We describe a specific implementation of the Alternating Direction Method of Multipliers (ADMM) algorithm for distributed optimization. This implementation runs logistic regression with L2 regularization over large datasets and does not require a user-tuned learning rate metaparameter or any tools beyond MapReduce. Throughout we emphasize the practical lessons learned while implementing an iterative MapReduce algorithm and the advantages of remaining within the Hadoop ecosystem.
{kind=link}
{kind=link}
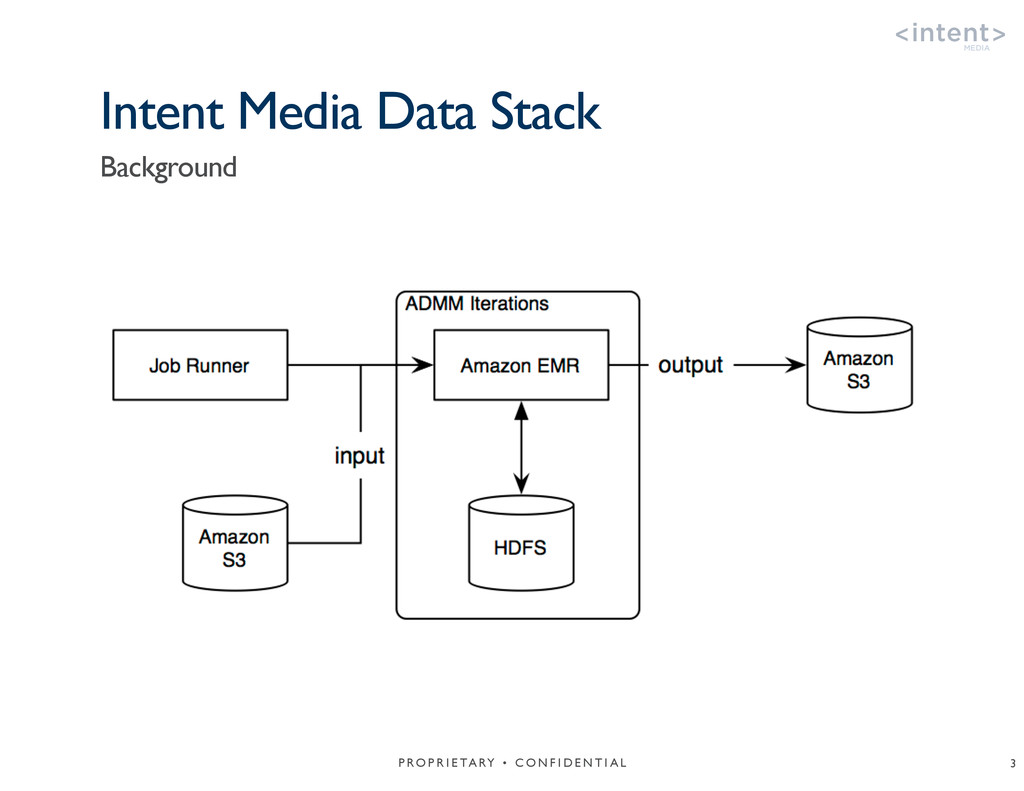{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
