models Big Data (Google scale - MapReduce) Counting stuff in logs / Indexing the Web Machine Learning? often somewhere in the middle Sunday, September 16, 2012
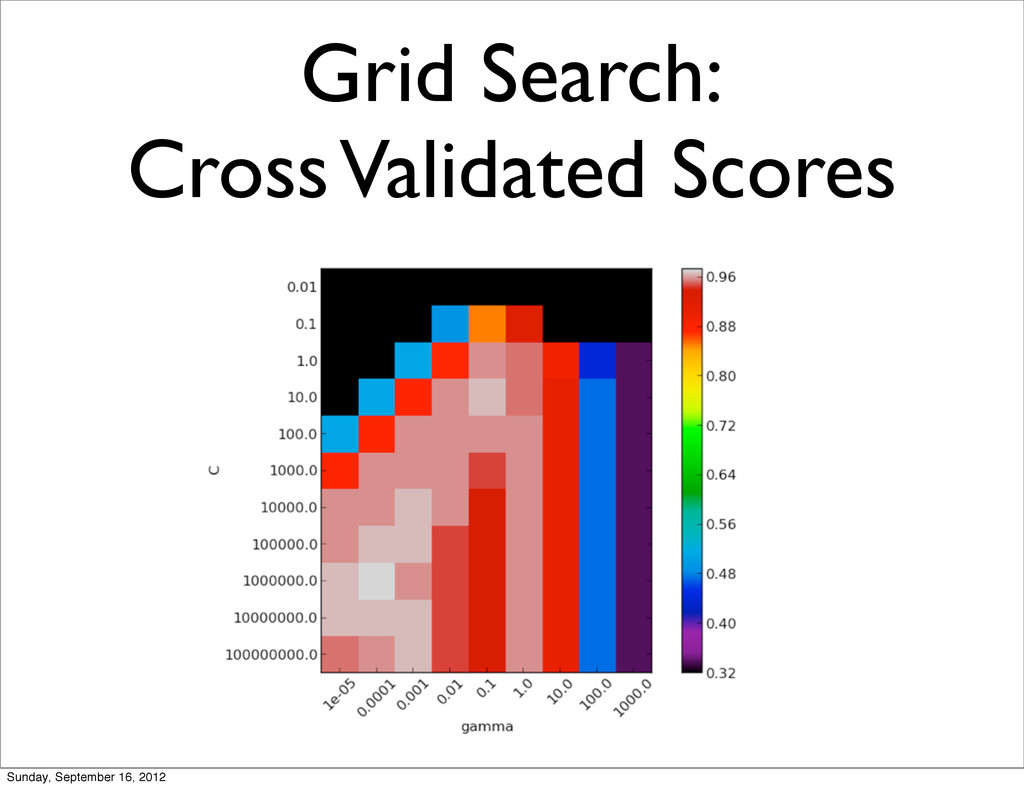
(100, 1e4) (1, 1e5) (10, 1e5) (100, 1e5) Only 3 allocated datasets shared