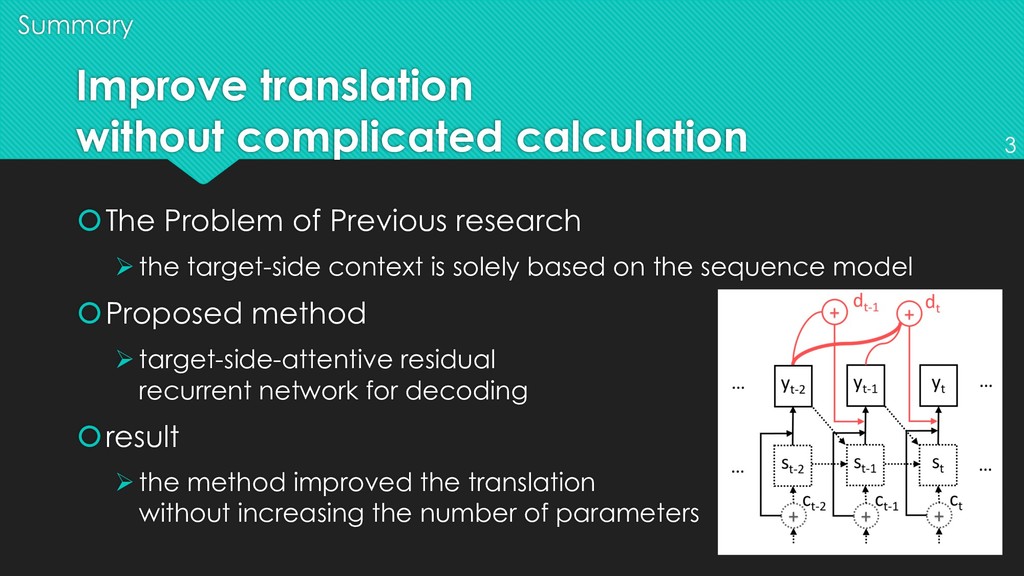
based on the sequence model Proposed method Øtarget-side-attentive residual recurrent network for decoding result Øthe method improved the translation without increasing the number of parameters Summary Improve translation without complicated calculation 3
!" # = softmax ," # ," # = -. tanh 1 2 3" + 1 5 6# or ," # = -. tanh 1 2 3" the context does not necessarily lead to the best translation the content is effective to extract representations of the whole sentence Results Impact of the Attention Function 13
of Self-attentive RNN vary for each word Self-attentive residual connections model focuses on particular words Qualitative Analysis Distribution of Attention 15
and teachers are taking the date lightly. B: Students and teachers are being taken lightly to the date. O: Students and teachers are taking the date lightly. R: Not because he shared their world view, but because for him, human rights are indivisible. B: Not because I share his ideology, but because he is indivisible by human rights. O: Not because he shared his ideology, but because for him human rights are indivisible. Worse than baseline R: The Government is trying not to build so many small houses. B: The government is trying not to build so many small houses. O: The government is trying to ensure that so many small houses are not built. R: Other people can have children. B: Other people can have children. O: Others may have children.
model, but not the 4-gram LSTM This shows that even if a model improves language modeling, it does not necessarily improve machine translation Appendix Performance on Language Modeling 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}