Casa de Maurício (de Nassau), na cidade de Haia, na Holanda É A Lição de Anatomia do Dr. Nicolaes Tulp, (1632) . Pintura a óleo de Rembrandt, no Museu Mauritshuis (Casa de Maurício)
em madeira, 1596/7 Fui ao MASP, em São Paulo, ver a exposição de Caravaggio. A cabeça da Medusa, com as serpentes, é apavorante. Mas eu não petrifiquei!
pela Av. Paulista e procurem as Livrarias. Ouçam a OSESP na Sala São Paulo, apreciem a arquitetura da Catedral da Sé. Almocem no Mercado Municipal, ...
Nicolaes Tulp para abertura desta lição não é por acaso. É uma indicação artística de que, agora, passaremos a dissecar a representação IEEE 754/2008 em Python/NumPy.
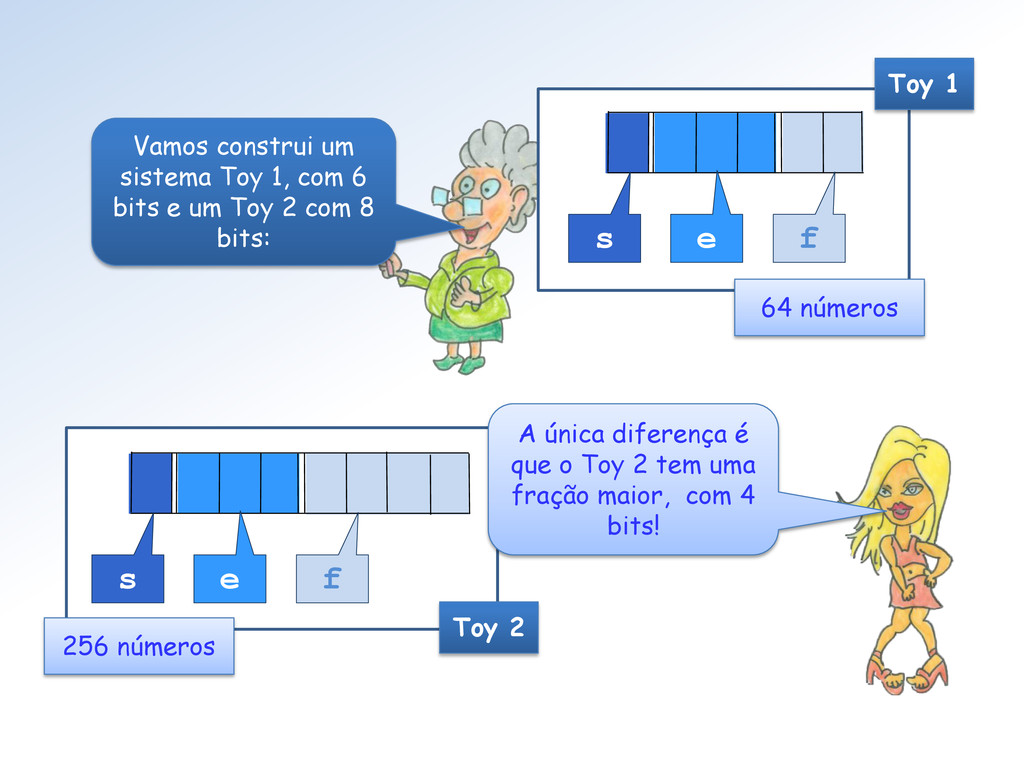
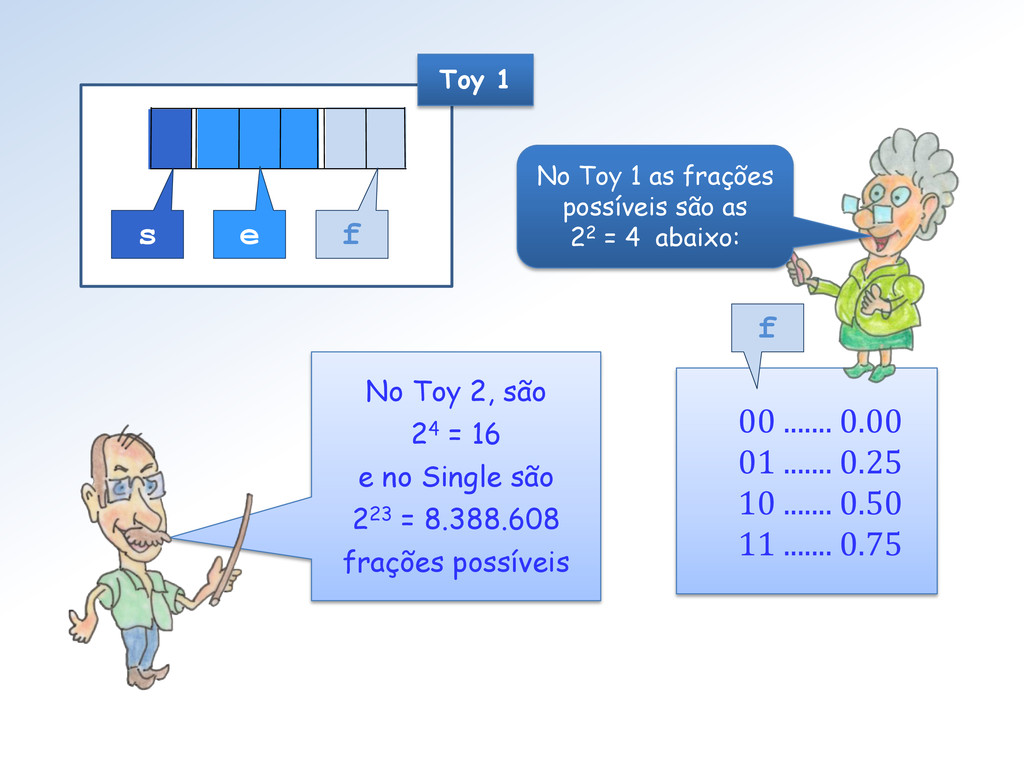
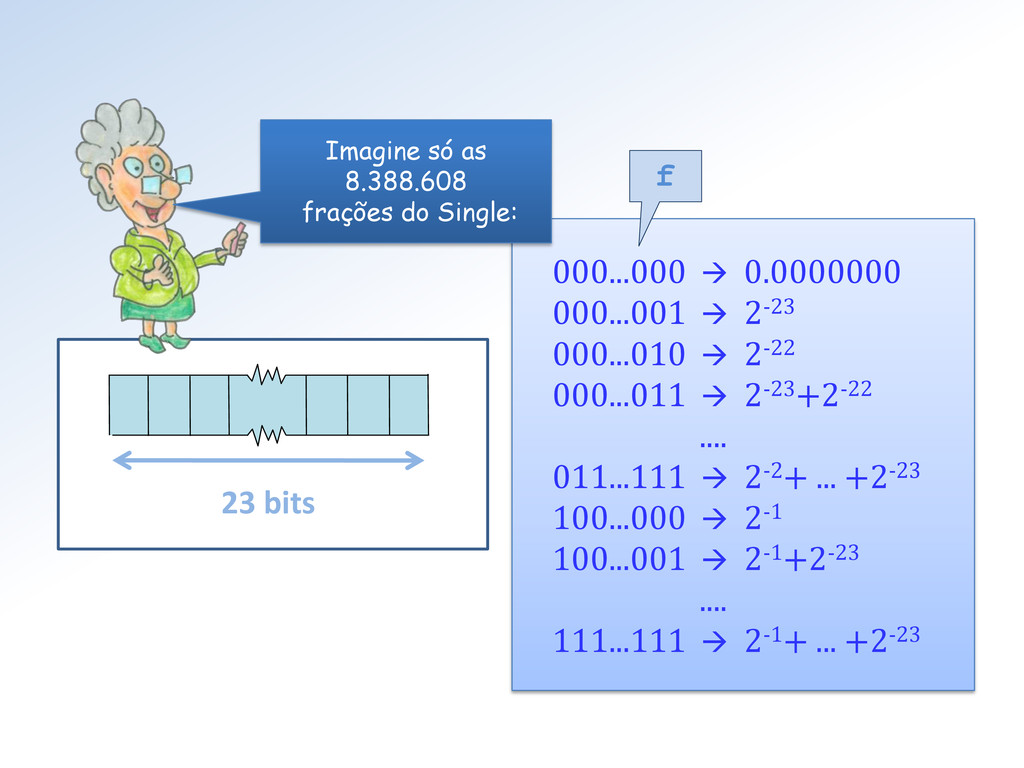
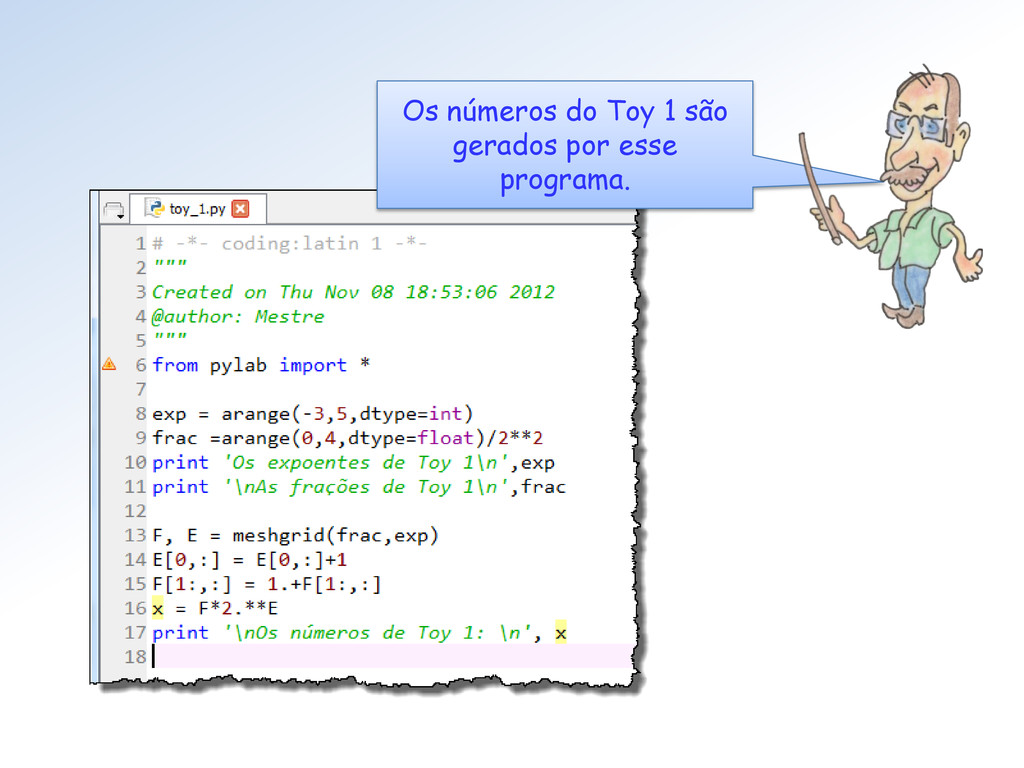
0.25 10 ....... 0.50 11 ....... 0.75 f No Toy 1 as frações possíveis são as 22 = 4 abaixo: No Toy 2, são 24 = 16 e no Single são 223 = 8.388.608 frações possíveis
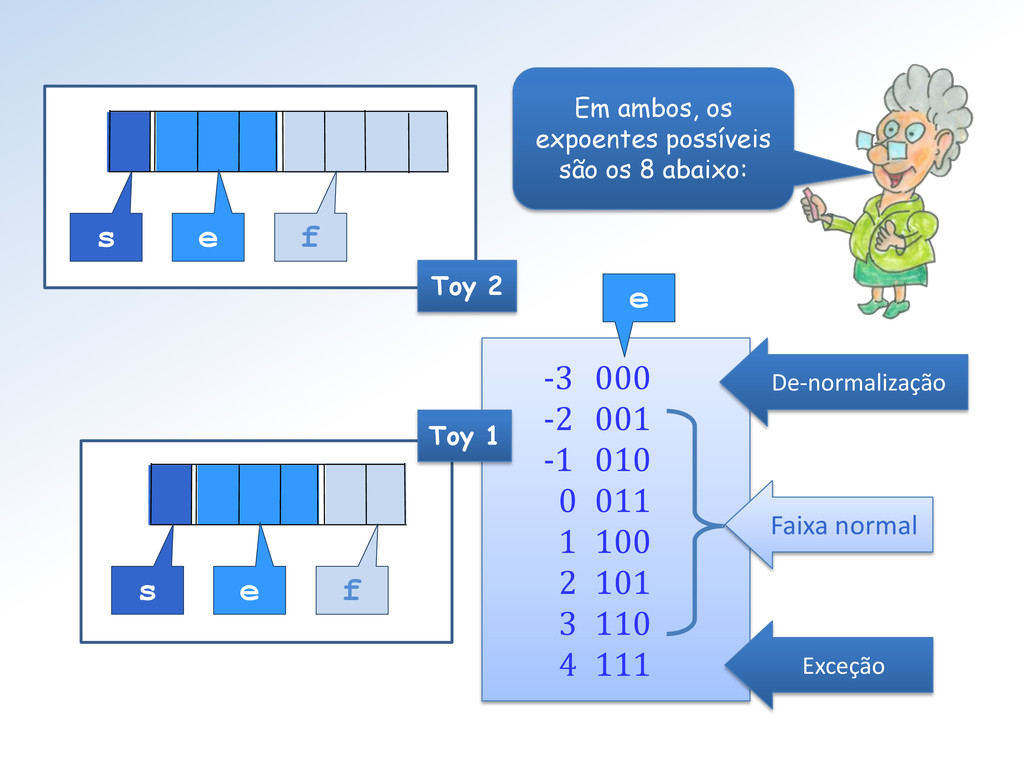
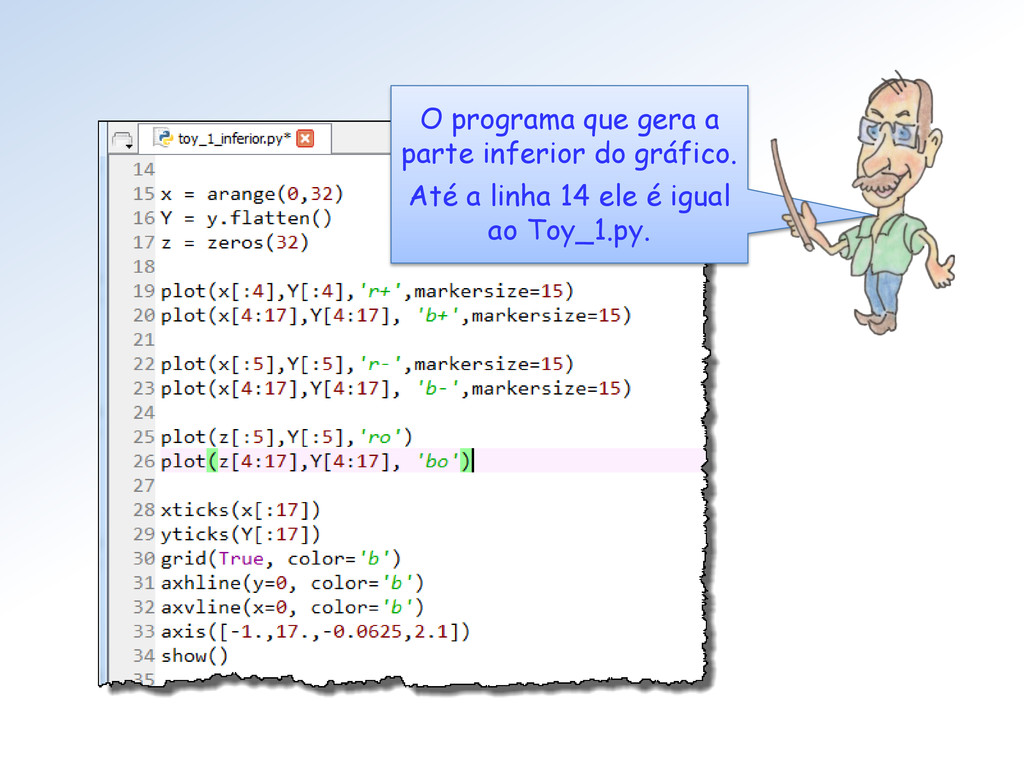
,4,5 ou 6 (-1)s ∗ 2e-2 ∗ (0.f) .... se e = 0 e f ≠ 0 (-1)s ∗ 0 .................... se e = 0 e f = 0 (-1)s ∗ Inf ................ se e = 7 e f = 0 NaN ......................... se e = 7 e f ≠ 0 x = Nos dois padrões Toy a regra de decodificação é quase a mesma. Isto pq. a condicional sobre o expoente é a mesma (eles são iguais!). A diferença reside só nas frações.