by all the concurrent workers performing the grid search. Sunday, September 16, 2012
stuff to disk for failover Inefficient for small to medium problems [(k, v)] mapper [(k, v)] reducer [(k, v)] Data and model params as (k, v) pairs? Complex to leverage for Iterative Algorithms Sunday, September 16, 2012
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Model Selection the Hyperparameters hell p1 in [1, 10, 100]](https://files.speakerdeck.com/presentations/50548cb8bf73df0002051928/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MapReduce? [ (k1, v1), (k2, v2), ... ] mapper mapper](https://files.speakerdeck.com/presentations/50548cb8bf73df0002051928/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
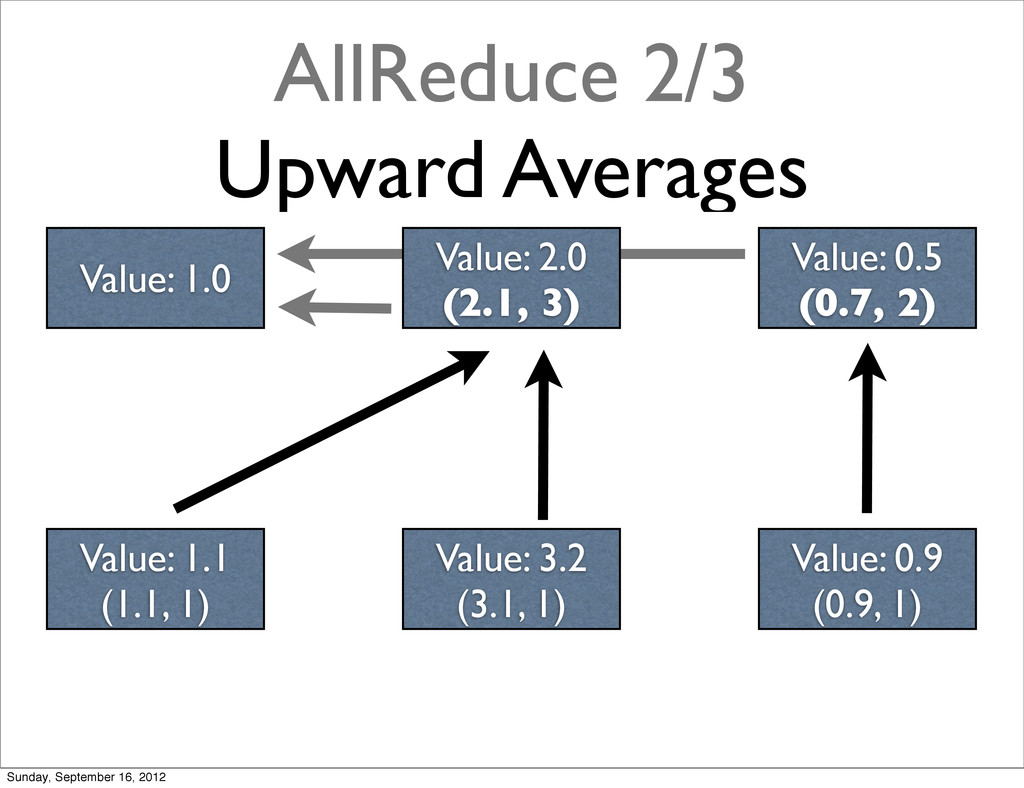{kind=link}
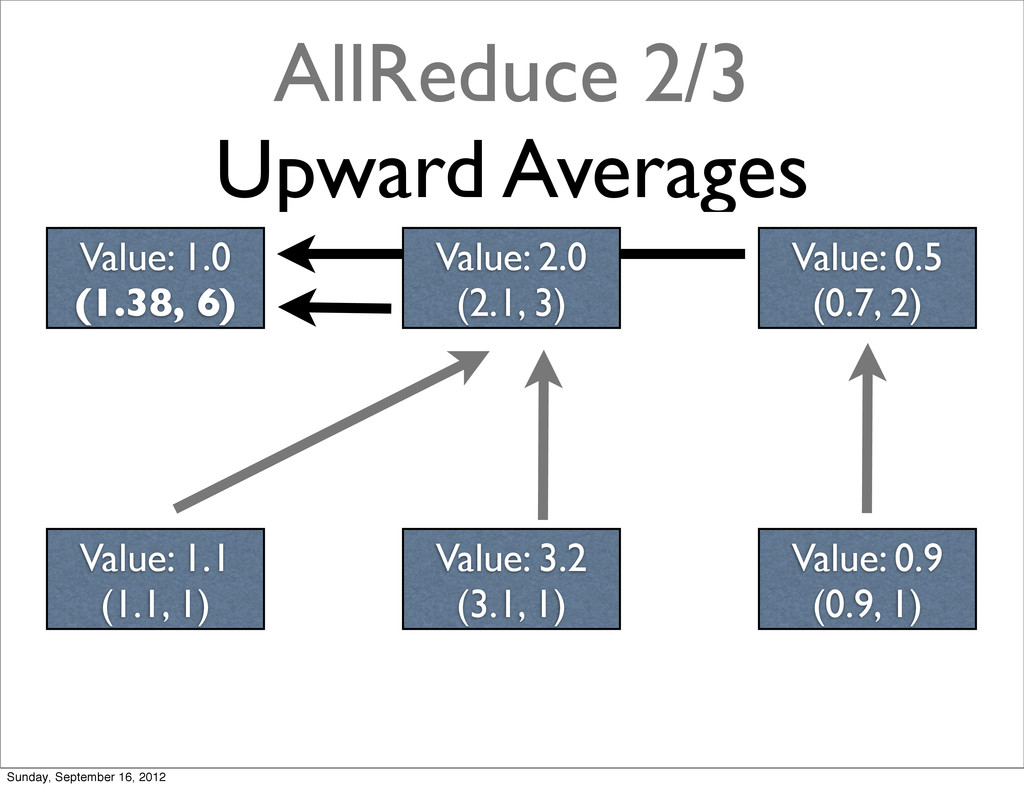{kind=link}
