Mohammadamin Barekatain, Ryo Yonetani, Masashi Hamaya, "MULTIPOLAR: Multi-Source Policy Aggregation for Transfer Reinforcement Learning between Diverse Environmental Dynamics", IJCAI'20
paper: https://www.ijcai.org/Proceedings/2020/430
blog: https://medium.com/sinicx/multipolar-multi-source-policy-aggregation-for-transfer-reinforcement-learning-between-diverse-bc42a152b0f5
code: https://github.com/Mohammadamin-Barekatain/multipolar
{kind=link}
{kind=link}
{kind=link}
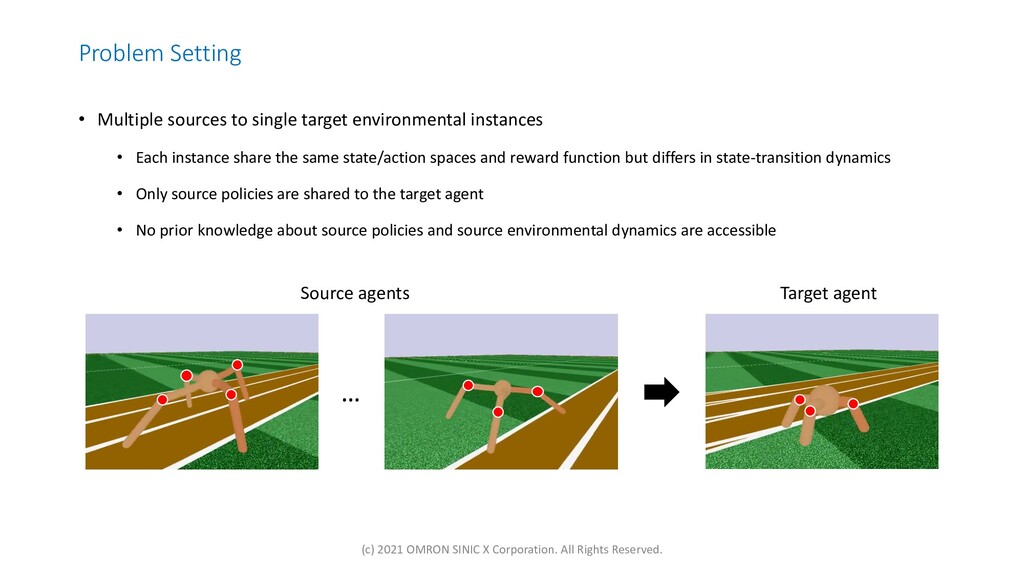{kind=link}
{kind=link}
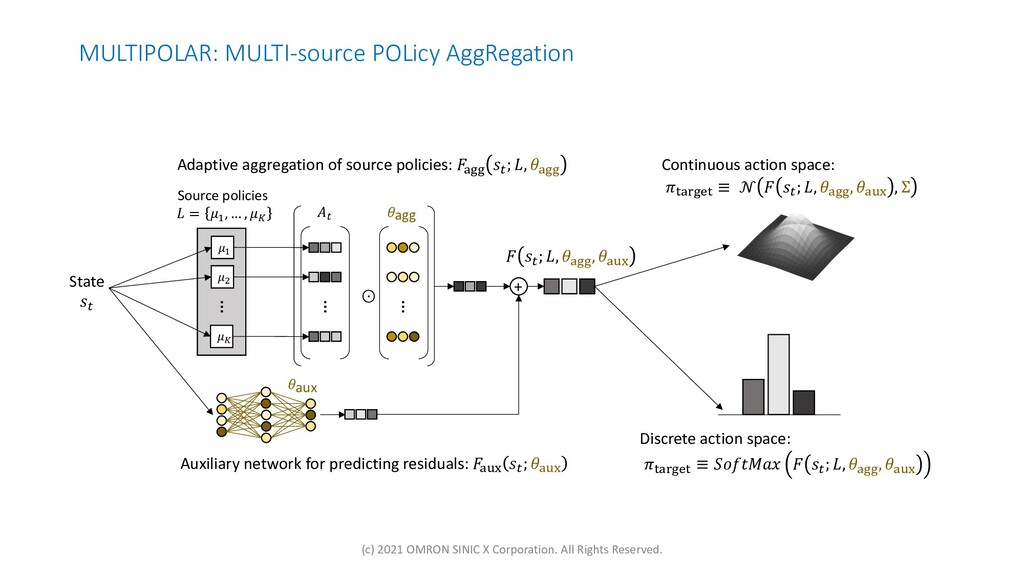{kind=link}
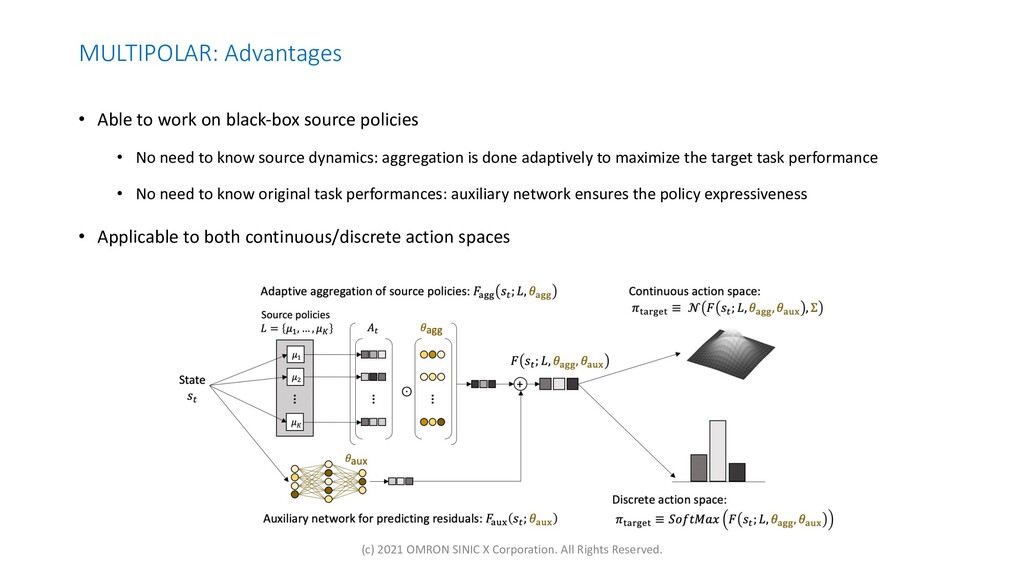{kind=link}
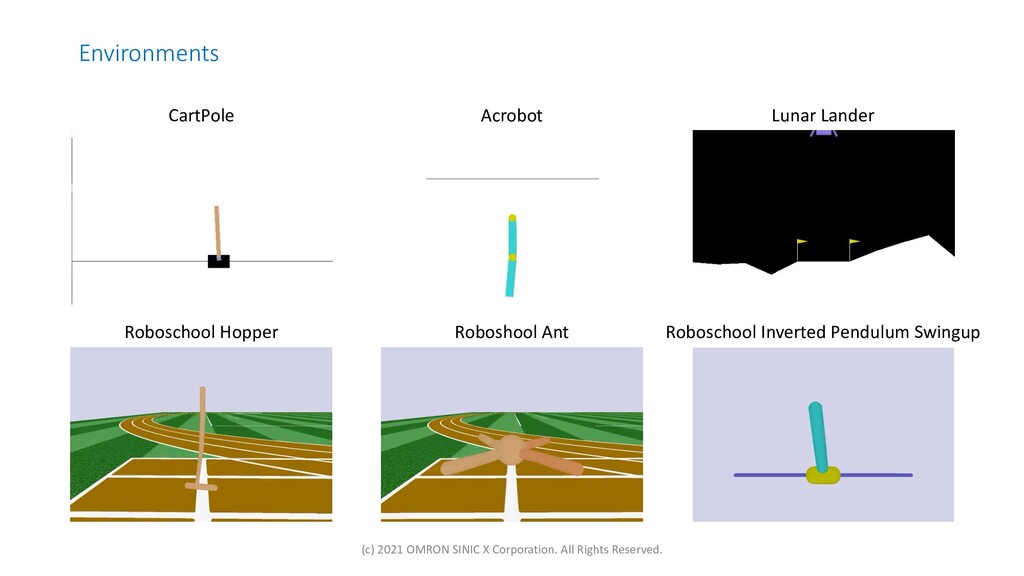{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}