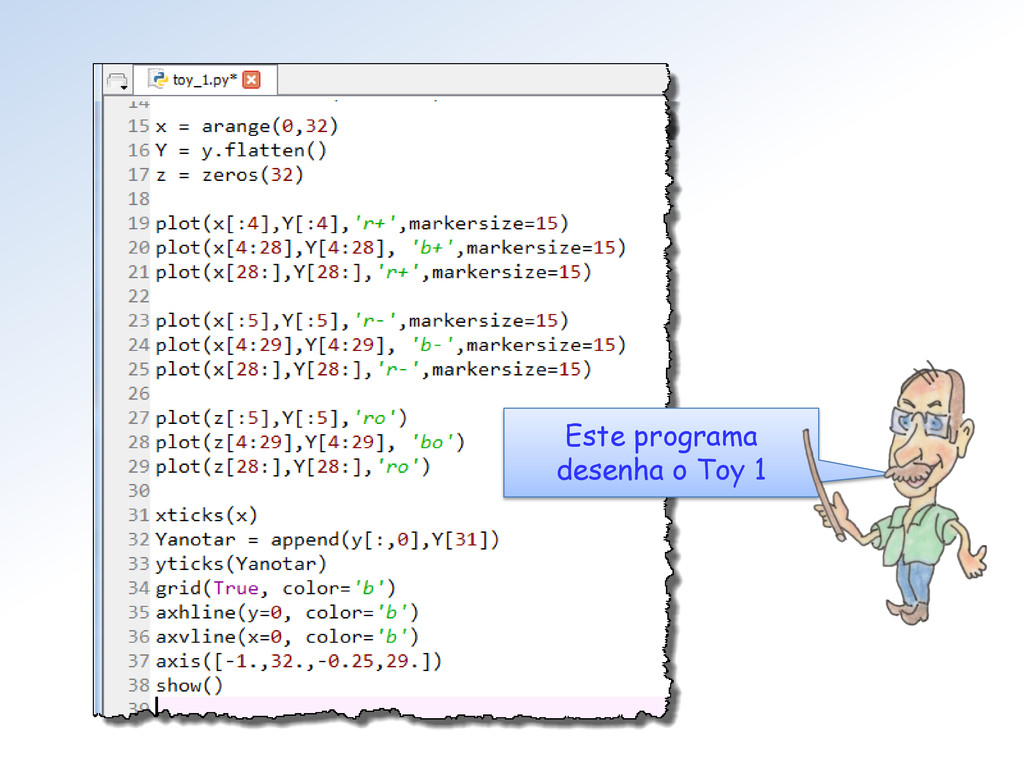
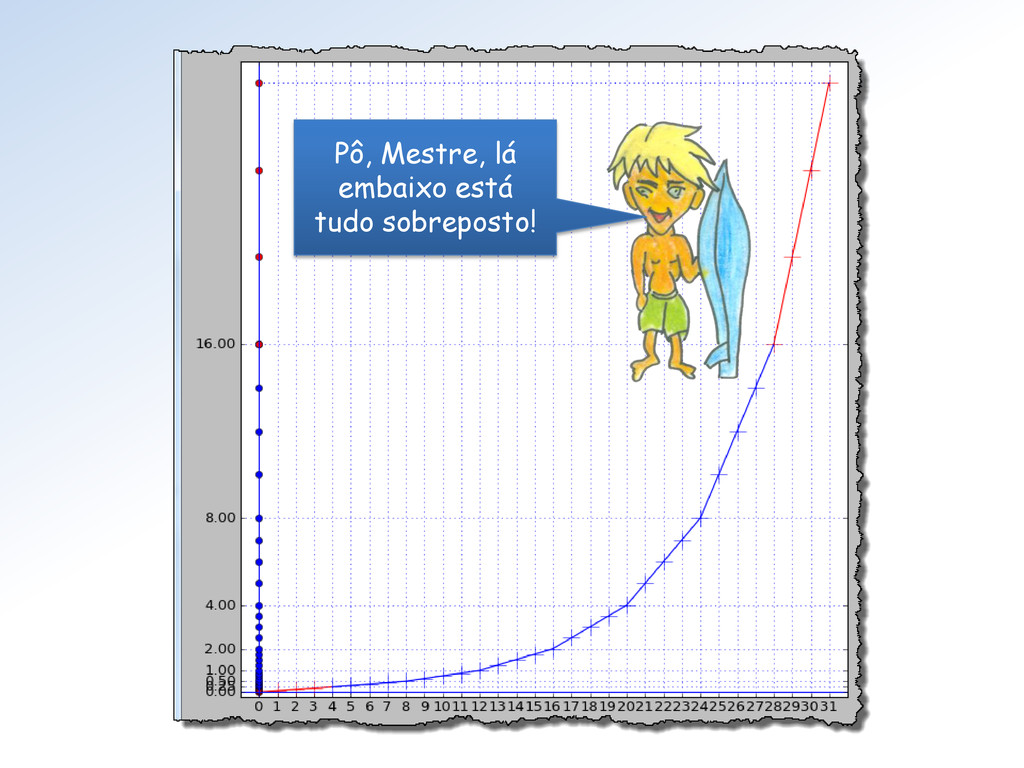
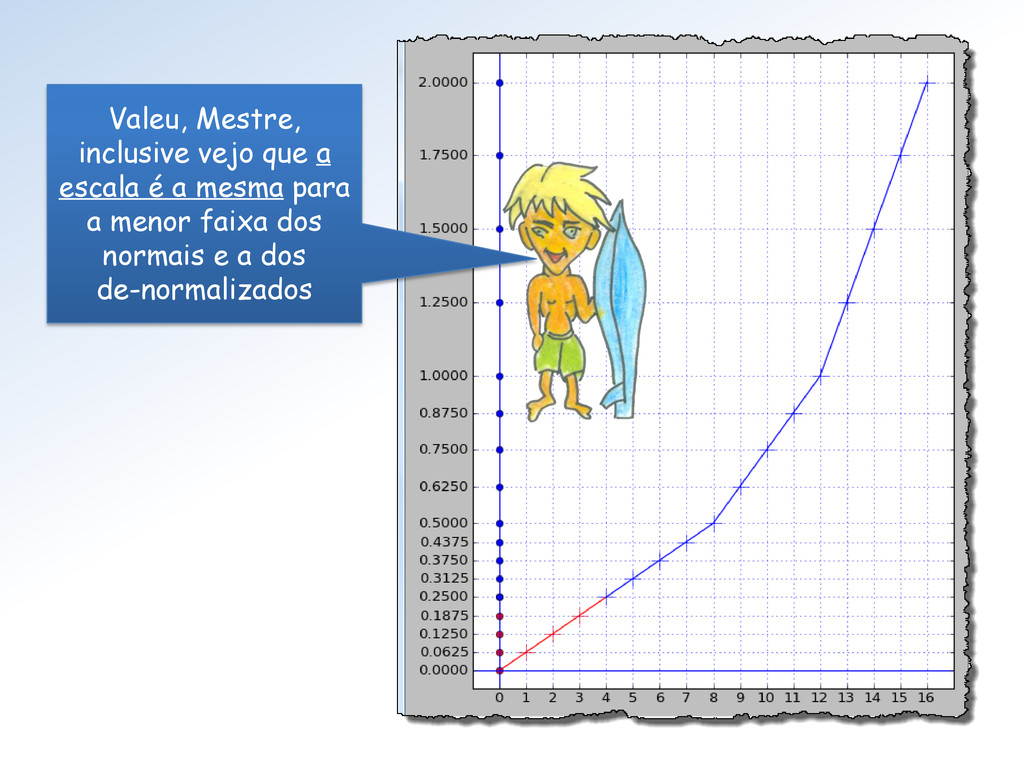
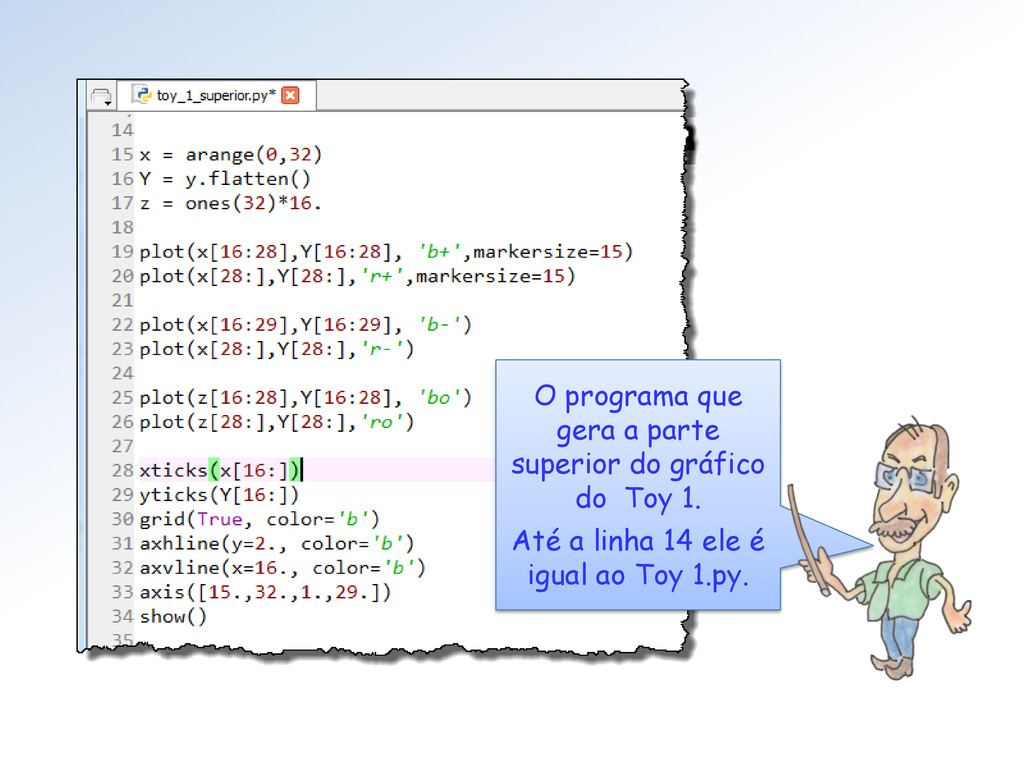
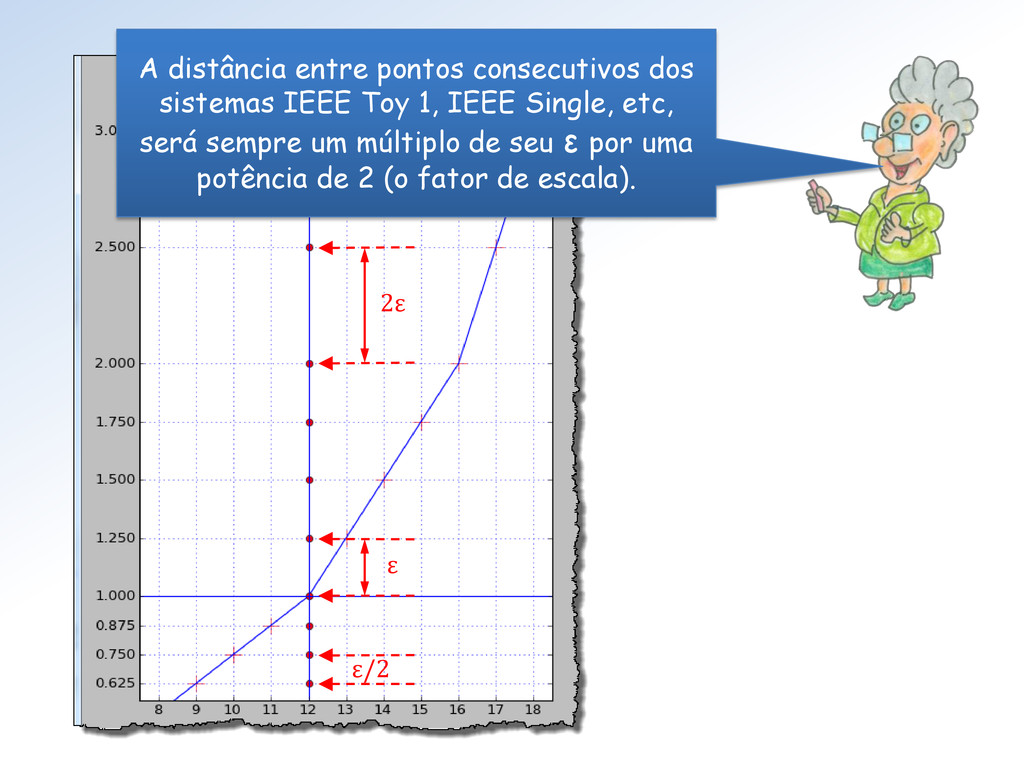
2. para baixo e outro de y = 2. para cima. Tem razão Surfista, é porque para cada grupo de 4 números de Toy 1 o fator de escala muda(*) numa potência de 2: 2-2, 2-2, 2-1, 20, 21, 23 e 24. (*) Exceto transição dos de-normalizados para a 1ª faixa normal.
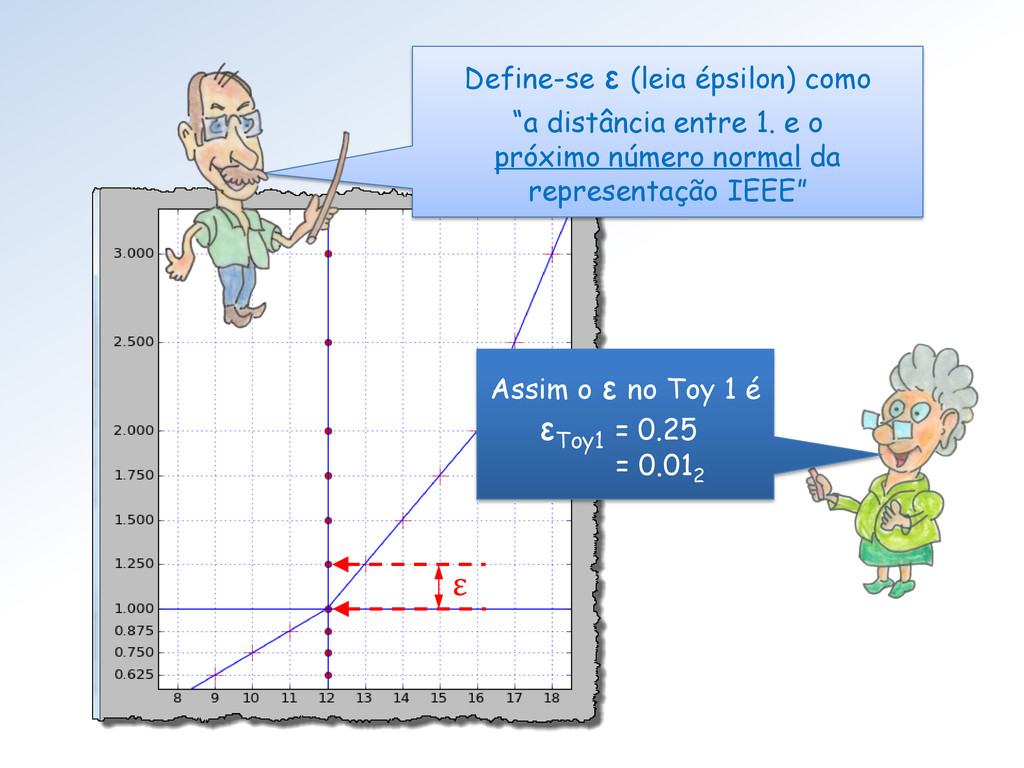
2e-3 ∗ (1.f) com e = 1 e f = 0.00. Ele é, portanto, 1/22 = 0.25. No Single é a mesma coisa, só que ele é dado por 2e-127 ∗ (1.f). Com e = 1 e f = 00 ... 00, obtemos 1/2126 ≅ 1.1754943508222875e-38
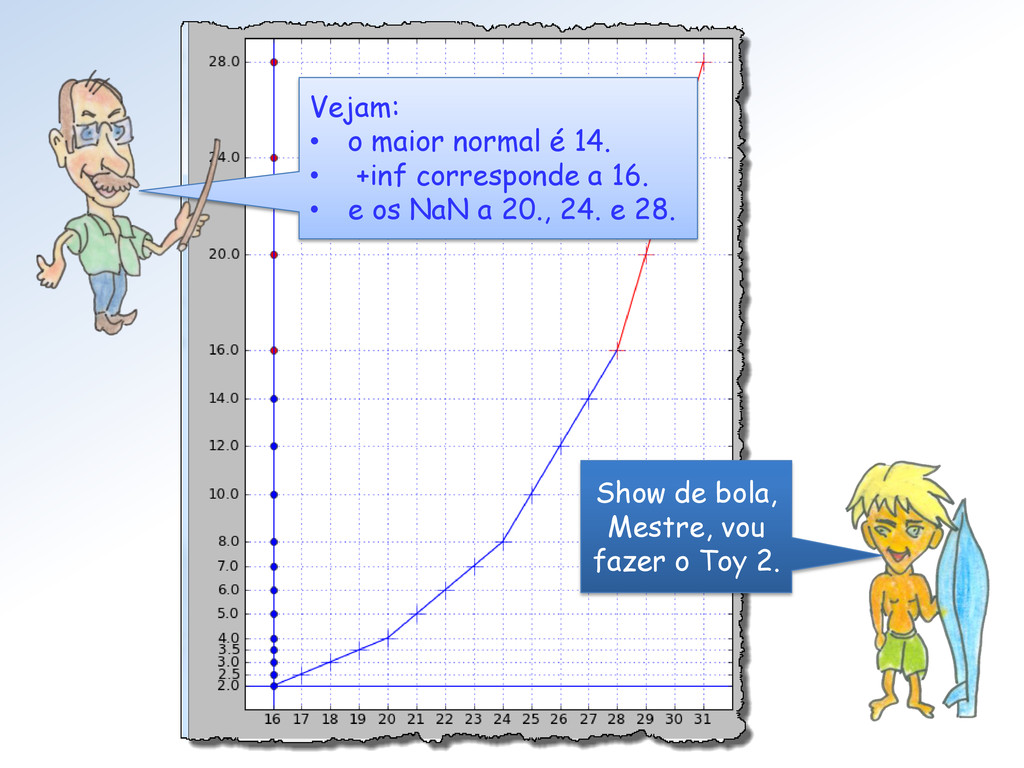
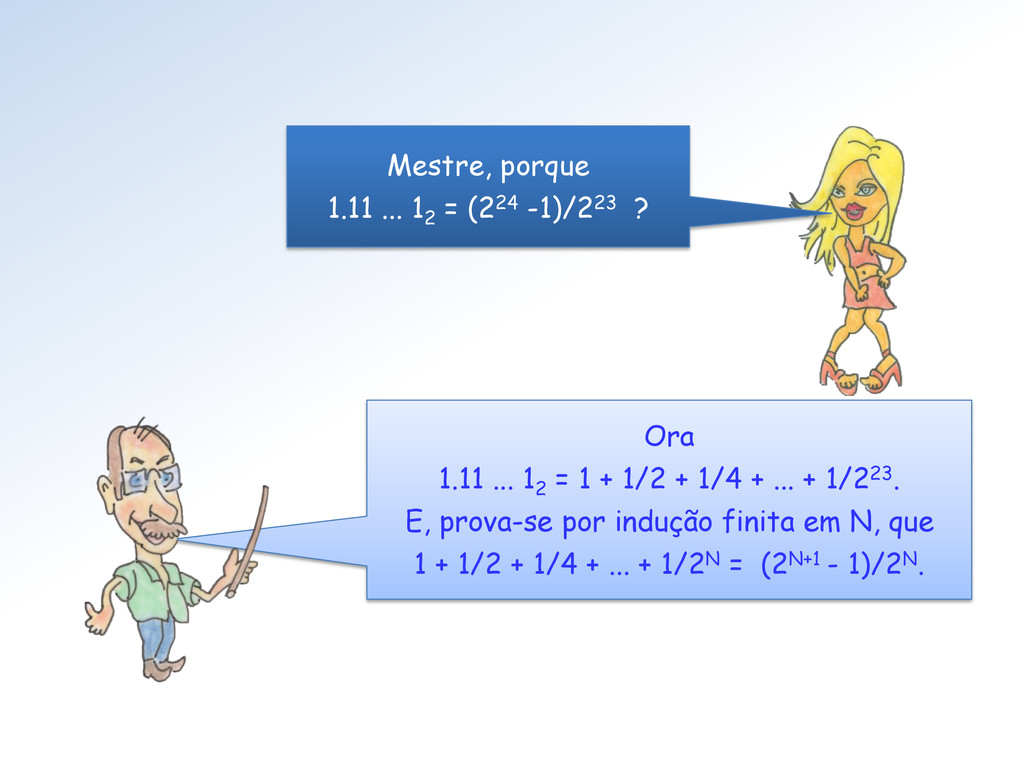
dado por 2e-127 ∗ (1.f). Com e = 254 e f = 0.11 ... 1, obtemos 2128 ∗ (1 + 1/2 + ... + 223) = = 2128 ∗ (224 -1)/ 223 = 2105 ∗ (224 -1) ≅ 6.805646932770577e+38 O maior normal no Toy 1 é dado por 2e-3 ∗ (1.f) com e = 6 e f = 0.11. Assim, ele é 23 ∗ (1 + 1/2 + 1/4) = 8 ∗ 7/4 = 14.
