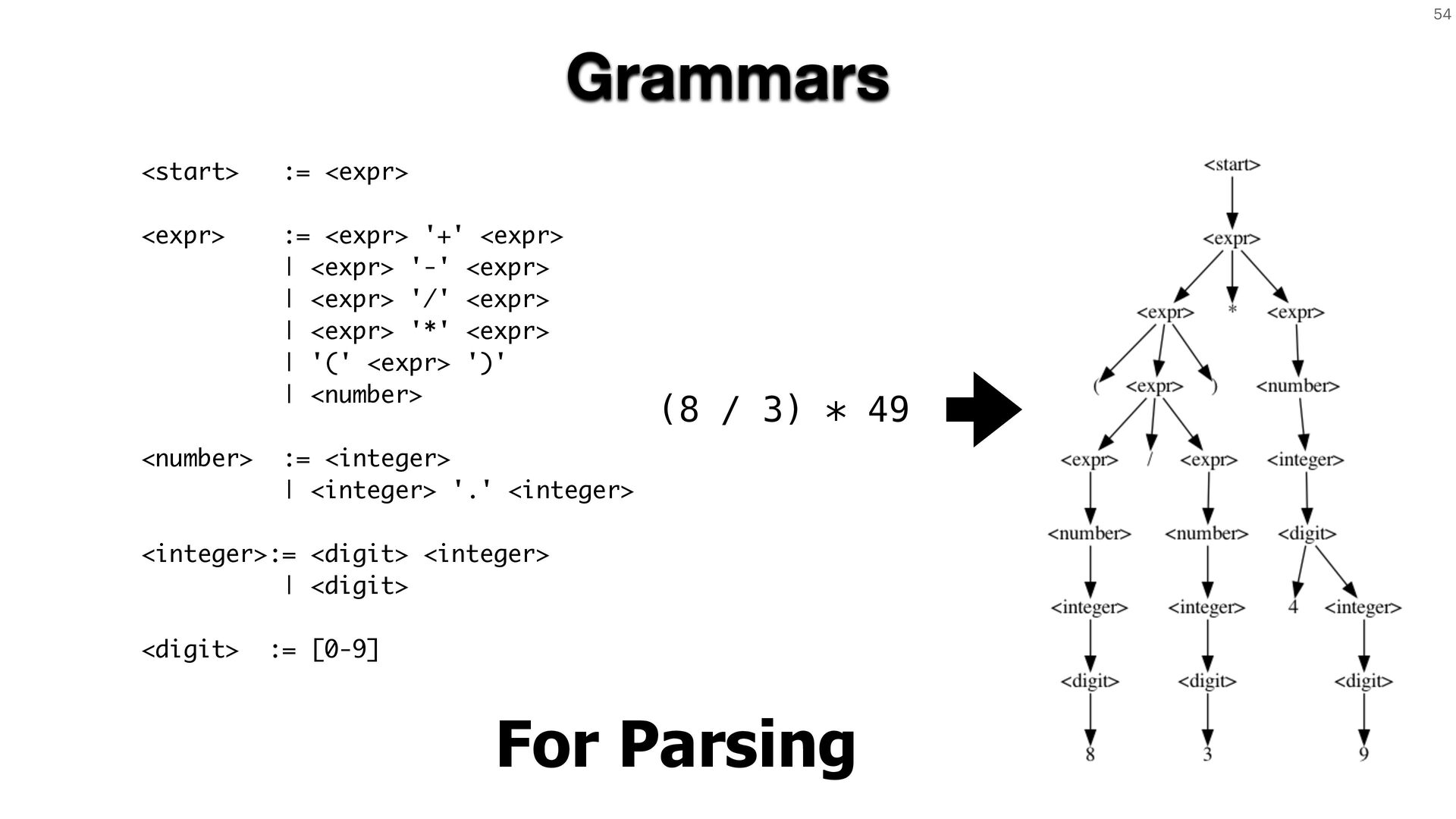
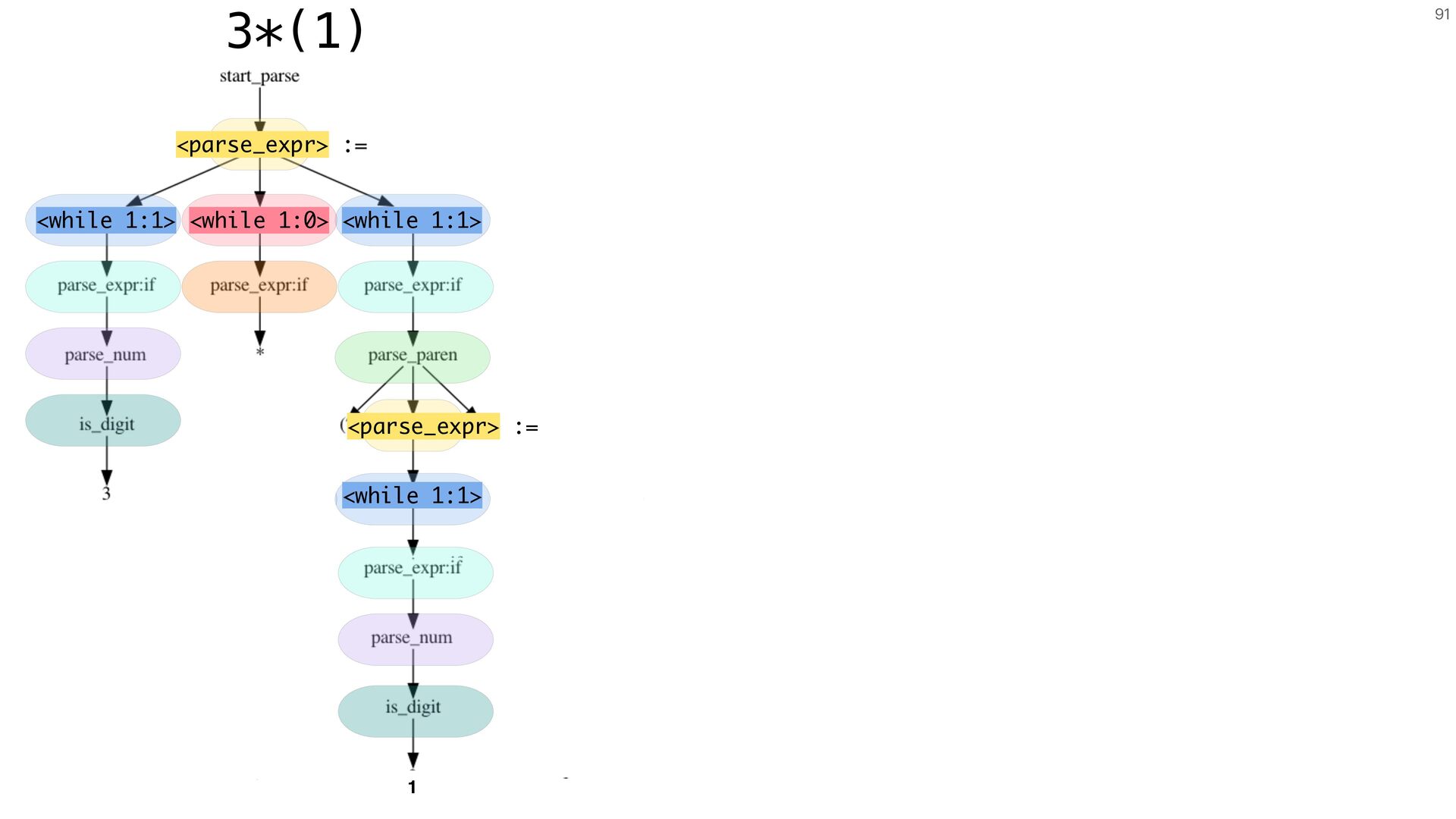
A bug uncovered by fuzzing is seldom the product of a single input. More often, it's a family of inputs that reliably triggers the same underlying flaw.
Validating a fix means testing against that entire family, not just the one input that happened to surface the problem. In this lecture, I'll show how to
capture these families as specialized grammars that encode specific program behaviors, particularly faulty ones. You'll learn how to extract and merge such
patterns into targeted grammars, and how to use them to focus your fuzzing efforts. These grammars compose naturally with smart fuzzers, giving you fine-
