This presents a real-world case study of how the Earnin Payroll frontend team adopted an agentic AI development workflow — powered by Claude Code, Cursor, and a suite of Model Context Protocol (MCP) integrations — to fundamentally reshape how frontend engineers plan, build, review, and ship features across a production NX monorepo.
The Problem: Modern frontend development demands constant context-switching — reading Jira tickets for requirements, translating Figma designs into components, writing Storybook stories for visual regression, coordinating with backend teams on Slack, creating PRs on GitHub, and managing cross-repo dependencies in a micro-frontend architecture. Each tool lives in its own silo, and developers spend significant time bridging the gaps between them.
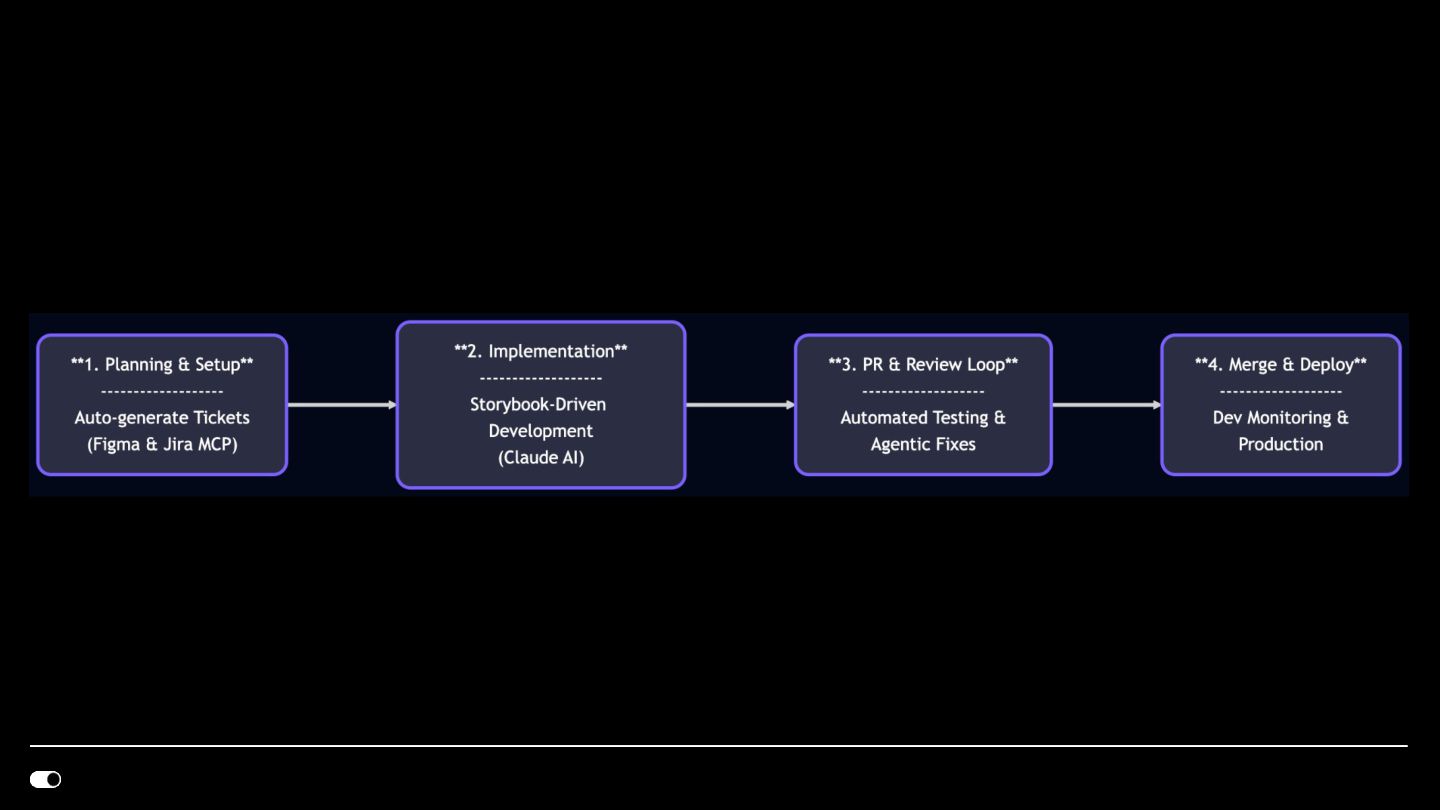
Our Approach: We built an interconnected agentic workflow where AI agents operate across the full development lifecycle through MCP server integrations:
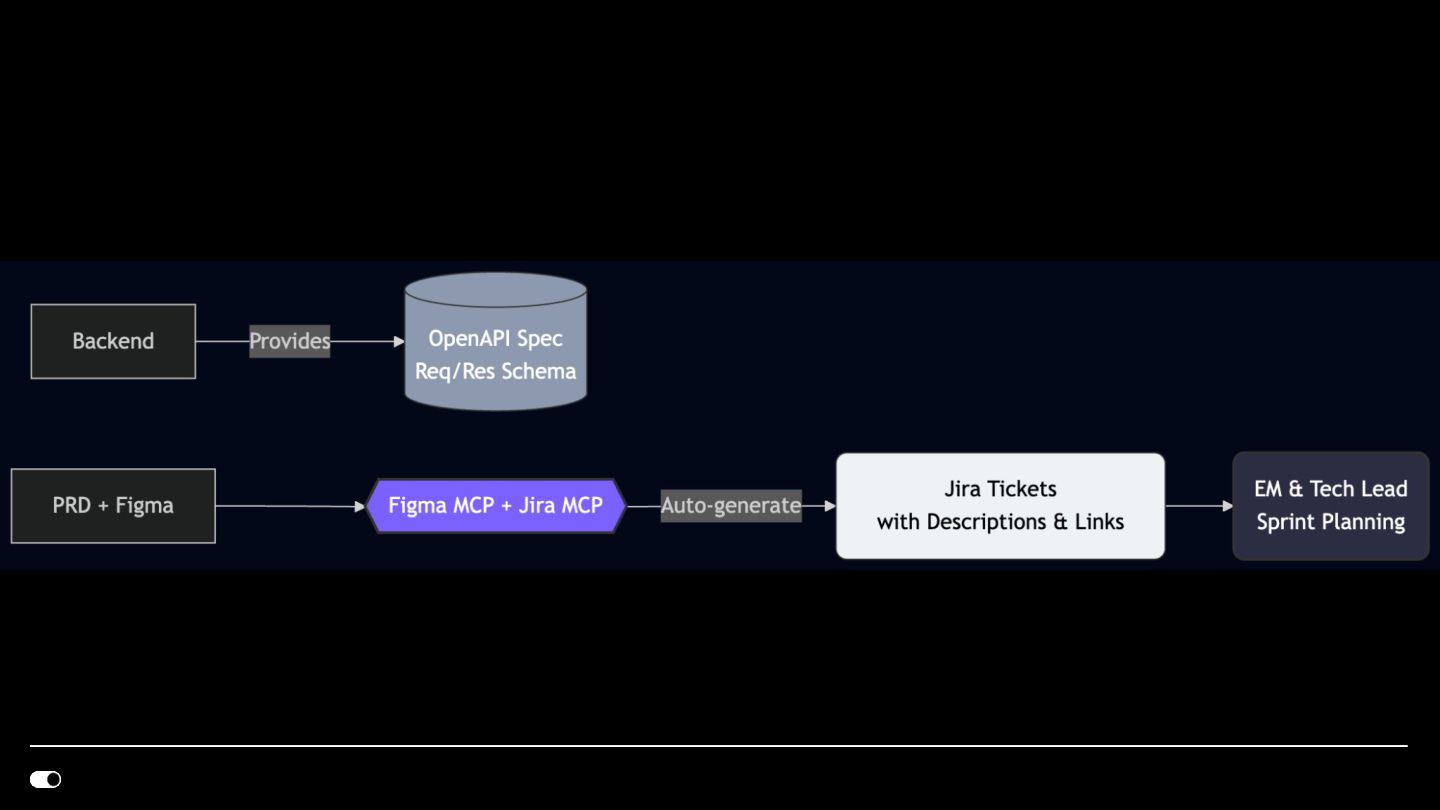
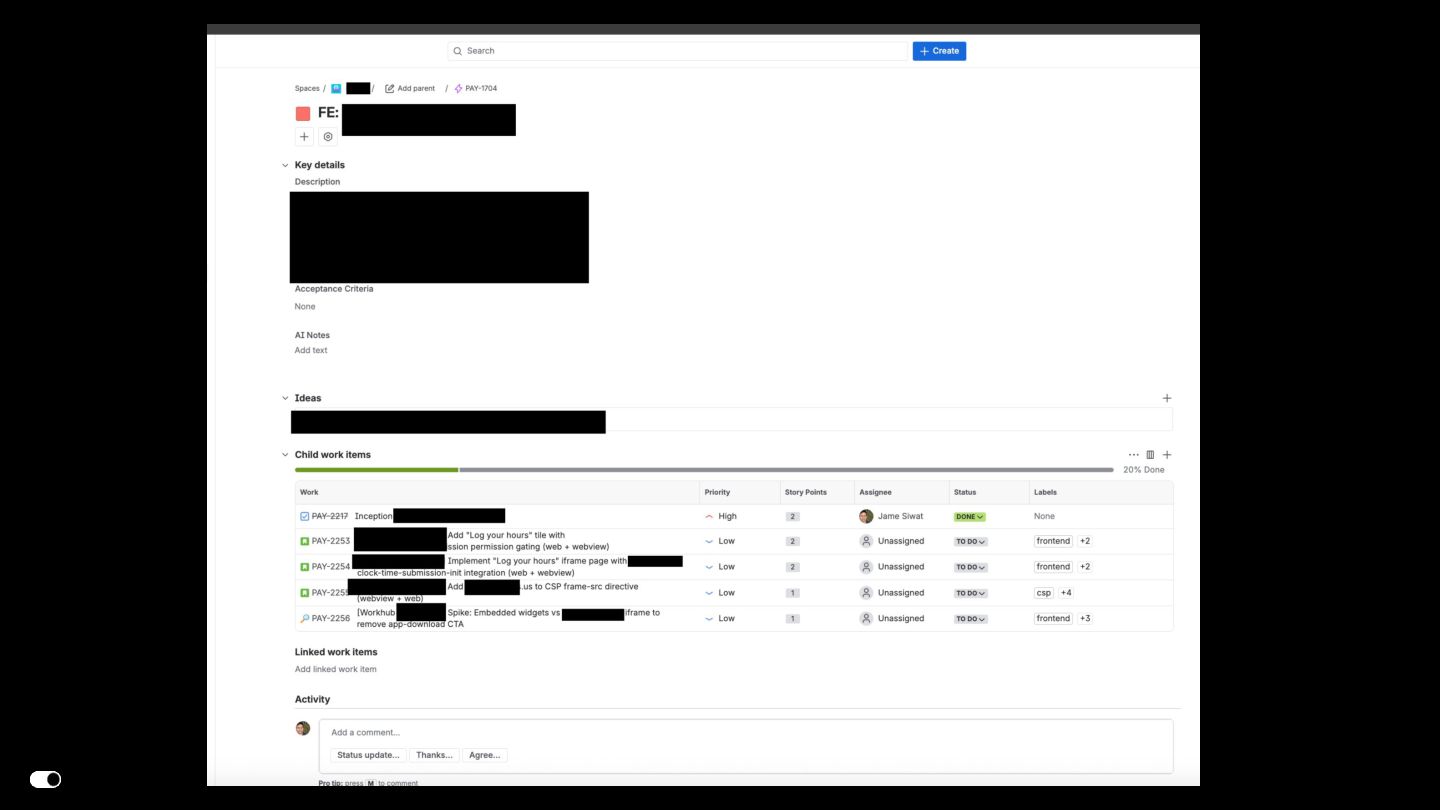
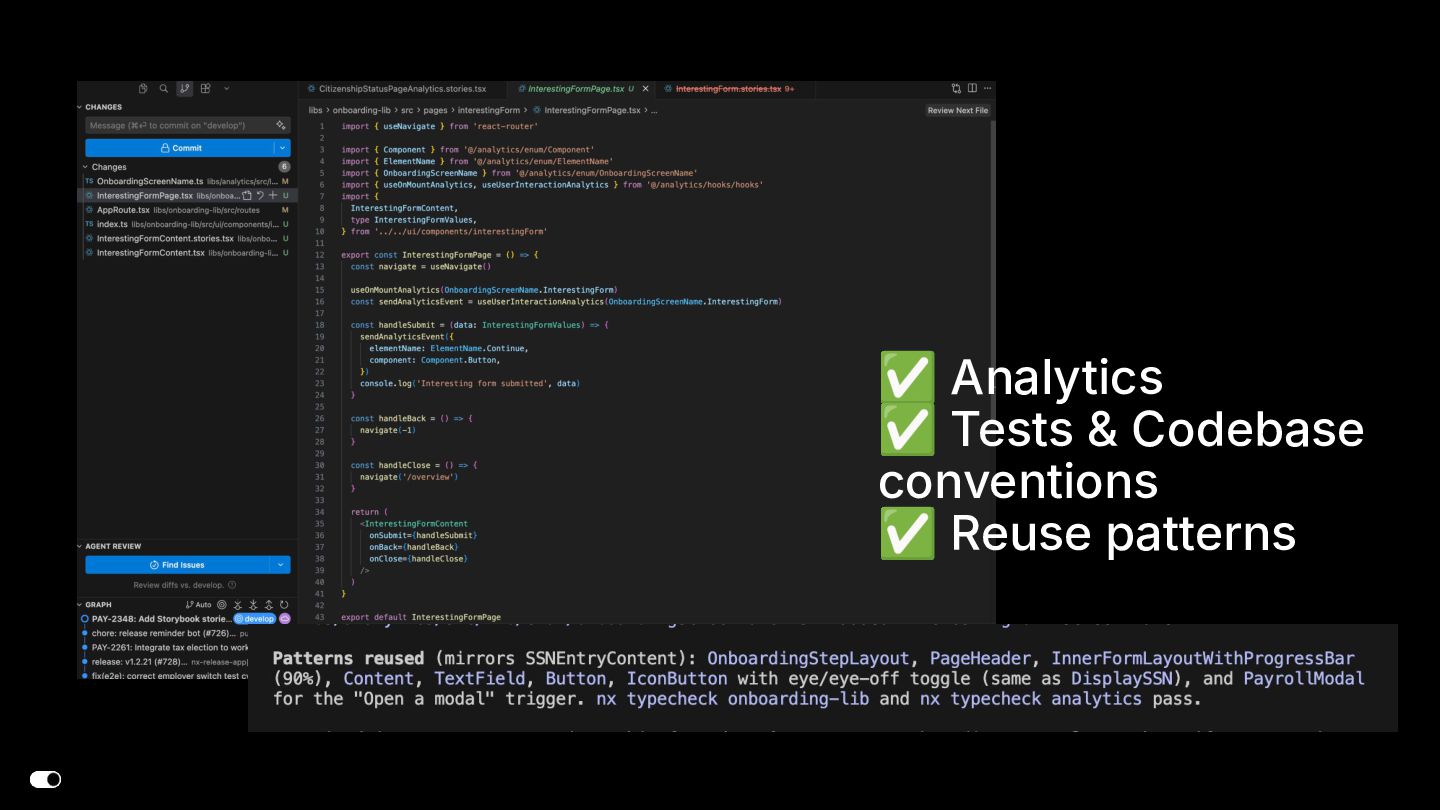
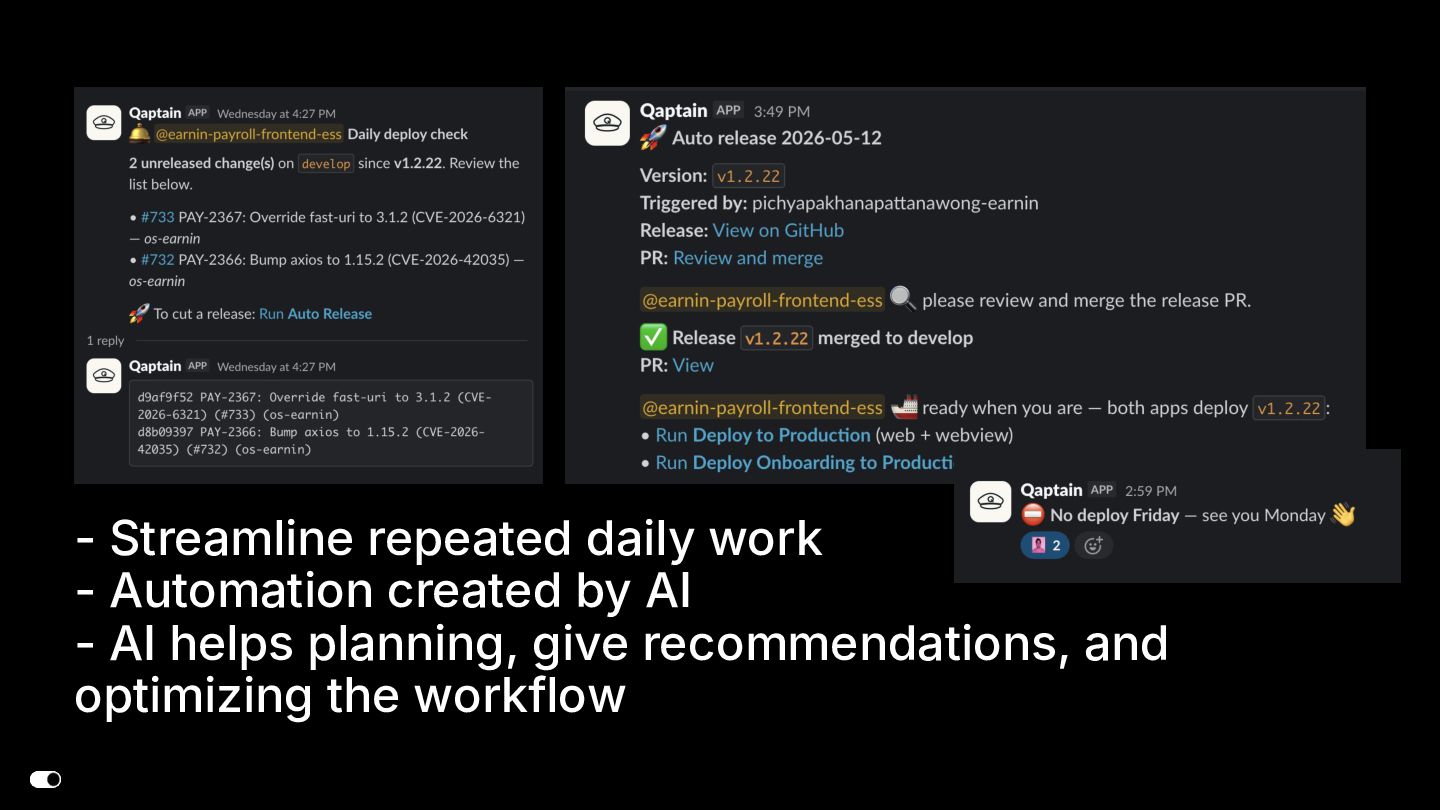
- Jira MCP — Agents read ticket requirements, create bug tickets from Slack conversations, and automatically reply in Slack threads with ticket links, keeping traceability without manual effort.
