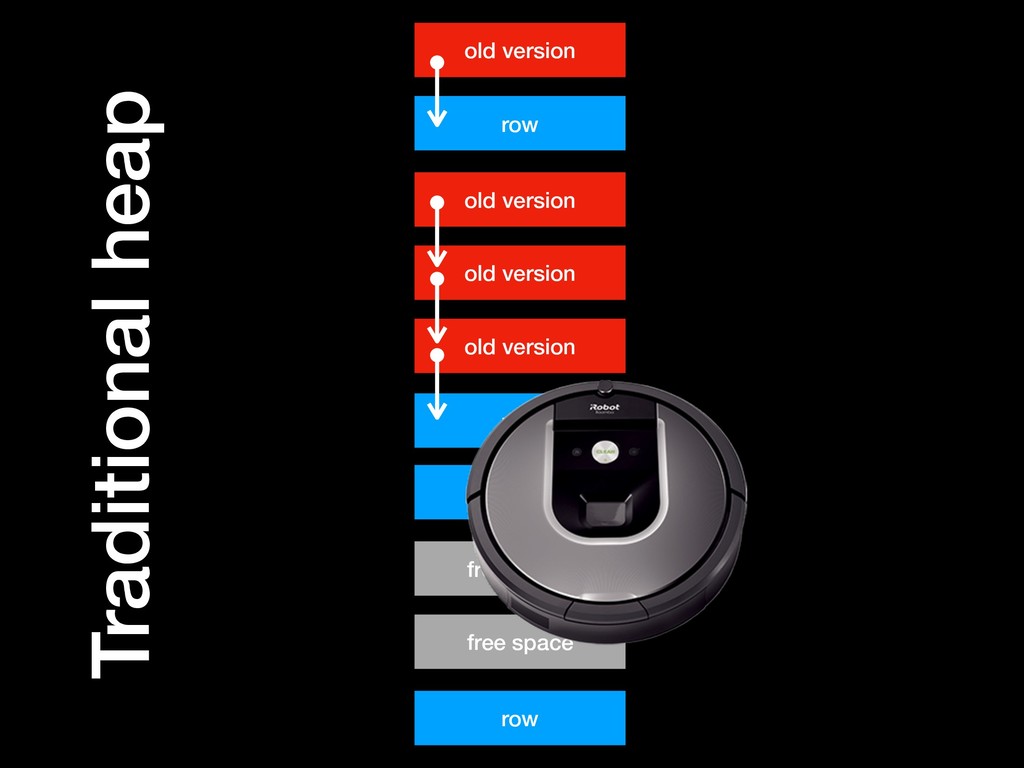
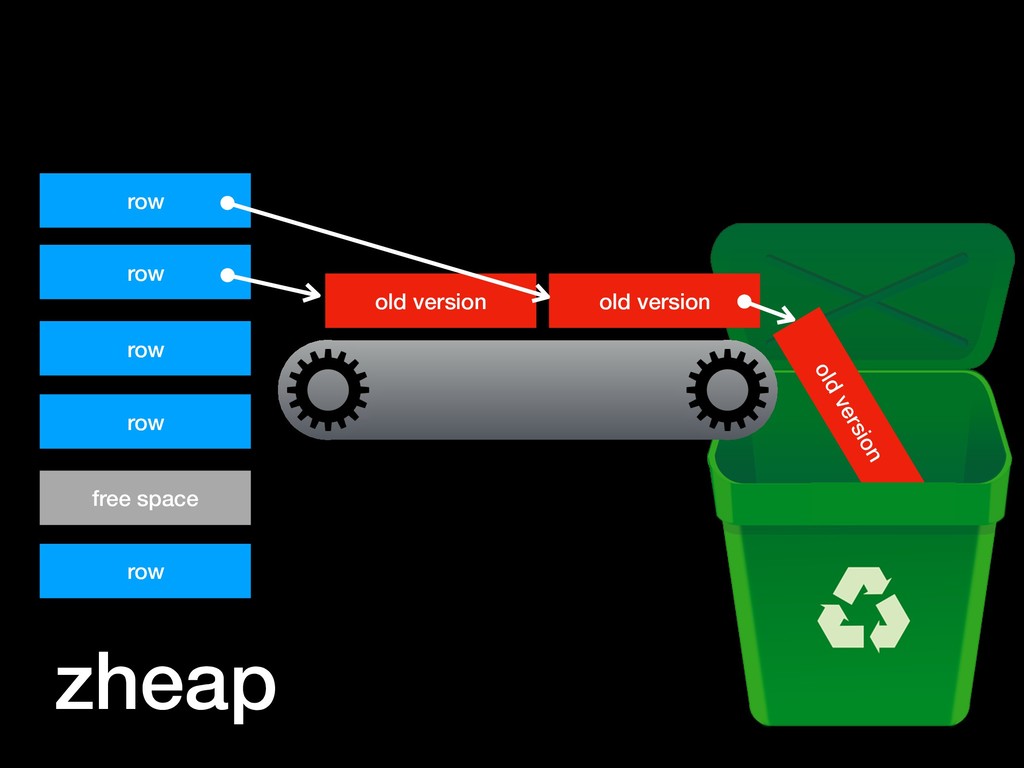
• efficient write access, optimised for many concurrent writers without contention; like logs • efficient discarding: the usual outcome is that transactions is that data is discarded without ever being written to disk; like a queue • efficient read access through shared buffers, because the data they hold is needed for MVCC; older snapshots need to read it quickly; like a relation
tablespace | discard | insert | end | xid | pid ------------+-------------+------------+------------------+------------------+------------------+-----+------- 0 | permanent | pg_default | 000000000000004A | 000000000000004A | 