2014a) 1 collect phyletic pattern data (shared cognates) of the languages that shall be investigated 2 use gain-loss mapping techniques with different weighting models, allowing for different amounts of to analyze how the cognates evolved along a given reference tree 3 use ancestral vocabulary size distributions as an external criterion to determine the best weighting model 4 allow for a substantial amount (5%) of parallel evolution 5 assume that all patterns for which the best model yields more than one gain event result from lateral gene transfer 6 reconstruct a minimal lateral network by connecting multiple gains of the same cognate by lateral edges 35 / 50
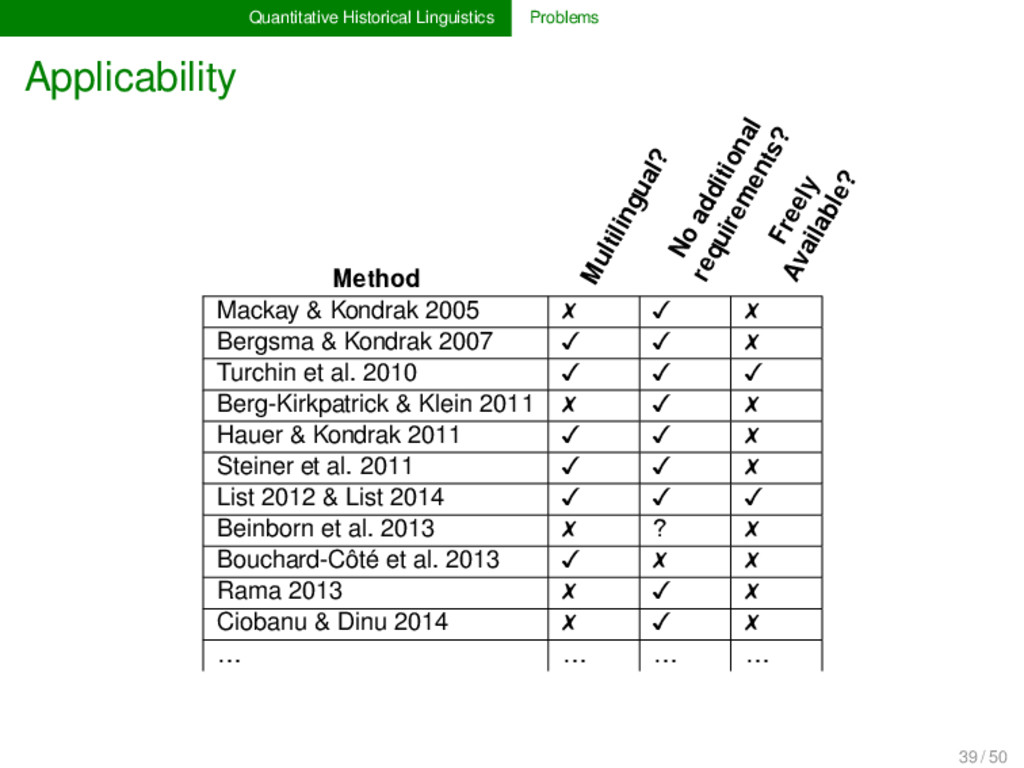
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. 38 / 50
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. It is difficult to communicate the results to traditional linguists. 38 / 50
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. It is difficult to communicate the results to traditional linguists. → Many linguists regard automatic approaches as 38 / 50
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. It is difficult to communicate the results to traditional linguists. → Many linguists regard automatic approaches as – not trustworthy and error-prone, or 38 / 50