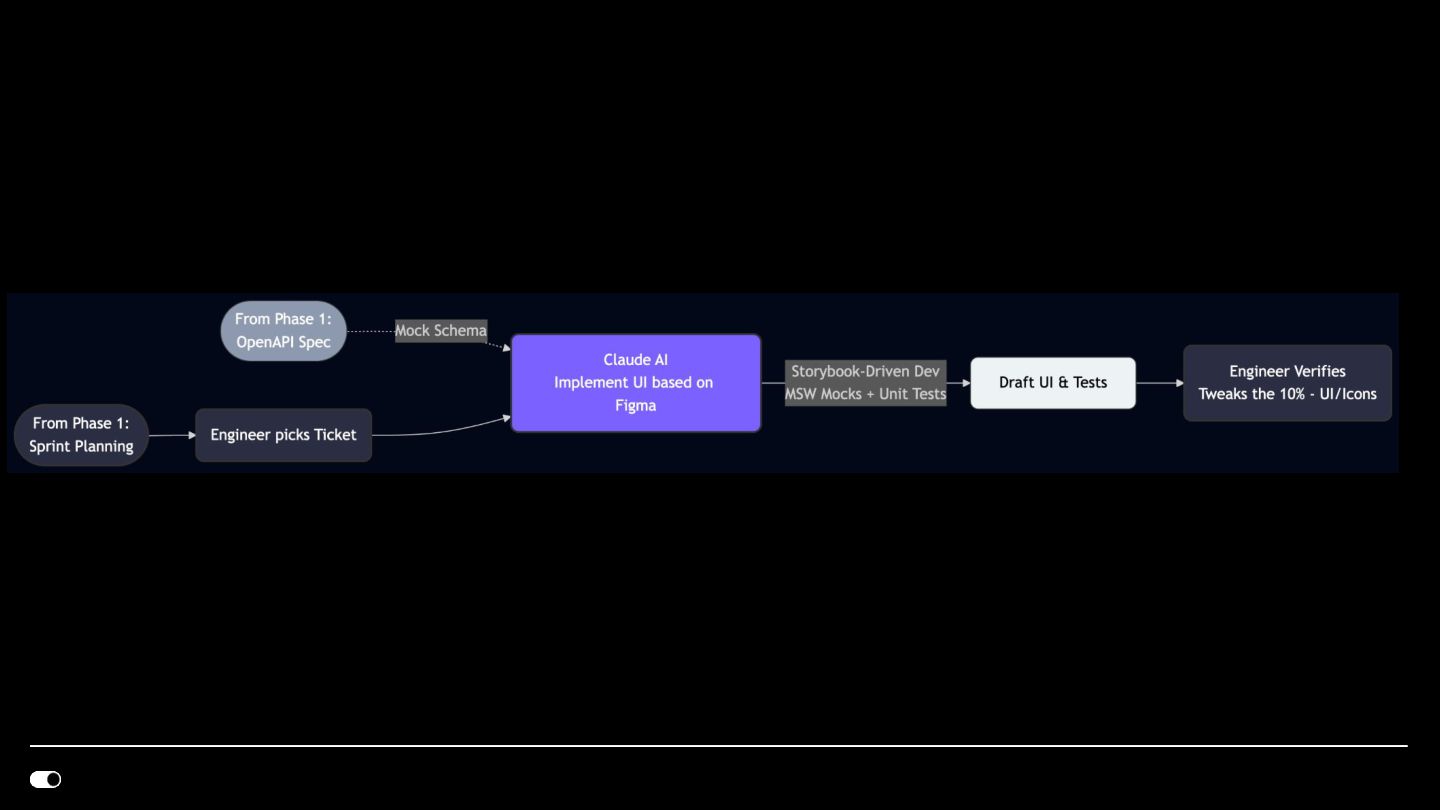
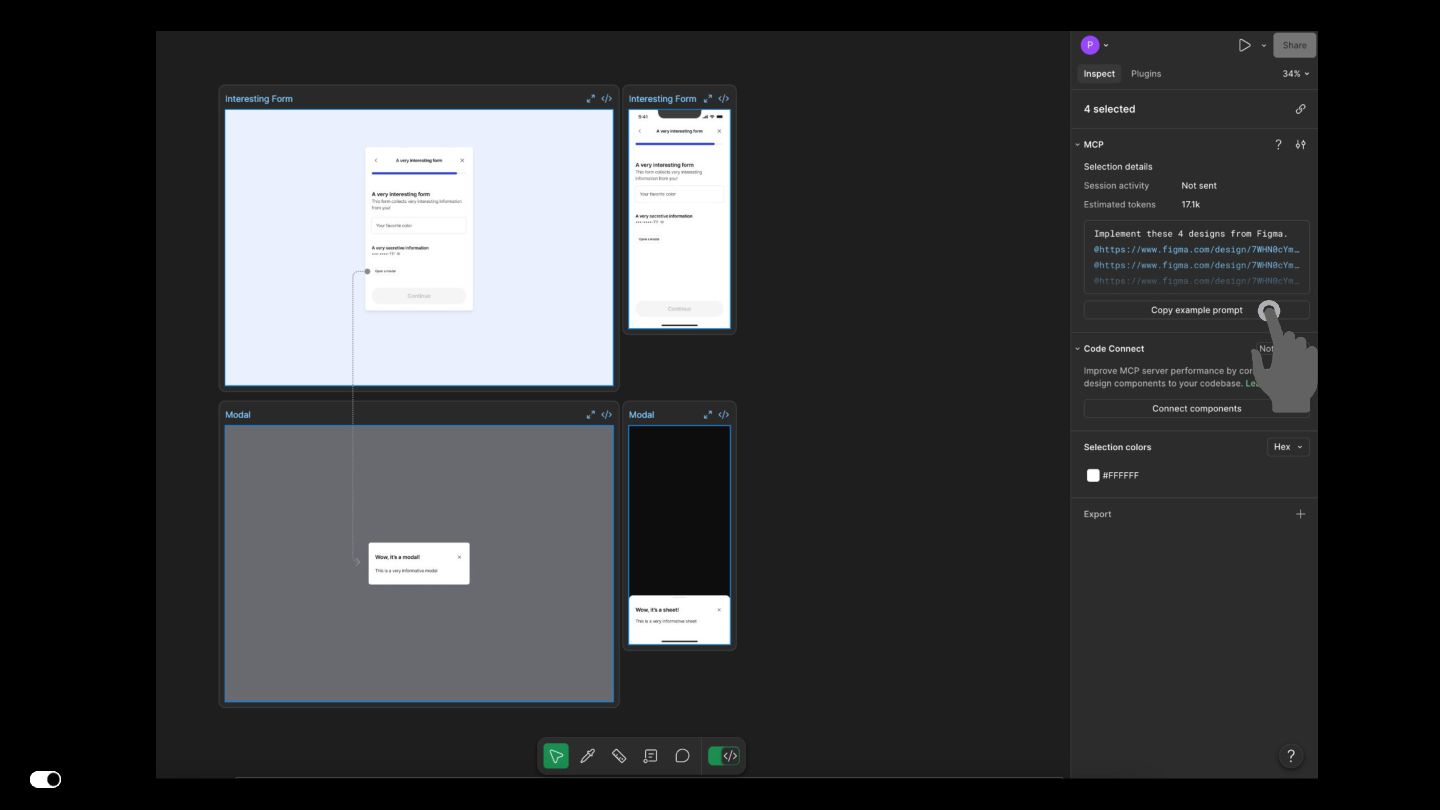
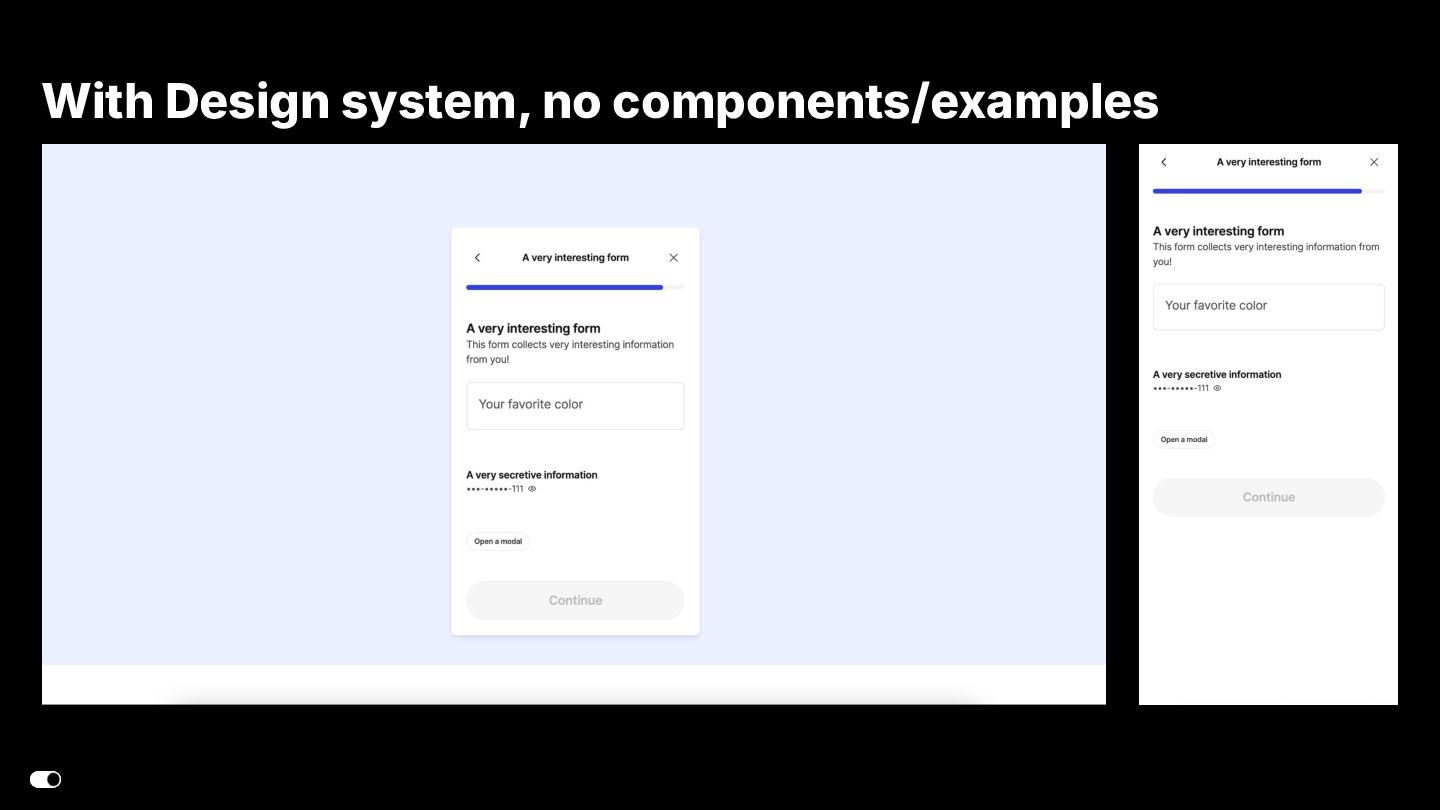
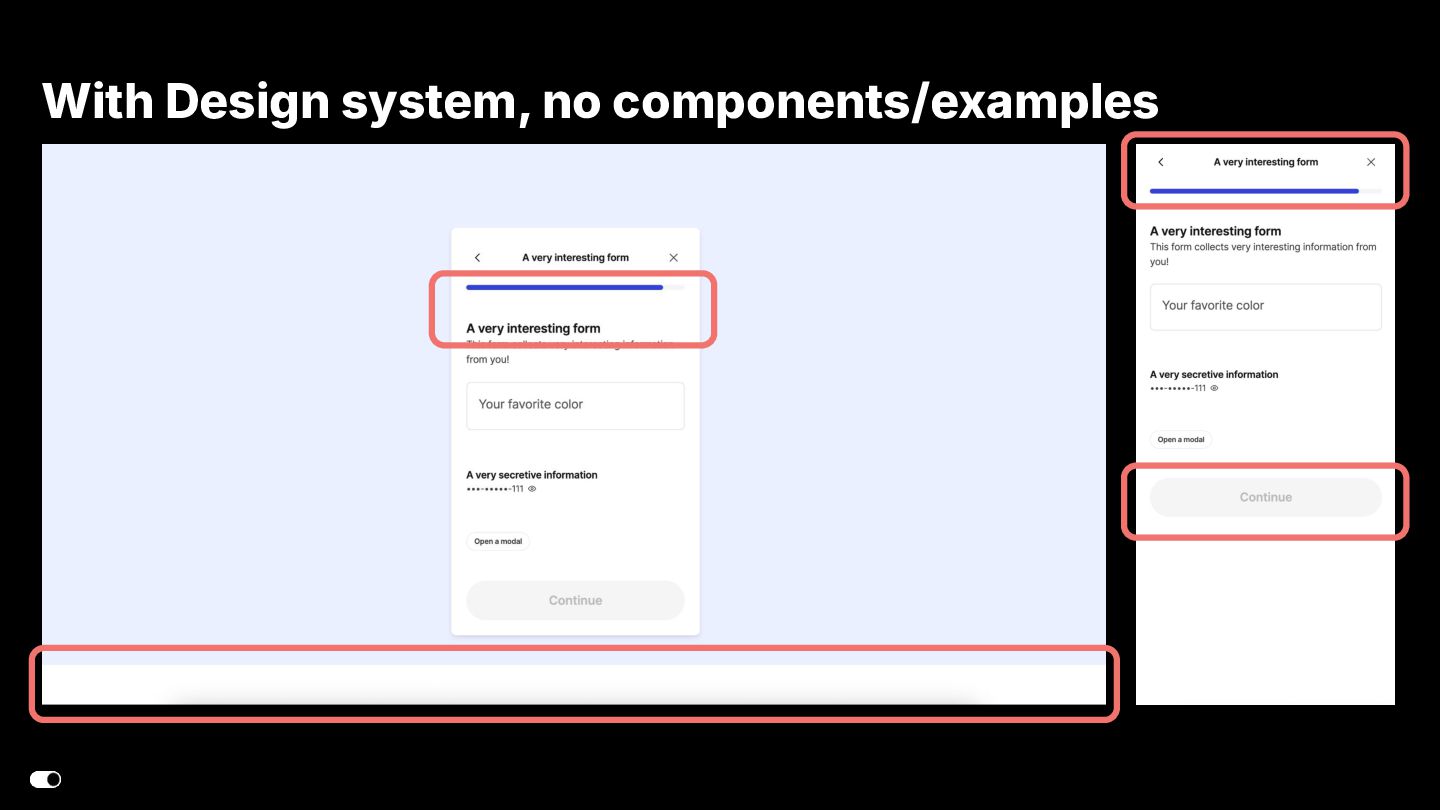
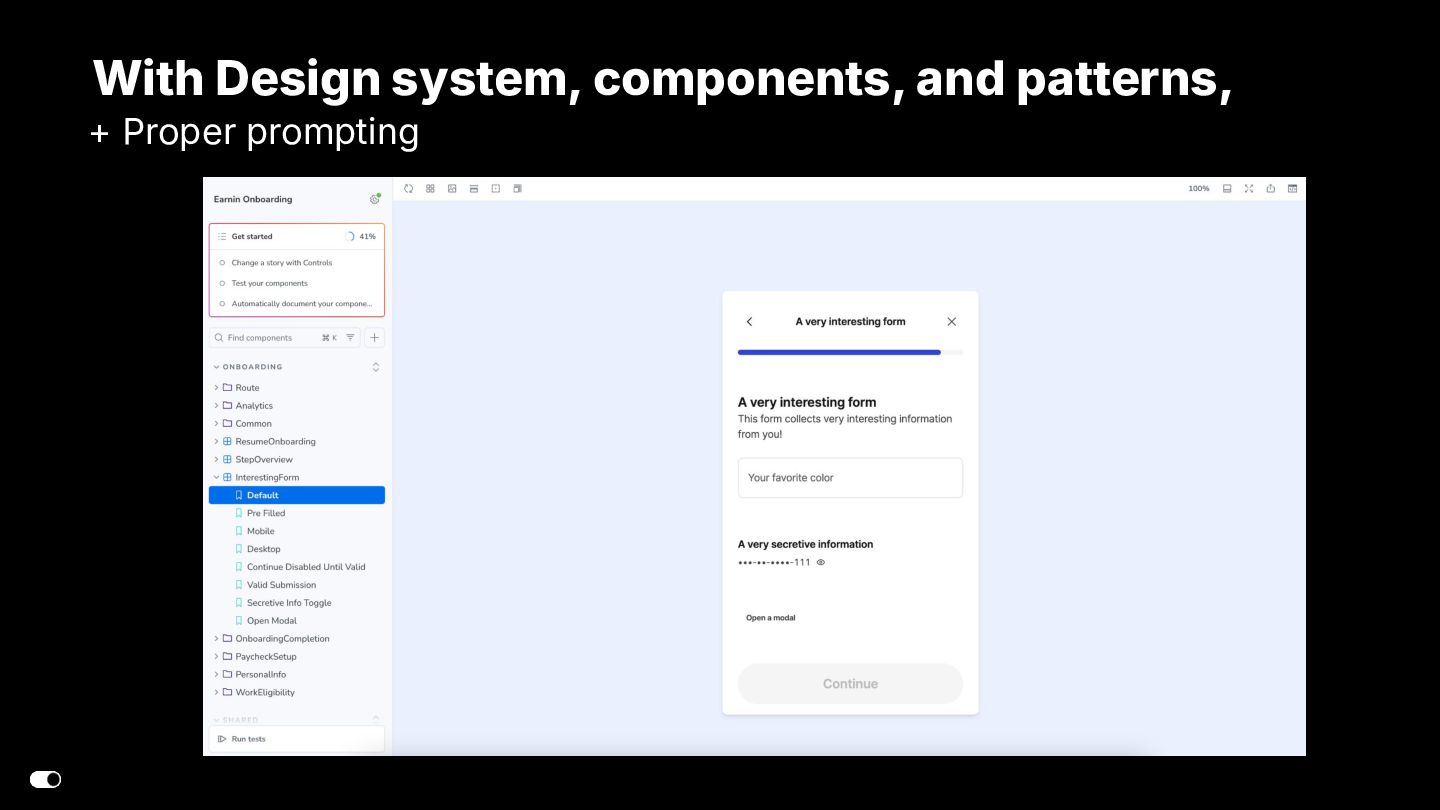
- Figma MCP — Design-to-code translation where agents consume Figma