linear = , conhecidos na literatura como métodos estacionários. Como desejamos achar uma “raiz” da equação vetorial () = 0, onde = − , procuraremos por pontos-fixo de alguma função linear = + obtida através de manipulação algébrica de ().
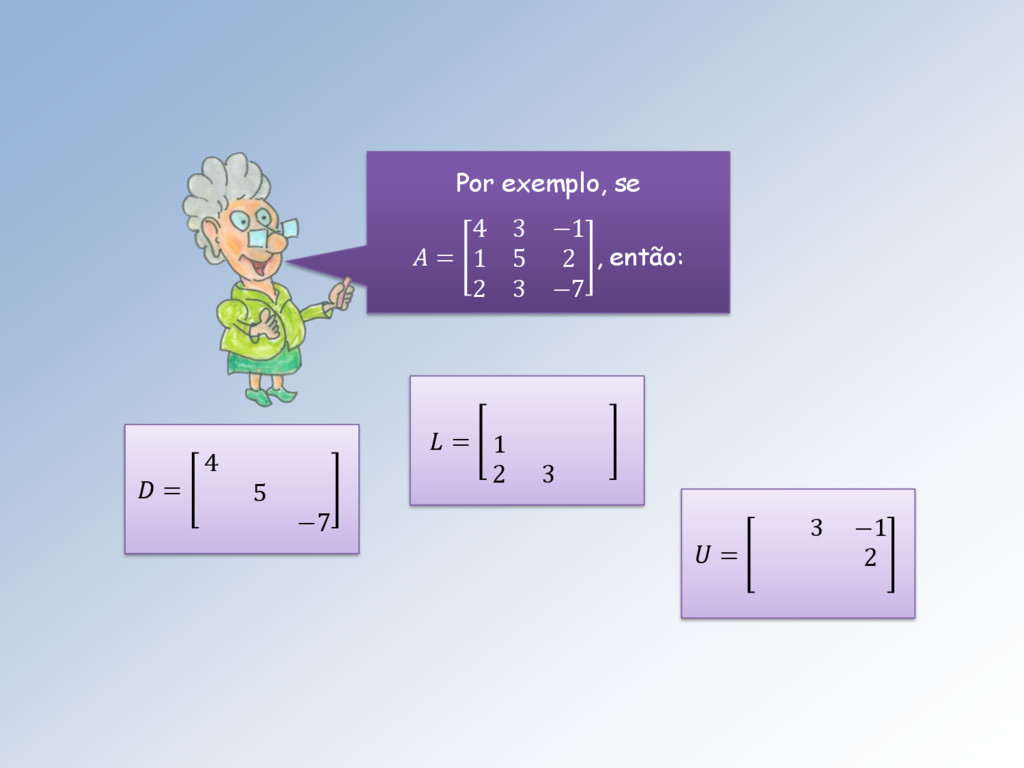
: ℝ → ℝ para os métodos de Jacobi, Gauss-Seidel e Gauss-Seidel com relaxação, usaremos a seguinte partição da matriz A: = + + onde: 1. é a diagonal da A, 2. L é a parte triangular inferior de A, abaixo da diagonal, 3. U é a parte triangular superior de A, acima da diagonal.
convergentes, então: • = + = −1 − + + • = + = + −1 − + Uma continha direta fornece que esse limite satisfaz: = . Em outras palavras, é solução do sistema linear!
