2025/03/23 PHPerKaigi2025 LT大会
PHPで巨大データ検索の高速化:strposと計算量の重要性
PHPで大量データを扱う際、コードが正しく動いていても、パフォーマンスの低下が発生し、ユーザーの離脱につながったりすることがあります。
本トークでは、私たちのプロジェクトで直面した「strposによる文字列検索が原因で処理が30秒以上かかった」事例をもとに、計算量の重要性とパフォーマンス最適化についてお話しします。
問題の背景は、数千件の文字列を1件ずつ、約1万件の集合と照合する処理でした。
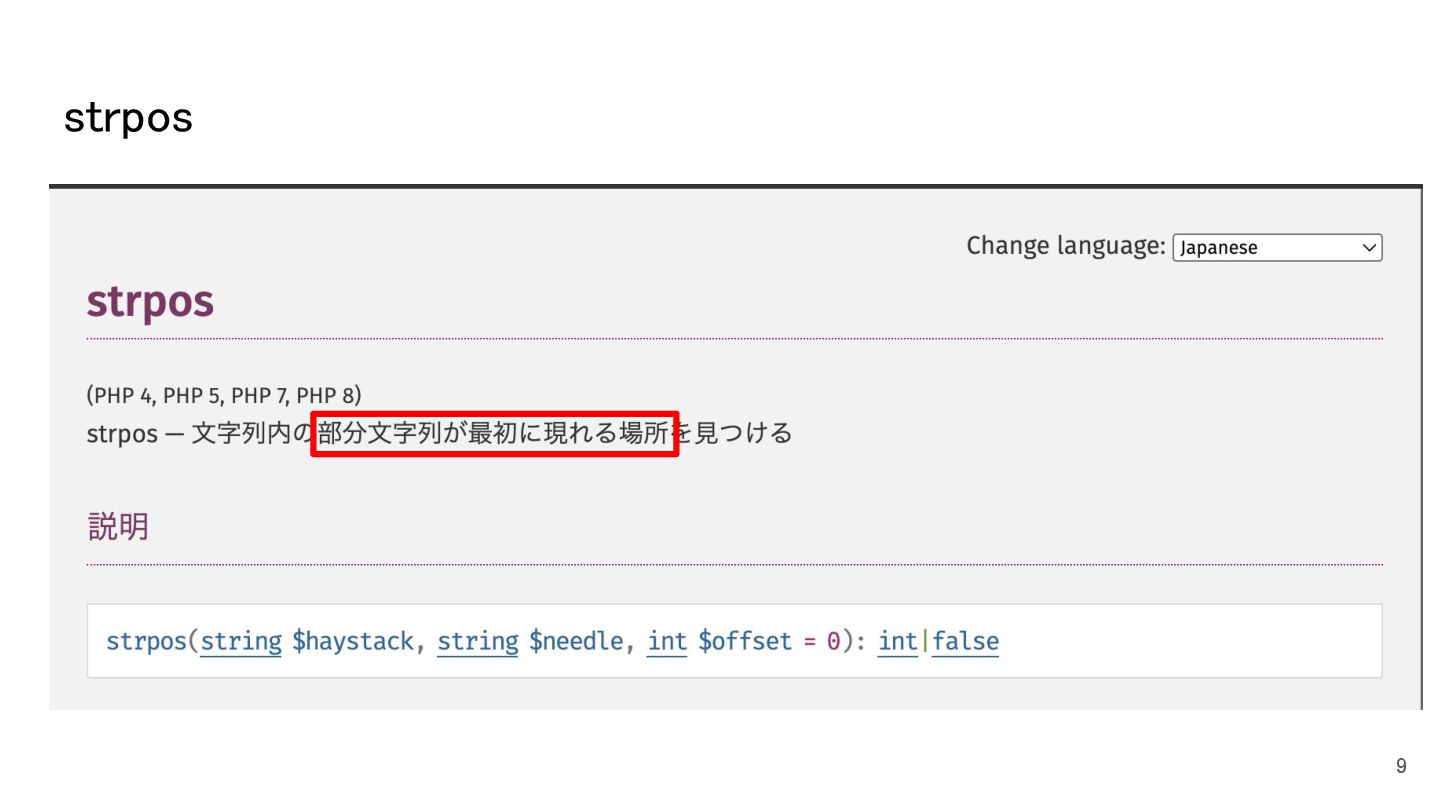
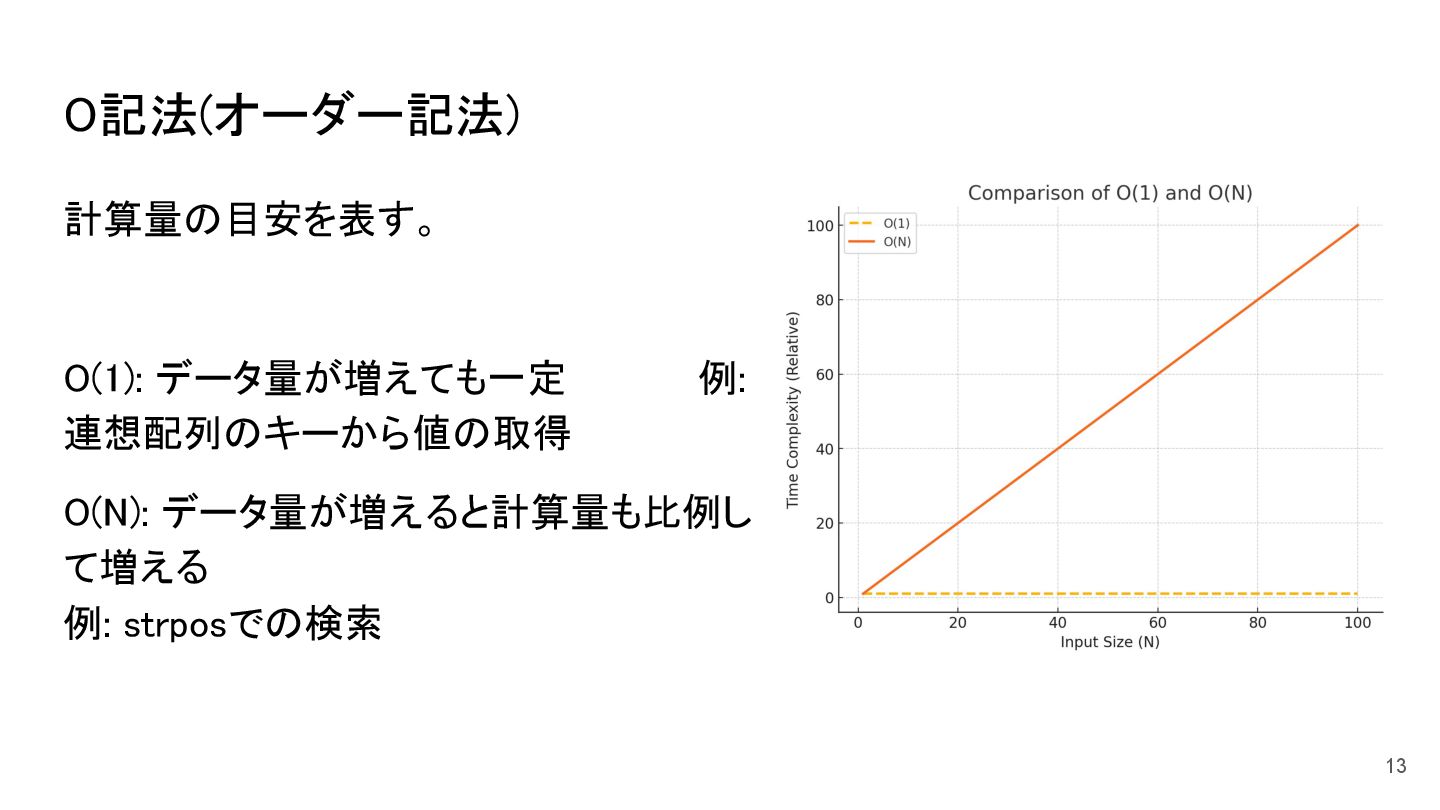
文字列の部分一致のチェックをstrposで実装していましたが、線形検索(O(n))のため、1回の検索がミリ秒単位でも、繰り返し処理が積み重なり、最終的には数十秒に達しました。
処理の遅延が原因でタイムアウトが発生し、ユーザーが機能を使えない危機に直面しました。
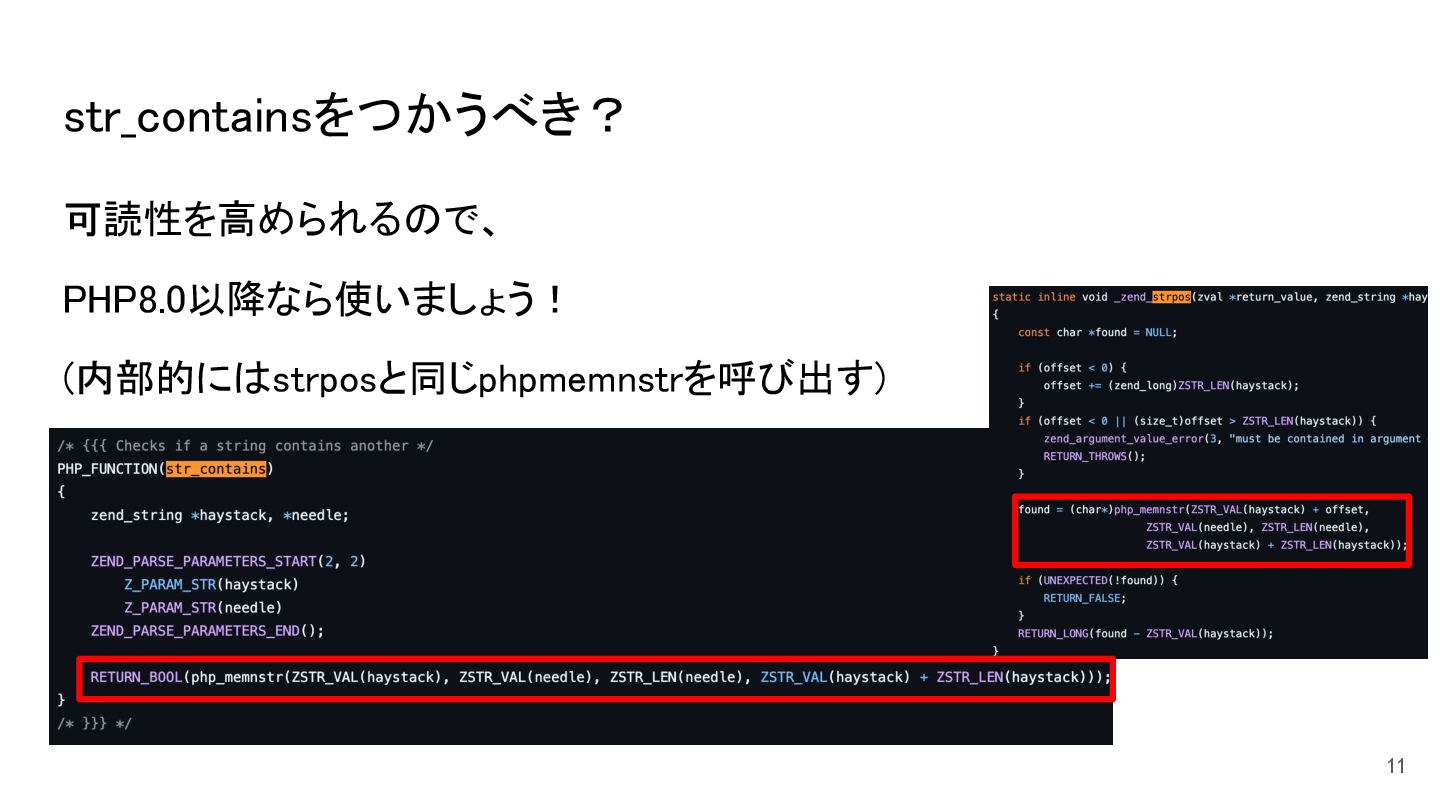
