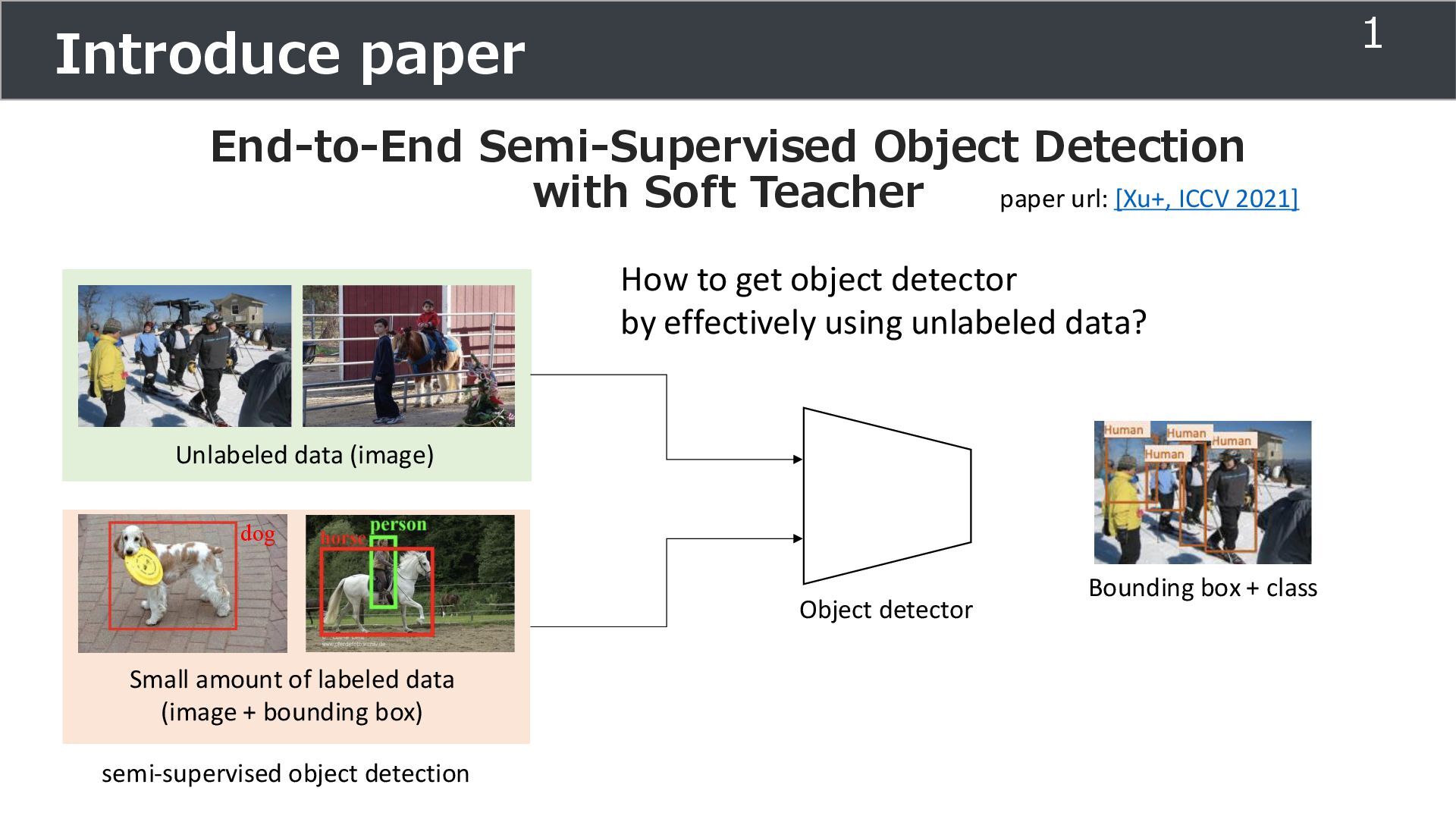
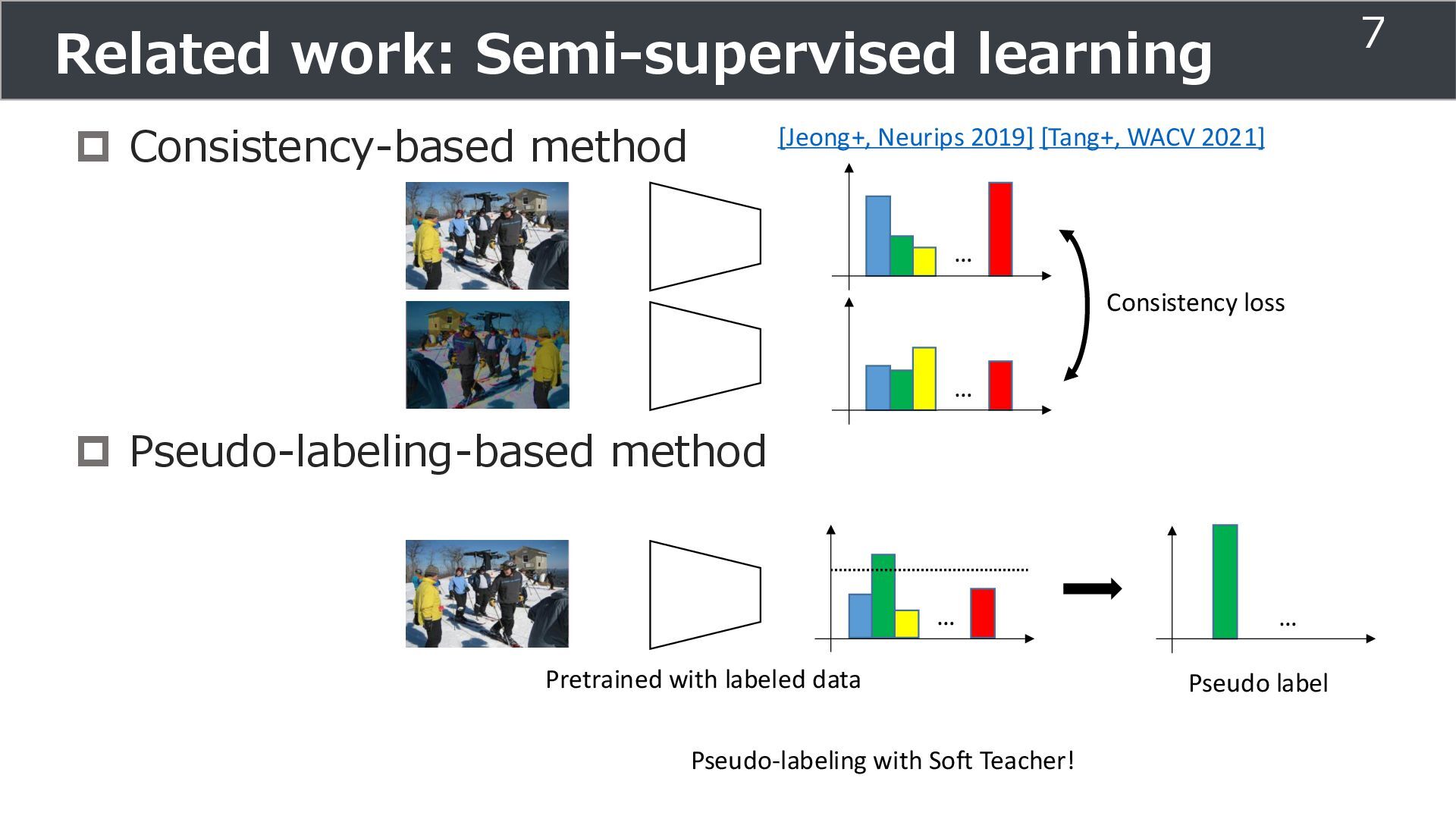
amount of labeled data (image + bounding box) Unlabeled data (image) paper url: [Xu+, ICCV 2021] dog semi-supervised object detection Object detector Bounding box + class How to get object detector by effectively using unlabeled data? 1
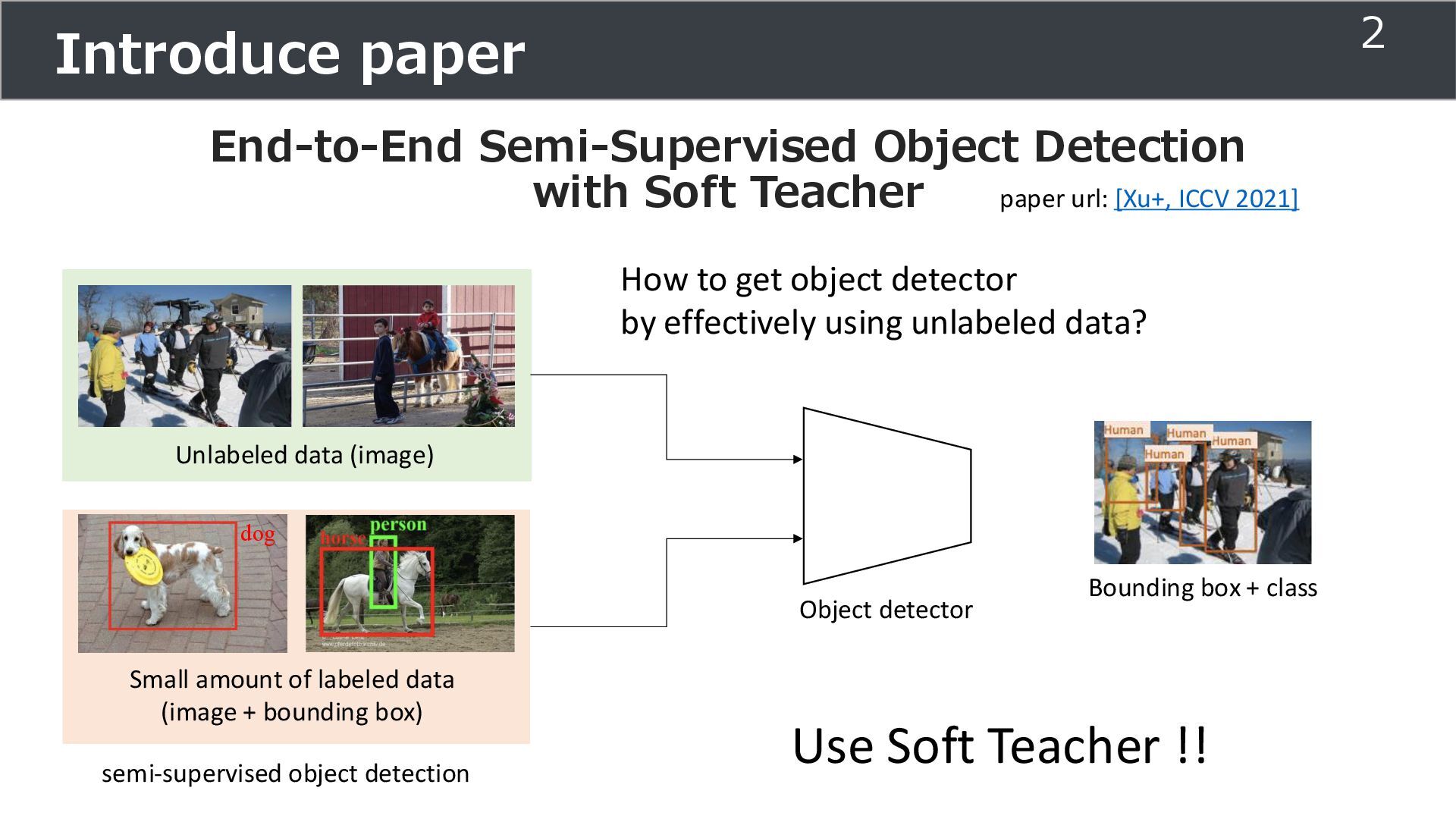