0000000000400000 | 559 | 56156 1 | permanent | pg_default | 00000100009C1908 | 00000100009C1908 | 0000010001000000 | 562 | 56163 2 | permanent | pg_default | 000002000000004A | 000002000000004A | 0000020000400000 | 563 | 56174 (3 rows) • The meta-data used for space management within each undo log is: discard <= insert <= end. Discard and insert we have met; end shows unused space that has been allocated on disk. • We also track the currently attached backend and xid, if there is one. These are visible in the pg_stat_undo_logs view.
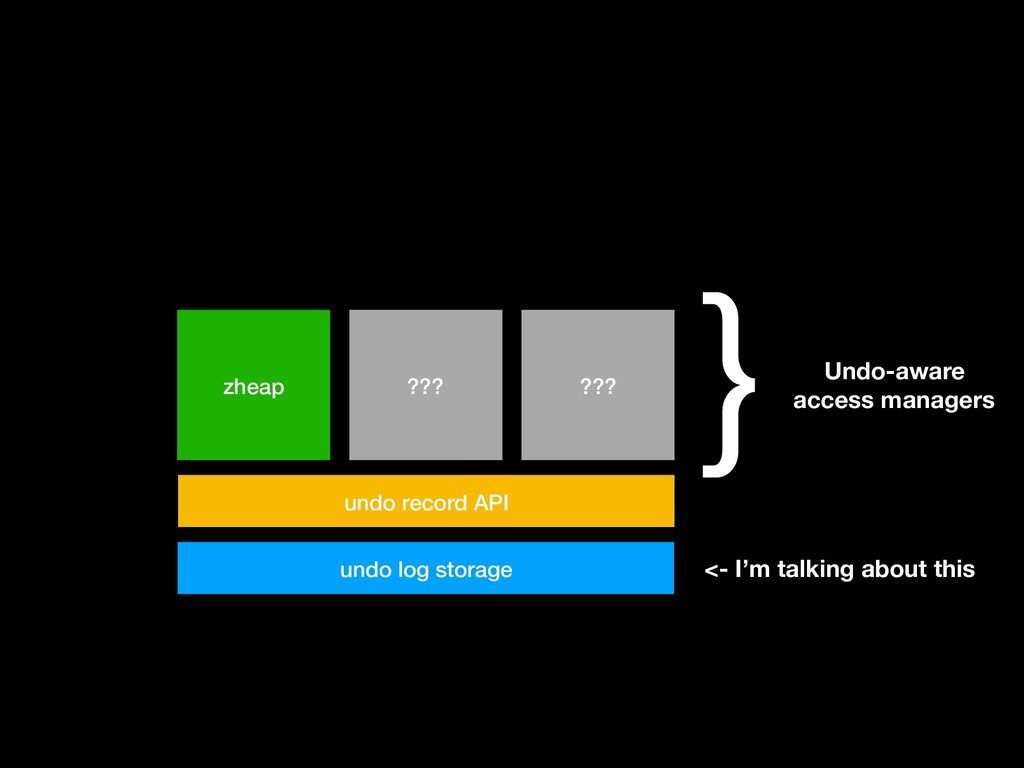
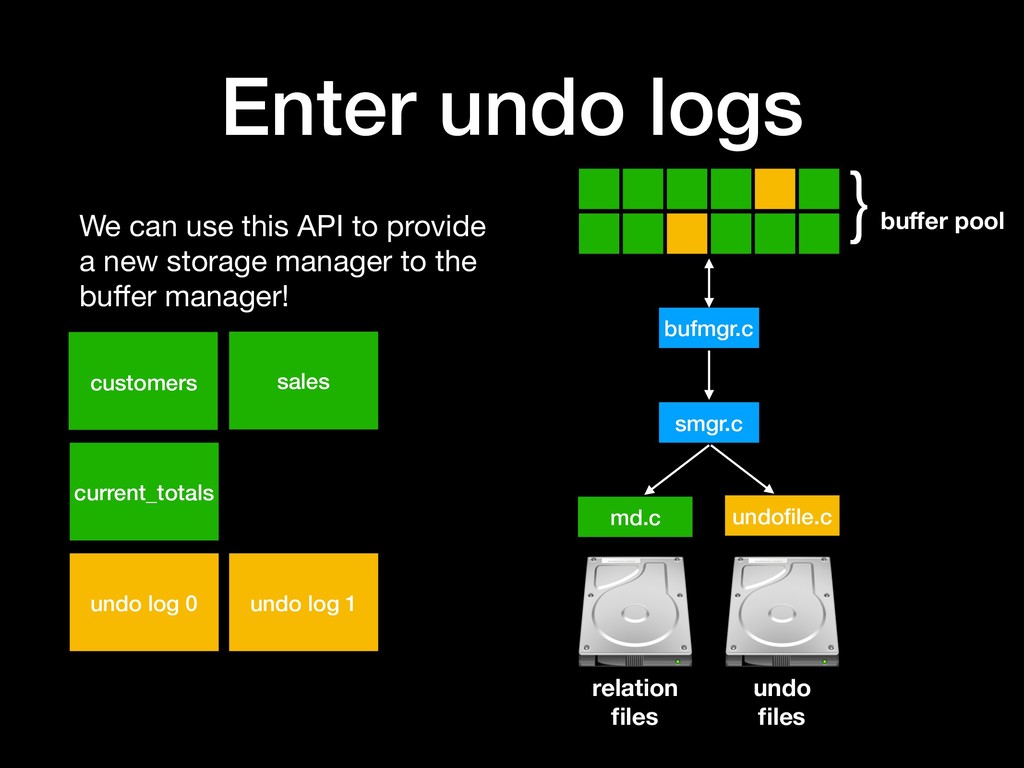
