Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Measuring Quality Content
Search
Adam Hyland
August 04, 2012
Research
89
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Measuring Quality Content
Presentation to Wikimania 2012 on Article Feedback Tool statistics.
Adam Hyland
August 04, 2012
More Decks by Adam Hyland
See All by Adam Hyland
Here Comes (a significant fraction of) Everybody
protonk
0
82
Boston Data Swap: Data Vis Under Uncertainty
protonk
0
59
Why Nate Silver is Famous
protonk
1
130
Data Visualization under Uncertainty
protonk
0
780
Phillips Academy Wikipedia Introduction
protonk
0
94
Other Decks in Research
See All in Research
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
250
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.5k
議論 学術ムーブメントを成功させるために何が必要なのだろうか
rmaruy
0
110
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4.1k
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
160
Claude Code × autoresearch 実践
mathbullet
0
210
kintone リサーチ副部/UXリサーチャー 業務紹介
cybozuinsideout
PRO
0
120
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
業界横断 副業コンプライアンス調査 三者(副業者・本業先・発注者)におけるトラブル認知ギャップの構造分析
fkske
0
1.3k
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
590
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
260
Featured
See All Featured
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Leo the Paperboy
mayatellez
8
1.9k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Un-Boring Meetings
codingconduct
0
350
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
The World Runs on Bad Software
bkeepers
PRO
72
12k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
410
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
Transcript
Measuring Article Quality Peer Review and the Article Feedback Tool
Adam Hyland protonk @ en-wp
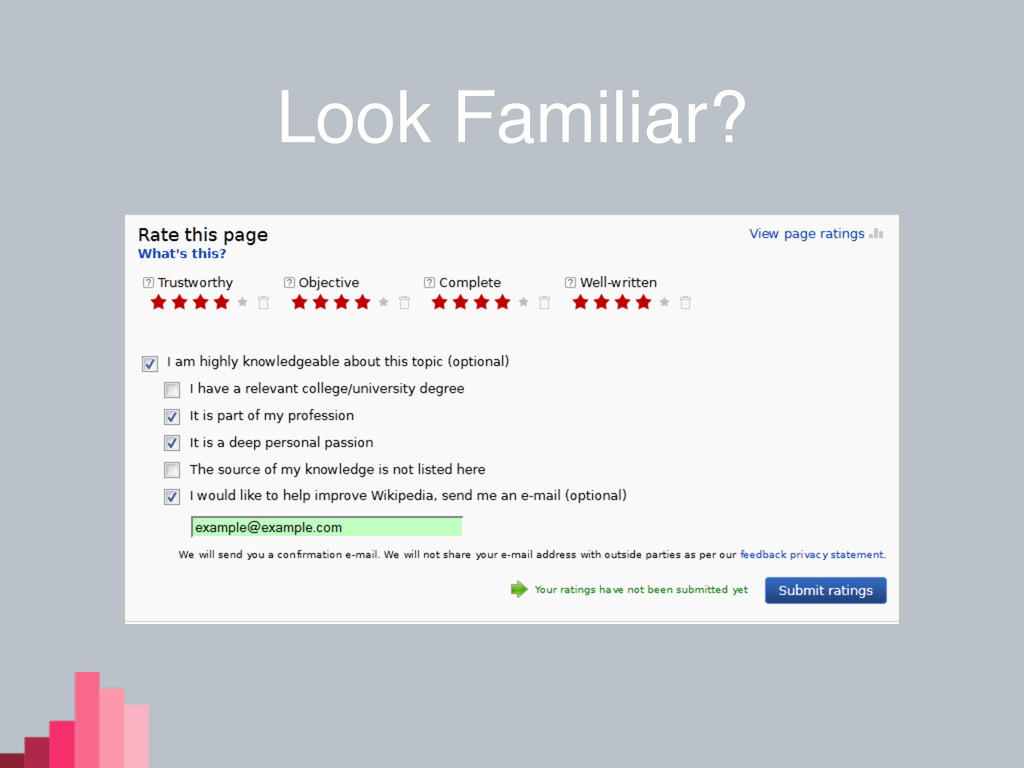
Look Familiar?