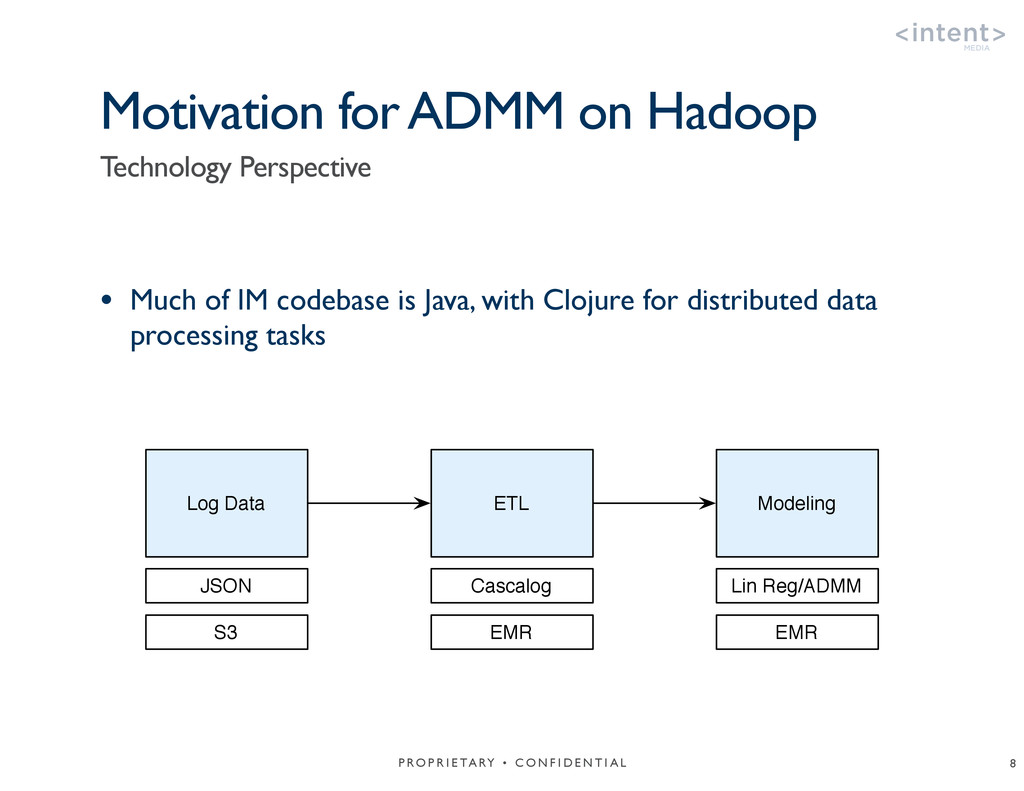{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
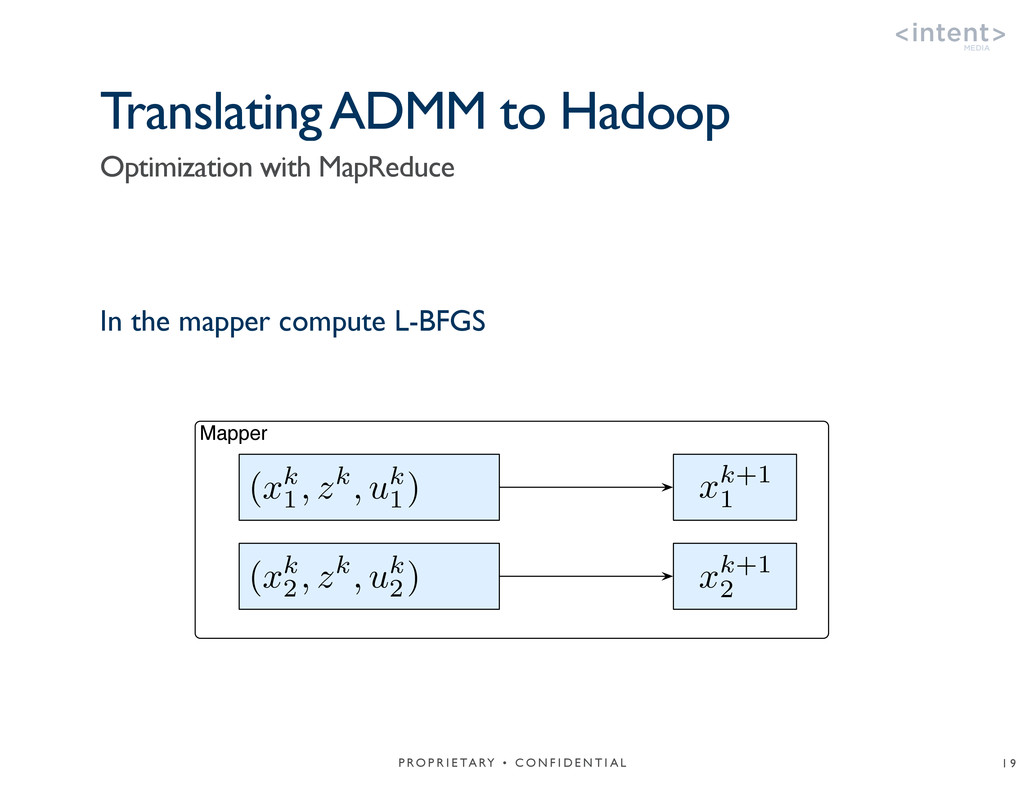{kind=link}
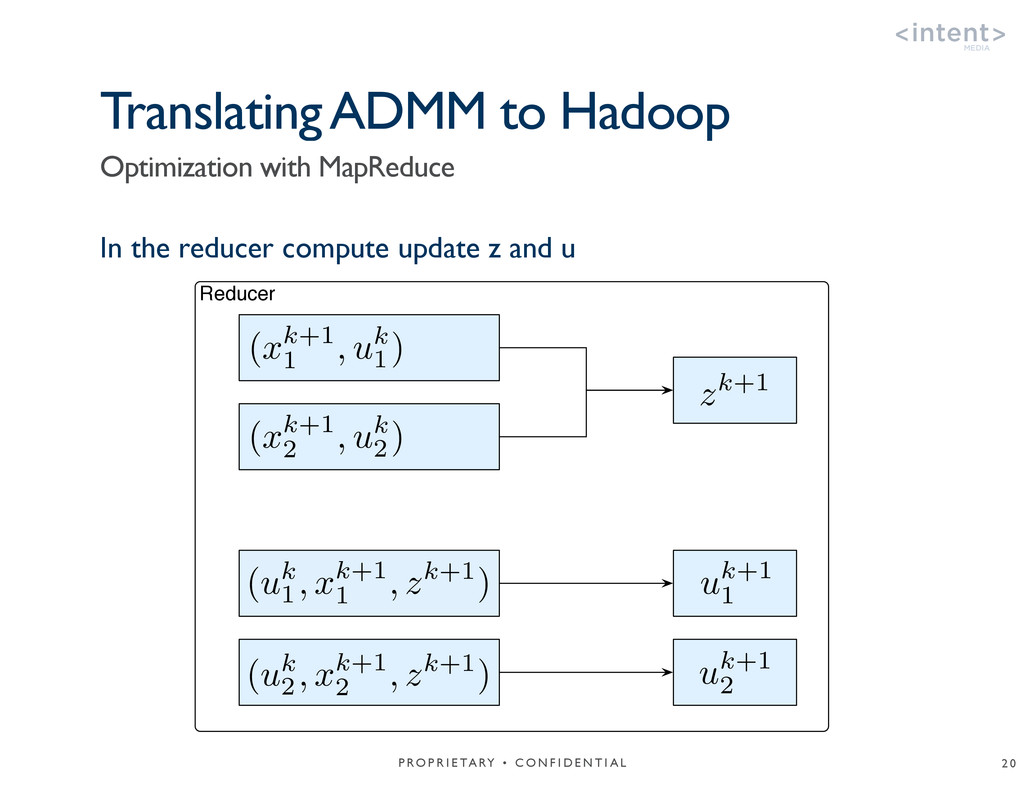{kind=link}
