Slides for the second part of the Data Science London Meetup on scikit-learn on Mar. 7 2013
View rendered demo notebook: http://nbviewer.ipython.org/5115540/Model%20Selection%20for%20the%20Nystroem%20Method.ipynb
The source code for the demo is here:
https://gist.github.com/ogrisel/5115540
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
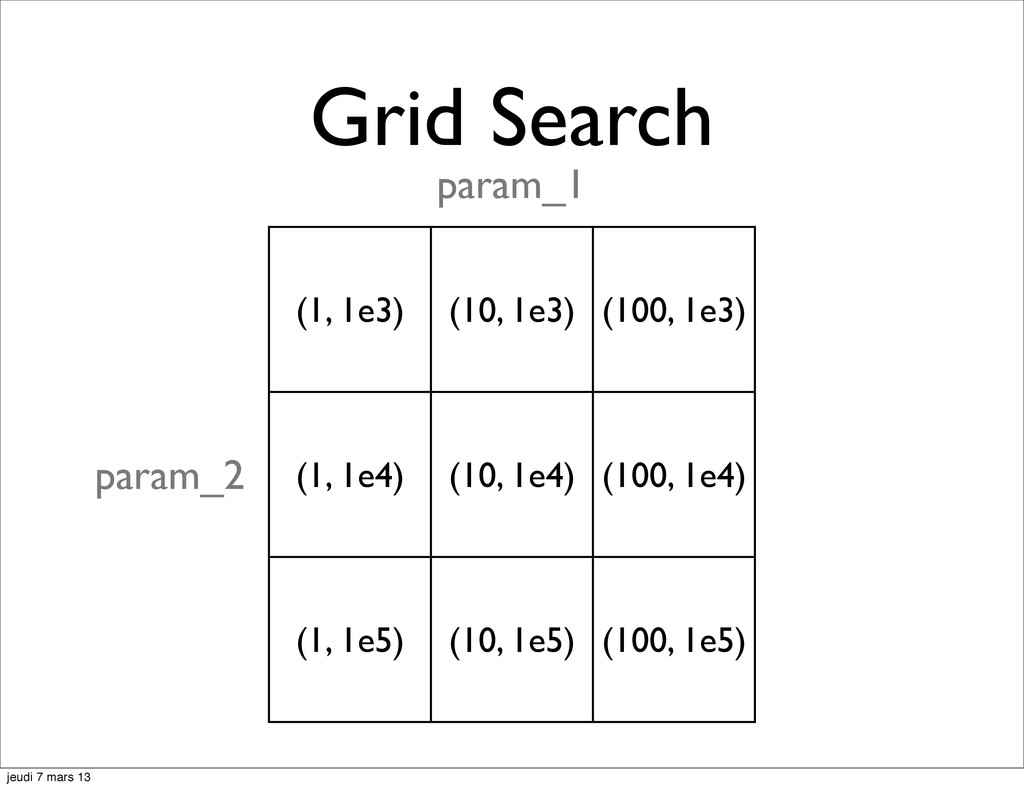
![Model Selection the Hyperparameters hell param_1 in [1, 10, 