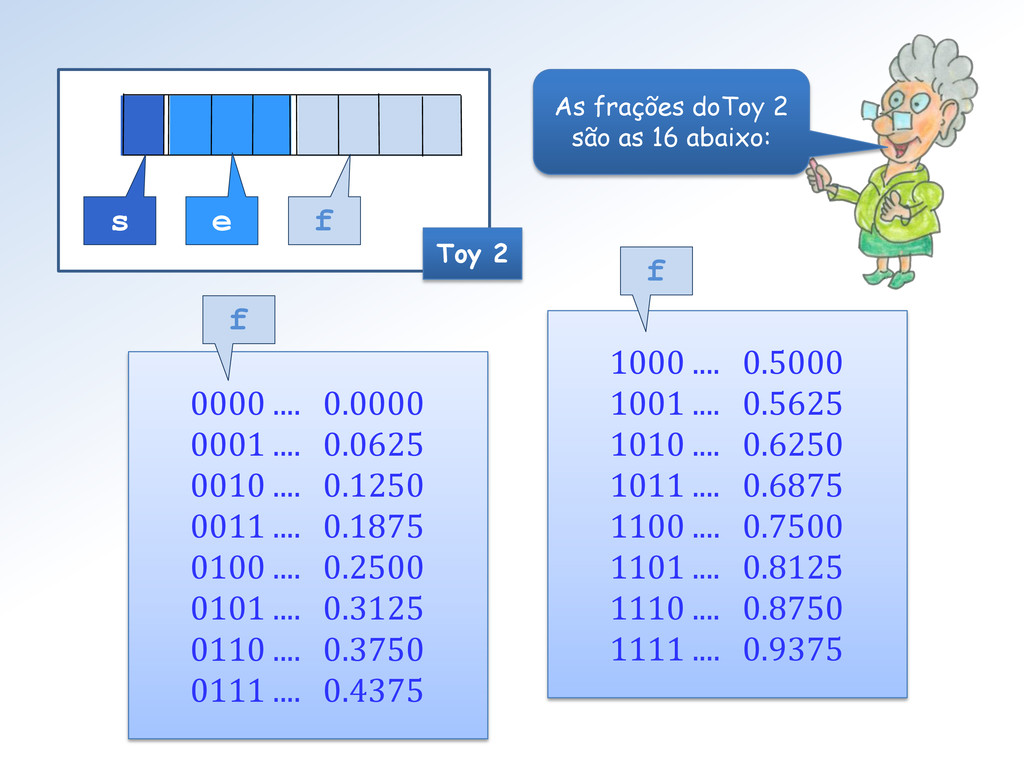
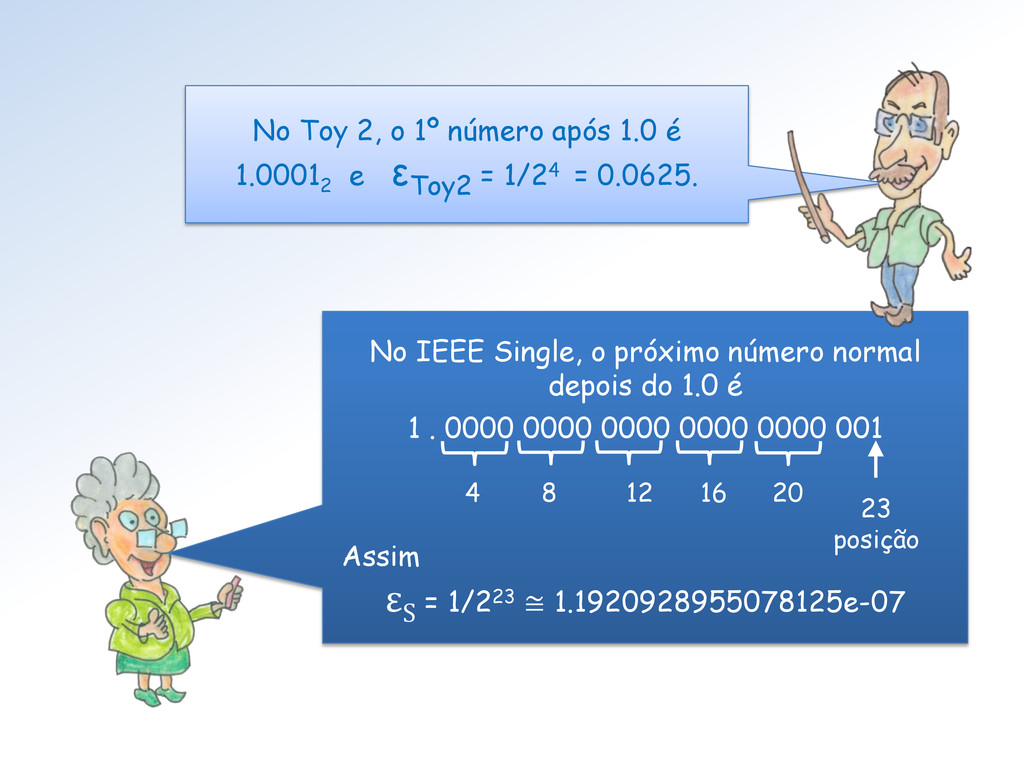
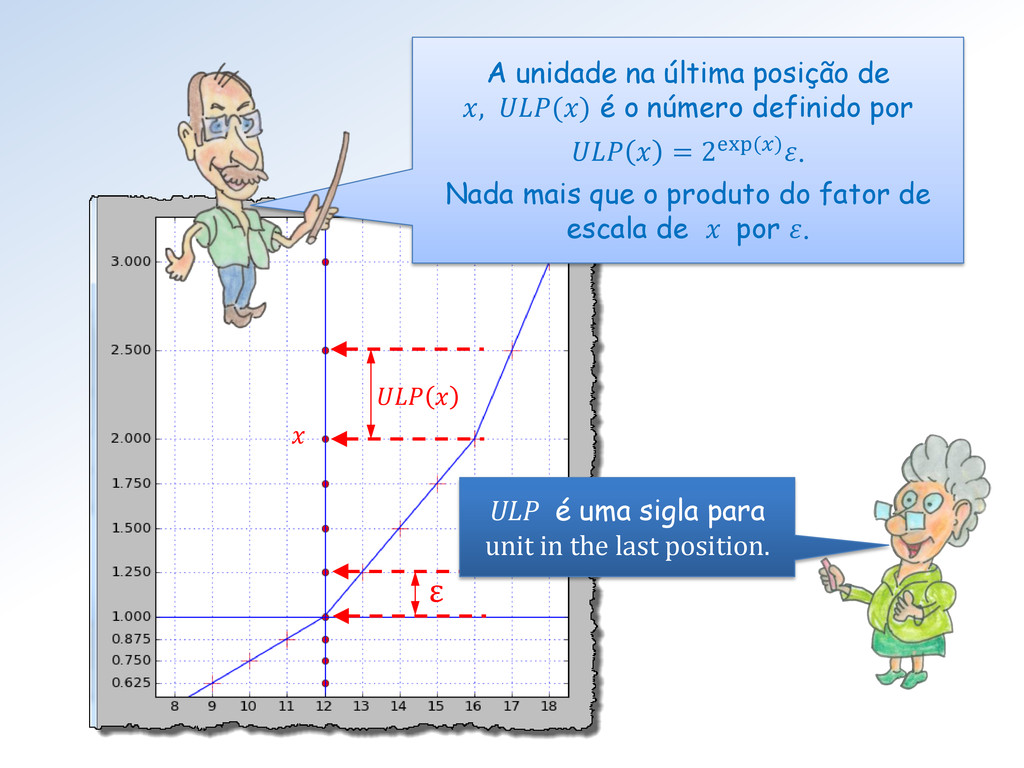
é 1 . 0000 0000 0000 0000 0000 001 Assim ε S = 1/223 ≅ 1.1920928955078125e-07 4 8 12 16 20 23 posição No Toy 2, o 1º número após 1.0 é 1.0001 2 e ε Toy2 = 1/24 = 0.0625.
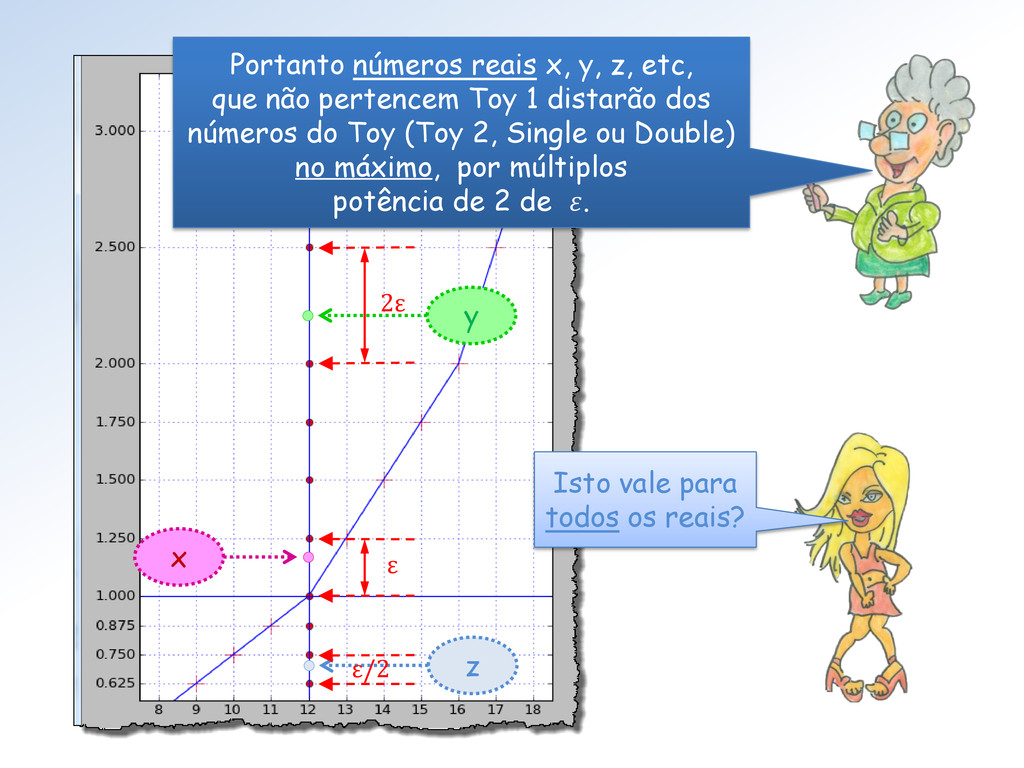
não pertencem Toy 1 distarão dos números do Toy (Toy 2, Single ou Double) no máximo, por múltiplos potência de 2 de . ε z Isto vale para todos os reais? 2ε ε/2
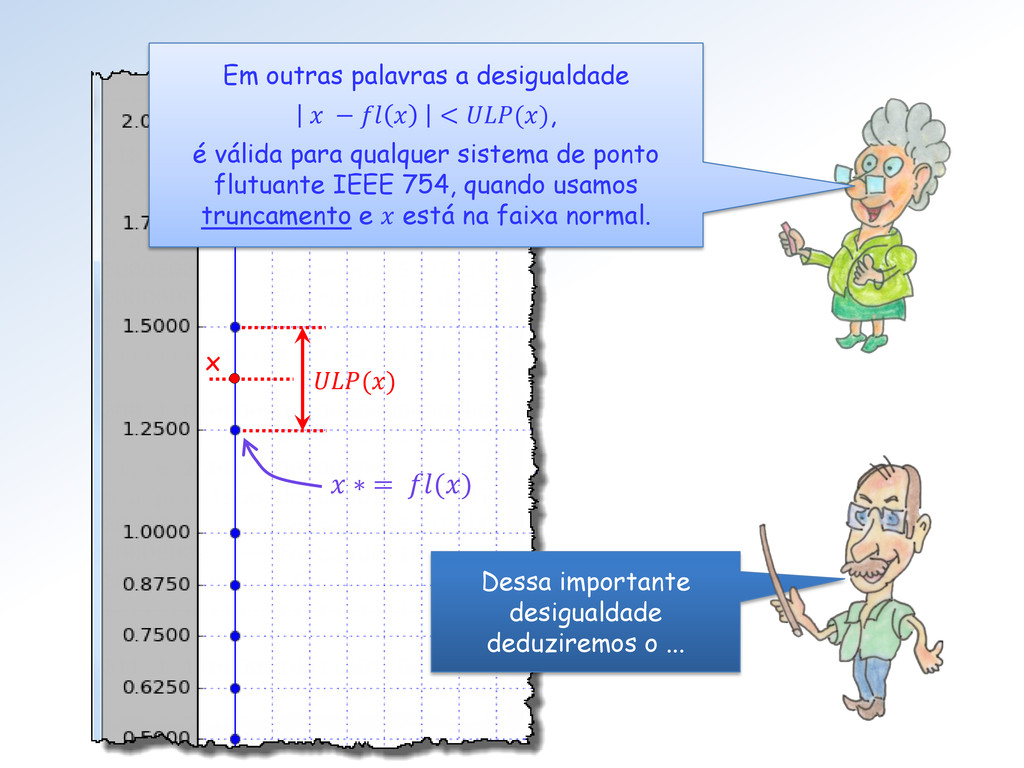
Em outras palavras a desigualdade − < (), é válida para qualquer sistema de ponto flutuante IEEE 754, quando usamos truncamento e está na faixa normal.
IEEE 754, então = (1 + ) para algum satisfazendo < /2, onde é o épsilon desse sistema, quando usamos arredondamento. Teorema fundamental da representação de ponto flutuante IEEE 754:
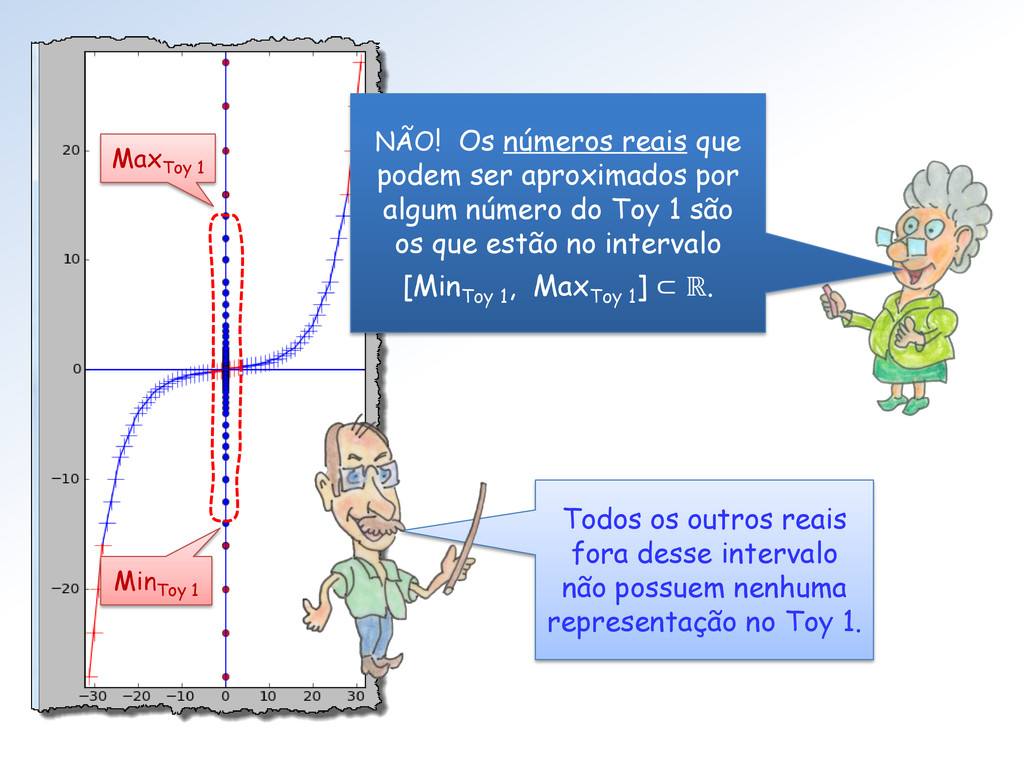
número do Toy 1 são os que estão no intervalo [Min Toy 1 , Max Toy 1 ] ⊂ ℝ. Max Toy 1 Min Toy 1 Todos os outros reais fora desse intervalo não possuem nenhuma representação no Toy 1.