grained control over input generation and making tests consistent and reproducible.
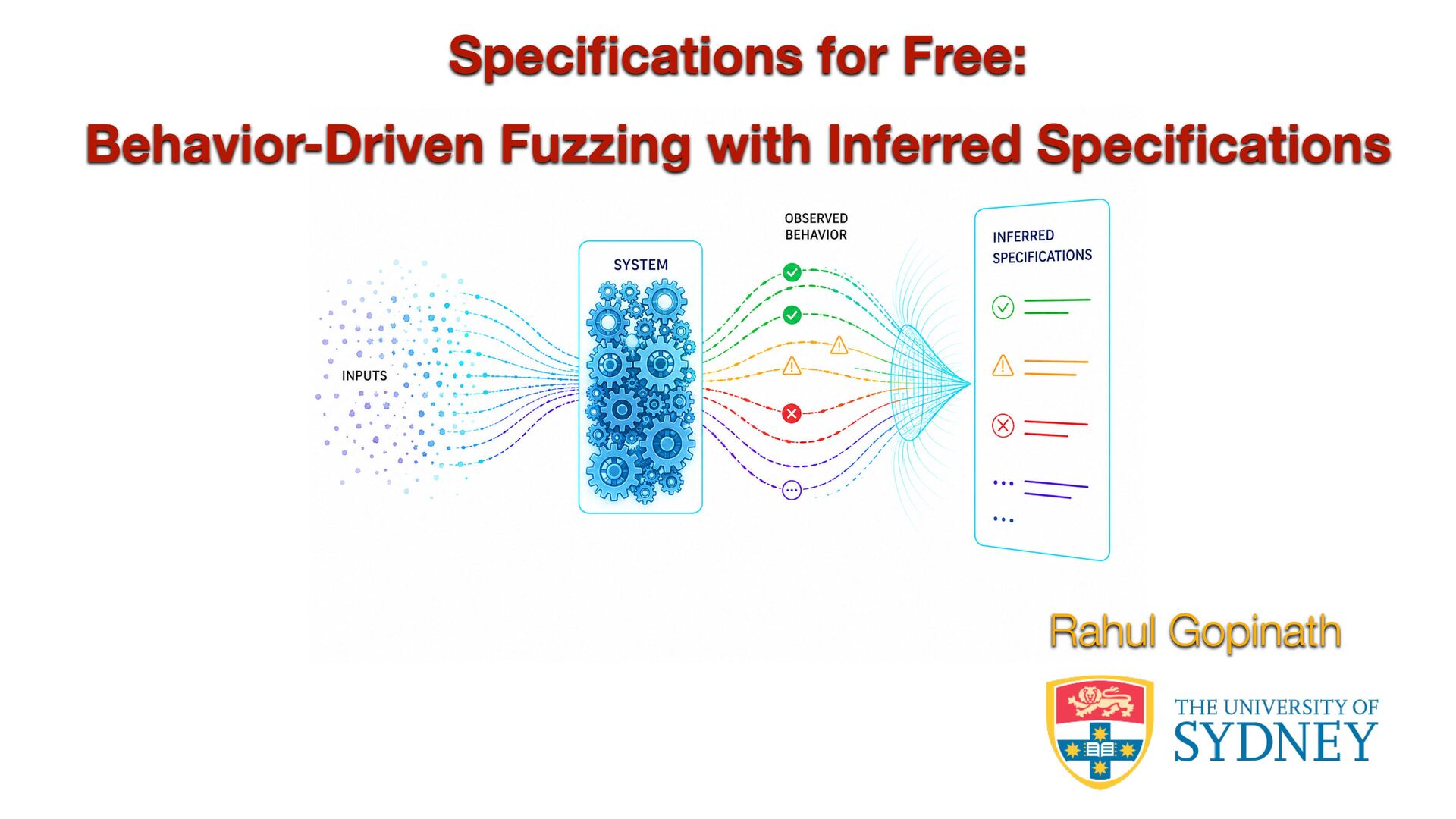
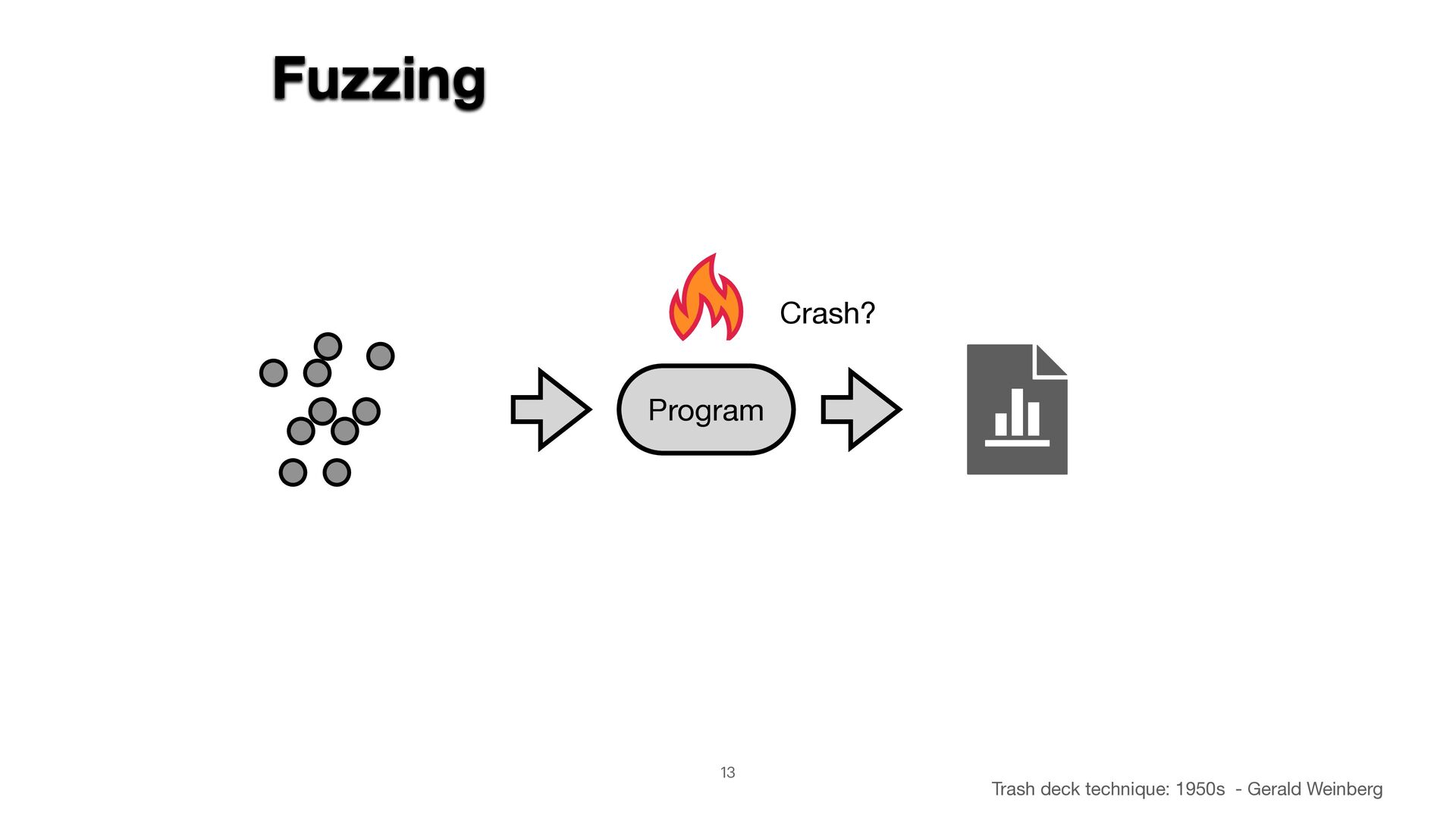
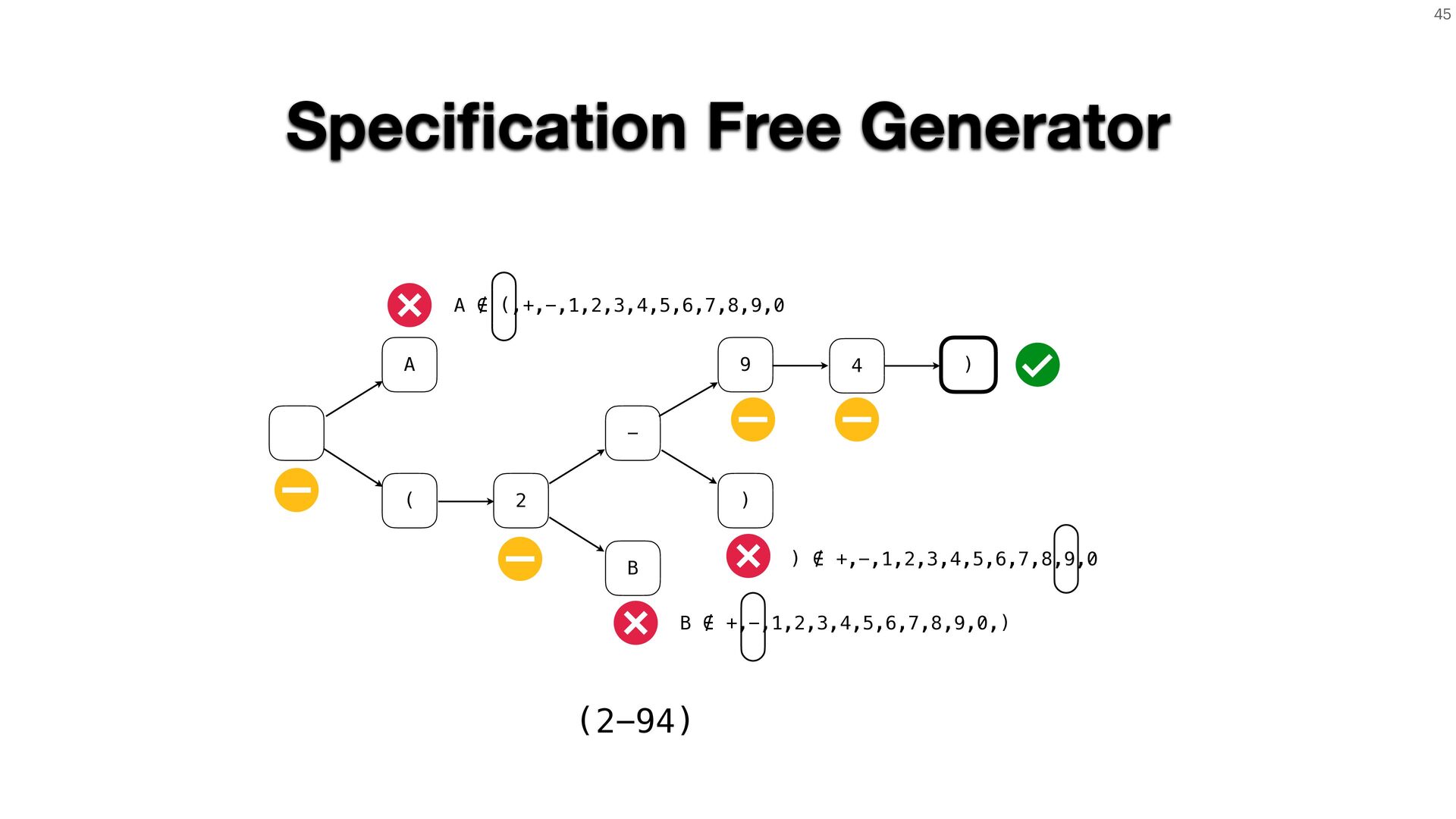
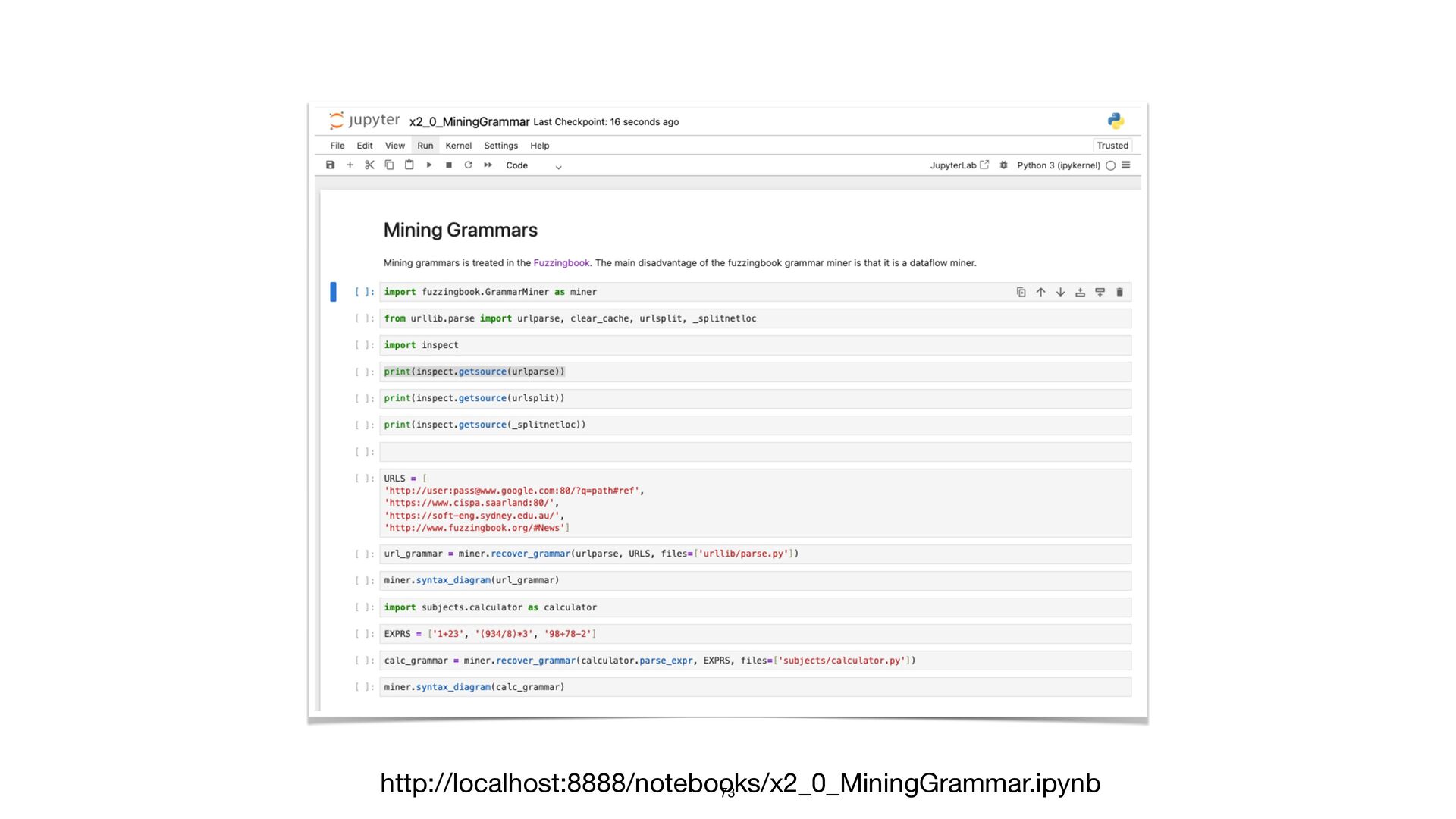
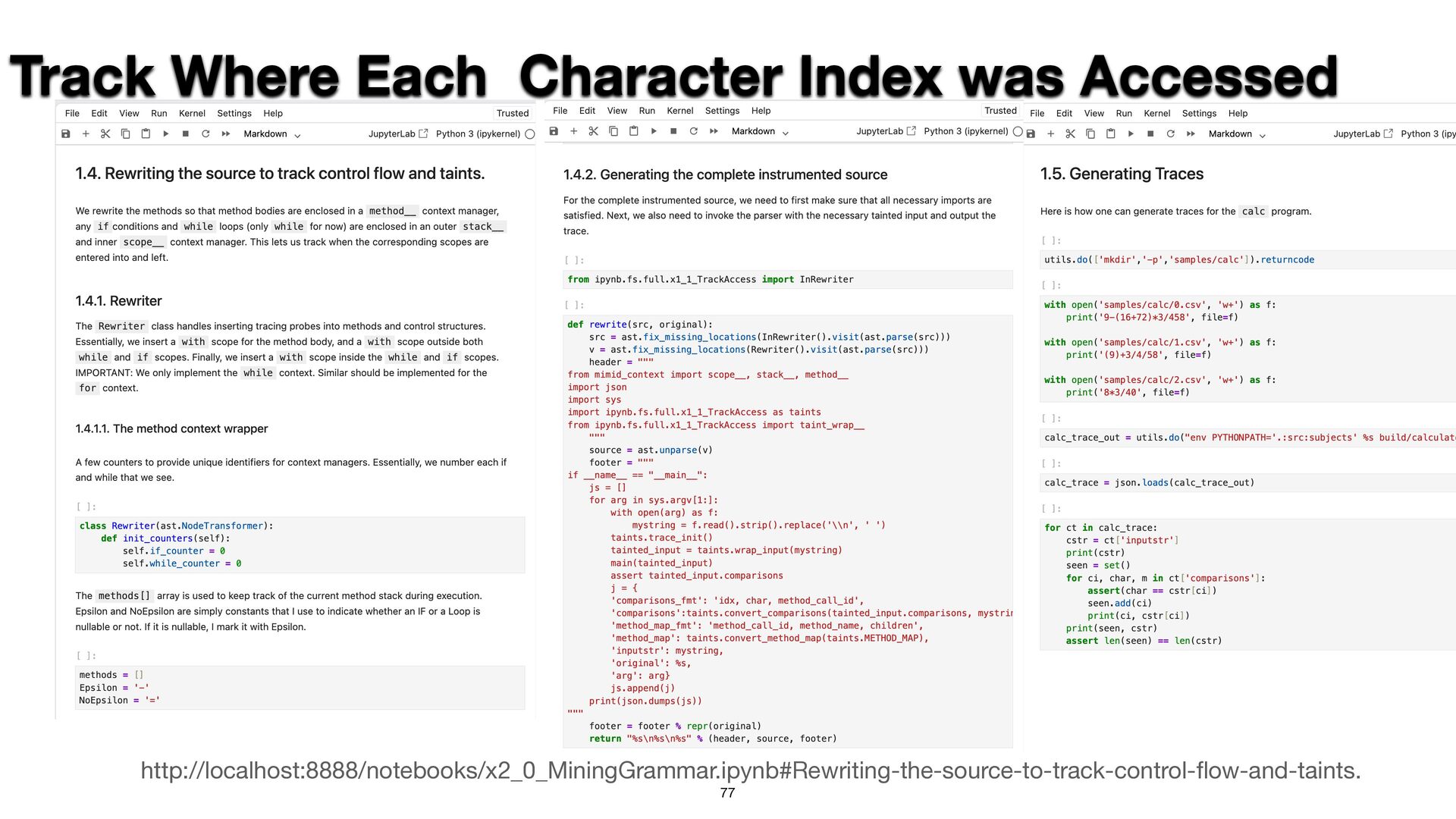
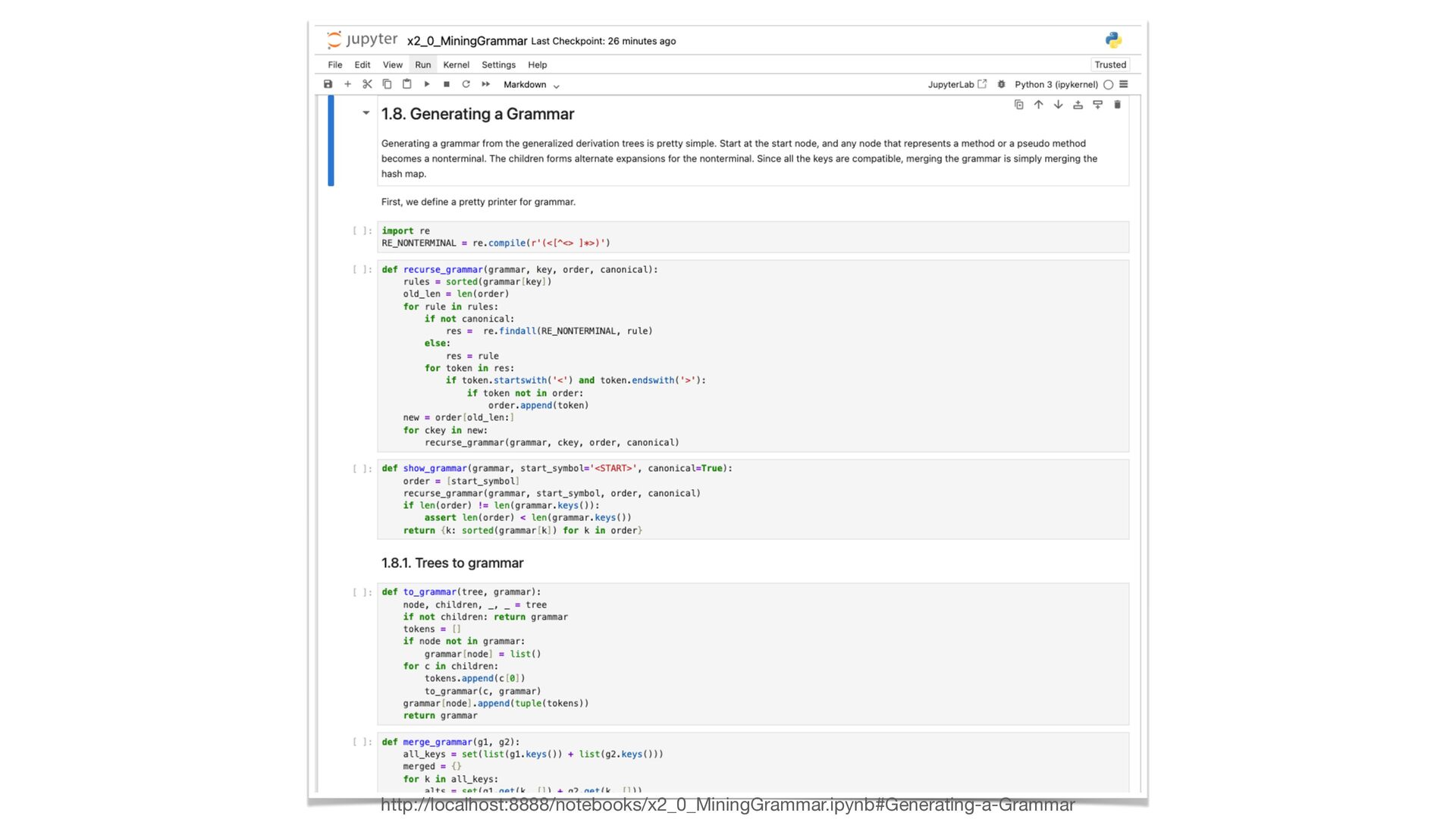
A persistent challenge in fuzzing is that leveraging input structure requires accurate specifications, which aren't always on hand. I'll show how to
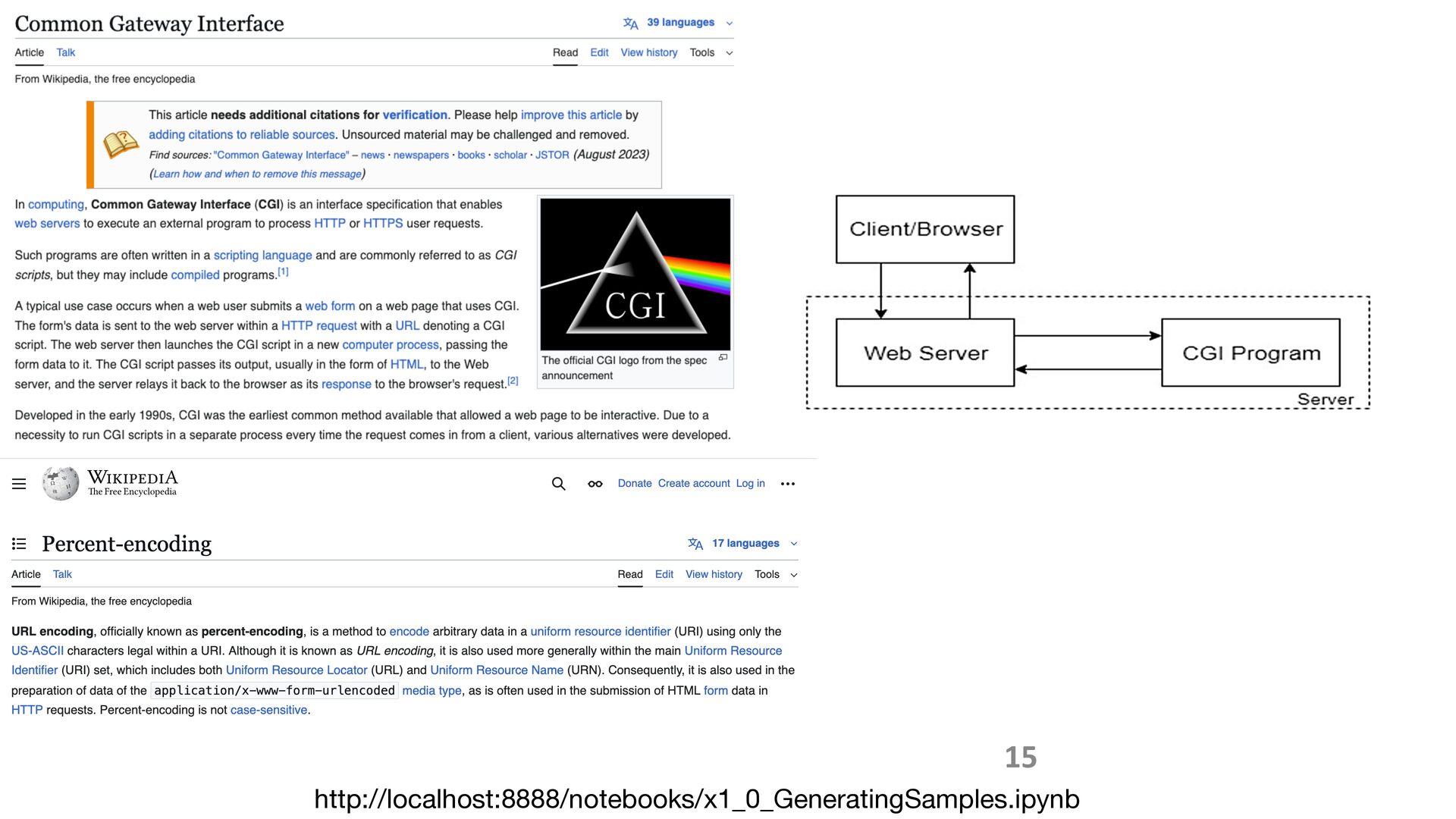
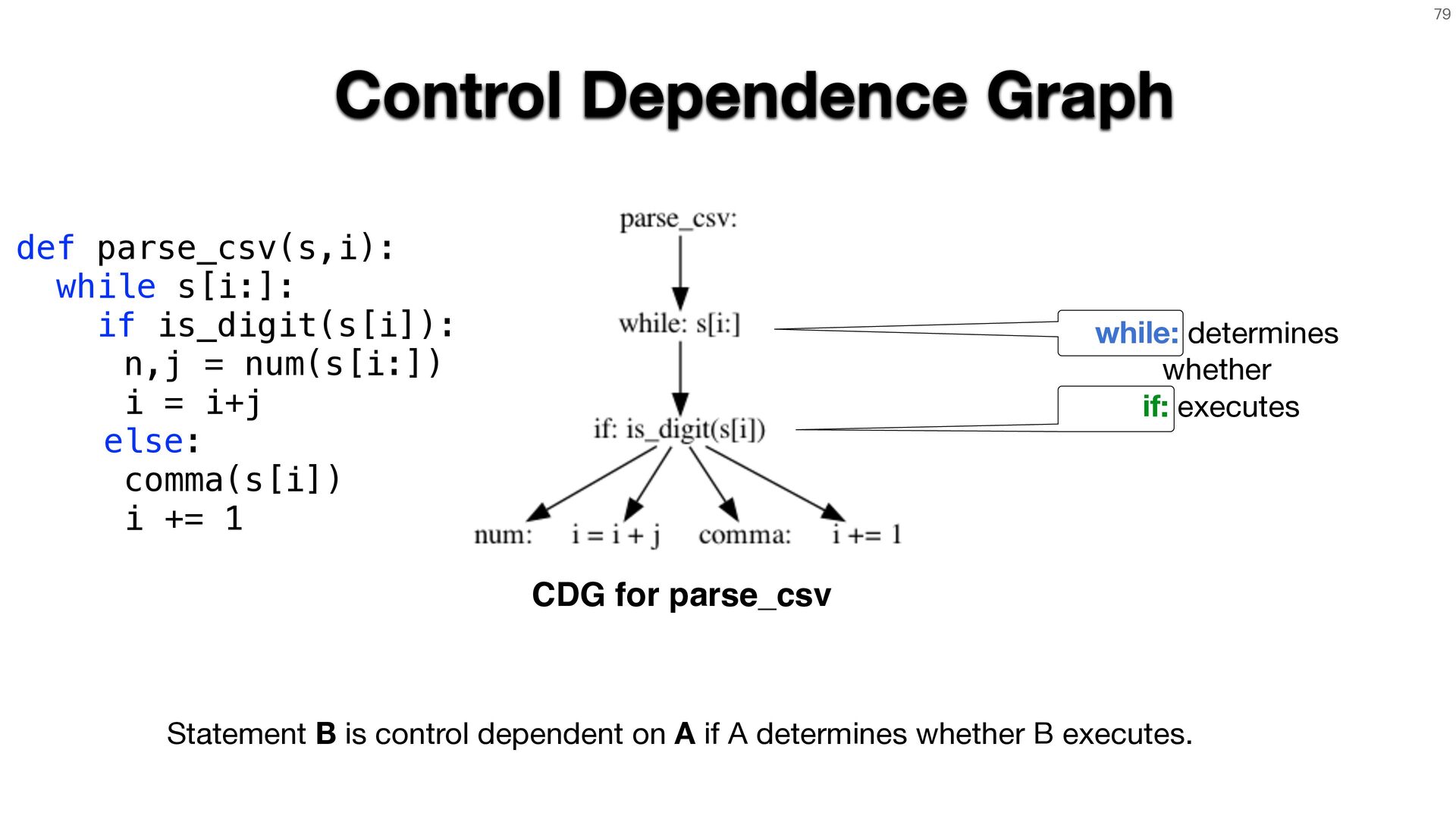
