Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
COLING読み会2020_Graph Enhanced Dual Attention Net...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
maskcott
January 11, 2021
Research
64
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
COLING読み会2020_Graph Enhanced Dual Attention Network for Document-Level Rlation Extraction
maskcott
January 11, 2021
More Decks by maskcott
See All by maskcott
論文紹介2022後期(EMNLP2022)_Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer
maskcott
0
77
論文紹介2022後期(ACL2022)_DEEP: DEnoising Entity Pre-training for Neural Machine Translation
maskcott
0
43
PACLIC2022_Japanese Named Entity Recognition from Automatic Speech Recognition Using Pre-trained Models
maskcott
0
46
WAT2022_TMU NMT System with Automatic Post-Editing by Multi-Source Levenshtein Transformer for the Restricted Translation Task of WAT 2022
maskcott
0
53
論文紹介2022前期_Redistributing Low Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
maskcott
0
66
論文紹介2021後期_Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
maskcott
0
83
WAT2021_Machine Translation with Pre-specified Target-side Words Using a Semi-autoregressive Model
maskcott
0
60
NAACL/EACL読み会2021_NEUROLOGIC DECDING: (Un)supervised Neural Text Generation with Predicate Logic Constraints
maskcott
0
47
論文紹介2021前期_Bilingual Dictionary Based Neural Machine Translation without Using Parallel Sentences
maskcott
0
54
Other Decks in Research
See All in Research
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
480
人間中心の意思決定支援AI
yukinobaba
PRO
6
3.1k
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
390
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
460
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
520
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
140
LLM Compute Infrastructure Overview
karakurist
2
1.5k
量子コンピュータの紹介
oqtopus
0
340
