Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Solrイントロダクション #TechLunch
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Livesense Inc.
PRO
April 21, 2014
Technology
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Solrイントロダクション #TechLunch
Solrイントロダクション
2012/10/31 (水) @ Livesense TechLunch
発表者:松永 一郎
Livesense Inc.
PRO
April 21, 2014
More Decks by Livesense Inc.
See All by Livesense Inc.
Rubyはただの⾔語に⾮ず
livesense
PRO
0
430
28新卒_Webエンジニア職採用_会社説明資料
livesense
PRO
0
110
27新卒_総合職採用_会社説明資料
livesense
PRO
0
6k
27新卒_Webエンジニア職採用_会社説明資料
livesense
PRO
0
11k
株式会社リブセンス・転職会議 採用候補者様向け資料
livesense
PRO
0
510
株式会社リブセンス 会社説明資料(報道関係者様向け)
livesense
PRO
1
1.7k
データ基盤の負債解消のためのリプレイス
livesense
PRO
0
640
26新卒_総合職採用_会社説明資料
livesense
PRO
0
13k
株式会社リブセンス会社紹介資料 / Invent the next common.
livesense
PRO
2
69k
Other Decks in Technology
See All in Technology
Baseline対応のDOMの型定義を作った
uhyo
3
720
知見・人・API・DB・予算 ─ ナイナイ尽くしだった人事データ整備 with dbt、5年間の学び
ken6377
1
170
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
12
4.9k
そのタスクオンスケですか?
poropinai1966
0
140
フルカイテン株式会社 エンジニア向け採用資料
fullkaiten
0
11k
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
400
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
210
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
3
3k
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
1
2.4k
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
130
小さいから、全部わかる。— 常駐AI "xangi" のすすめ
sugupoko
0
270
テスト設計の本質を改めて考えてみる~生成AIを活用する時代だからこそ、作ったテストの説明性を高めよう~
yamasaki696
1
390
Featured
See All Featured
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Context Engineering - Making Every Token Count
addyosmani
9
1k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Optimizing for Happiness
mojombo
378
71k
Become a Pro
speakerdeck
PRO
31
6k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
770
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
A designer walks into a library…
pauljervisheath
211
24k
Abbi's Birthday
coloredviolet
3
8.5k
Everyday Curiosity
cassininazir
0
250
Transcript
Solr使ってみた レジュメオープン化への適用
はじめに(免責事項) すいません。現在時刻、2012/10/31 (水) 16:22 ようするに、当日に作ってるありさまです。 な、わけなんで、ちょっと内容荒くてすいません。そ して、よみにくいです。すいません。 一時はキャンセルする事も考えたのですが、
が頭をよぎったんで、がんばりました。
なにを話すか そもそもsolrは全文検索出来る言うけど、詳細には 何が出来るの?って話をします。 転職会議のサブプロジェクトである所のレジュメ オープン化プラットフォームに於いてメインの検索 エンジンとして使う際の、使い所的な話とかをする つもりです。
簡単なSolrの出来る事説明 Solr自体は、 • なにかしらのデータ(mysqlだったり、xmlだった りテキストだったり、なんでも良い)を、要素(更新 日付とかタイトルとか本文とか)に分けて、イン デックス化し、そのインデックスをフィールドと呼 ばれる部分に格納する • フィールドを指定して、文言検索する。
という事が出来ます。
Solrデータ構造 +: n件保持 -: 1件保持 solr + doc -uniqueKey (fieldの特種な形)
+field [+|-] value +dynamic field [+|-] value