sidestep this by deriving input grammars directly from the program. When source code is available, static and dynamic analysis can trace input-handling
logic from first principles. Without it, we can infer structure by observing how the program responds to inputs and iteratively refining our model through
feedback.
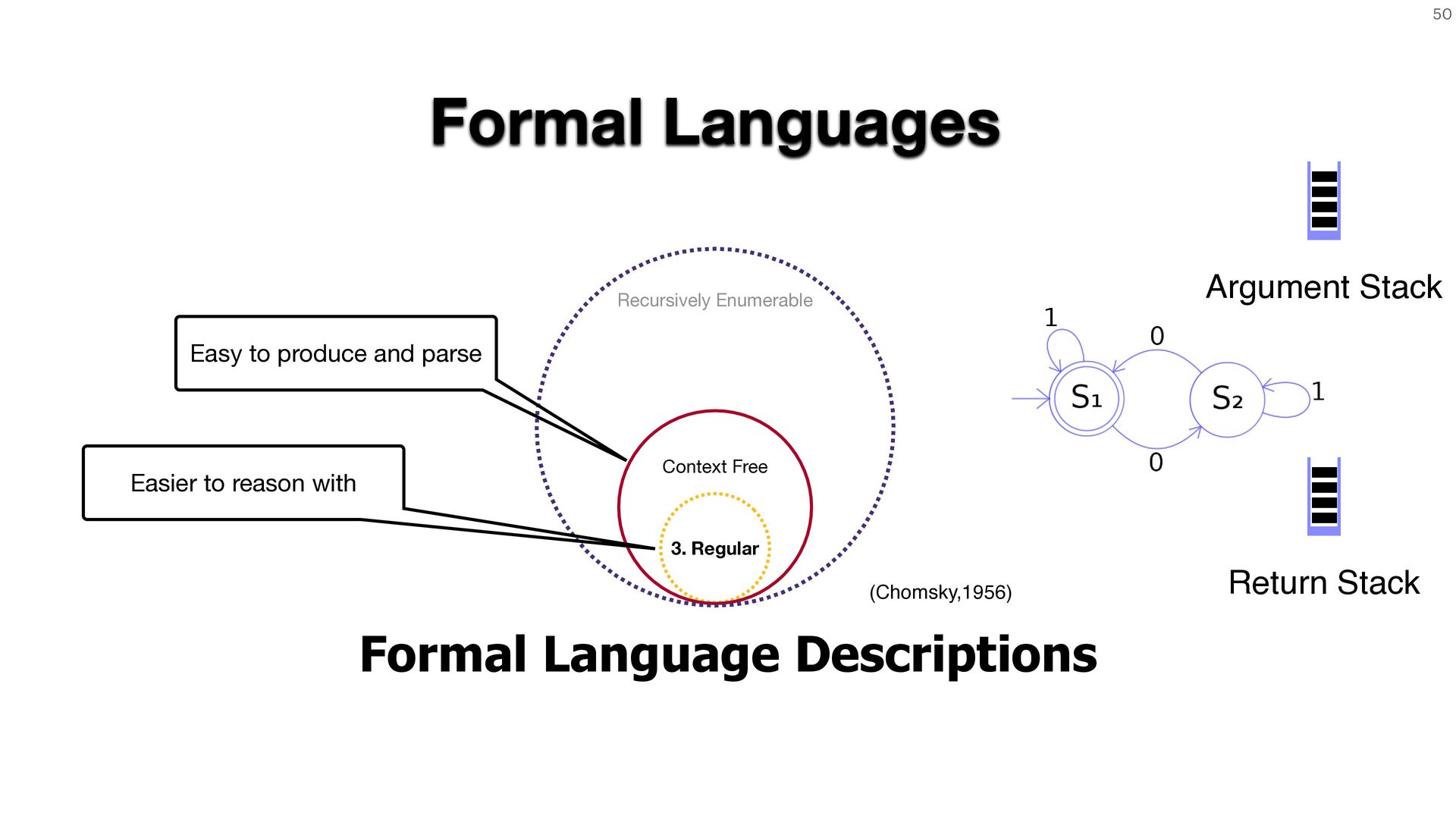
Together, these techniques make specification-free fuzzing practical and lay the foundation for the behavior-driven strategies we'll develop throughout the
session.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![14 $ ./fuzz [;x1-GPZ+wcckc];,N9J+?#6^6\e?]9lu 2_%'4GX"0VUB[E/r ~fApu6b8<{%siq8Z h.6{V,hr?;{Ti.r3PIxMMMv6{xS^+'Hq! AxB"YXRS@!Kd6;wtAMefFWM(`|J_<1~o} z3K(CCzRH JIIvHz>_*.