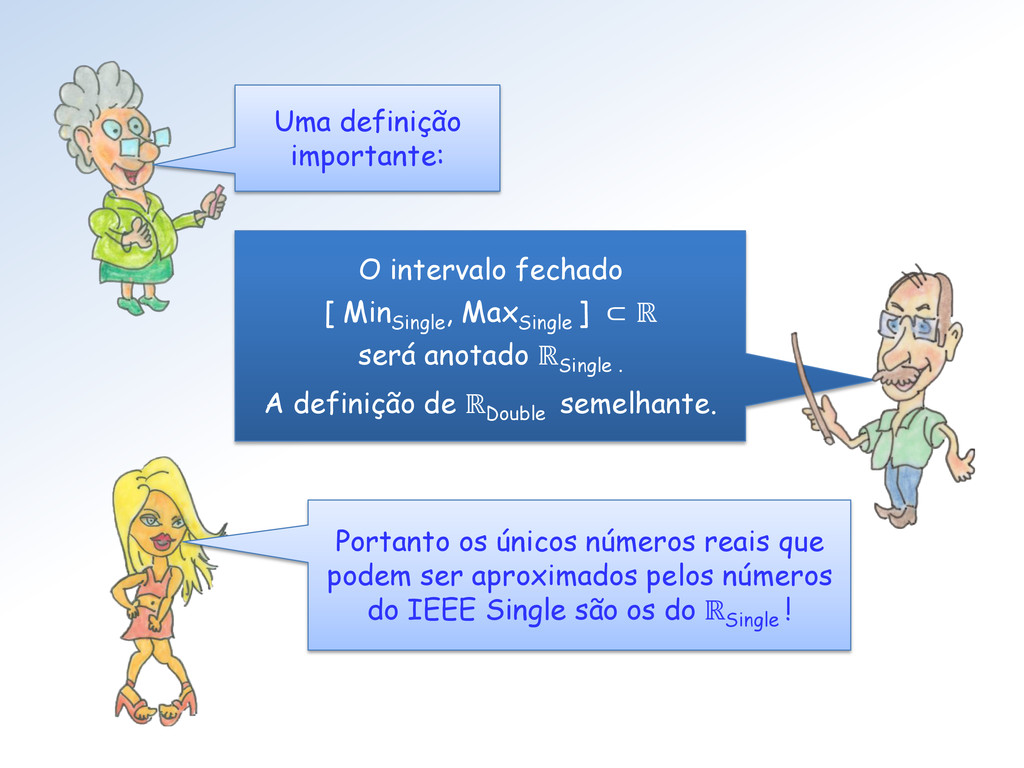
números do IEEE Single são os do ℝSingle ! O intervalo fechado [ Min Single , Max Single ] ⊂ ℝ será anotado ℝSingle . A definição de ℝDouble semelhante. Uma definição importante:
de x; 2. efetuando arredondamento de x; 3. escolhendo o 1º elemento de Float ao “subir” de x para +Inf”; 4. escolhendo o 1º elemento de Float ao “descer” de x para -Inf”. De fato, o padrão IEEE 754 estabelece quatro possíveis funções fl S : ℝSingle → Float x ↦ x* = fl S (x) e outras quatro para double, de acordo com uma das regras:
exemplo, truncando -2.38 obtemos -2,3 e truncando 2.38 obtemos 2.3, ambos mais próximo de zero. Assim, ao truncar, você sempre “caminha” em direção ao zero. Mas no truncamento não “descemos” sempre para -Inf?
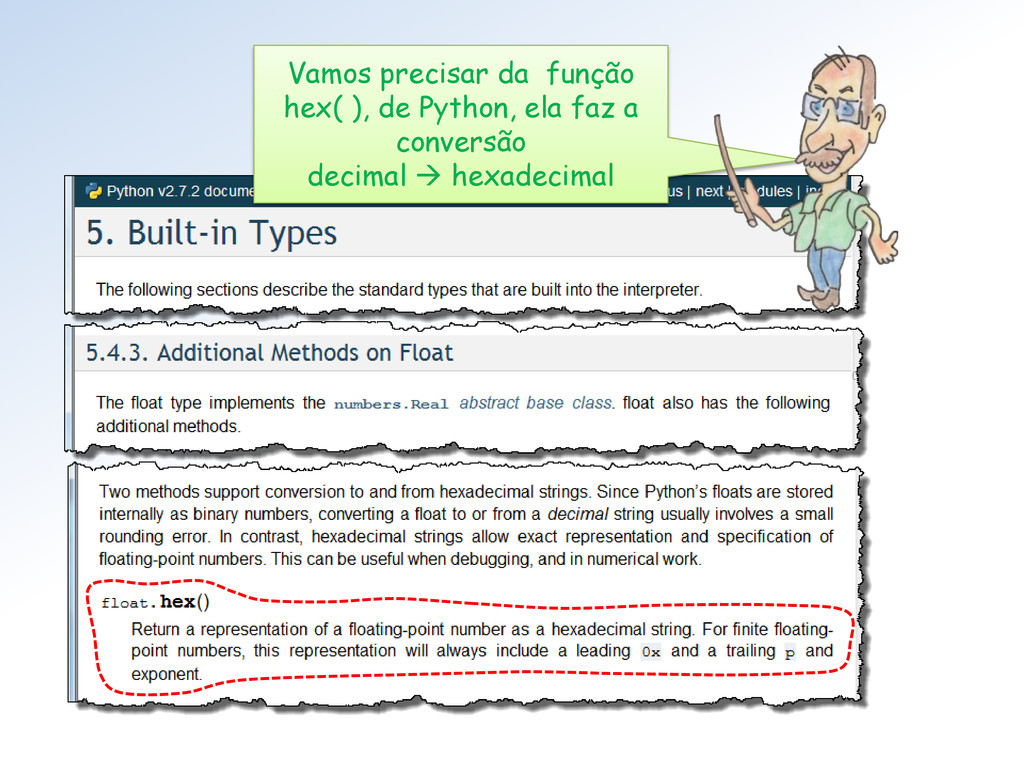
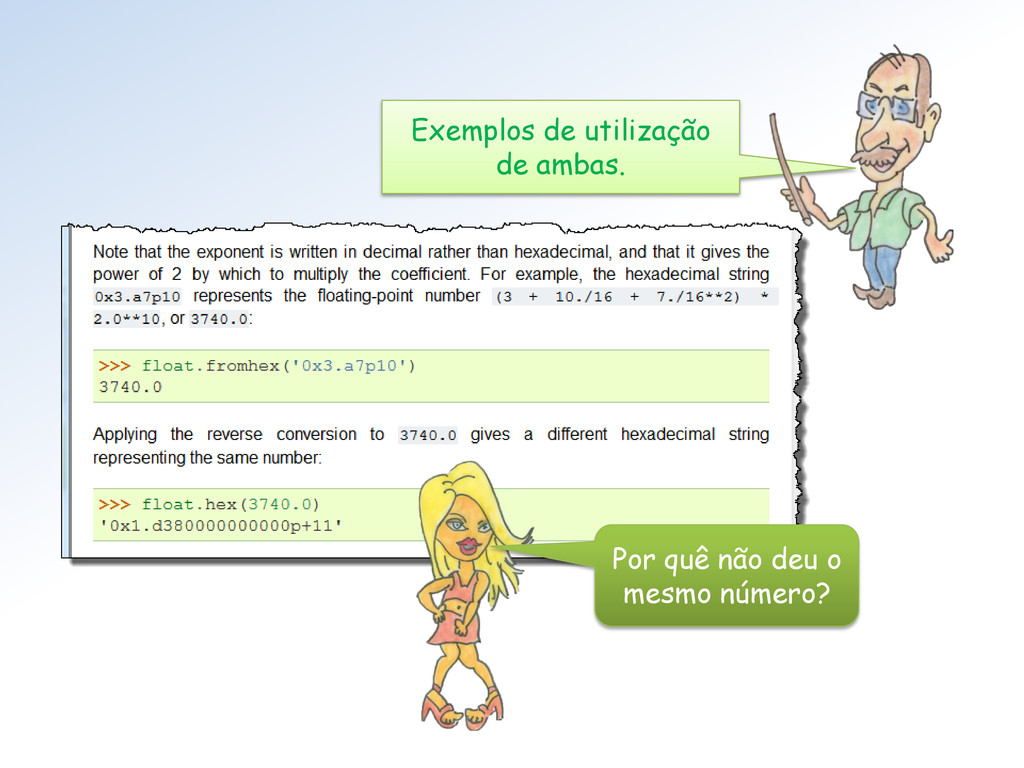
base 10 para sua representação de base 2. Fizemos isto na aula passada! Mestre, mas como eu obtenho, de fato, a representação IEEE Single de um número decimal no ℝSingle ?
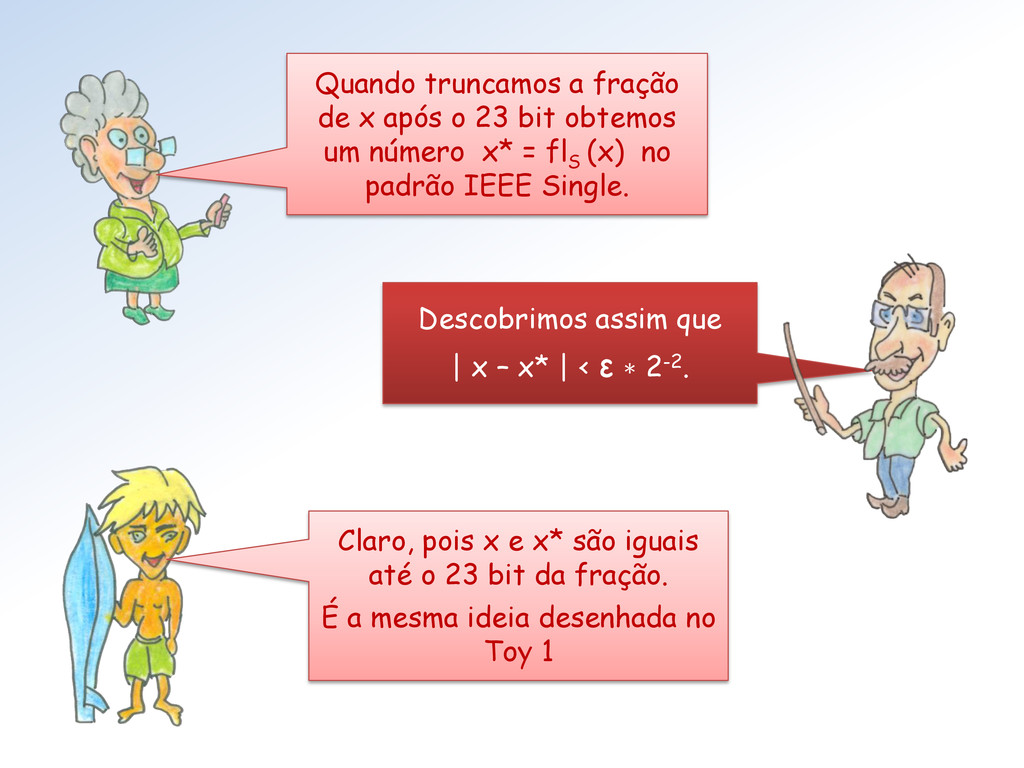
obtemos um número x* = fl S (x) no padrão IEEE Single. Descobrimos assim que | x – x* | < ε ∗ 2-2. Claro, pois x e x* são iguais até o 23 bit da fração. É a mesma ideia desenhada no Toy 1
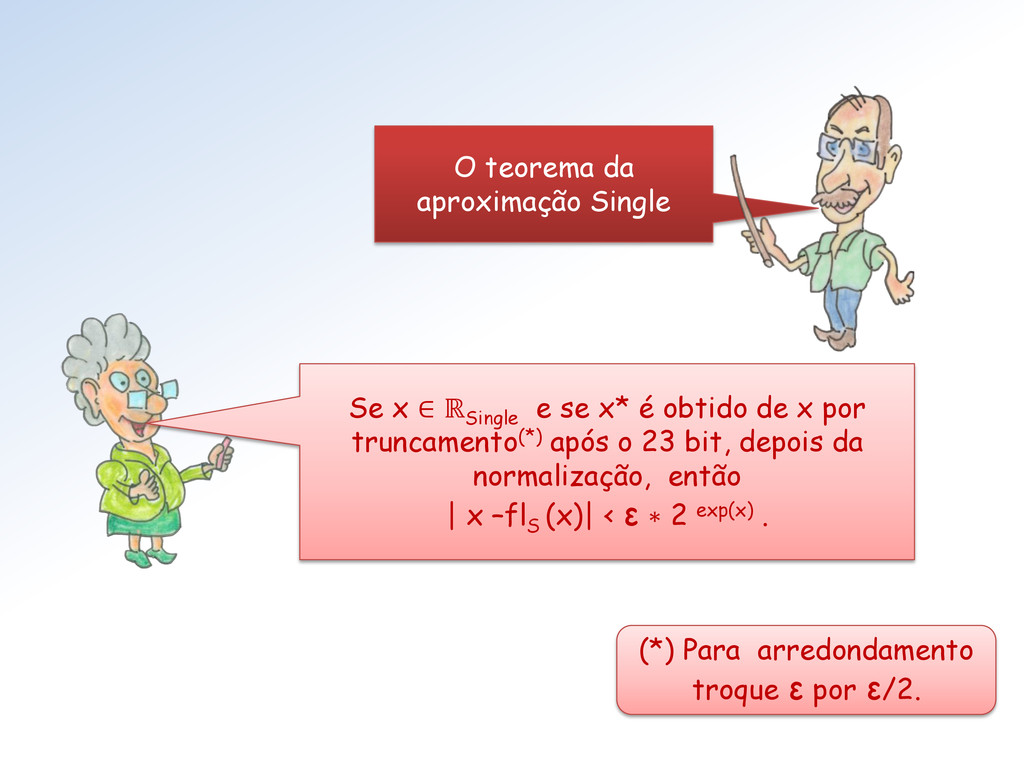
se x* é obtido de x por truncamento(*) após o 23 bit, depois da normalização, então | x –fl S (x)| < ε ∗ 2 exp(x) . (*) Para arredondamento troque ε por ε/2.
outro x*, definem-se dois tipos de erro: • o erro absoluto, E abs (x→x*) = |x- x*| • e o erro relativo, E rel (x→x*) = E abs (x)/|x|, desde que x ≠ 0. A definição abaixo é de caráter geral.
por truncamento(*) após o 23 bit, depois da normalização, então E abs (x→x*) < ULP S (x). Assim o Teorema da aproximação Single fica: E, pode ser provado que, nesse processo, E rel (x→x*) < ε S (*) No arredondamento é metade disso.
por truncamento(*) após o 52 bit, depois da normalização, então E abs (x→x*) < ULP D (x) . O Teorema de aproximação Double é semelhante: E, pode ser provado que, nesse processo, E rel (x→x*) < ε D (*) No arredondamento é metade disso.