amount of labeled data (image + bounding box) Unlabeled data (image) paper url: [Xu+, ICCV 2021] dog semi-supervised object detection Object detector Bounding box + class How to get object detector by effectively using unlabeled data? Use Soft Teacher !! 2
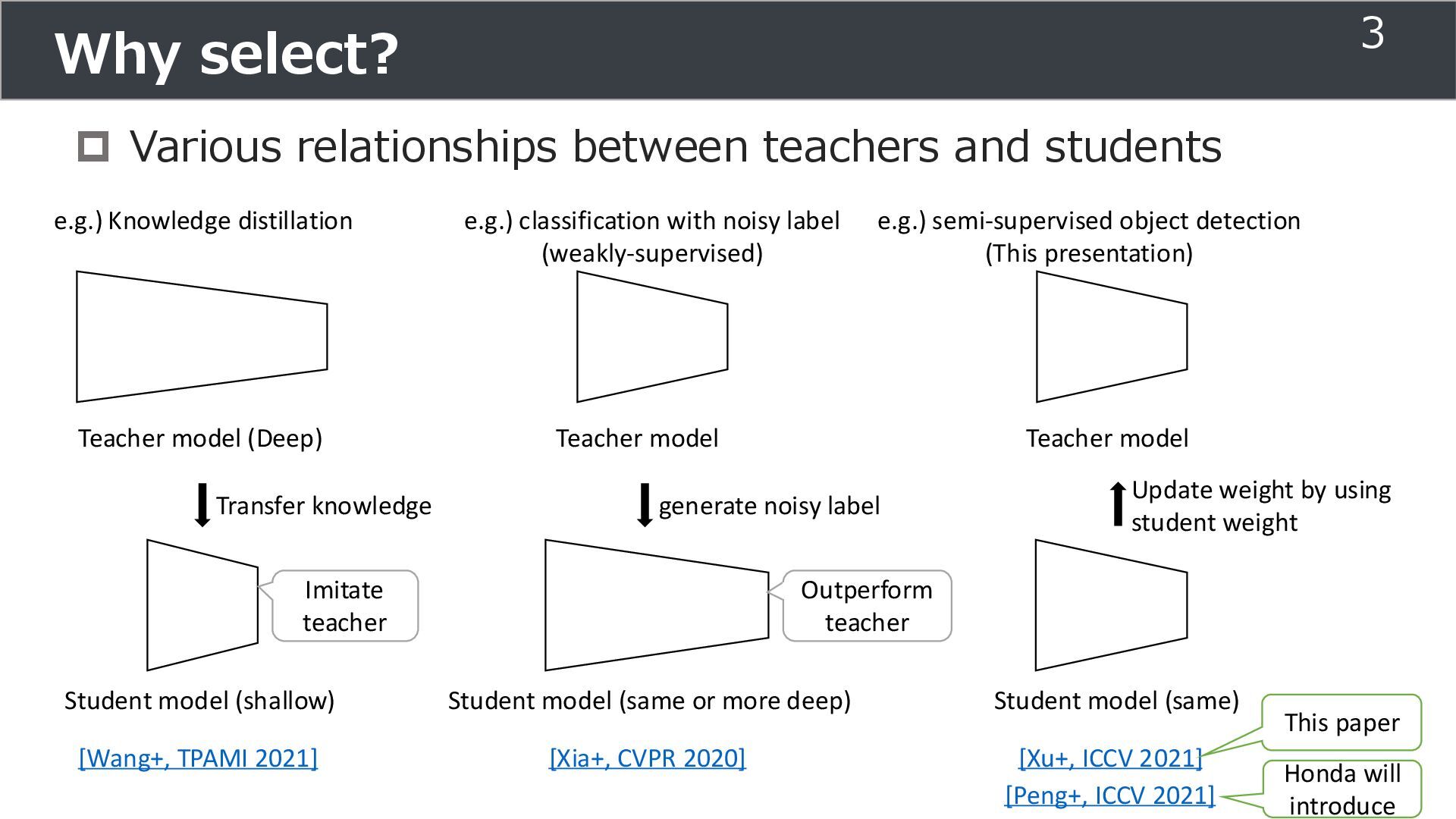