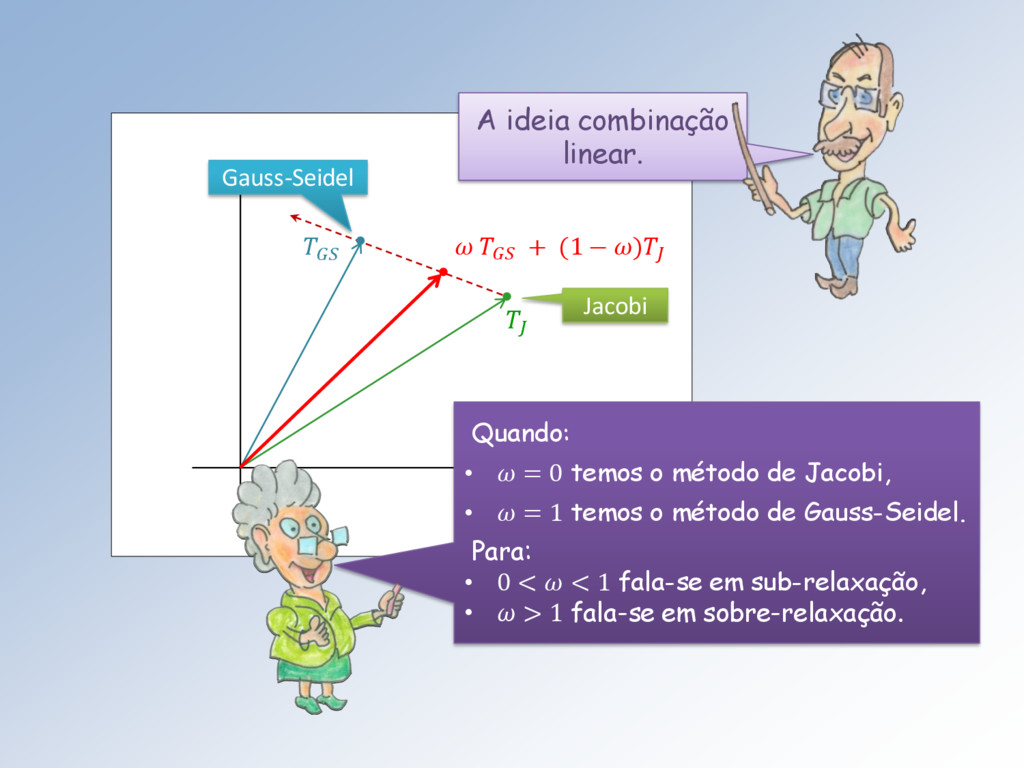
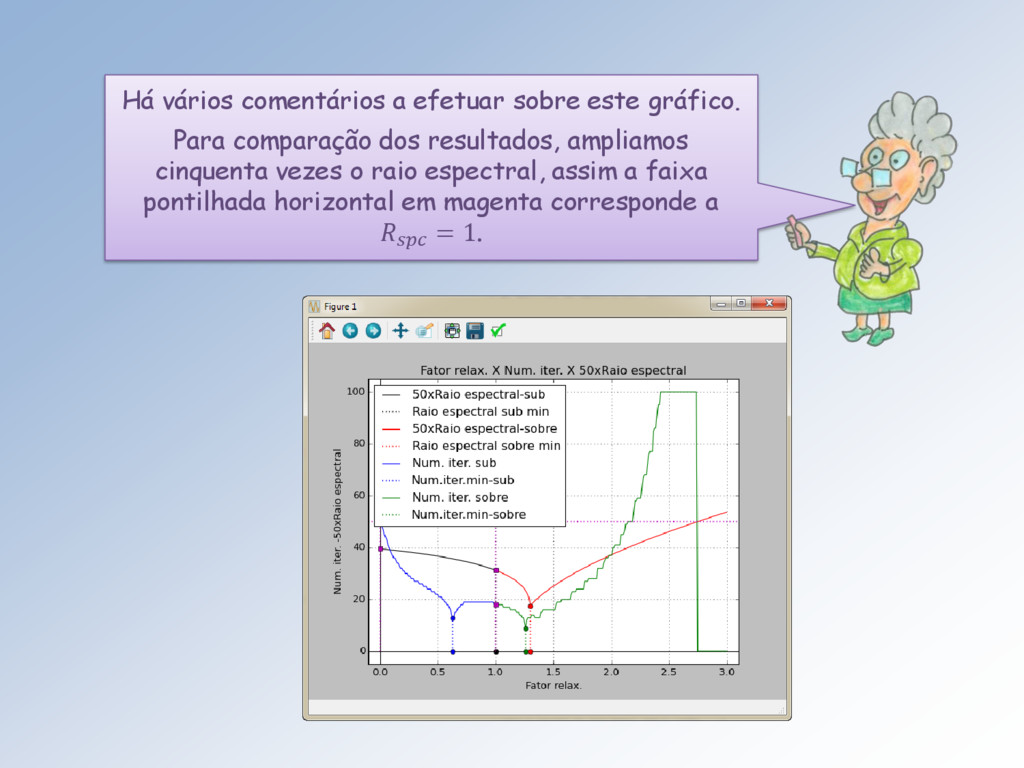
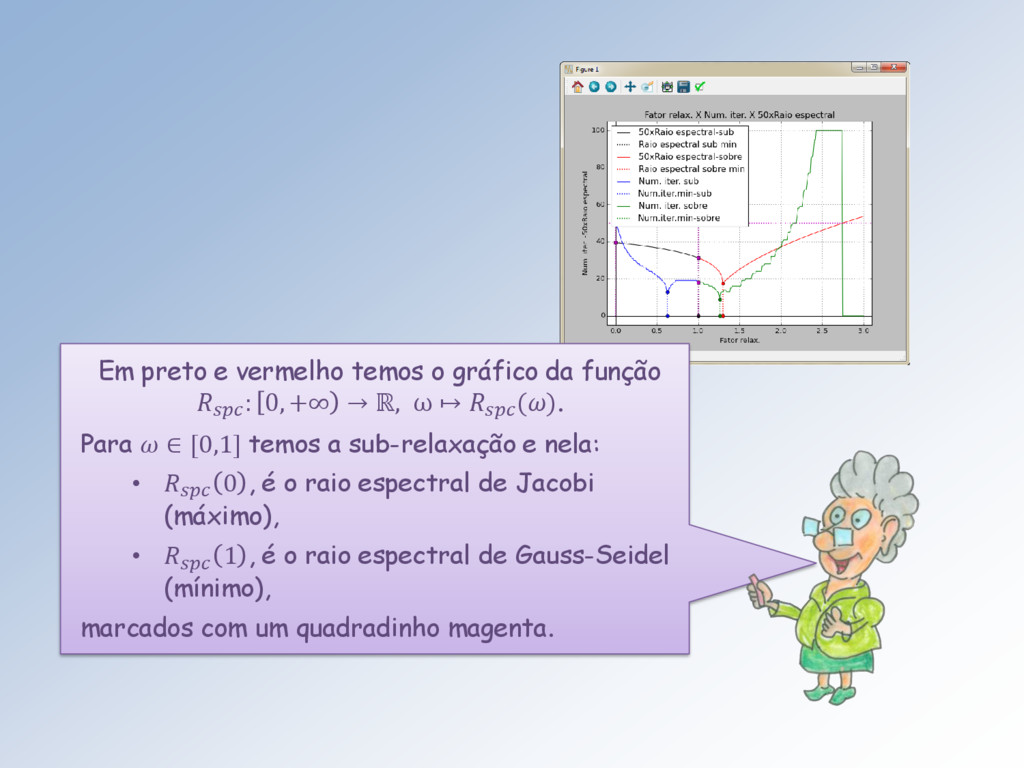
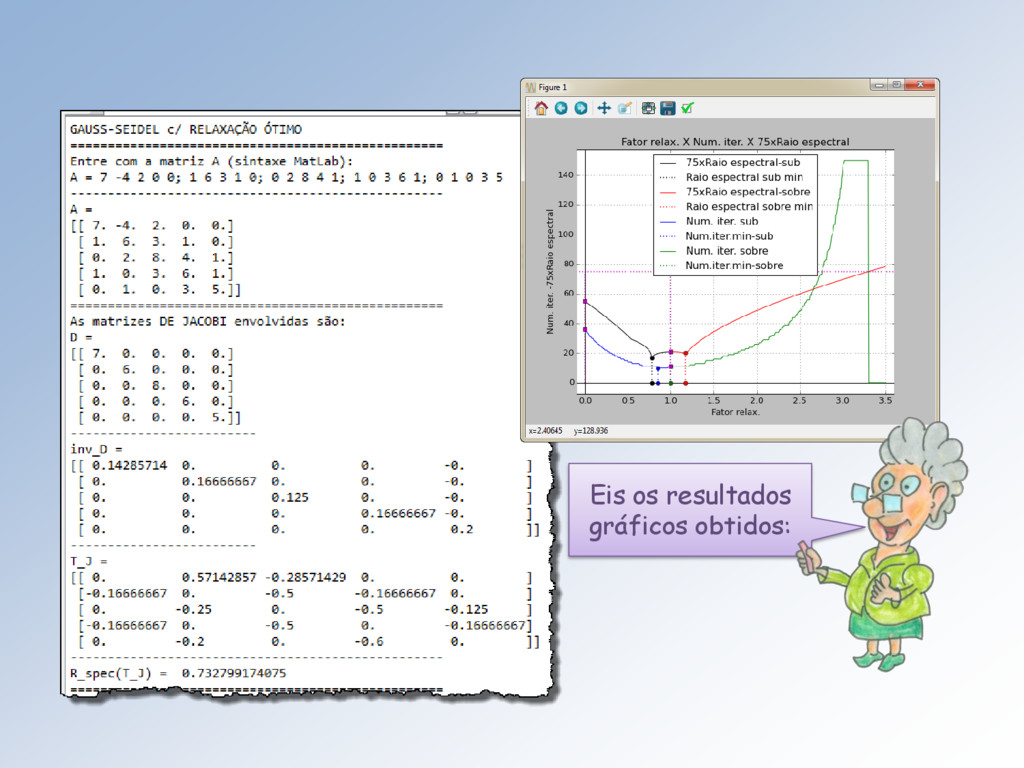
0, +∞ → ℝ, ω ↦ (). Para ∈ [0,1] temos a sub-relaxação e nela: • 0 , é o raio espectral de Jacobi (máximo), • 1 , é o raio espectral de Gauss-Seidel (mínimo), marcados com um quadradinho magenta.