to three undo logs at a given time, where it will write new data: • A “permanent” one for undo data from persistent relations; discarded only when no longer needed for rollback or MVCC • An “unlogged” one for undo data from persistent relations; as above but also deleted on startup after crash • A “temporary” one for for undo data from temporary relations; temporary buffers, deleted at startup
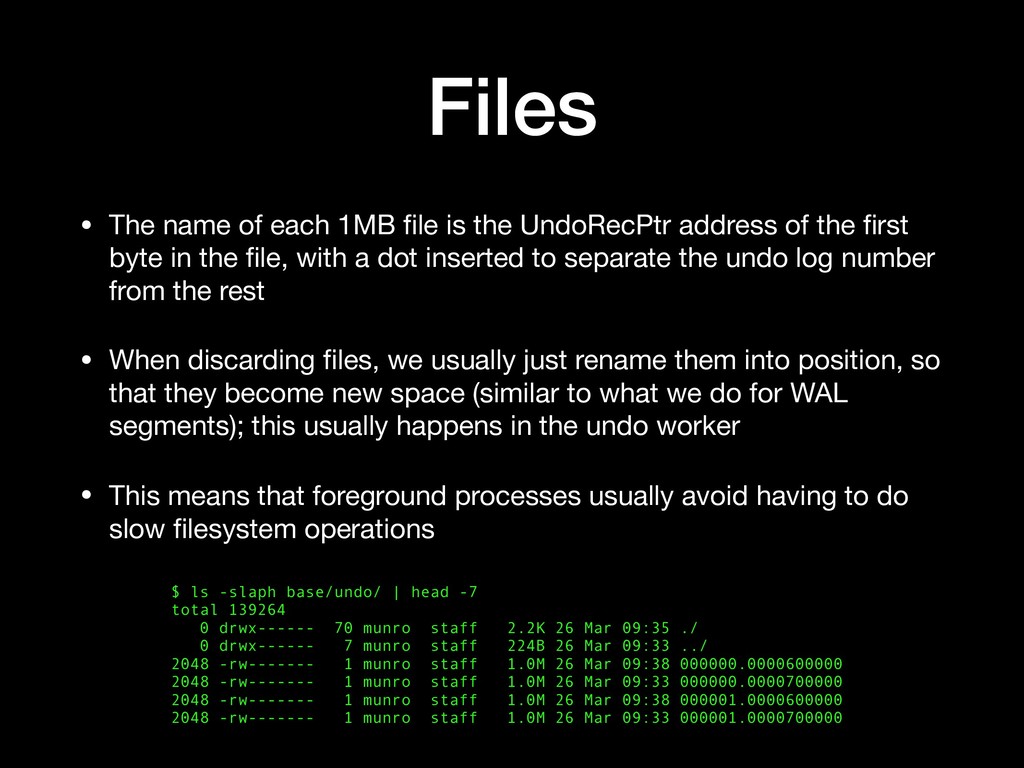
UndoRecPtr address of the first byte in the file, with a dot inserted to separate the undo log number from the rest • When discarding files, we usually just rename them into position, so that they become new space (similar to what we do for WAL segments); this usually happens in the undo worker • This means that foreground processes usually avoid having to do slow filesystem operations $ ls -slaph base/undo/ | head -7 total 139264 0 drwx------ 70 munro staff 2.2K 26 Mar 09:35 ./ 0 drwx------ 7 munro staff 224B 26 Mar 09:33 ../ 2048 -rw------- 1 munro staff 1.0M 26 Mar 09:38 000000.0000600000 2048 -rw------- 1 munro staff 1.0M 26 Mar 09:33 000000.0000700000 2048 -rw------- 1 munro staff 1.0M 26 Mar 09:38 000001.0000600000 2048 -rw------- 1 munro staff 1.0M 26 Mar 09:33 000001.0000700000
(creating, unlinking, renaming segment files) • Filesystem operations are synchronous and must be fsync()ed, but they usually happen in the background • Note that changes to insert pointers are not WAL logged explicitly!