「車1割削減、渋滞半減、公共交通2倍」を 熊本から岡山へ@RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
1
1.2k
Can We Teach Logical Reasoning to LLMs? – An Approach Using Synthetic Corpora (AAAI 2026 bridge keynote)
morishtr
1
260
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
570
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
3.9k
Featured
See All Featured
BBQ
matthewcrist
89
10k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Chasing Engaging Ingredients in Design
codingconduct
0
230
We Are The Robots
honzajavorek
0
260
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Done Done
chrislema
186
16k
Agile that works and the tools we love
rasmusluckow
331
22k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
sira's awesome portfolio website redesign presentation
elsirapls
0
290
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Unsuck your backbone
ammeep
672
58k
Deep Space Network (abreviated)
tonyrice
0
210
Transcript
COLING2020 紹介者: 今藤誠一郎(TMU 小町研究室 B4) 2021/1/11 COLING読み会
概要 ・文書レベルの関係抽出には文間の推論能力が必要 ・Graph Enhanced Dual Attention network(GEDA)を用いて、文と潜在的なrelation instance 間の複雑な相互作用を特徴づけることを提案 ・既存のデータセットを用いた実験で、本モデルが特に文間の関係抽出において競争力
のある性能を発揮すること、ニューラルな予測が解釈可能かつ簡単に分かることを示し た
導入 関係抽出(RE)は与えられた文章とターゲットとなるentityから関係を検出するタスク 与えられる文章によって大きく二つに分類される 1) Sentence-level RE (Zeng et al., 2015;
Zhou et al., 2016; etc) 2) Document-level RE (Sahu et al., 2019; Gupta et al., 2019; etc) この論文で扱うのは2のタスク 2の方がより困難なタスク
導入 複数文と複数のrelation instance間の相互関係を特徴づけることで課題に取り組む ・1つの relation instance は複数の文によって表現されることがある ・1つの文が複数の事実関係を明らかにすることもある → 複雑な多対多の相互作用を捉えるために文と潜在的
relation instance 間のアテン ションを利用する ・Sentence-to-relation(S2R)とRelation-to-sentence(R2S)からなるbi-directionalなア テンションメカニズムを導入する
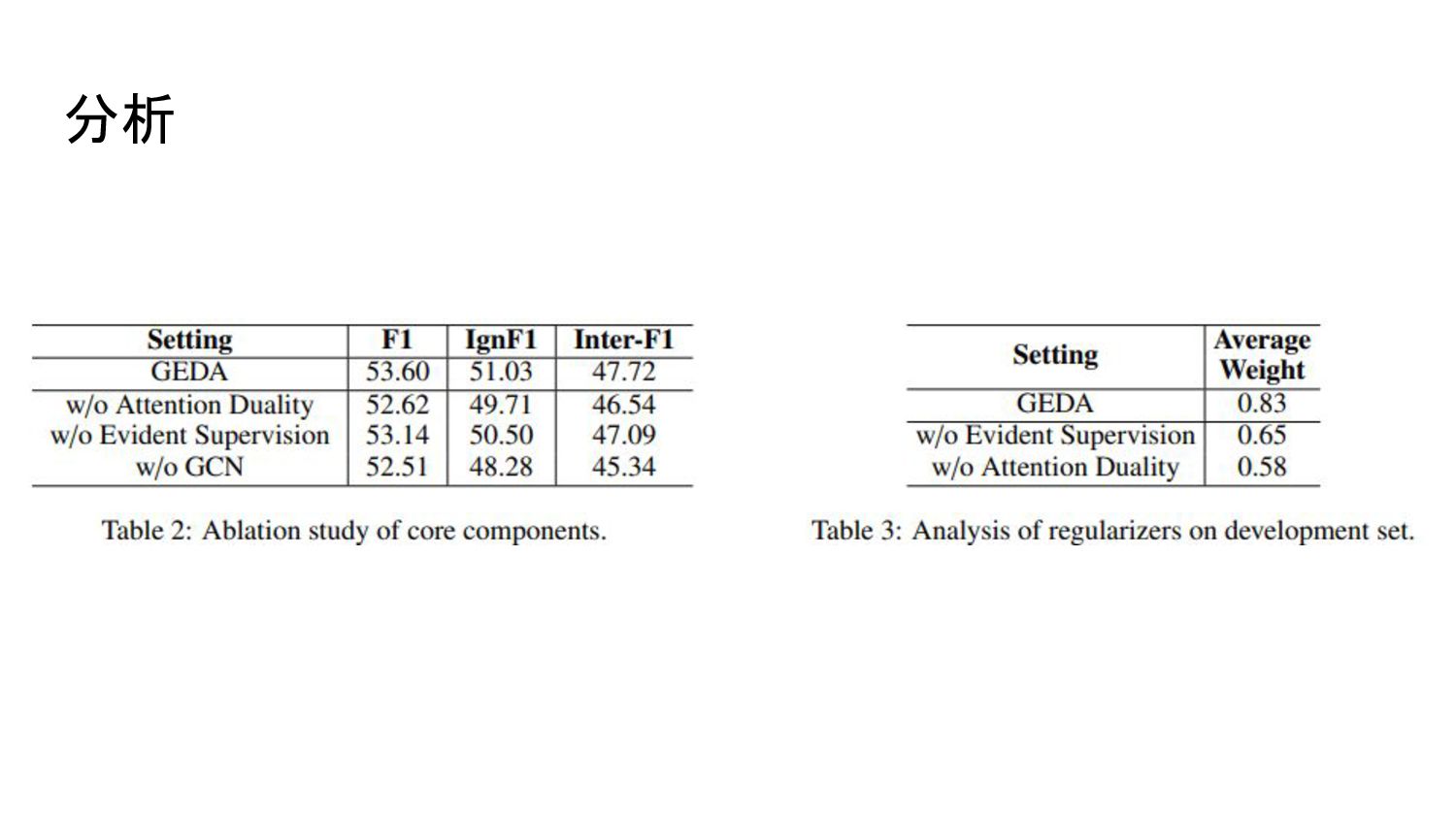
提案モデルの3つの特徴 1. 特定の事実関係を表現する文は文書の異なる位置に存在しうる →従来の手法ではノイズの多い文を含めて文情報を合成するので良くない →S2Rで生成された文表現をGCNで畳みこんで洗練してから合成し、R2Sに供給 することでより精度の高い潜在的 relation instanse の表現を得る 2.
