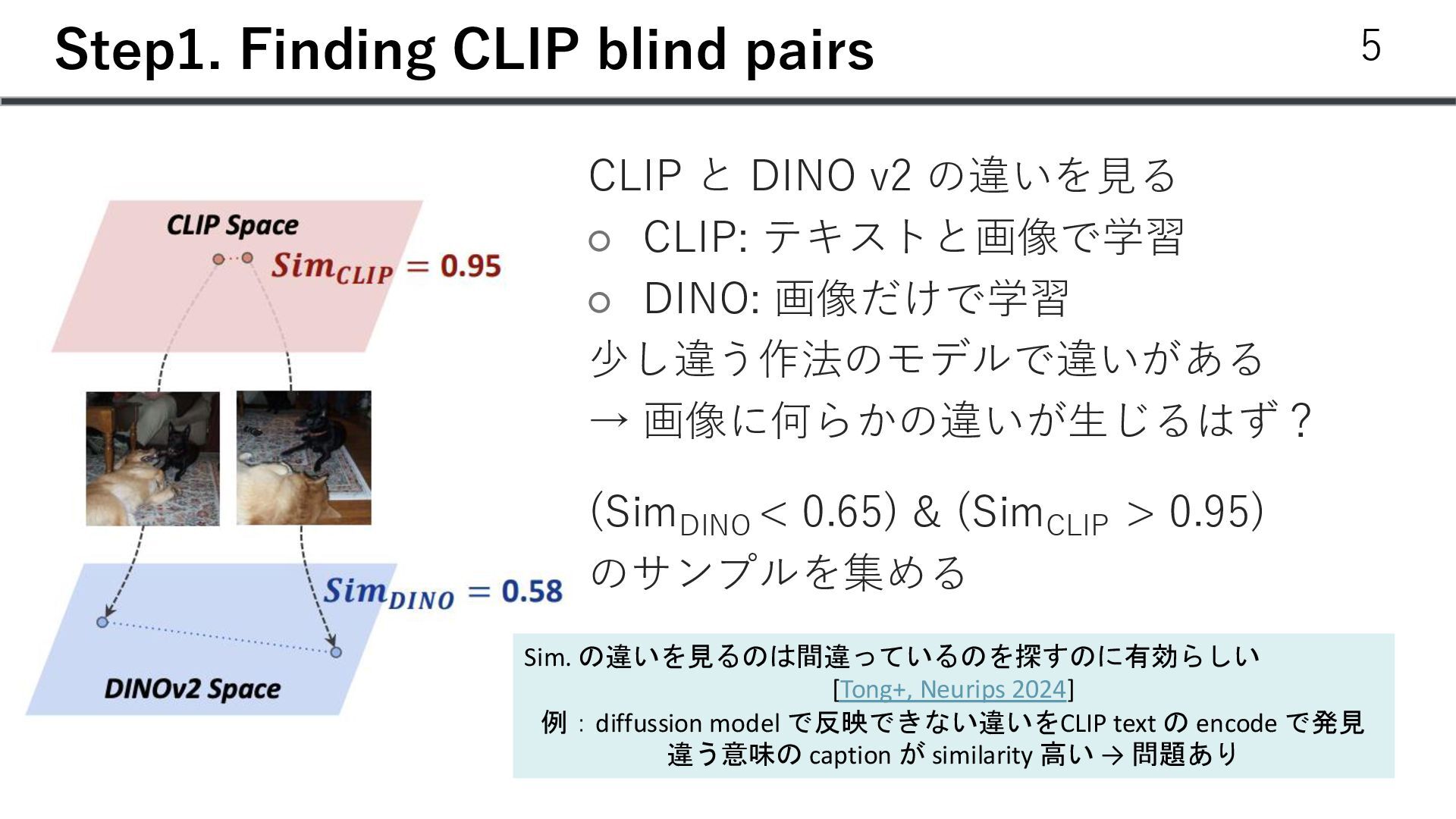
◦ CLIP: テキストと画像で学習 ◦ DINO: 画像だけで学習 少し違う作法のモデルで違いがある → 画像に何らかの違いが生じるはず? (Sim DINO < 0.65) & (Sim CLIP > 0.95) のサンプルを集める 5 Sim. の違いを見るのは間違っているのを探すのに有効らしい [Tong+, Neurips 2024] 例:diffussion model で反映できない違いをCLIP text の encode で発見 違う意味の caption が similarity 高い → 問題あり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}