set undo_tablespaces = ts1; SET postgres=# insert into foo values (42); INSERT 0 1 postgres=# select * from pg_stat_undo_logs where tablespace = 'ts1'; log_number | persistence | tablespace | discard | insert | end | xid | pid ------------+-------------+------------+------------------+------------------+------------------+--------+------- 60 | permanent | ts1 | 00003C0000000018 | 00003C0000000018 | 00003C0000100000 | 189257 | 46137 (1 row) postgres=# drop tablespace ts1; DROP TABLESPACE 2018-03-28 15:44:50.265 NZDT [46137] LOG: created undo segment "pg_tblspc/16416/PG_11_201802061/undo/00003C.0000000000" • GUC “undo_tablespaces” controls where your session writes undo data (similar to “temp_tablespaces”) • Tablespace can only be dropped when contained undo logs are empty (no attached transactions in progress, fully discarded); attached sessions will be forcibly detached
PostgreSQL: • “steal”: if you need a buffer and none are free, you steal one (write it out to disk if dirty); “no force”: committing doesn’t require writing out dirty buffers • buffers are written out by checkpoints and by “stealing” (= memory pressure); otherwise they don’t have to be written to disk • the checkpointer calls fsync() at appropriate times • We want all this existing machinery for free for our undo logs! • We also need a new way to “forget” buffers holding discarded data, to avoid all IO completely if we’re lucky
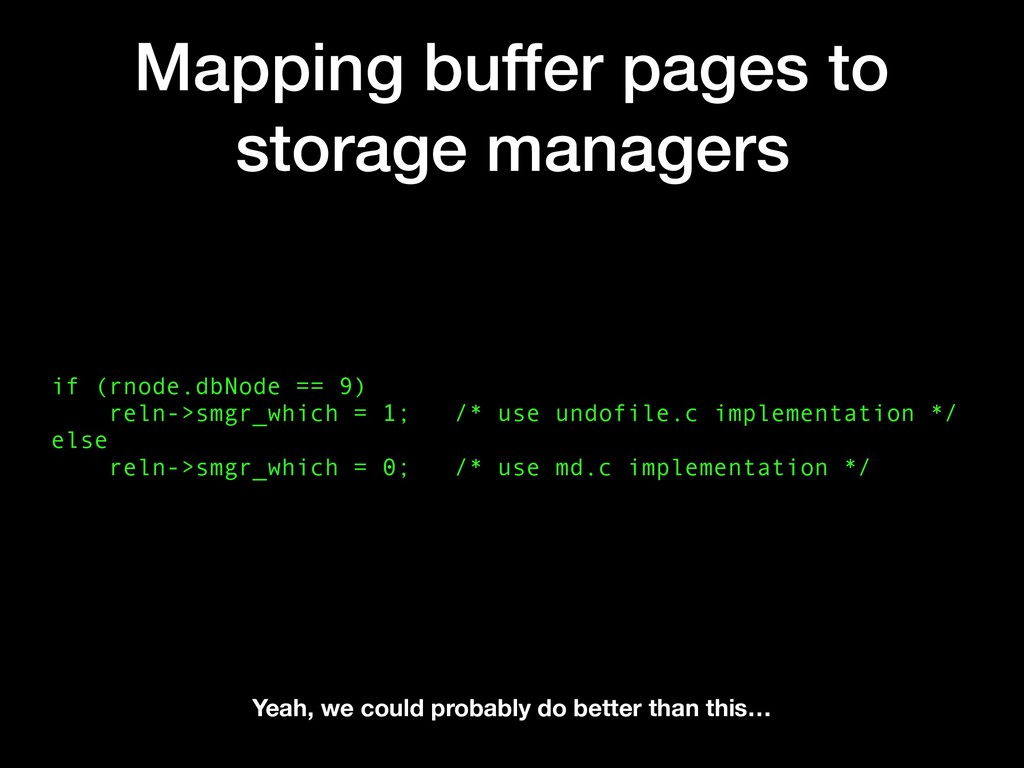
reln->smgr_which = 1; /* use undofile.c implementation */ else reln->smgr_which = 0; /* use md.c implementation */ Yeah, we could probably do better than this…
inserting (pgbench): • rarely write undo data to disk (only at checkpoints) • recycle same 1-2 buffers constantly • If not able to discard (long lived snapshot): • compete with other buffer pool contents • … need ring? … different page reclamation?