100]](https://files.speakerdeck.com/presentations/983b21f06a070130c77d22000a91bfda/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[global] DEFAULT_TEMPLATE=ip [key mykey] KEY_LOCATION=~/.ssh/mykey.rsa [plugin ipcluster] SETUP_CLASS = starcluster.plugins.ipcluster.IPCluster](https://files.speakerdeck.com/presentations/983b21f06a070130c77d22000a91bfda/slide_62.jpg){kind=link}
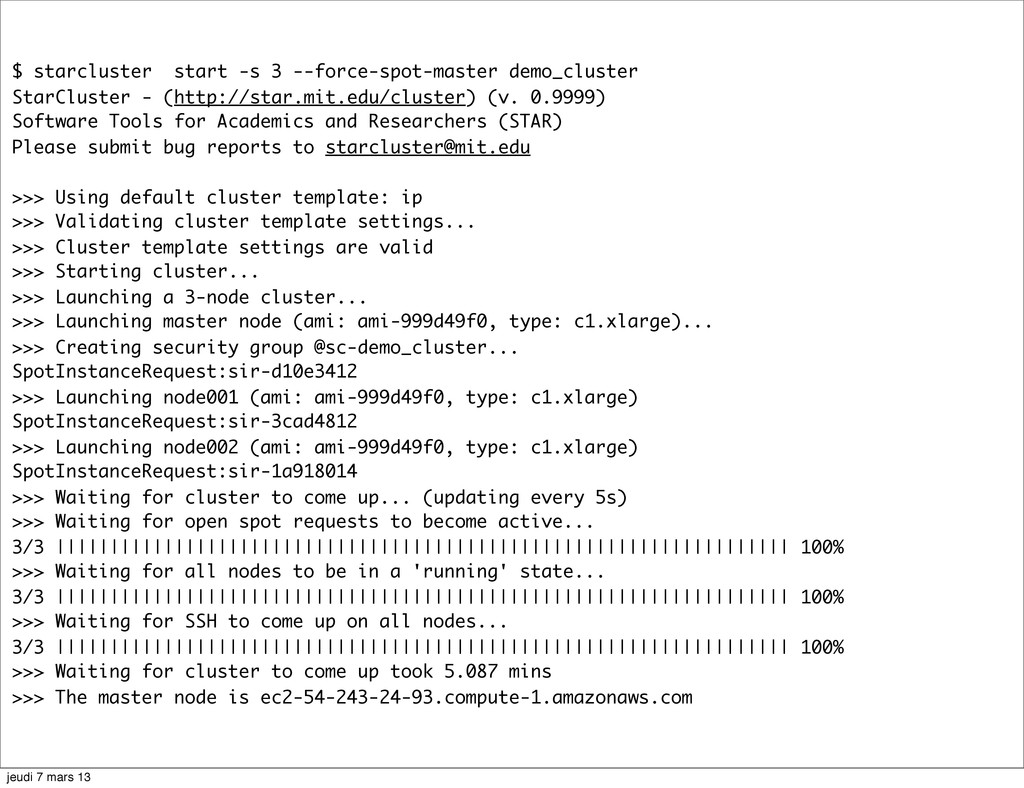{kind=link}
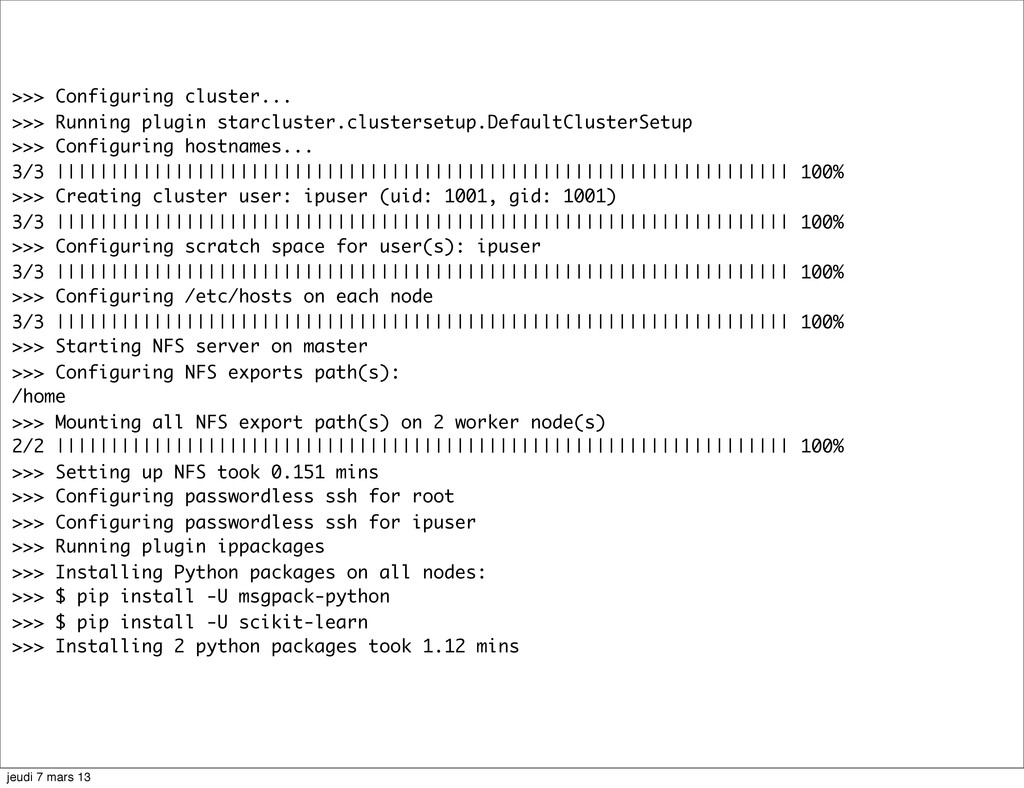{kind=link}