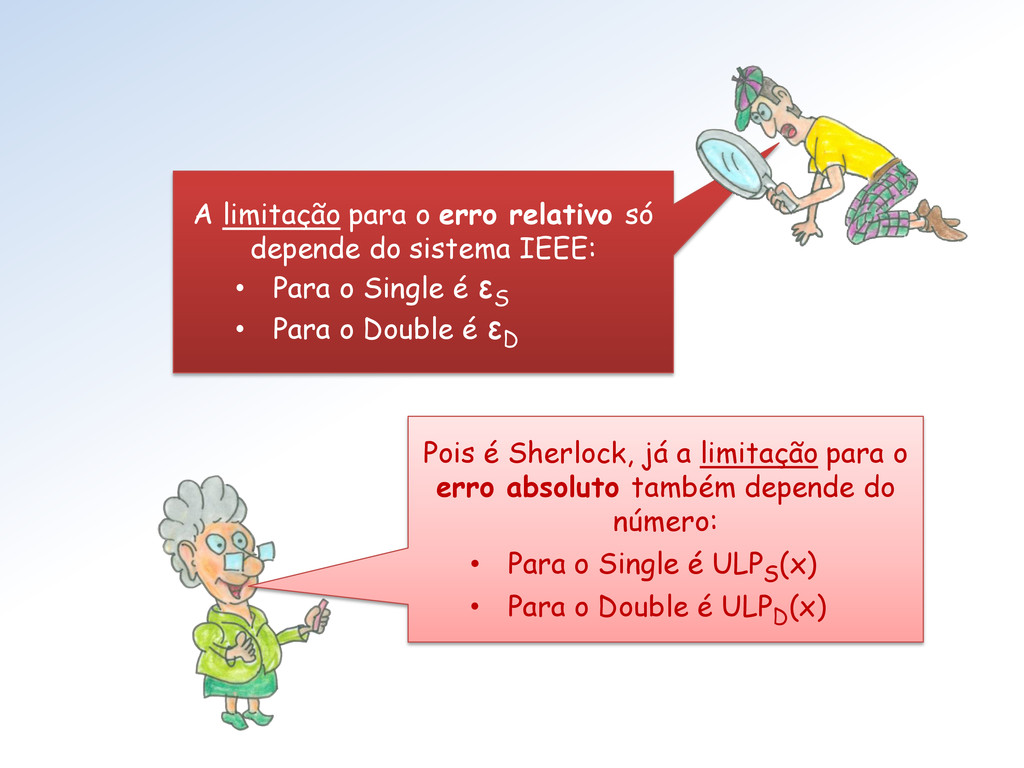
IEEE: • Para o Single é ε S • Para o Double é ε D Pois é Sherlock, já a limitação para o erro absoluto também depende do número: • Para o Single é ULPS (x) • Para o Double é ULPD (x)
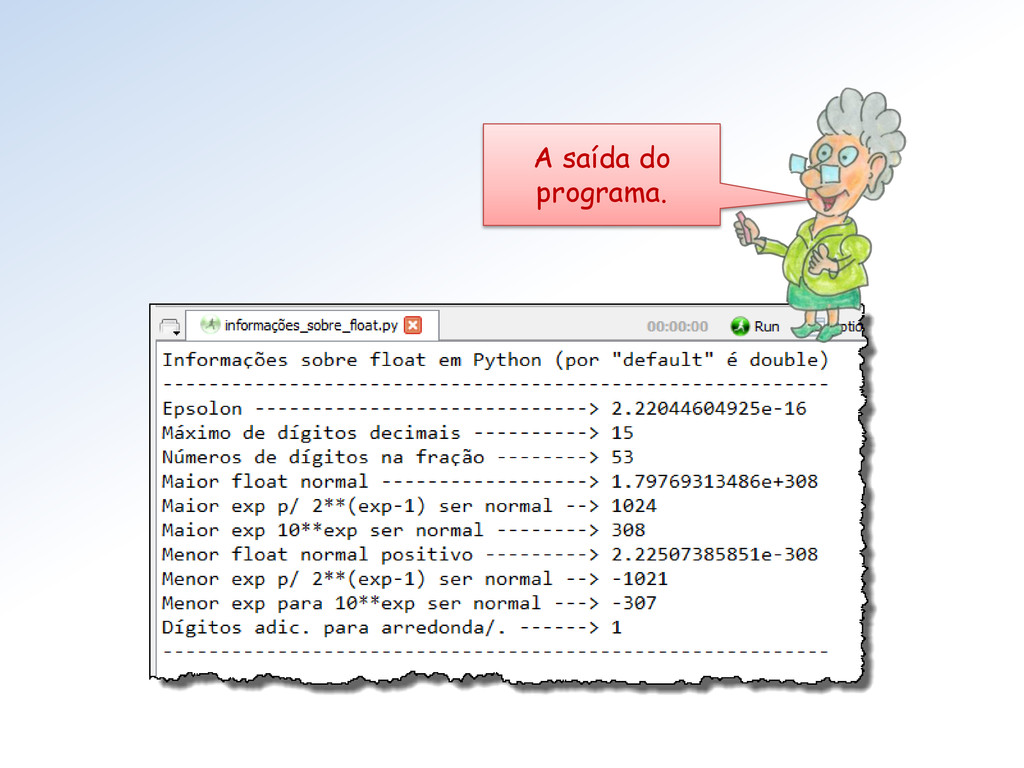
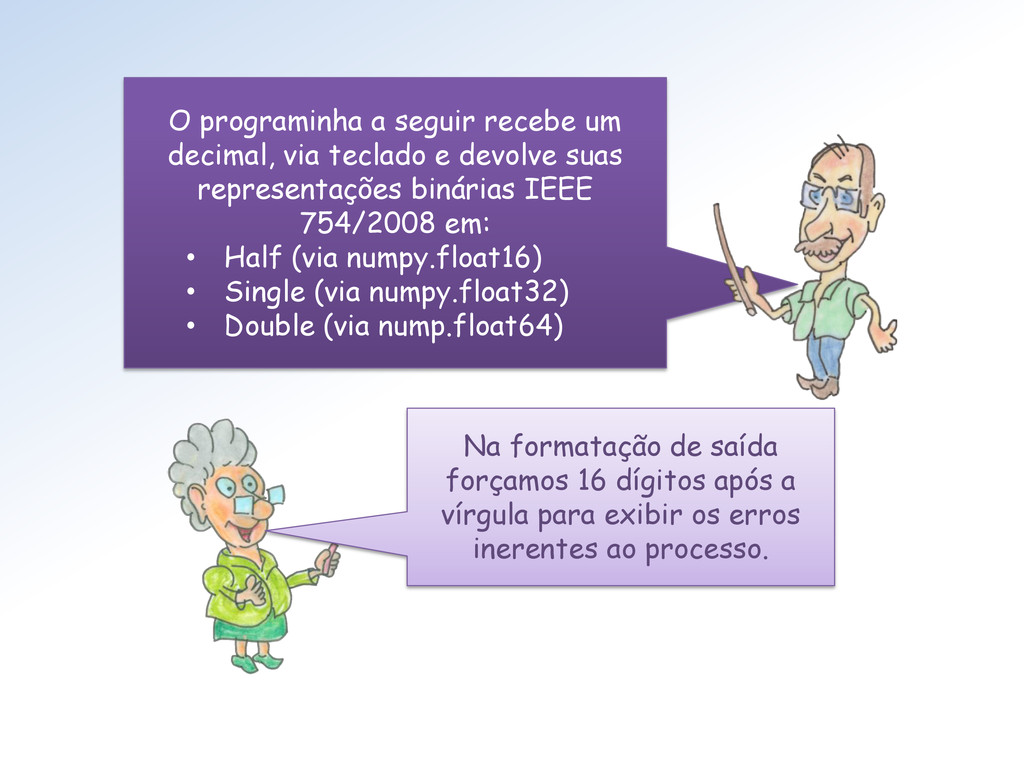
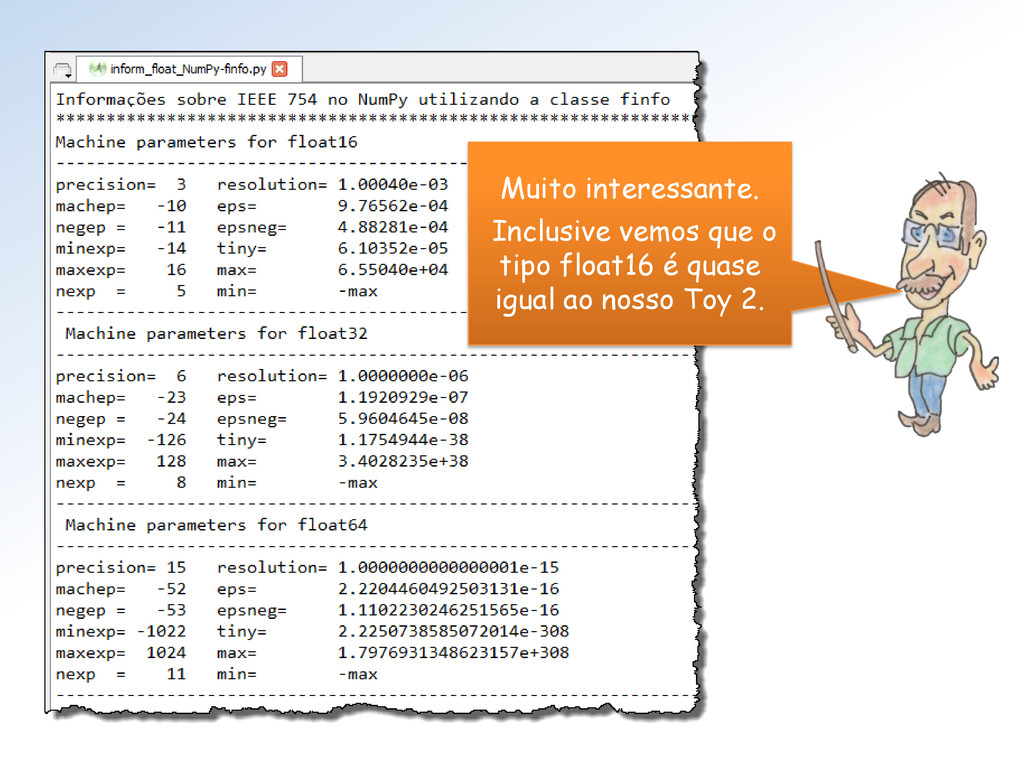
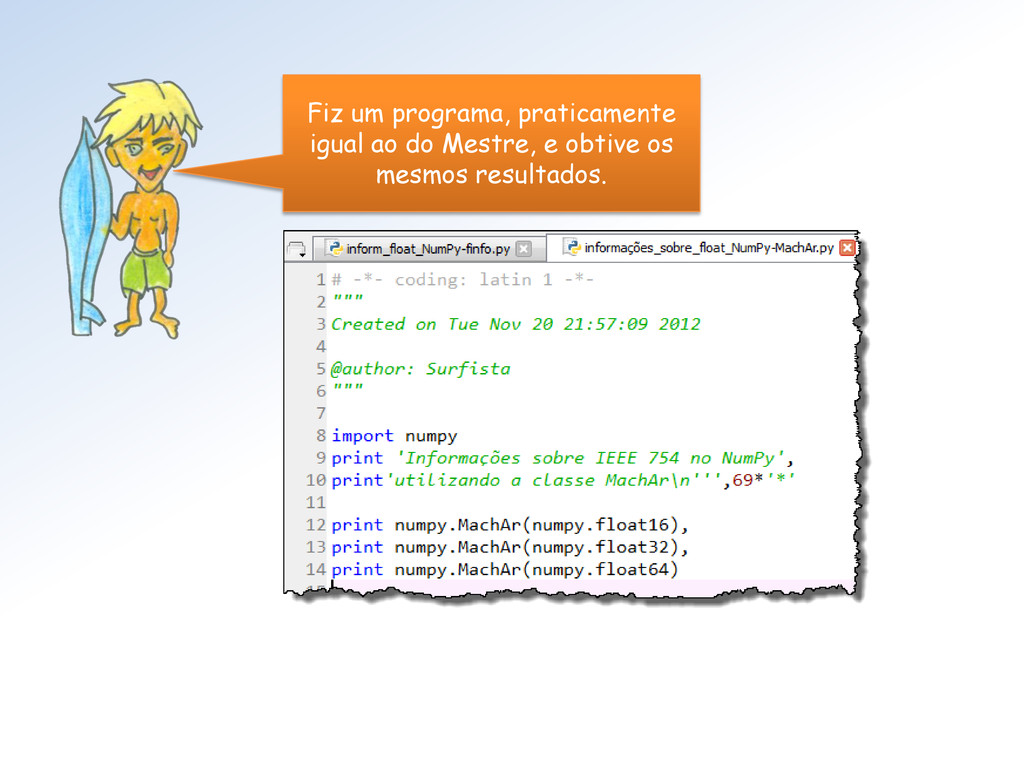
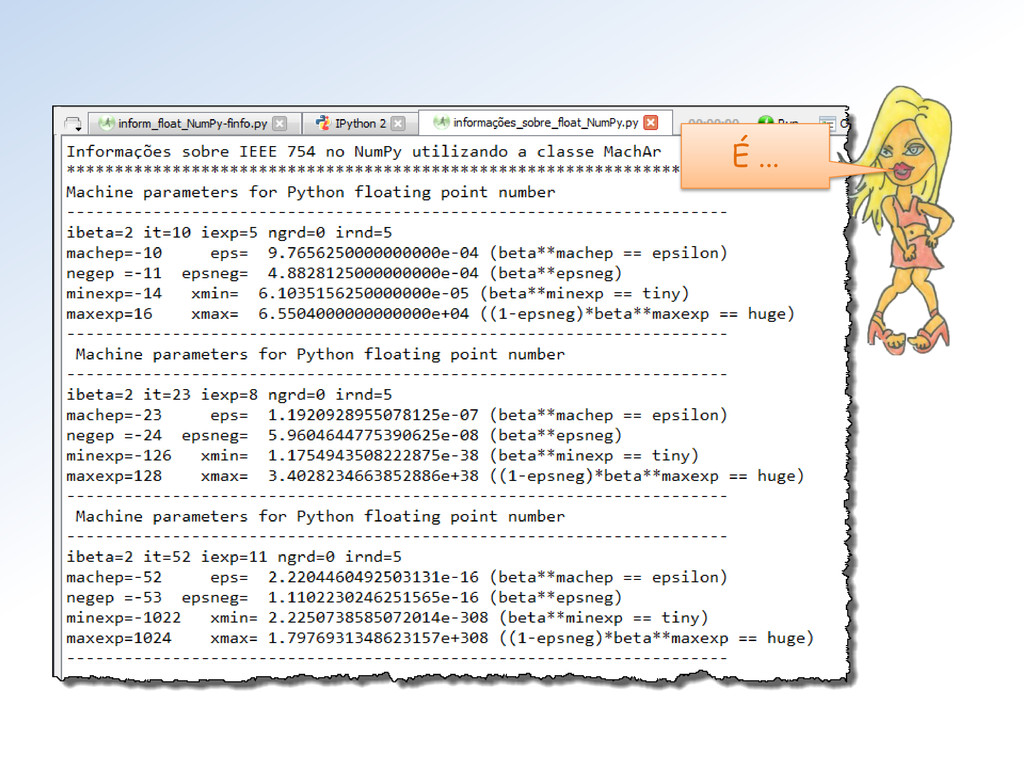
devolve suas representações binárias IEEE 754/2008 em: • Half (via numpy.float16) • Single (via numpy.float32) • Double (via nump.float64) Na formatação de saída forçamos 16 dígitos após a vírgula para exibir os erros inerentes ao processo.
do erro no cálculo de funções. Aguardem! Vou voltar no tempo, lá para a Magna Grécia, nos 400 AC. Desisto de apoiar os cursos desse Professor. Lá usamos ábacos – são mais confiáveis que esses computadores.
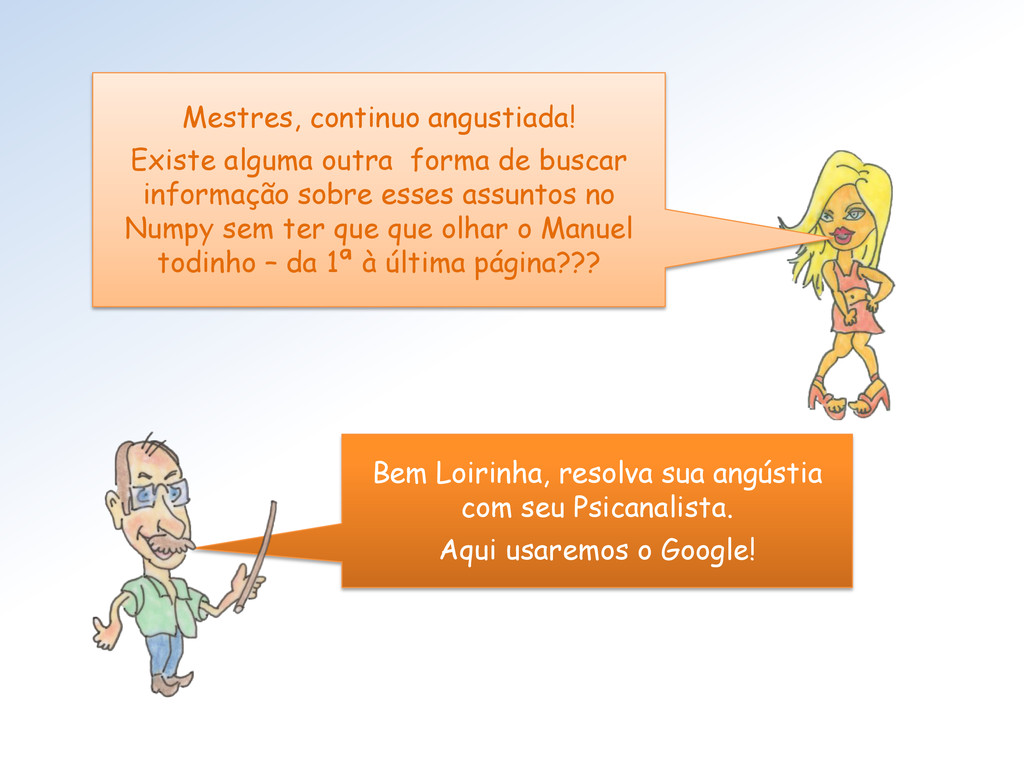
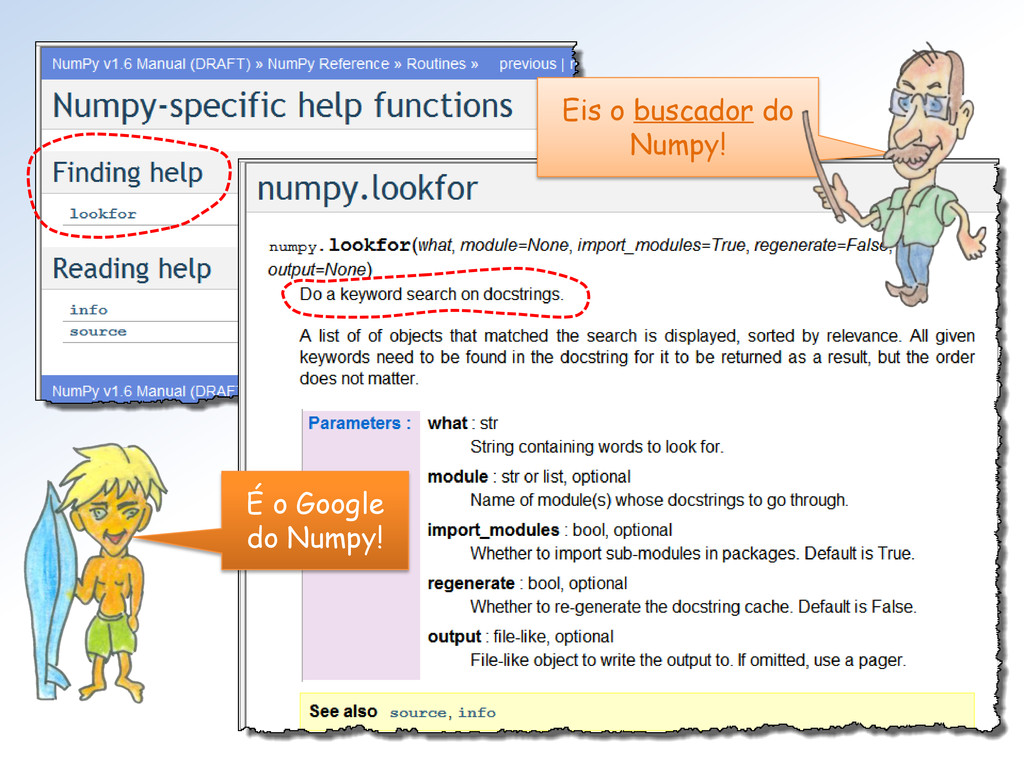
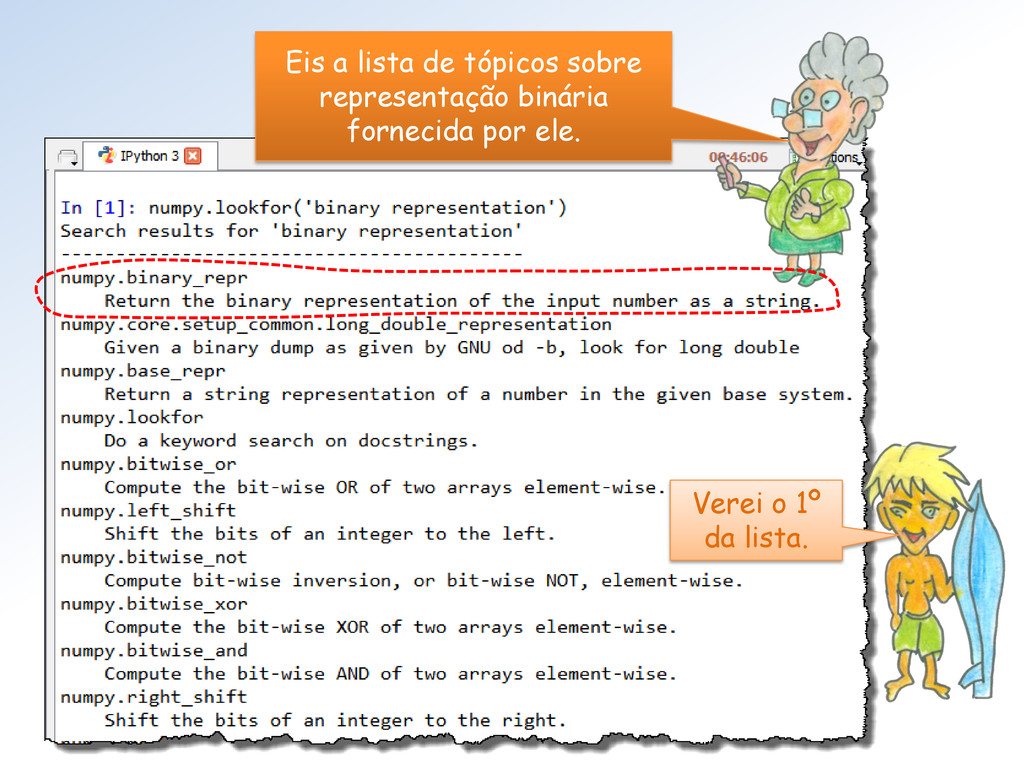
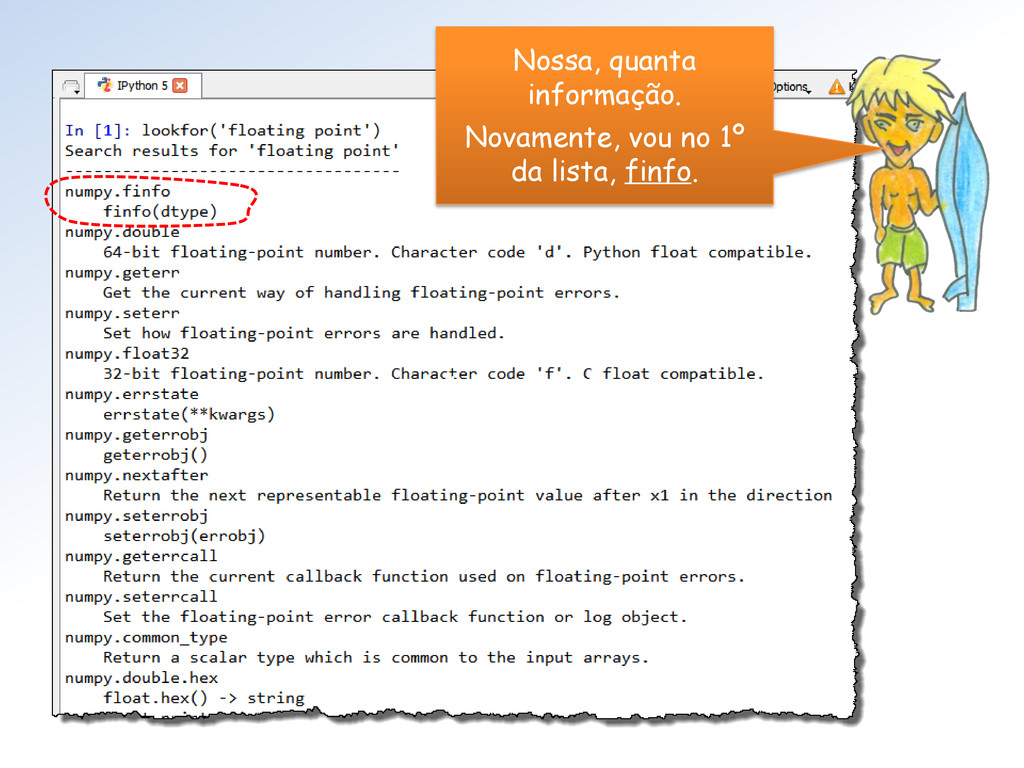
sobre esses assuntos no Numpy sem ter que que olhar o Manuel todinho – da 1ª à última página??? Bem Loirinha, resolva sua angústia com seu Psicanalista. Aqui usaremos o Google!