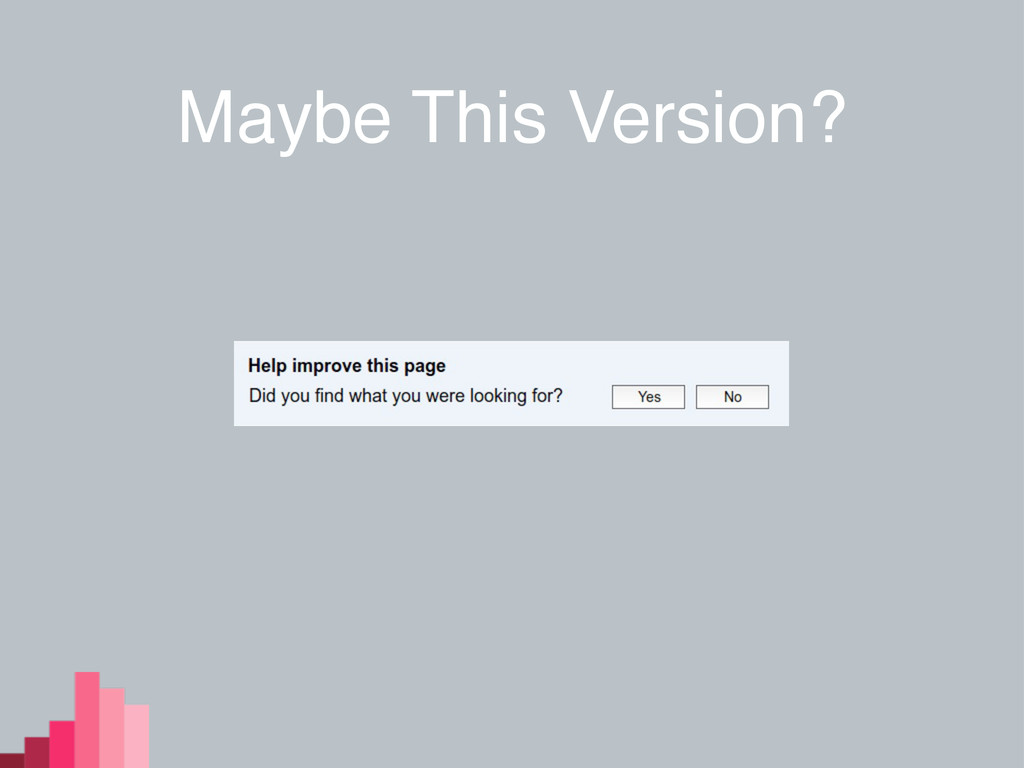
Maybe This Version?
None
Article Feedback Tool • Deployed in 2010 • Version 4
(the current version) ramped up in 2011 • Designed to offer an avenue for reader feedback • High volume of reader feedback
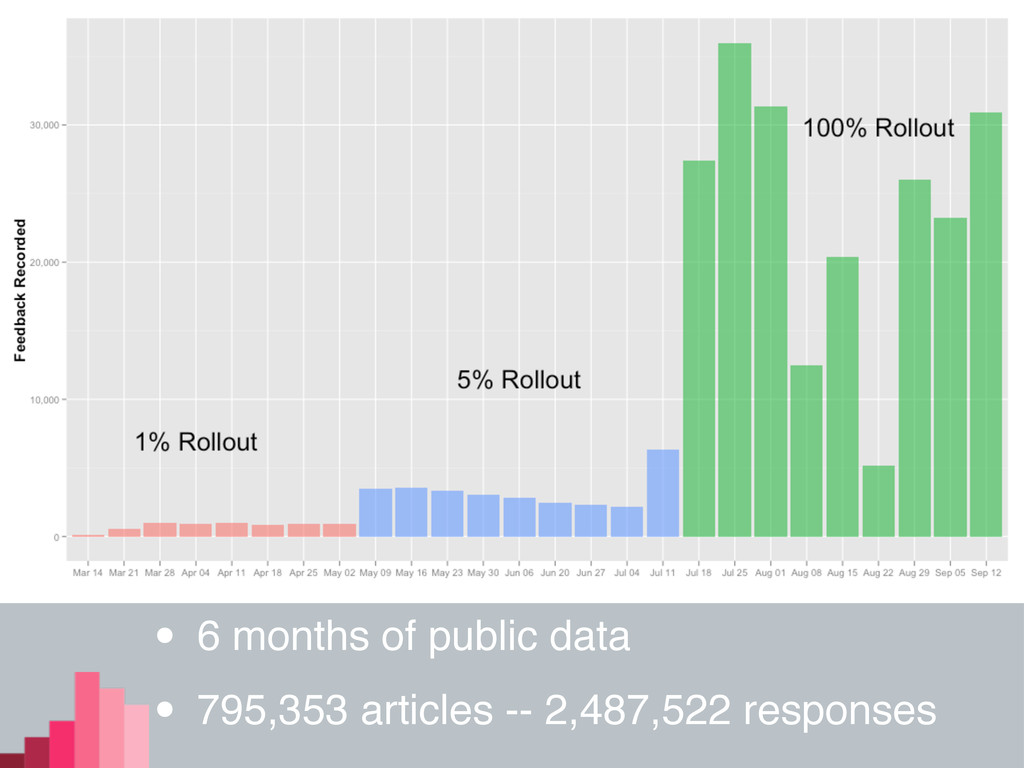
• 6 months of public data • 795,353 articles --
2,487,522 responses
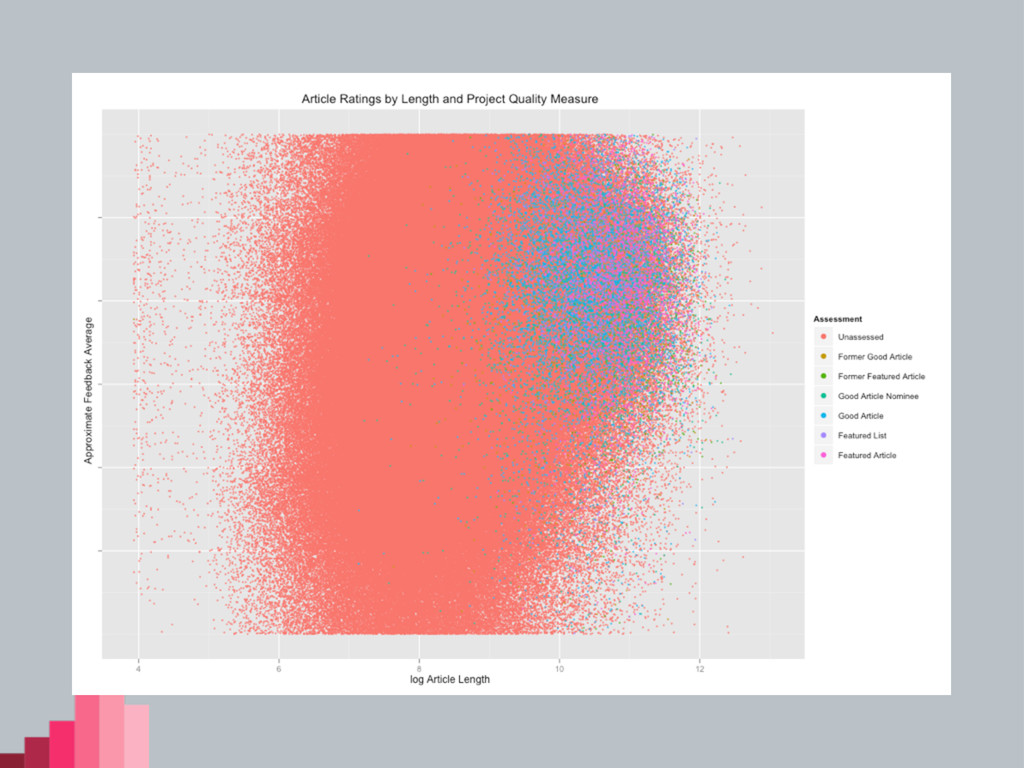
Featured Articles (FA) • 3,599 articles (0.09% of all articles)
• 2,267 Featured Lists (FL) • Most rigorous peer review process on the English Wikipedia • Very sensitive to editor preferences • Some idiosyncrasies