{kind=link}
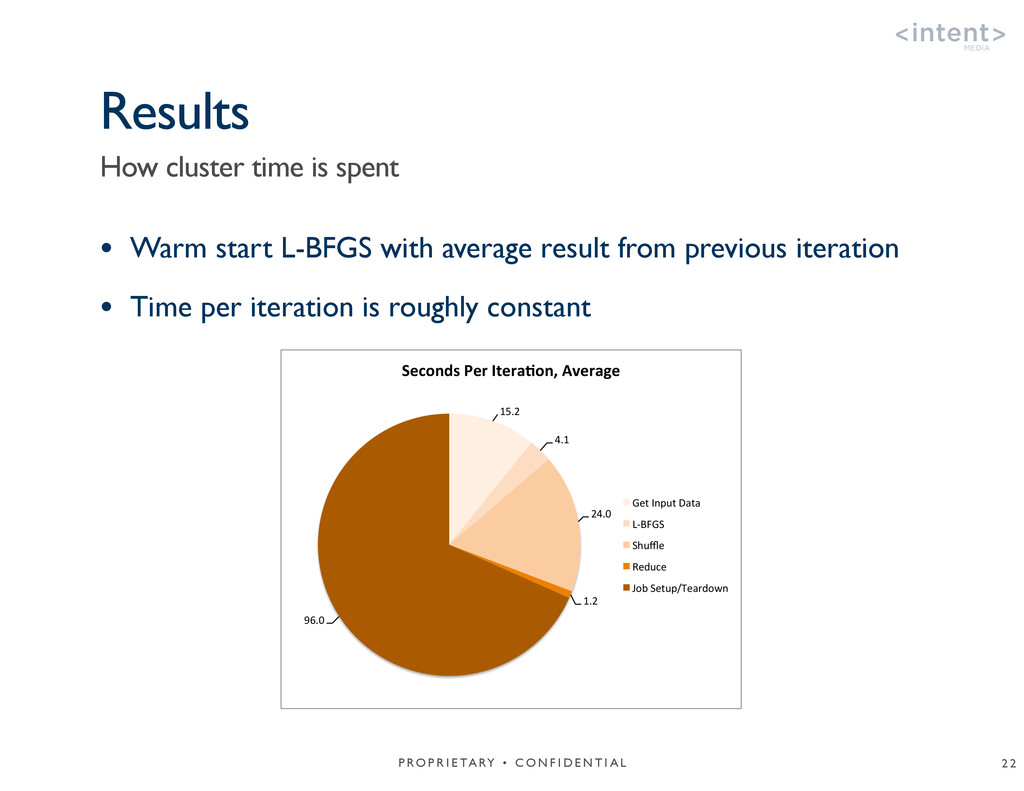{kind=link}
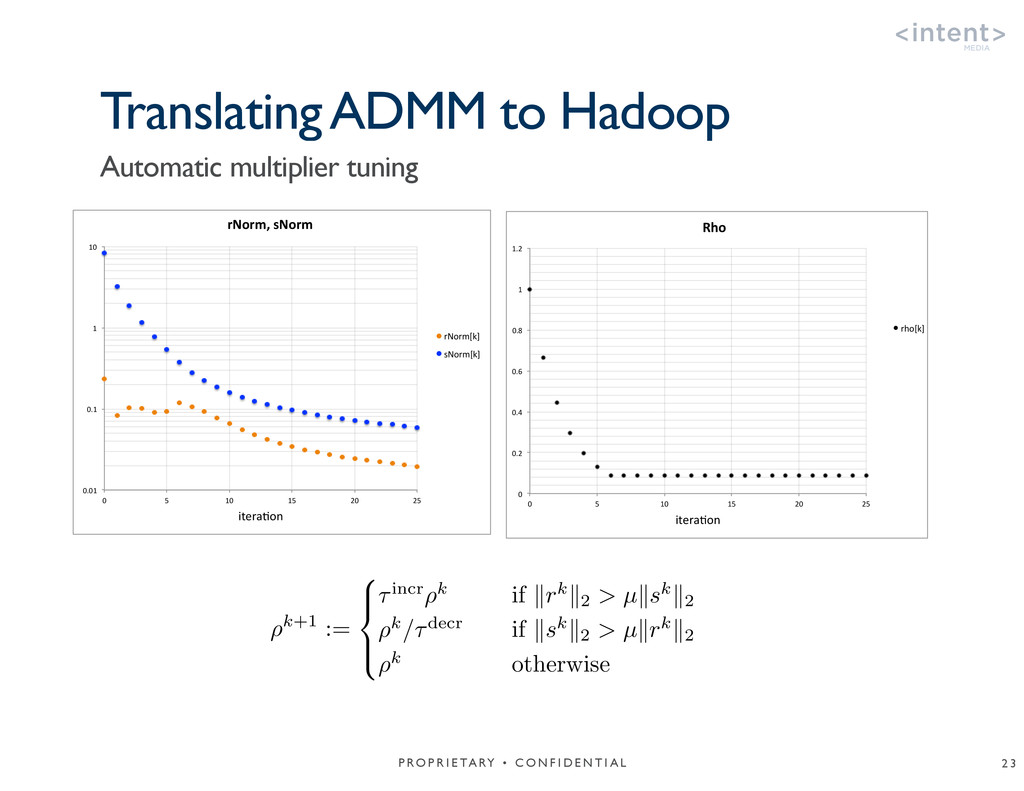{kind=link}
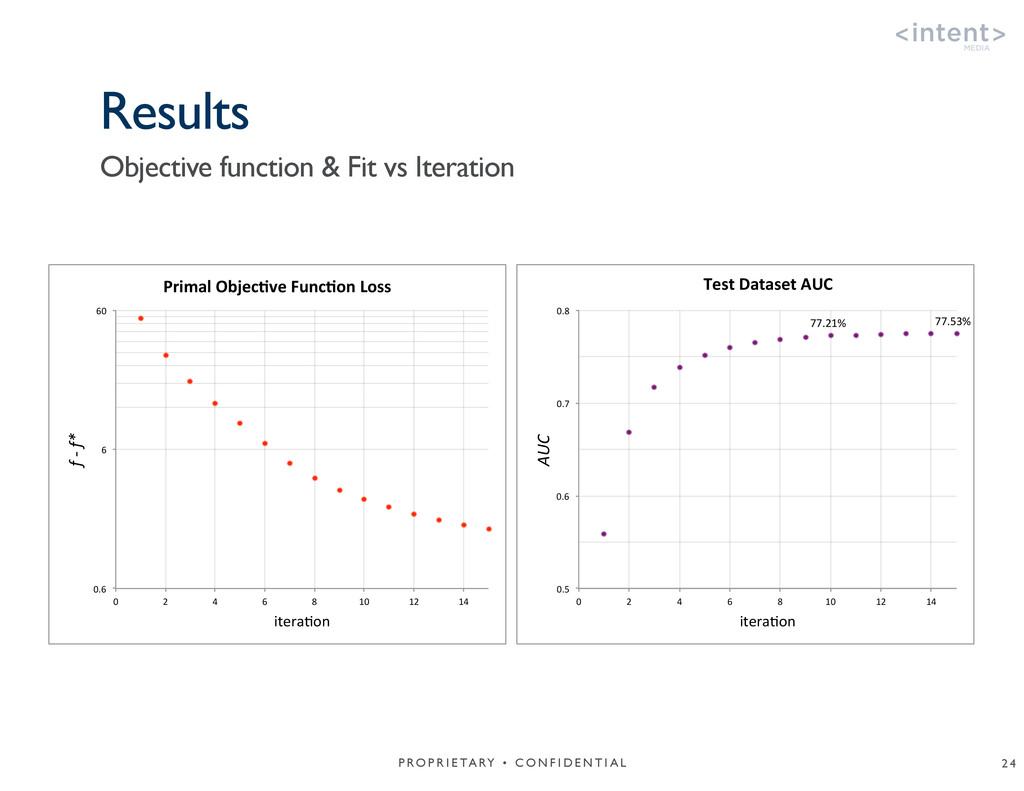{kind=link}
{kind=link}
{kind=link}