components directly and generate implementation aligned with our design system library.
- Slack MCP — Agents draft team communications with the right formatting conventions (threaded messages, channel routing for PR reviews vs. casual discussions), propose replies for human approval, and tag the right team members — all without leaving the coding context.
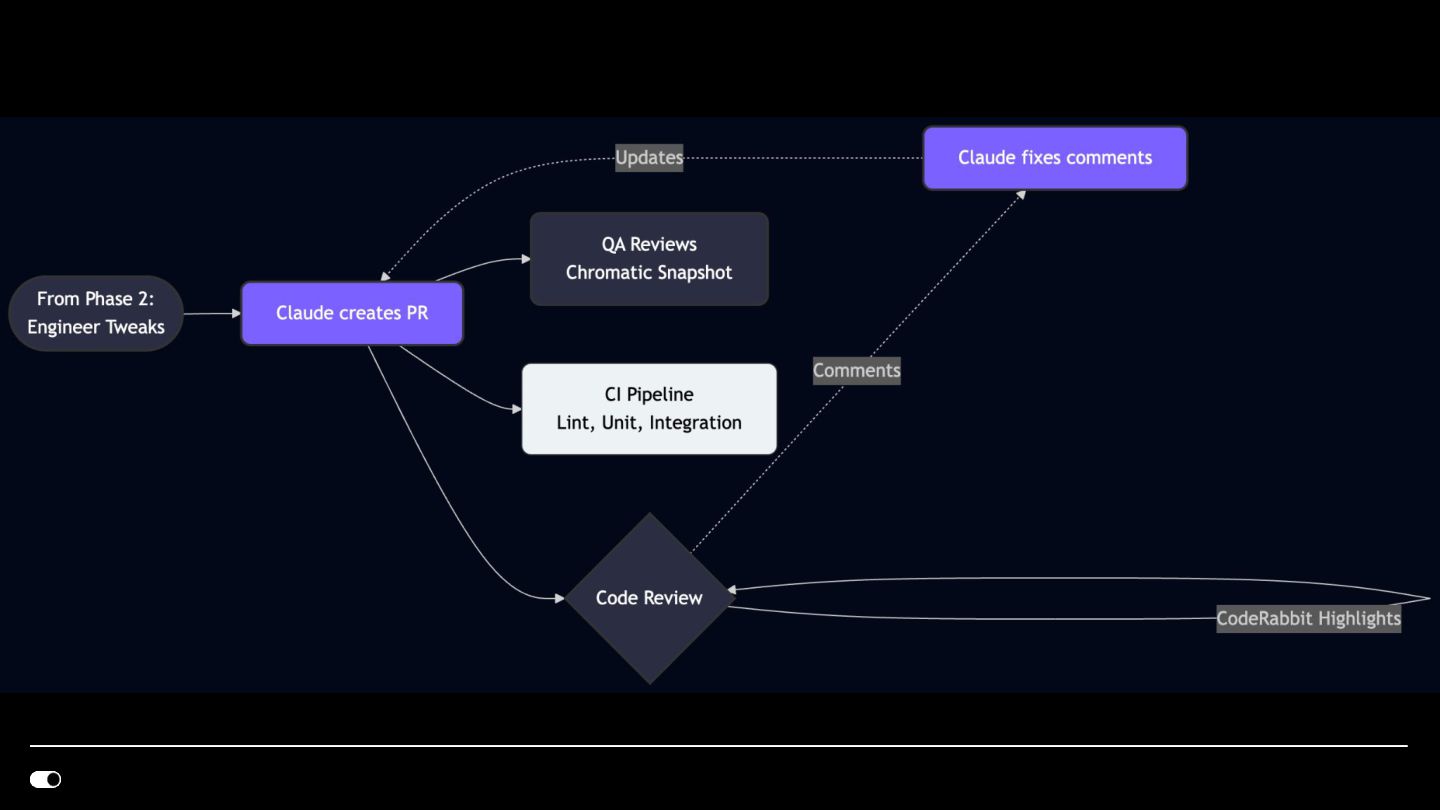
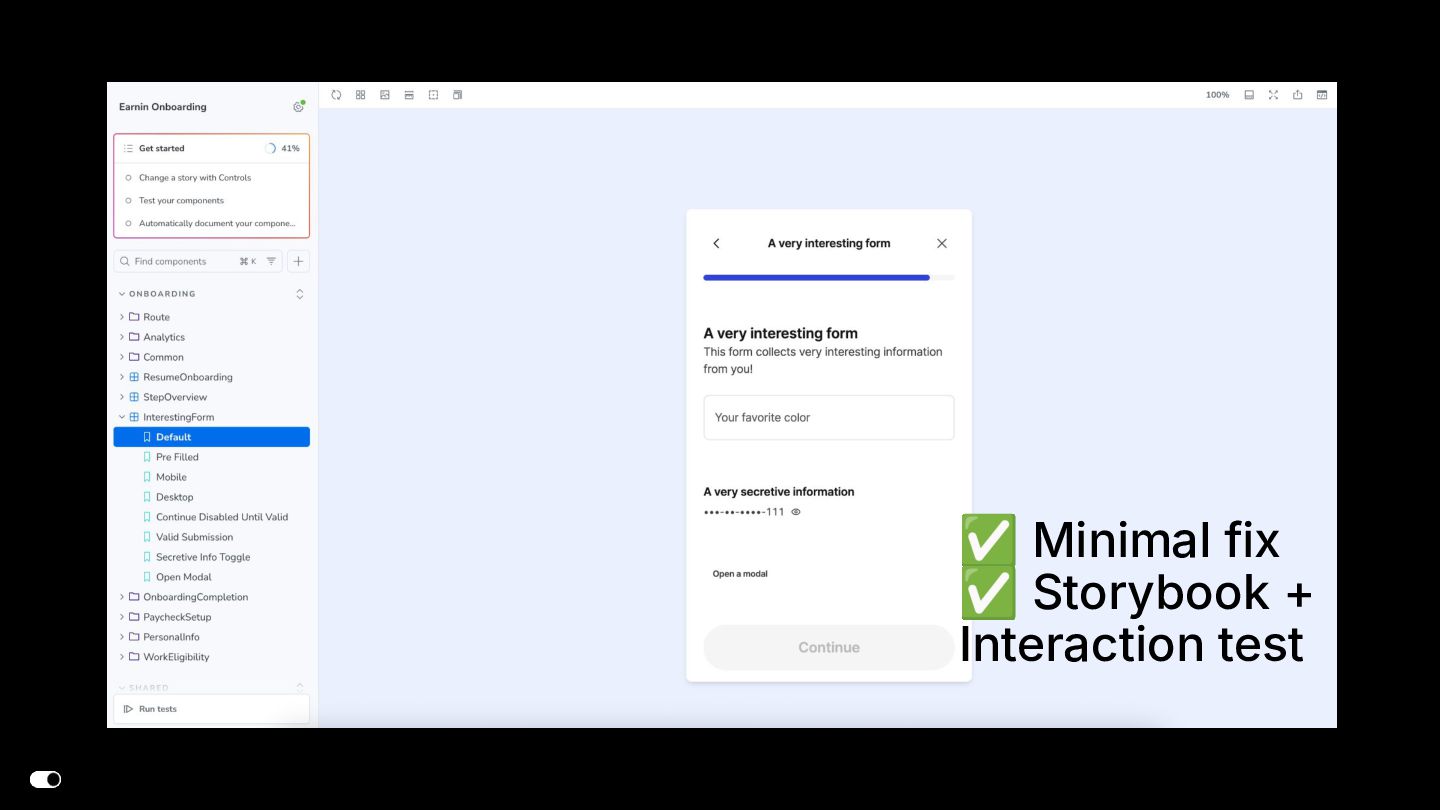
- Storybook MCP — Agents generate stories with proper Chromatic snapshot configuration, automatically disabling