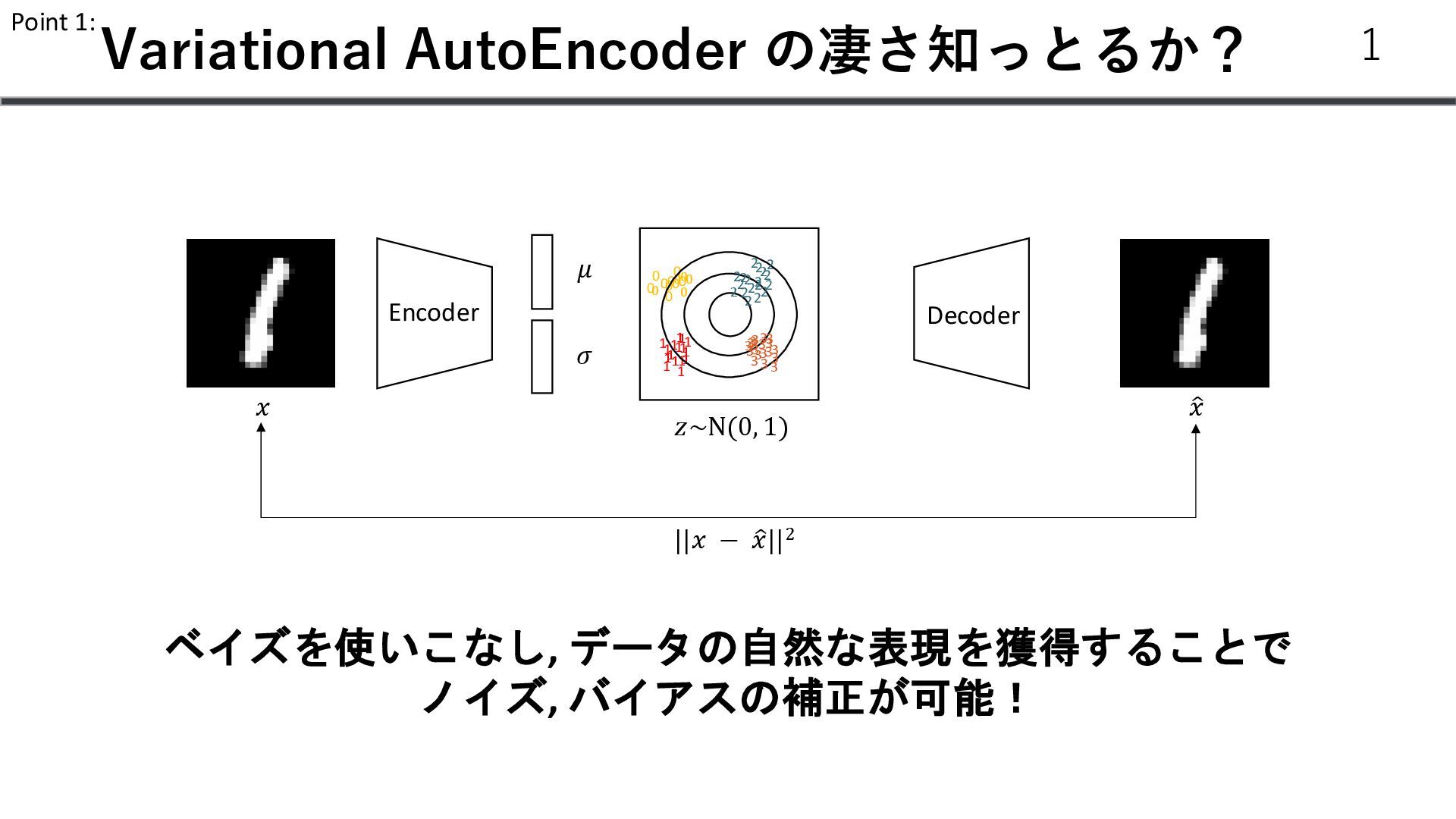
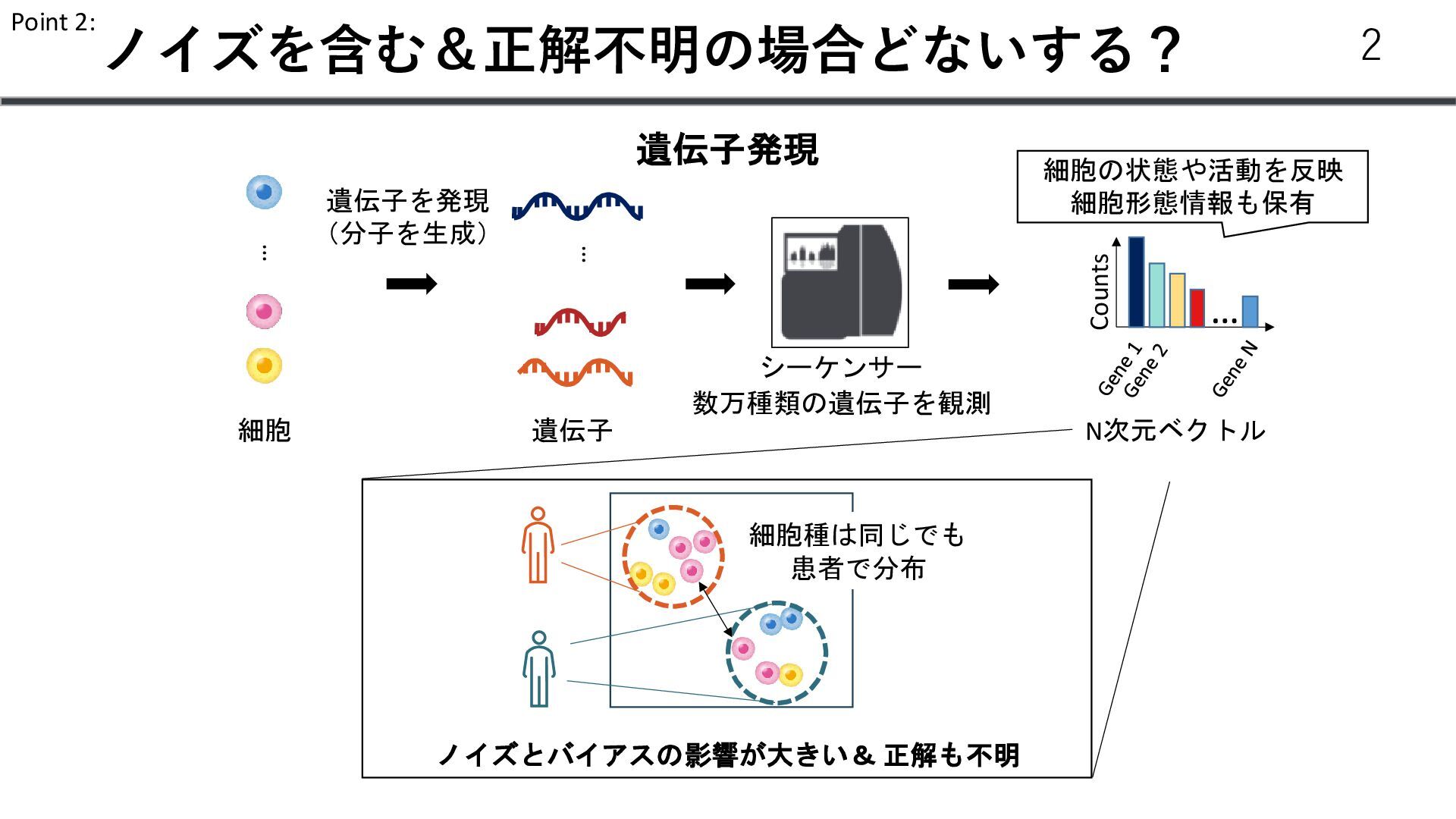
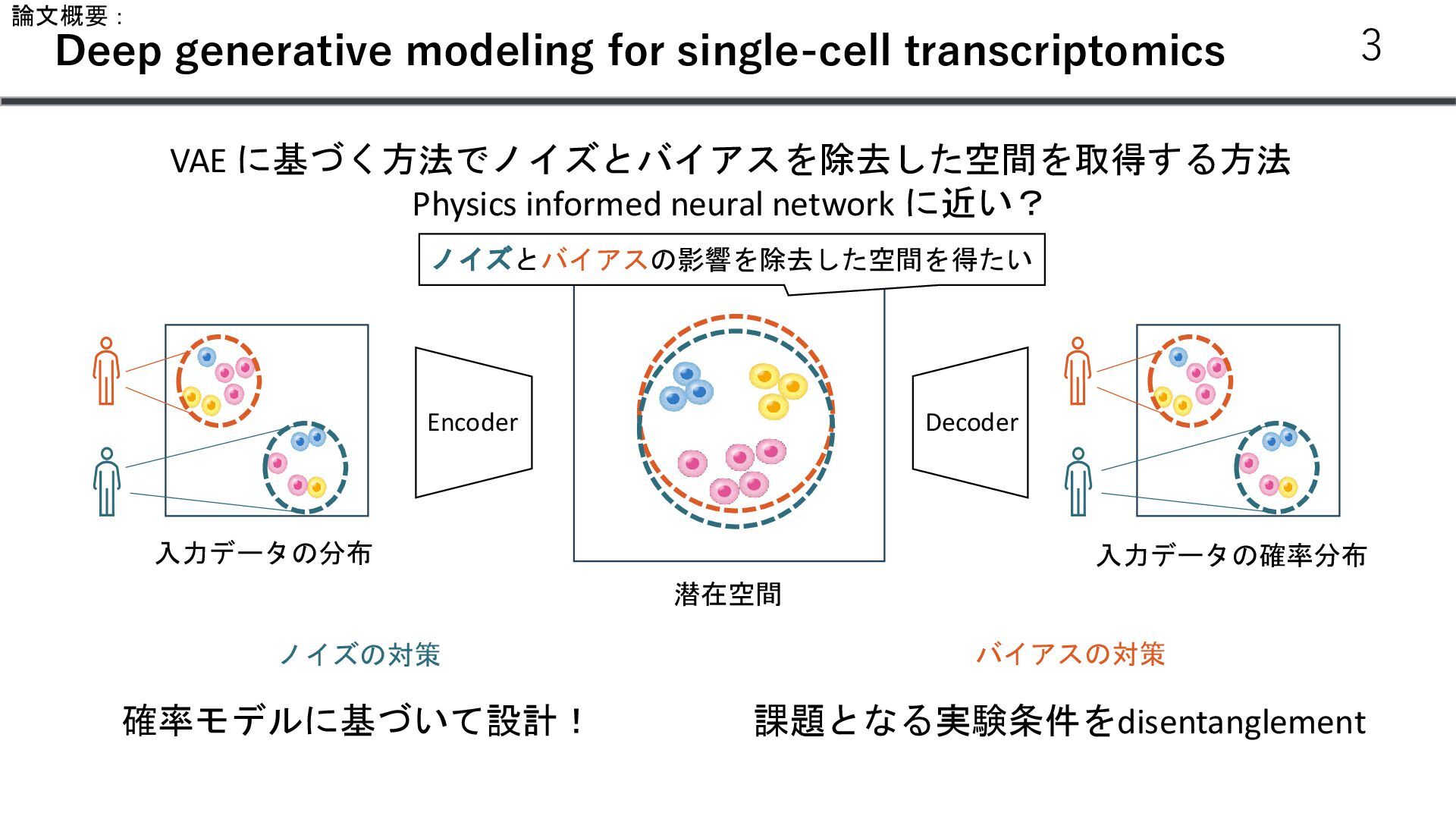