S2RとR2Sの注意の二元性から単純で効果的な正則化器としての帰納バイアスを 利用 3. アテンションの重みを学習する際にR2Sの重みを教師付き信号とすることで relation instanceの根拠を学習に利用
貢献 ・文書レベルの関係抽出のためにGEDAを提案 →文と潜在的なrelation instanceの複雑な相互作用を特徴づけて文間の推論を改善で きた ・GEDAの新規性は1)グラフ強調操作、2)アテンションの二元性を正則化、3)根拠の裏 付けとなる教師アテンション、の3つが設計されている →文書レベルのREの性能向上と解釈可能性を提供するのに効果的であることが示さ れた
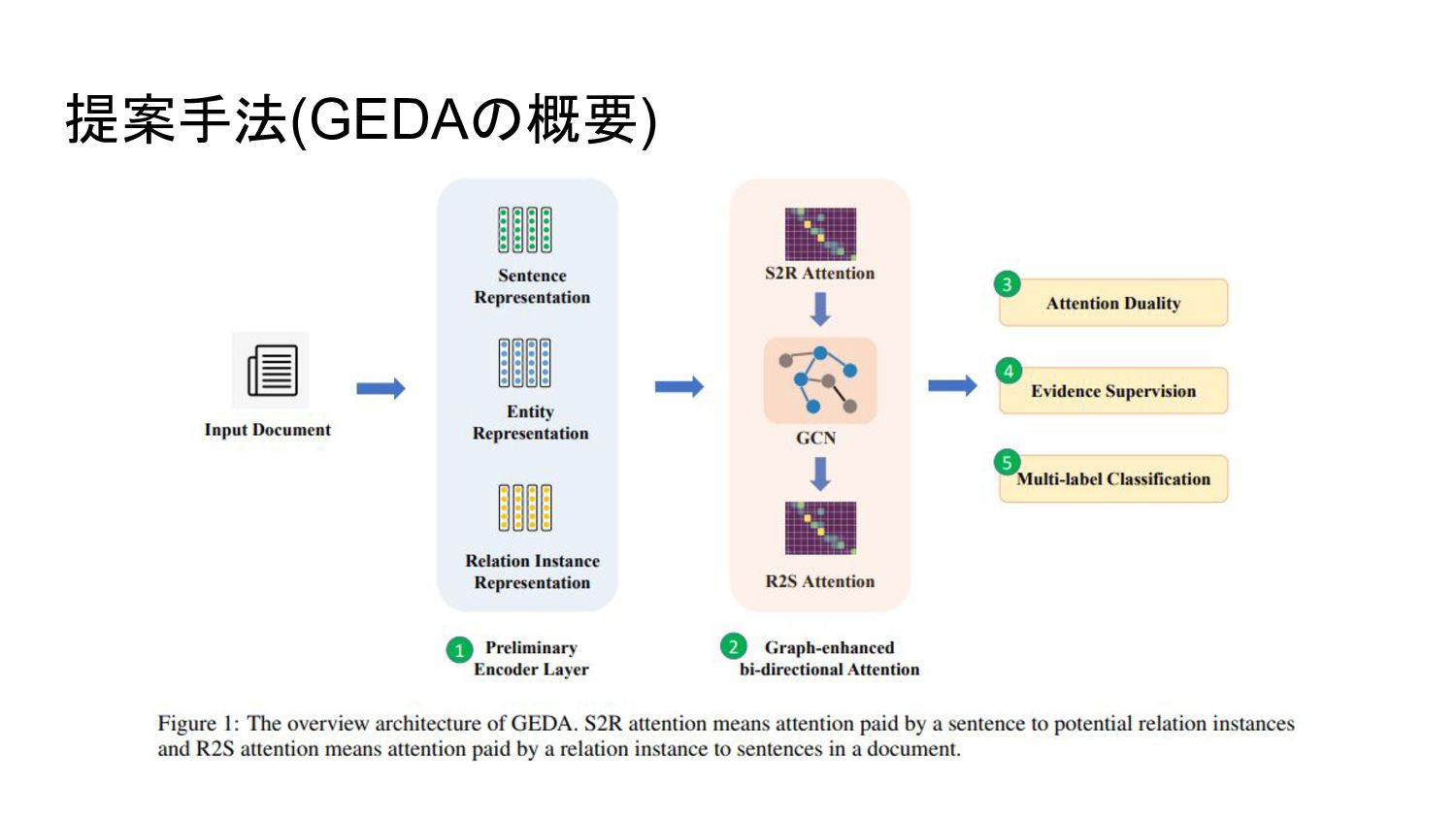
提案手法(GEDAの概要)
Encoding Layer 文書はn語, m文, k個のentity (relation instanceはk(k-1)個) からなる 1)word embedding,
2)entity type embedding, 3)entity order embedding (Yao et al., 2019) 隠れユニットh個のBiLSTMで文書を とする i番目の文のベクトル表現: entityのベクトル表現: relation instanceのベクトル表現: 全てのentityのペア に双対関数を使用し、 なるベクトル表現とする