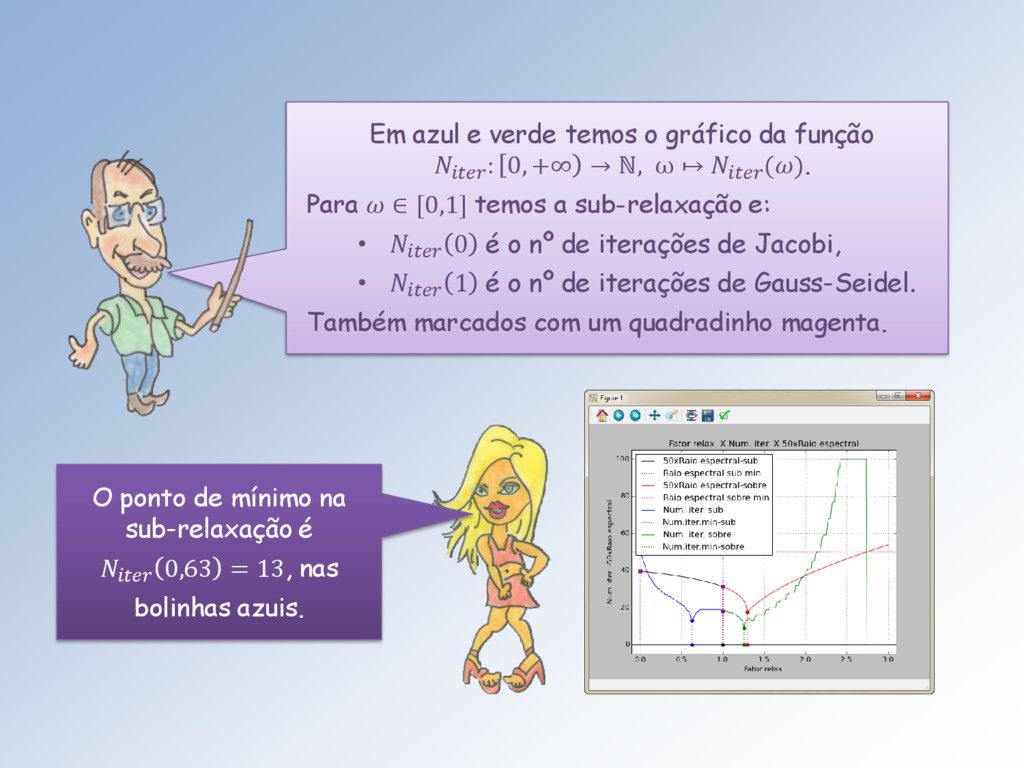
0, +∞ → ℕ, ω ↦ (). Para ∈ [0,1] temos a sub-relaxação e: • 0 é o nº de iterações de Jacobi, • 1 é o nº de iterações de Gauss-Seidel. Também marcados com um quadradinho magenta. O ponto de mínimo na sub-relaxação é 0,63 = 13, nas bolinhas azuis.