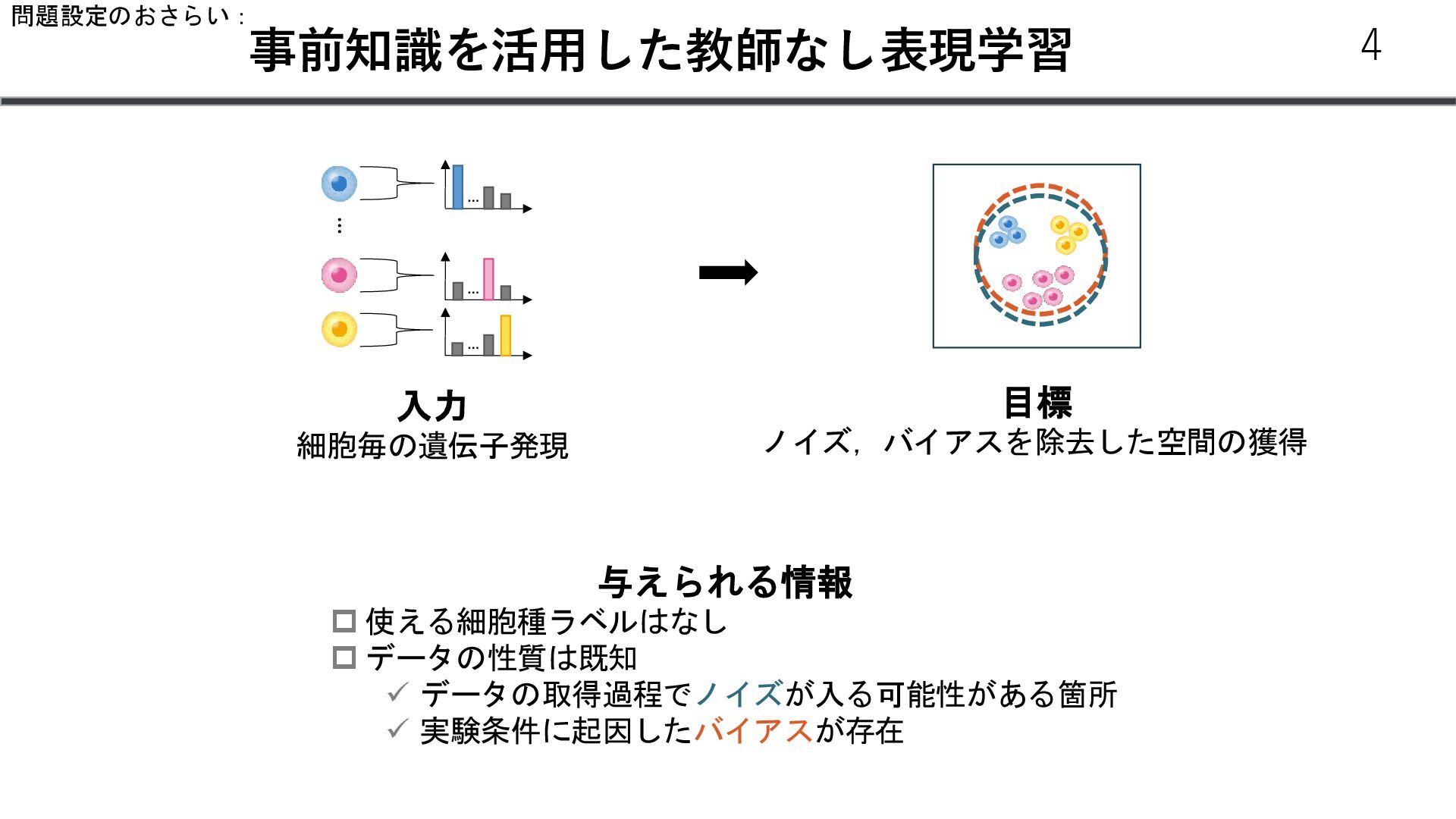
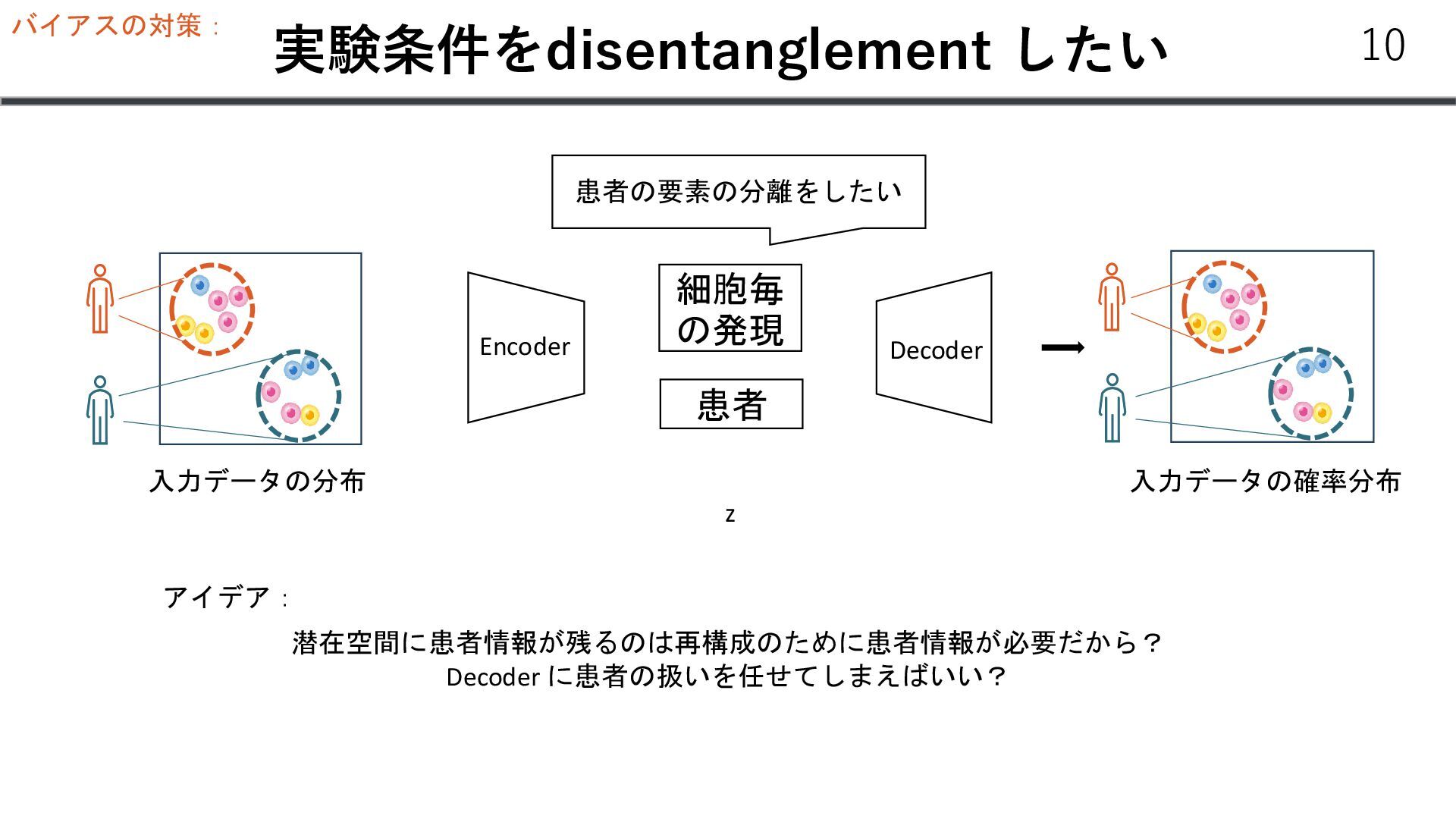
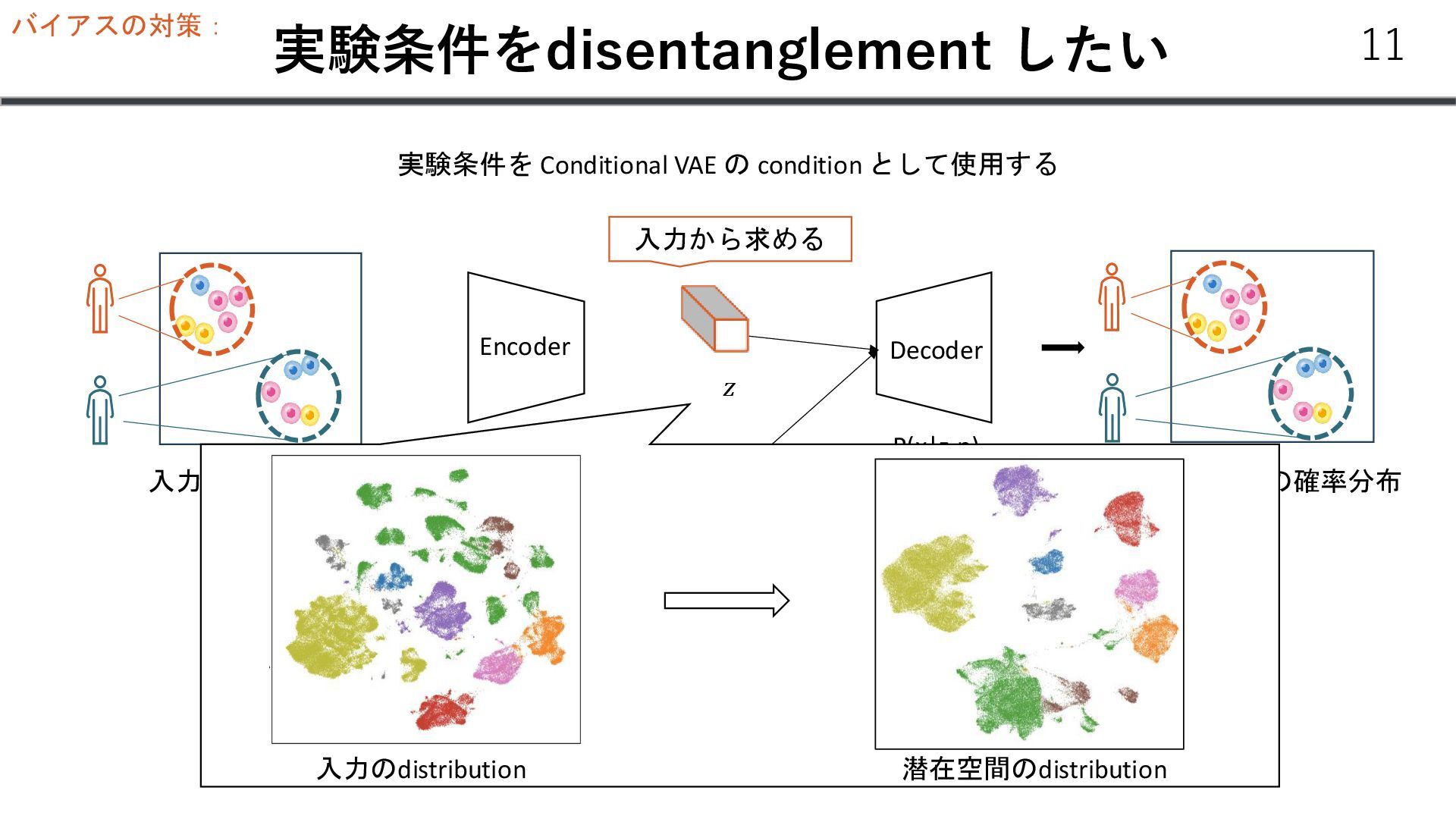
個数 Gene 1 4 Gene 2 0 … … Gene