snapshots for interaction-only or visually duplicate stories to reduce CI cost and noise.
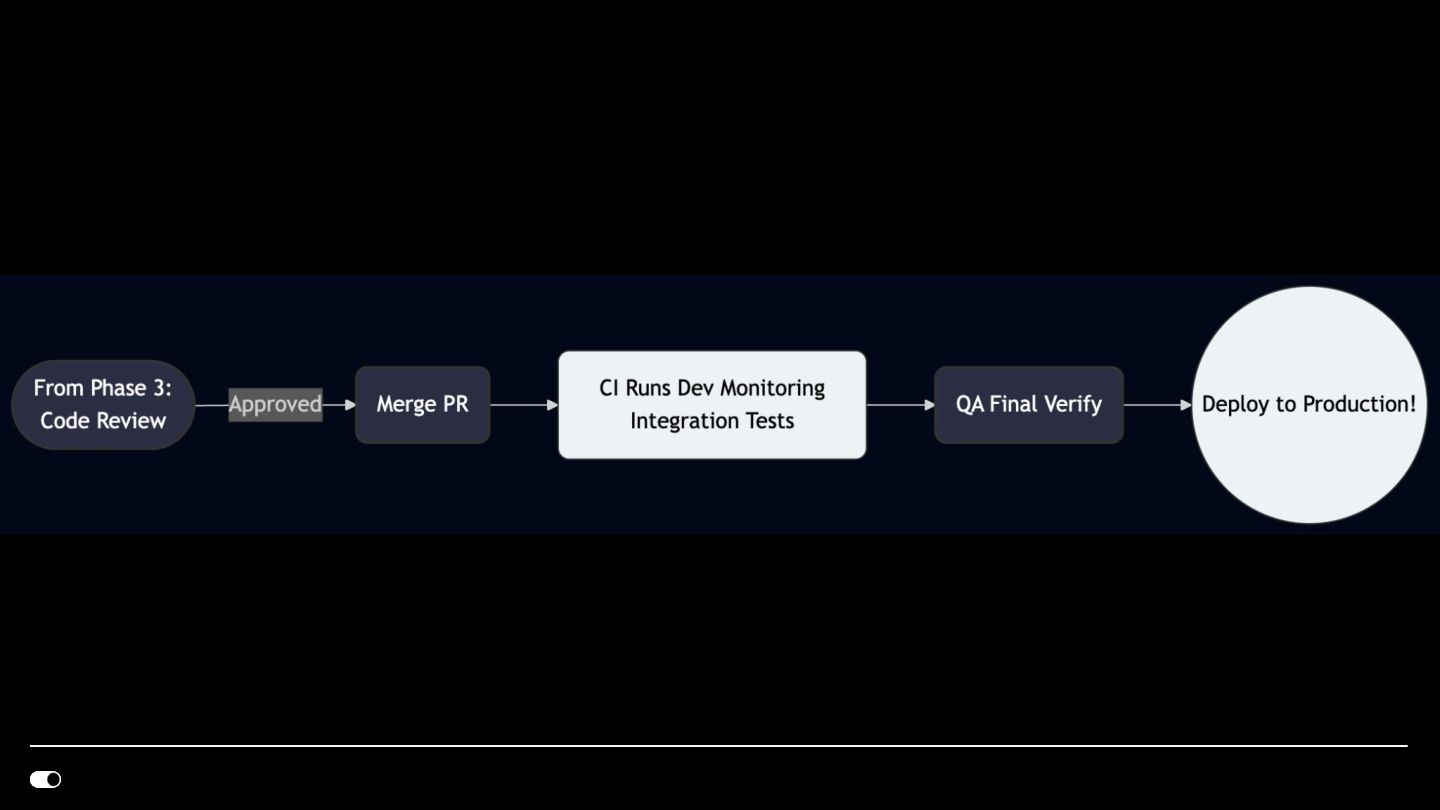
- GitHub CLI — Automated PR creation with conventional commit messages, branch management, and code review workflows integrated into the agent loop.