\>JrlU32~eGP?](https://files.speakerdeck.com/presentations/f5037af7e19141598e140b4d03383dde/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
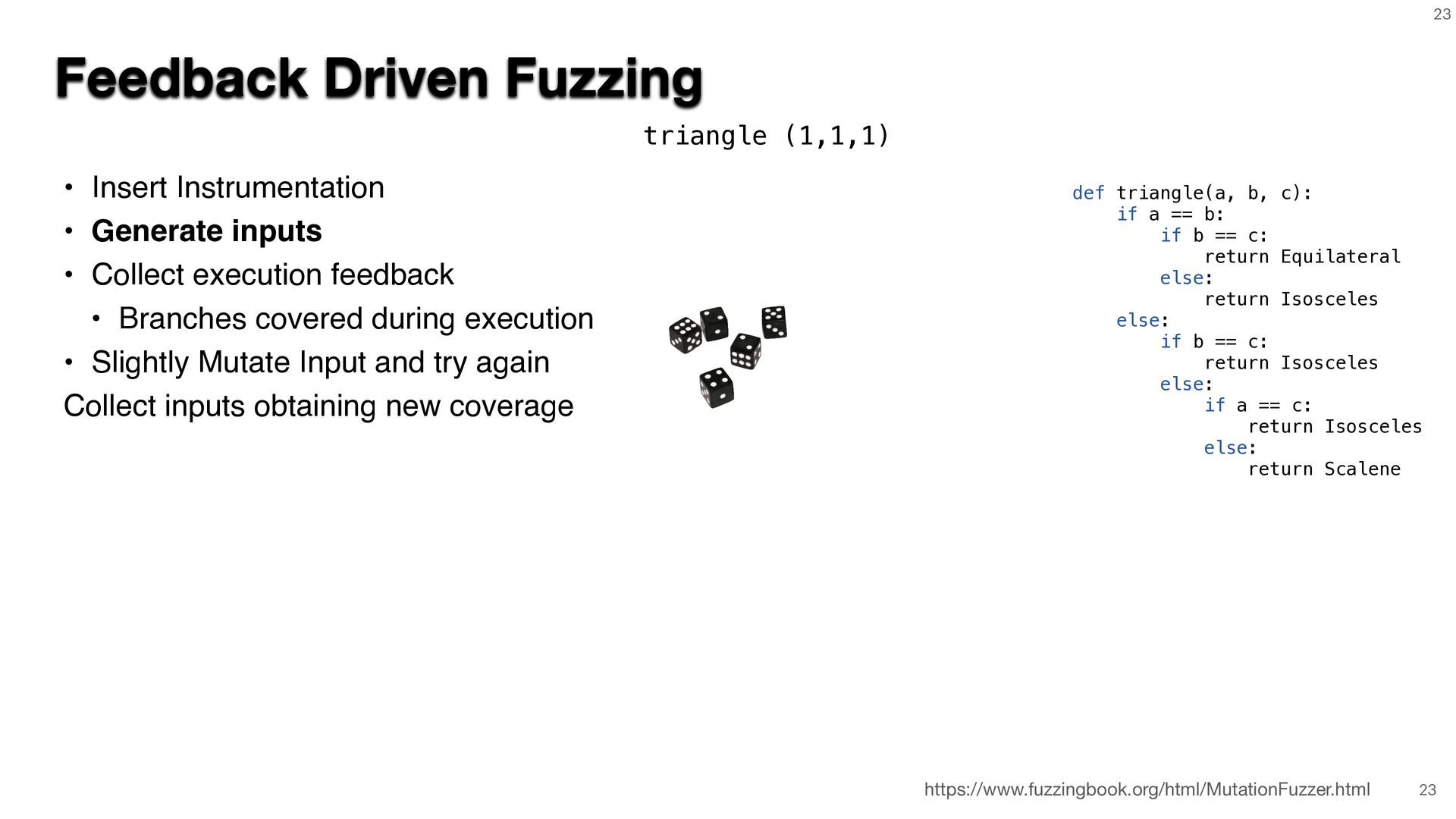{kind=link}
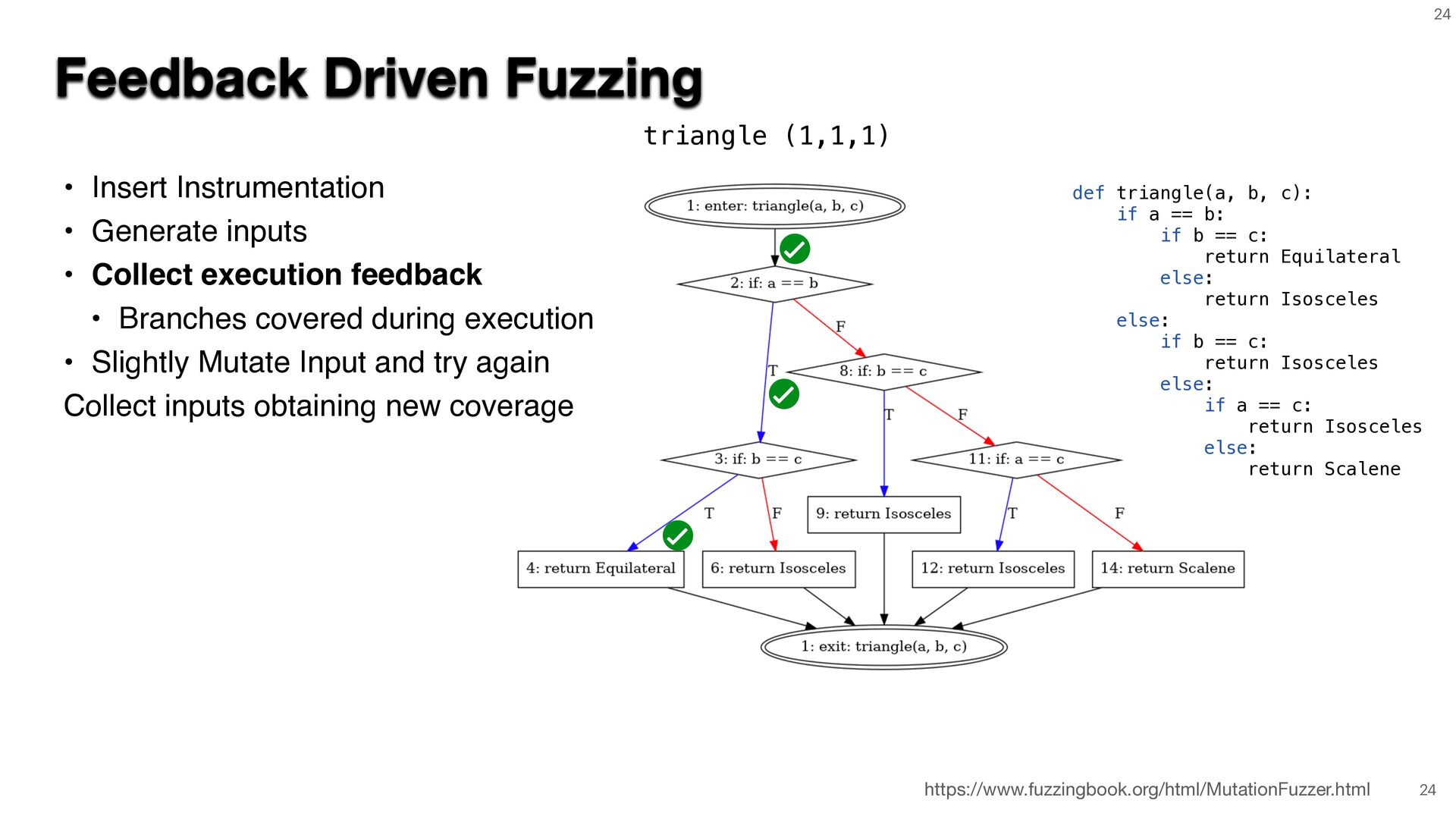{kind=link}
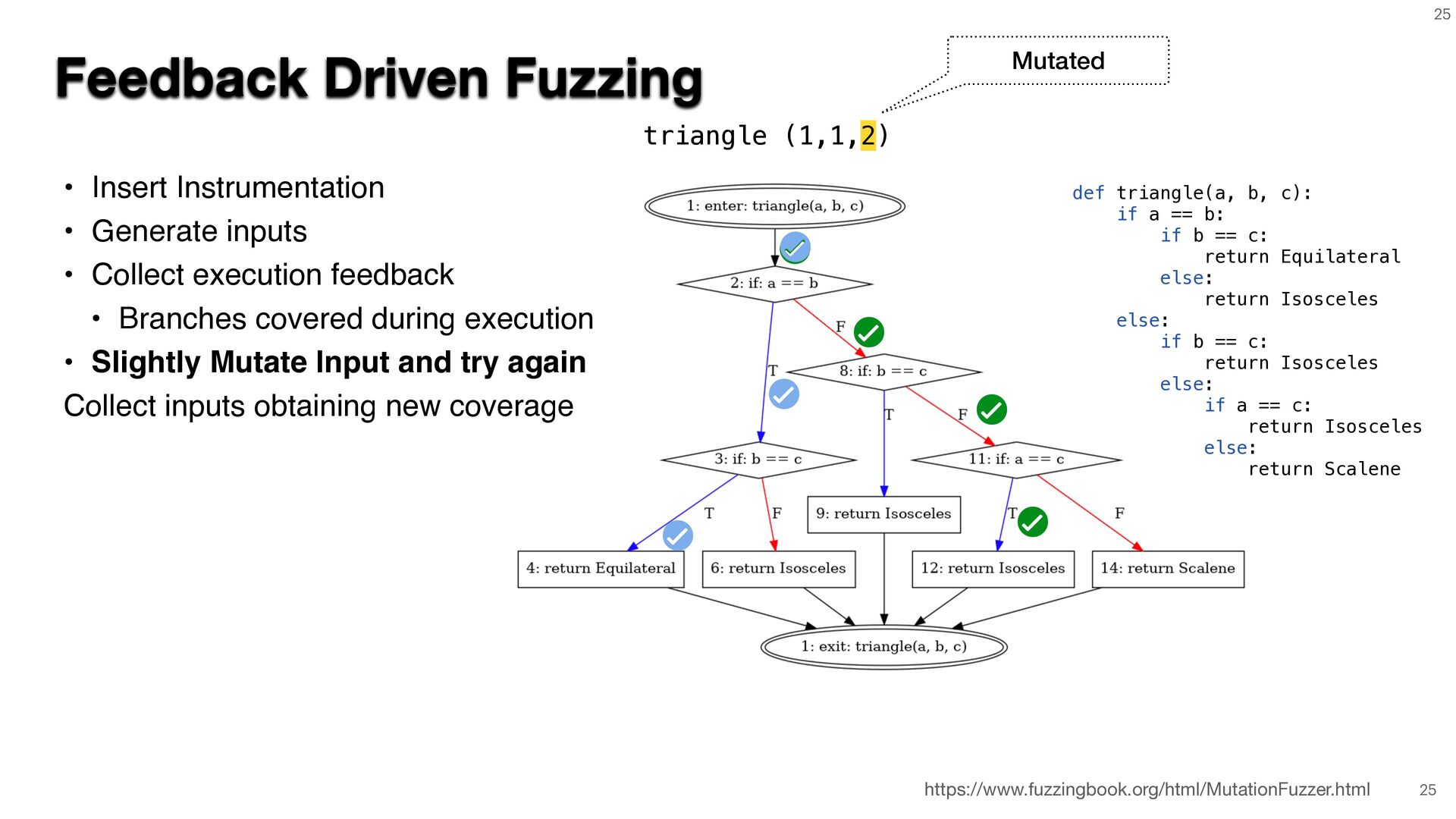{kind=link}
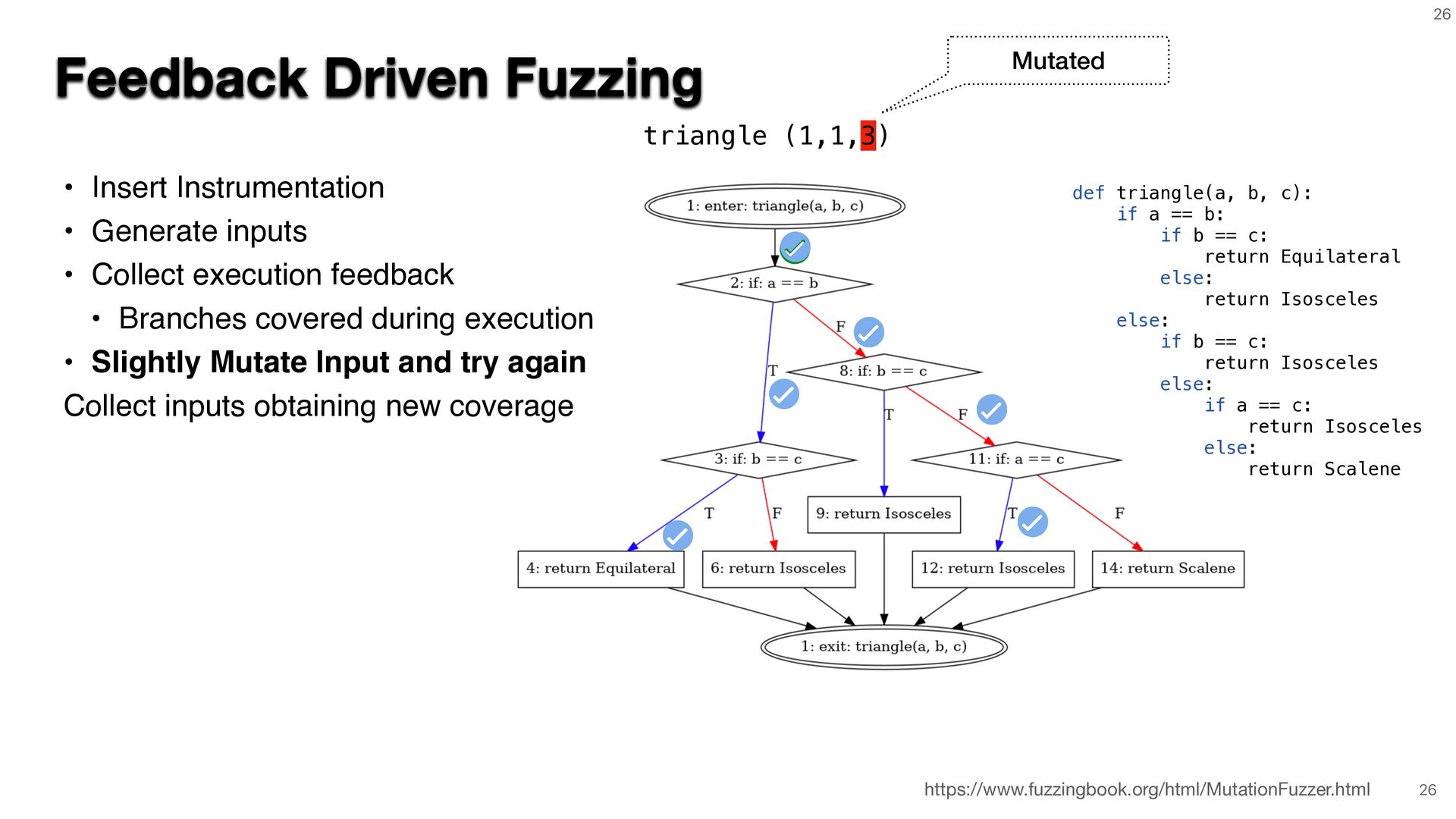{kind=link}
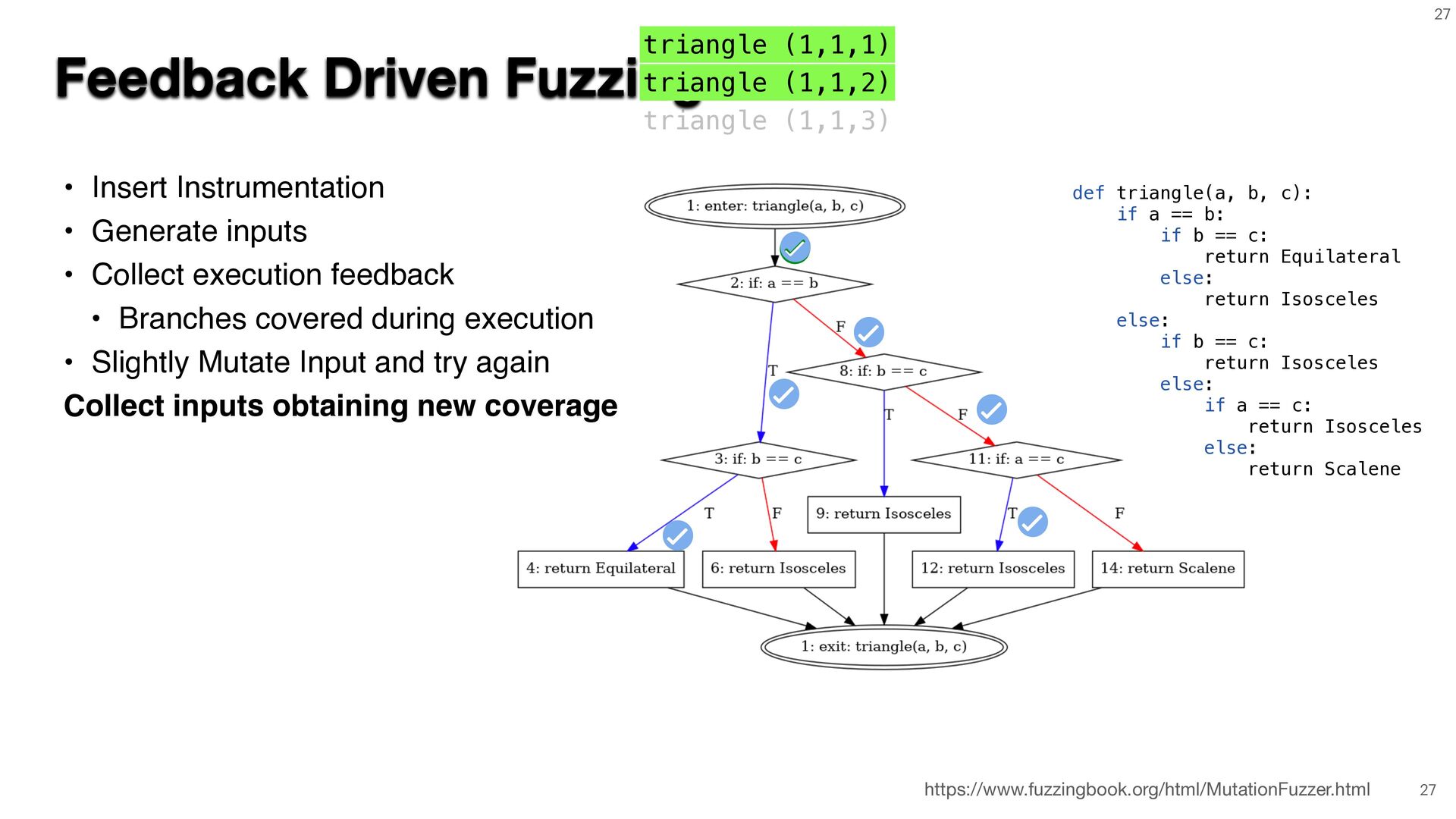{kind=link}
{kind=link}
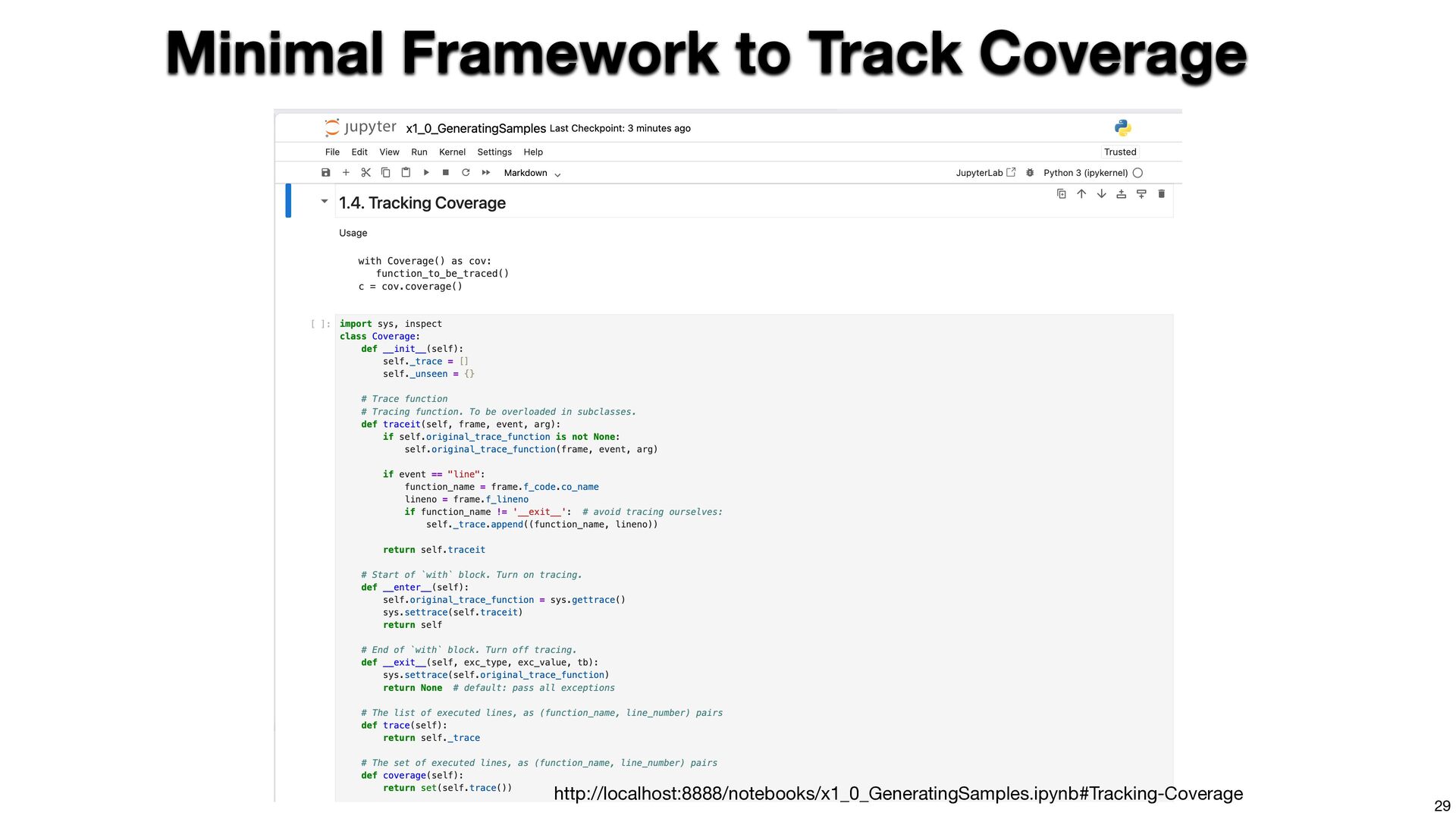{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![34 JSON Parser Validation [{"id":1},{"id":2,"tags":["x","y"]}] {"user":{"name":"alice","roles":["admin","dev"]}} [{"path":["home","docs"]},{"size":{"w":1920,"h":1080}}] {"api":{"status":200,"headers":{"content-type":"json"}}} {"system":{"services":[{"name":"db"},{"name":"cache"}]}} Business](https://files.speakerdeck.com/presentations/f5037af7e19141598e140b4d03383dde/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
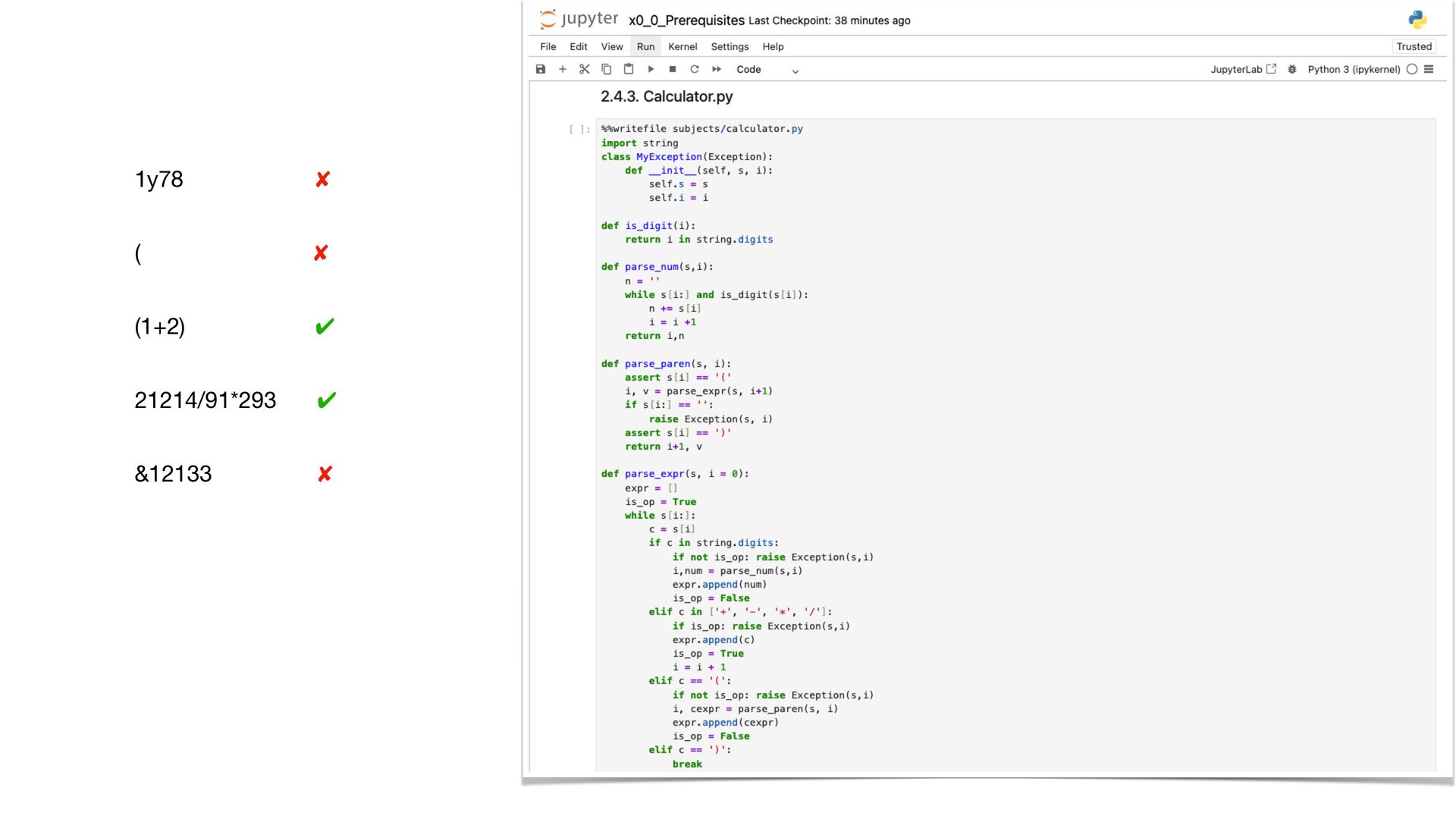{kind=link}
![38 Fuzzing Parsers $ ./fuzz [;x1-GPZ+wcckc];,N9J+?#6^6\e?]9lu 2_%'4GX"0VUB[E/r ~fApu6b8<{%siq8Z h.6{V,hr?;{Ti.r3PIxMMMv6{xS^+'Hq! AxB"YXRS@!Kd6;wtAMefFWM(`|J_<1~o}](https://files.speakerdeck.com/presentations/f5037af7e19141598e140b4d03383dde/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