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. It is difficult to communicate the results to traditional linguists. → Many linguists regard automatic approaches as – not trustworthy and error-prone, or – “impossible per se”, or 38 / 50
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. It is difficult to communicate the results to traditional linguists. → Many linguists regard automatic approaches as – not trustworthy and error-prone, or – “impossible per se”, or – as useful as “rolling a dice”. 38 / 50
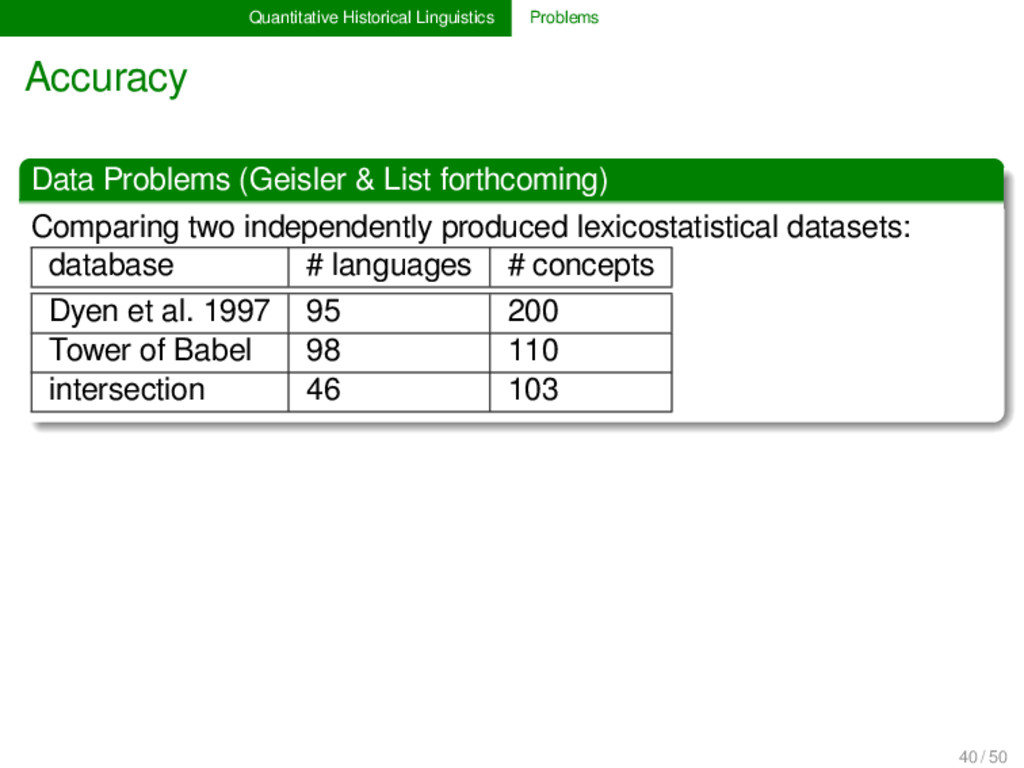
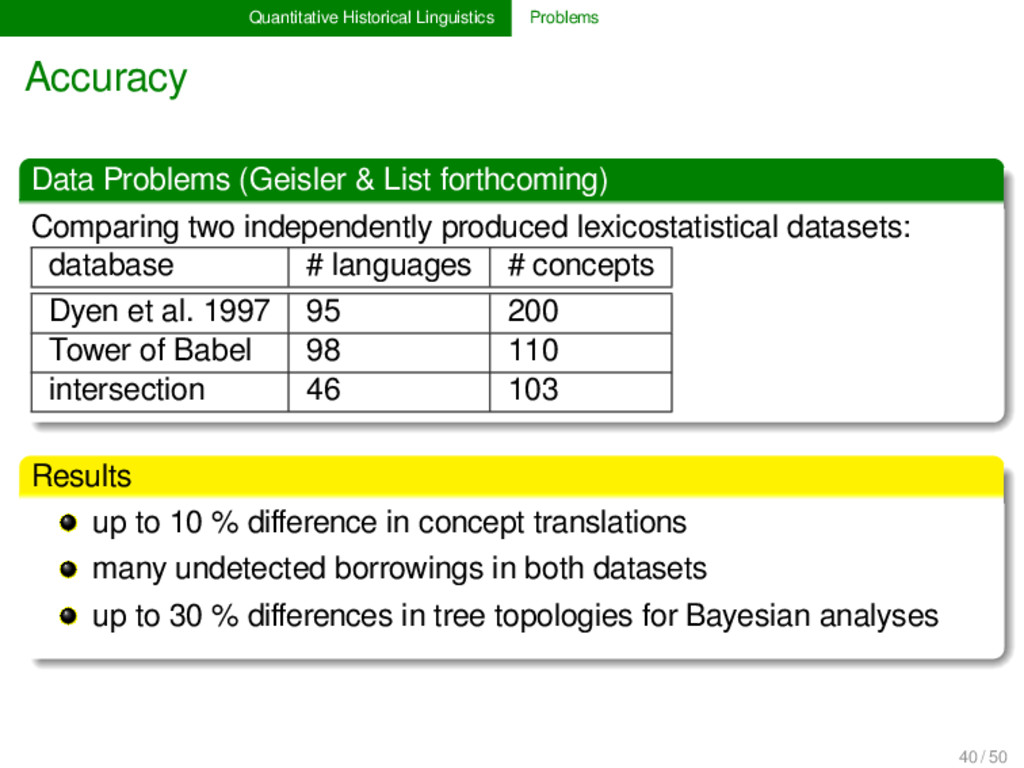
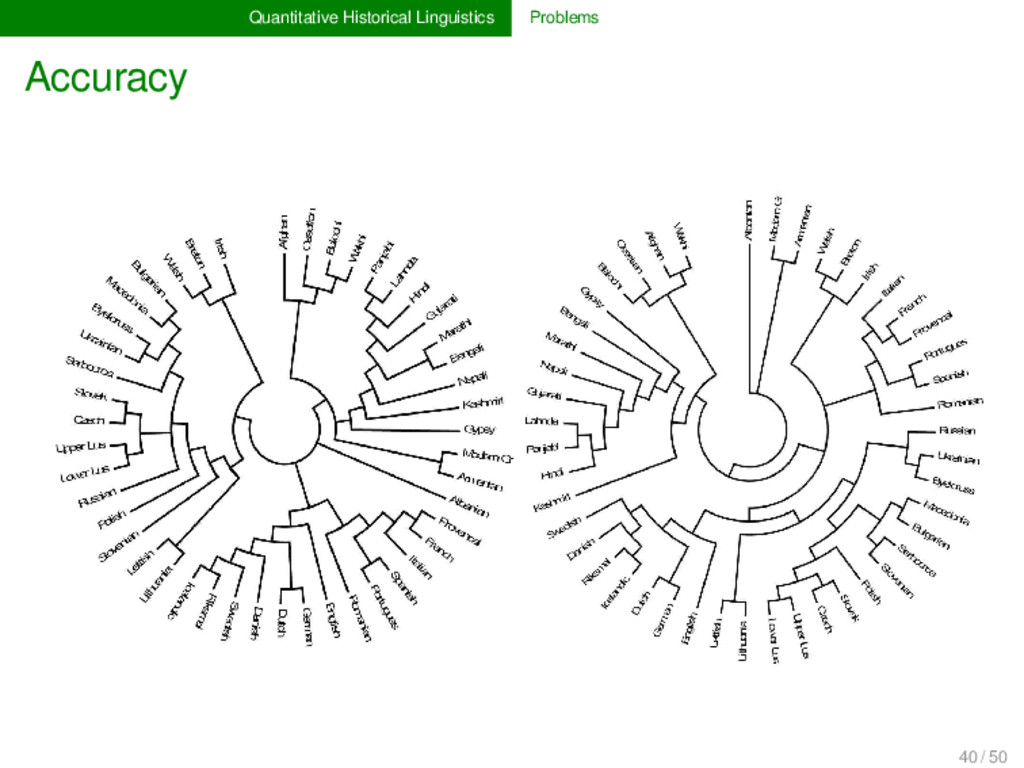
forthcoming) Comparing two independently produced lexicostatistical datasets: database # languages # concepts Dyen et al. 1997 95 200 Tower of Babel 98 110 intersection 46 103 Results up to 10 % difference in concept translations many undetected borrowings in both datasets up to 30 % differences in tree topologies for Bayesian analyses 40 / 50
based on manually compiled datasets cannot cope with errors resulting from inconsistent data compilation. They are only as objective as the data being fed to them! Many quantitative approaches are insufficiently tested, and scholars are