【Gotanda.unity #7】及び【札幌HoloLens ミートアップ vol.2 ~夏編~】にて登壇したときの発表資料です。
※「おまけ」については【Gotanda.unity #7】の発表時にて追加
● Gotanda.unity #7 in 株式会社ミクシィ @渋谷
https://gotanda-unity.connpass.com/event/92616/?utm_campaign=event_participate_to_follower&utm_medium=twitter&utm_source=notifications
● 札幌HoloLens ミートアップ vol.2 ~夏編~ LT資料
https://hololens.connpass.com/event/90368/
▼ スライド中のリンク
・今回実装したやつ
https://twitter.com/TEST_H_/status/1019018416798162944
▼ 検証用リポジトリ
https://github.com/mao-test-h/DokabenLogoVR
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
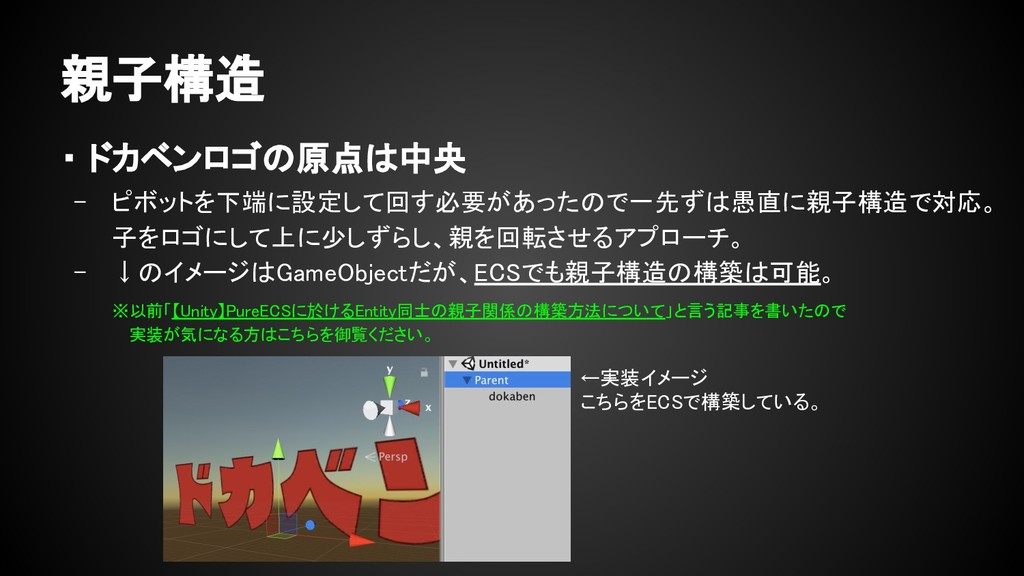{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}