Graph-Enhanced Bi-directional Attention 文とrelation instance間の複雑な相互作用をモデル化することが目的 S2R layer, GCN layer, R2S
layerからなる S2R layer この層の出力はrelation instanceから得られる文のベクトル クエリを , キーを の各行 としてアテンションの重みを計算 出力: この層でアテンションの重み行列 も得られる
Graph-Enhanced Bi-directional Attention GCN Layer entity nodeとsentence nodeからなるグラフ 3種類のedge 1)
sentence-sentence edge: 2文が同じentityを持つとき 2) entiy-entity edge: 2つのentityがある一つの文に現れるとき 3) entity-sentence edge: entityがその文の中に現れるとき entityのベクトル表現を前層で出力した の次元に揃える → を使って →特徴ベクトル
Graph-Enhanced Bi-directional Attention 隣接行列 対角成分, 2つのnode間にedgeがあれば1, 無ければ0の行列 GCN(グラフ畳み込み)をすることで新しい特徴量 対称正規化隣接行列 この特徴量は次のように解釈できる
1) 上からk行は洗練されたentityの行列 2) k+1行からk+m行は洗練された文の行列 さらに1) に対して双対関数を使うことで洗練された relation instance のベクトル表現 を得る
Graph-Enhanced Bi-directional Attention R2S Layer クエリが キーが でS2Rのように重みを計算 出力は文から得られるrelation instanceのベクトル表現 (i行目はi番目のrelation instanceに相当) アテンションの重みベクトル
も得られる
Regularizer of Attention Duality 文からrelation instanceへのアテンションとrelation instanceから文へのアテンションは 一般的に一貫性がある → と の間には二元性がある この二元性を利用した単純な帰納バイアスを導入