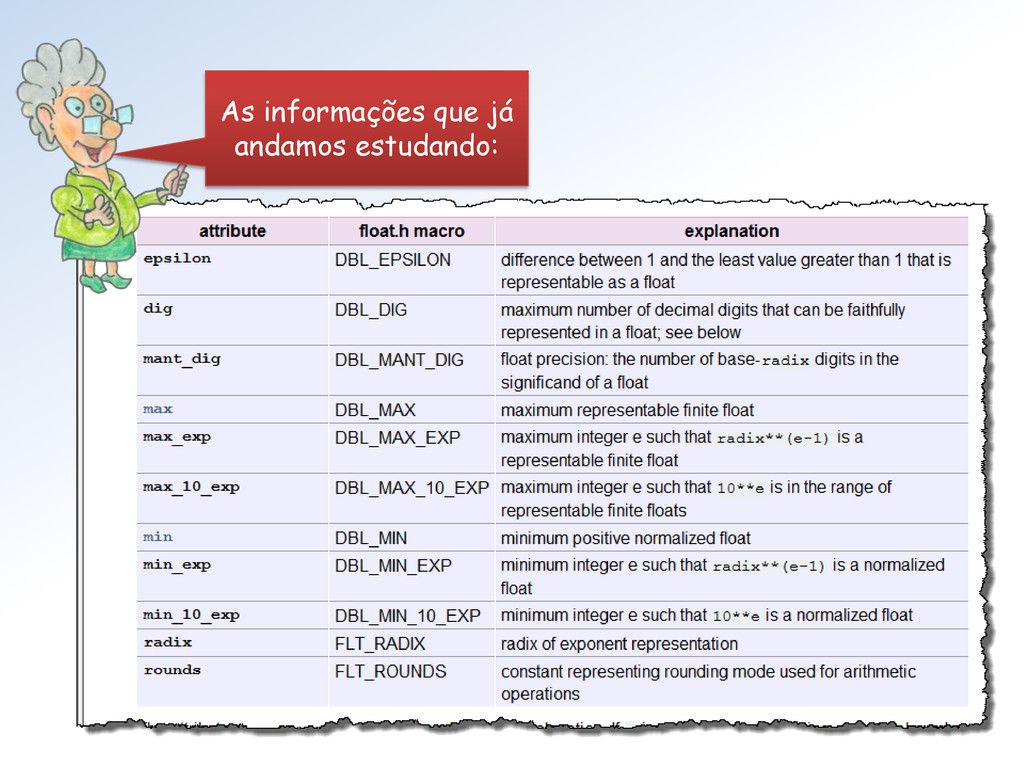
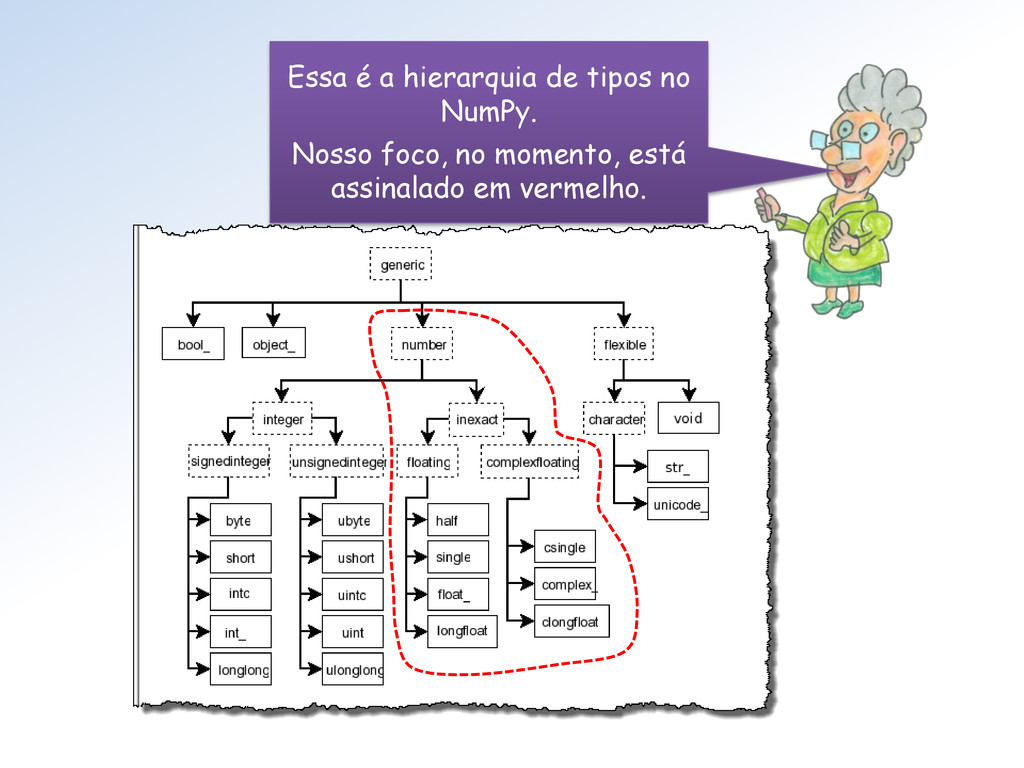
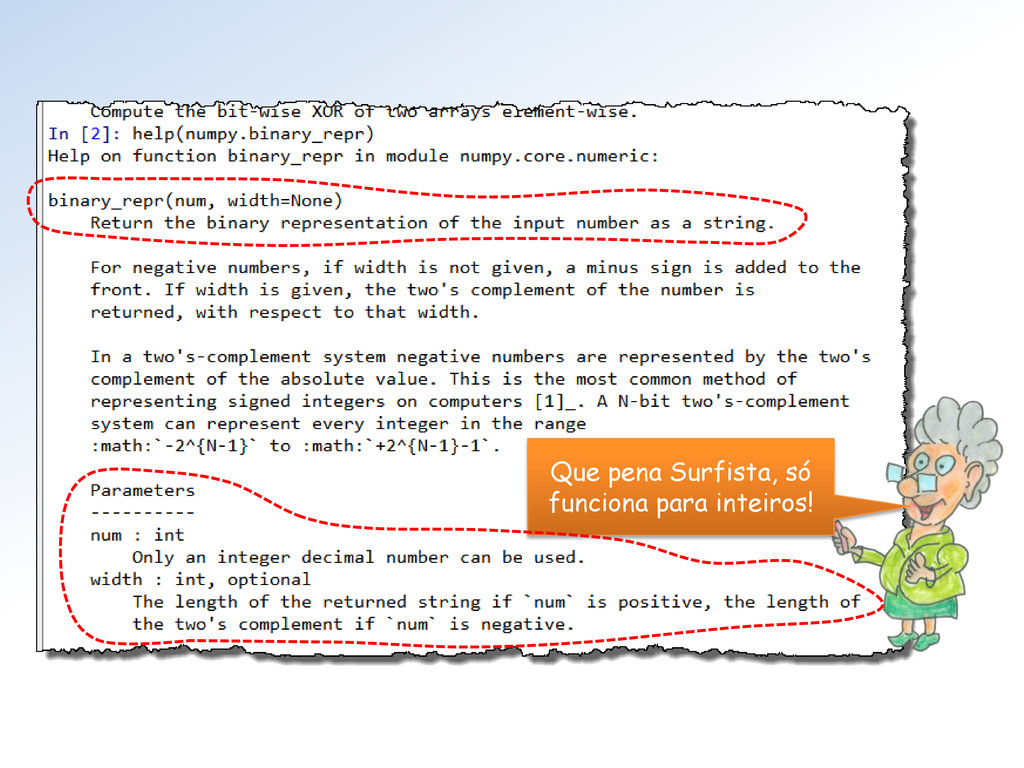
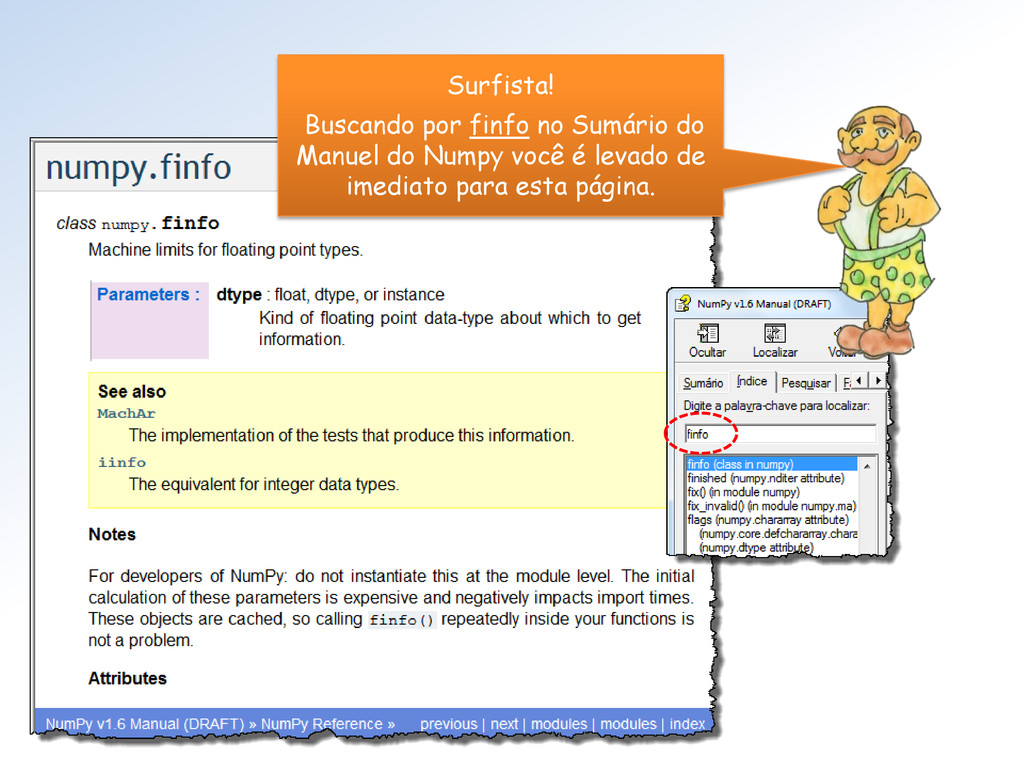
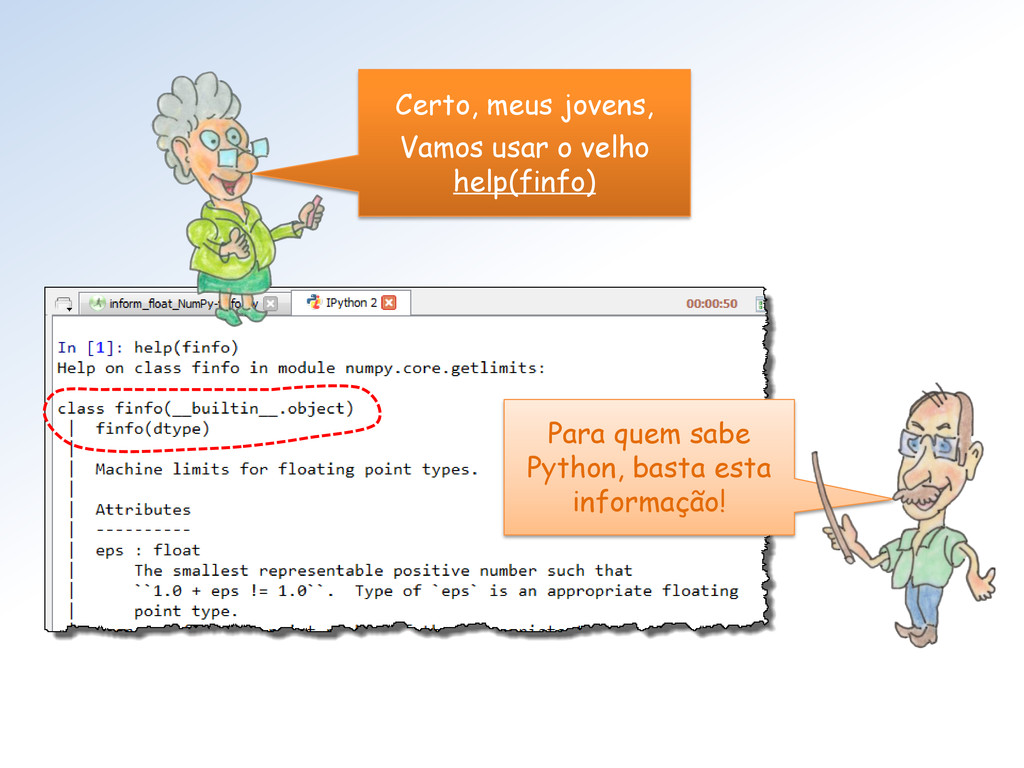
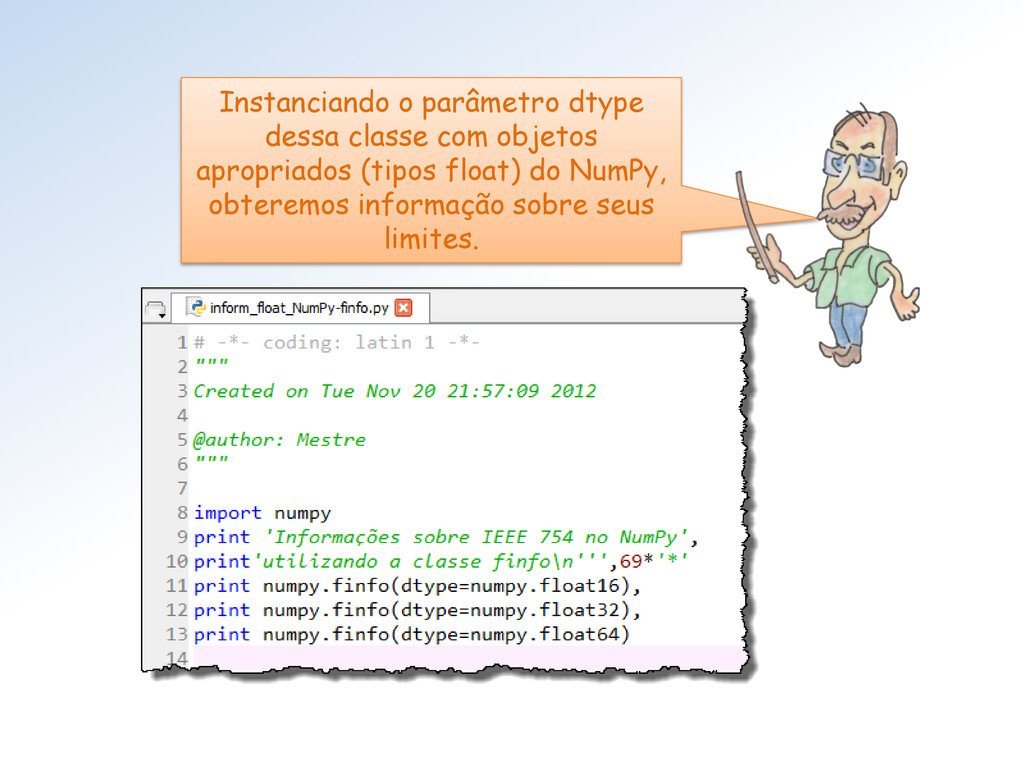
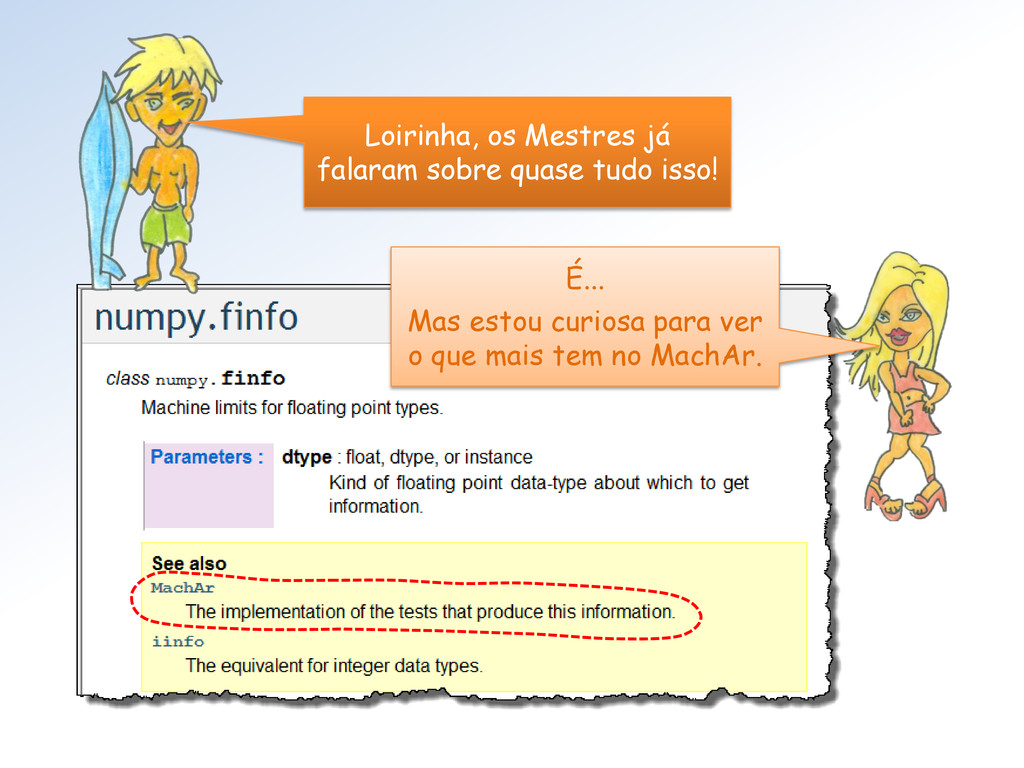
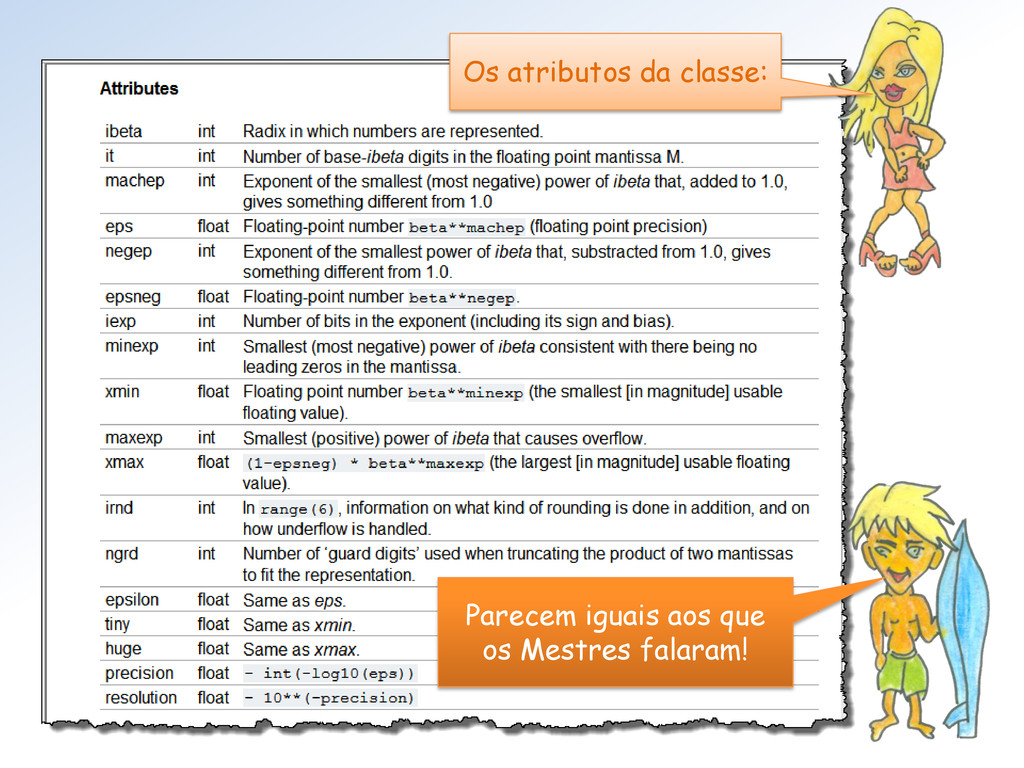
tipos float do Numpy (seus limites). Mestra não vejo como proceder para utilizar essa classe. Além disso, parece que faltam informações (Atributos = ??).
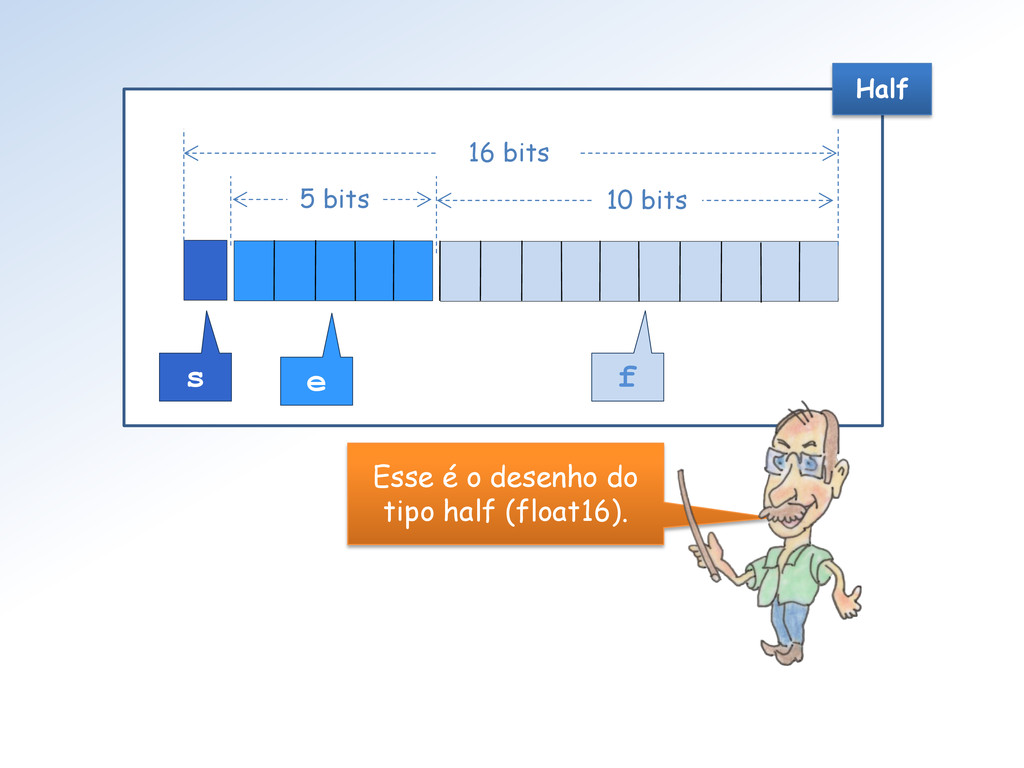
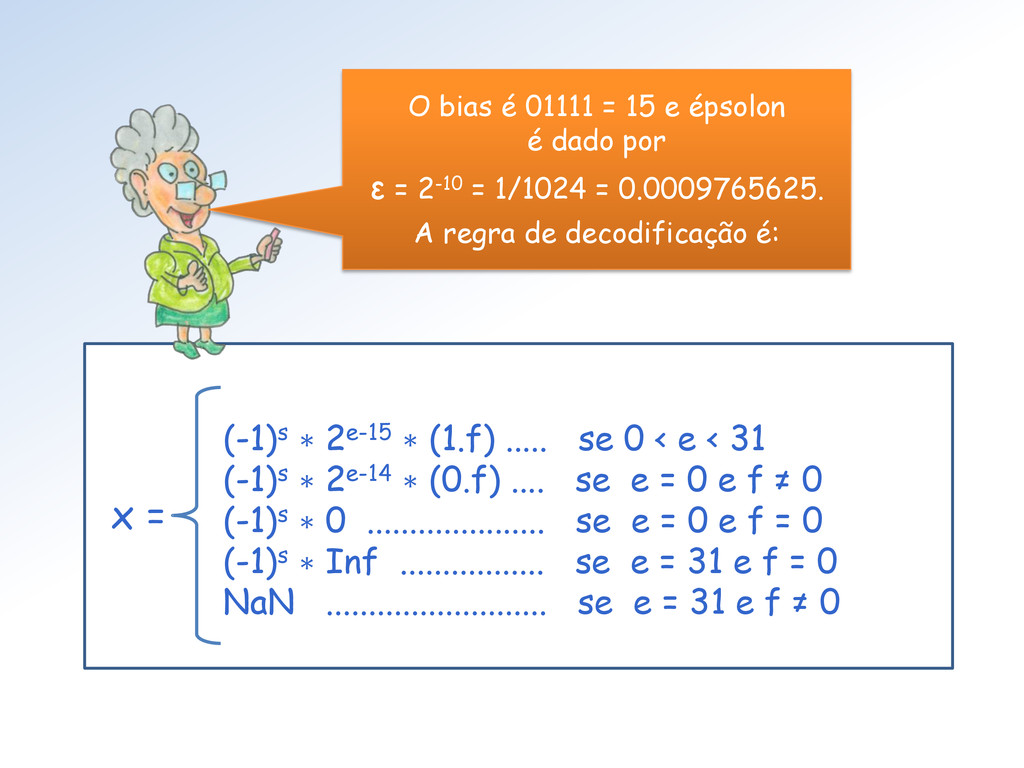
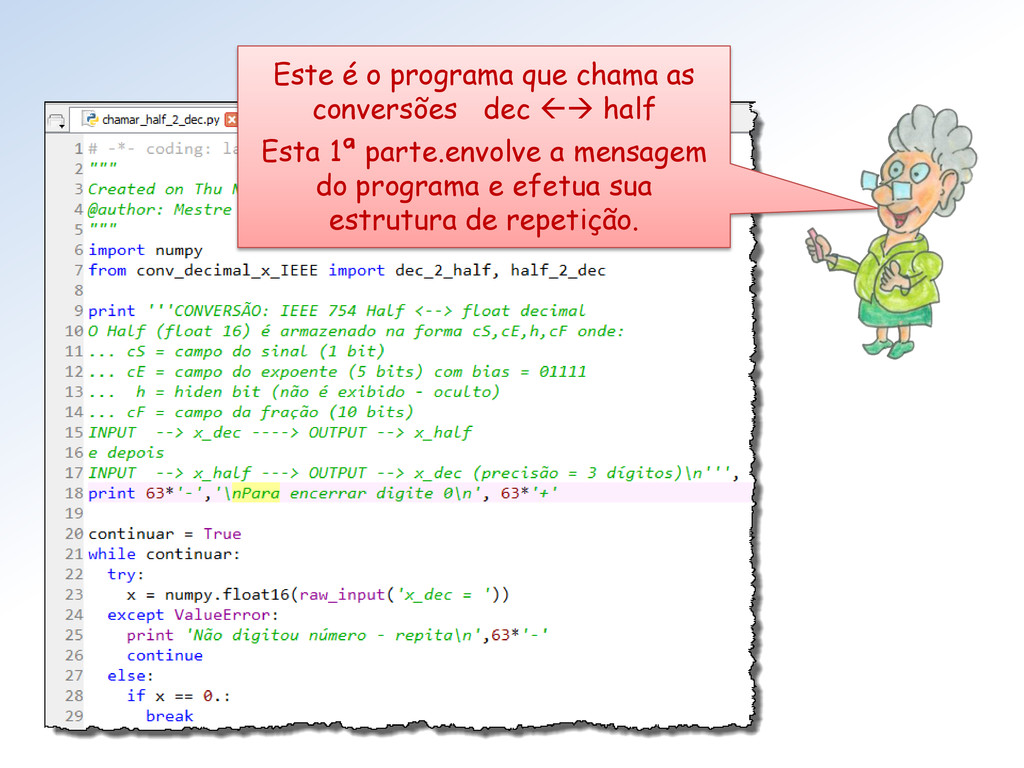