model (Deep) Student model (shallow) e.g.) Knowledge distillation Teacher model Student model (same or more deep) e.g.) classification with noisy label (weakly-supervised) Transfer knowledge [Wang+, TPAMI 2021] [Xia+, CVPR 2020] e.g.) semi-supervised object detection (This presentation) generate noisy label Imitate teacher Outperform teacher Student model (same) Update weight by using student weight Teacher model [Xu+, ICCV 2021] [Peng+, ICCV 2021] Honda will introduce This paper 3
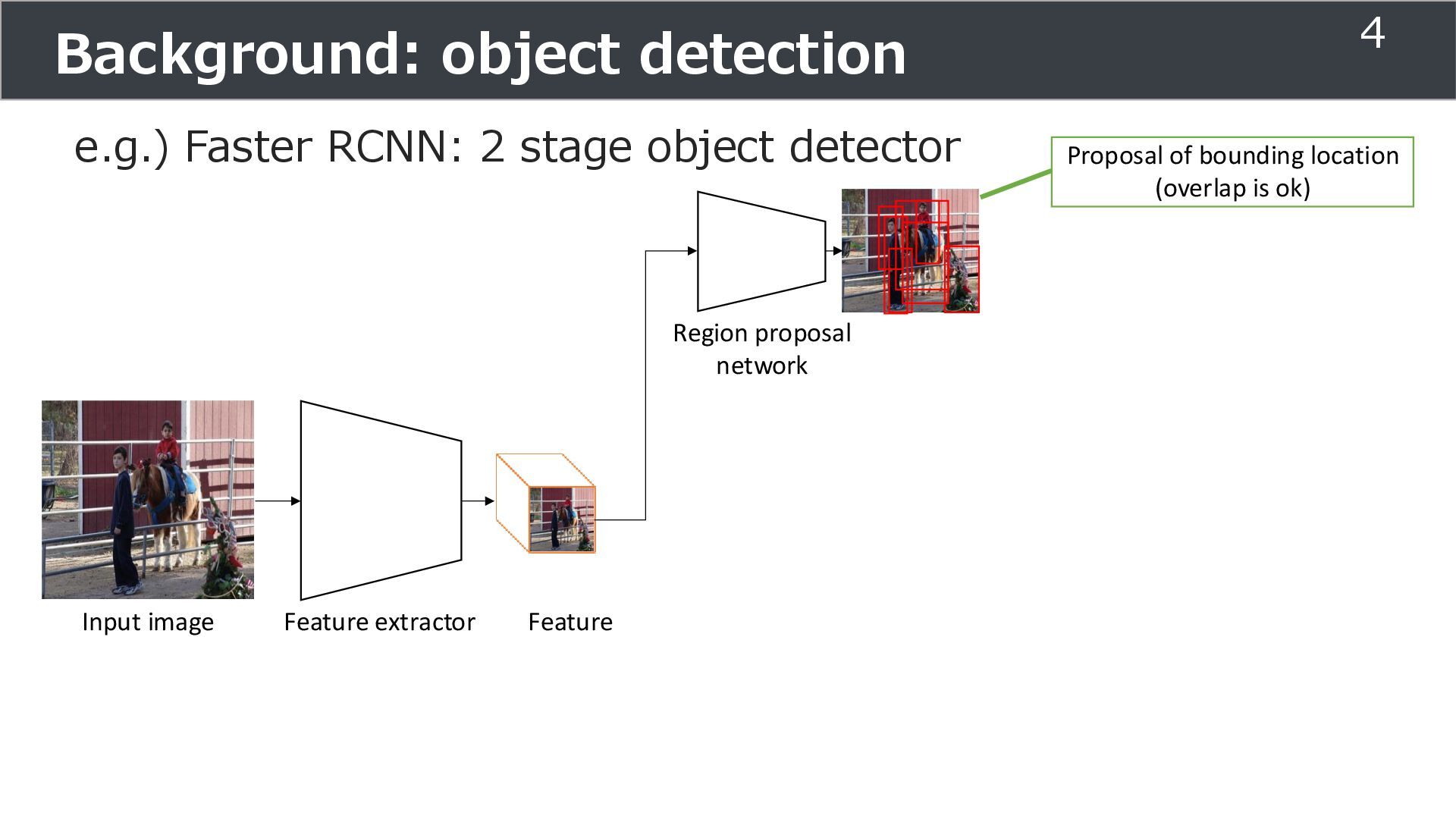
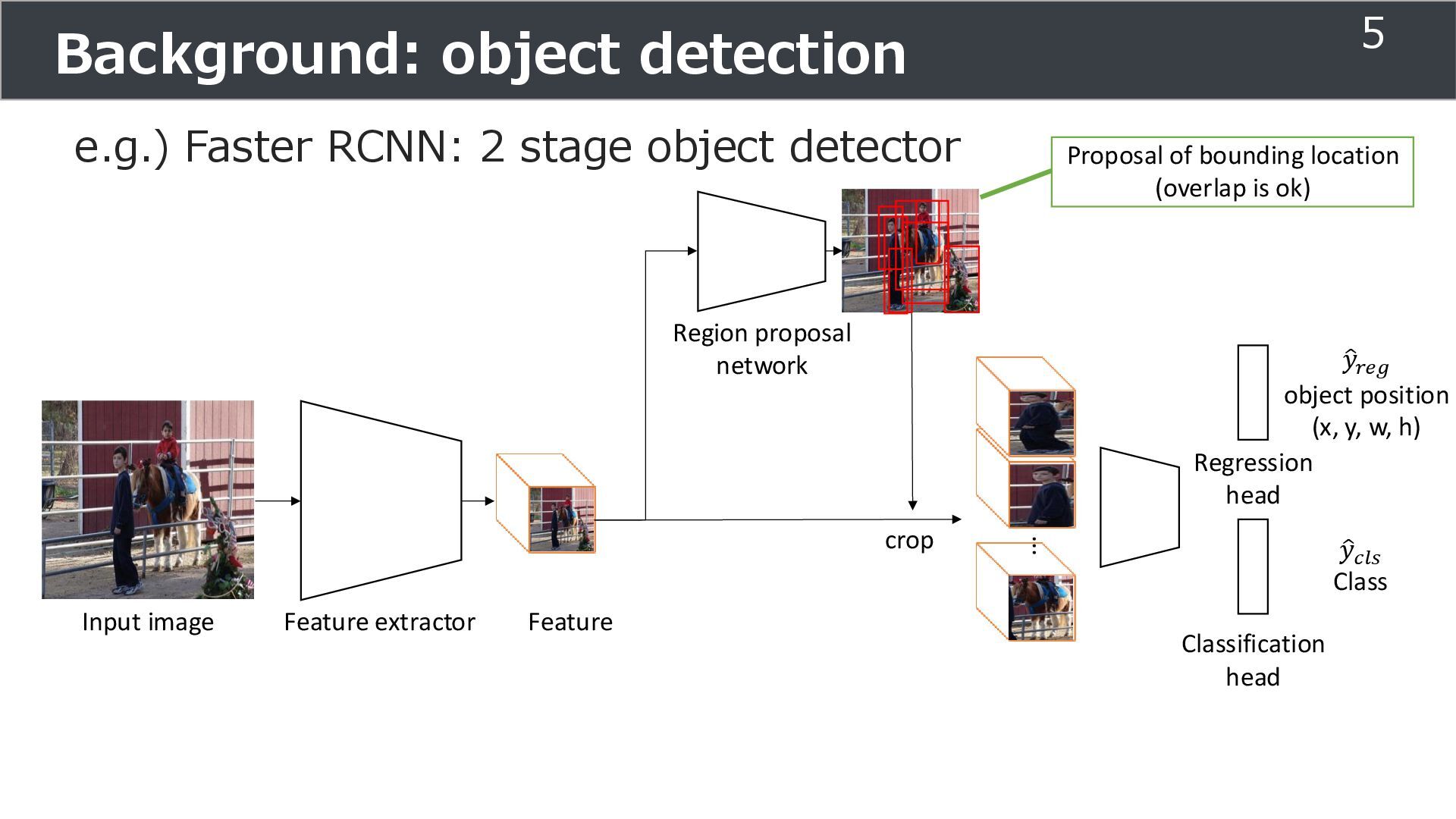
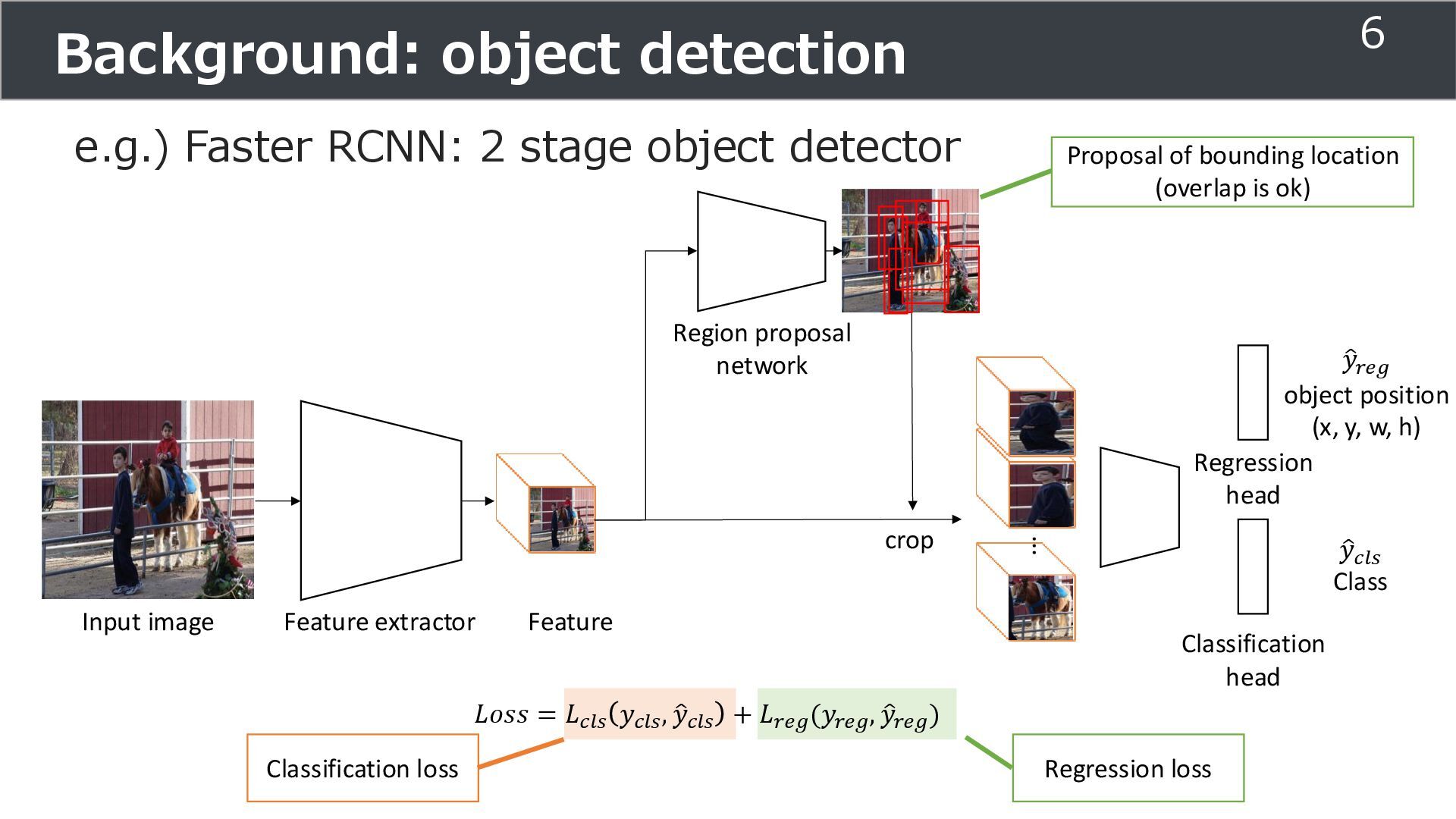
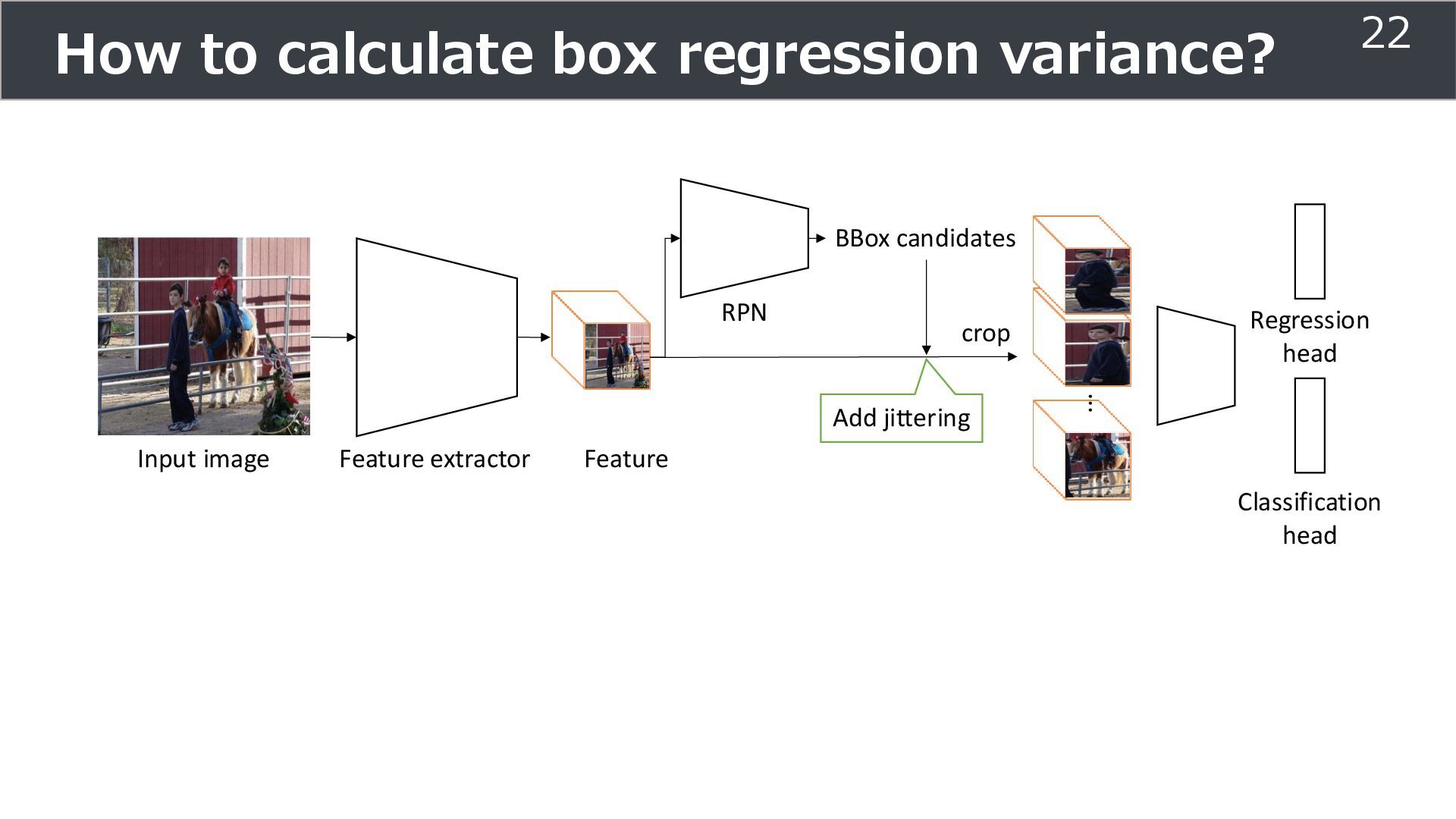
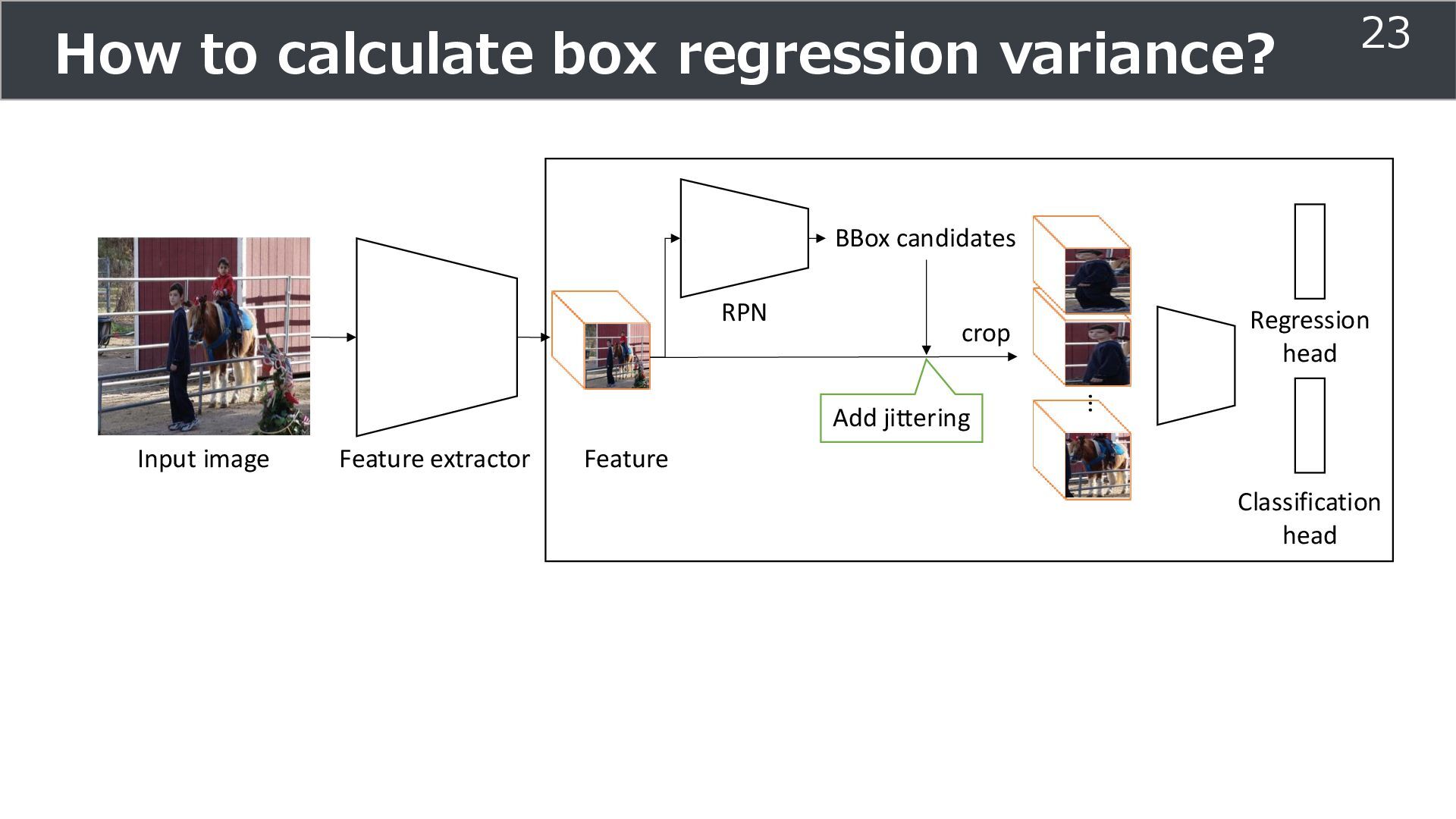
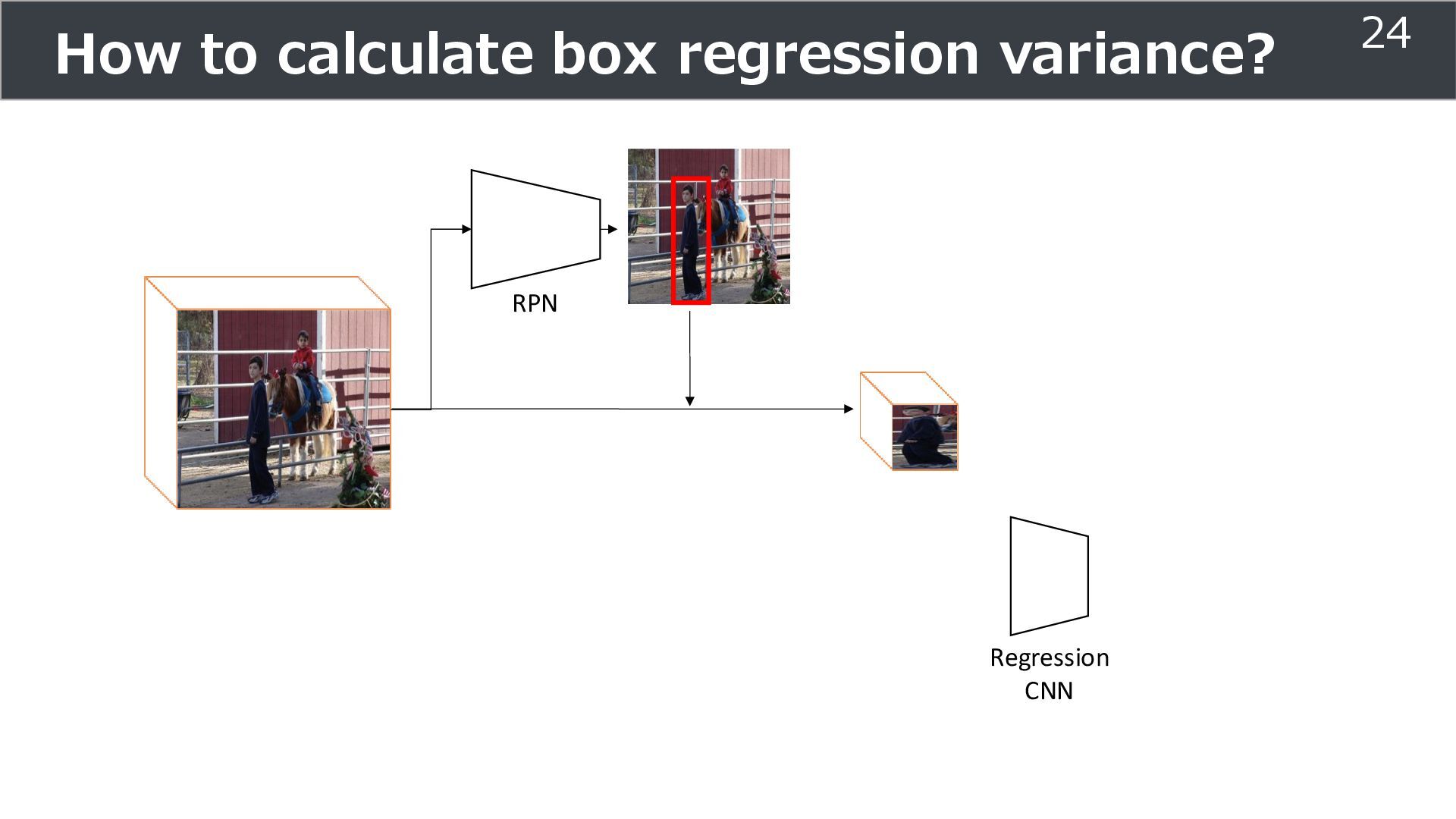