often content with results traditional linguists would never accept. Additionally, quantitative approaches are often presented in a way that makes it hard (not only for traditional linguists) to understand what they are based upon. Results are reported in an intransparent way, supplementary data is often lacking, concrete examples are seldom provided and source code (essential to check and replicate analyses) is missing in almost all recent publications. 41 / 50
far, the majority of computational approaches in histori- cal linguistics largely disregards the actual needs of histori- cal linguistics. Despite the frequent claims that the algorith- ms are intended to supplement traditional research, many of them are mere attempts to prove the power of modern machine learning approaches and completely disregard the achievements of traditional research in historical linguistics. 43 / 50
we really want to make a difference with computational ap- proaches and not simply seek to replace every expert who likes books with a computer or abacus, we need to work much, much harder, on a real integration of computational and traditional approaches. 43 / 50
FRANZ BOPP VERY, VERY LONG TITLE Apart from “computational historical linguistics”, we need to establish a new discipline of “computer-aided historical linguistics”. Such a framework needs bench- marks and new standards to cope with general problems of quantitati- ve approaches. However, such a framework will also need additional resources that help traditional approaches to leave the “realm of intuition”. 43 / 50
benchmark databases have been compiled and published: Benchmark Database of Phonetic Alignments (BDPA, List & Prokić 2014, http://alignments.lingpy.org) Benchmark Database for Cognate Detection (BDCD, presented in List 2014, http://sequencecomparison.github.io). Benchmark Database for Linguistic Reconstruction (BDLR, in preparation). 45 / 50
data is given in phonetic transcriptions (IPA), tokenized into phonemic units, freely available for download, and can be directly used in LingPy. 45 / 50
approaches hide essential aspects of their analyses. These aspects are not only valid to test the power of methods, but also to get the best out of the results. Aggregation of results is useful for publications, but we know, that “every word has its own history”, and traditional research has always been concerned with this. Visualizing and reporting all detailed decisions and findings of automatic methods will not only increase their transparency, it may