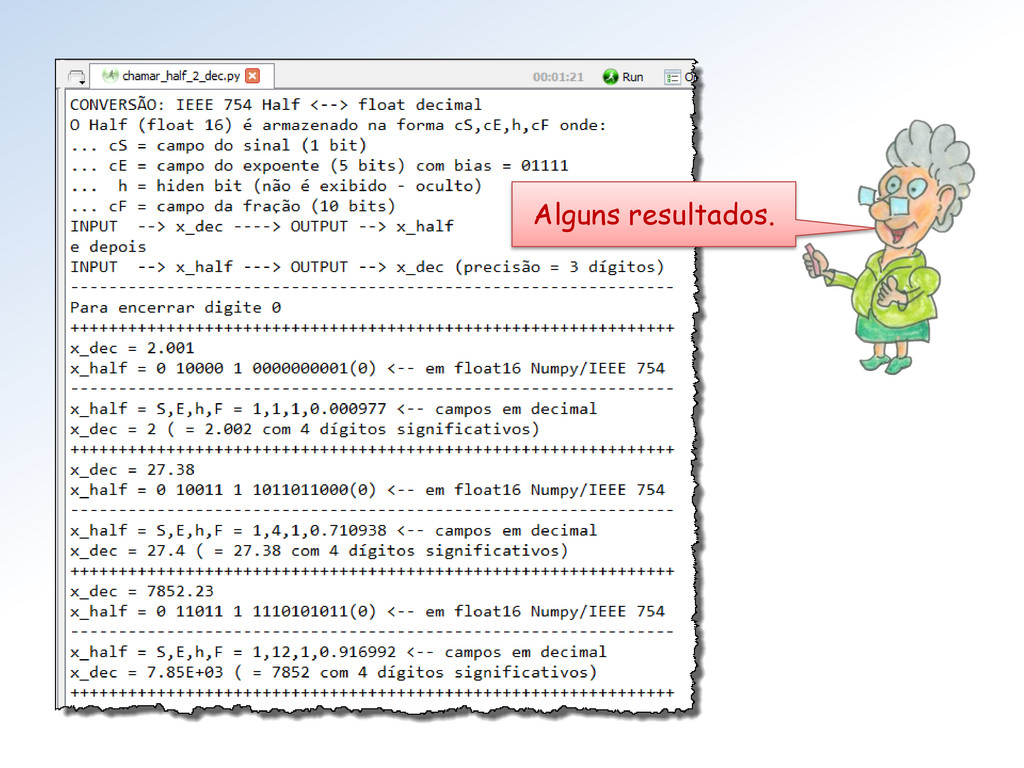
< 31 (-1)s ∗ 2e-14 ∗ (0.f) .... se e = 0 e f ≠ 0 (-1)s ∗ 0 ..................... se e = 0 e f = 0 (-1)s ∗ Inf ................. se e = 31 e f = 0 NaN .......................... se e = 31 e f ≠ 0 x = O bias é 01111 = 15 e épsolon é dado por ε = 2-10 = 1/1024 = 0.0009765625. A regra de decodificação é:
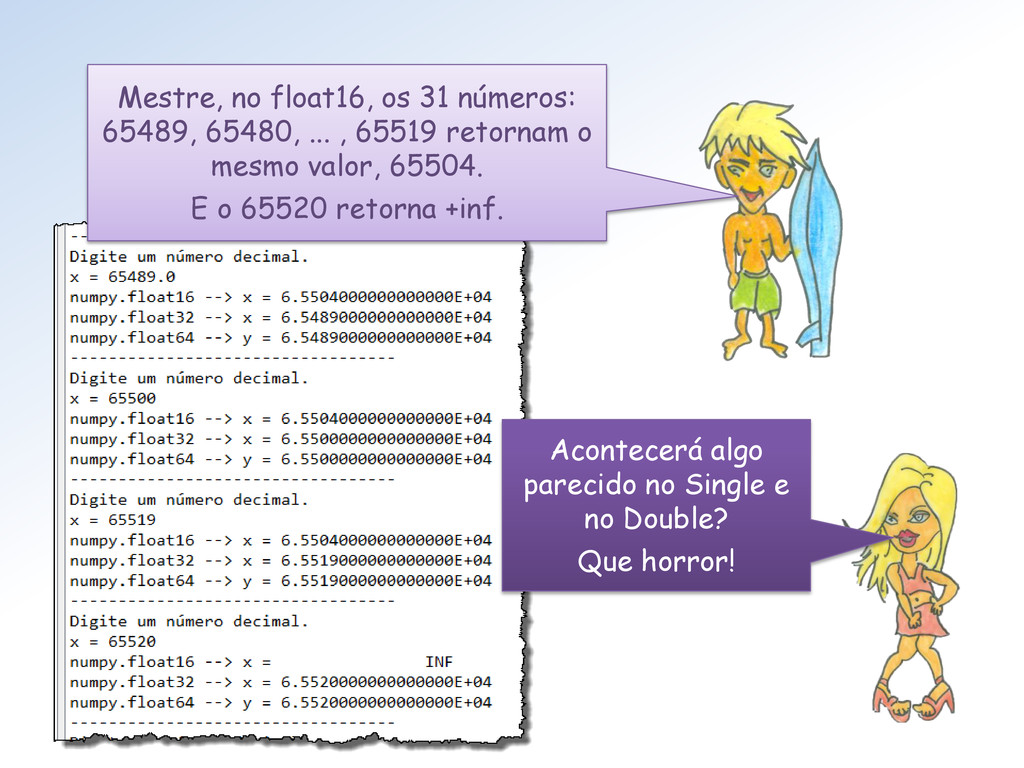
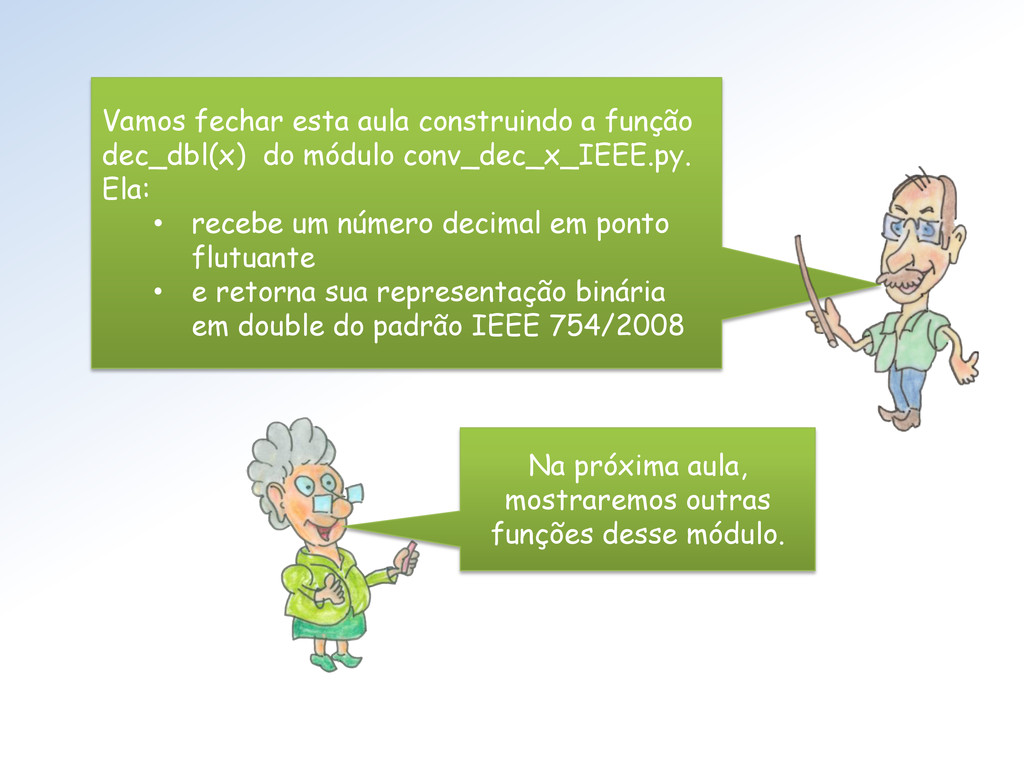
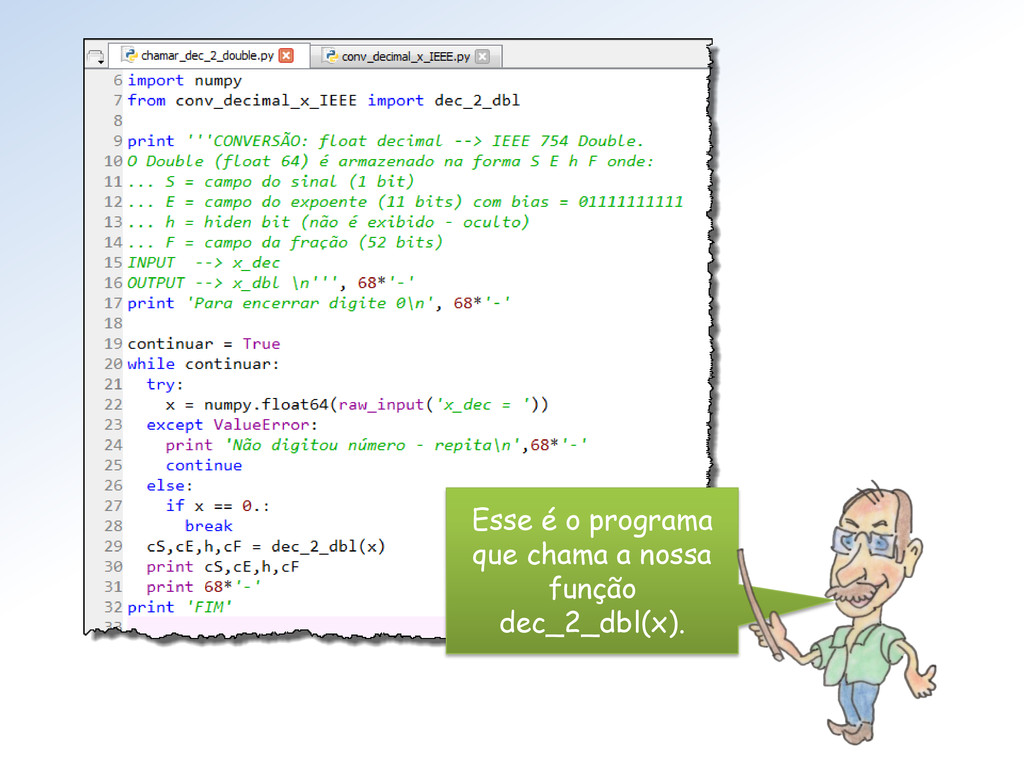
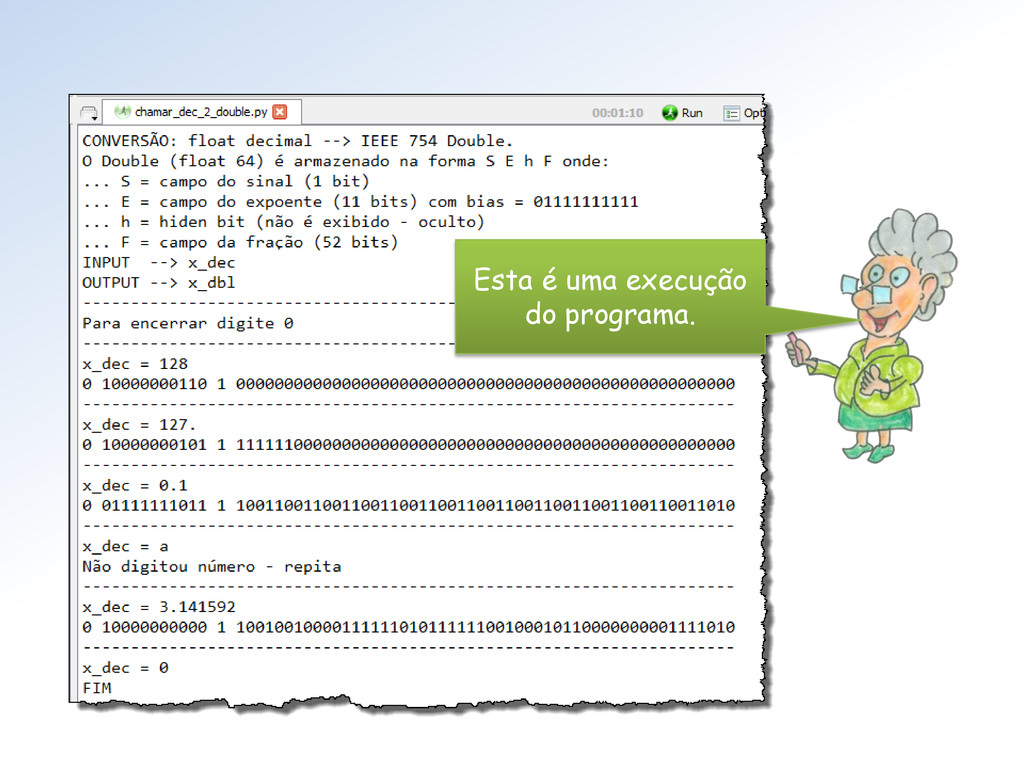
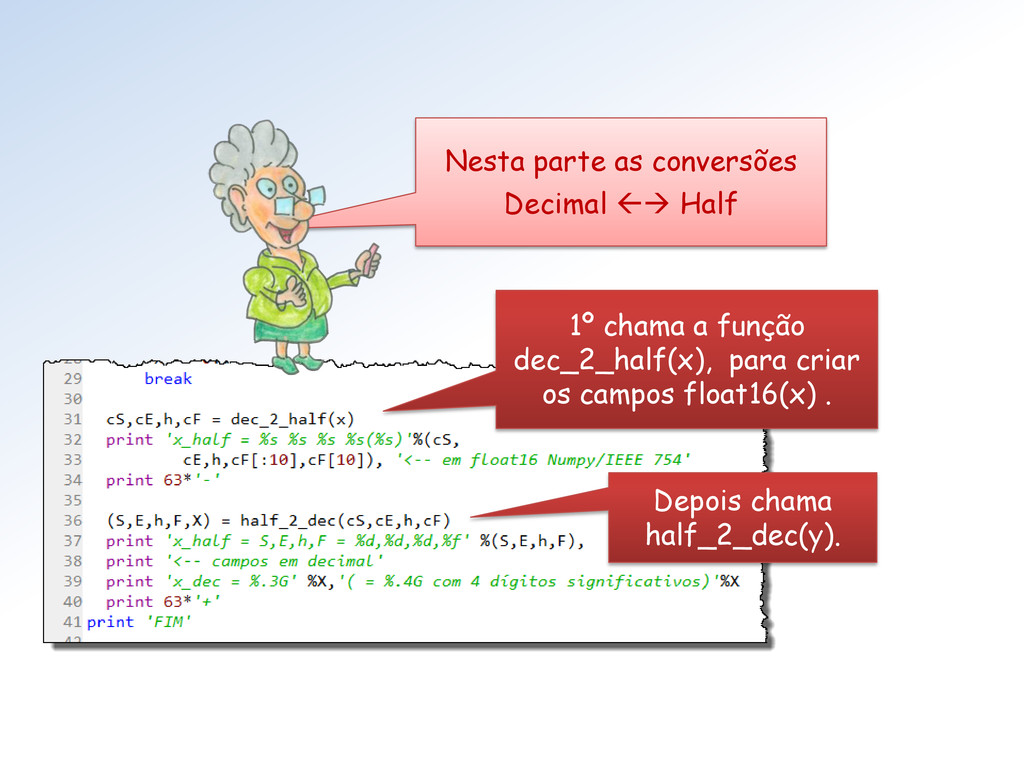