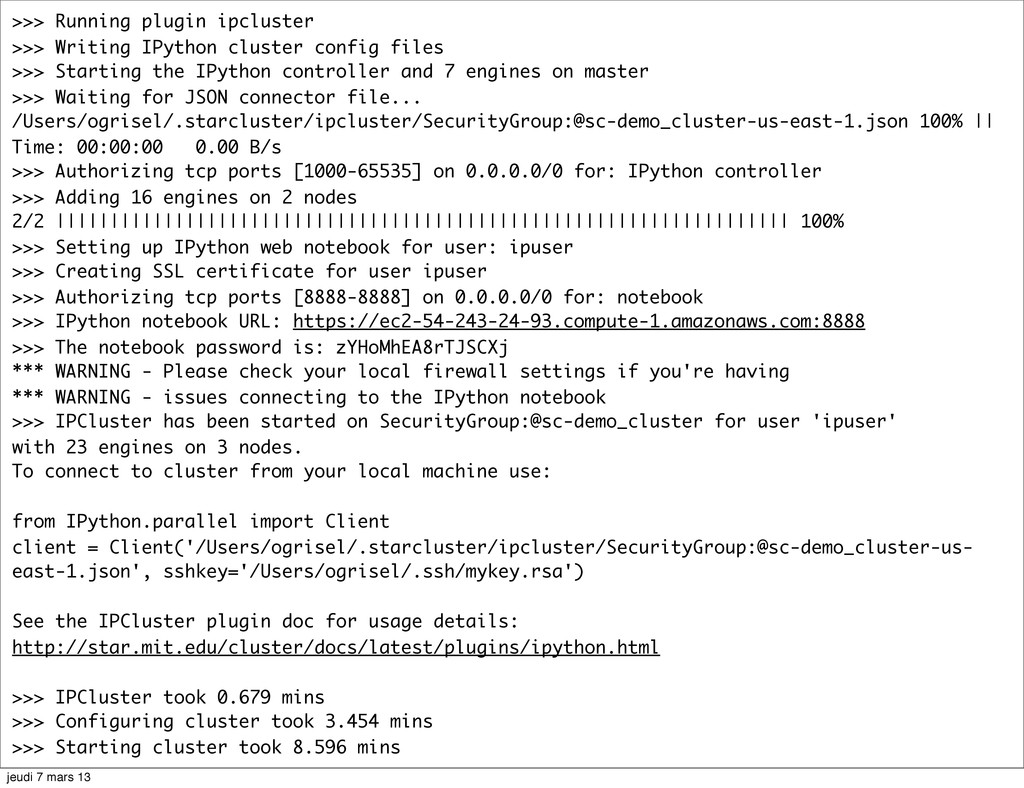{kind=link}
{kind=link}
{kind=link}
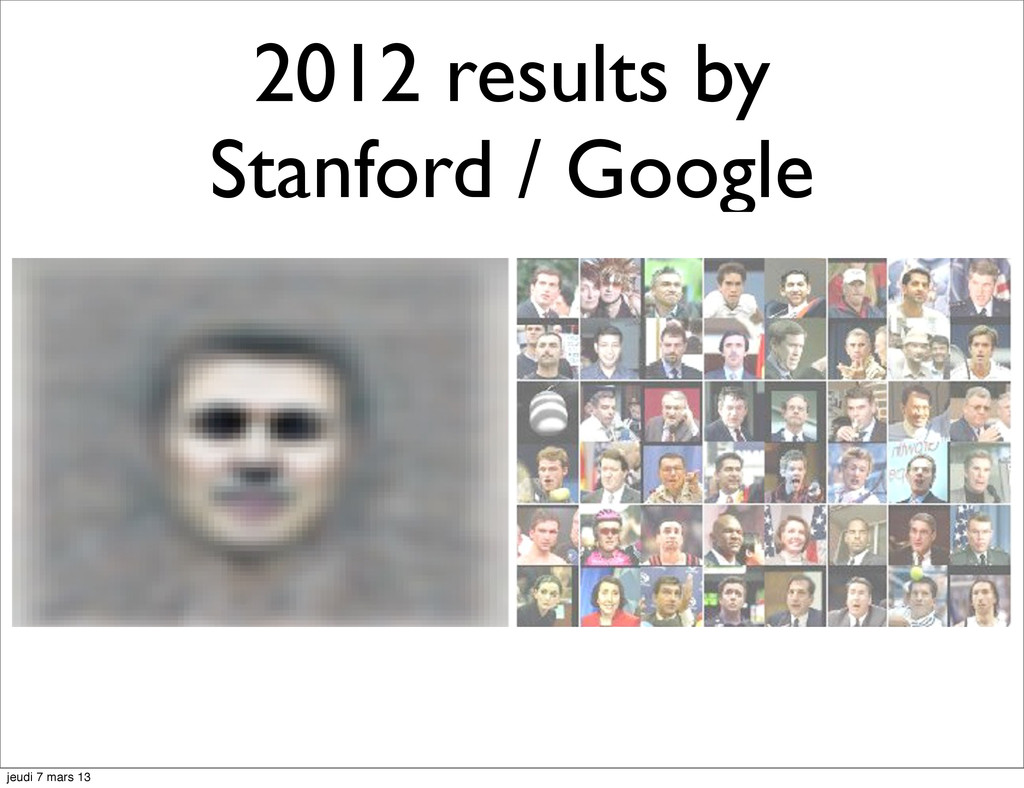{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MapReduce? [ (k1, v1), (k2, v2), ... ] mapper