Evidence Supervision どの文が特定のrelation instanceに貢献しているのかをベクトル化 ex) m文からなる文書の、i番目のrelation instanceが冒頭2文によって根拠づけられて いる場合、evidenceベクトルは どの文にも当てはまらないときは全ての要素が1/m 直感的に
のi行目 はevidenceベクトルに近いベクトルであるべき → KLダイバージェンス 追加のロスとして計算
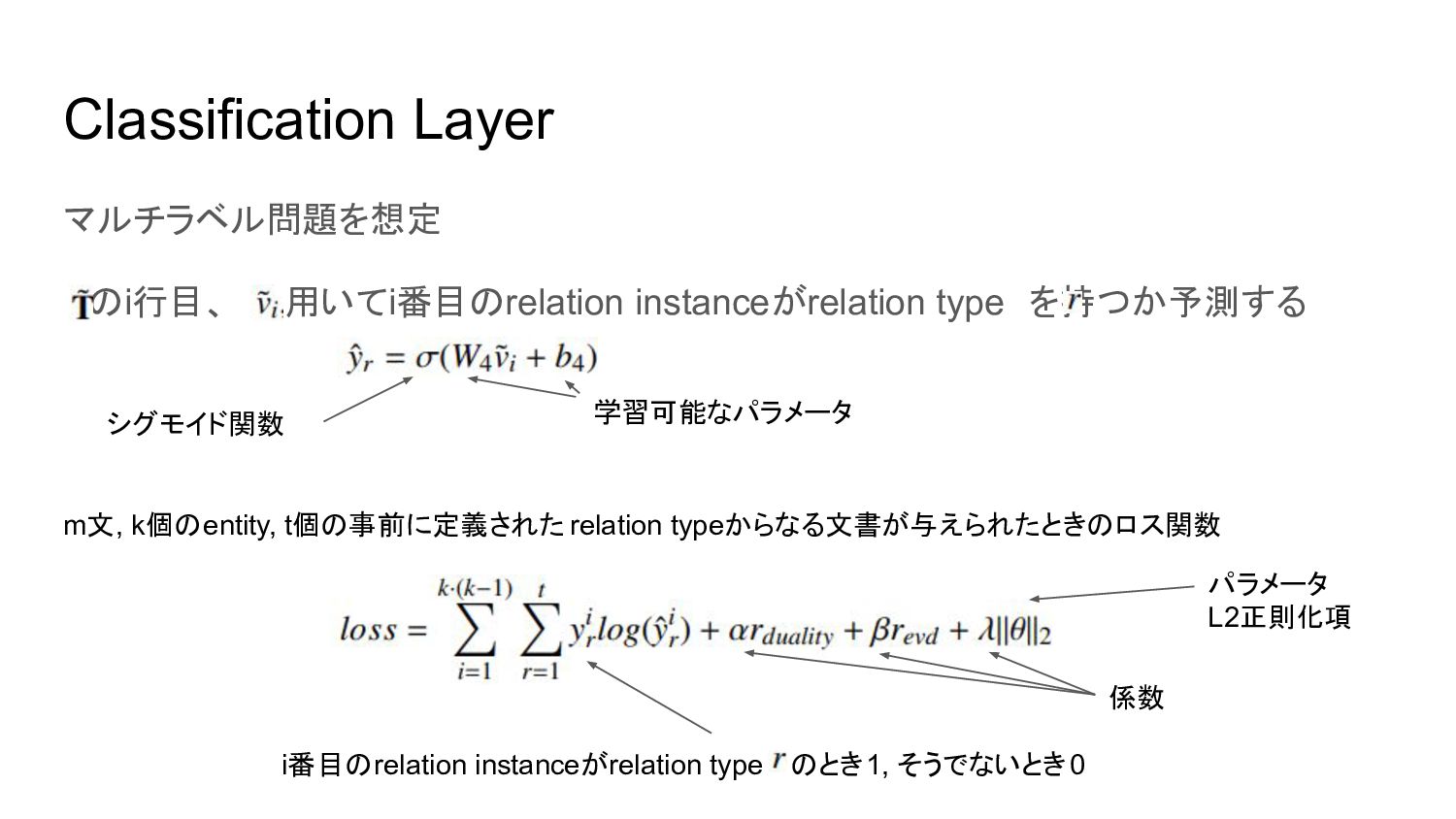
Classification Layer マルチラベル問題を想定 のi行目、 を用いてi番目のrelation instanceがrelation type を持つか予測する 学習可能なパラメータ シグモイド関数 m文, k個のentity,
t個の事前に定義された relation typeからなる文書が与えられたときのロス関数 i番目のrelation instanceがrelation type のとき1, そうでないとき0 パラメータ L2正則化項 係数
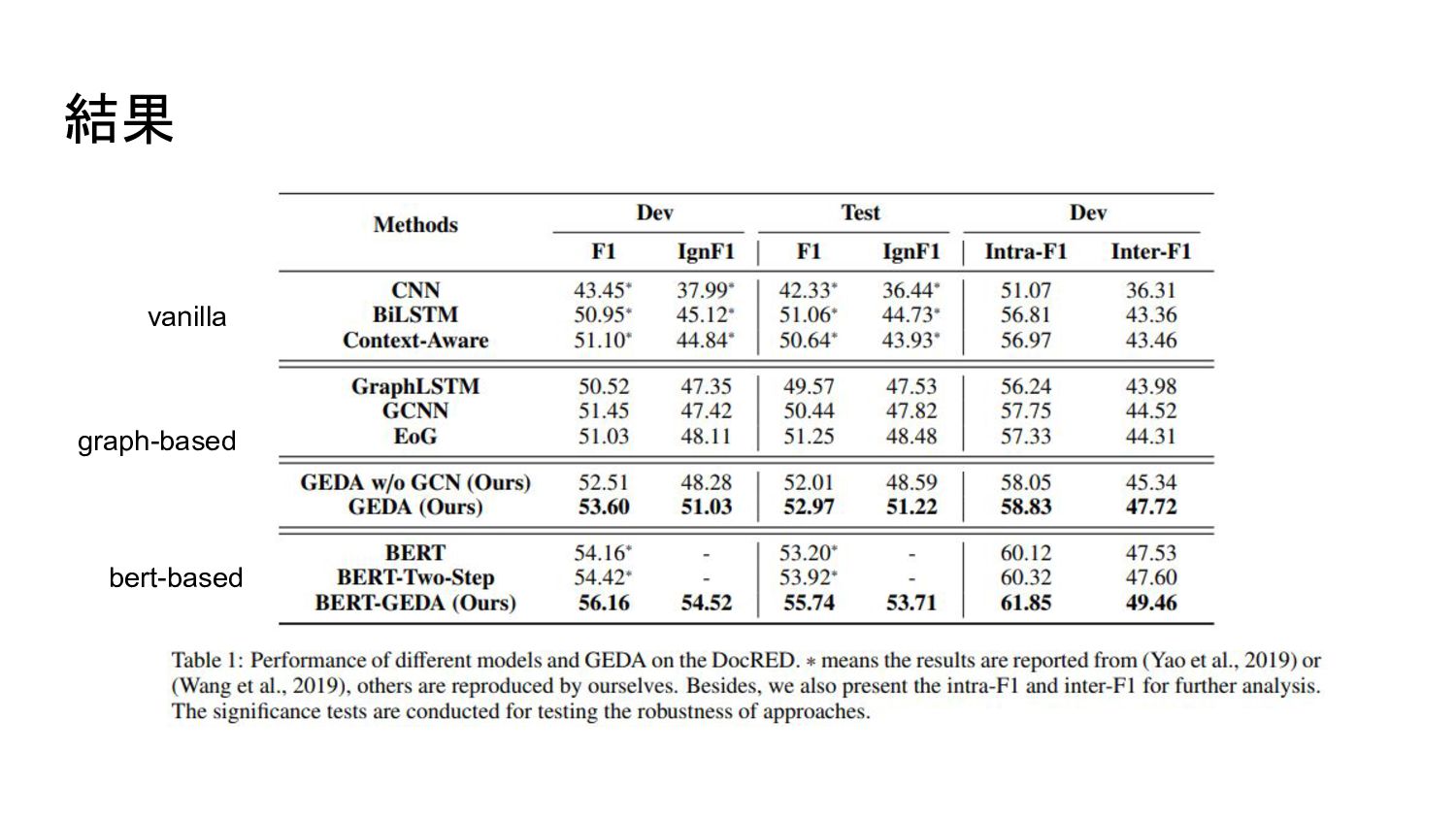
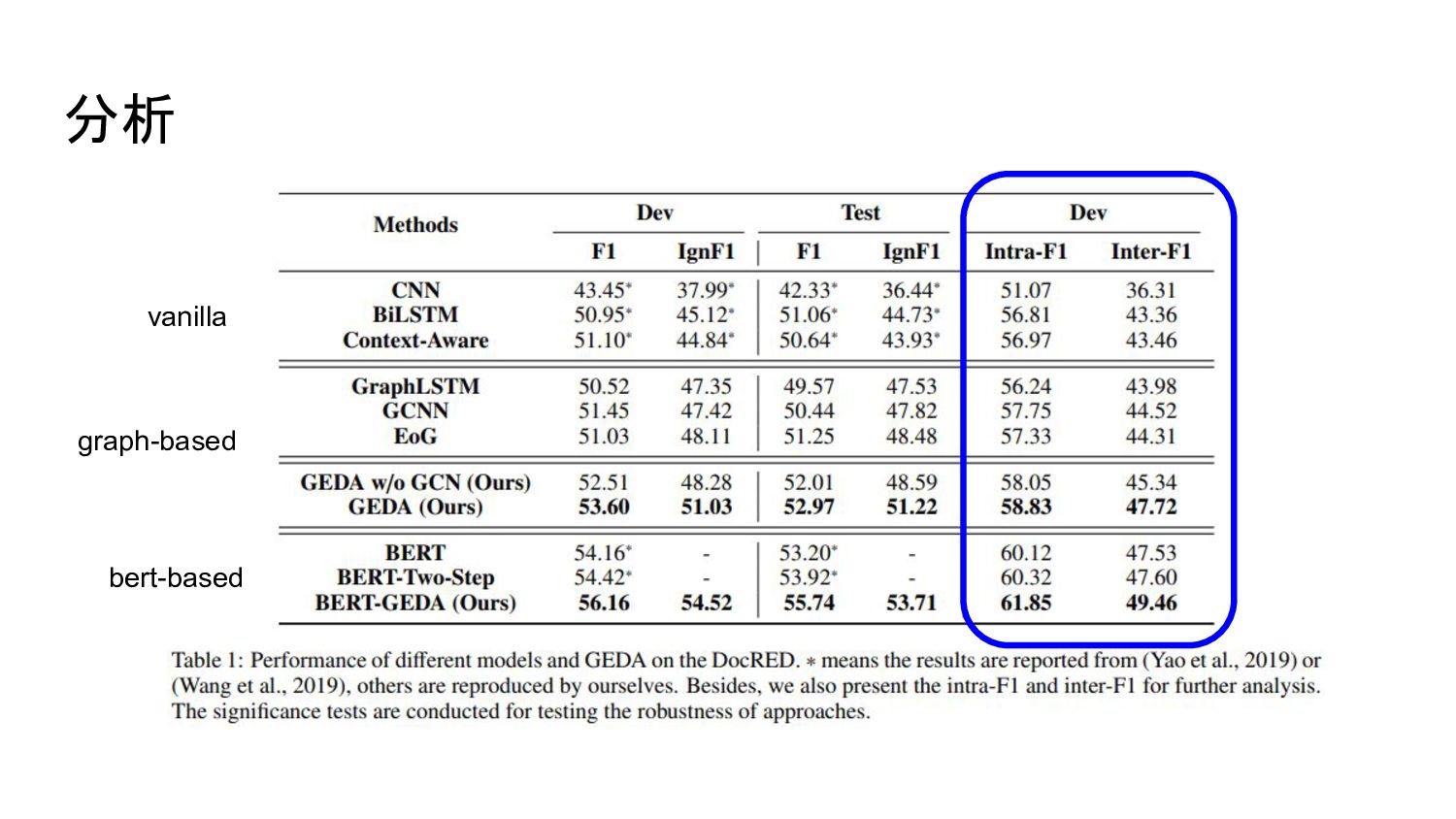
実験 データセット: DocRED (Yao et al., 2019) 大規模な文書レベルREのデータセット training doc:
3,053, development doc: 1,000, test doc: 1,000, relation type: 96 entityのペアが複数の関係を持ち得るのでmulti-label classification問題とする 先行研究 (Yao et al., 2019) に倣ってF1とIgnF1(trainingに出てくるentity pairを取り除 く)で評価 entityのペアが同一文内か否かでもintra-F1とinter-F1としてそれぞれ評価
結果 vanilla graph-based bert-based
分析 vanilla graph-based bert-based
分析
case study
conclusion ・GEDAをドキュメントレベルの関係抽出に導入した ・文とrelation instanceの相互作用を特徴づけることでドキュメント内での文間の推論性 能が上がった ・GEDAの新規性はグラフに基づく文表現の精練と、二元性と根拠の裏付けに基づく単 純な正則化
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}