conv_dec_x_IEEE.py. Ela: • recebe um número decimal em ponto flutuante • e retorna sua representação binária em double do padrão IEEE 754/2008 Na próxima aula, mostraremos outras funções desse módulo.
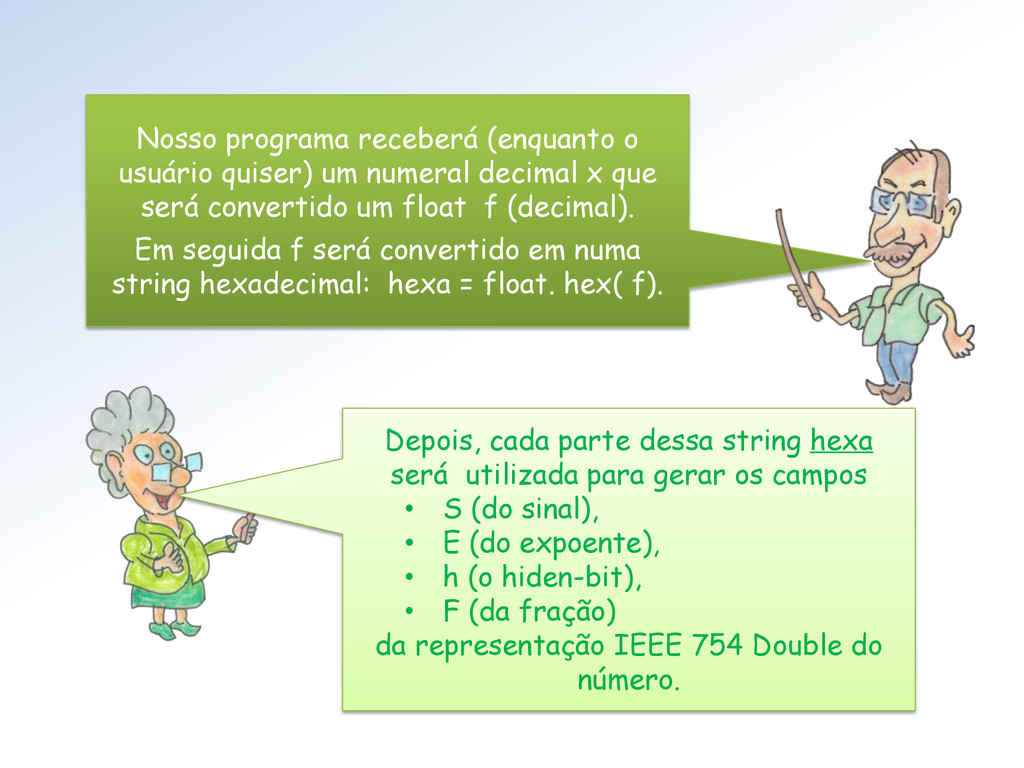
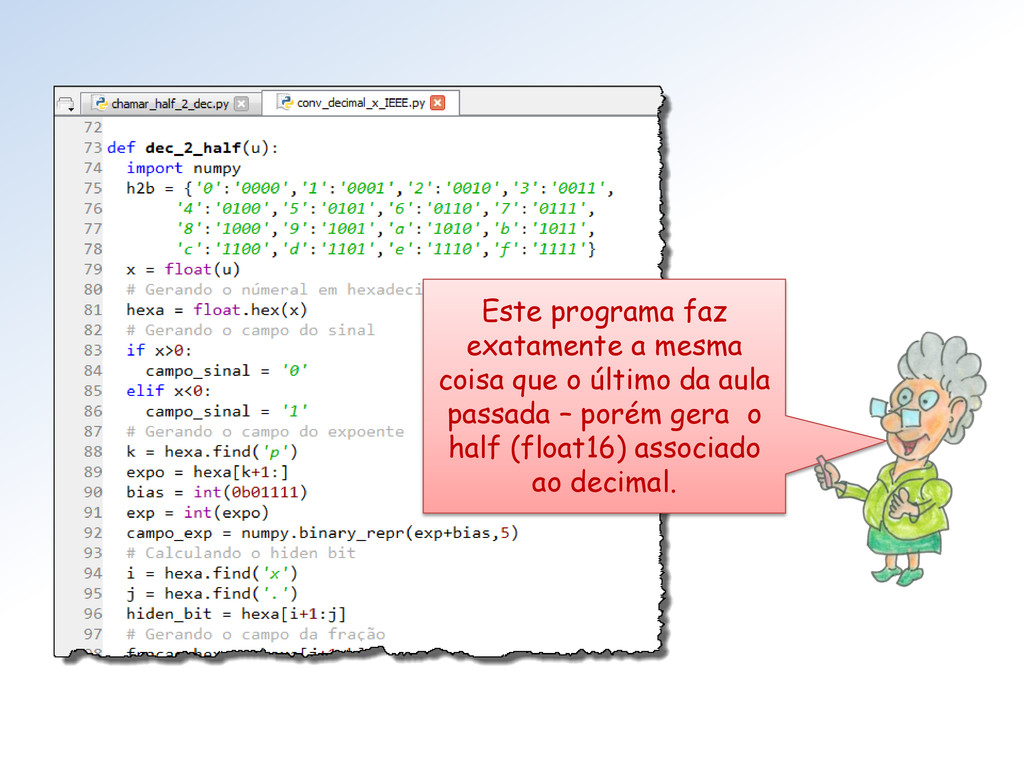
x que será convertido um float f (decimal). Em seguida f será convertido em numa string hexadecimal: hexa = float. hex( f). Depois, cada parte dessa string hexa será utilizada para gerar os campos • S (do sinal), • E (do expoente), • h (o hiden-bit), • F (da fração) da representação IEEE 754 Double do número.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}