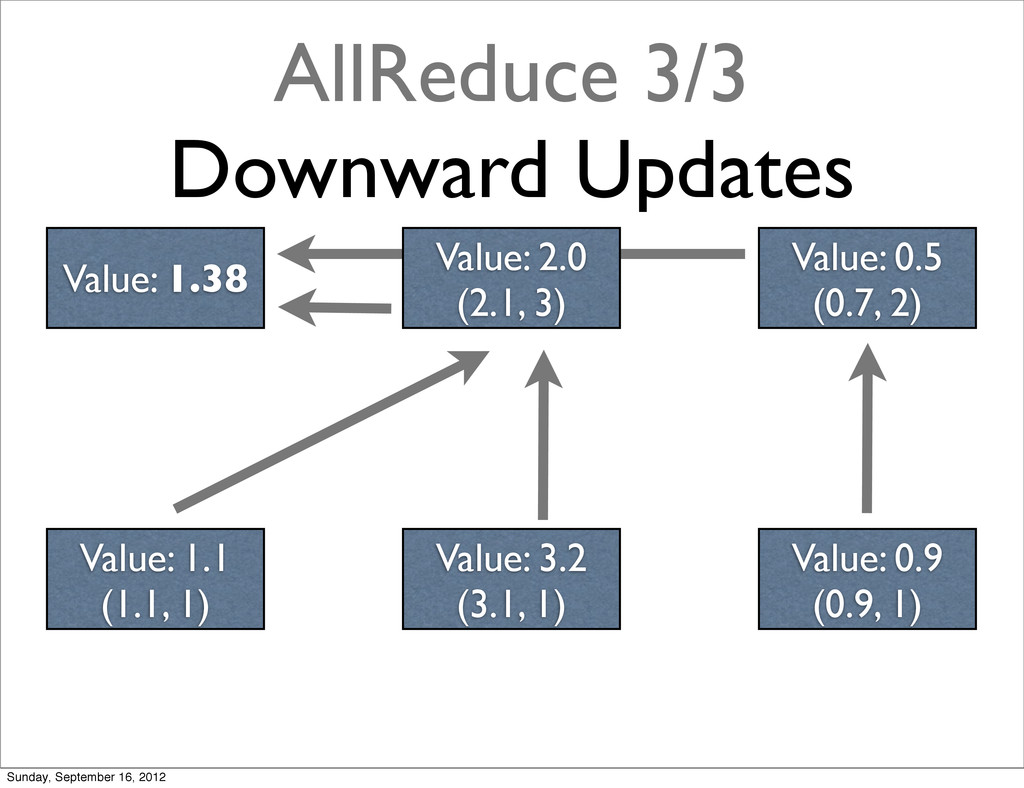{kind=link}
{kind=link}
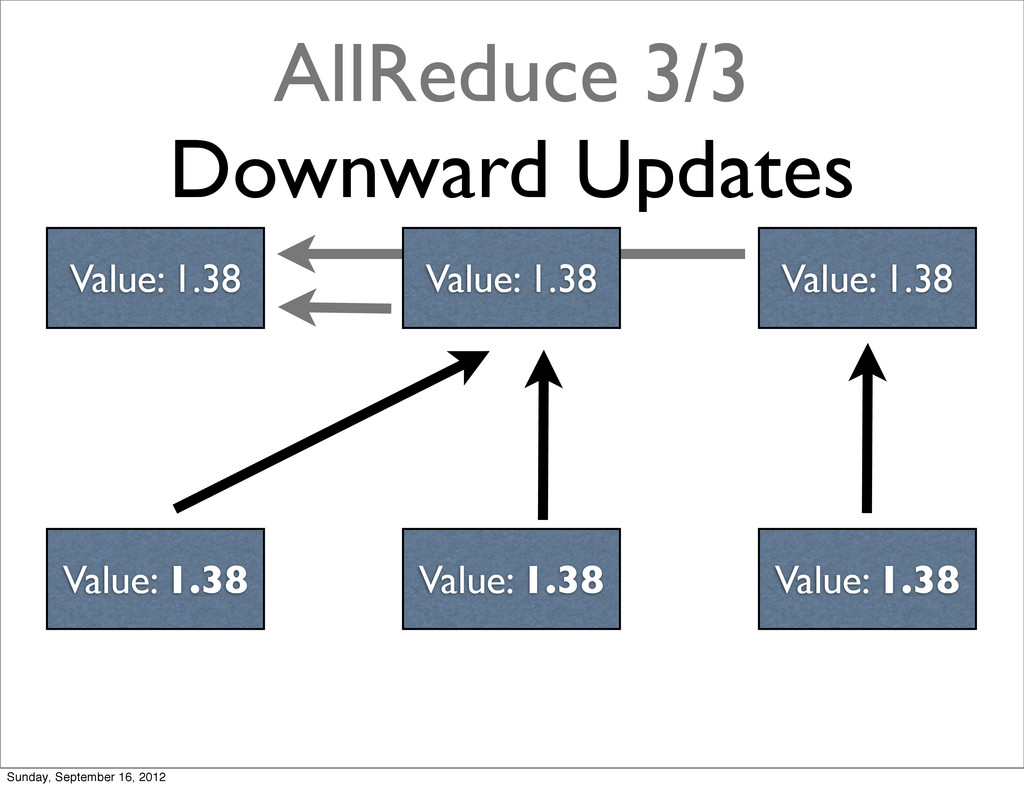{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
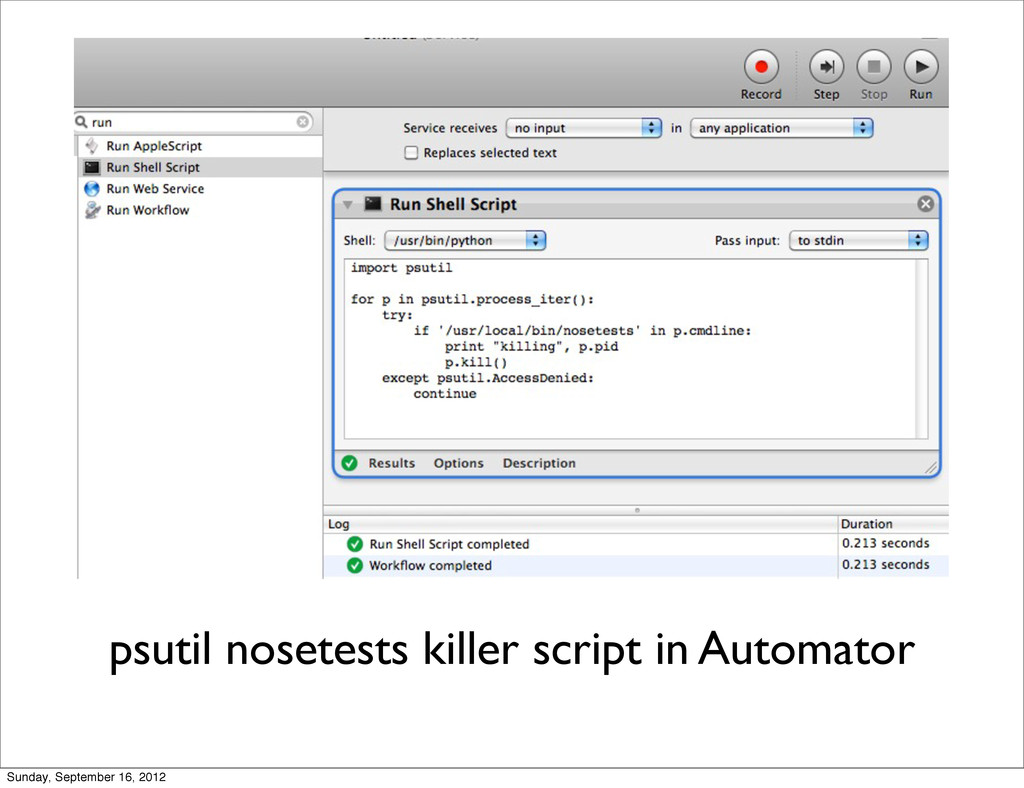{kind=link}
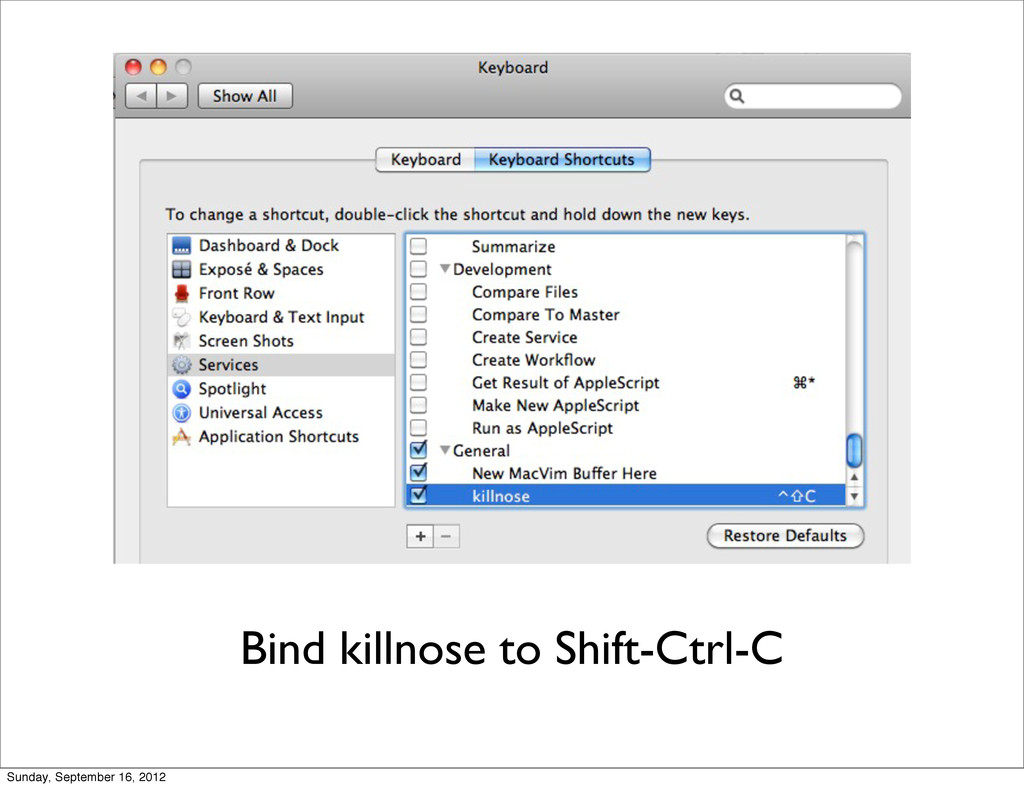{kind=link}
{kind=link}