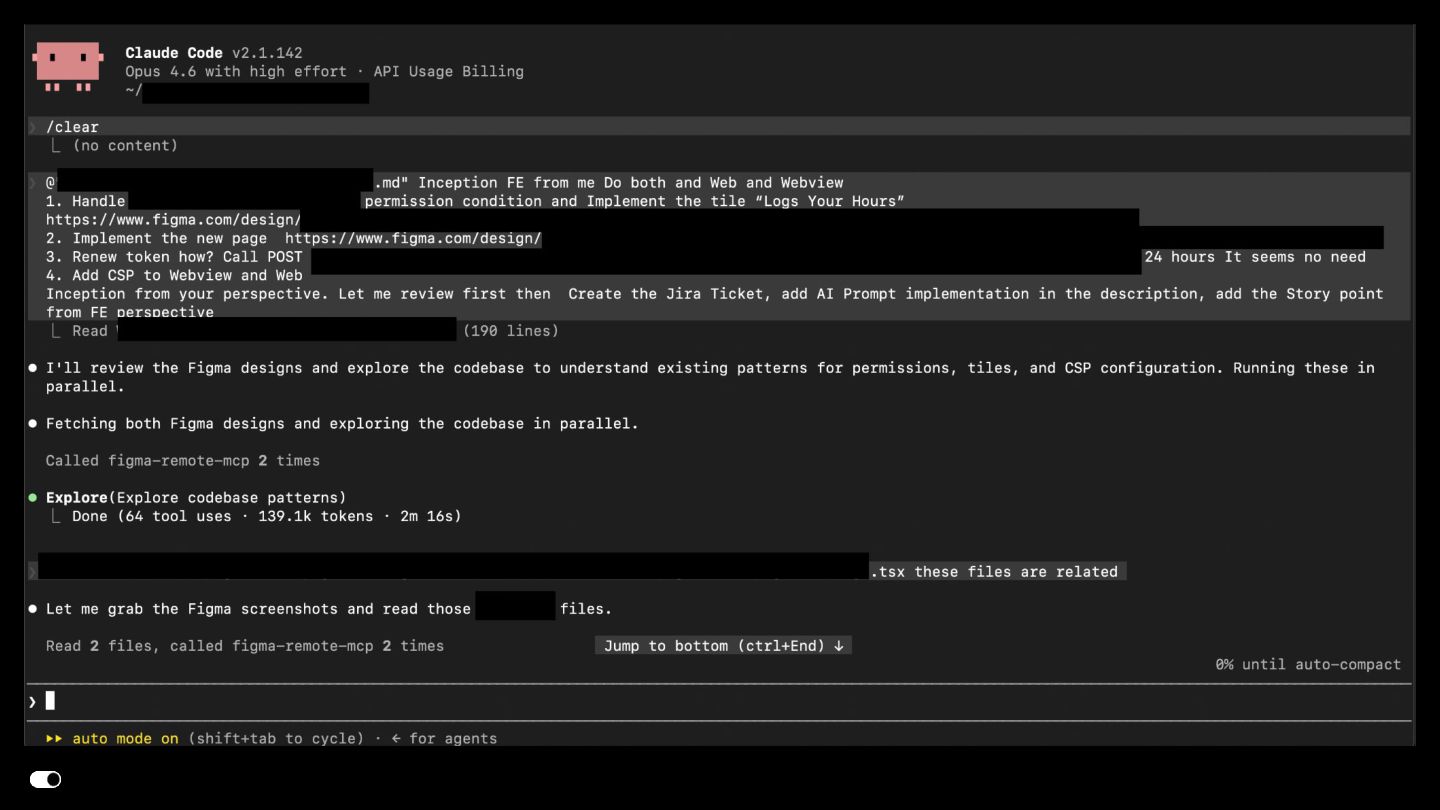
- Claude Code — The orchestration layer that ties everything together. Multi-agent dispatch for parallel ticket work (e.g., researching the codebase once, then fanning out parallel agents for independent Jira tickets). Persistent memory for team preferences, project context, and architectural decisions that carry acrossg documentation