Classification head Input image Feature extractor Feature Region proposal network Proposal of bounding location (overlap is ok) ... Regression head crop ො 𝑦𝑟𝑒𝑔 object position (x, y, w, h) ො 𝑦𝑐𝑙𝑠 Class 5
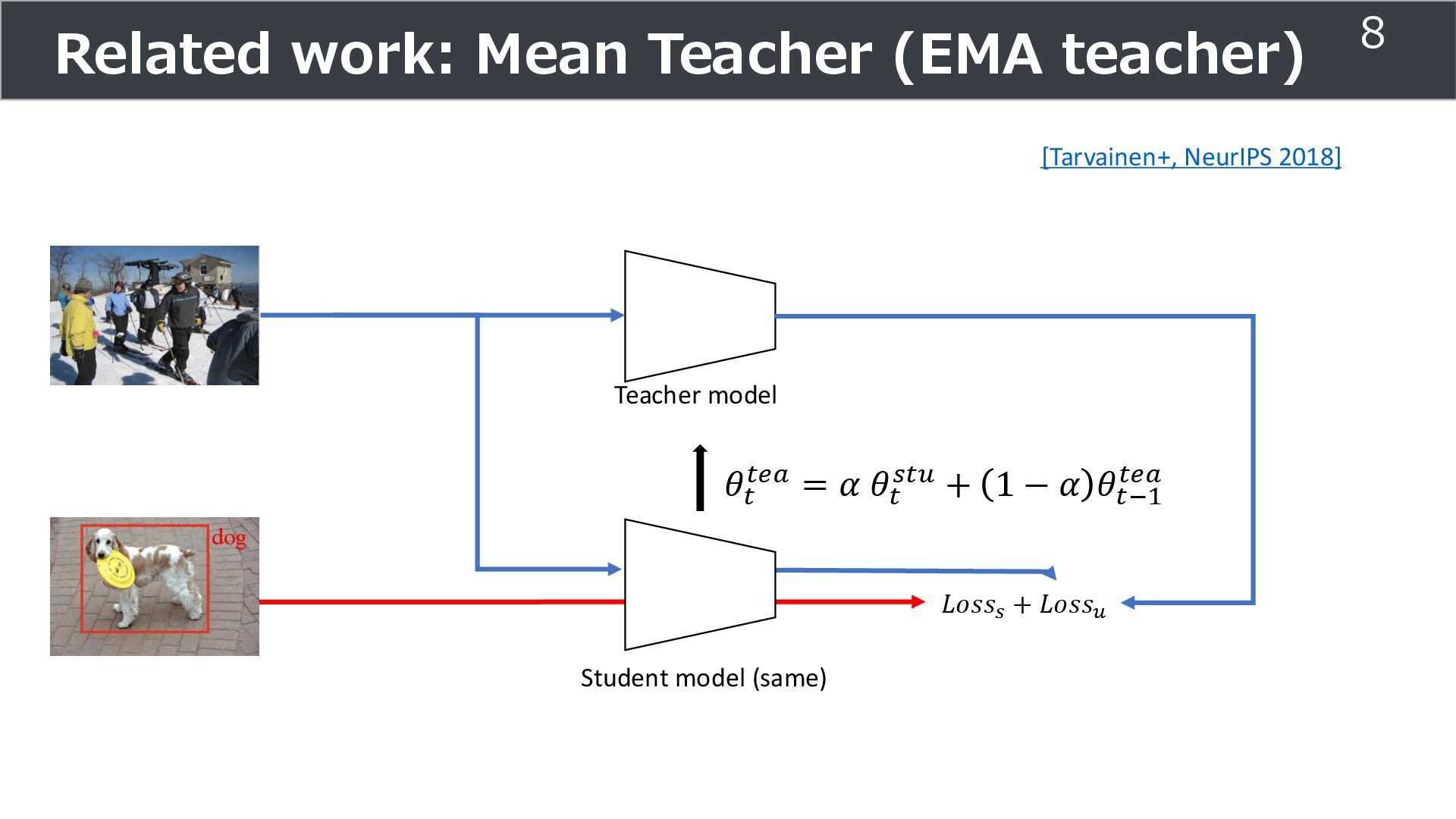
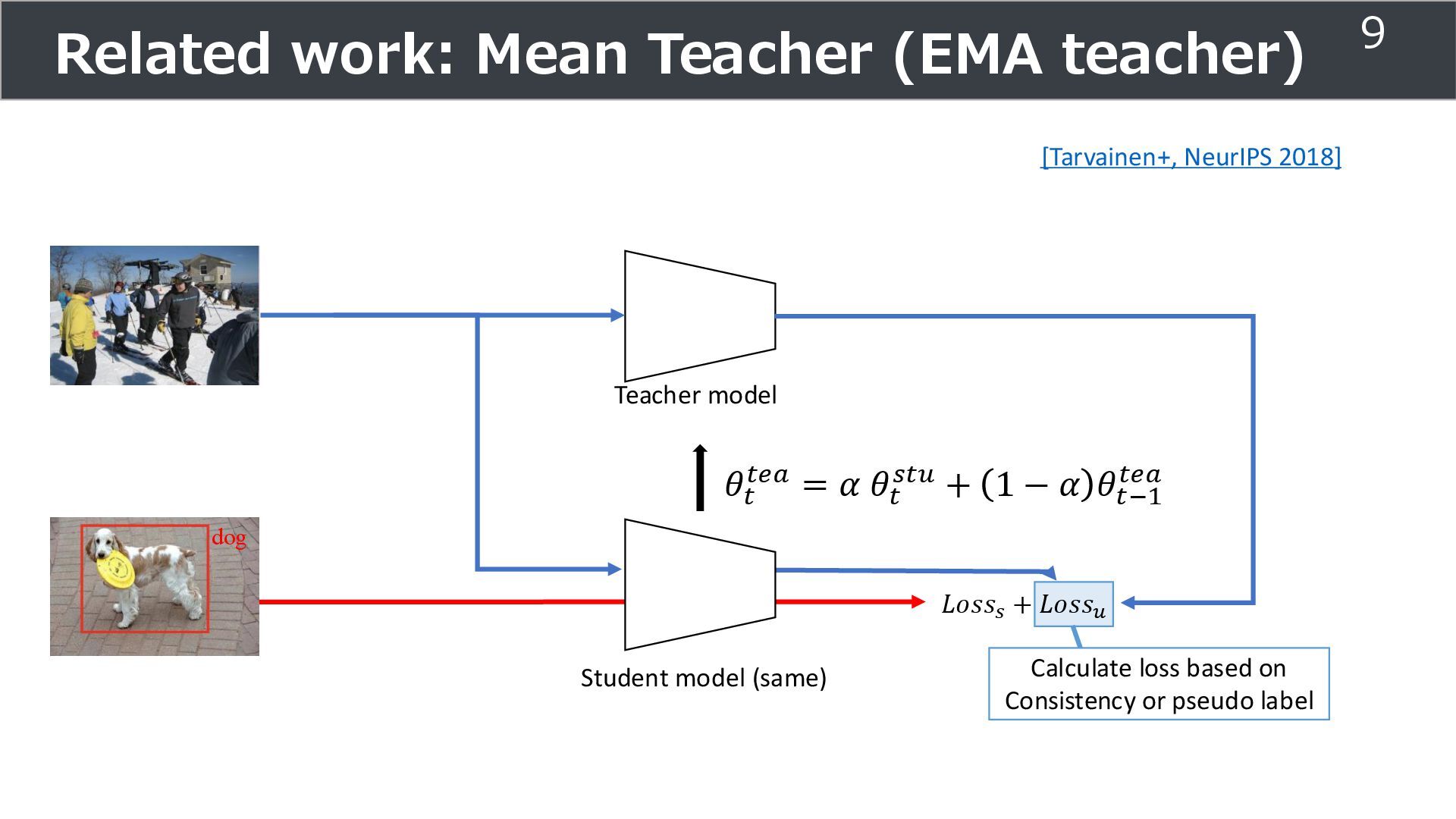
1 − 𝛼 𝜃𝑡−1 𝑡𝑒𝑎 Teacher model dog 𝐿𝑜𝑠𝑠𝑠 + 𝐿𝑜𝑠𝑠𝑢 Related work: Mean Teacher (EMA