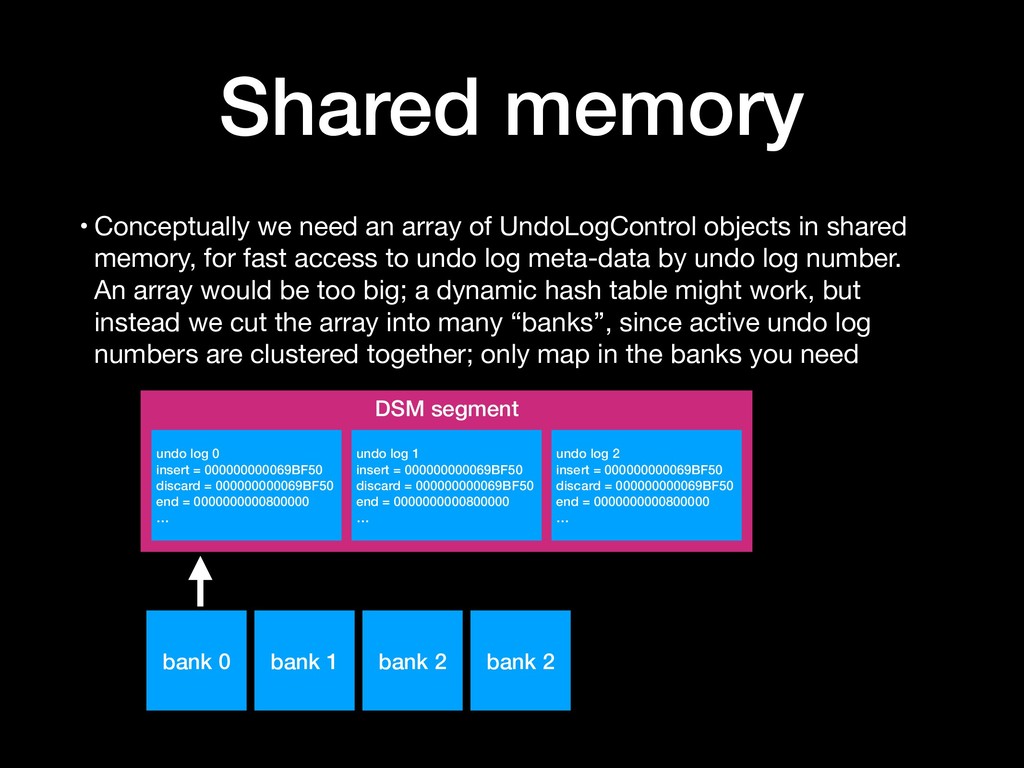
discard = 000000000069BF50 end = 0000000000800000 … undo log 1 insert = 000000000069BF50 discard = 000000000069BF50 end = 0000000000800000 … undo log 2 insert = 000000000069BF50 discard = 000000000069BF50 end = 0000000000800000 … bank 0 bank 1 bank 2 • Conceptually we need an array of UndoLogControl objects in shared memory, for fast access to undo log meta-data by undo log number. An array would be too big; a dynamic hash table might work, but instead we cut the array into many “banks”, since active undo log numbers are clustered together; only map in the banks you need bank 2
of all meta-data from shared memory into an undo log checkpoint file under pg_undo. • For shutdown checkpoints, these are by definition consistent (no concurrent activity is allowed) • For online checkpoints, these contain a snapshot of each undo log’s meta-data from some arbitrary moment after the redo point, which is a problem…
WAL record is written to each undo log after a checkpoint (ie after the redo point of a checkpoint), we first write an undo log ‘meta data’ record, which will compensate for the inconsistencies in the undo checkpoint file. All writes after that can omit the location because it’s implied, reducing WAL size. • When I showed this slide at pgcon unconf, I had something here about why we don’t need full_page_writes, but that was wrong: we do need them, but we can probably use REGBUF_WILL_INIT or something similar to avoid them almost always; I’m looking into that…
association between sessions (= backends) and undo logs (ie currently attached) • At “REDO” time, sessions are gone: everything will be replayed by the start-up process. So we maintain an xid- >undo log mapping during recovery • The first time any transaction writes to any undo log, it writes an “attach” record in the WAL
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}