N 13 𝑥𝑖 :遺伝子発現 𝑠: 患者𝐼𝐷 𝜇 v 𝑧 𝑁(𝜇, v) 𝑠 患者ID 𝑥𝑖 ~𝑍𝑁𝐵 𝑟, 𝑝, 𝜋 r: 失敗回数 P: 成功確率 𝜋: zeroになる確率 𝑧1 ~𝑁 0, 1 𝐿𝑒𝑙𝑏𝑜 = 𝐾𝐿(𝑞(𝑧1 |𝑥)| 𝑝 𝑧1 − 𝔼𝑞(𝑧|𝑥) [log 𝑝(𝑥|𝑧1 )] 𝑙 ∈ ℝ𝑁𝑠 𝜇 𝜎 ∈ ℝ𝑁𝑔 Trainable vector 𝑁𝐵 𝑝, 𝑟 𝑝𝑠 Softmax Decoder p(x|z, s) 13 𝑙 = log(∑𝑥)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Single cell VAE の概要 [Lopez+, nature method 2018] 12 Encoder](https://files.speakerdeck.com/presentations/accf767ec904400a8133ec82984d92e6/slide_12.jpg){kind=link}
![Single cell VAE の概要 [Lopez+, nature method 2018] Encoder 𝑞(z|x)](https://files.speakerdeck