teacher) 9 Calculate loss based on Consistency or pseudo label [Tarvainen+, NeurIPS 2018]
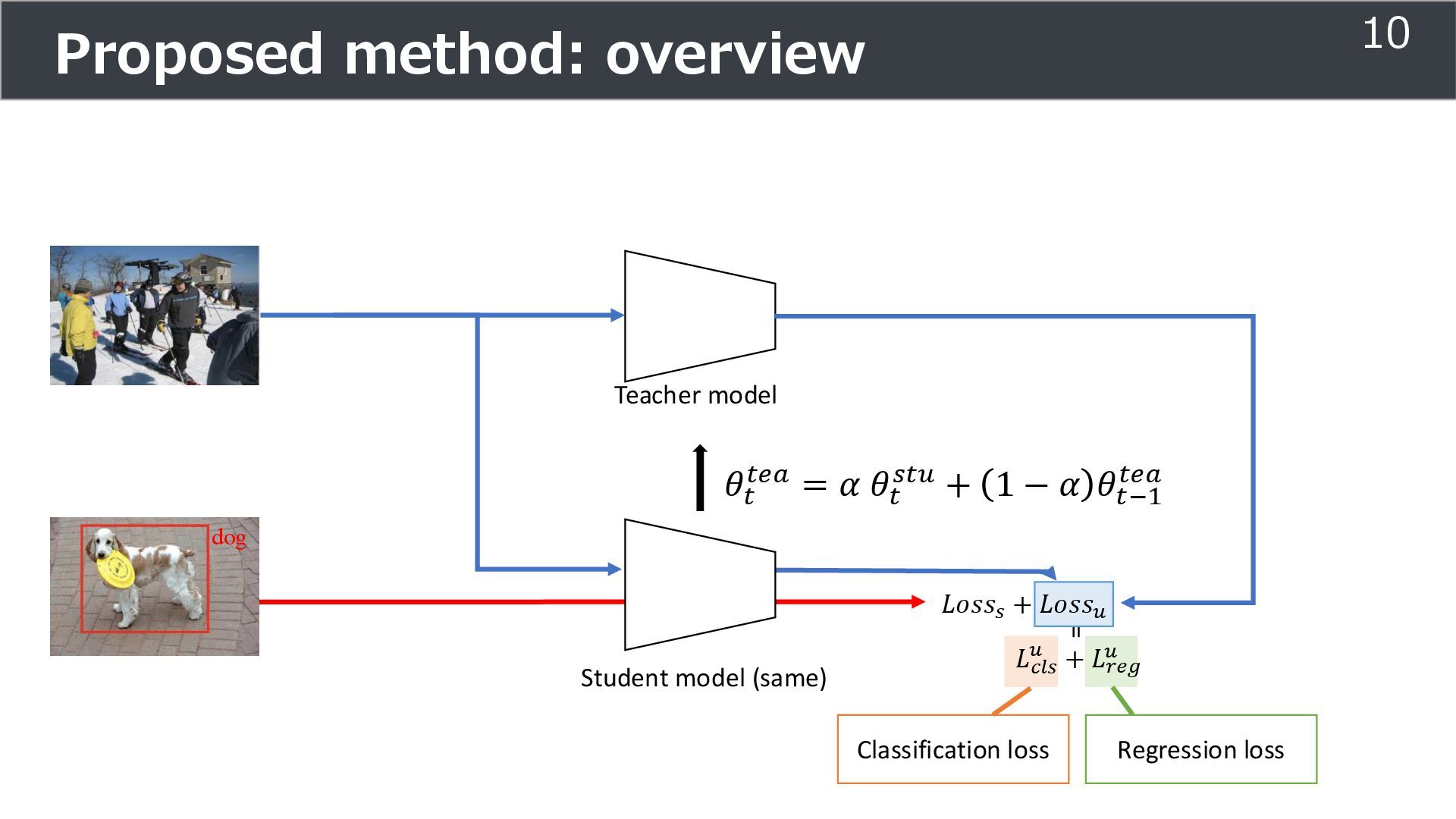
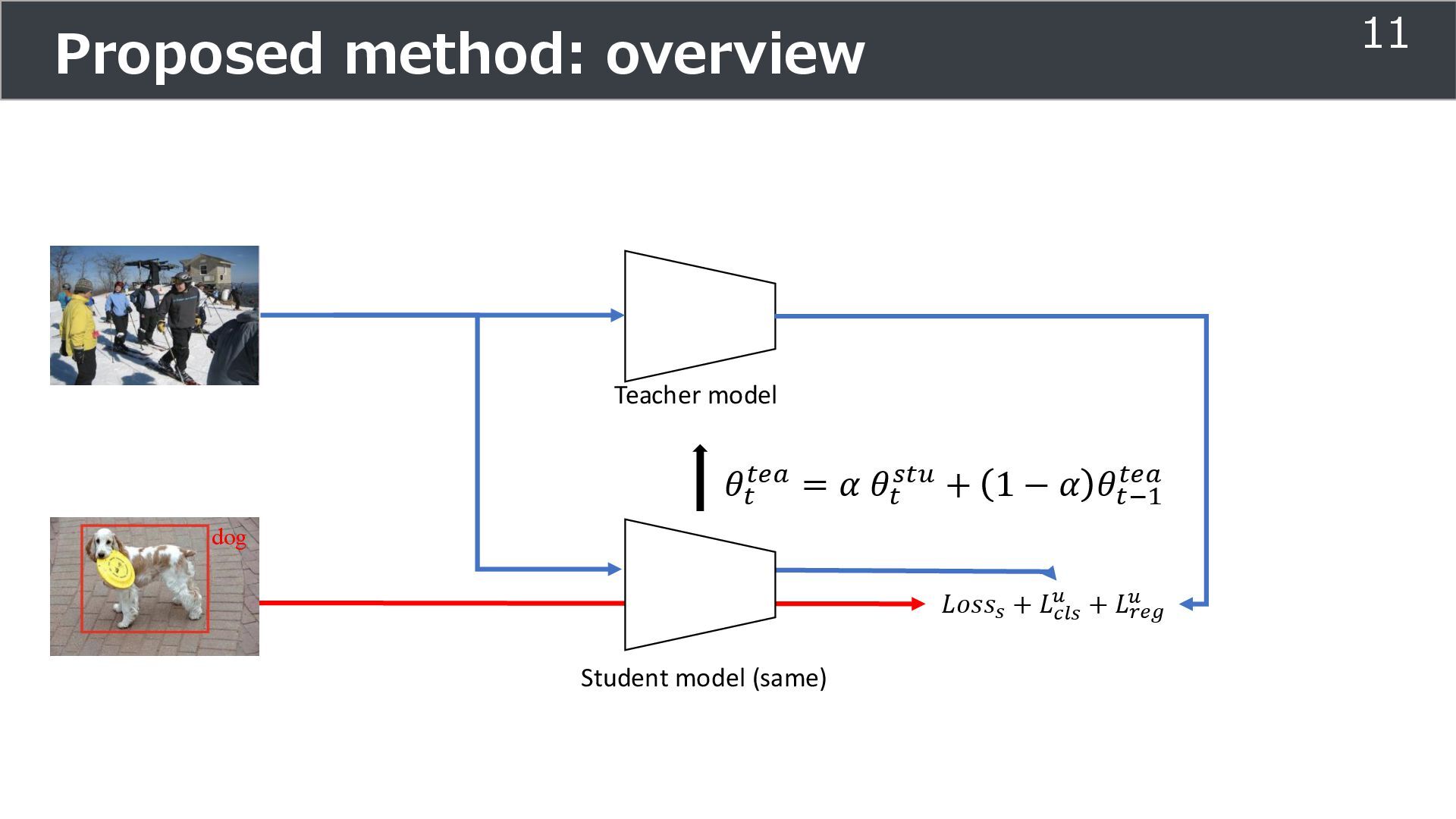
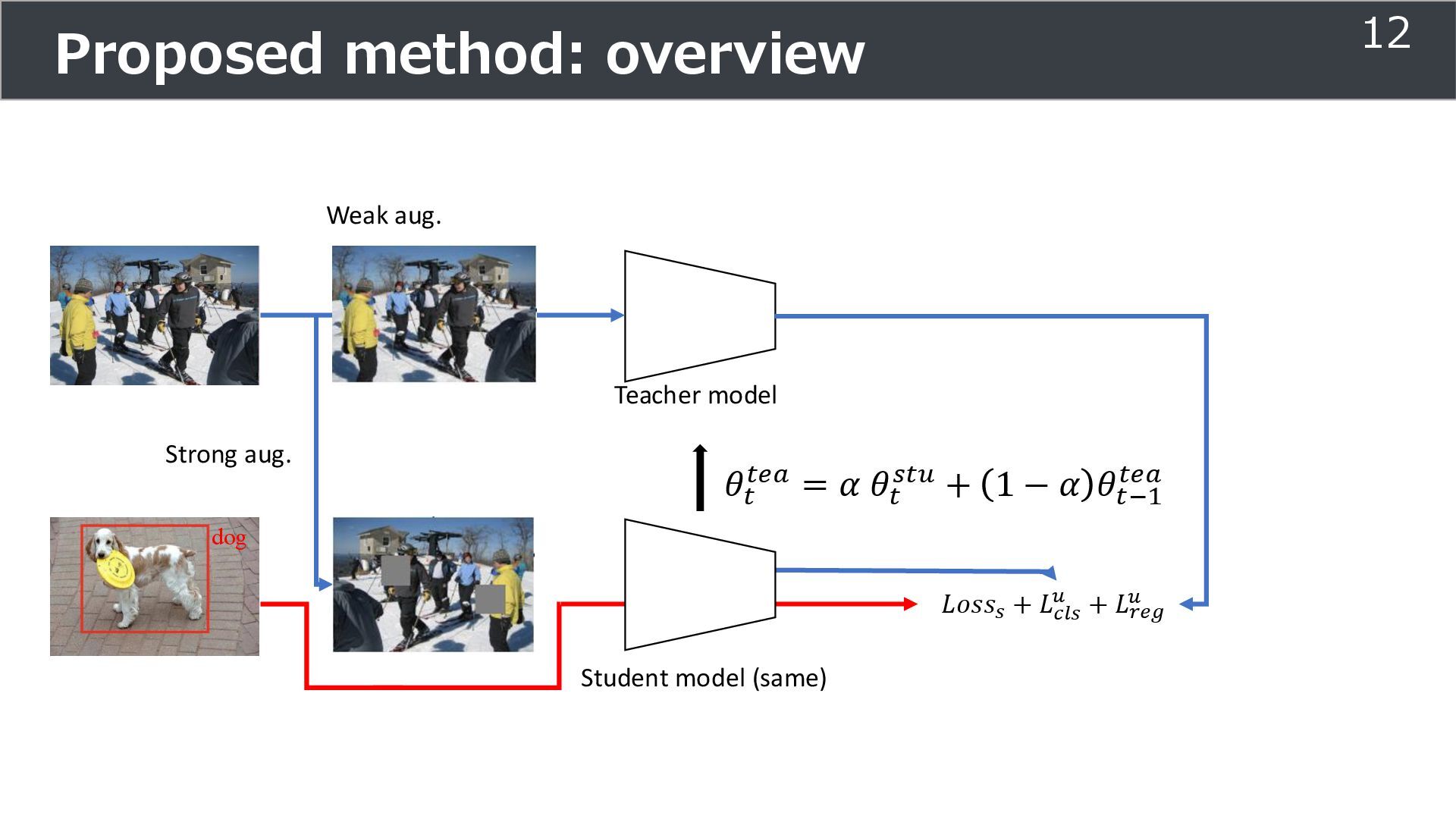
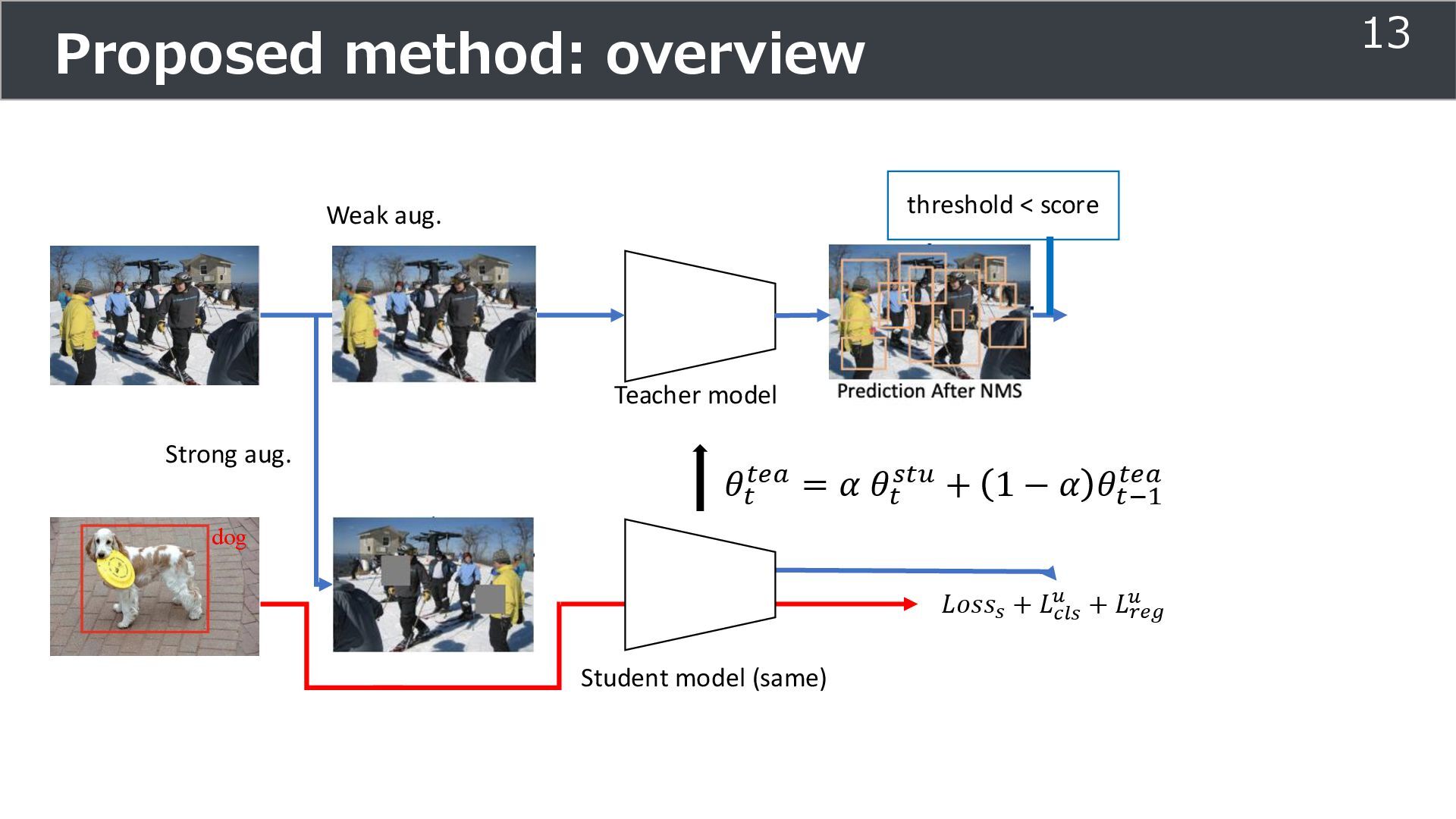
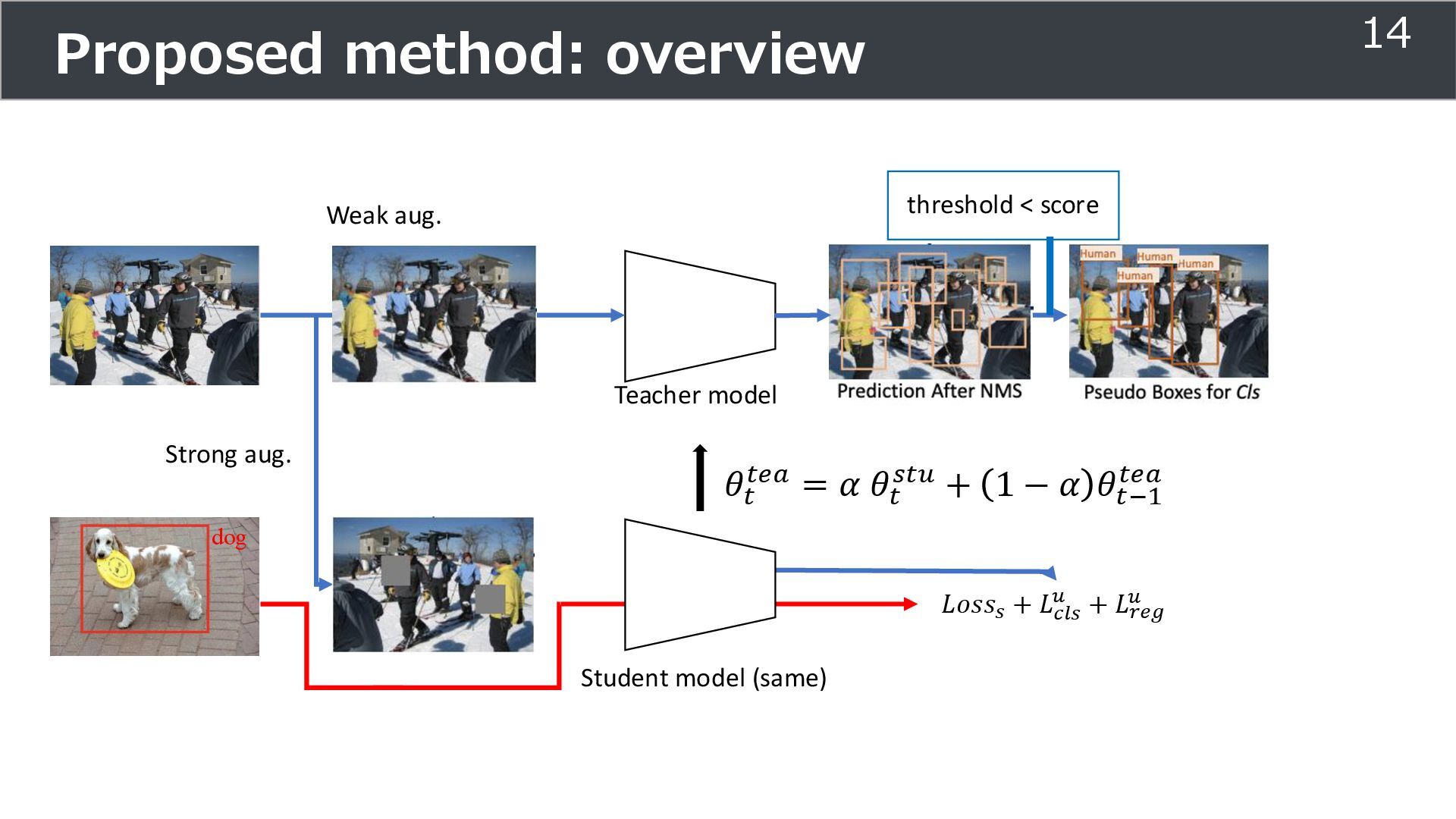
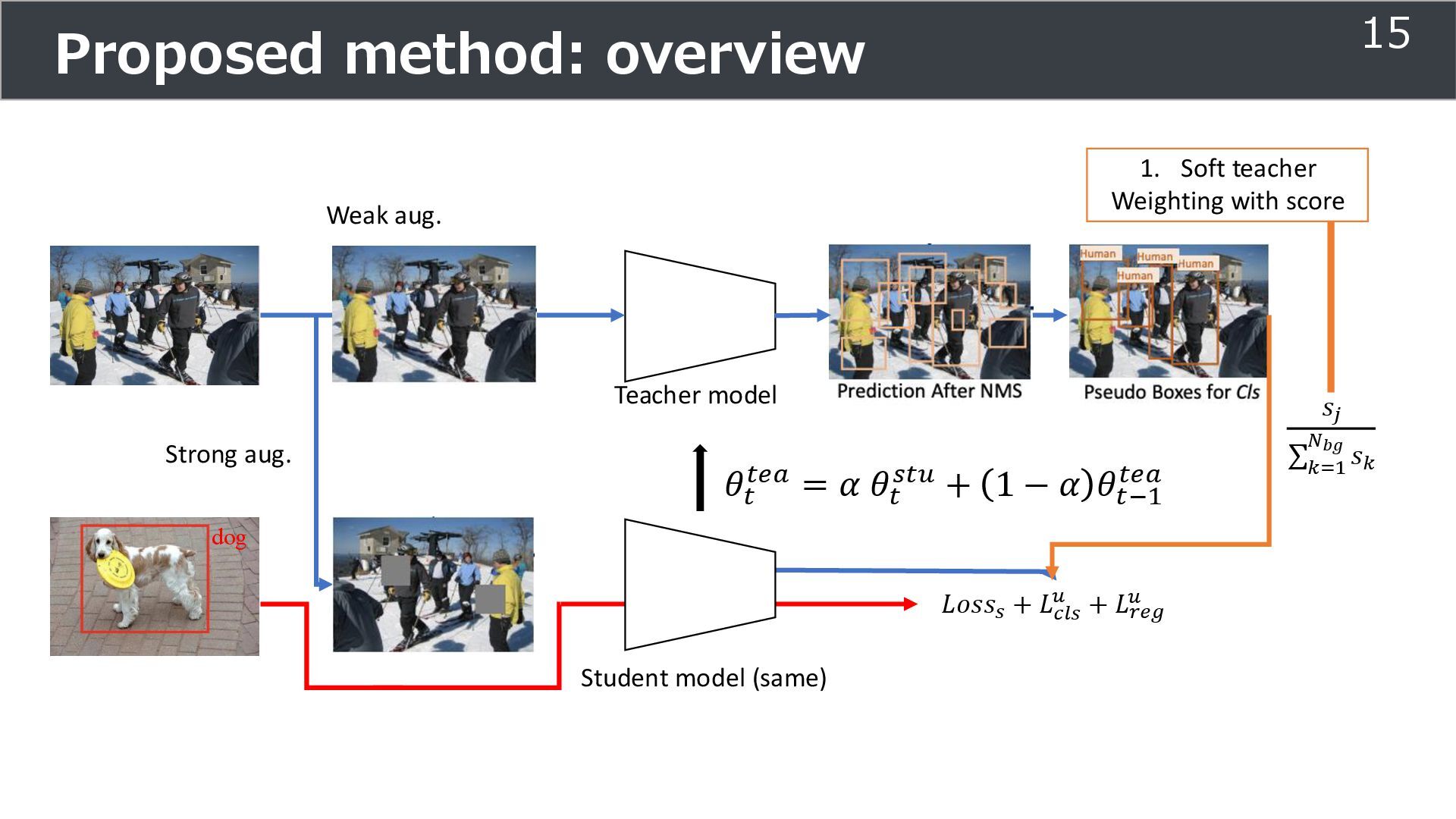