Good Articles (GA) • 15,357 articles • Relatively rigorous peer
review (yes I know reasonable minds may disagree) • Less idiosyncratic than FA in some ways • Perhaps less dependent on editor preference
Data • Article name • Length (in bytes) • GA/FA
status (including former/not- promoted) • Some user data
None
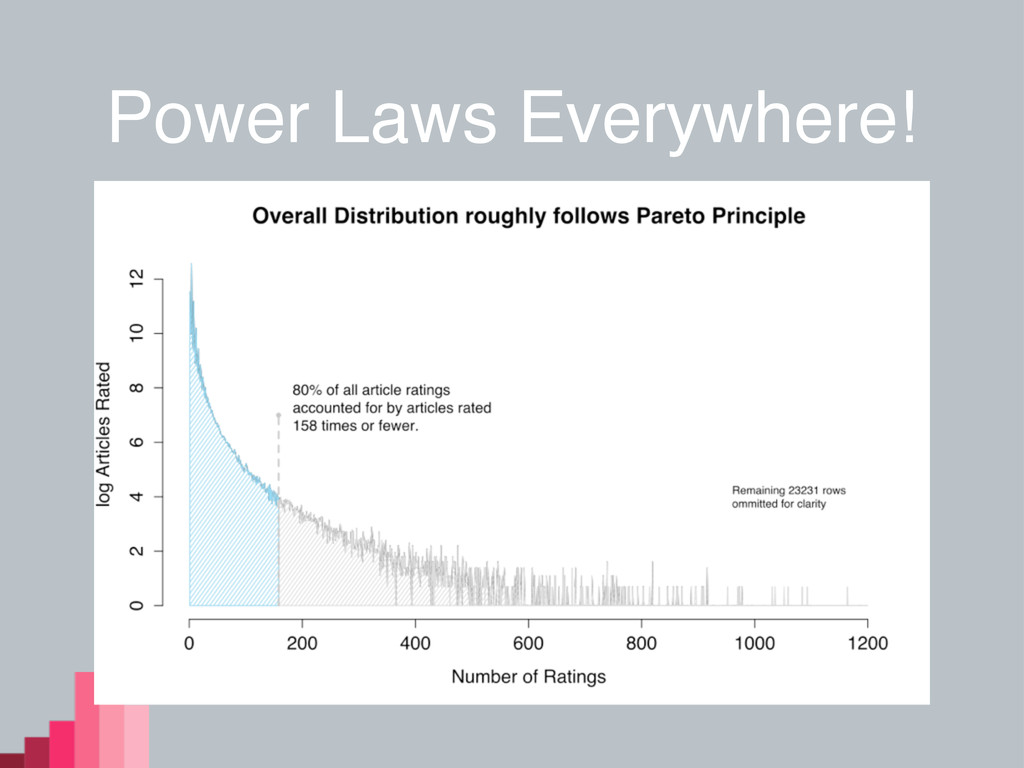
Beyond Summaries • Reader ratings follow pageviews • Predominantly non-editors
• Popular articles: • Call of Duty • Justin Bieber • Jimmy Wales (avg. rating: 1.10585)
Power Laws Everywhere!
Classical(ish) Models • Logistic regression model supports a relationship between
rating and likelihood of FA/GA • Linear model does, but with a twist • Can’t escape Cambridge Endogeneity Police!
None
Data Mining • Predicting featured status from reader ratings and
minimal meta-data. • Bayesian classifier able to roughly predict featured status (with a high false positive rate)
But the system’s changing! • AFT v4 is a multi-category
quantitative measure • AFT v5 is, roughly, YES/NO • Is this a problem? • Frank Harrell and the perils of dichotomization.