mapper](https://files.speakerdeck.com/presentations/983b21f06a070130c77d22000a91bfda/slide_72.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
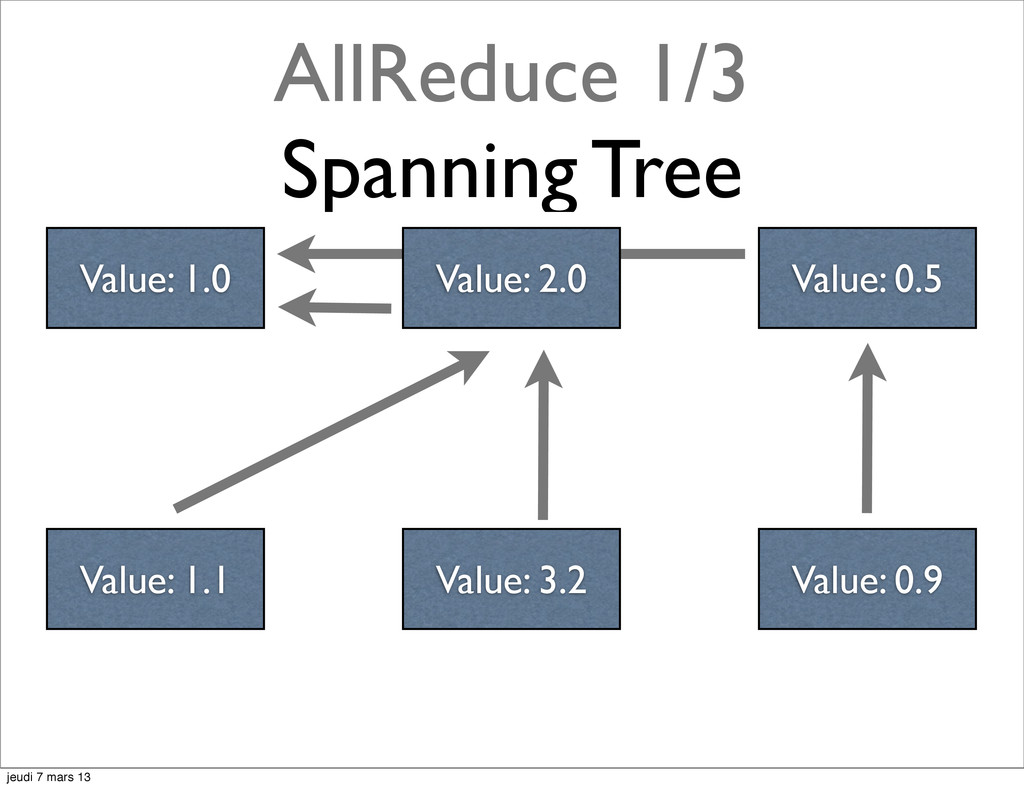{kind=link}
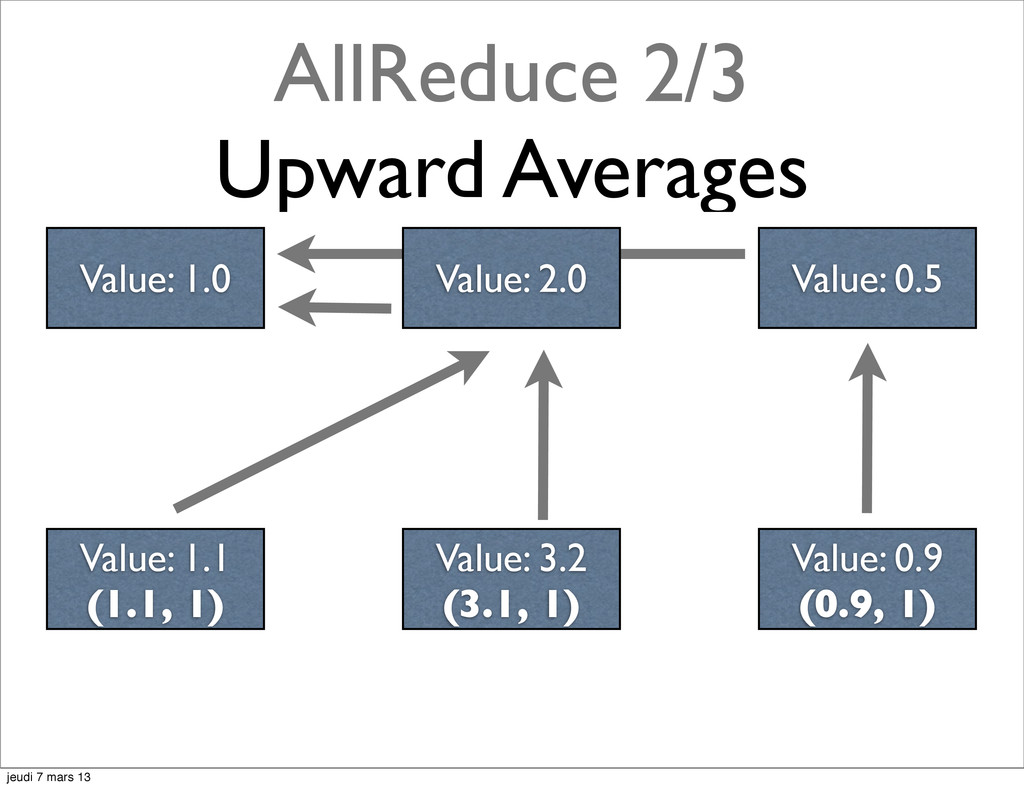{kind=link}