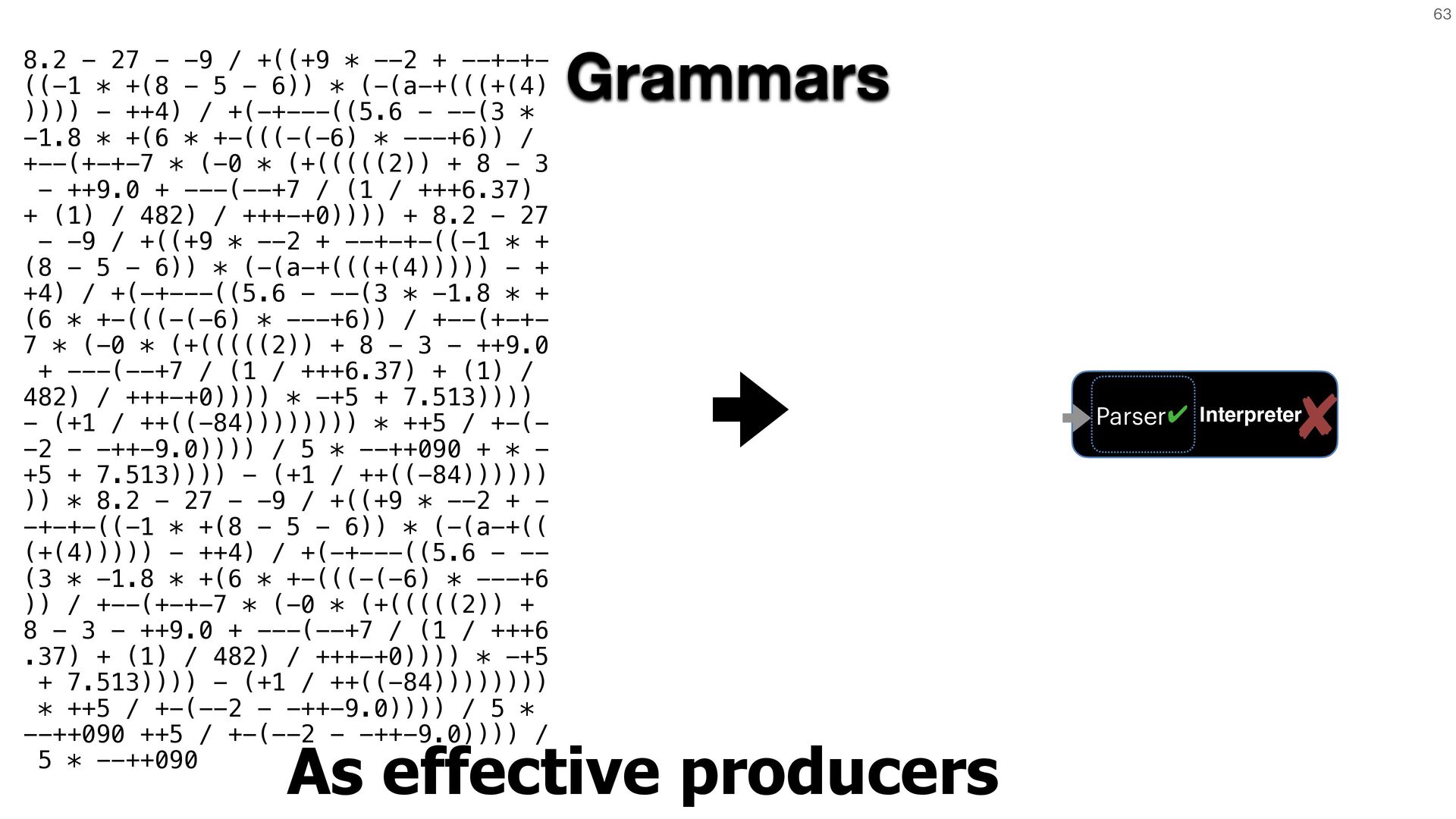{kind=link}
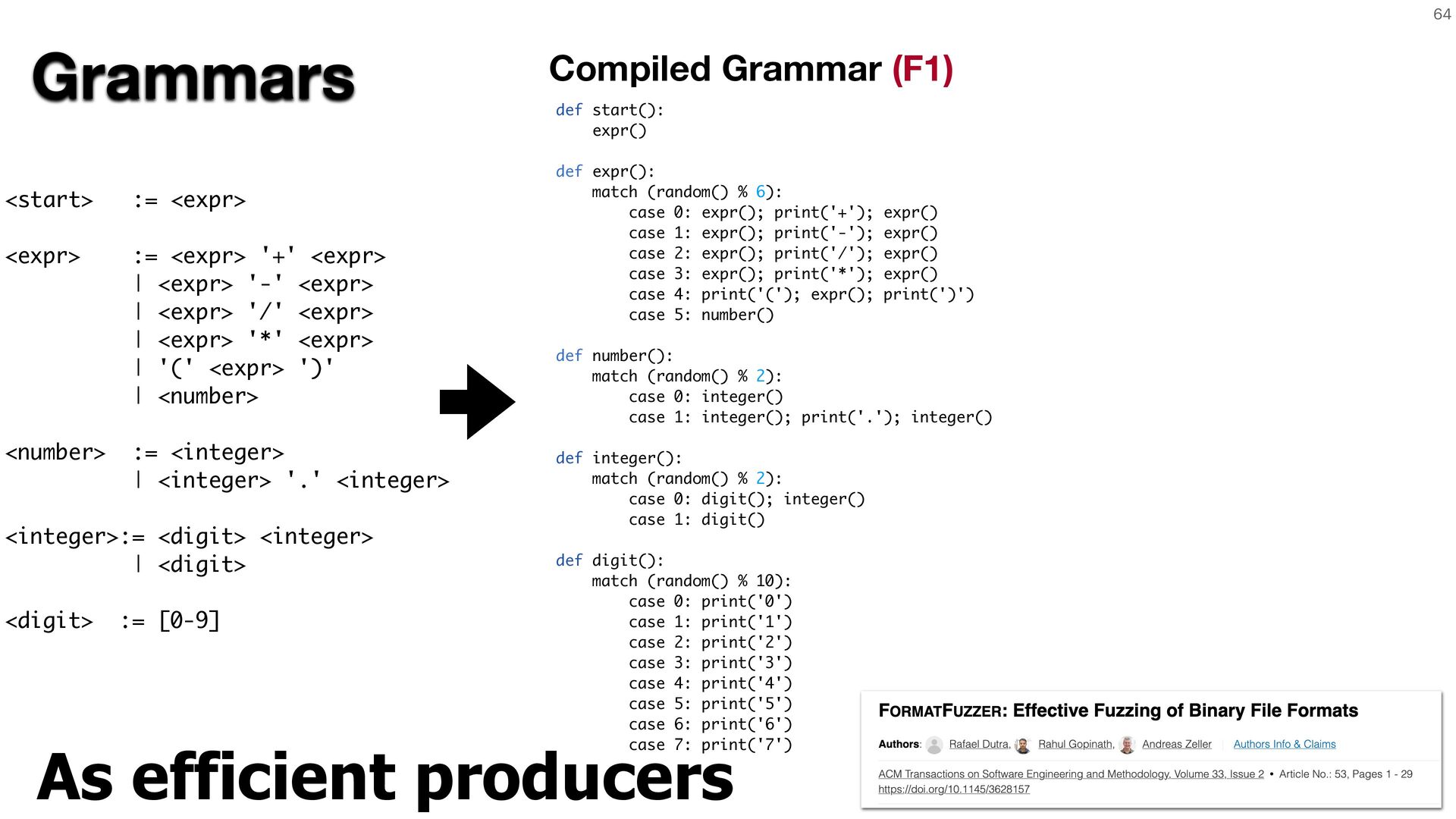{kind=link}
{kind=link}
{kind=link}
{kind=link}
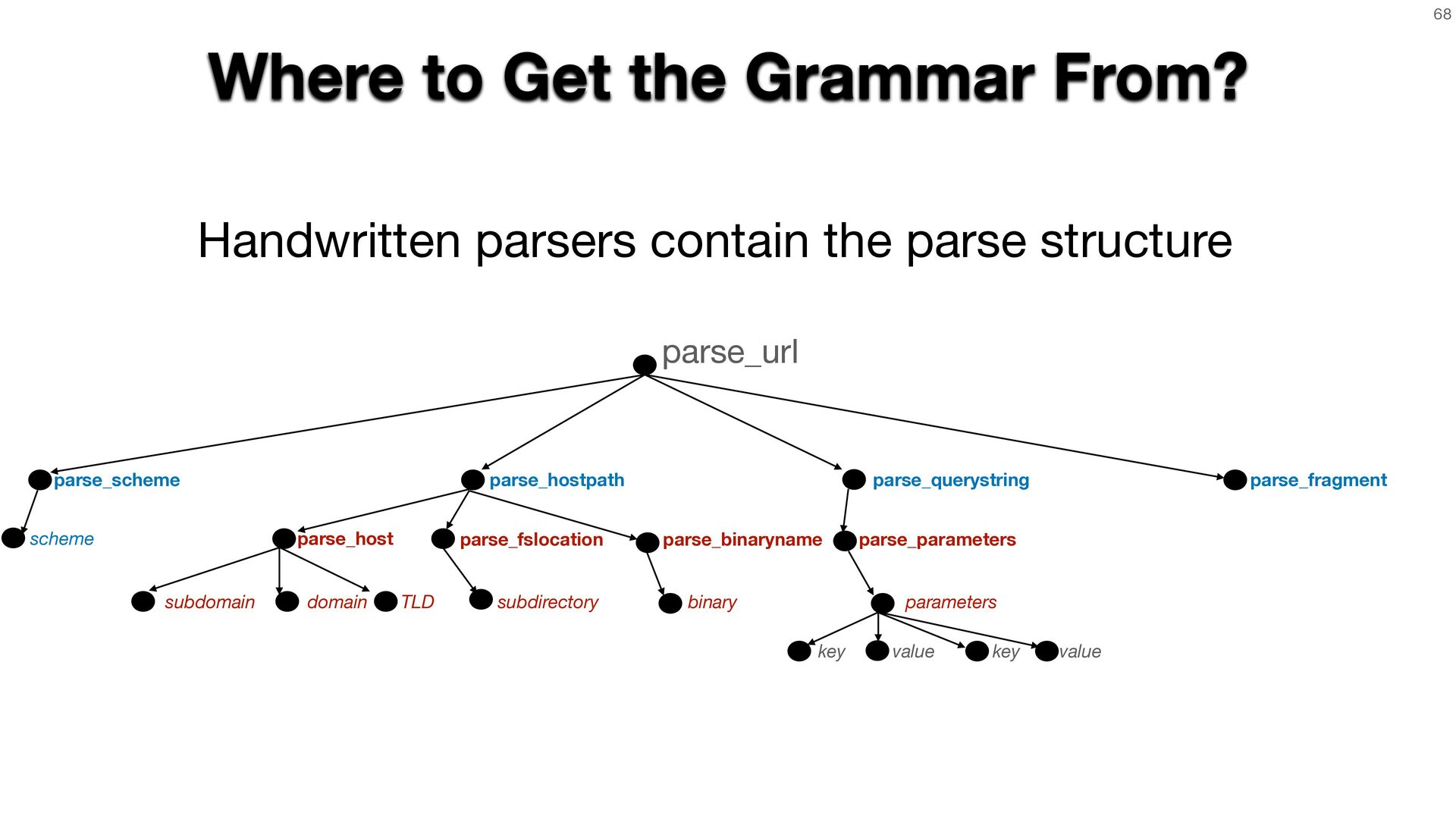{kind=link}
{kind=link}
![70 http://user:[email protected]:80/?q=path#ref urlparse:url = 'http://user:[email protected]:80/?q=path#ref' urlsplit:scheme = 'http' urlsplit:netloc =](https://files.speakerdeck.com/presentations/f5037af7e19141598e140b4d03383dde/slide_69.jpg){kind=link}
{kind=link}
![{ '<urlparse:url>': [ ['<urlsplit:scheme>', '://', '<urlsplit:netloc>', '/?', '<urlsplit:query>', '#', '<urlsplit:fragment>'],](https://files.speakerdeck.com/presentations/f5037af7e19141598e140b4d03383dde/slide_71.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![80 def parse_csv(s,i): while s[i:]: if is_digit(s[i]): n,j = num(s[i:])](https://files.speakerdeck.com/presentations/f5037af7e19141598e140b4d03383dde/slide_79.jpg){kind=link}
![81 def parse_csv(s,i): while s[i:]: if is_digit(s[i]): n,j = num(s[i:])](https://files.speakerdeck.com/presentations/f5037af7e19141598e140b4d03383dde/slide_80.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
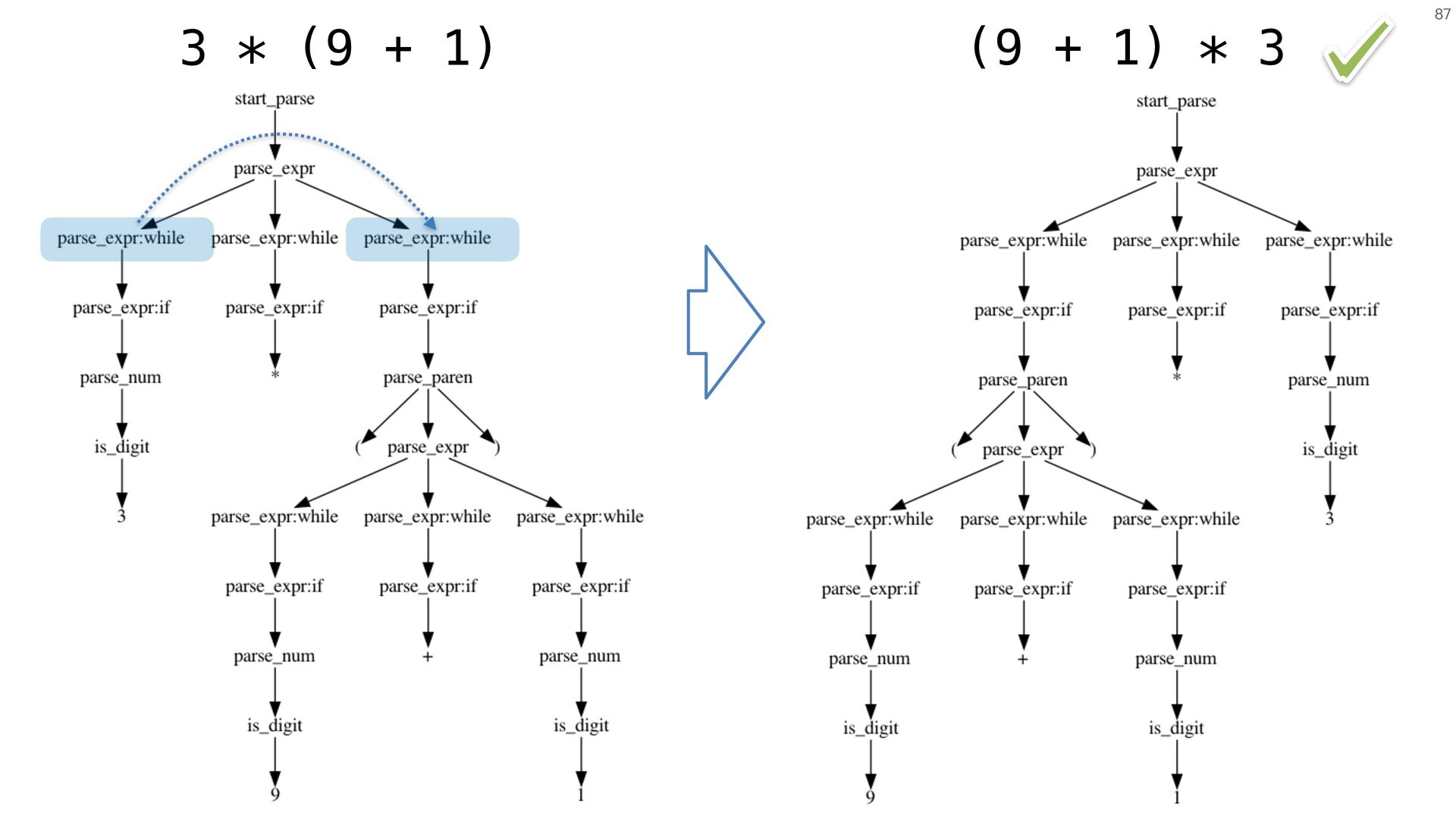{kind=link}
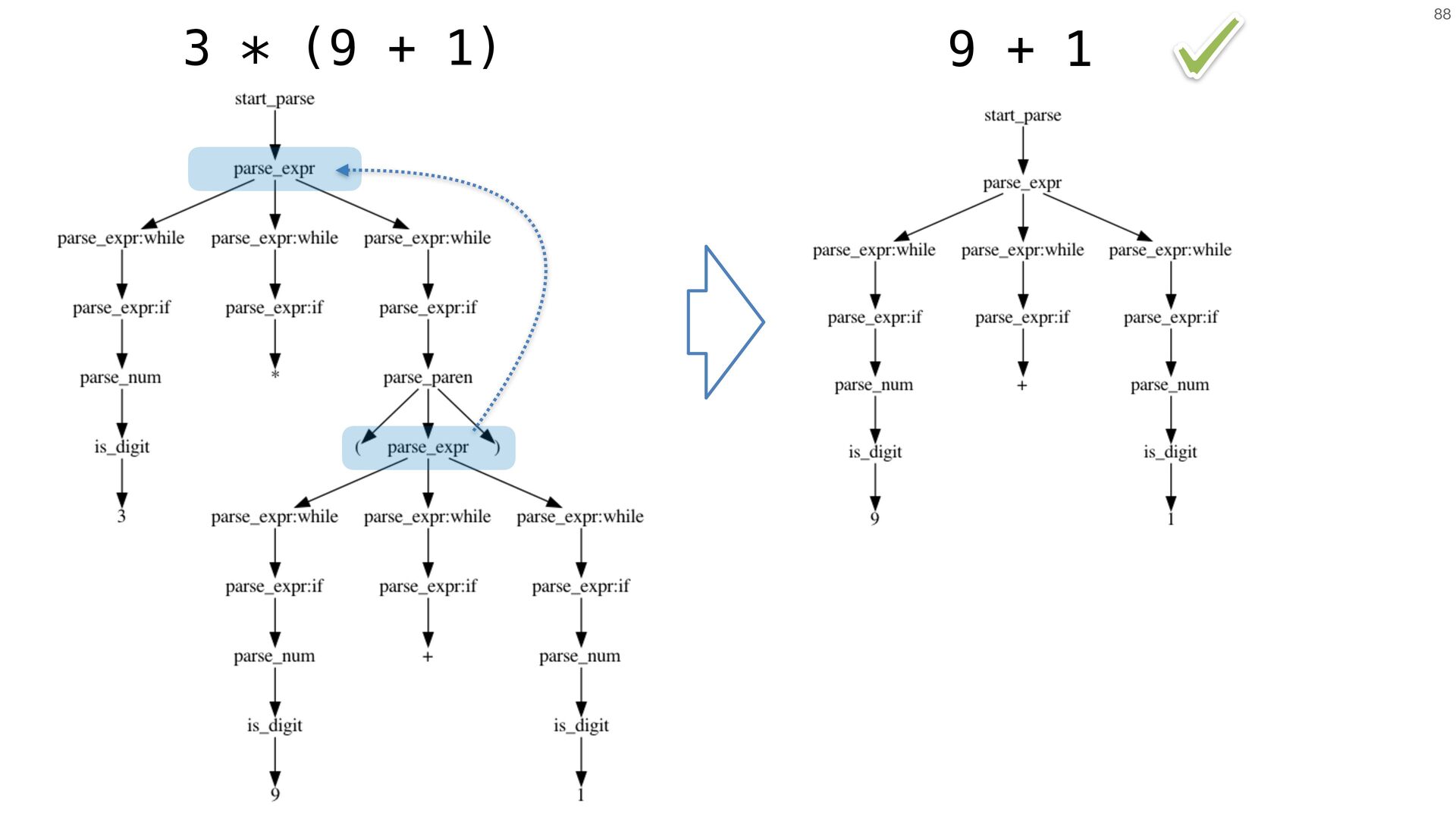{kind=link}