also help convincing traditional scholars that computational approaches may provide valuable insights. Apart from static visualizations, JavaScript and HTML5 offer unique ways for interactive data visualization and make it easy to produce, share, and explore what automatic methods have produced. So far, we have develop JavaScript prototype tools that – visualize phonetic alignments of cognate sets (JavaScript Cognate Viewer, JCOV, http://github.com/dighl/jcov/), – allow to edit and refine alignments and cognate sets online using online tools (Etymological Dictionary Editor, EDICTOR, http://tsv.lingpy.org), and – tools that visualize phylogenetic trees in geographic space (together with T. Mayer, Tree Explorer, TREX, http://github.com/dighl/TREX). 46 / 50
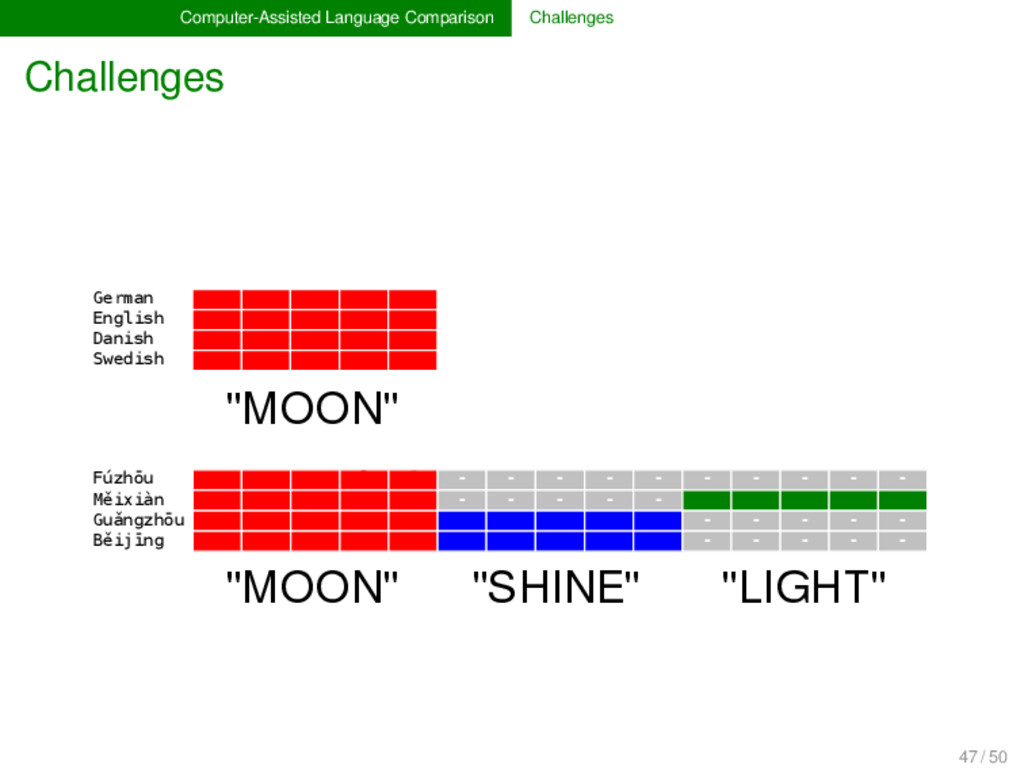
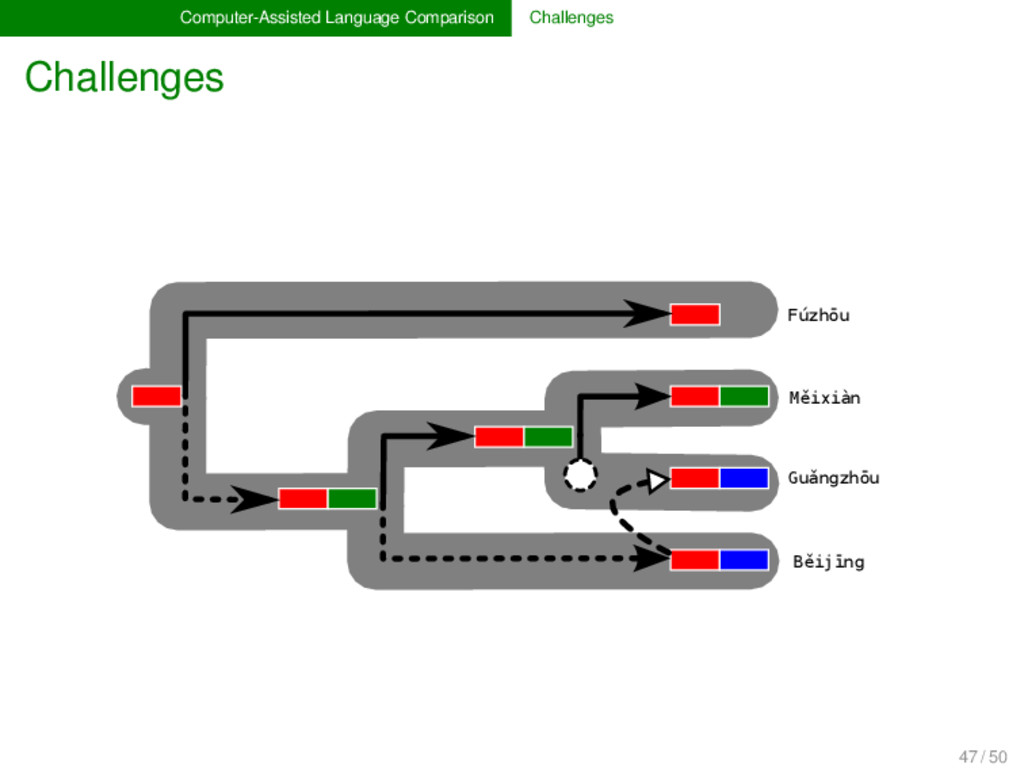
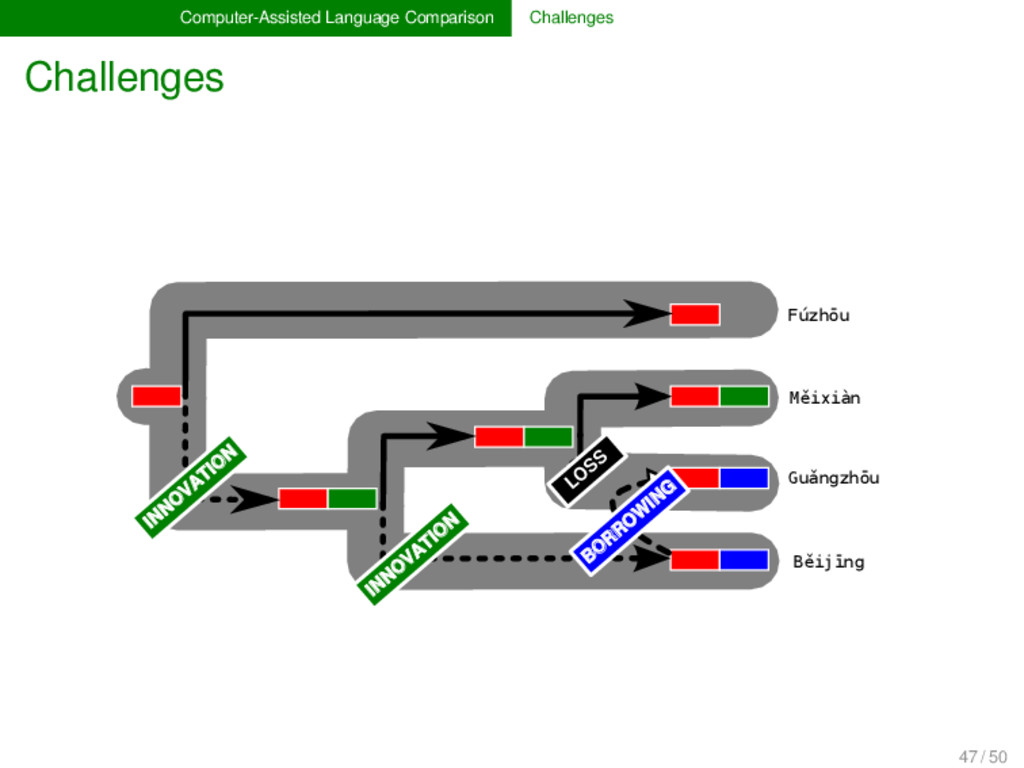
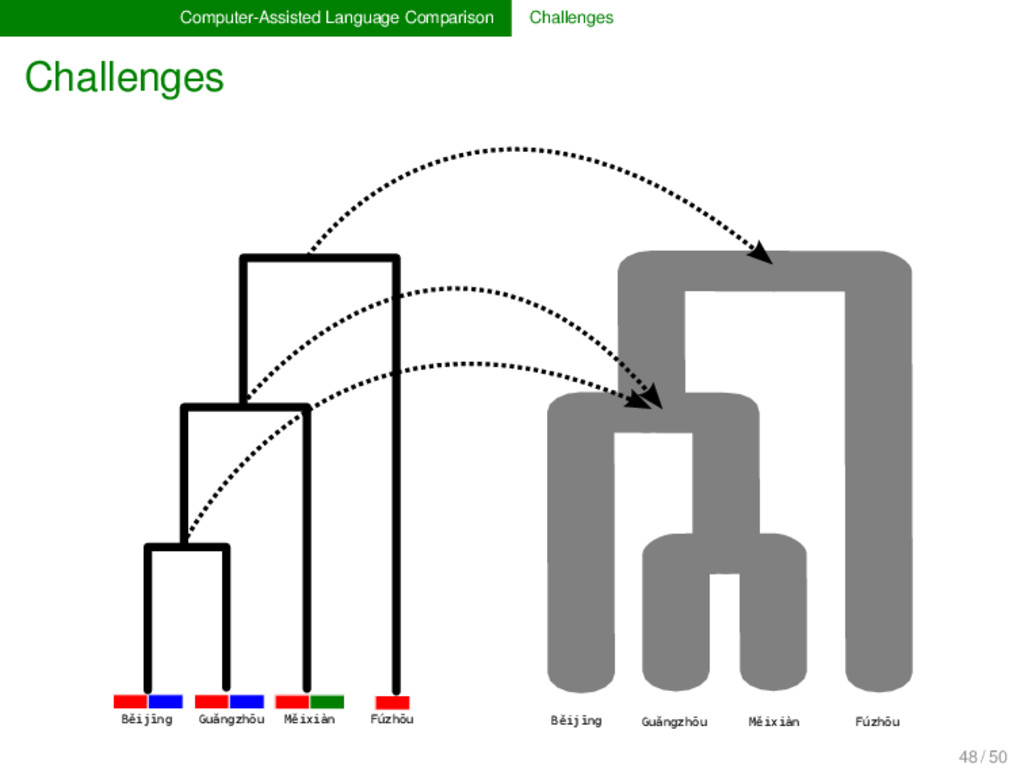
- English m uː n - - Danish m ɔː n - ə Swedish m oː n - e Fúzhōu ŋ u o ʔ ⁵ - - - - - - - - - - Měixiàn ŋ i a t ⁵ - - - - - k u o ŋ ⁴⁴ Guǎngzhōu j - y t ² l - œ ŋ ²² - - - - - Běijīng - y ɛ - ⁵¹ l i ɑ ŋ - - - - - - 47 / 50