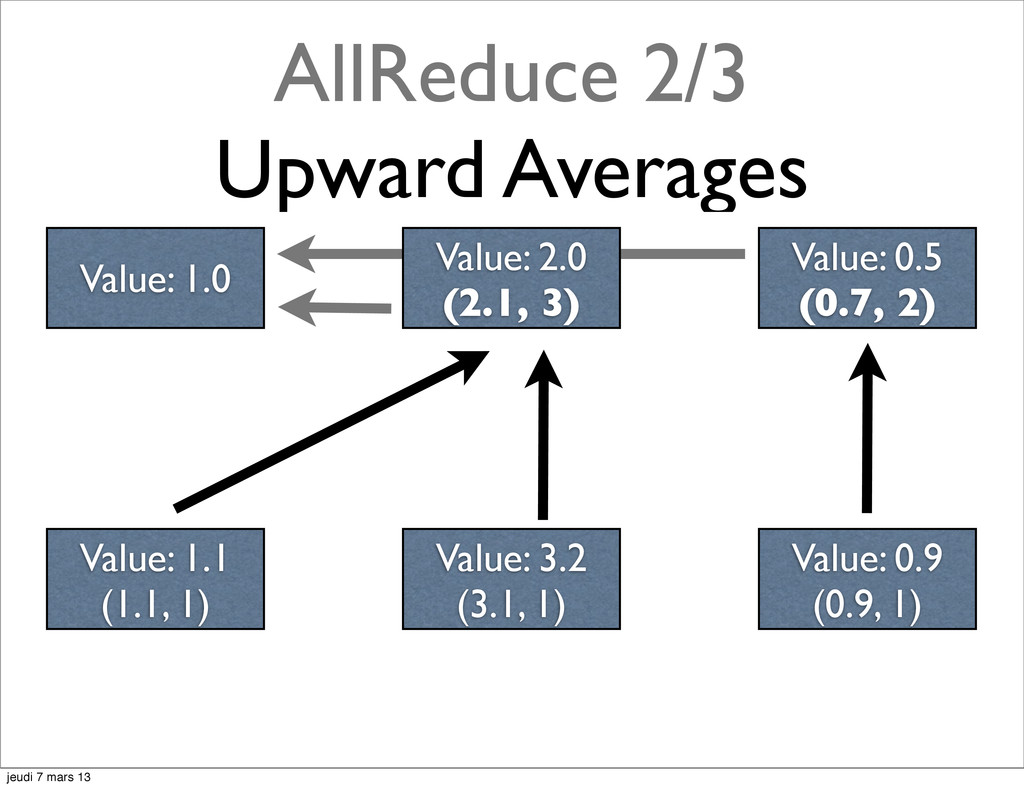{kind=link}
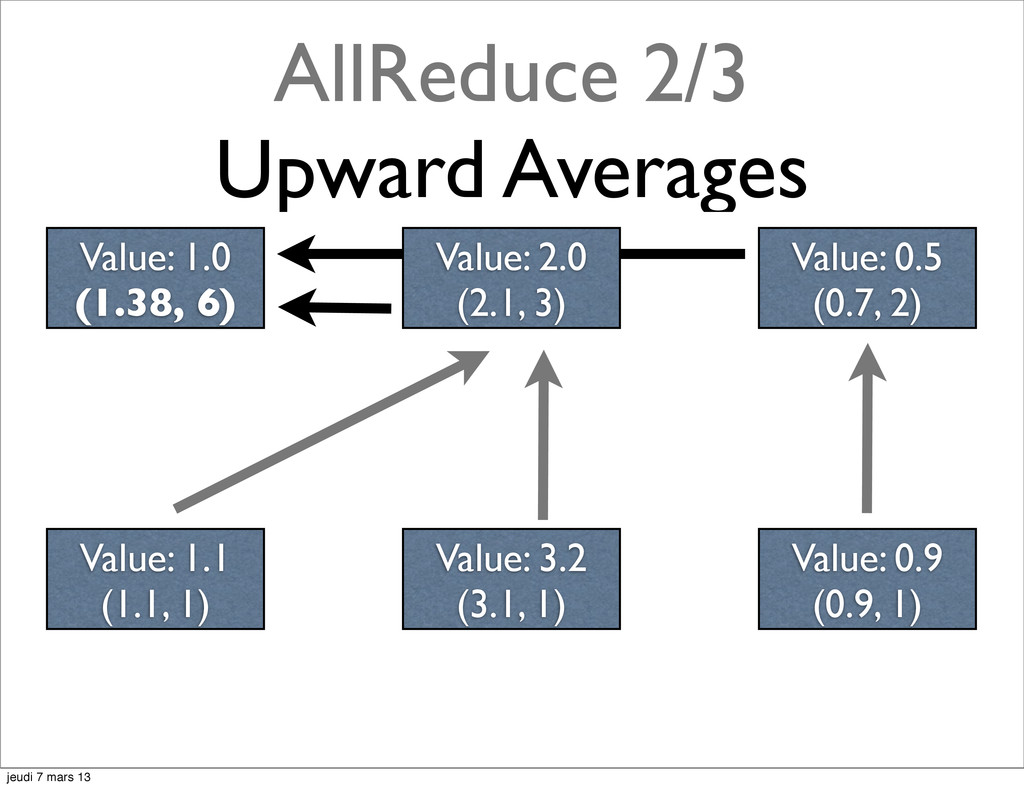{kind=link}
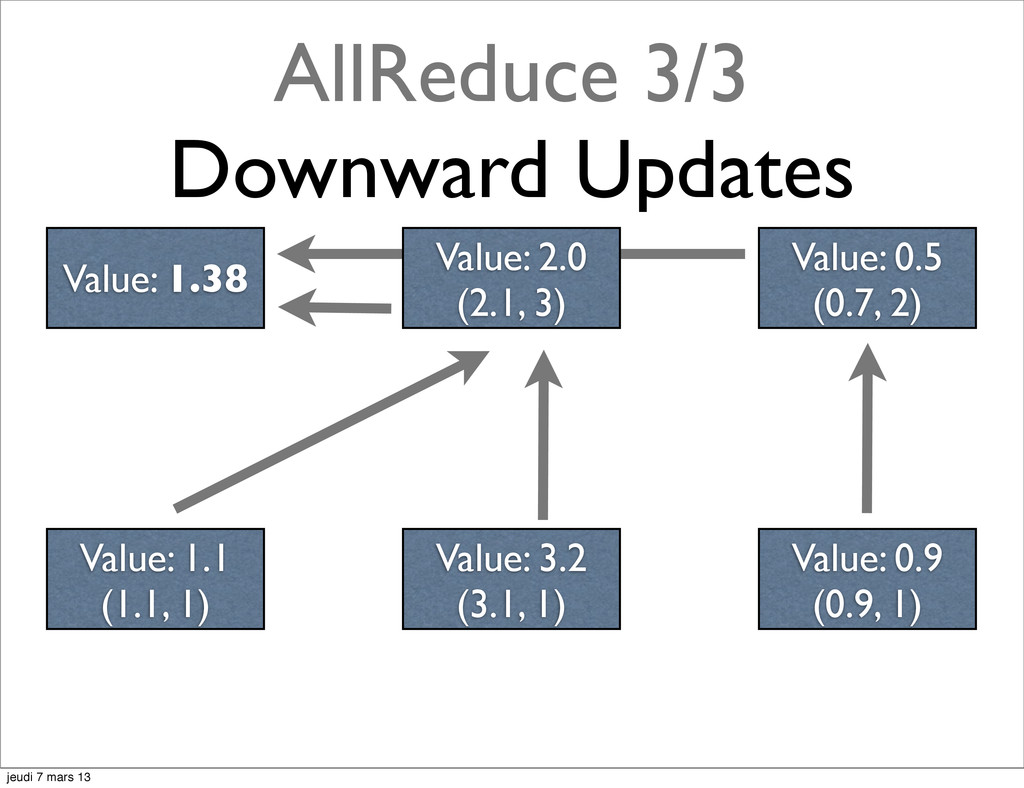{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Killall IPython engines on