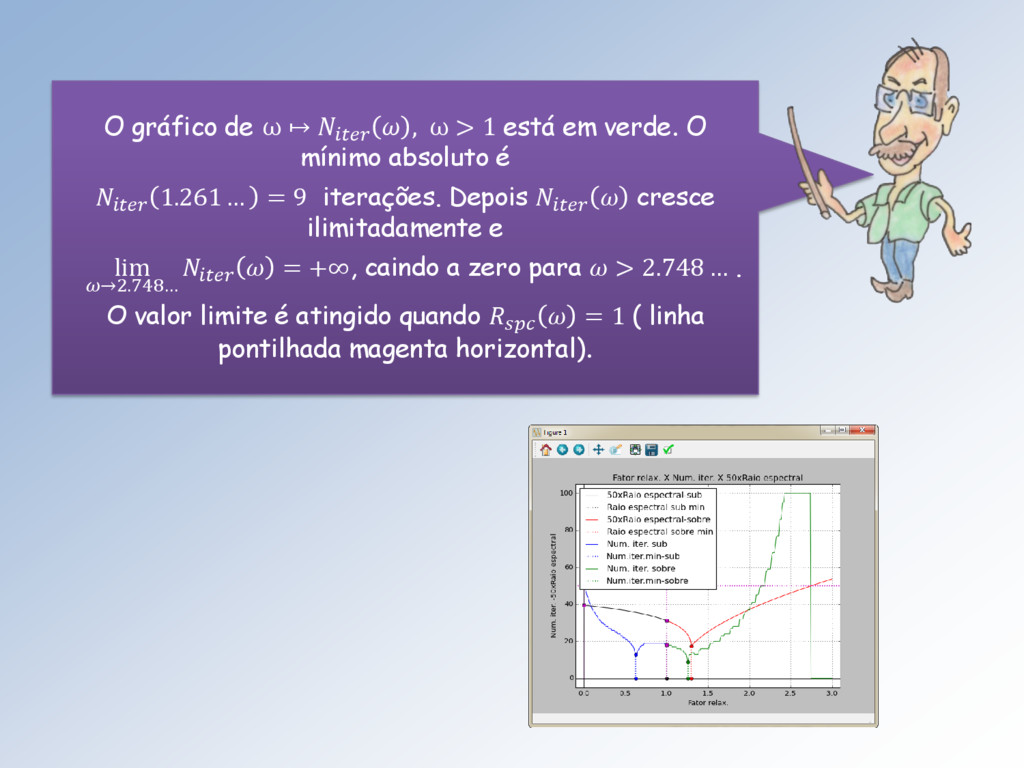
em verde. O mínimo absoluto é 1.261… = 9 iterações. Depois cresce ilimitadamente e lim →2.748… = +∞, caindo a zero para > 2.748 … . O valor limite é atingido quando = 1 ( linha pontilhada magenta horizontal).
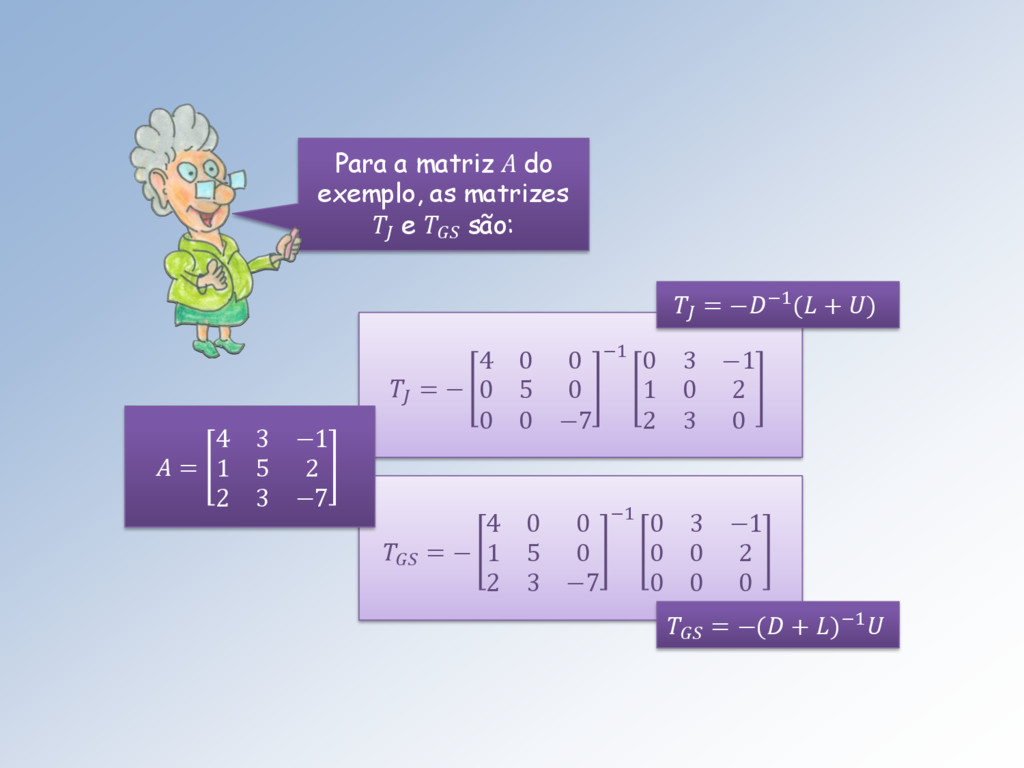
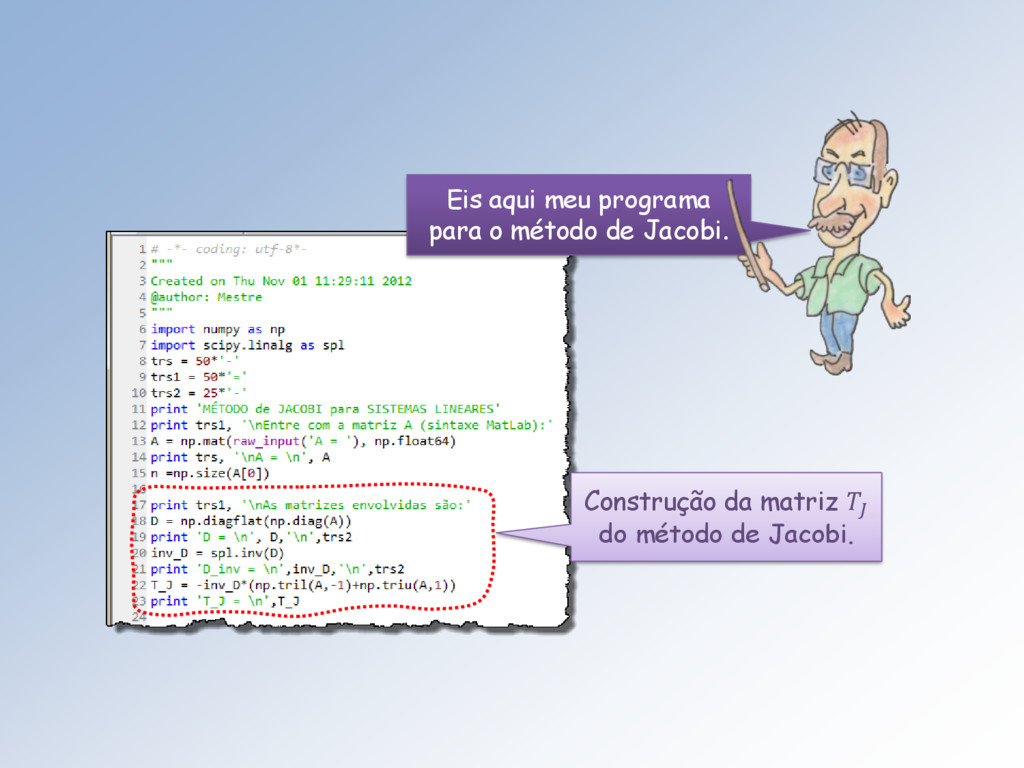
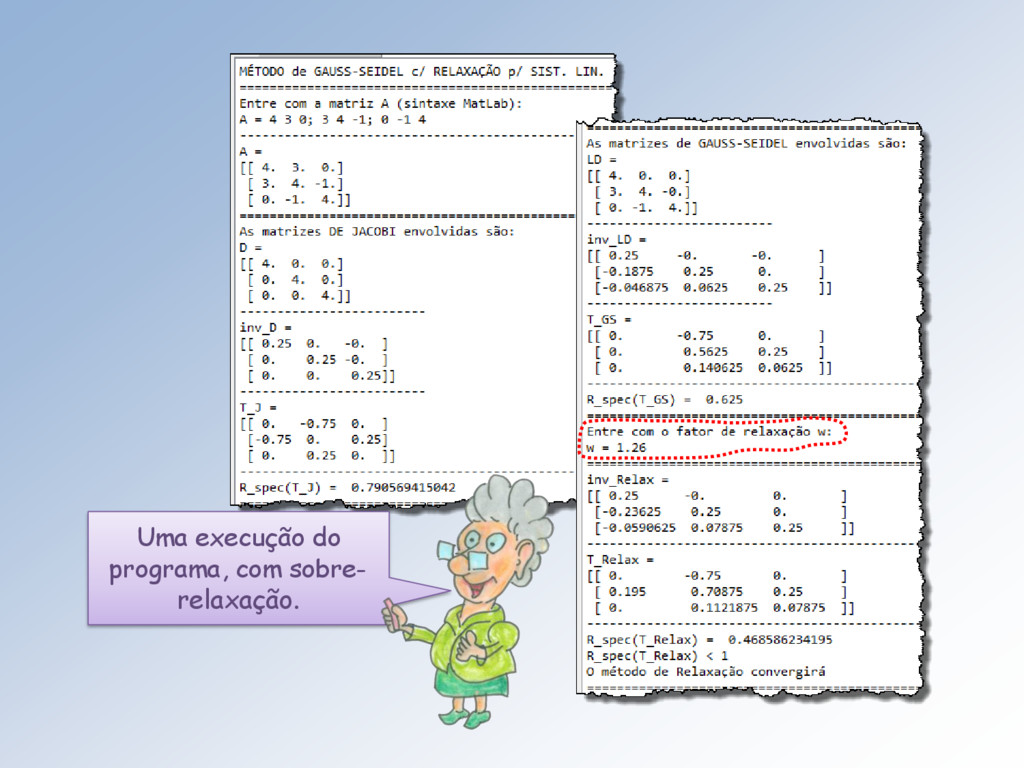