fieldについて fieldはvalueを持ちます。valueにデータの対応要 素のインデックス情報が入ります。 設定によってはデータそのものも入れる事が出来 ます。 検索する場合には、このfieldに、query文字列であ るところの「◦◦」が入ってるdocを頂戴的に行ない ます。
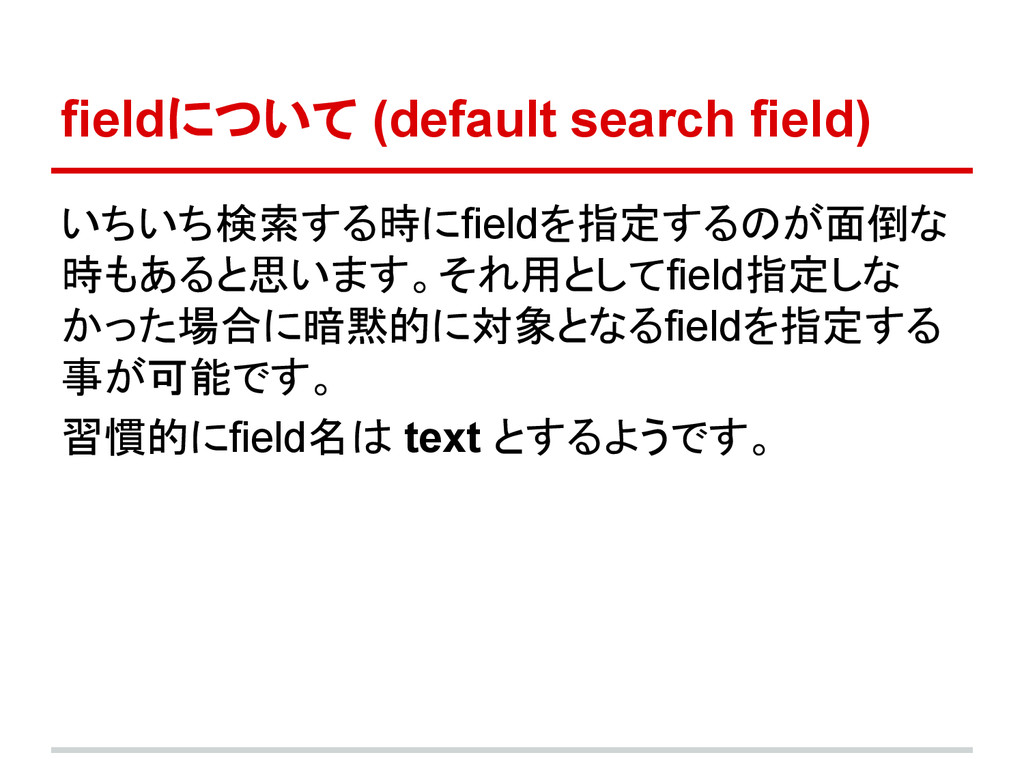
fieldについて (default search field) いちいち検索する時にfieldを指定するのが面倒な 時もあると思います。それ用としてfield指定しな かった場合に暗黙的に対象となるfieldを指定する 事が可能です。 習慣的にfield名は text
とするようです。
fieldについて (multi valued) 1fieldに複数のvalueを入れる事が可能です。 例えば、メールの場合、検索する際に、subjectも fromもtoもbodyもdateも串刺しで検索したい場合、 投入する1 fieldに全部投入して、そのfieldを対象 に検索する事が可能です。
fieldについて (multi valued) filedとしてSubject, From, To, Body, Dateを定義 し、それぞれにそれぞれの要素のindexを格納す る。また、text
fieldにもそれぞれの要素のindexを 格納する事が可能と言う事です。 subjectで絞りたい時にはsubject fieldに対して、 発信日時で絞りたい時にはdate fieldに対して queryを発行。 あるいはそれらをグチャグチャでquery発行したい 場合は、text fieldに対して発行。
field (型: fieldType) fieldは型を持ちます。正しく言うと、fieldが保持す るvalueの型です。 型とは、簡単に言うと、インデックス化する際に、ど のように単語を分かち書きしますか?定義みたい なものです。 もちろん、int,boolean, floatなどもありますが、メイ
ンとなるのは、string型をどのように分かち書きしま すかによる型の設計になります。
fieldType 例えば、日本語を対象とするfieldの場合ですが、 • 辞書で分かち書きしたいfieldの場合 • n-gramで分かち書きしたいfieldの場合 • 英語等のように空白で分かち書きしたfieldの場合 などがあると思います。 それらを、それぞれ、
• text_ja • text_n_ja • text_en のような型を宣言/設定し、各fieldはどの型を利用するかを記述 します。
dynamic field 今迄説明して来たfieldは、事前に定義体で、この fieldはこういう名前で、こういうvalue(型)で入れる と設定する必要がありました。 でも、各docに動的にfieldを足す事も出来ます。そ のfieldがdynamic fieldです。
dynamic field レジュメの場合、スキルという項目があり、 • TOEIC: 713 • 英検: 1級 •
会話: ビジネス用途 • java: 2年 みたいに、複数持つ事があると思います。 また、検索する際に、「TOEIC 500点以上」、かつ、「javaを3年 以上」、自己PRに「火消し」が入っているで絞りたい場合がある と思います。
dynamic field どんなスキルがあるかをマスタ管理する方法もあると思います が、複数メディアを統合するサービスだとそれもなかなか大変 かと思います。 また、フリーワード検索との併用が難しい(mysqlのqueryとsolr へのqueryの2段回呼び出しが必要になる)状態になります。
dynamic field それらを全てsolrに寄せる事が可能なのが、 dynamic fieldになります。 データ投入の際に、dynamic filedとして、TOEIC fieldや、英検 filedを足し、valueとして、700や1等 を設定し、queryとして英検
fieldが500以上でみた いなqueryが発行出来ます。
dynamic field skill fieldを作り、その下にkey:valueで入れればい いじゃん的な発想もあると思いますが、valueは index情報が入る場所なので、fieldの入れ子は出 来ません。
fieldがどう保持されているか 実際の値 (エンジニアでtext fieldを検索) curl 'http://localhost:8983/solr/select?indent=on&version=2.2&q=%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82% A2&fq=&start=0&rows=10&indent=on' ..... <doc> <date
name="created_at">2012-09-26T15:09:02Z</date> <int name="id">29299</int> <arr name="job_category"><str>生産技術_機械_</str><str>生産技術・生産管理・プロセス開発(電気・電子) </str><str>生産技術・生産管 理・プロセス開発(半導体) </str></arr> <str name="job_content">【具体的な業務内容】 ... </str> <str name="pr_content">私たちの会社は、一人ひとりの エンジニアによって....</str> <str name="pr_title">1人ひとりの... </str> <arr name="text"> <str>1人ひとりの... </str> <str>【具体的な業務内容】 ... </str> </arr> <date name="updated_at">2012-09-26T15:21:16Z</date> <float name="生産技術_機械__ja">6.3</float> <float name="生産技術・生産管理・プロセス開発(半導体) _ja">8.9</float> <float name="生産技術・生産管理・プロセス開発(電気・電子) _ja">3.6</float> </doc> .....