StarCluster [plugin ipcluster] SETUP_CLASS = starcluster.plugins.ipcluster.IPCluster](https://files.speakerdeck.com/presentations/983b21f06a070130c77d22000a91bfda/slide_86.jpg){kind=link}
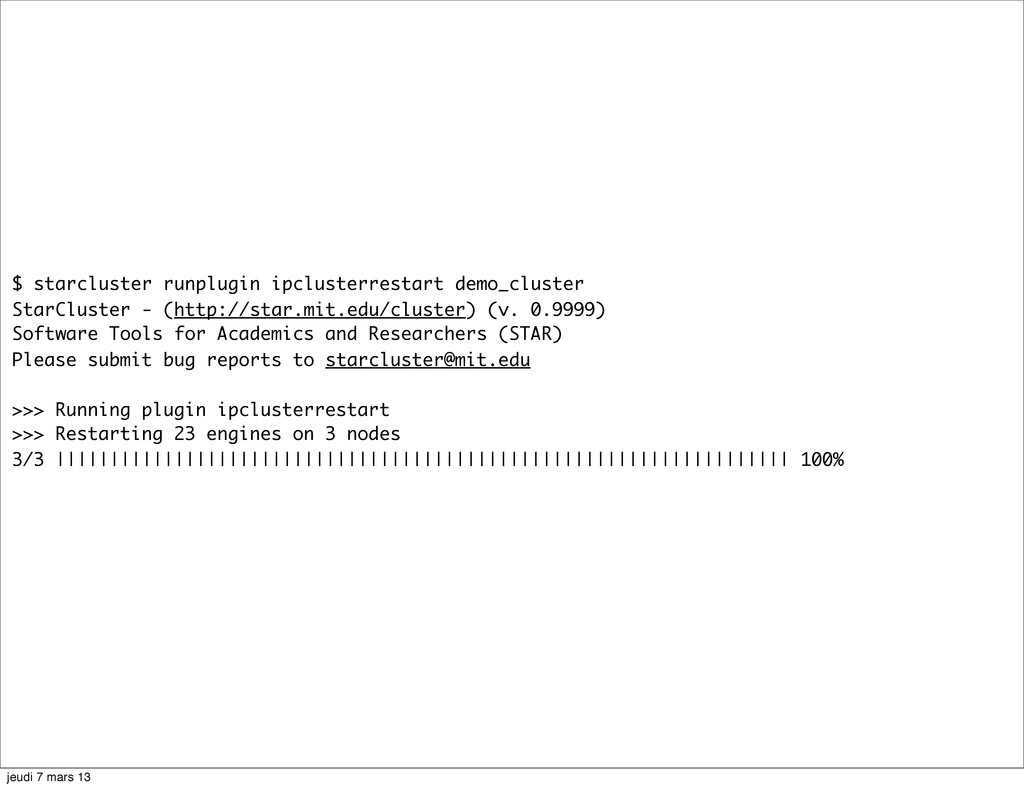{kind=link}