Explore The Workshop:
https://github.com/microsoft/Build26-LAB540-observe-optimize-and-protect-your-hosted-agents-in-microsoft-foundry
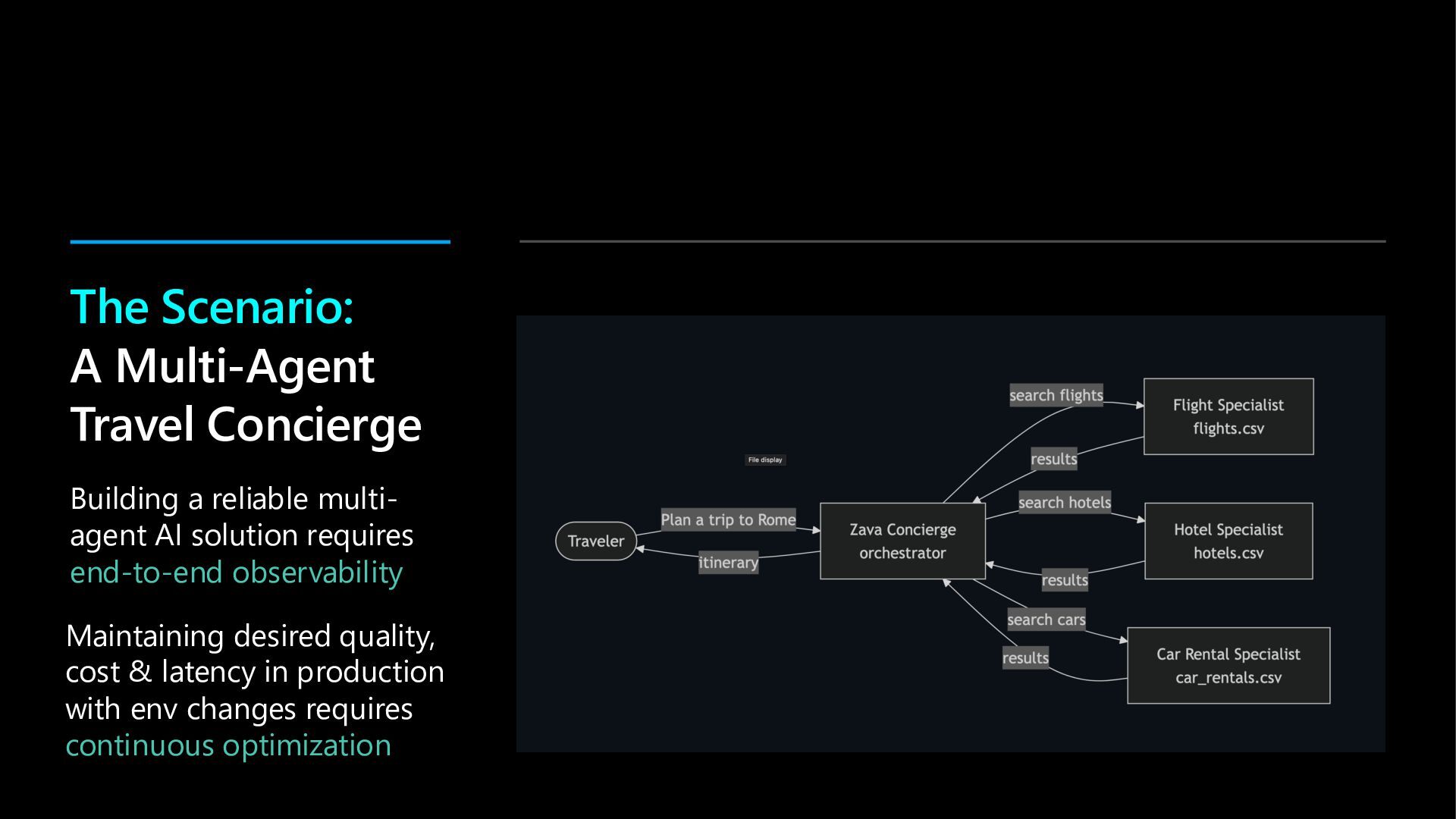
Modern agents can fail in ways that traditional monitoring can't catch.