that guides agent behavior withinlibrary boundaries and import conventions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
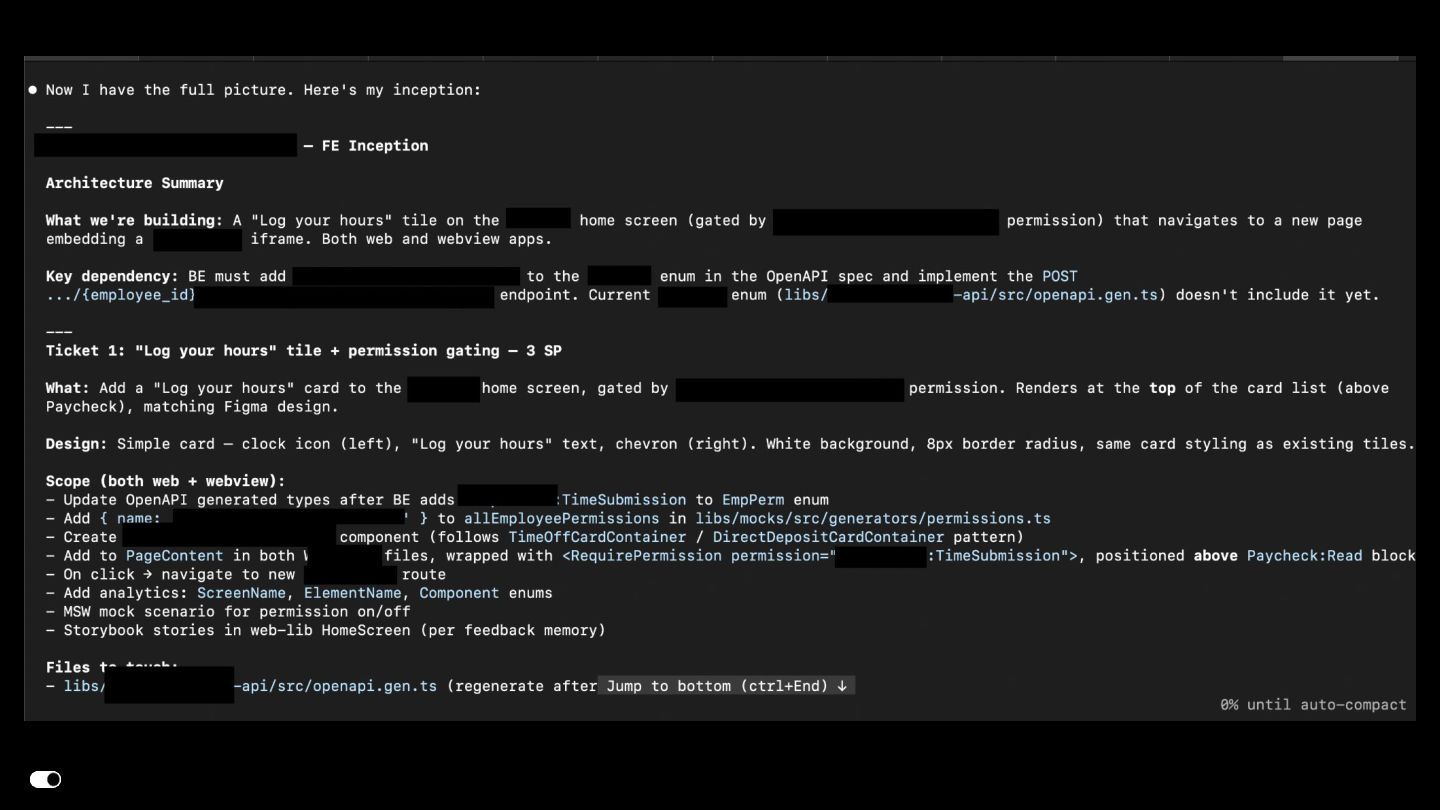{kind=link}
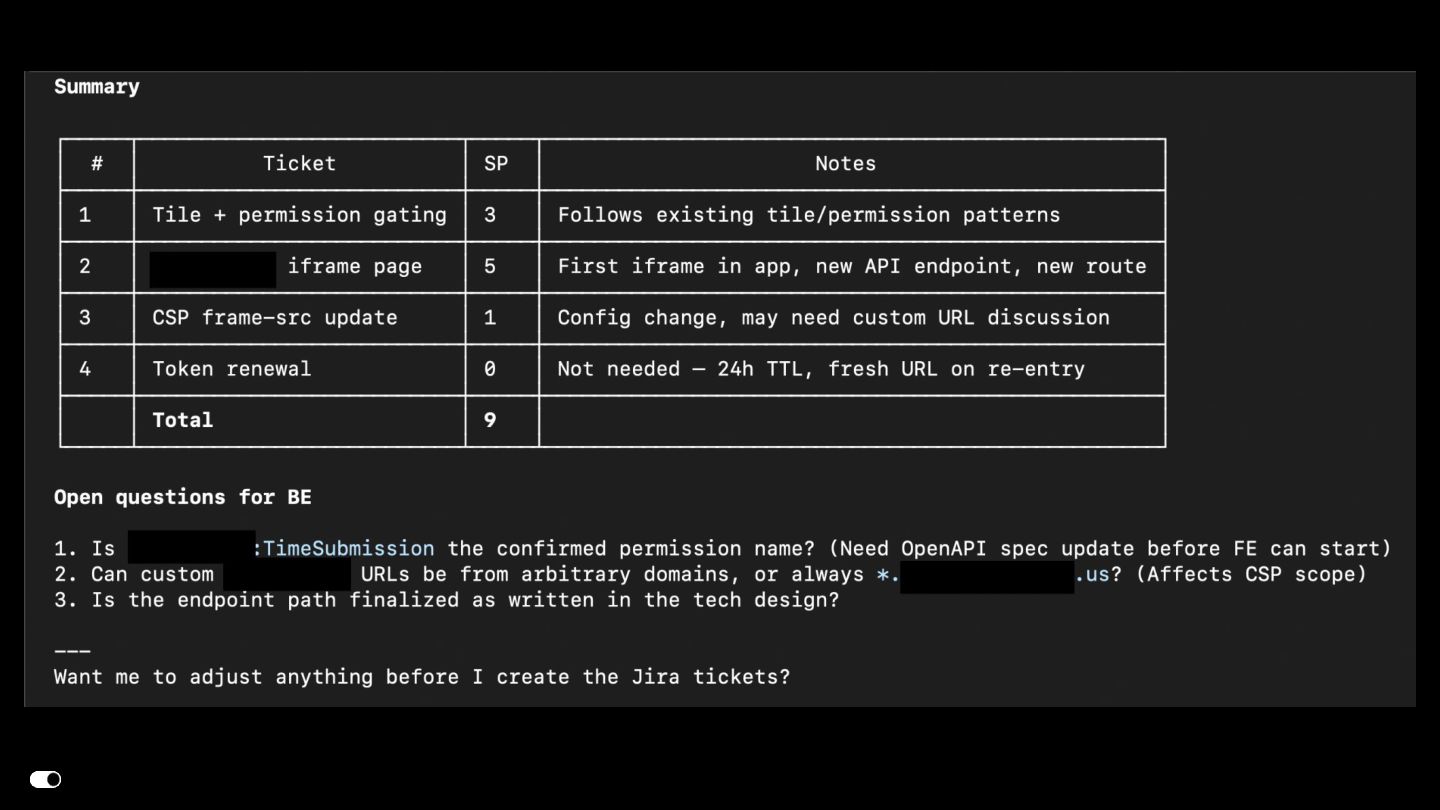{kind=link}
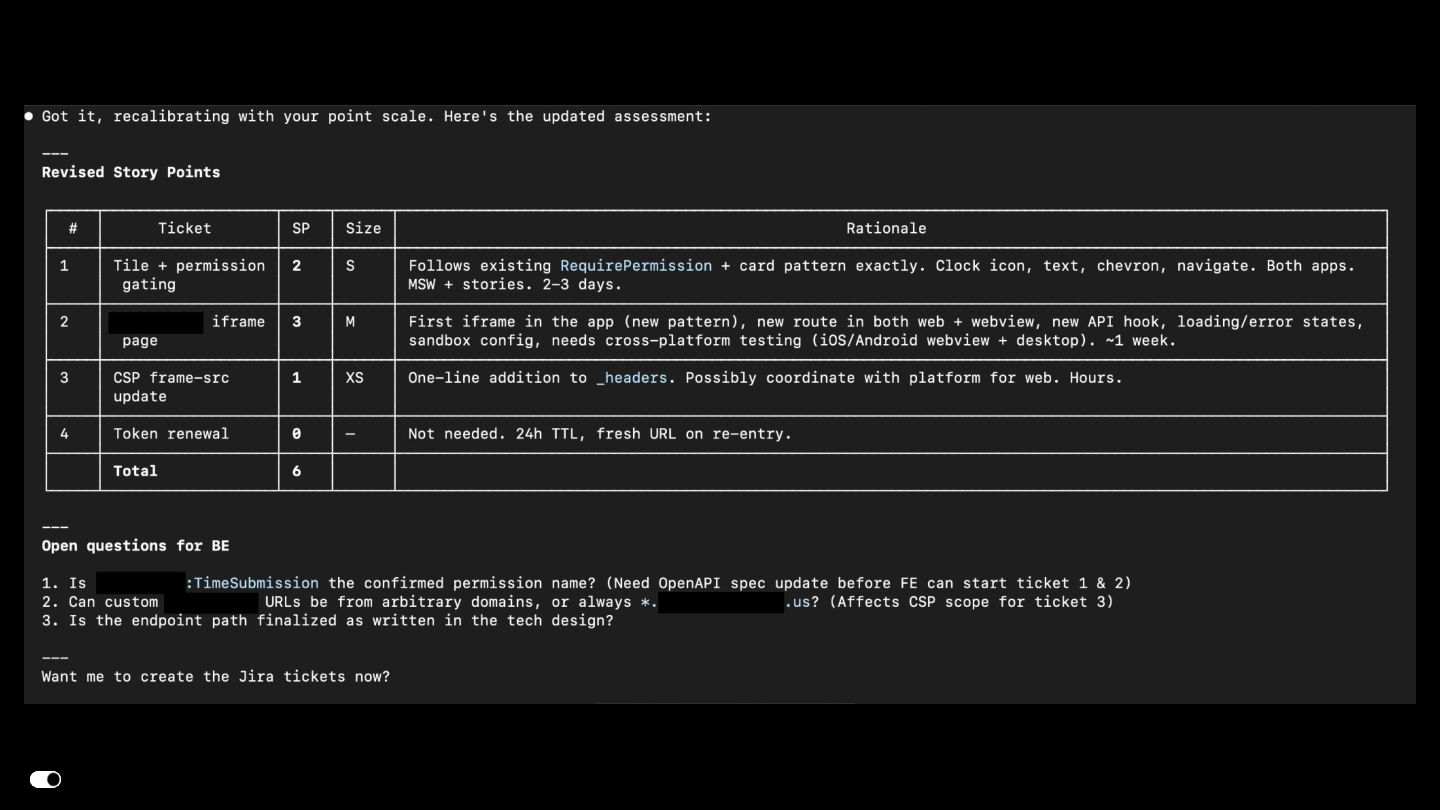{kind=link}
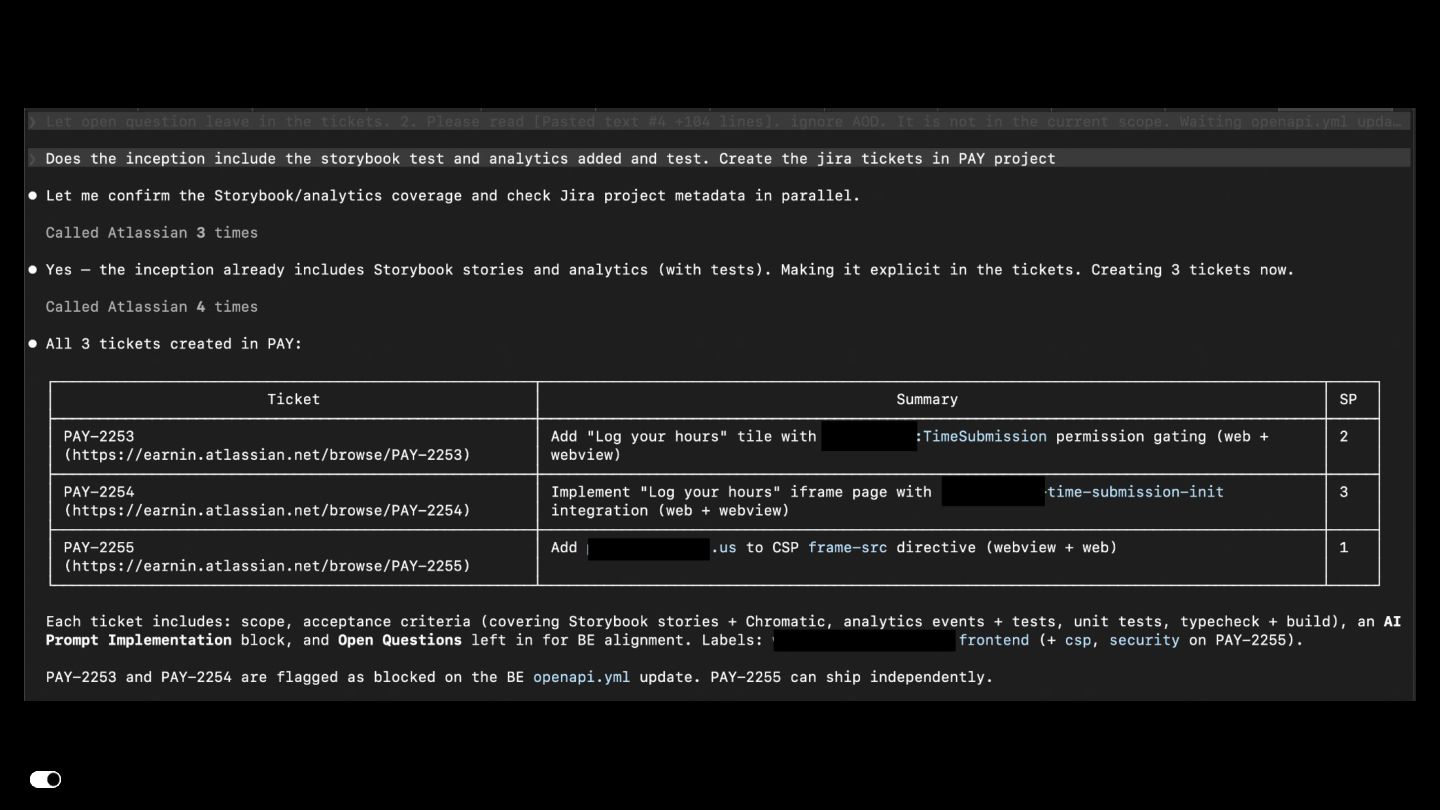{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}