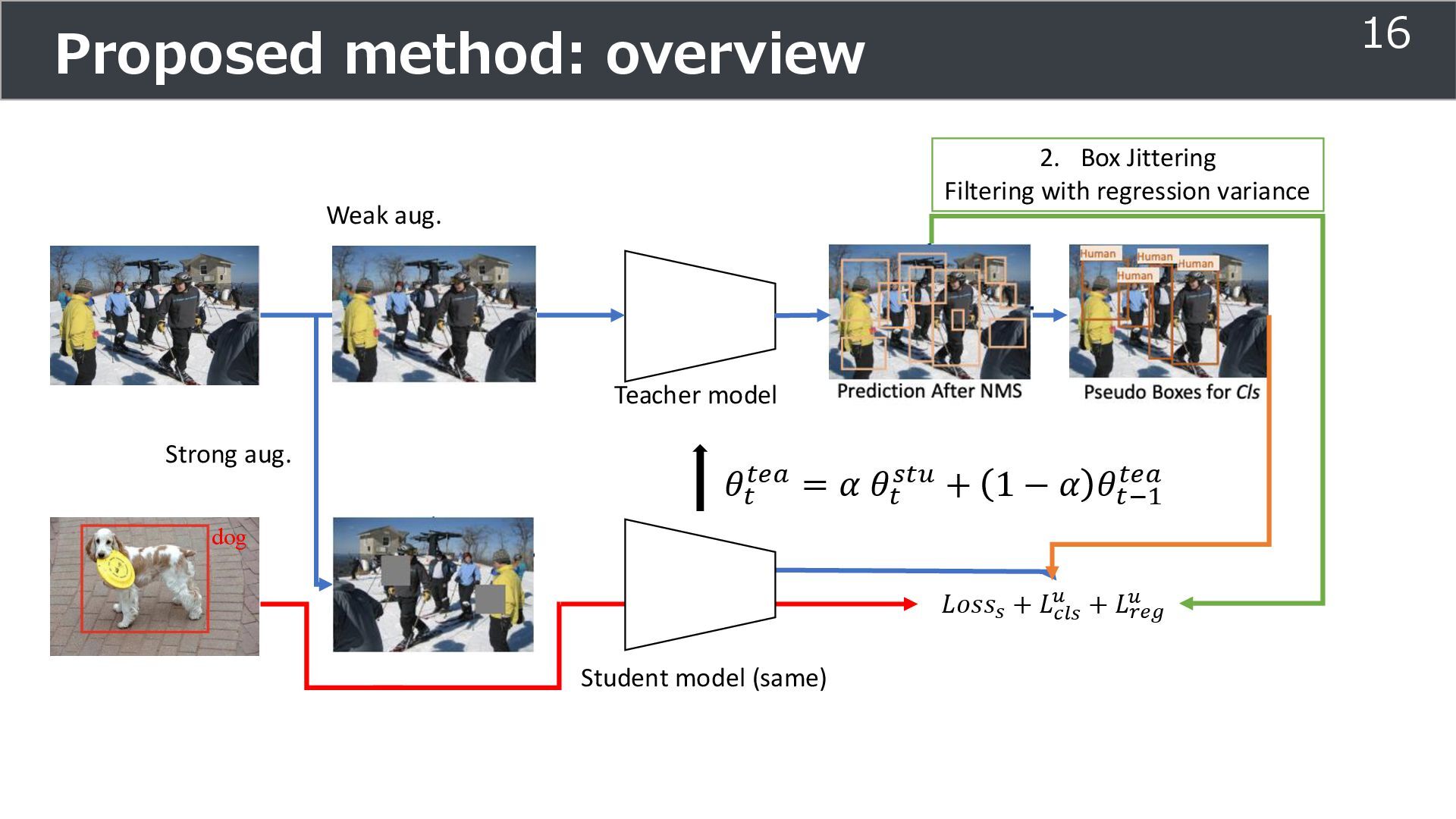
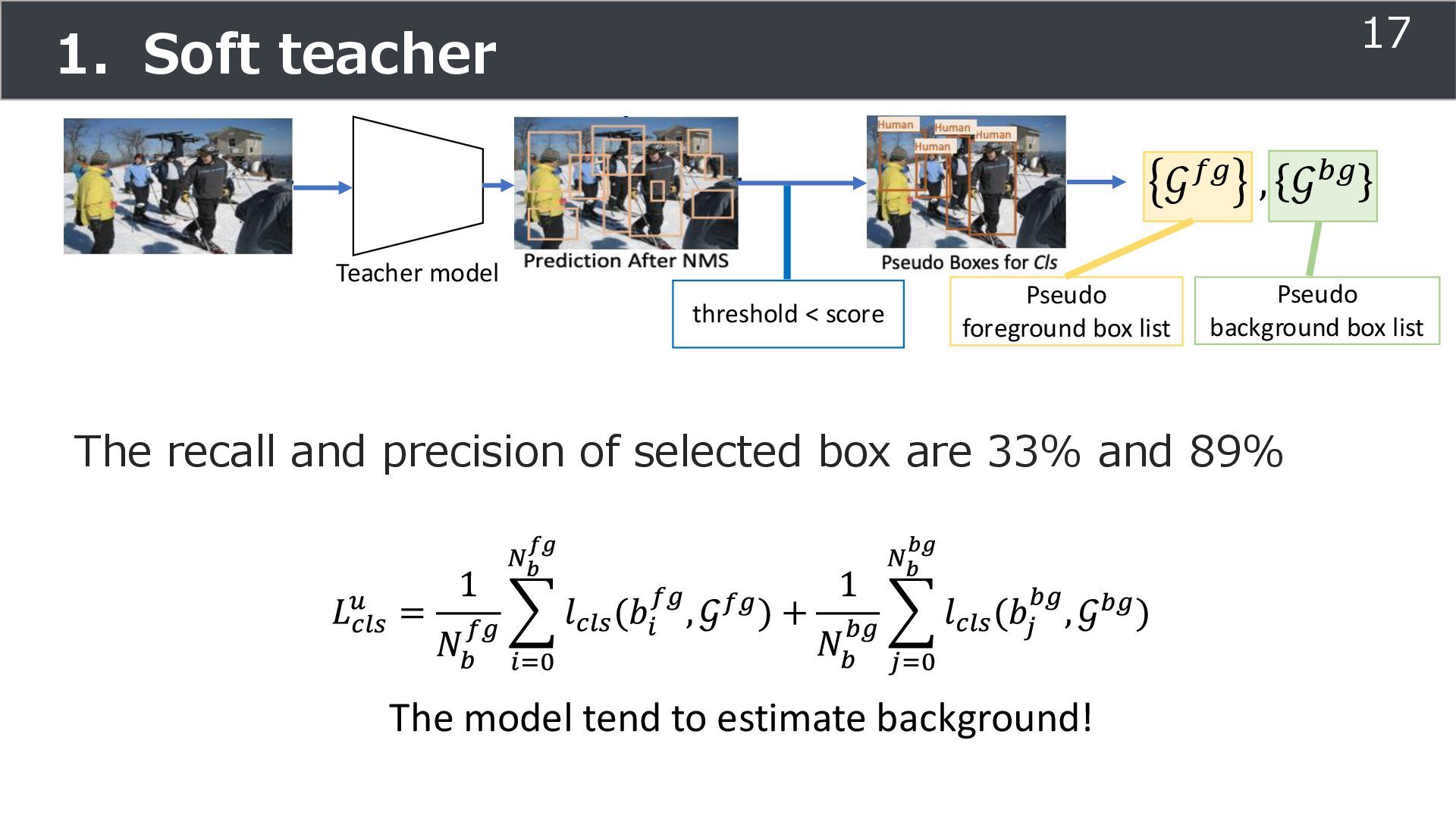
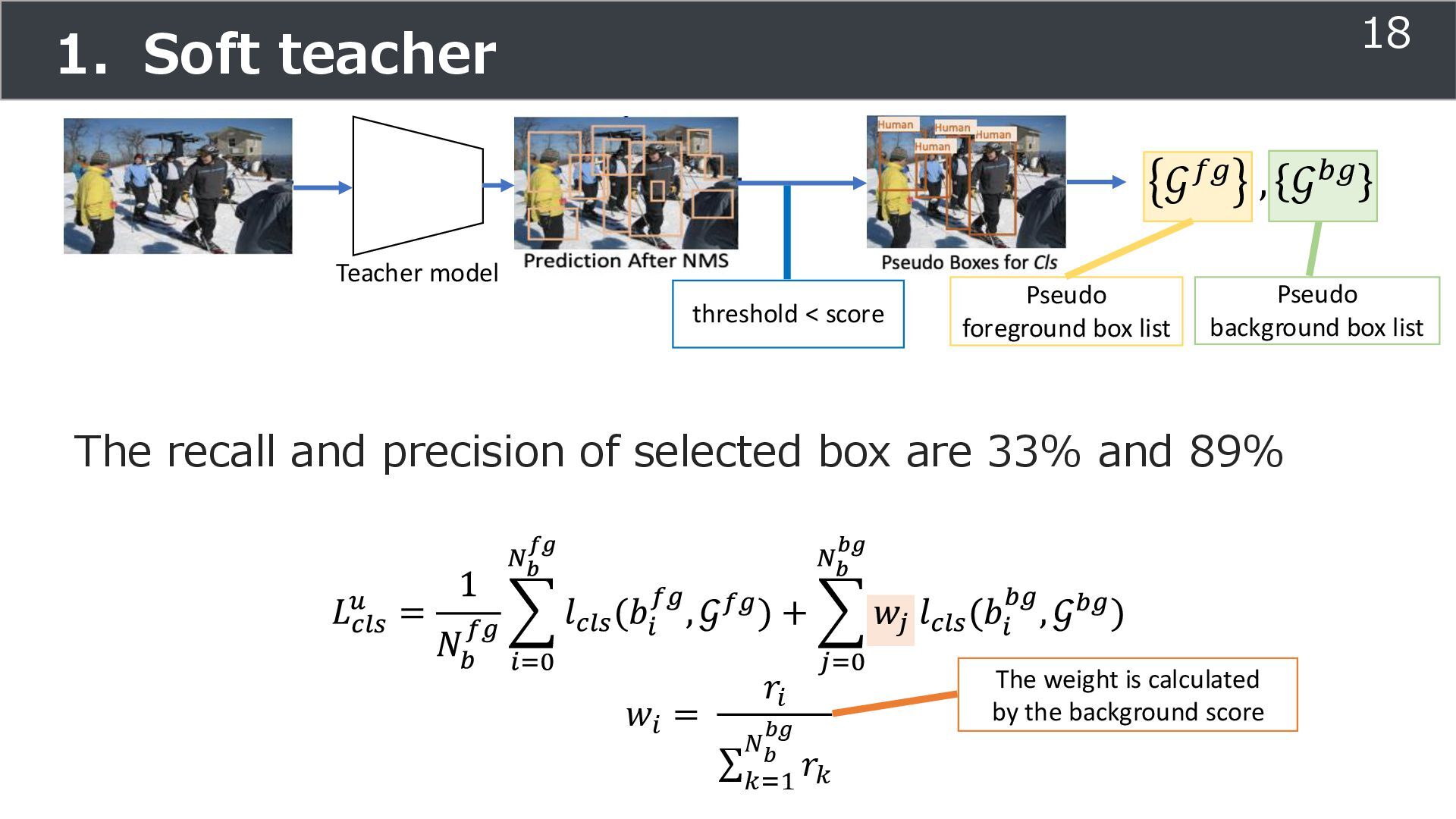
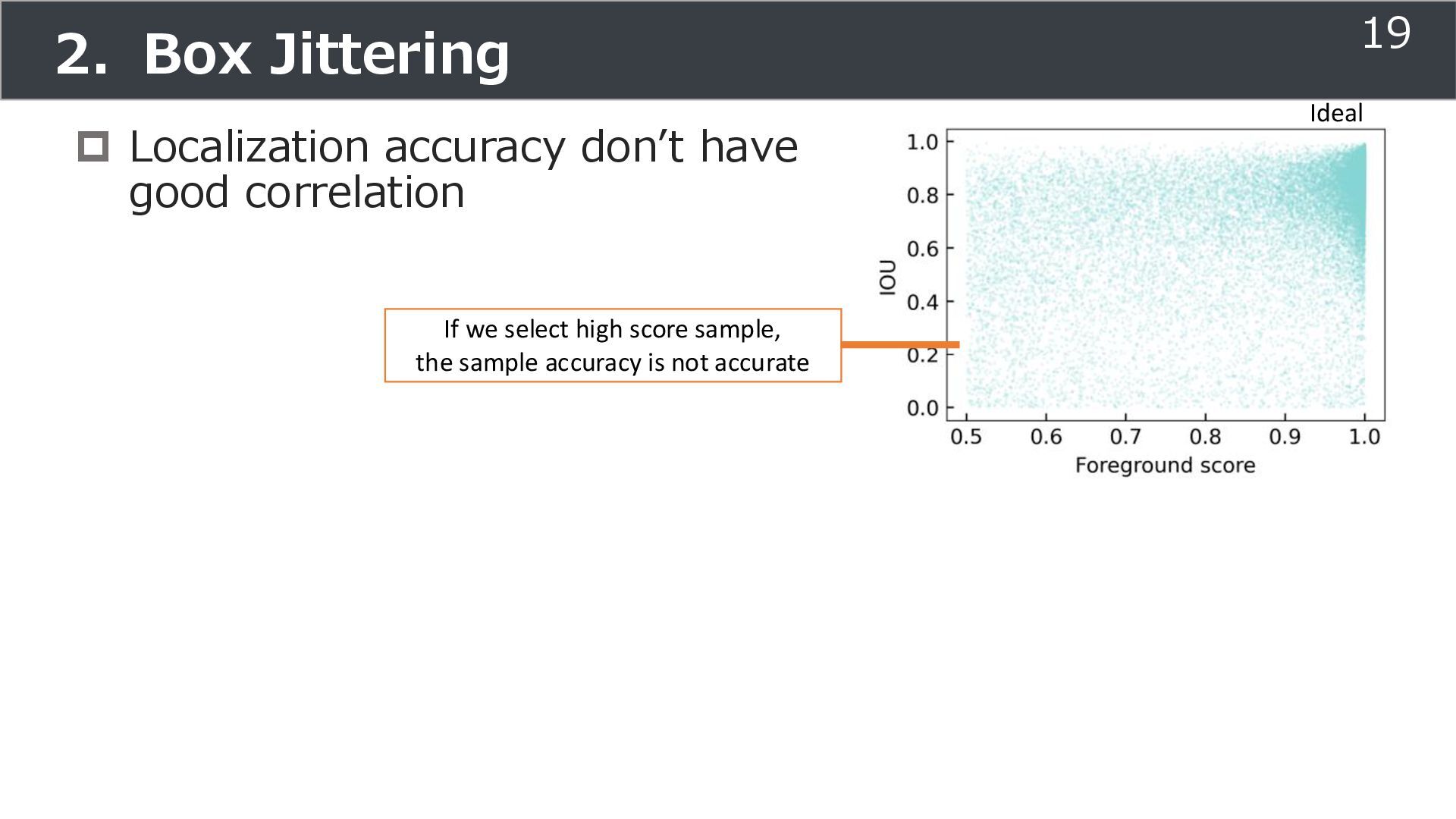
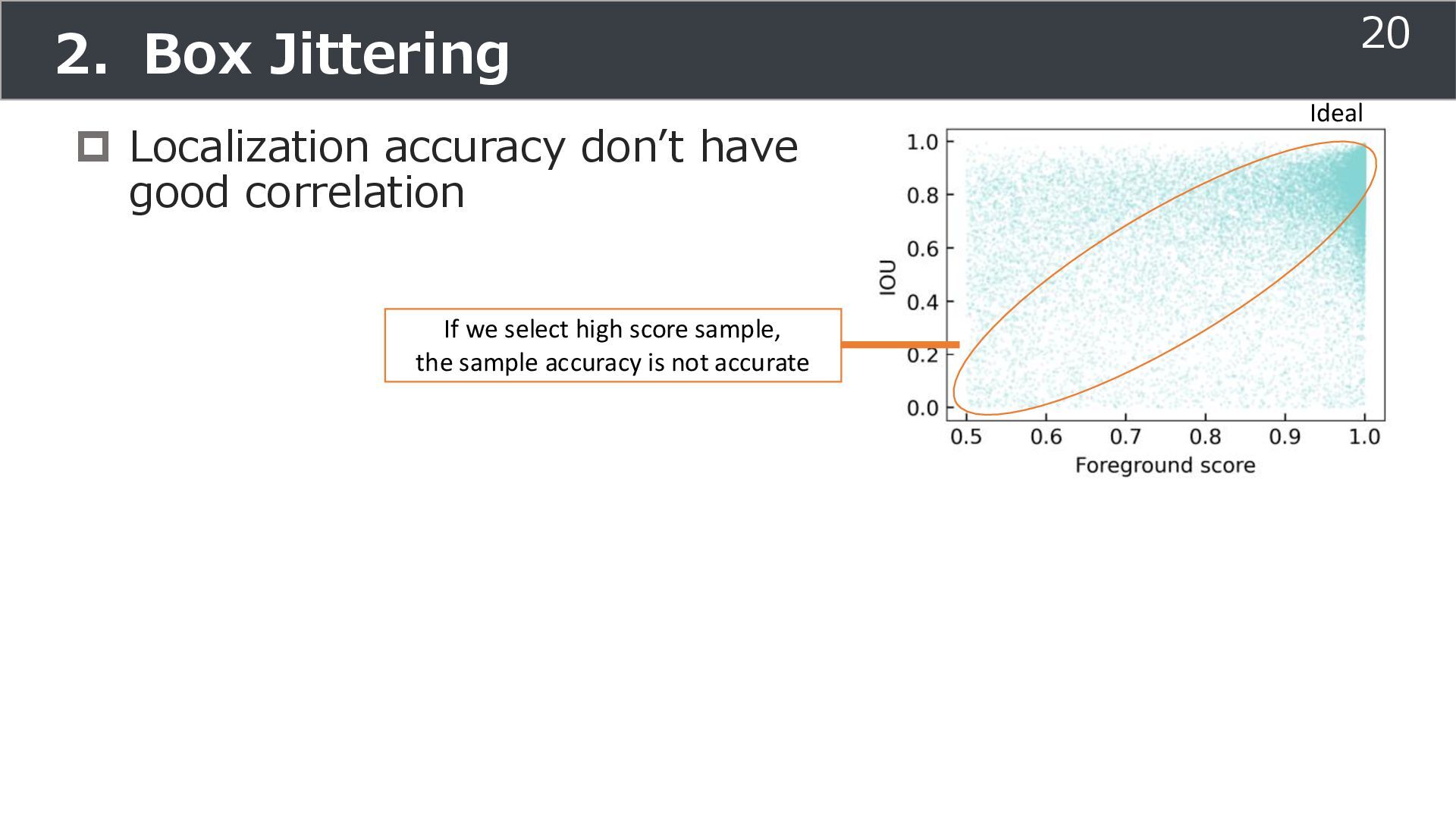
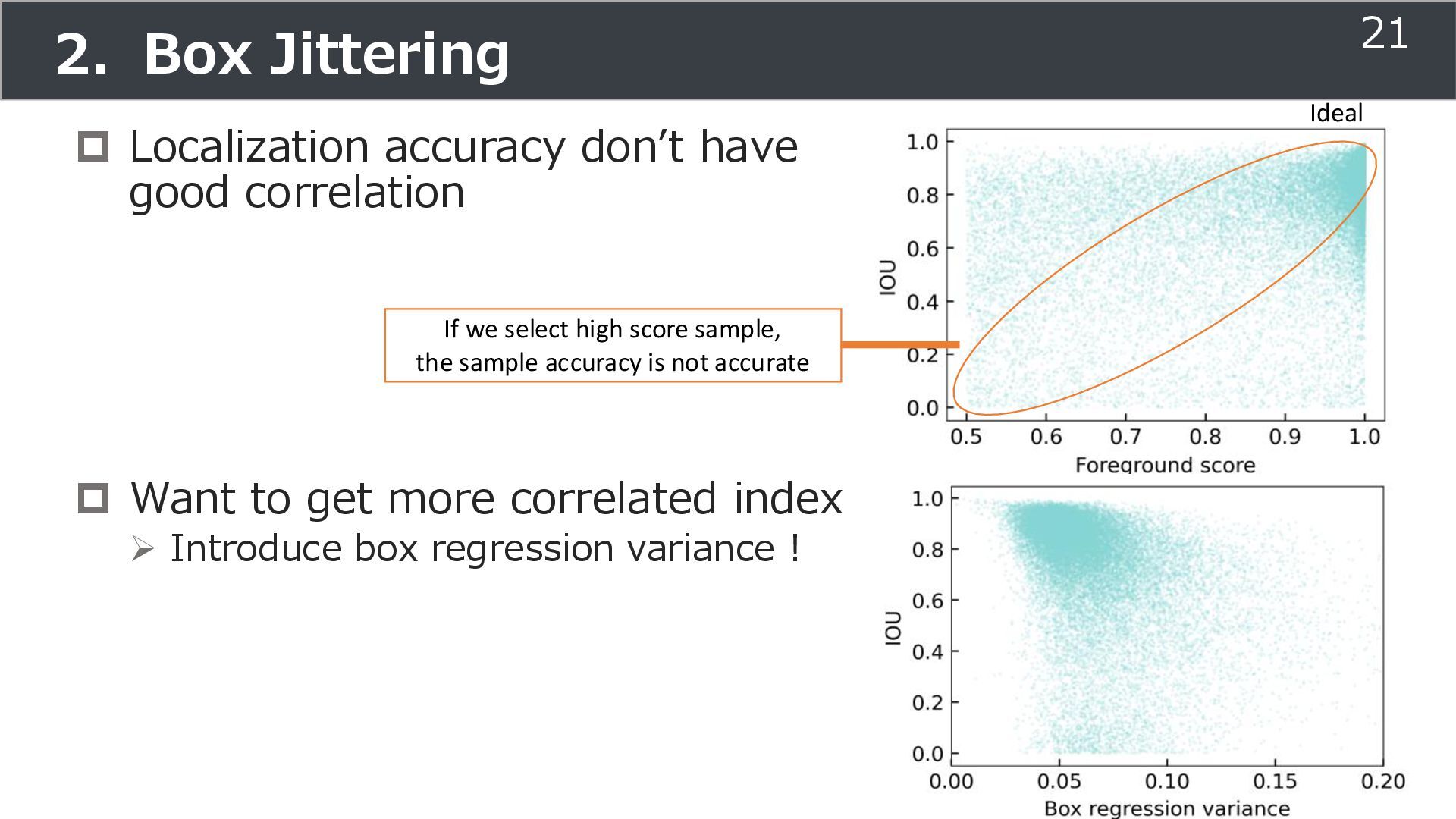
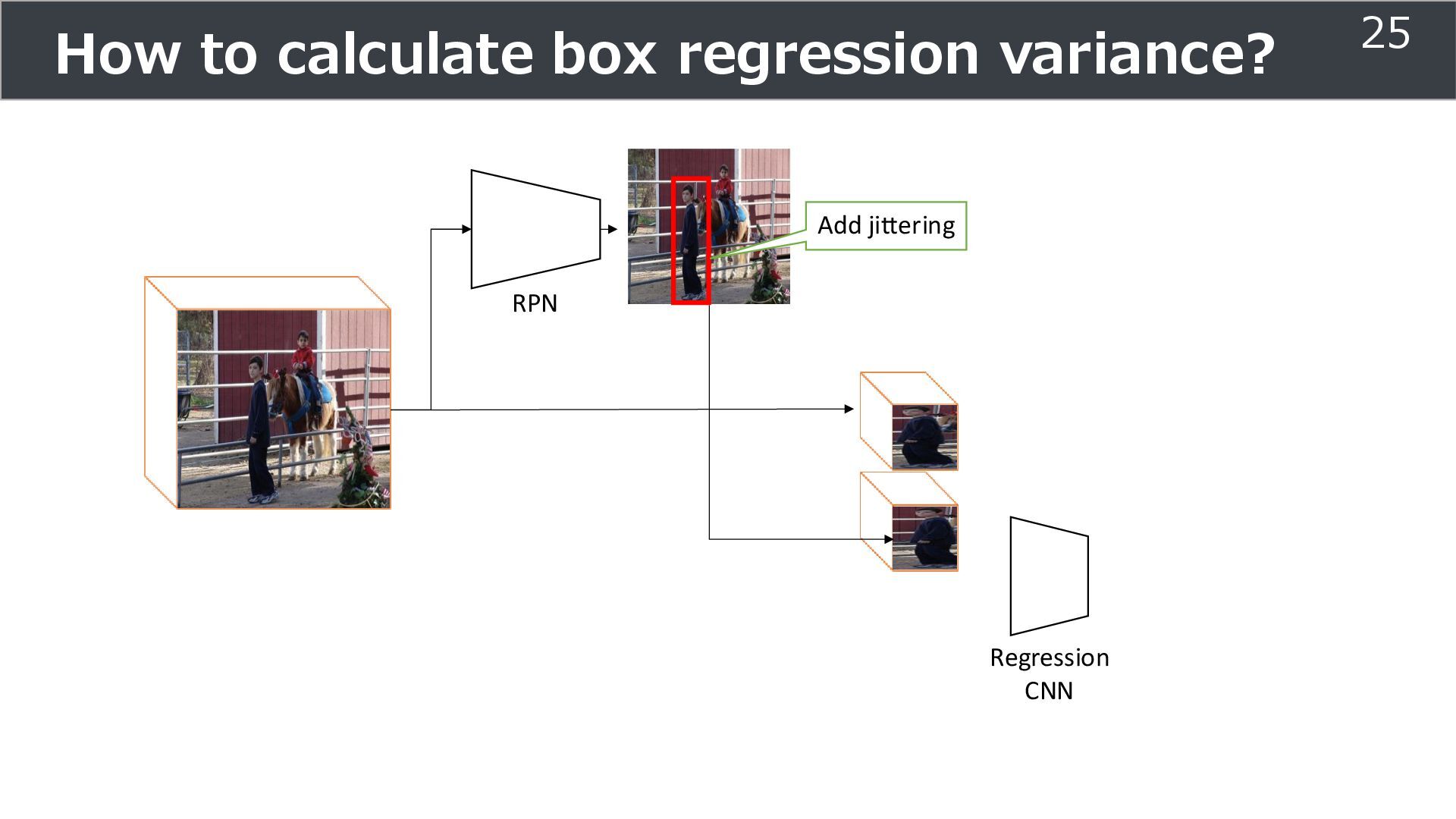
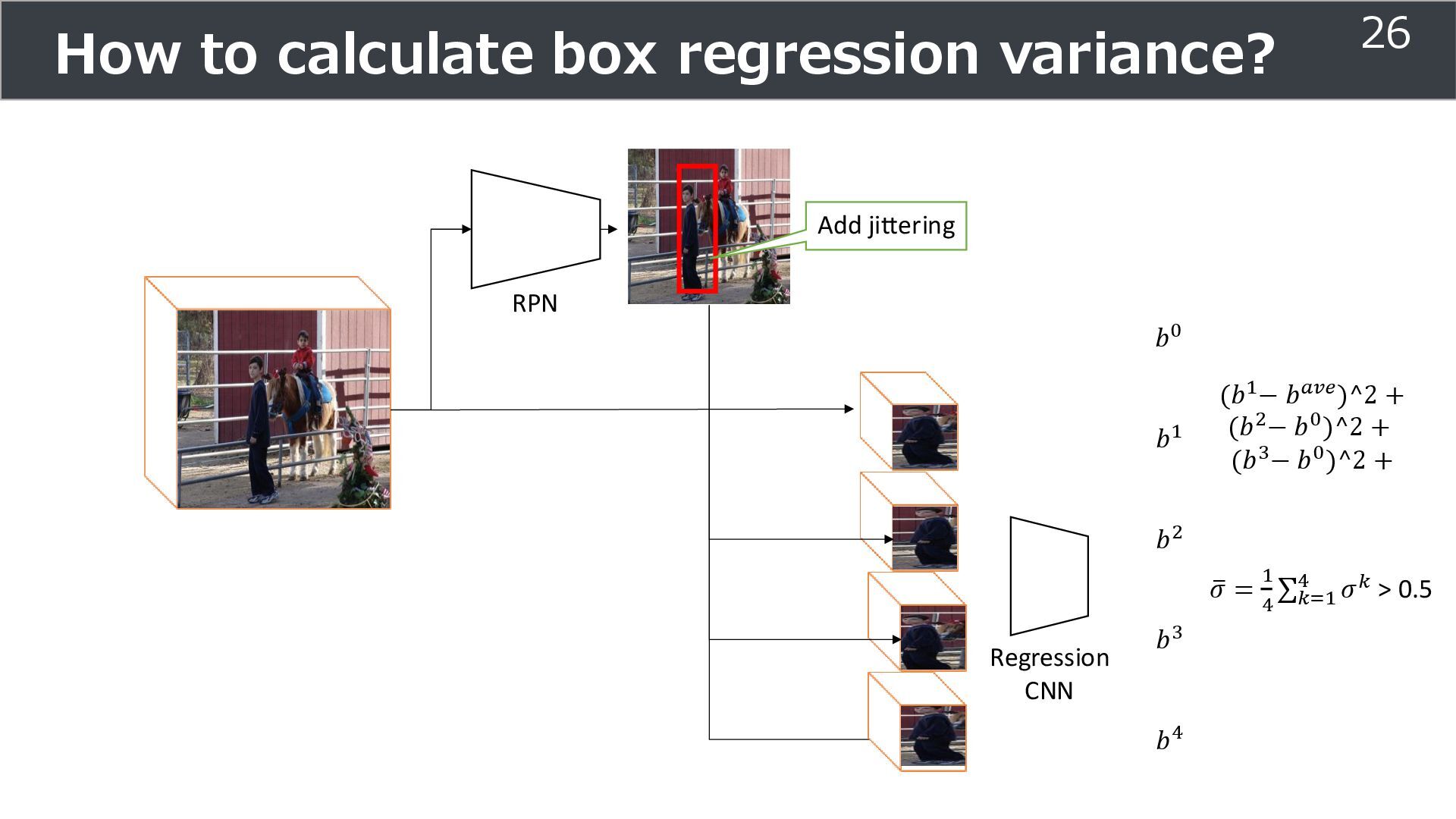
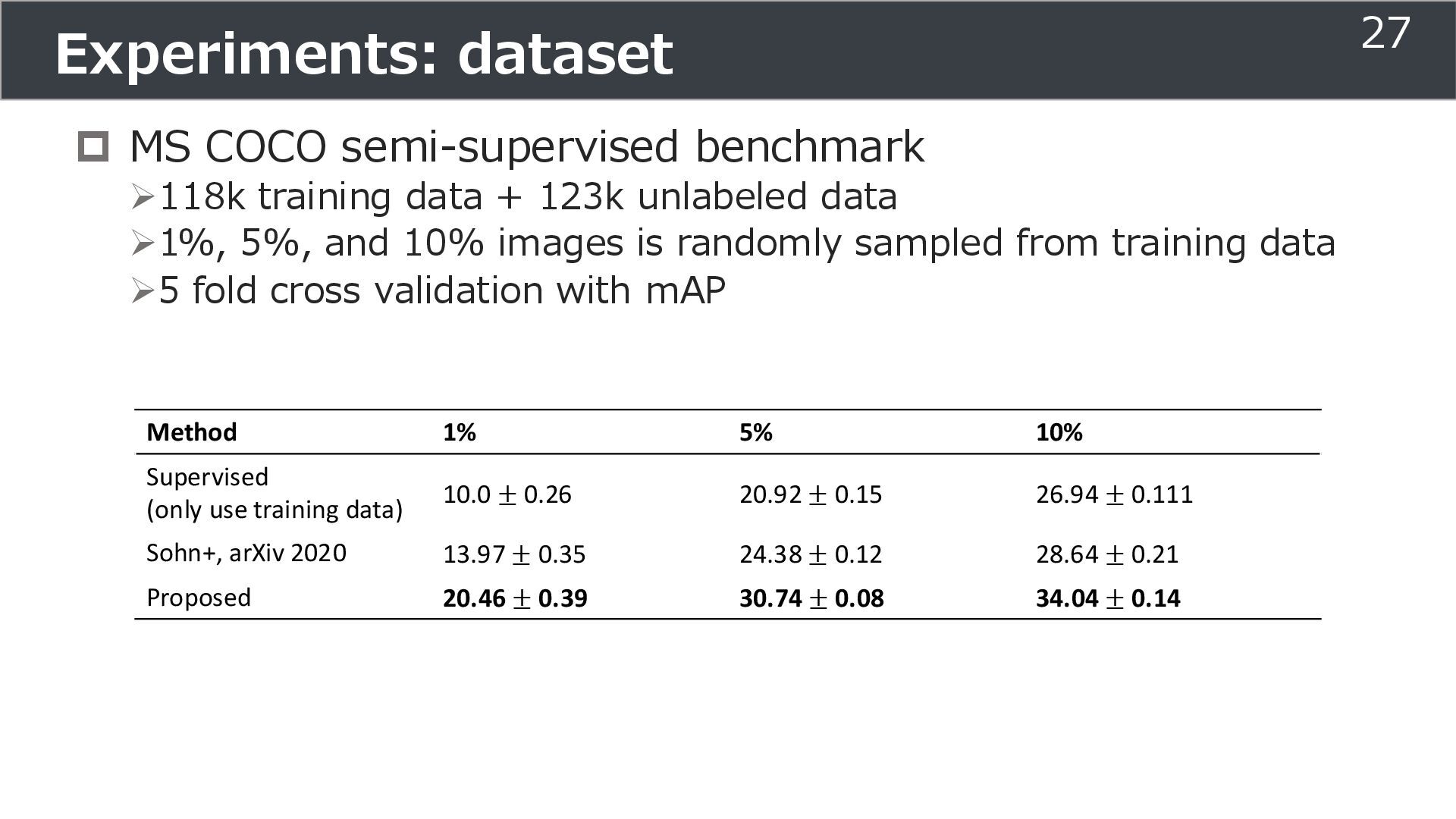