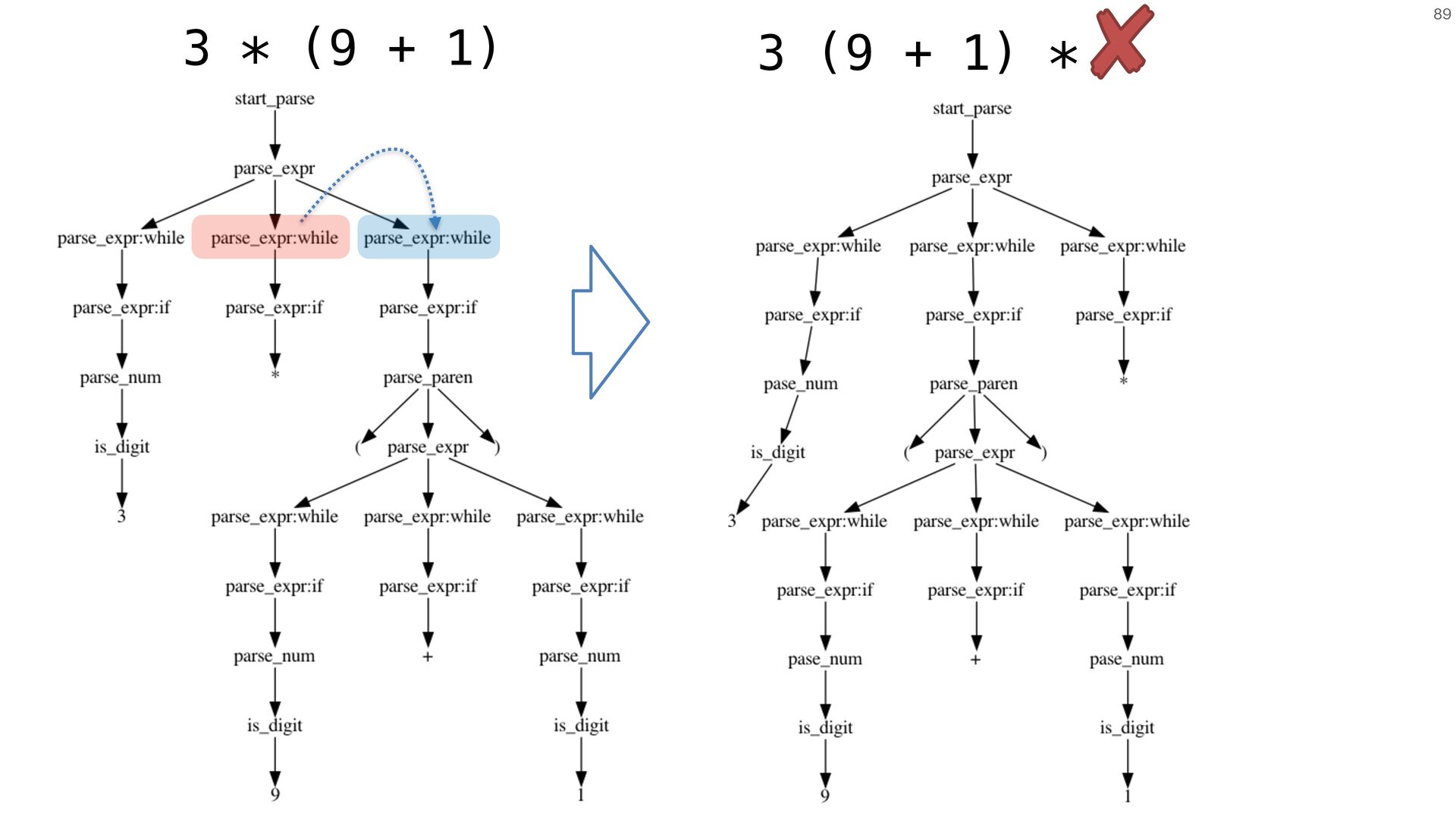{kind=link}
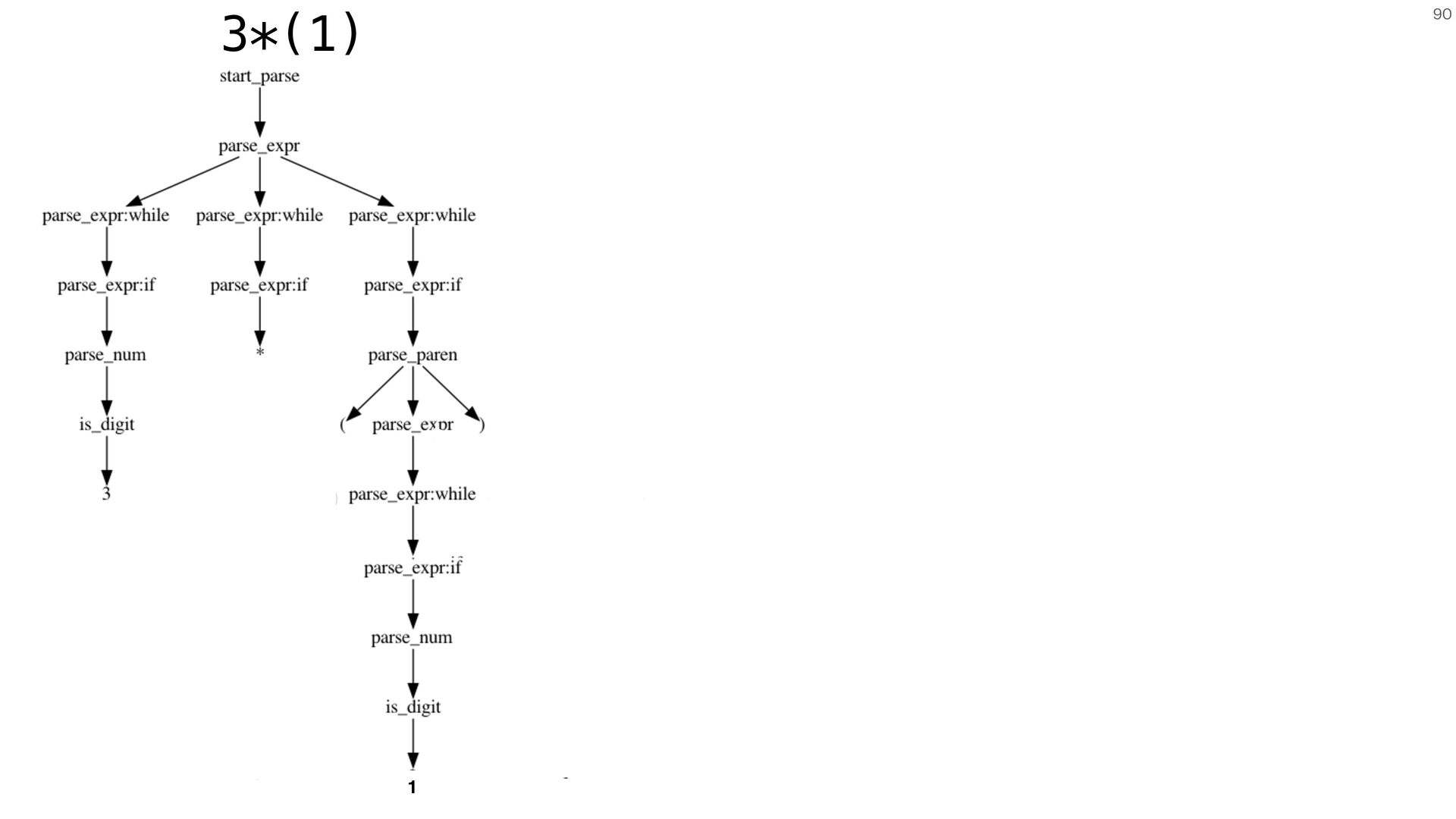{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
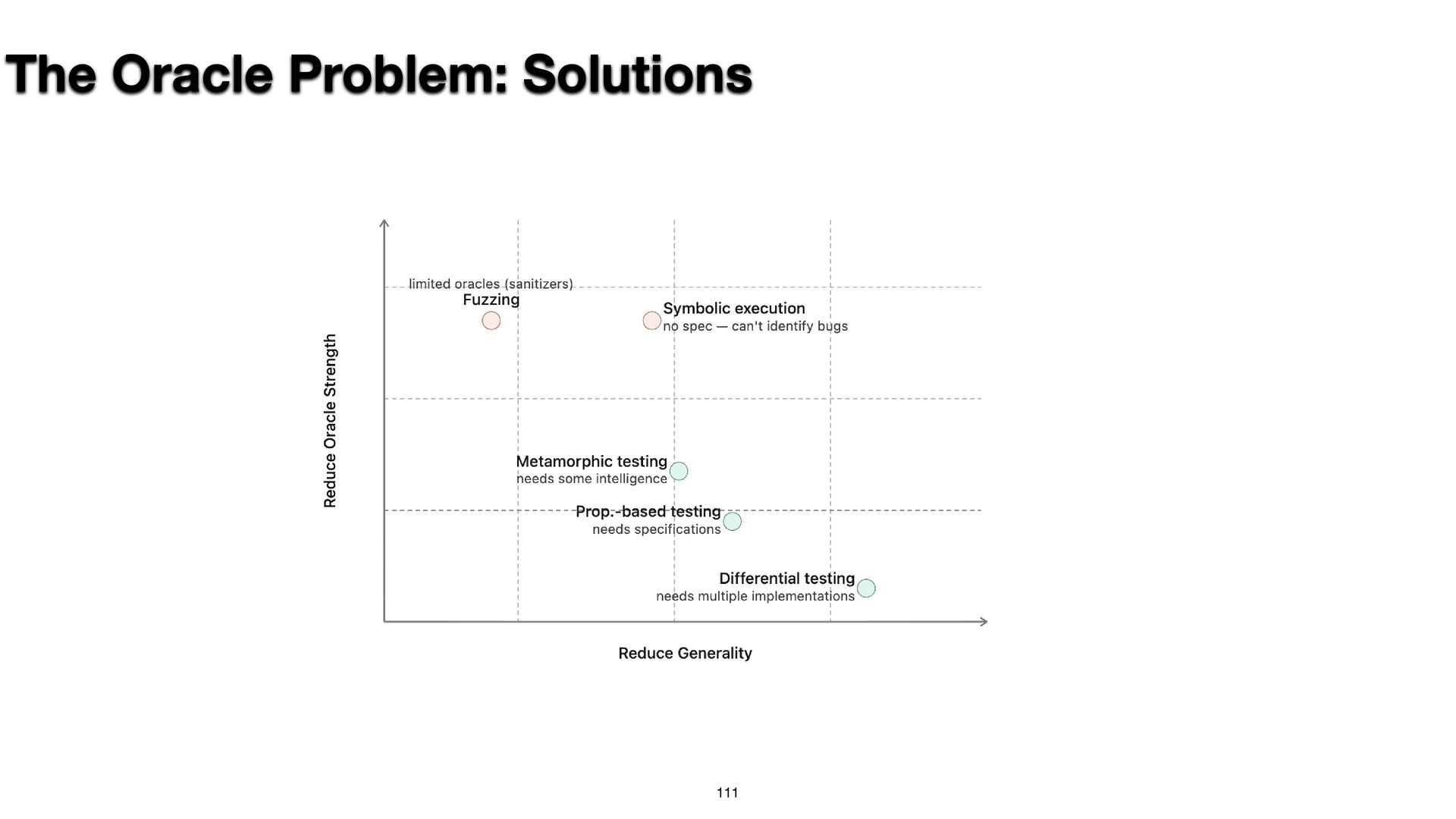{kind=link}
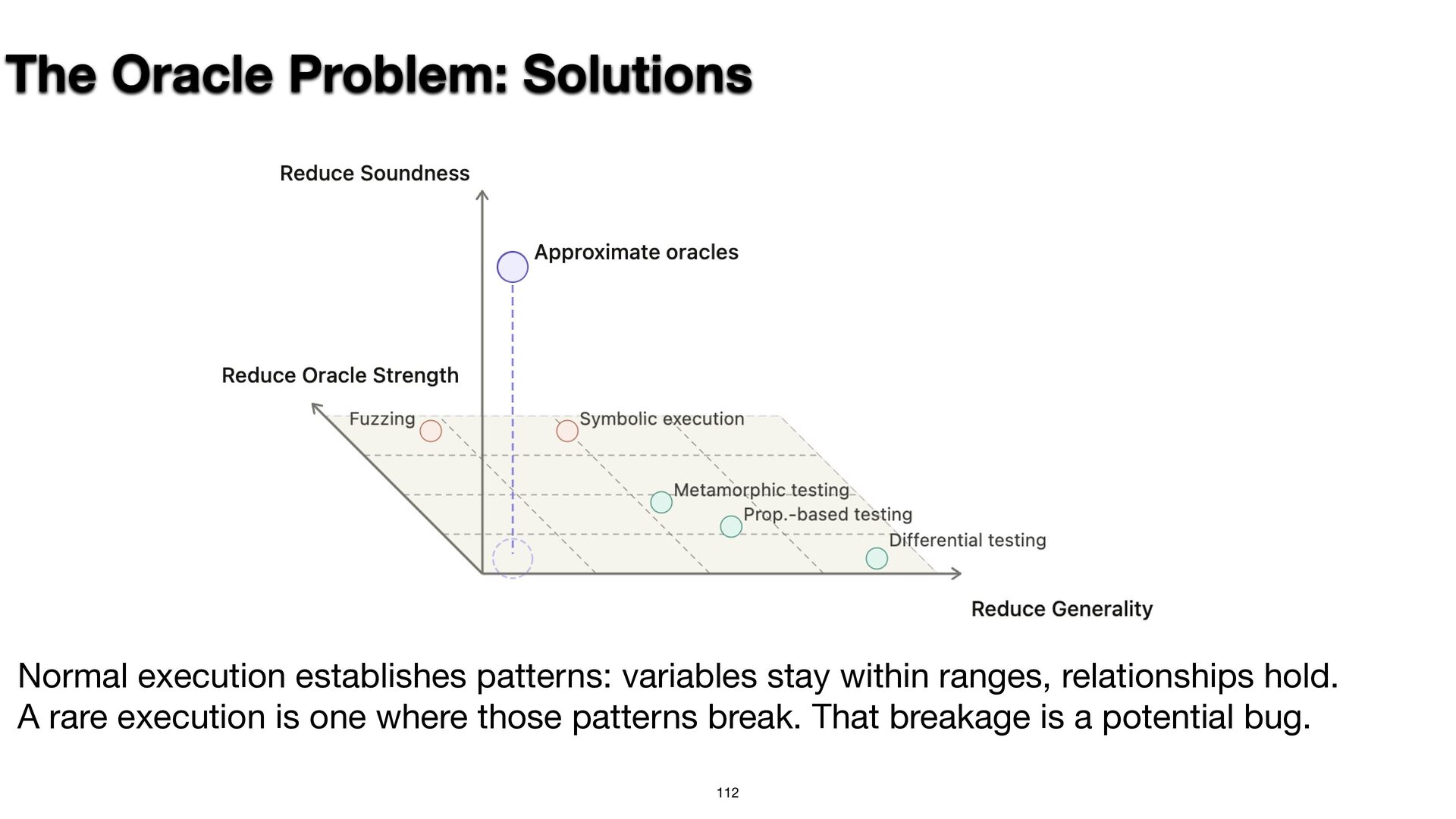{kind=link}
{kind=link}
{kind=link}
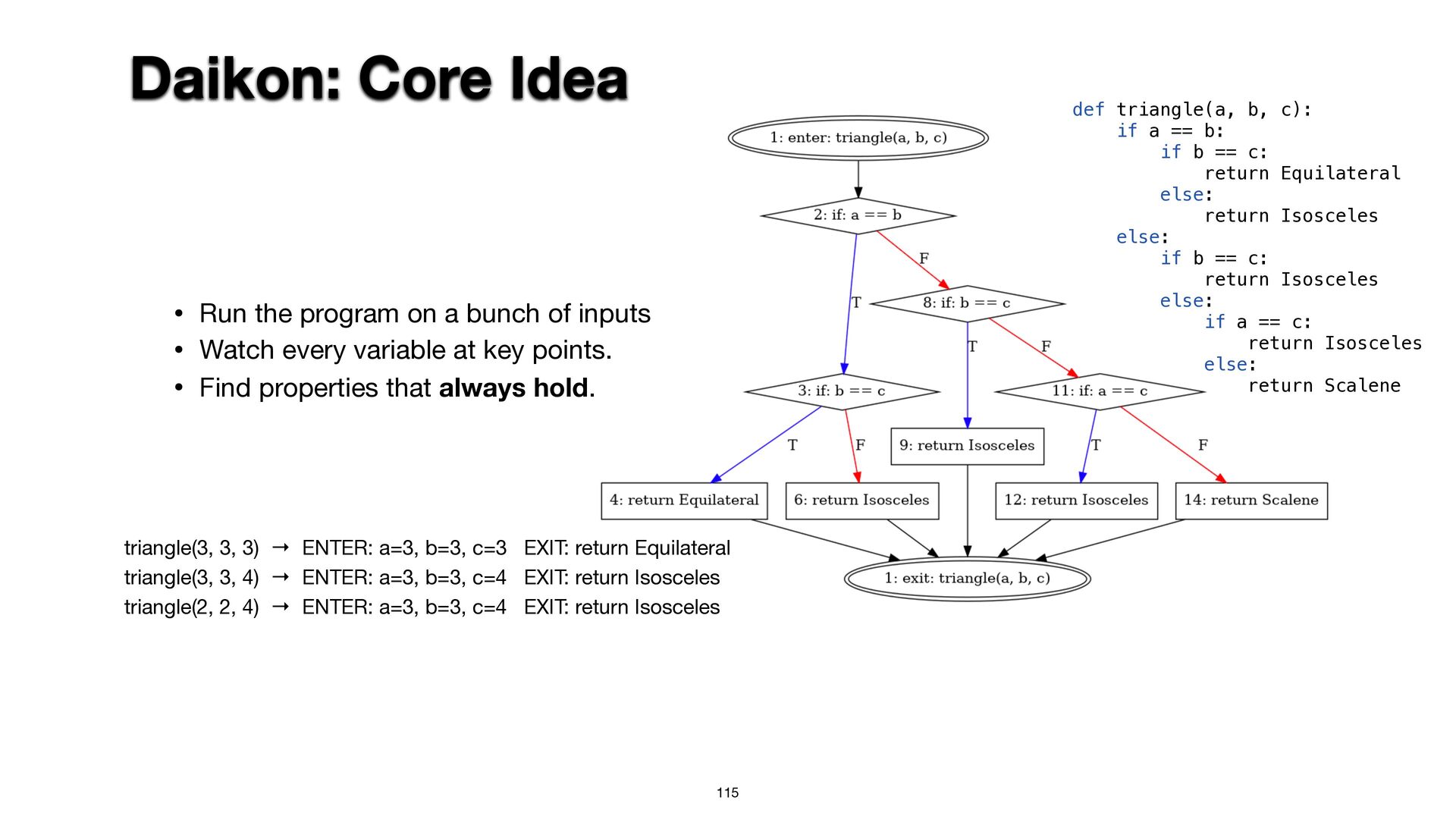{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
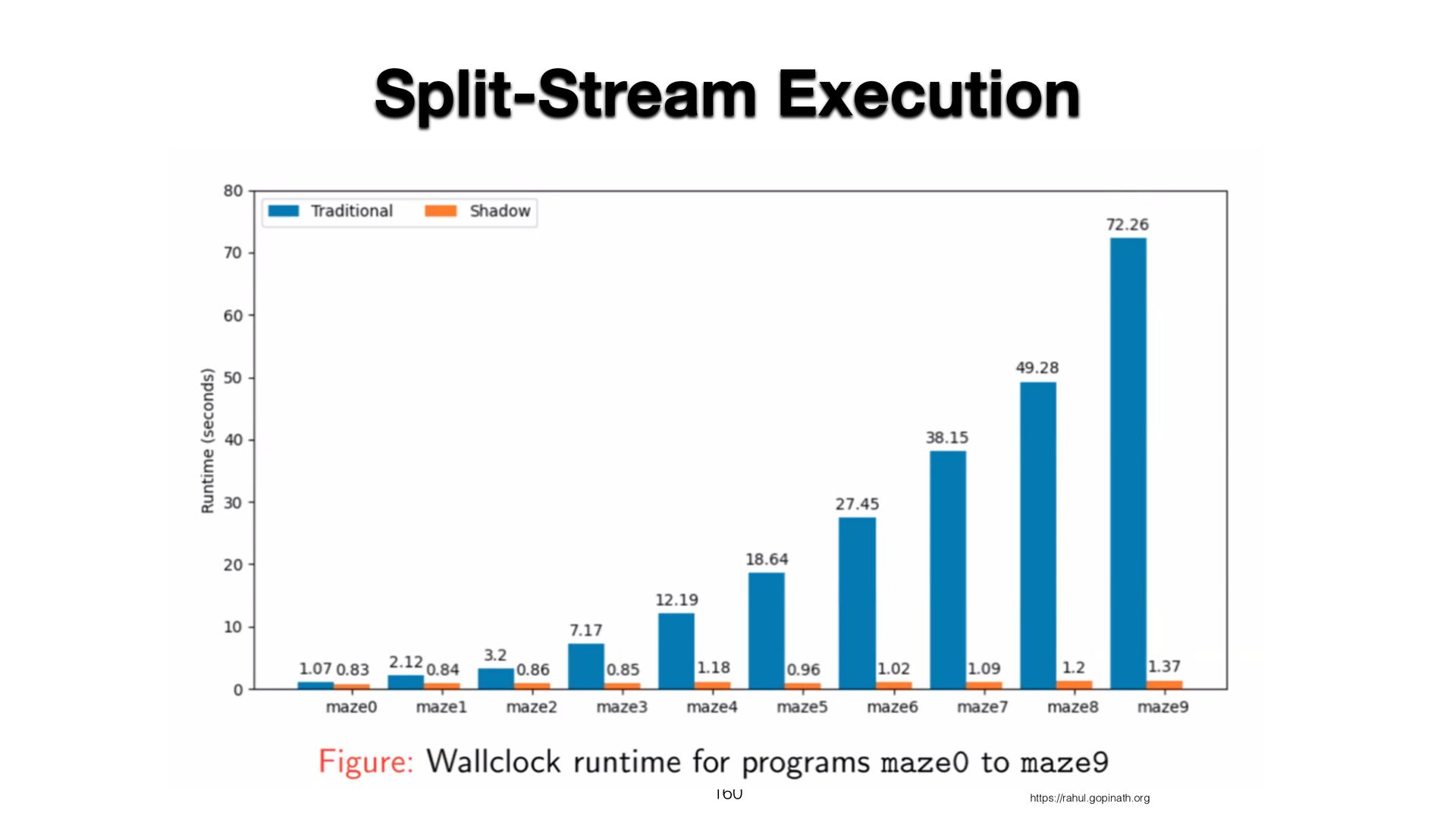{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
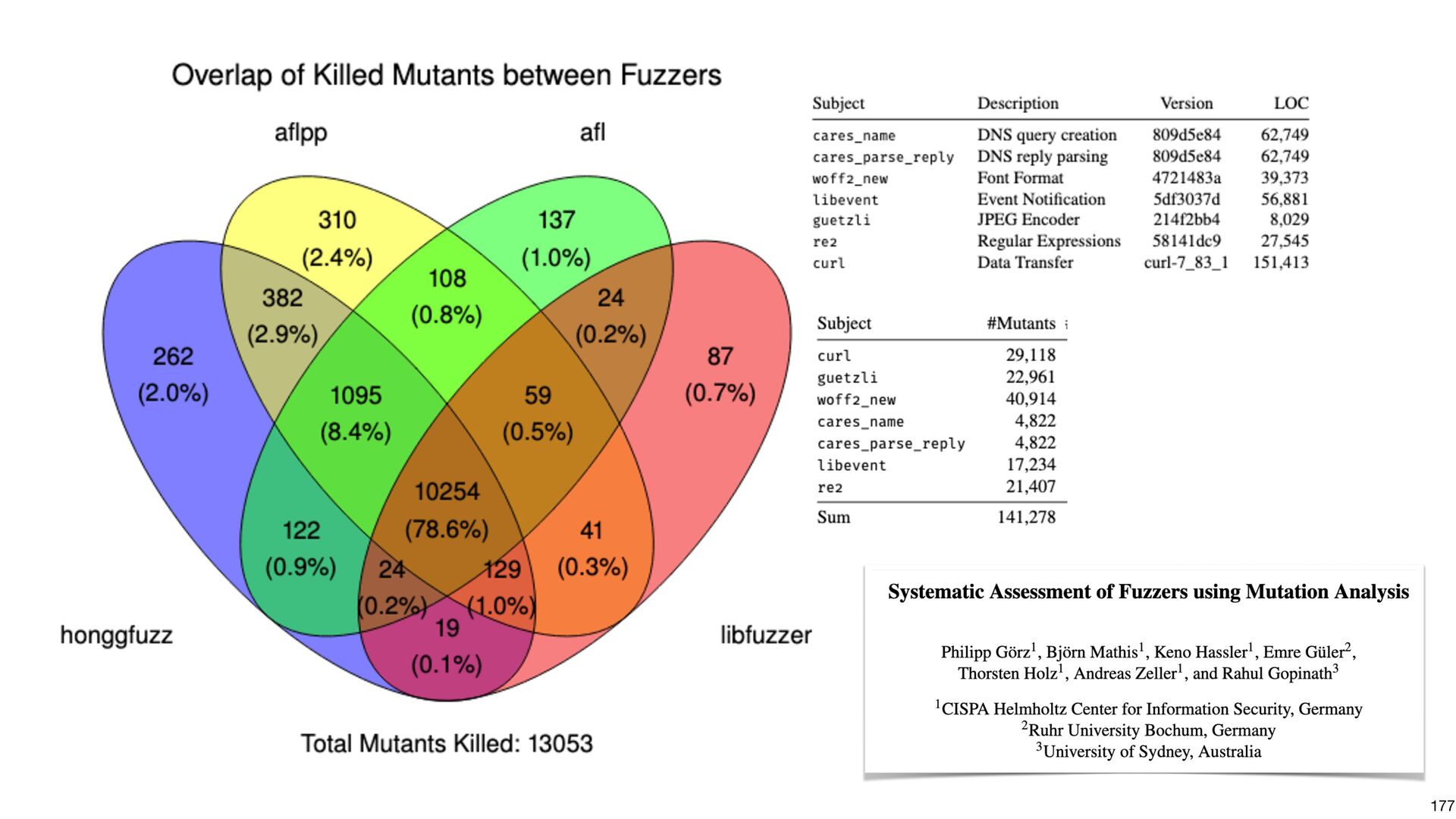{kind=link}
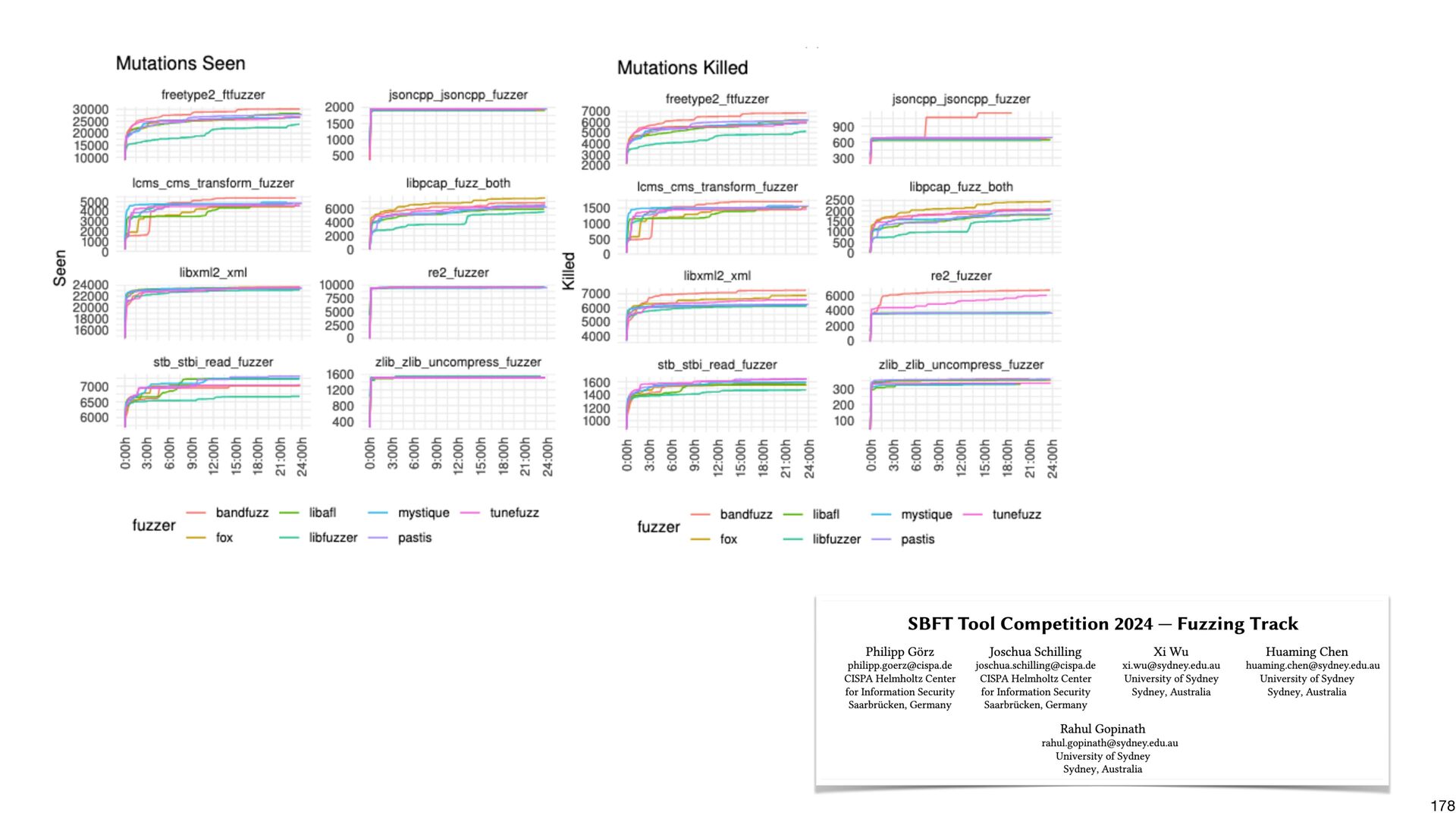{kind=link}
{kind=link}
{kind=link}
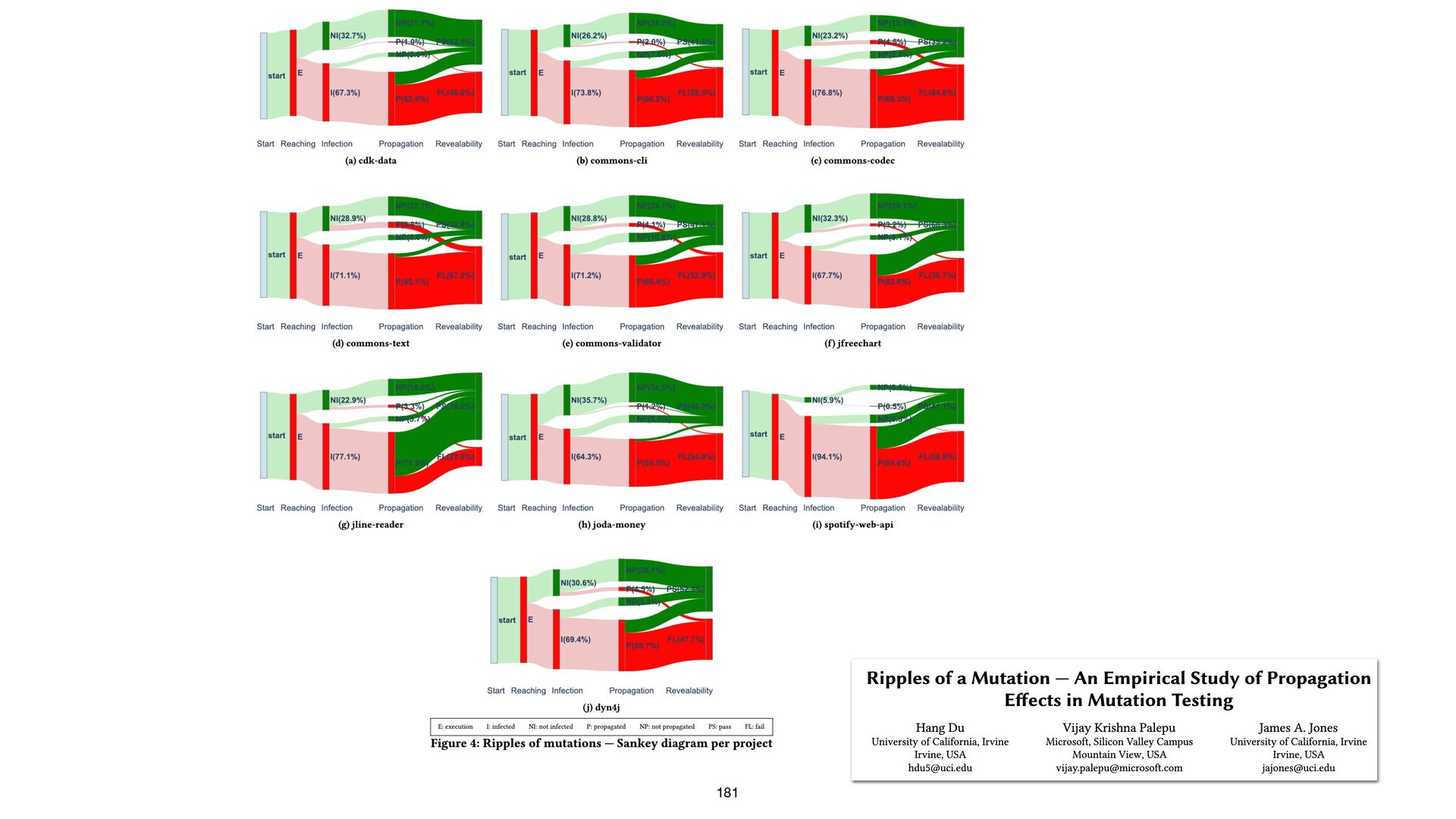{kind=link}