+ 21 1 + 12 2 + a22 2 + 13 3 + 23 3 + ⋯ + 1 = 1 + 2 = 2 ⋮ 1 1 + 2 2 + 2 2 + ⋯ + = Lembro que no método de: • Jacobi a matriz T é definida por = −−1( + ) e o vetor c por = −1. • Gauss-Seidel a matriz T é definida por = − −1 e o vetor c por = ( − )−1.
= , a igualdade +1 = −1 − + + se escreve, para cada linha = 1, … , : +1 = 1 =1, ≠ ( − ) . Esta fórmula pode ser obtida seguindo o algoritmo descrito na próxima transparência.
1, … , ): =1 = 2. Em cada equação, separe os termos da diagonal: + =1,≠ = , 3. Passe os termos do somatório para o segundo membro e divida tudo por , obtendo: = ൘ − =1,≠ , 4. Imponha que os do lado esquerdo dessa igualdade sejam os elementos +1 vetor +1 e os do lado direito os elementos do vetor e pronto: = ൘ − =1,≠ .
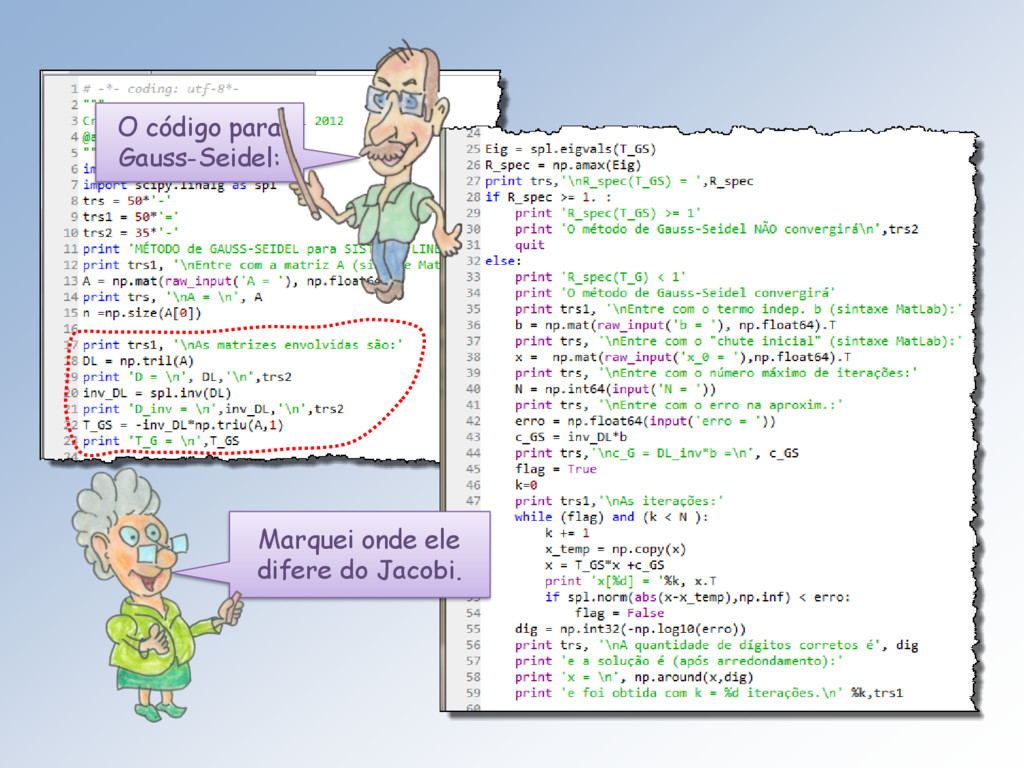
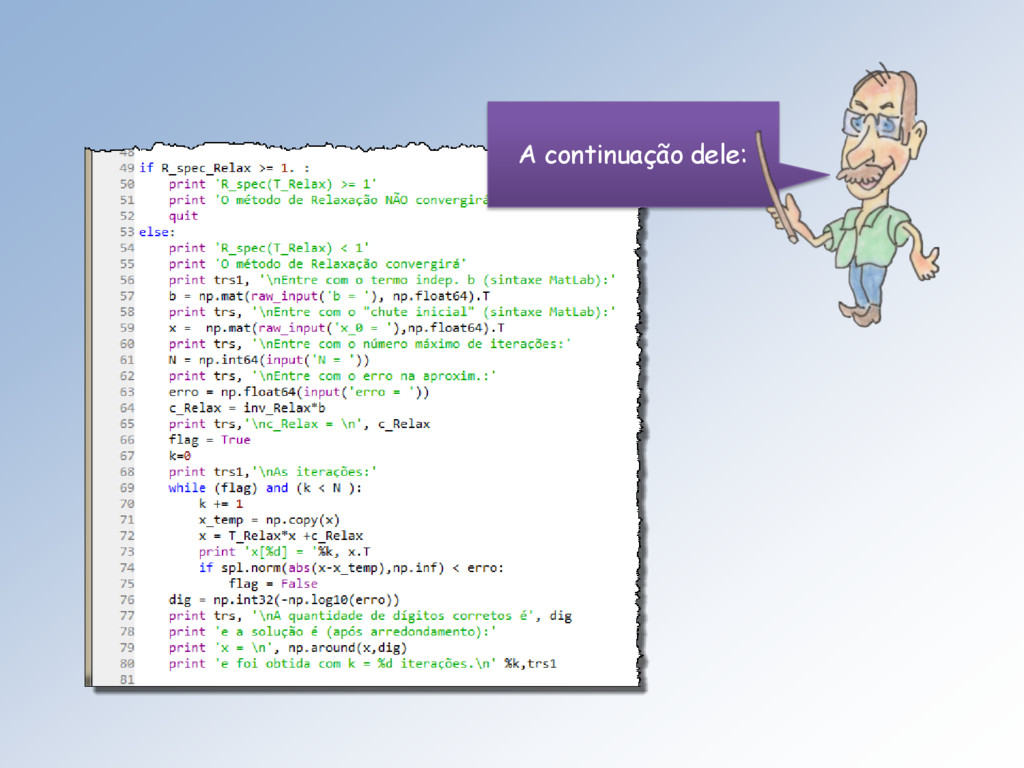
)−1 − + se rescreve + +1 = − + que, em termos das equações do sistema = , é ≥ +1 = − < , = 1, … , . Esta fórmula pode ser obtida seguindo o algoritmo descrito na próxima transparência.
1, … , ): =1 = 2. Em cada equação, separe os termos da diagonal: ≥ + < = , 3. Passe os termos do 2º somatório para o segundo membro: ≥ = − < , 4. Imponha que os do lado esquerdo dessa igualdade sejam os elementos +1 vetor +1 e os do lado direito os elementos do vetor e pronto: ≥ +1 = − < . Continua
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}