- English m uː n - - Danish m ɔː n - ə Swedish m oː n - e Fúzhōu ŋ u o ʔ ⁵ - - - - - - - - - - Měixiàn ŋ i a t ⁵ - - - - - k u o ŋ ⁴⁴ Guǎngzhōu j - y t ² l - œ ŋ ²² - - - - - Běijīng - y ɛ - ⁵¹ l i ɑ ŋ - - - - - - "MOON" "MOON" "SHINE" "LIGHT" 47 / 50
the multiple dimensions of lexical change, we need new methods and models in historical linguistics, which ex- plicitly deal with borrowing, partial cognacy, and semantic change. Following the lead of evolutionary biology, these methods could be combined under a unified framework of tree reconciliation (Page & Cotton 2002) in historical linguistics. 48 / 50
linguistics. Nevertheless, the majority of the new approaches shows a great lack in transparency and applicability. One reason for this is the gap between traditional and computational approaches which are mostly applied independently from each other. 49 / 50
linguistics. Nevertheless, the majority of the new approaches shows a great lack in transparency and applicability. One reason for this is the gap between traditional and computational approaches which are mostly applied independently from each other. In order to increase the interaction between traditional and computational historical linguists, we need a paradigm shift in historical linguistic. 49 / 50
linguistics. Nevertheless, the majority of the new approaches shows a great lack in transparency and applicability. One reason for this is the gap between traditional and computational approaches which are mostly applied independently from each other. In order to increase the interaction between traditional and computational historical linguists, we need a paradigm shift in historical linguistic. Computational linguists need to increase the transparency of their results, focusing on their detailed and interactive presentation instead of hiding behind numbers. 49 / 50
linguistics. Nevertheless, the majority of the new approaches shows a great lack in transparency and applicability. One reason for this is the gap between traditional and computational approaches which are mostly applied independently from each other. In order to increase the interaction between traditional and computational historical linguists, we need a paradigm shift in historical linguistic. Computational linguists need to increase the transparency of their results, focusing on their detailed and interactive presentation instead of hiding behind numbers. Traditional linguists need to increase the transparency of their methods, focusing on formalizing their intuitions instead of hiding behind their “expert insights”. 49 / 50
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}