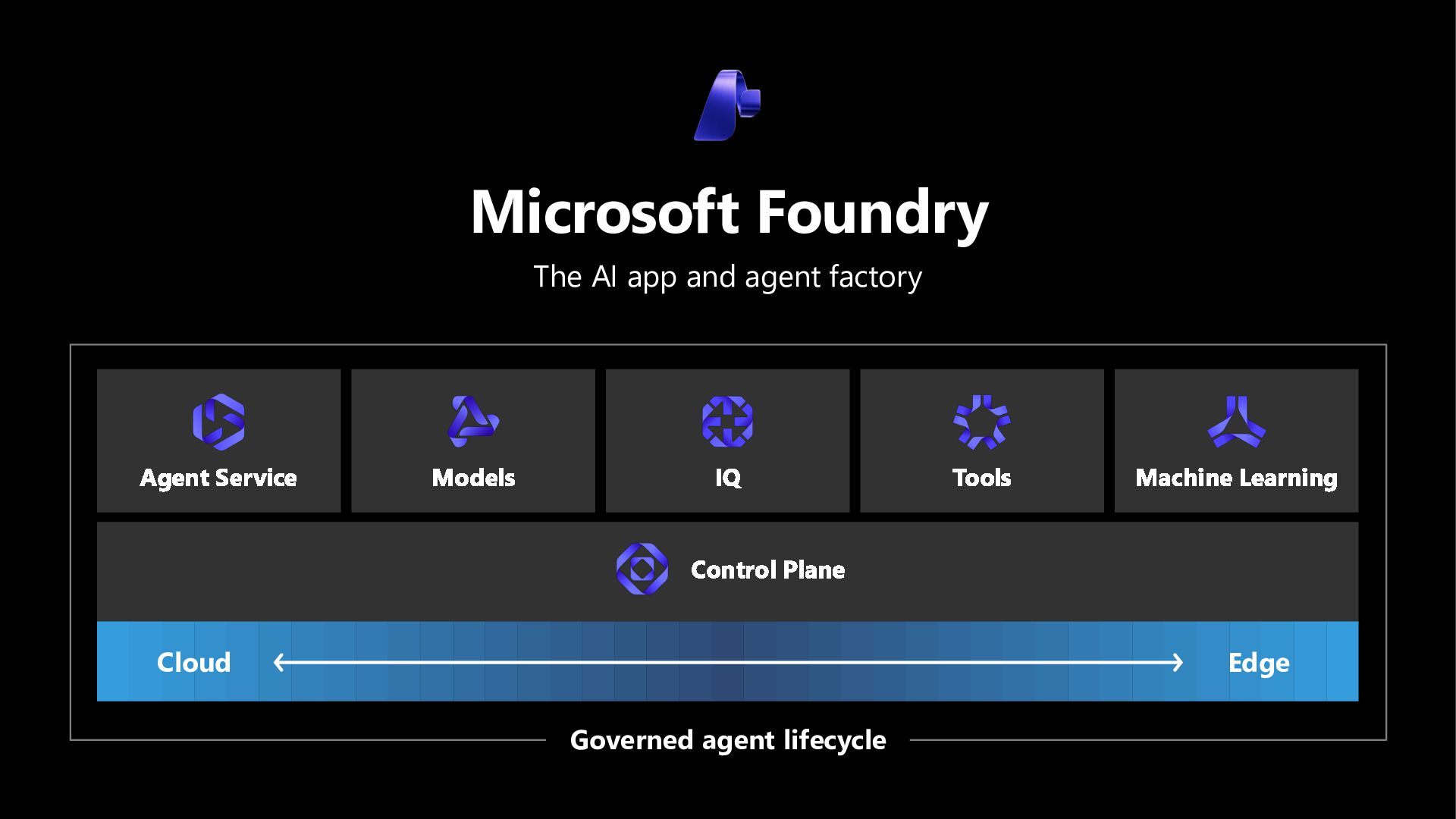
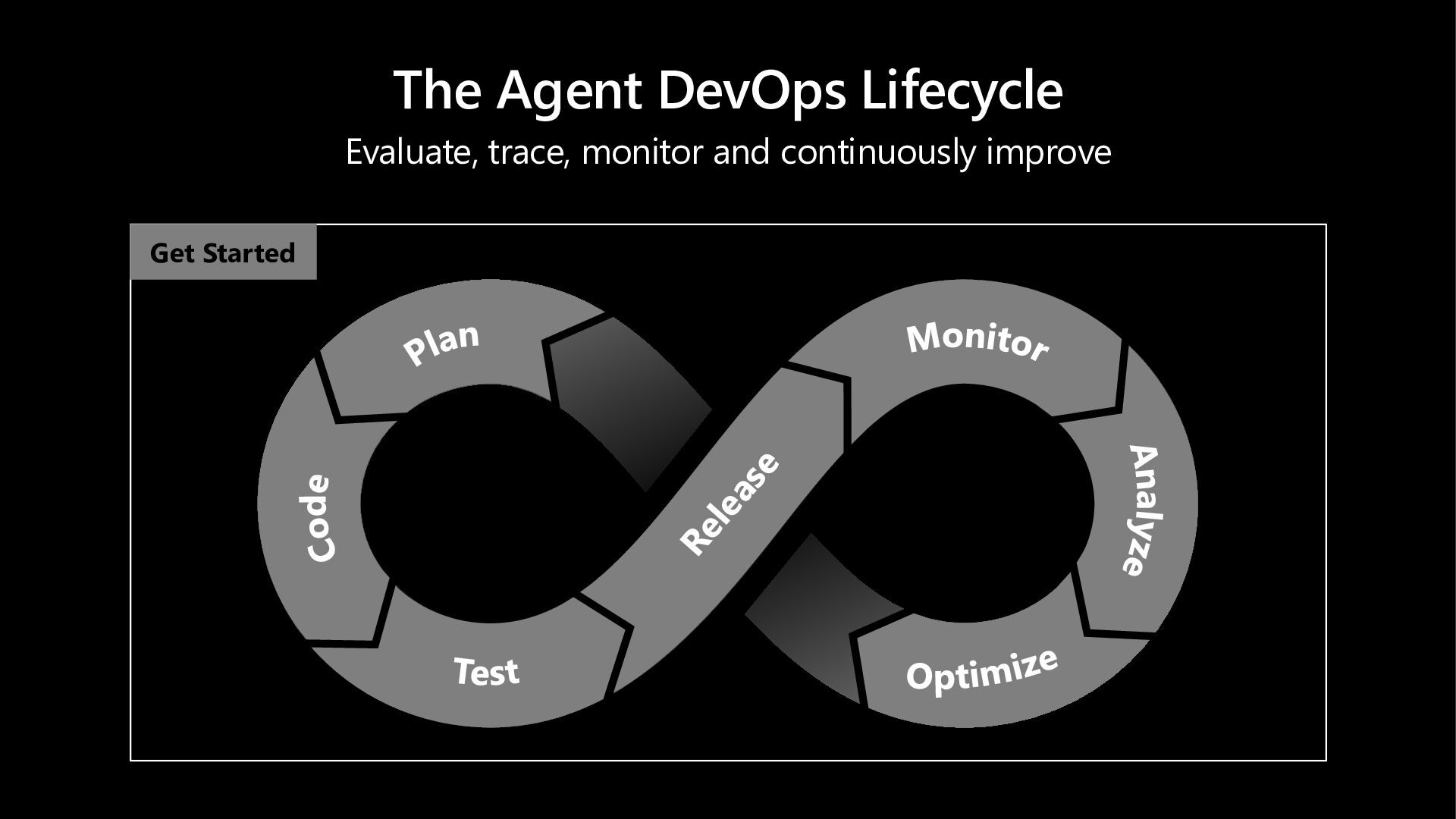
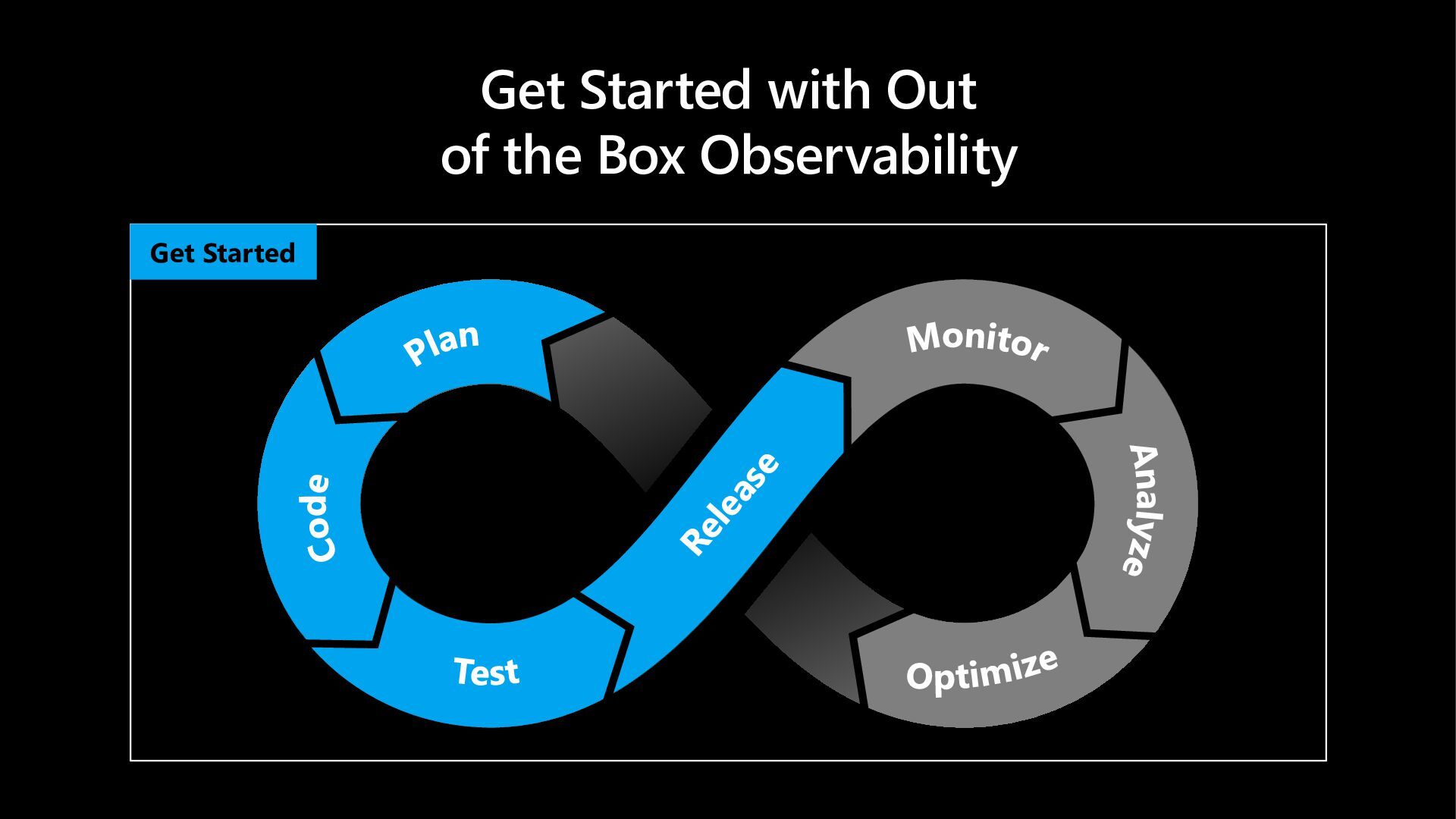