.com/presentations/accf767ec904400a8133ec82984d92e6/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
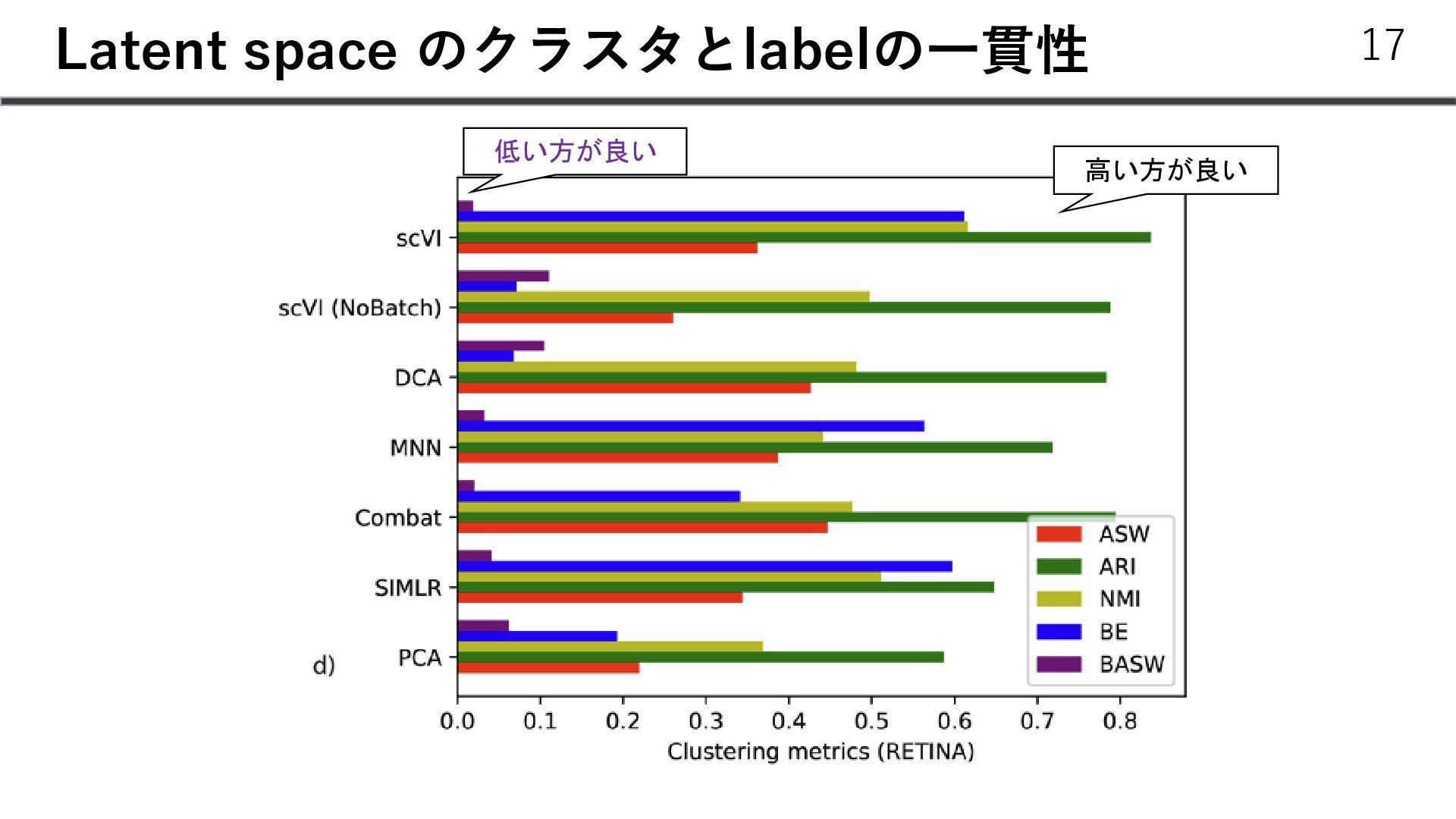