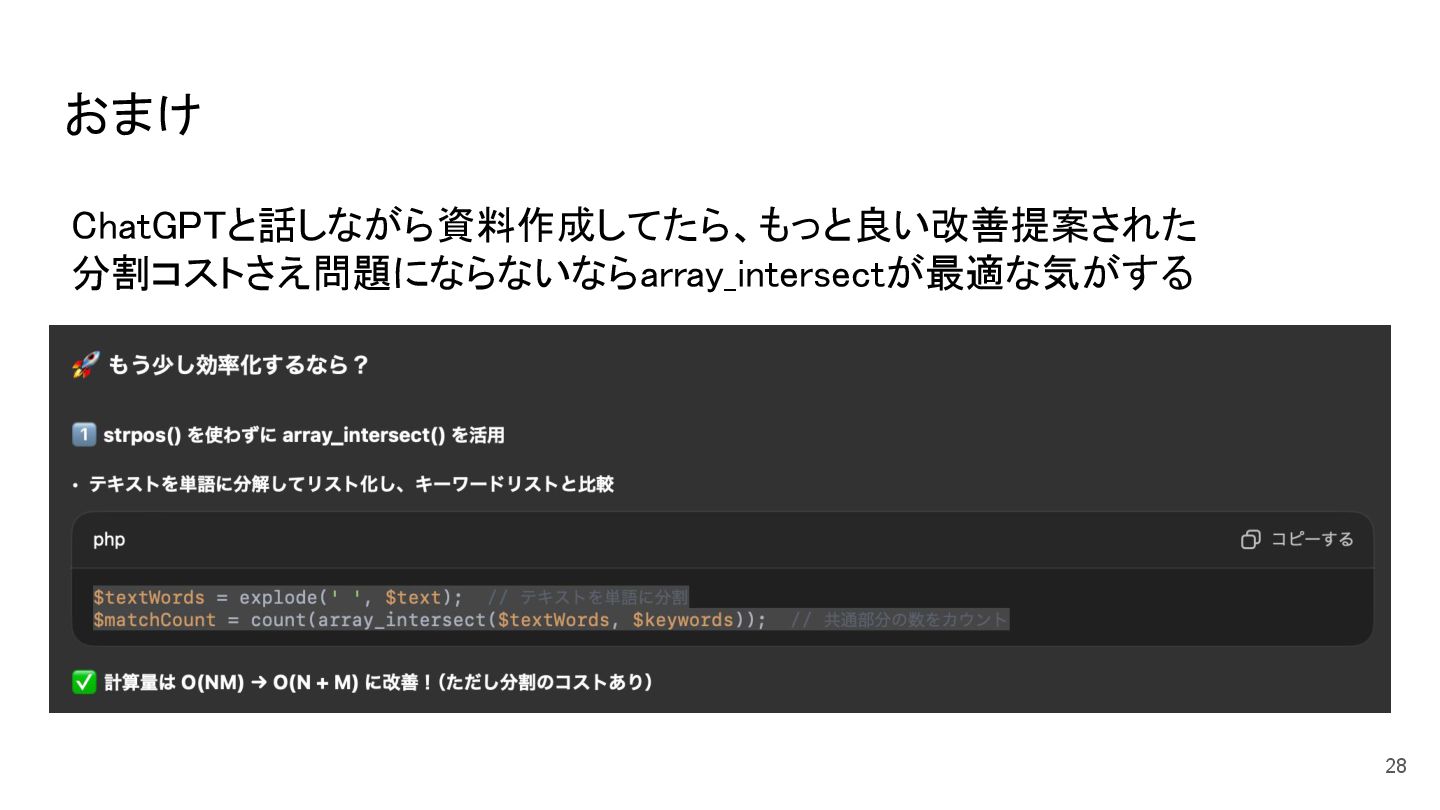
解決策として、array_flipとarray_key_existsを用いて、検索処理をハッシュベース(O(1))に変更することで、処理時間を30秒から約6秒に短縮しました。
この経験を通じて、パフォーマンス問題を解決するには計算量の意識が不可欠であると学びました。
このように、1回の処理がわずか1ミリ秒遅延しただけであっても、大規模データでは致命的な影響を与える可能性があること、計算量や計算時間が特に大事になってくることを学びました。
このようなパフォーマンス改善は、ユーザー体験を向上させ、機能の価値を最大化するための重要なステップです。
ユーザーが快適に使える環境を提供するため、私たちエンジニアが取り組むべき課題を一緒に考えてみませんか?
https://fortee.jp/phperkaigi-2025/proposal/1740b466-cd6f-4895-8362-2f16c8ace62e
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}