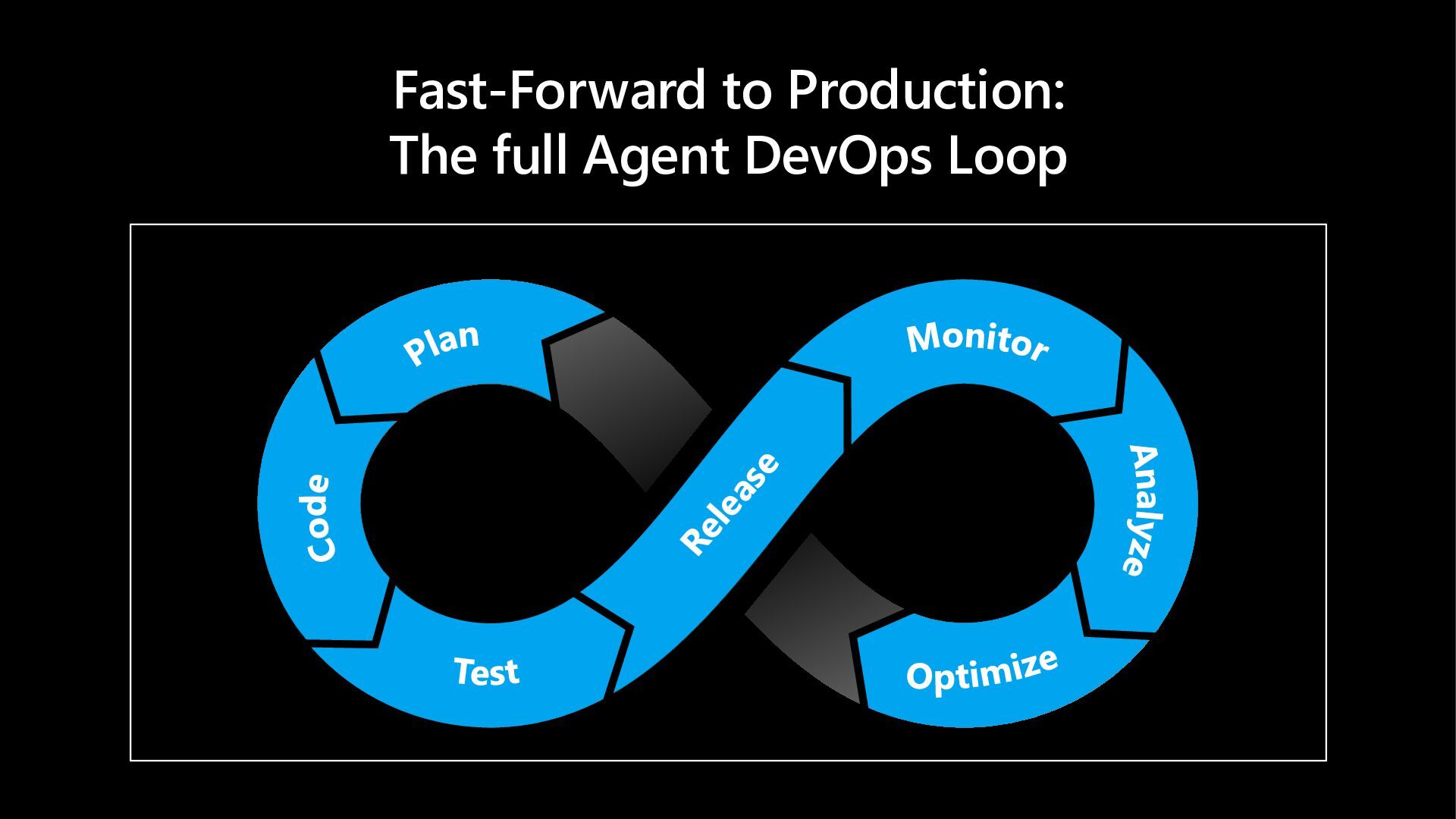
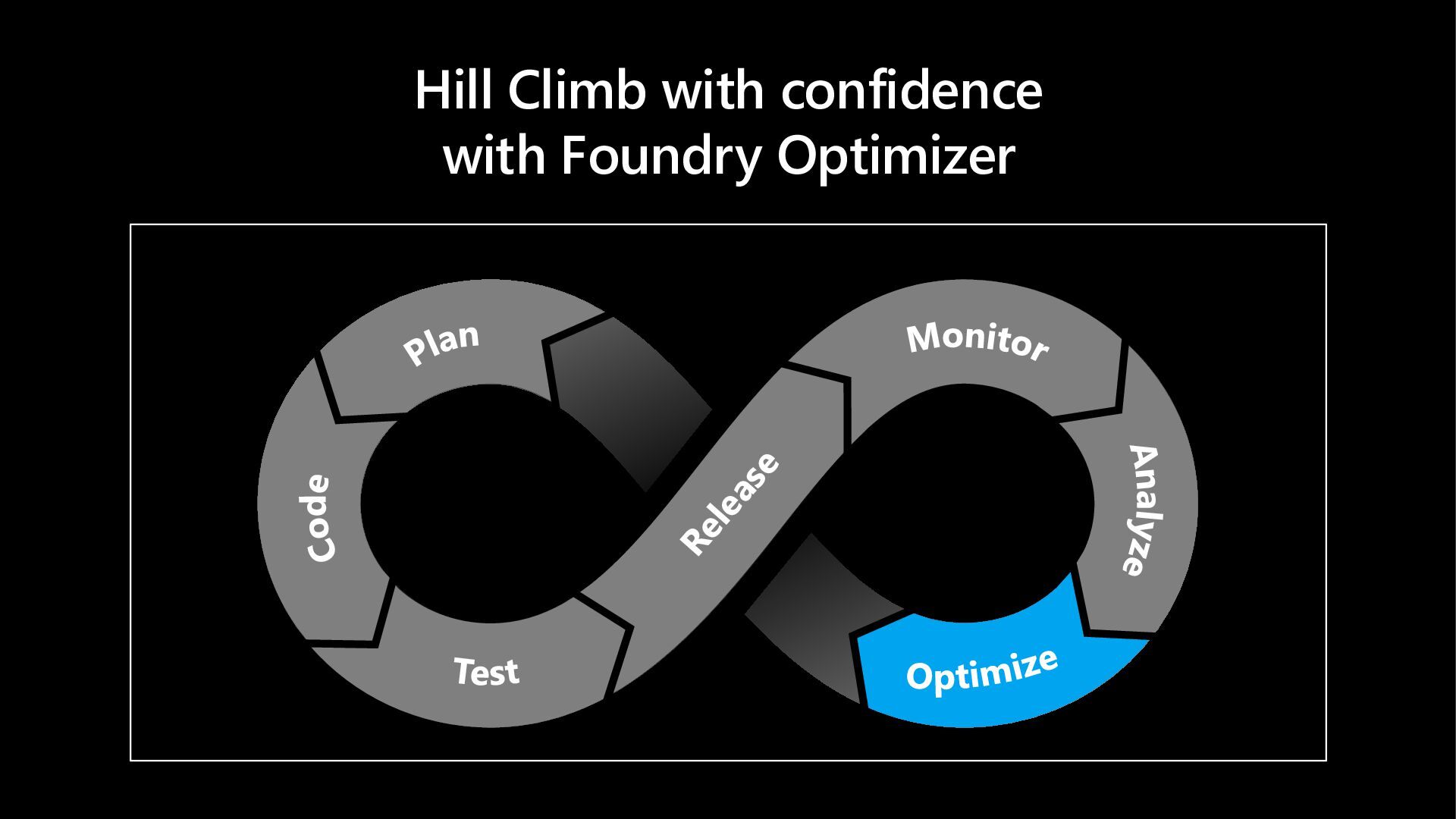
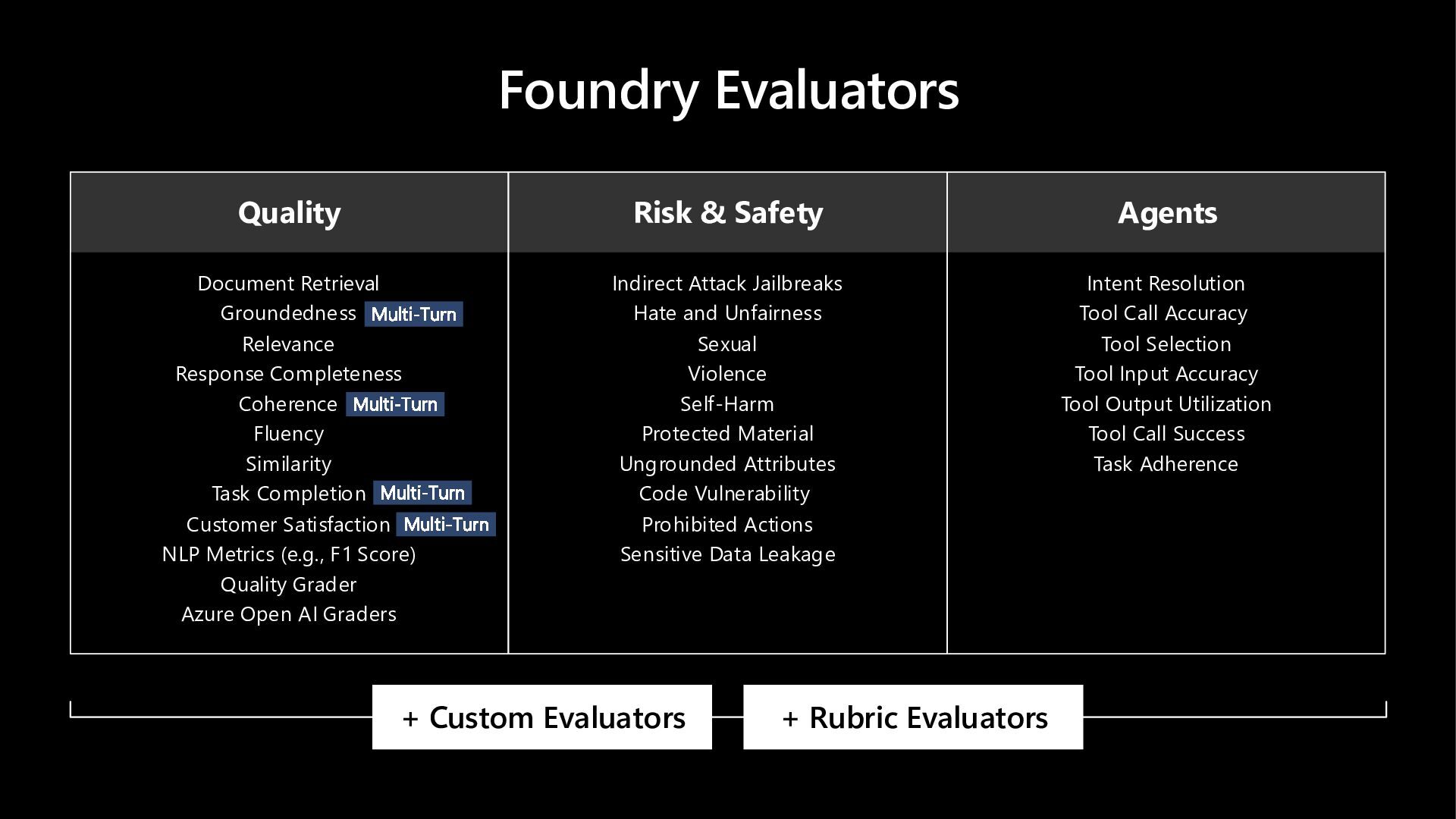
In this hands-on lab, learn more about how Microsoft Foundry Observability helps you move from prototype to production - with context-specific evaluation suites (auto-generated evaluators + test datasets) wired into developer workflows via skills and MCP tooling for hosted agents. Scale quality with continuous evaluations, trace-linked analysis and adaptive red teaming - and walk away with a sandbox you can use to explore additional features at your own pace.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}