dynamic field query: select w.id, jc.name from partner_work w inner
join patner_work_job_relation jr on (w.id = jr.partner_work_id) inner join job_small_category jc on (jr.job_small_category_id = jc.id) where w.id = 29299; result: *************************** 1. row *************************** id: 29299 name: 生産技術(機械) *************************** 2. row *************************** id: 29299 name: 生産技術・生産管理・プロセス開発(電気・電子) *************************** 3. row *************************** id: 29299 name: 生産技術・生産管理・プロセス開発(半導体) 3 rows in set (0.00 sec)
dynamic field 生産技術(機械)のfieldが6〜9の範囲値を持つ情報を抽出 $ curl 'http://localhost:8983/solr/select?indent=on&version=2.2&q=%E7%94%9F%E7%94%A3%E6% 8A%80%E8%A1%93_%E6%A9%9F%E6%A2%B0__ja%3A%5B6+TO+9% 5D&fq=&start=0&rows=10&fl=id+%E7%94%9F%E7%94%A3%E6%8A%80%E8%A1%93_%E6%A9% 9F%E6%A2%B0__ja&indent=on&wt=csv' id,生産技術_機械__ja
95,7.3 234,7.6 368,7.0 1183,6.2 1189,7.0 1356,8.7 1528,7.8 1540,6.8 1582,6.3 1801,8.8
わかちがきとsynonym なかなか調整が難しいです。 詳細は実演で。
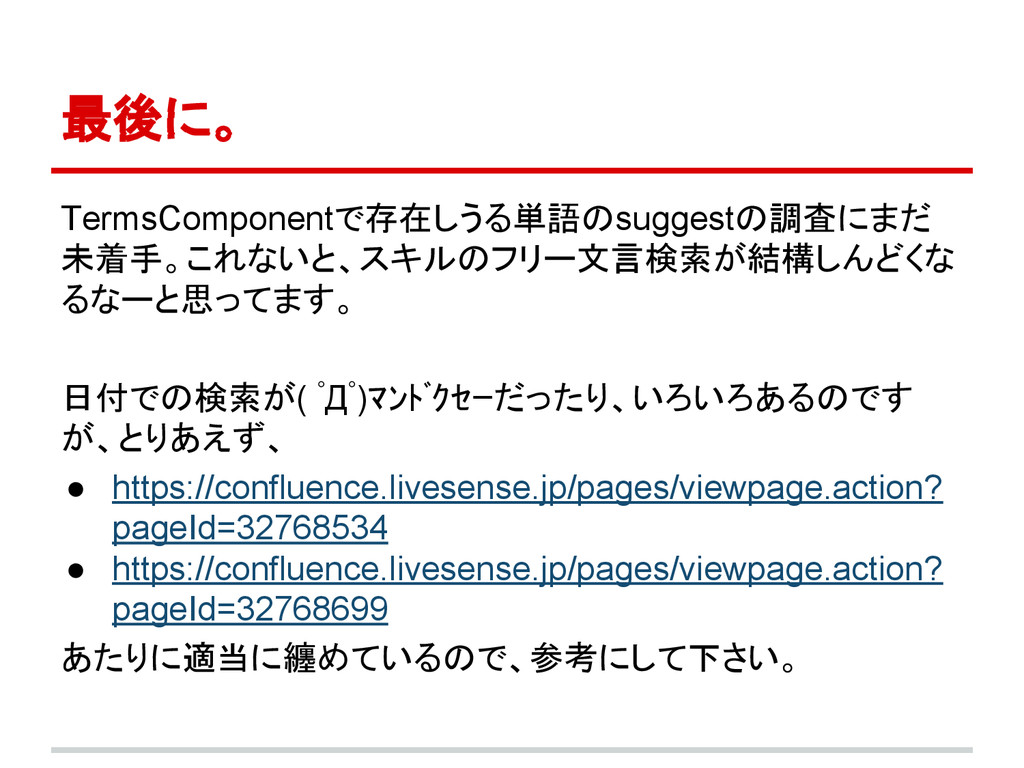
最後に。 TermsComponentで存在しうる単語のsuggestの調査にまだ 未着手。これないと、スキルのフリー文言検索が結構しんどくな るなーと思ってます。 日付での検索が( ゚Д゚)マンドクセーだったり、いろいろあるのです が、とりあえず、 • https://confluence.livesense.jp/pages/viewpage.action? pageId=32768534
• https://confluence.livesense.jp/pages/viewpage.action? pageId=32768699 あたりに適当に纏めているので、参考にして下さい。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}