{kind=link}
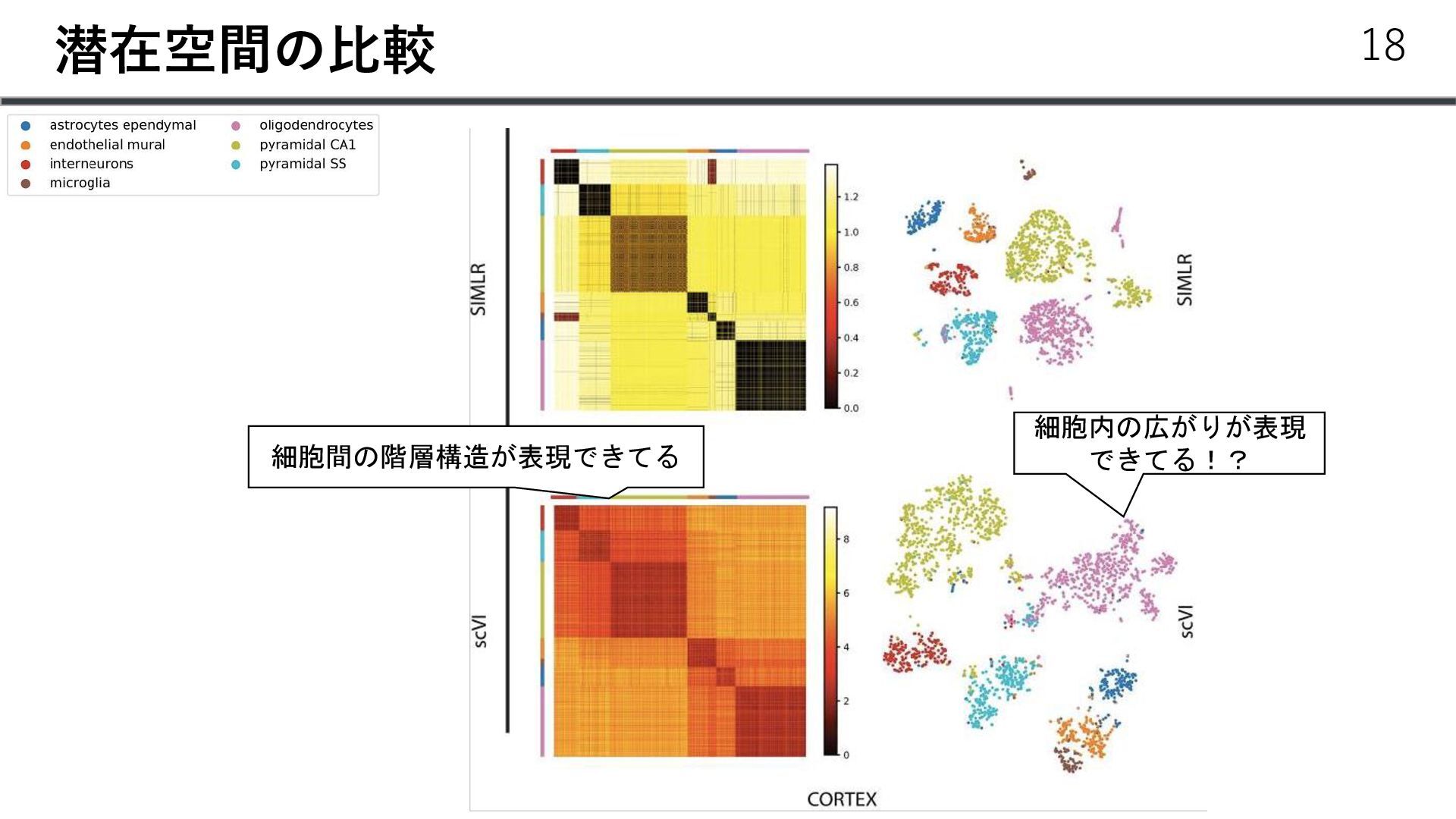{kind=link}
{kind=link}
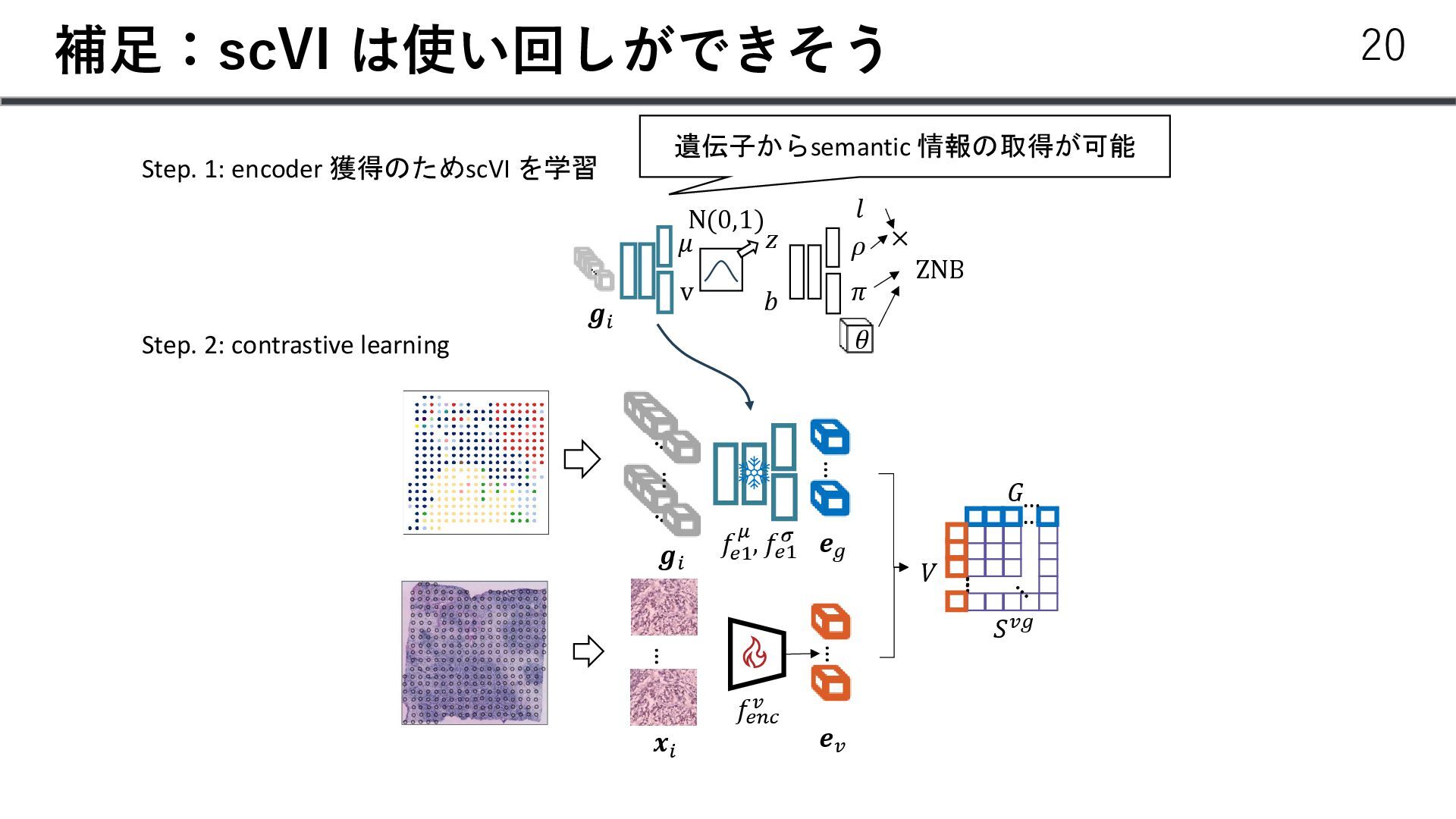{kind=link}