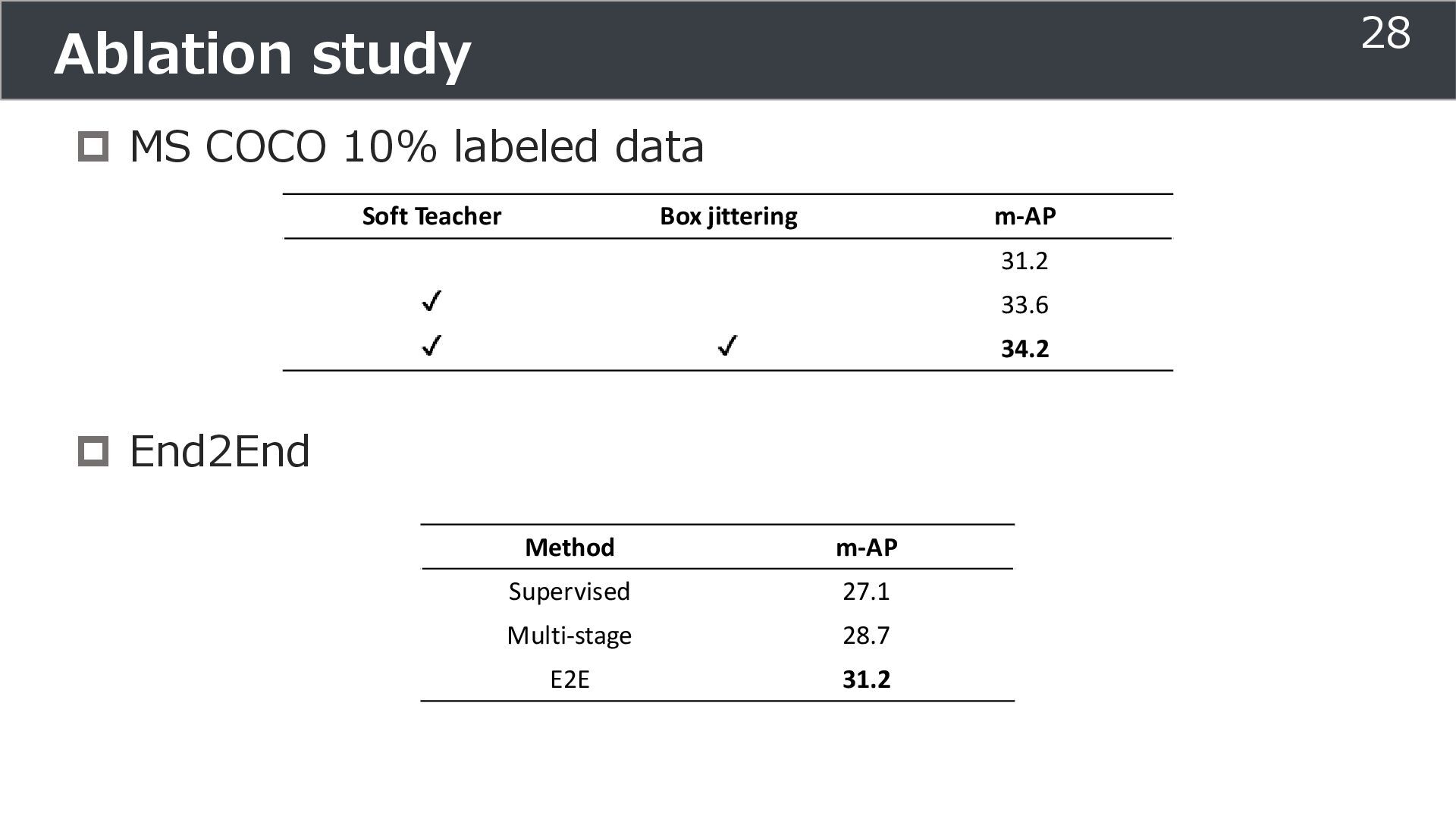
is used for training ➢Soft teacher that effectively transfer teacher info. ➢Box jittering that can omit inaccurate pseudo-label Outperforms SoTA methods on MS COCO benchmark Take home message ➢Teacher and student framework is used for various task 29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}