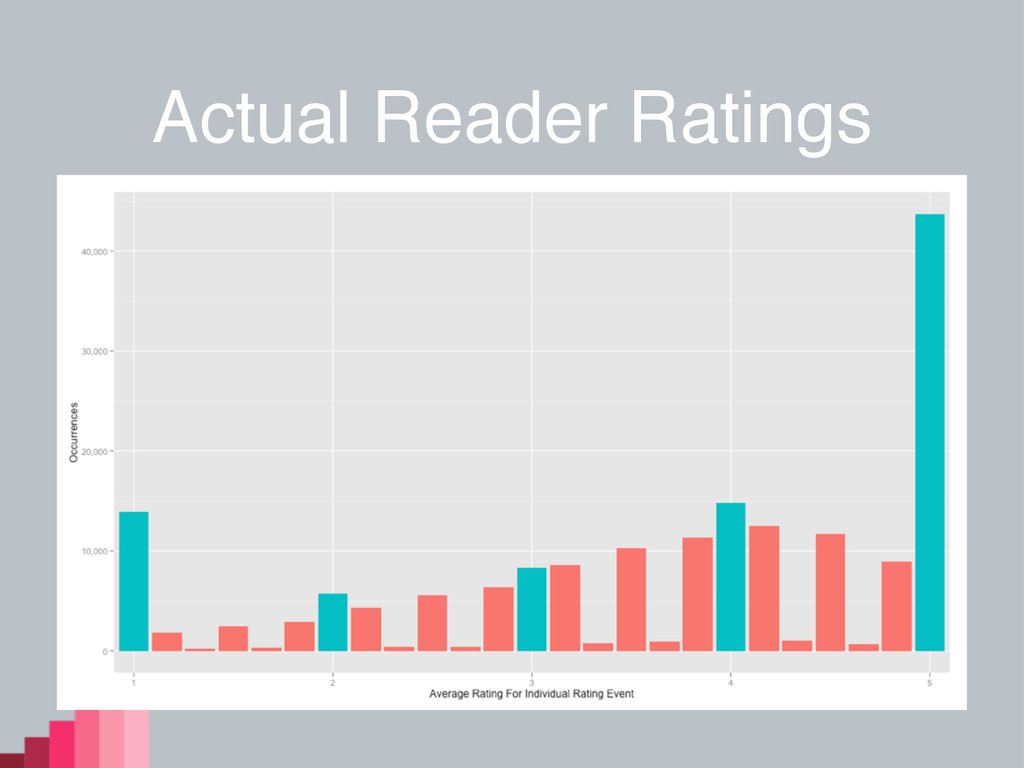
Actual Reader Ratings
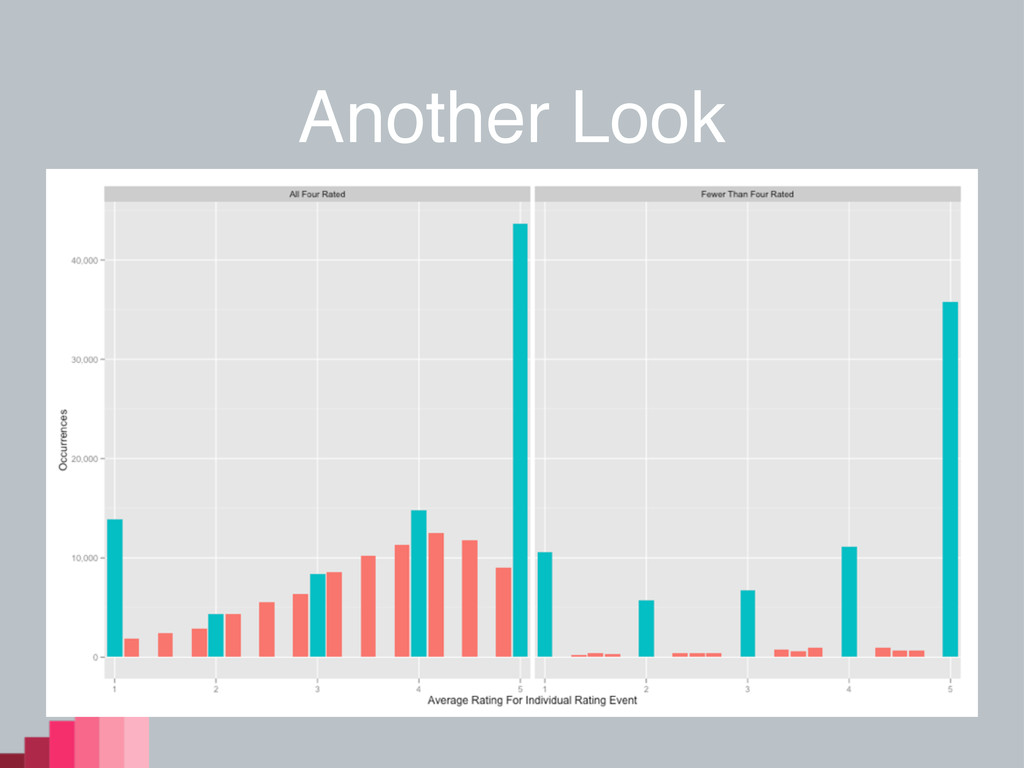
Another Look
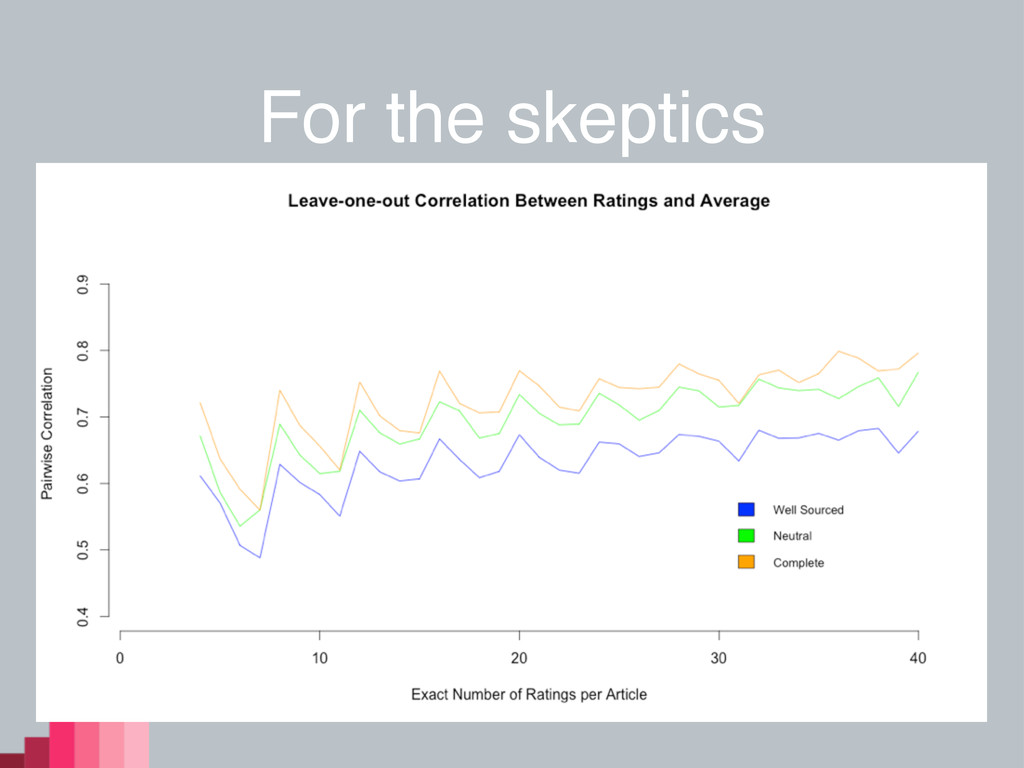
For the skeptics
Information • We can imagine we might not lose information
in shifting to v5 • This is born out by the classifier, to some degree. • We don’t lose a lot of power when dichotomizing individual ratings
A Look Ahead • Really exciting! • Great compliment to
current research methods • Long exposures can help discover reader/editor divergence • Predictive analytics • Need more open data
Questions? • Of course you have questions! • All work
is or soon will be available on github under a free license • Full writeup on en-wp forthcoming
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}